一句话介绍
Multi-Head Latent Attention (MLA) 是 DeepSeek-V3 模型中用于高效推理的核心注意力机制。MLA 通过 低秩键值联合压缩(Low-rank Key-Value Joint Compression) 技术,减少了推理时的 KV cache,从而在保持性能的同时显著降低了内存占用。
在标准的 Transformer 模型 中,多头注意力(Multi-Head Attention, MHA)机制通过并行计算多个注意力头来捕捉输入序列中的不同特征。每个注意力头都有自己的 Query、Key 和Value 矩阵:
- 查询矩阵 Q:用于计算输入序列中每个位置的注意力分数。
- 键矩阵 K:用于与查询矩阵 Q 计算注意力分数。
- 值矩阵 V:用于根据注意力分数加权求和,得到最终的输出。
MLA 的核心思想是通过低秩联合压缩,减少 K 和 V 矩阵的存储和计算开销。
1. 低秩联合压缩
键值矩阵的低秩压缩
MLA 通过以下步骤对 K 和 V 矩阵进行低秩联合压缩:
压缩键和值:
设输入序列的第 个 token 的注意力输入为 ,其中 是嵌入维度(embedding dimension)。通过一个下投影矩阵 ,将 压缩为一个低维的潜在向量(latent vector) ,其中 , 是每个注意力头的维度, 是注意力头的数量1。
重建键和值:通过上投影矩阵 和 ,将压缩后的潜在向量 重建为键和值矩阵:
其中 可视为按 head 分块:
每一块 对应第 个 head 的 Key 上投影。同理 也可按 head 分块()。
应用旋转位置编码:为了引入位置信息,MLA 对键矩阵应用旋转位置编码(Rotary Positional Encoding):
其中, 是用于生成携带 RoPE 位置信息的解耦 Key 分量(RoPE 分量)的投影矩阵, 是 向量的维度,这个向量会被复制到每个头,与每个头的压缩键 拼接:
什么是“解耦 Query / Key”?为什么解耦后要在 head 间共享?
Q1:这里的“解耦(decoupled)”到底指什么?
指把用于注意力计算的 Query/Key 拆成两段并分别生成:一段主要表达内容(content),另一段主要承载位置信息(RoPE),最后在特征维度上做拼接(concatenate)。
- Key:。其中 由潜在向量 上投影重建(位置无关、便于压缩/缓存), 则由 生成并施加 RoPE(位置相关,但维度很小)。
- Query:。其中 来自压缩向量 的上投影重建, 来自单独的 RoPE 分支(下文公式 (8))。
为什么需要这种解耦?(KV 压缩 vs. RoPE 的“冲突”)
MLA 的 KV 压缩希望缓存尽可能小:KV cache 的核心是缓存压缩后的 (以及额外很小的 ),需要时再用位置无关的 重建 。但 RoPE 是位置敏感的:如果把 RoPE 直接施加在“内容 Key”上,要么不得不缓存旋转后的高维 Key(缓存膨胀、失去压缩意义),要么每步都重建并旋转(增加延迟),同时还会破坏很多工程上“矩阵可融合/可吸收”的优化空间。
解耦的关键点是:让 RoPE 只作用在一段小维度的 上,而把可压缩、可缓存、位置无关的内容部分留在 路径里。Q2:解耦之后,“每个 head 共享”有什么意义?
这里的共享主要指 Key 的 RoPE 分量 在所有 head 之间共享(而 仍是每个 head 私有的内容分量)。直觉上,位置信息对所有 head 是一致的:token 的“坐标/相对距离”不因 head 不同而改变。共享带来的收益是非常直接的:
- KV cache 更小:若不共享,每个 token 需要为每个 head 存一份 ();共享后每个 token 只需缓存一份 ()。
- 参数与计算更省:共享意味着只需一个 (而不是 ),并且每个 token 的 RoPE 只需对这一份 计算一次。
- 表达能力不受太大影响:head 的多样性主要由 的内容分量提供;位置分量作为“统一坐标系”共享即可。
补充:在本文给出的公式里,Query 的 RoPE 分量 是按 head 生成的(见 的输出维度),而不是像 Key 那样跨 head 共享。
最终键和值:最终的键和值矩阵由压缩后的键和值以及旋转位置编码后的键组合而成:
查询矩阵的低秩压缩
MLA 同时还对查询矩阵 Q 进行低秩压缩,以减少训练时的激活内存:
压缩查询:
通过下投影矩阵 ,将 压缩为一个低维的潜在向量 ,其中 。
重建查询:通过上投影矩阵 ,将压缩后的潜在向量 重建为查询矩阵:
应用 RoPE :
其中, 是用于生成解耦查询的矩阵。它会为每个注意力头生成对应的 (可理解为把 reshape 为 )。
最终查询:最终的查询矩阵由压缩后的查询和旋转位置编码后的查询组合而成:
2. 注意力计算
最终的注意力输出通过以下步骤计算:
计算注意力分数:对于每个注意力头 ,计算查询 和键 的点积,并除以 进行缩放:
计算注意力分数:对注意力分数进行 softmax 归一化,得到:
加权求和:使用注意力分数对值 进行加权求和,得到每个注意力头的输出:
合并多头输出:将所有注意力头的输出拼接起来,并通过输出投影矩阵 进行线性变换,得到最终的输出:
汇总起整个流程,就是:
3. 思考问题
低维潜在向量维度的取值
低维的潜在向量的维度应该如何取值,这个维度和原始 token 的嵌入维度是否存在比例关系,如果存在的话,比例通常设置多少?依据什么来设置?
