Introduction
| Performance | Average | Worst |
|---|---|---|
| Space | ||
| Search | ||
| Insert | ||
| Delete |
In computer science, a trie (/ˈtriː/, /ˈtraɪ/), also called digital tree or prefix tree1, is a type of k-ary search tree, a tree data structure used for locating specific keys from within a set. These keys are most often strings, with links between nodes defined not by the entire key, but by individual characters. In order to access a key (to recover its value, change it, or remove it), the trie is traversed depth-first, following the links between nodes, which represent each character in the key.
Unlike a binary search tree, nodes in the trie do not store their associated key. Instead, a node’s position in the trie defines the key with which it is associated. This distributes the value of each key across the data structure, and means that not every node necessarily has an associated value.
All the children of a node have a common prefix of the string associated with that parent node, and the root is associated with the empty string. This task of storing data accessible by its prefix can be accomplished in a memory-optimized way by employing a radix tree.
Though tries can be keyed by character strings, they need not be. The same algorithms can be adapted for ordered lists of any underlying type, e.g. permutations of digits or shapes. In particular, a bitwise trie is keyed on the individual bits making up a piece of fixed-length binary data, such as an integer or memory address. The key lookup complexity of a trie remains proportional to the key size. Specialized trie implementations such as compressed tries are used to deal with the enormous space requirement of a trie in naive implementations.
History, etymology, and pronunciation
The idea of a trie for representing a set of strings was first abstractly described by Axel Thue in 19122 3. Tries were first described in a computer context by René de la Briandais in 1959.
The idea was independently described in 1960 by Edward Fredkin, who coined the term trie, pronouncing it /ˈtriː/ (as “tree”), after the middle syllable of retrieval. However, other authors pronounce it /ˈtraɪ/ (as “try”), in an attempt to distinguish it verbally from “tree”.
Overview
Tries are a form of string-indexed look-up data structure, which is used to store a dictionary list of words that can be searched on in a manner that allows for efficient generation of completion lists. A prefix trie is an ordered tree data structure used in the representation of a set of strings over a finite alphabet set, which allows efficient storage of words with common prefixes.
Tries can be efficacious on string-searching algorithms such as predictive text, approximate string matching, and spell checking in comparison to a binary search trees. A trie can be seen as a tree-shaped deterministic finite automaton4.
Operations
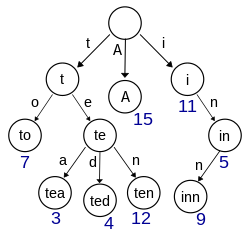
 Fig. 2: Trie representation of the string sets: sea, sells, and she.
Fig. 2: Trie representation of the string sets: sea, sells, and she.
Tries support various operations: insertion, deletion, and lookup of a string key. Tries are composed of that contain links that are either references to other suffix child nodes, or . Except for root, each node is pointed to by just one other node, called the parent. Each node contains links, where is the cardinality of the applicable alphabet, although tries have a substantial number of links. In most cases, the size of array is bitlength of the character encoding - 256 in the case of (unsigned) ASCII.
The links within in emphasizes the following characteristics:
- Characters and string keys are implicitly stored in the trie data structure representation, and include a character sentinel value indicating string-termination.
- Each node contains one possible link to a prefix of strong keys of the set.
A basic structure type of nodes in the trie is as follows:
structure Node
Children Node[Alphabet-Size]
Is-Terminal Boolean
Value Data-Type
end structure
- may contain an optional
- , which is associated with each key stored in the last character of string, or terminal node.
Searching
Searching a in a trie is guided by the characters in the search string key, as each node in the trie contains a corresponding link to each possible character in the given string. Thus, following the string within the trie yields the associated for the given string key. A link within search execution indicates the inexistence of the key.
Following pseudocode implements the search procedure for a given string key () in a rooted trie ().
Trie-Find(x, key)
for 0 ≤ i < key.length do
if x.Children[key[i]] = nil then
return false
end if
x := x.Children[key[i]]
repeat
return x.Value
In the above pseudocode, and correspond to the pointer of trie’s root node and the string key respectively. The search operation, in a standard trie, takes , 





Tries occupy less space in comparison with BST if it encompasses a large number of short strings, since nodes share common initial string subsequences and stores the keys implicitly on the structure. The terminal node of the tree contains a non-nil 
Insertion
Insertion into trie is guided by using the character sets as the indexes into the 
Trie-Insert(x, key, value)
for 0 ≤ i < key.length do
if x.Children[key[i]] = nil then
x.Children[key[i]] := Node()
end if
x := x.Children[key[i]]
repeat
x.Value := value
x.Is-Terminal := True
If a 



Deletion
Deletion of a key–value pair from a trie involves finding the terminal node with the corresponding string key, marking the terminal indicator and value to false and
Following is a recursive procedure for removing a string key ( 
Trie-Delete(x, key)
if key = nil then
if x.Is-Terminal = True then
x.Is-Terminal := False
x.Value := nil
end if
for 0 ≤ i < x.Children.length
if x.Children[i] != nil
return x
end if
repeat
return nil
end if
x.Children[key[0]] := Trie-Delete(x.Children[key[0]], key[1:])
return x
The procedures begins by examining the
Replacing other data structures
Replacement for hash tables
A trie can be used to replace a hash table, over which it has the following advantages:
- Searching for a node with an associated key of size
has the complexity of
, whereas an imperfect hash function may have numerous colliding keys, and the worst-case lookup speed of such a table would be
, where
denotes the total number of nodes within the table.
- Tries do not need a hash function for the operation, unlike a hash table; there are also no collisions of different keys in a trie.
- Buckets in a trie, which are analogous to hash table buckets that store key collisions, are necessary only if a single key is associated with more than one value.
- String keys within the trie can be sorted using a predetermined alphabetical ordering.
However, tries are less efficient than a hash table when the data is directly accessed on a secondary storage device such as a hard disk drive that has higher random access time than the main memory. Tries are also disadvantageous when the key value cannot be easily represented as string, such as floating point numbers where multiple representations are possible (e.g. 1 is equivalent to 1.0, +1.0, 1.00, etc.), however it can be unambiguously represented as a binary number in IEEE 754, in comparison to two’s complement format.
Implementation strategies
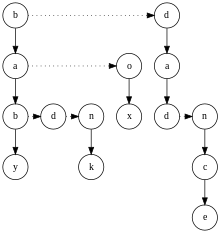 Fig. 3: A trie implemented as a left-child right-sibling binary tree: vertical arrows are {baby, bad, bank, box, dad, dance}. The lists are sorted to allow traversal in lexicographic order.
Fig. 3: A trie implemented as a left-child right-sibling binary tree: vertical arrows are {baby, bad, bank, box, dad, dance}. The lists are sorted to allow traversal in lexicographic order.
Tries can be represented in several ways, corresponding to different trade-offs between memory use and speed of the operations. Using a vector of pointers for representing a trie consumes enormous space; however, memory space can be reduced at the expense of running time if a singly linked list is used for each node vector, as most entries of the vector contains
Techniques such as alphabet reduction may alleviate the high space complexity by reinterpreting the original string as a long string over a smaller alphabet i.e. a string of n bytes can alternatively be regarded as a string of 2_n_ four-bit units and stored in a trie with sixteen pointers per node. However, lookups need to visit twice as many nodes in the worst-case, although space requirements go down by a factor of eight. Other techniques include storing a vector of 256 ASCII pointers as a bitmap of 256 bits representing ASCII alphabet, which reduces the size of individual nodes dramatically.
Bitwise tries
Bitwise tries are used to address the enormous space requirement for the trie nodes in a naive simple pointer vector implementations. Each character in the string key set is represented via individual bits, which are used to traverse the trie over a string key. The implementations for these types of trie use vectorized CPU instructions to find the first set bit in a fixed-length key input (e.g. GCC’s __builtin_clz() intrinsic function). Accordingly, the set bit is used to index the first item, or child node, in the 32- or 64-entry based bitwise tree. Search then proceeds by testing each subsequent bit in the key.
This procedure is also cache-local and highly parallelizable due to register independency, and thus performant on out-of-order execution CPUs.