在 MLA 中,低维潜在向量的维度 (KV 压缩维度)与 (Query 压缩维度)是两个最关键的超参数:它们决定了信息瓶颈有多窄,从而直接影响性能与效率(KV cache、计算、激活内存)。
DeepSeek-V3(MLA)相关维度配置(便于对照)
参数 符号(本文记法) DeepSeek-V3 设置值 隐藏层维度 7168 注意力头数量 128 非 RoPE 的 Q/K 每头维度 (对应 qk_nope_head_dim)128 解耦 RoPE 的 Q/K 维度 (对应 qk_rope_head_dim)64 值的每头维度 (对应 v_head_dim)128 KV 压缩维度 (对应 kv_lora_rank)512 Query 压缩维度 (对应 q_lora_rank)1536
-
先明确: / 控制的是“有效自由度(rank)”,不是输出形状 以 Key 的内容分量为例(不含 RoPE 的那条压缩路径):
如果把它看成一个“等价的普通线性层”,它的权重就是 ,输出维度是 ;但它的秩被 限死()。
所以 可以大于 ,这只是“输出形状更宽”,并不代表模型真的拥有 维的独立信息通道;真正的瓶颈是 (KV)与 (Q)。 -
为什么 (KV)可以更小,而 (Q)通常更大? KV cache 是推理的主要内存瓶颈,而 Query 不进 cache。
-
越小,KV cache 越省,但信息瓶颈风险越大。推理时每个 token 至少需要缓存 ,以及共享的 (用于位置相关的 RoPE 分量)。在 DeepSeek-V3 的配置下,单 token 缓存维度大约是:
如果对比“把每个 token 的 K/V 都按 head 完整缓存”的做法(这里按 MLA 最终的 head 维度来算:Key 每头 ,Value 每头 ),则单 token 的缓存维度大约是:
粗略压缩比约为 。(具体节省还与 dtype、对齐、实现细节有关。)
-
主要影响训练/推理每步计算与激活内存。它不需要跨 token 长度线性累积地缓存,所以可以设置得更大来减少信息损失。DeepSeek-V3 的 (约为 的 )明显大于 (约为 的 ),就是“KV 极致压缩、Q 更侧重保真”的直接体现。
-
-
取值依据:
- 性能/压缩的主权衡:、 太小会成为信息瓶颈,注意力质量下降;太大则 KV cache/计算收益下降。
- 与 head 形状的耦合:当 很大时,如果 太小,等价投影矩阵的秩上限过低,可能不足以支撑“每个 head 都有有用的内容分量”。因此 往往需要与模型规模、head 配置一起调参。
- Q 与 KV 的差异化目标:KV 维度选择要优先服务推理内存;Q 维度选择要优先服务注意力打分的稳定与精度(尤其对大模型/复杂任务)。
- 低秩注意力的经验类比:像 Linformer 这类方法也证明了“把注意力相关表示投到低秩空间”可以在合理的 rank 下保持性能。
与 MHA 在 head 数量与维度上的不同
上一问可以观察到,head 数量与维度之积 , 这与标准 MHA 不同。原因如下:
-
经典 MHA 的“等式”更多是工程习惯,不是数学硬约束 很多实现会令:
这样 的输出维度都是 ,实现上最方便(也便于与残差、FFN 等模块对齐)。但从数学上讲,MHA 只需要:
- ,,
- 最后再用 投回
因此 可以不等于 。只是当你用的是“普通全连接投影”时,这么做会显著增加参数量与算力,所以不常见。
-
MLA 为什么敢让 变得很大?因为它是低秩重建(LoRA-style factorization) MLA 的 Q/K(内容分量)不是直接用一个大矩阵从 投到 ,而是“先压缩到 /,再上投影回去”。以 KV 为例:
等价地看,它实现的是一个大矩阵 ,但这个大矩阵的秩被 限制()。这使得:
- 输出形状可以是 ,并不要求等于
- 但它的“有效自由度”并不会随着输出形状线性爆炸(因为 rank 被 卡住了)
这也是 MLA 能在扩大 head 形状的同时,仍然把 KV cache 压到很小的根本原因。
-
每头维度 在 MLA 里应如何理解? 在 DeepSeek-V3 的配置里,最终用于注意力打分的 Query/Key 是拼接向量:
因此单头的最终 Q/K 维度是:
这里技术报告里提到的 “per-head dimension ” 更准确地说对应的是 非 RoPE 的内容分量维度(
qk_nope_head_dim),而不是最终拼接后的总维度。
为什么要对 Query 和 Key 应用 RoPE?
RoPE(Rotary Positional Embedding)通过对向量施加与位置相关的旋转,把相对位置信息“内生”地写进注意力分数(点积)里。MLA 沿用这一设计,同时对 Query 和 Key 应用 RoPE,主要原因可以归纳为三点:
-
对称性与对齐:注意力分数来自 Query 与 Key 的点积。如果只对一侧做旋转,点积会依赖单侧的绝对位置而非两者的相对位置;同时对两侧应用 RoPE,才能在同一数学空间里对齐位置信息,让打分稳定地表达 token 间的距离关系。
-
相对位置建模(无需 的相对偏置参数化):RoPE 的关键性质是把“绝对位置旋转”转化为“相对位移”:
其中 表示位置 对应的旋转。因而相对位置 会自然进入点积结果。相比之下,T5-style
relative_position_bias通常以 bucket 形式参数化(参数量不随 增长),但在计算 attention logits 时会广播/形成形如 的 bias 张量参与运算,因此运行时的中间张量与计算仍与 相关。RoPE 的优势在于避免了 的相对偏置参与参数化;实现上位置相关项一般以 形式按位置生成或缓存(缓存时约为 )。 -
长序列外推与工程可扩展性:RoPE 的形式允许通过调整旋转频率(例如缩放因子)来扩展上下文窗口,这是一个通用手段。DeepSeek-V3 的技术报告中,为了获得更可靠的外推效果,采用的是“两阶段继续训练”:先在 4K 长度上预训练,再结合 YaRN(一种 RoPE 扩展方法)分别在 32K 与 128K 长度上继续训练;并且 YaRN 只作用于解耦出来、跨 head 共享的 RoPE Key 分量 ,不作用于内容压缩/重建路径。由于 在 Key 侧只有一份共享表示,这也让长上下文扩展策略的工程实现更简单。
需要强调的是:在 MLA 里,RoPE 并不是作用在整段的 Query/Key 上,而是只作用于解耦出来的 RoPE 分量(上文的 与 )。由于最终是拼接:
因此注意力打分会自然分解为“内容匹配 + 位置匹配”两部分:
其中第二项由 RoPE 提供相对位置信号,而第一项保持在低秩压缩/可融合的内容路径上。
对比其他位置编码方法:
| 方法 | 特点 | 局限性 |