Compressed tries
Radix tree, also known as a compressed trie, is a space-optimized variant of a trie in which nodes with only one child get merged with its parents; elimination of branches of the nodes with a single child results in better in both space and time metrics. This works best when the trie remains static and set of keys stored are very sparse within their representation space.
One more approach is to “pack” the trie, in which a space-efficient implementation of a sparse packed trie applied to automatic hyphenation, in which the descendants of each node may be interleaved in memory.
Patricia trees
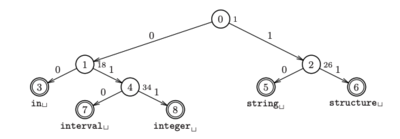
 Fig. 4: Patricia tree representation of string keys: in, integer, interval, string, and structure.
Fig. 4: Patricia tree representation of string keys: in, integer, interval, string, and structure.
Patricia trees are a particular implementation of compressed binary trie that utilize binary encoding of the string keys in its representation. Every node in a Patricia tree contains an index, known as a “skip number”, that stores the node’s branching index to avoid empty subtrees during traversal. A naive implementation of a trie consumes immense storage due to larger number of leaf-nodes caused by sparse distribution of keys; Patricia trees can be efficient for such cases.
A representation of a Patricia tree with string keys 

Applications
Trie data structures are commonly used in predictive text or autocomplete dictionaries, and approximate matching algorithms. Tries enable faster searches, occupy less space, especially when the set contains large number of short strings, thus used in spell checking, hyphenation applications and longest prefix match algorithms. However, if storing dictionary words is all that is required (i.e. there is no need to store metadata associated with each word), a minimal deterministic acyclic finite state automaton (DAFSA) or radix tree would use less storage space than a trie. This is because DAFSAs and radix trees can compress identical branches from the trie which correspond to the same suffixes (or parts) of different words being stored. String dictionaries are also utilized in natural language processing, such as finding lexicon of a text corpus.
Sorting
Lexicographic sorting of a set of string keys can be implemented by building a trie for the given keys and traversing the tree in pre-order fashion; this is also a form of radix sort. Tries are also fundamental data structures for burstsort, which is notable for being the fastest string sorting algorithm as of 2007, accompanied for its efficient use of CPU cache.
Full-text search
A special kind of trie, called a suffix tree, can be used to index all suffixes in a text to carry out fast full-text searches.
Web search engines
A specialized kind of trie called a compressed trie, is used in web search engines for storing the indexes - a collection of all searchable words. Each terminal node is associated with a list of URLs—called occurrence list—to pages that match the keyword. The trie is stored in the main memory, whereas the occurrence is kept in an external storage, frequently in large clusters, or the in-memory index points to documents stored in an external location.
Bioinformatics
Tries are used in Bioinformatics, notably in sequence alignment software applications such as BLAST, which indexes all the different substring of length k (called k-mers) of a text by storing the positions of their occurrences in a compressed trie sequence databases.
Internet routing
Compressed variants of tries, such as databases for managing Forwarding Information Base (FIB), are used in storing IP address prefixes within routers and bridges for prefix-based lookup to resolve mask-based operations in IP routing.
See also
- Suffix tree
- Hash trie
- Hash array mapped trie
- Prefix hash tree
- Ctrie
- HAT-trie
References
- ^ Jump up to: a b
- ^ Thue, Axel (1912). “Über die gegenseitige Lage gleicher Teile gewisser Zeichenreihen”. Skrifter Udgivne Af Videnskabs-Selskabet I Christiania. 1912 (1): 1–67. Cited by Knuth.
- ^ Jump up to: a b c d Knuth, Donald (1997). “6.3: Digital Searching”. The Art of Computer Programming Volume 3: Sorting and Searching (2nd ed.). Addison-Wesley. p. 492. ISBN 0-201-89685-0.
- ^ de la Briandais, René (1959). File searching using variable length keys (PDF). Proc. Western J. Computer Conf. pp. 295–298. doi: 10.1145/1457838.1457895. S2CID 10963780. Archived from the original (PDF) on 2020-02-11. Cited by Brass and by Knuth.
- ^ Jump up to: a b c d Brass, Peter (8 September 2008). Advanced Data Structures. UK: Cambridge University Press. doi: 10.1017/CBO9780511800191. ISBN 978-0521880374.
- ^ Jump up to: a b Edward Fredkin (1960). “Trie Memory”. Communications of the ACM. 3 (9): 490–499. doi: 10.1145/367390.367400. S2CID 15384533.
- ^ Jump up to: a b Black, Paul E. (2009-11-16). “trie”. Dictionary of Algorithms and Data Structures. National Institute of Standards and Technology. Archived from the original on 2011-04-29.
- ^ Jump up to: a b c d e Franklin Mark Liang (1983). Word Hy-phen-a-tion By Com-put-er (PDF) (Doctor of Philosophy thesis). Stanford University. Archived (PDF) from the original on 2005-11-11. Retrieved 2010-03-28.
- ^ “Trie”. School of Arts and Science, Rutgers University. 2022. Archived from the original on 17 April 2022. Retrieved 17 April 2022.
- ^ Connelly, Richard H.; Morris, F. Lockwood (1993). “A generalization of the trie data structure”. Mathematical Structures in Computer Science. Syracuse University. 5 (3): 381–418. doi: 10.1017/S0960129500000803. S2CID 18747244.
- ^ Jump up to: a b Aho, Alfred V.; Corasick, Margaret J. (Jun 1975). “Efficient String Matching: An Aid to Bibliographic Search” (PDF). Communications of the ACM. 18 (6): 333–340. doi: 10.1145/360825.360855. S2CID 207735784.
- ^ Jump up to: a b c d e f Thareja, Reema (13 October 2018). “Hashing and Collision”. Data Structures Using C (2 ed.). Oxford University Press. ISBN 9780198099307.
- ^ Daciuk, Jan (24 June 2003). Comparison of Construction Algorithms for Minimal, Acyclic, Deterministic, Finite-State Automata from Sets of Strings. International Conference on Implementation and Application of Automata. Springer Publishing. pp. 255–261. doi: 10.1007/3-540-44977-9_26. ISBN 978-3-540-40391-3.
- ^ Jump up to: a b c d e f g Sedgewick, Robert; Wayne, Kevin (3 April 2011). Algorithms (4 ed.). Addison-Wesley, Princeton University. ISBN 978-0321573513.
- ^ Jump up to: a b c d e f Gonnet, G. H.; Yates, R. Baeza (January 1991). Handbook of algorithms and data structures: in Pascal and C (2 ed.). Boston, United States: Addison-Wesley. ISBN 978-0-201-41607-7.
- ^ Patil, Virsha H. (10 May 2012). Data Structures using C++. Oxford University Press. ISBN 9780198066231.
- ^ S. Orley; J. Mathews. “The IEEE 754 Format”. Department of Mathematics and Computer Science, Emory University. Archived from the original on 28 March 2022. Retrieved 17 April 2022.
- ^ Bellekens, Xavier (2014). “A Highly-Efficient Memory-Compression Scheme for GPU-Accelerated Intrusion Detection Systems”. Proceedings of the 7th International Conference on Security of Information and Networks - SIN ‘14. Glasgow, Scotland, UK: ACM. pp. 302:302–302:309. arXiv: 1704.02272. doi: 10.1145/2659651.2659723. ISBN 978-1-4503-3033-6. S2CID 12943246.
- ^ Jump up to: a b Willar, Dan E. (27 January 1983). “Log-logarithmic worst-case range queries are possible in space O (n)”. Information Processing Letters. ScienceDirect. 17 (2): 81–84. doi: 10.1016/0020-0190 (83) 90075-3.
- ^ Sartaj Sahni (2004). “Data Structures, Algorithms, & Applications in C++: Tries”. University of Florida. Archived from the original on 3 July 2016. Retrieved 17 April 2022.
- ^ Mehta, Dinesh P.; Sahni, Sartaj (7 March 2018). “Tries”. Handbook of Data Structures and Applications (2 ed.). Chapman & Hall, University of Florida. ISBN 978-1498701853.