|---|---|---|
| 绝对位置编码(Sinusoidal) | 固定频率的正弦函数编码位置,简单易用。 | 无法建模相对位置关系,长序列性能下降。 |
| 相对位置偏置(T5-style) | 为位置差引入偏置(常见为 bucket 参数化),直接建模相对位置。 | 参数量不随 增长,但 logits 的 bias 广播/中间张量与计算仍与 相关。 |
| RoPE | 通过旋转把相对位置融入 Q/K 表示(对称地作用在两侧)。 | 无需 的偏置参数表,但需要生成/缓存 (可视实现为 或以算换存)。 |
注:推理时的 RoPE scaling 属于通用手段;DeepSeek-V3 为追求更好的外推效果,采用了 YaRN + 继续训练来扩展上下文(YaRN 作用在共享的 分支上)。
对 Q 和 K 进行 RoPE 的不同之处
在 MLA 中,RoPE 分支对 Query/Key 的输入并不对称:
- Query:(输入是压缩向量 )
- Key:(输入是原始向量 ,且 跨 head 共享)
这背后的核心考量可以概括为:KV 侧的设计首先服务于“可缓存、可复用”,因此尽量把会造成瓶颈/干扰的东西从 KV 压缩路径里解耦出去;而 Q 侧的设计首先服务于“当前步的计算高效”,因此能在已压缩空间里算就尽量在已压缩空间里算。
-
KV 侧(Key)的 RoPE 分量:避免把“位置相关分量”塞进 KV 压缩瓶颈 MLA 已经用 承担了内容分量的极致压缩(推理时需要缓存并被未来反复复用)。如果再让 也从 产生,那么位置相关的 RoPE 分支也会被强行限制在同一个 的信息瓶颈里,容易造成“压缩路径既要负责内容、又要负责位置”的相互干扰(这也会削弱前面提到的解耦动机)。
因此,MLA 选择让 直接由 产生:在写入 cache 的当下, 本来就已计算得到;用一个很小的投影 生成 维向量并施加 RoPE,开销很低,但能让“位置相关分量”独立于 的压缩瓶颈。
这并不意味着要缓存
推理时缓存的是 (以及额外很小的、共享的 ),而不是高维的 。
-
Q 侧(Query)的 RoPE 分量:把“每步都算的东西”尽量放在已压缩空间里算 Query 不进 KV cache(不会随序列长度线性累积存储),它的主要压力来自每个解码步的即时计算与训练激活。既然 Query 路径已经先得到 ,那么让 也从 生成有两个直接收益:
- 更省参数/算力:用 从 映射到 ,比从 映射要便宜。
- 压缩不至于过猛:在 DeepSeek-V3 里 相对 并不算极端压缩,通常足以支撑 RoPE 分支所需的信息。
-
“复用 vs. 私有”的差异:Key 的 共享,Query 的 按 head 生成 Key 的 RoPE 分量 需要被未来所有 Query 重复使用,且位置信息对不同 head 是一致的,因此跨 head 共享非常自然;而 Query 的 RoPE 分量由 一次性生成 份(每头一份),与每头的内容分量配对使用。
这个设计的底层逻辑可以用下表来概括:
| 维度 | Key路径 | Query路径 |
|---|---|---|
| 核心目标 | 极致压缩KV Cache | 减少计算量,保持准确性 |
| 输入来源 | 原始向量 (7168维) | 压缩向量 (1536维) |
| 原因 | 让 RoPE 位置分量不受 的 KV 压缩瓶颈影响;同时仍然保持 KV cache 极小 | Query 不入 cache,可在 空间里高效生成 RoPE 分量(且 压缩不算过猛) |
| 共享性 | 全局共享:一个 服务所有未来头 | 私有:只用于当前token的当前头 |
| RoPE来源 | 从原始 生成共享的解耦键 | 从压缩 生成解耦查询 |
| 缓存 | 缓存 (512维) 与共享的 (64维) | 不缓存任何东西 |
所以,这个不对称设计的本质是:Key 侧把“位置相关但小维度”的部分单独拎出来(共享且轻量),避免干扰 KV 的极致压缩;Query 侧则在已压缩的 空间里完成 RoPE 分量生成,以降低每步计算与训练激活开销。
压缩查询矩阵的必要性:分维度精细化分析
在进入分析前先明确一个已知的前提:MLA 对 Query 与 KV 的压缩策略并不对称。在 DeepSeek-V3 的配置中,Query 压缩维度 明显大于 KV 压缩维度 :KV 侧更偏向推理阶段的 KV cache 极致压缩;Query 侧更偏向训练阶段的激活内存/计算效率,同时尽量保留信息。
为避免口径混乱,下面把“显存/计算/通信/参数”拆成几个相互独立的分析维度。
- 分析维度的界定
| 分析维度 | 涵盖内容 | 与序列长度 的关系 | 对比口径说明 |
|---|---|---|---|
| KV cache per token | 推理时每新增 1 个 token,需要为该 token 缓存的历史信息量 | 线性增长(总 cache ) | MLA vs MHA 的核心差异点 |
| 训练激活内存 | 前向中需为反向保留/可重算的中间激活 | 与 、batch size、kernel 实现相关 | Query 压缩的主要收益落在这里 |
| 参数量 | 模型静态权重(投影矩阵等) | 与 无关 | 不能混入“随 增长的显存项” |
| 运行时中间张量/算子开销 | logits、softmax、重建/吸收等算子产生的中间量与 FLOPs | 通常与 或 相关(视训练/推理而定) | MLA 不是简单把“点积维度”整体降到 |
-
KV cache per token(推理阶段的核心收益) 这部分是 MLA 最关键的优势点:cache 缓存的对象改变了。
标准 MHA 的 KV cache(按每 token 计):每个 token 需要为所有 head 缓存 Key 与 Value:
在常见设置 下,就是 。以 DeepSeek-V3 的 为例:
(个浮点数;若 FP16 约 64 KiB/ token)
MLA 的 KV cache(按每 token 计) :DeepSeek-V3 报告强调推理需要 cache 的核心是两类向量:
- 压缩后的潜在向量 (内容信息)
- 解耦 RoPE Key 分量 (位置信息,跨 head 共享)
因此每 token 的 cache 大小约为:
(个浮点数;若 FP16 约 1.1 KiB/ token)
压缩比(以“标准 MHA 缓存 K/V”作为 baseline)约为:
这也就是 DeepSeek V2 报告中初次提出 MLA 所说的 KV Cache 压缩率 97%+ 的来源。
-
计算量:MLA 的关键在权重吸收,而非把点积维度替换成 MLA 的注意力 logits 依然来自每头最终的拼接向量:
其中内容分量维度是 ,RoPE 分量维度是 ,缩放项也写成 。
MLA 的“计算侧”优化重点在于:虽然 的数学定义是上投影重建,但实现时可以通过权重吸收/算子重排避免显式重建所有历史 token 的 K/V:
也就是说,对每个 head ,可以先把当前 Query 的内容分量投到 latent 空间:
然后与 cache 中的 做点积,得到内容项 logits。这样做的收益主要是:
- 内存带宽更友好:历史侧读取的是小向量 (而不是大 K/V)。
- 避免显式物化 K/V:减少中间张量与写回。
同理,Value 的“重建 + 加权求和”也可重排为先在 latent 空间做加权,再一次性上投影:
因此,更准确的说法是:MLA 把“对历史 token 的开销”尽可能推到对小向量 的读写与点积上,并通过吸收/融合减少大张量重建与访存,而不是简单把注意力从 变成 。
-
训练激活内存:Query 压缩主要在这里省 训练时显存瓶颈通常来自激活(以及注意力 kernel 的实现方式)。从“可持久化激活”的角度看:
- 标准 MHA 往往需要为反向保存/重算 (形状约 )以及相关中间量。
- MLA 的 Query 路径可以把“可保留的核心表示”压缩到 ,并在反向时重算上投影与 RoPE 分支。DeepSeek-V3 的实现也明确提到会在反向中重算 RMSNorm 与 MLA up-projection,以减少需要持久化存储的激活。
同时,Query 的低秩分解也会改变 Q 投影的参数规模:标准 MHA 的 通常为 ;而 MLA 将其分解为 与 ,参数量从 变为 ,优化器状态(如 Adam 的动量/方差)也会相应变化。训练时若仅持久化保存低维的 并在反向重算上投影,则能进一步降低需要长期保留的激活内存。
需要注意:注意力 logits/softmax 的 级别中间量是否物化取决于 kernel(如 FlashAttention 类方法通常不显式存整张 矩阵)。MLA 的 Query 压缩并不改变“注意力的几何维度”,但能显著降低 Q/K/V 相关的激活与反向重算成本。
-
参数量的空间占用: 以 KV 相关投影为例:
- 标准 MHA 的 KV 相关参数量(假设 ):
代入 ,约为 。
- MLA 的 KV 相关参数量:
代入 ,约为 ,约 11.2× 的参数压缩。
-
通信开销(分布式训练/推理):取决于并行策略与实现 在张量并行/序列并行等设置下,通信量与“需要跨设备同步/传输的激活张量”相关。直观上:
- 若实现允许在更低维的 / 空间先做一部分聚合/同步,再在本地完成重建与后续算子,则通信带宽压力可能下降;
- 但 attention logits/softmax 相关的通信(例如序列并行下的部分归约)是否减少,取决于具体 kernel 与并行切分方式,不能一概而论。
| 维度 | 标准 MHA | MLA | 主要变化 | 说明 |
|---|---|---|---|---|
| KV cache per token | (常见为 ) | 大幅减少(DeepSeek-V3 约 ) | 推理核心收益:缓存的是 latent + 共享 RoPE Key | |
| 训练激活(Q 侧核心表示) | (需要保留/可重算的 Q 表示规模) | (保留 并重算上投影) | 显著减少(DeepSeek-V3 约 ) | 具体节省取决于重算策略与 attention kernel |
| 注意力几何维度 | 略增 | logits/缩放依然基于最终拼接维度 | ||
| KV 相关参数量 | 减少(约 ) | 静态权重,与 无关 |
核心洞察:MLA 的核心不是“把注意力点积维度整体降到 ”,而是通过低秩参数化与算子重排,把随 线性增长的 cache从“完整 K/V”变成“latent + 小 RoPE 分量”,并在计算侧用吸收/融合尽量避免物化大张量;Query 压缩则主要服务训练激活与每步计算效率。
先降维再升维是否真的能减少显存和计算量?
这个问题的答案必须拆开说:显存(尤其是推理 KV cache)几乎一定减少;但 FLOPs 未必减少,甚至可能增加。 MLA 的关键收益来自“带宽/访存”而不是“算术量”。
下面用 DeepSeek-V3 的典型配置做一个数量级估算(按乘法次数计,忽略常数与实现细节;并以解码单步、历史长度 为例):
-
推理显存:KV cache 的缩减(这是确定的)
标准 MHA(按 的常见口径)每 token 缓存:MLA 每 token 缓存:
压缩比约 。这意味着在“KV cache 主导”时,MLA 往往能显著扩大可用上下文长度或 batch 上限;但是否真的能“扩大 56.9 倍”还会受到其他显存项(如激活、框架开销、对齐/分页策略等)的约束。
-
推理计算:FLOPs 可能增加
直觉上,MLA 的历史交互在内容分量上是对 做点积/加权,而标准 MHA 是对 做点积/加权;在 DeepSeek-V3 的数值下 ,因此仅看“历史交互”这部分,MLA 的算术量通常会更大。更具体地,如果按“标准 MHA 缓存完整 K/V”作为 baseline,则其与历史交互(logits + 加权求和)的大致乘法次数是:
而 MLA 的对应部分(内容分量在 latent 空间,位置分量在 RoPE 空间)更接近:
注意:这里的 不能省略,因为在本文公式设定下 是按 head 生成的(每头要与共享的 做一次 维点积),并不是“所有 head 共享同一个 ”。
代入 可得:
- MHA 历史交互:
- MLA 历史交互:
因此在长上下文下,MLA 的算术量确实可能高于“标准 MHA”口径。
关于“MLA 的 FLOPs 只多一点点”的口径差异
计算量对计数方式非常敏感。举例来说,Query 的 RoPE 分支并不是 量级:由于 ,其矩阵乘规模是 ,在本配置下约为 次乘法;并且每个 head 还需要计算一次 (对应上面的 项)。把这些都计入后,在 的条件下,MLA 解码单步的总乘法次数粗略落在 量级,而该 baseline 的“标准 MHA”约为 (约 +25%),具体比例仍会随实现的融合/重算策略变化。
-
那为什么 MLA 仍可能更快?带宽瓶颈与 FlashMLA
现代 GPU 在推理时的解码场景常常是内存带宽受限:每一步都要从 HBM 读取大量历史 KV。MLA 的关键优势是把“每个历史 token 需要读的数据量”从:降到:
在 DeepSeek-V3 的数字下,这正是约 的 HBM 读流量缩减。即便 FLOPs 略高,更小的 cache + 更规整的访问模式往往能显著降低“等数据”的时间。
解码步的 HBM 读流量对比(以 FP16 为例):