- ^ Jan Daciuk; Stoyan Mihov; Bruce W. Watson; Richard E. Watson (1 March 2000). “Incremental Construction of Minimal Acyclic Finite-State Automata”. Computational Linguistics. MIT Press. 26 (1): 3–16. arXiv: cs/0007009. Bibcode: 2000cs… 7009D. doi: 10.1162/089120100561601.
- ^ “Patricia tree”. National Institute of Standards and Technology. Archived from the original on 14 February 2022. Retrieved 17 April 2022.
- ^ Jump up to: a b c Crochemore, Maxime; Lecroq, Thierry (2009). “Trie”. Encyclopedia of Database Systems. Boston, United States: Springer Publishing. Bibcode: 2009eds.. book…L. doi: 10.1007/978-0-387-39940-9. ISBN 978-0-387-49616-0 – via HAL (open archive).
- ^ Jump up to: a b c Martinez-Prieto, Miguel A.; Brisaboa, Nieves; Canovas, Rodrigo; Claude, Francisco; Navarro, Gonzalo (March 2016). “Practical compressed string dictionaries”. Information Systems. Elsevier. 56: 73–108. doi: 10.1016/j.is. 2015.08.008. ISSN 0306-4379.
- ^ Kärkkäinen, Juha. “Lecture 2” (PDF). University of Helsinki. The preorder of the nodes in a trie is the same as the lexicographical order of the strings they represent assuming the children of a node are ordered by the edge labels.
- ^ Kallis, Rafael (2018). “The Adaptive Radix Tree (Report #14 -708-887)” (PDF). University of Zurich: Department of Informatics, Research Publications.
- ^ Ranjan Sinha and Justin Zobel and David Ring (Feb 2006). “Cache-Efficient String Sorting Using Copying” (PDF). ACM Journal of Experimental Algorithmics. 11: 1–32. doi: 10.1145/1187436.1187439. S2CID 3184411.
- ^ J. Kärkkäinen and T. Rantala (2008). “Engineering Radix Sort for Strings”. In A. Amir and A. Turpin and A. Moffat (ed.). String Processing and Information Retrieval, Proc. SPIRE. Lecture Notes in Computer Science. Vol. 5280. Springer. pp. 3–14. doi: 10.1007/978-3-540-89097-3_3. ISBN 978-3-540-89096-6.
- ^ Giancarlo, Raffaele (28 May 1992). “A Generalization of the Suffix Tree to Square Matrices, with Applications”. SIAM Journal on Computing. Society for Industrial and Applied Mathematics. 24 (3): 520–562. doi: 10.1137/S0097539792231982. ISSN 0097-5397.
- ^ Yang, Lai; Xu, Lida; Shi, Zhongzhi (23 March 2012). “An enhanced dynamic hash TRIE algorithm for lexicon search”. Enterprise Information Systems. 6 (4): 419–432. Bibcode: 2012EntIS… 6.. 419Y. doi: 10.1080/17517575.2012.665483. S2CID 37884057.
- ^ Transier, Frederik; Sanders, Peter (December 2010). “Engineering basic algorithms of an in-memory text search engine”. ACM Transactions on Information Systems. Association for Computing Machinery. 29 (1): 1–37. doi: 10.1145/1877766.1877768. S2CID 932749.
Footnotes
-
Maabar, Maha (17 November 2014). “Trie Data Structure”. CVR, University of Glasgow. Archived from the original on 27 January 2021. Retrieved 17 April 2022. ↩
-
Thue, Axel (1912). “Über die gegenseitige Lage gleicher Teile gewisser Zeichenreihen”. Skrifter Udgivne Af Videnskabs-Selskabet I Christiania. 1912 (1): 1–67. Cited by Knuth. ↩
-
Knuth, Donald (1997). “6.3: Digital Searching”. The Art of Computer Programming Volume 3: Sorting and Searching (2nd ed.). Addison-Wesley. p. 492. ISBN 0-201-89685-0. ↩
-
Daciuk, Jan (24 June 2003). Comparison of Construction Algorithms for Minimal, Acyclic, Deterministic, Finite-State Automata from Sets of Strings. International Conference on Implementation and Application of Automata. Springer Publishing. pp. 255–261. doi: 10.1007/3-540-44977-9_26. ISBN 978-3-540-40391-3. ↩