- 标准 MHA:每步需读取所有历史 token 的 Key/Value,字节数约为 以 估算,约为 bytes(约 256 MiB,约 268 MB)。
- MLA:每步读取历史 token 的 与共享的 ,字节数约为 以 估算,约为 bytes(约 4.5 MiB,约 4.7 MB)。
读流量缩减约 ,与 KV cache 压缩比一致。需要注意:这只是在对齐“历史 KV 读取”这一项的物理量级,不包含权重读取、输出写回、以及 kernel 内部的其他访存与算子开销。
这也是 FlashMLA(以及类似的 MLA 解码 kernel)优化的核心出发点:
- 不物化完整 K/V:cache 只存
ckv_cache()与kpe_cache(),历史侧只流式读取这两类小向量。 - 矩阵吸收/重排:把内容分量的 logits 与输出计算改写为“Query 侧先投影到 latent / latent 空间先加权再上投影”,减少大张量重建与写回(前文的等价式就是数学基础)。
- 分块与在线 softmax:沿着历史维度按块处理 KV(tile/split-KV),在线更新 softmax 归一化与累加结果,避免显式存 的中间矩阵,并提高数据复用。
- 分页 KV cache(工程):用 block table 等结构支持变长序列与高效的 cache 管理,使实际部署更可控。
一个更稳妥的结论表述
- “先降维再升维”对 KV cache 显存 的节省非常确定(MLA 的核心卖点)。
- 对 FLOPs 的影响取决于 与实现(是否吸收/融合、kernel 是否带宽受限等),并不保证减少;在 DeepSeek-V3 这组数值下,历史交互的算术量通常会增大。
- FlashMLA 的意义在于把“以算换存”的设计变成高吞吐的 kernel:让额外算术尽量落在 Tensor Core / SRAM 友好的路径上,同时把 HBM 读写压到最低。
矩阵吸收及其在 MLA 实现中的应用
1) 数学本质:结合律 + 转置
矩阵吸收(matrix absorption / weight folding)不是一种新算子,而是把一串线性变换用等价的方式重新结合(重排计算图),从而改变“什么时候、在哪个张量上、用哪条 GEMM/点积”去做同一件事。——其数学本质就是矩阵乘法的结合律和转置这种内积搬移的 trick。
它依赖的核心前提是:你要重排的那段计算子图是纯线性(中间没有 softmax/归一化/门控等非线性,或依赖数据的分支);这些非线性是不能被“跨过去吸收”的。MLA 的吸收恰好发生在打分的点积结构与 Value 的线性加权结构两侧。在此前提下,你可以做两类常见的“吸收”:
- 结合律:把两次线性变换折叠成一次 如果有 那么可以离线预先算出 推理时直接做 这就是把 “吸收到” 里(或反过来)。这在推理里很常见:例如把 LoRA/Adapter 等线性分支融合到主权重里,减少一次 GEMM。
“可以随意换序”是不正确的
纯线性链条一般只允许重新结合(re-associate),不能任意交换矩阵乘法顺序(除非满足可交换等额外条件)。MLA 里更常用的是下面的“内积搬移”,它并不是换序,而是利用转置把线性变换搬到点积的另一侧。
-
内积搬移:把 Key 侧的线性变换搬到 Query 侧 注意力里最关键的一步是点积。如果 不是原始缓存,而是压缩后的向量 ,则恒等式成立:
含义很直观:你不一定要显式算出 (把 Key 展开并物化成大张量,再参与后续点积);而是可以先算 ,再跟 做内积。两者完全等价,但计算/访存路径不同。
这第二种就是 MLA 解码里“吸收”的核心:它让历史侧只需要缓存/读取小维度的 latent vector(),而不必把它展开成每个 head 的大维度 才能算注意力。
2) 工程落地:把“吸收”落在哪(融权重 vs. 融计算)
矩阵吸收在落地时常见有两种完全不同的目标函数:一种追求减少运行时的 GEMM 次数,另一种追求避免物化/缓存某个大中间张量。两者都源自上一节的线性代数恒等式,但优化对象不同。
-
A. 融权重(offline folding / 参数级融合):对应上一节的结合律。把一串固定的线性层(或线性分支)在加载权重/部署前就合成一个等价权重。典型例子是把 LoRA/Adapter 的线性更新折叠进主权重、或把连续的线性层 预先合成 ,从而推理时少一次 GEMM。 这类做法的限制也很明确:如果权重是量化态(INT8/FP8 等)或需要特定缩放/分组,折叠可能要求先反量化再重量化,带来精度与工程复杂度问题;另外它主要影响“当前 token 的前向投影”,对“历史侧反复读取”的瓶颈帮助有限。
-
B. 融计算(on-the-fly re-parameterization / 计算图级重排):对应 transpose trick 与线性性质(把 搬到点积另一侧、把 推迟到加权求和之后)。它不一定减少 GEMM 次数,但能改变“算在哪个张量上”,从而不显式物化某些大张量。 MLA 解码阶段用的就是这一类:历史侧缓存的是 (以及小维度的 ),计算时用 与 点积得到 logits,并在 latent 空间完成加权累加后再用 上投影得到输出。这里的关键不是少一次 GEMM,而是把“历史侧需要读/写的对象”压到最小。
在 MLA 的讨论里,基本都属于 B(融计算) 的范畴。这里关键的是把计算图重排成等价形式:利用 transpose trick 与线性性质,让解码时不必物化/缓存历史 token 的大 张量,而是直接让历史侧只缓存/读取 (外加很小的 )。
下面的推导与实现讨论都聚焦这种“在计算图里做吸收/重排”的用法。
3) MLA 中怎么吸收?(数学层面)
下面只讨论 内容分支(不含 RoPE 分支)。回忆前文:
- 每个 token 缓存的是
- 第 个 head 的内容 Key/Value 为
其中 (见前面对 的分块说明)。
-
Key 吸收:把 从 Key 侧搬到 Query 侧
内容分数(忽略 RoPE 拼接项)为:用 transpose trick:
定义
则
效果:历史侧不需要读/存 ,只需读 。
进一步,如果 本身来自 的上投影(),那么还可以把两步线性变换继续结合:
这也是很多实现里所谓“把 吸收到 (或反过来)”的来源:本质仍是线性重排。
(2) Value 吸收:把 推迟到加权求和之后
每个头的输出 由注意力权重 对 Value 加权求和得到:
利用线性性质把 提到求和外:
定义
则
效果:历史侧同样只需要读 做加权累加,最后才做一次 的上投影。
把两步合起来就能看出:注意力对历史序列的被访问对象从 变成了单个 (外加 RoPE 的小分量),这才是 MLA 在系统层面能兑现 KV cache/HBM 带宽收益的关键。
4) RoPE 解耦分支在吸收里怎么处理?
MLA 的 Key 实际是拼接 ,其中 是跨 head 共享的小维度且要施加 RoPE。这一段通常保持为“独立的 RoPE 分支”,原因是:
- 本来就小,缓存它成本低;
- RoPE 的旋转与位置索引相关,不是一个可以预先折叠成常量的矩阵乘。
因此 MLA 的吸收主要发生在内容分支的 上;RoPE 分支则以
的形式直接贡献位置项分数(在本文的公式设定下, 是按 head 生成的,因此每个 head 都要计算一次该点积)。
5) “训练时 MHA、推理时 MQA”这句话怎么理解?
在 DeepSeek V3.2 的技术报告和一些博客讨论中234,常常将 MLA 在不同场景下的应用描述为:训练时 MHA、推理时 MQA。
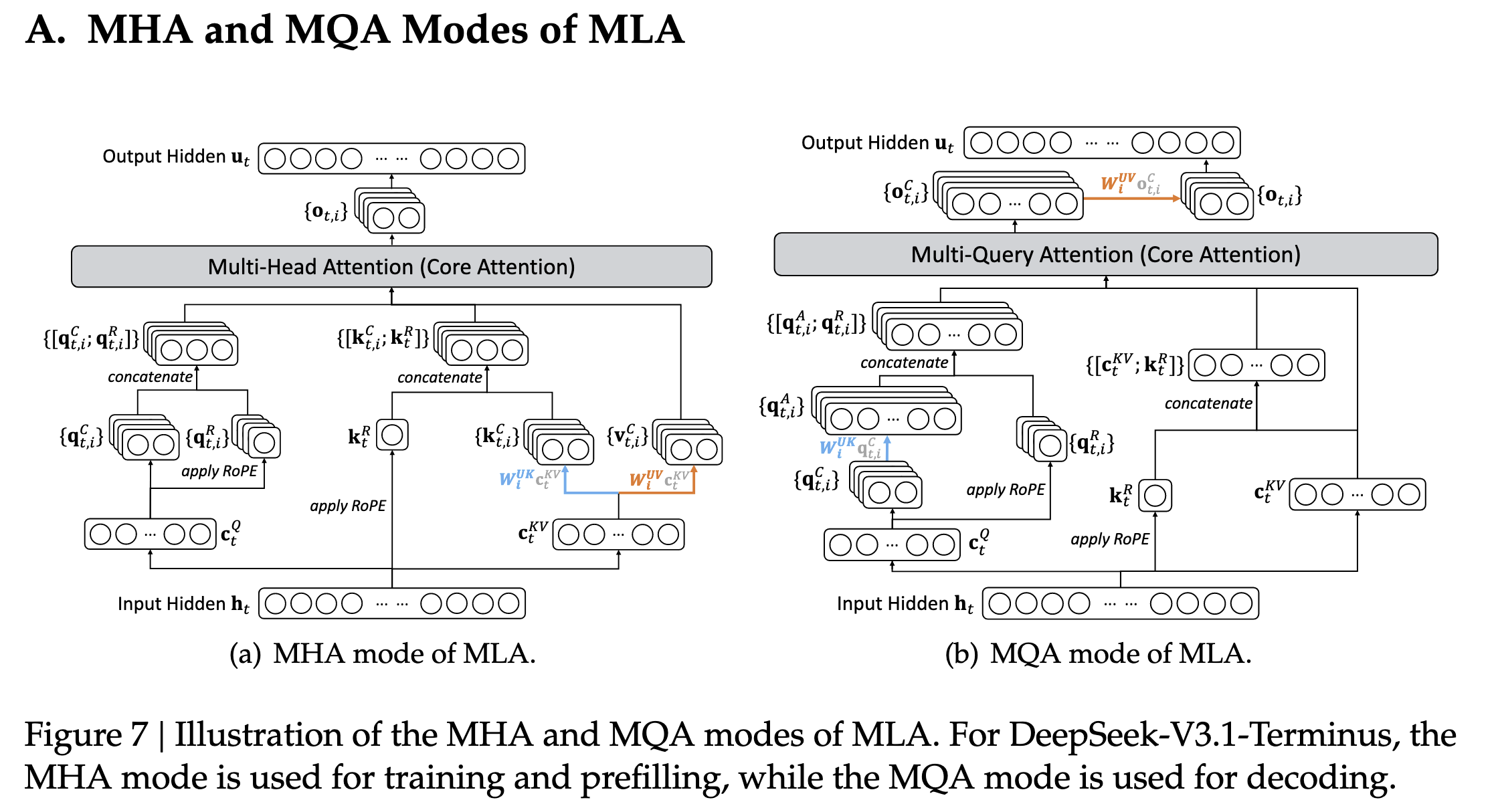 这句话更像是一种实现侧的类比:这里的 “MHA/MQA” 不是在说模型的注意力机制真的换成了另一套方案,而是在说 不同阶段的计算形态与缓存形态更像哪一种。
这句话更像是一种实现侧的类比:这里的 “MHA/MQA” 不是在说模型的注意力机制真的换成了另一套方案,而是在说 不同阶段的计算形态与缓存形态更像哪一种。
首先澄清一下三个概念及其特点:
- MHA(Multi-Head Attention):每个头有独立的 Query、Key、Value 投影矩阵,计算时每个头的 Key 和 Value 是独立的,表达能力最强。
- MQA(Multi-Query Attention):所有头共享同一组 Key 和 Value 投影矩阵,因此 KV Cache 只需存一份,但表达能力受限。
- MLA(Multi-head Latent Attention):通过低秩压缩,每个头仍有独立的 Key/Value 上投影矩阵(),但 KV Cache 只存共享的潜在向量 。
其次,我们需要明确这两个“模式”在 MLA 的语境中究竟指的什么:
| 模式 | 对应阶段 | 核心计算特征 | 缓存内容 |
|---|---|---|---|
| MHA 模式 | 训练(Training)& 预填充(Prefill) | 计算上更接近“按 head 展开”的多头注意力:显式重建每个头的 后做标准 MHA 计算(算术更省,吞吐更高) | 训练:不维护解码 KV cache;Prefill:会把 写入 cache 供后续 decode,但 prefill 内部不会像 decode 那样每步反复读取长历史 |
| MQA 模式 | 解码(Decoding) | 通过矩阵吸收/重排,在 latent 空间完成“当前 query ↔ 历史 token”的交互;历史侧只读所有头共享的 (外加 ),避免物化历史 | 压缩后的向量 + 共享的位置信息 |
MLA 向不同模式切换之所以能够实现,完全依赖于矩阵吸收:同一个注意力在数学上有两条等价计算路径,训练/Prefill 更倾向走“展开式”(类 MHA),Decode 必须走“吸收式”(类 MQA),这样就实现了训练时保留 MHA 的表达能力,推理时享受 MQA 的缓存效率的理想效果。
我们之前已经讨论过,这两条路径只是计算顺序不同:
-
展开式(类 MHA): 训练/prefill 中严格按照定义式计算,先显式重建 KV—— 、,再算每个头的注意力分数后拼接
整个过程中每个头都有自己独立的 Key 和 Value,这就是 MHA 的核心特征。
-
吸收式(类 MQA): 解码阶段,为了利用 KV cache,就要改变计算顺序,把 搬到 Query 侧,先算 ,再算
于是,计算分数时,不再需要为每个历史 token 重建完整的 ,只需要读取缓存的 并与 点积。 被成功“吸收”到了 Query 侧。此时,所有头的 都是共享的,缓存形式与 MQA 完全一致。 Value 侧同理:先在 latent 空间做加权累加 ,最后再做一次上投影得到 ,回到原始维度。 被“吸收”到了输出侧,避免了为每个历史 token 重建 Value 的巨大开销。
因此,从“缓存对象”看,Decode 阶段 MLA 的 cache/token 形态确实很像 MQA(历史侧共享一份表示,而不是每个 head 一份);但从“表达能力/参数化”看,MLA 依然保留每个 head 自己的 ,并没有像 MQA 那样把 KV 投影彻底共享成一套参数。
为什么还需要“解耦 RoPE”?
上面的吸收恒等式依赖于“内容分支是纯线性链条”:。而 RoPE 是一个与位置相关的、非线性的旋转操作。如果把位置相关的 RoPE 直接施加到这条内容路径上,打分会变成
其中 随 变化,导致你无法先算一个与 无关的 再对所有历史 token 复用。MLA 的解决方案正是之前笔记里详细分析的 “解耦”:把 Key 拆成两部分——不包含位置信息、可以自由吸收的内容部分 ,和一个专门负责携带 RoPE 位置信息的共享解耦键 。这样,内容部分依然可以完美执行矩阵吸收,而位置信息则通过另一条轻量级路径独立传递。
6) Prefill vs. Decode:矩阵吸收的动机差异
这一节通过计算量这一角度来判断 Prefill/Decode 中选择矩阵吸收的差异。
Prefill(处理整段 prompt)
这阶段更像“矩阵-矩阵”的问题:你要一次性计算长度 的整段注意力(通常会用 FlashAttention 类 kernel 来避免物化 中间矩阵)。在这个阶段,“是否做吸收”的关键不在于 cache(prefill 还没有很长的历史 cache),而在于算术量(尤其是 项)。
下面用 DeepSeek-V3 的典型配置解释为什么很多实现会在 prefill 阶段倾向于不走吸收路径(而把吸收留给 decode):
核心对比:注意力的 项
prefill 的主要计算量来自两件事:计算 logits()与对 Value 做加权求和()。把“内容分支 + RoPE 分支”的维度写出来:
| 级别计算项 | 非吸收(先重建 ) | 吸收(在 latent 空间交互) |
|---|---|---|
| 内容 logits | ||
| RoPE logits | 相同: | |
| Value 加权和 | 若在 latent 累加:(再加 的一次性上投影) |
代入 DeepSeek-V3::
- logits 的 系数:非吸收为 ;吸收为 ,约 3 倍。
- 若把 Value 加权和也一并考虑,则 系数从 变为 ,约 3.4 倍。
因此在 较大(例如 2K/4K)的 prefill 阶段,仅从 FLOPs 角度看,吸收路径往往会更“贵”。而 级别的预处理(例如显式重建 或计算 )相对 主项通常不是决定性因素。
这不是说 prefill “绝对不能吸收”
如果你的 kernel 可以从 latent 直接做计算并显著减少中间张量/访存(例如 fused/FlashMLA 风格),那么在某些硬件与 batch/并行设置下仍可能选择吸收式实现;但对 DeepSeek-V3 这组维度,prefill 的动机通常更偏向“算术更省”的非吸收路径。
Decode(逐 token 自回归生成)
这阶段每一步都要与所有历史 token 交互,历史长度逐步增长,导致“每步历史读取”线性上升。此时是否做吸收几乎是决定性的:
- 如果你缓存/读取的是每个 head 的 ,那么每步历史读流量是 ;
- 而 MLA + 吸收让历史侧只读 (再加 的小项),这正是前面 HBM 读流量量化(约 )能够成立的前提。
| 阶段 | Prefill | Decode |
|---|---|---|
| 输入长度 | 长(prompt) | 短(1 token) |
| KV cache 长度 | 0 | 长(累积) |
| 瓶颈类型 | 计算密集型 | 访存密集型 |
| 采用模式 | 类MHA(非吸收) | 类MQA(吸收后) |
| 核心收益 | 利用高性能 kernel | 57倍 HBM 读取减少 |
| 是否使用吸收 | 通常 ❌(视 kernel) | 通常 ✅ |
动态选择(实现相关)
一些推理引擎会根据“当前 prefill 的 query 长度”和“已有 cache 长度”等条件,动态选择更合适的实现路径(更偏向展开式还是吸收式)。具体切换条件与常数项强相关,应以实际 kernel/框架实现为准。
MLA 对训练场景的意义
我们前面更多讨论的是 MLA 在推理解码阶段对 KV cache 的压缩。但在训练阶段(一次前向会同时计算整段序列,通常不会维护随 decode step 增长的 KV cache),MLA 依然有意义,只是收益点从“KV cache per token”转向了训练激活内存、参数/优化器状态、以及与 kernel/重计算策略的协同。
-
核心认知:训练不存“解码 KV cache”,但要为反向传播付出显存 训练时确实不需要像推理那样把历史 K/V 按 token 追加到 cache 里供未来 step 复用;但为了反向传播,仍然需要保存(或可重算)大量中间量(activations)。这些激活值的规模与序列长度 、batch size、并行策略和 attention kernel 实现强相关,往往才是训练的显存瓶颈。
MLA 的低秩结构提供了一种更“便宜”的保存方式:与其持久化地存下高维 (或它们的关键中间量),可以保存更低维的 latent(如 ),并在反向中重算 up-projection / RoPE 分支(DeepSeek-V3 的实现也提到会在反向传播中重算 RMSNorm 与 MLA up-projections,以减少需要持久化存储的激活)。
训练视角下的低秩压缩:参数、梯度、优化器与激活
前面我们更多从“前向算子形态/激活保存”解释训练收益。这里补上一个反向传播视角:低秩压缩不仅影响前向的张量形状,也会影响训练时的参数量、梯度张量与优化器状态,并且让“存 latent + 反向重算”更自然。
1) 参数量:低秩分解如何减少可训练参数
以 KV 的内容分支为例,标准 MHA 往往是两张大矩阵:
- (注意这里按本文前文约定:,即左乘)
MLA 则用低秩分解替代:
- ,先得到
- ,再重建每头的
因此 KV 内容分支参数量从
变为
代入 DeepSeek-V3::
- 标准 MHA:
- MLA(仅 KV 内容分支):
参数减少约 。需要注意:完整的 MLA 还包含 RoPE 解耦分支(如 )与 Query 侧的低秩分解(),这里只是在对齐“KV 内容投影”的核心差异。
这个减少会带来两个直接的“训练显存收益”(与序列长度无关,但与训练并行/优化器实现相关):
- 梯度张量:梯度与参数同形状,参数变少通常意味着梯度张量也变少(若使用 ZeRO/分片,收益会体现在通信与分片规模上)。
- 优化器状态:以 Adam/AdamW 为例,常见实现会为每个参数维护一阶/二阶动量,状态量级通常与参数量线性相关,因此也会随低秩分解同比例下降。
2) 反向传播: 作为链式法则的“枢纽”
KV 内容分支的前向(按本文符号)是:
在反向里, 会汇集来自两条路径的梯度贡献:
- 来自 Value 聚合 的
- 来自 logits/softmax 的 (以及间接影响 的路径)
因此对 的梯度可以写成形如(省略与 softmax/attention 细节相关的展开):
随后梯度再通过下投影回到输入:
直观理解: 是一个把“多头、多位置的注意力梯度”汇聚到低维瓶颈的节点。这并不意味着训练一定更快(算术量未必下降),但它解释了为什么 “存一个低维 latent” 可以覆盖反向所需的关键信息:所有 head 对 KV 的依赖都会通过同一个 汇总回来。
3) 激活保存:重计算(recomputation)为什么和 MLA 很“搭”
训练时显存往往被 activations 主导。若不做优化,你可能需要长期保存(或可重算)大量中间表示(例如每头的 ,以及 attention kernel 需要的若干中间量)。
MLA 与激活重计算的协同点在于:可把“必须长期保存的表示”尽量降到 latent 维度。一种常见策略是:
- 前向只保存 、,以及小维度的 (和实现相关的少量额外元数据)
- 反向需要用到 或 时,再从保存的 latent 通过上投影重算
这与 DeepSeek-V3 报告里“反向重算 RMSNorm 与 MLA up-projections”的描述是一致的:
We recompute all RMSNorm operations and MLA up-projections during back-propagation, thereby eliminating the need to persistently store their output activations.
4) 一个“每层每 token”视角的粗量级对齐(实现相关)
如果采用“存 latent + 反向重算上投影”的策略,那么每层每 token 需要长期保存的核心表示可以粗略对齐为:
- MLA:(对应 )
- DeepSeek-V3 数值:
对比标准 MHA 常见会长期保存(或在反向中可重算)的核心表示,至少包含 的某种形式(其量级通常与 成正比)。如果仅以“每 token 的 宽度”作一个最保守的参照,则是 ;若以 三者合计作参照,则是 。因此 相比这些量级确实显著更小。
口径提醒:训练显存高度依赖 kernel
训练显存是否由“Q/K/V 激活”主导、以及这些激活是否能被重算替代,强依赖 attention kernel(是否物化 中间量、是否保存 logsumexp/softmax 归一化所需中间量、是否 checkpoint)。因此这里把它当作“解释为什么 MLA 有空间节省激活”的直观量级对齐,而不是通用的精确显存账本。
5) 小结:训练阶段 MLA 的“隐性收益”
从训练(含反向)看,低秩压缩的收益可以归纳为四类(与前文的训练总结互补):
- 参数/梯度/优化器状态:低秩分解直接减少 KV(以及部分 Q)侧投影参数,连带减少梯度与优化器状态规模。
- 激活保存更便宜:把“必须长期保存的核心表示”下沉到 latent()上,配合重算减少大张量持久化。
- 反向传播更易重算:上投影是纯线性层,重算开销可控,且天然适合与 fused kernel 搭配。
- 收益条件明确:当训练瓶颈由注意力相关 activations 主导、并采用重算/高效 kernel 时,MLA 的优势更容易兑现;否则收益可能被其他瓶颈掩盖。
-
训练阶段的三个主要收益:
- 激活内存:把“需要保留的核心表示”换成 latent(并配合重计算) 以 DeepSeek-V3 的典型配置()为例,如果采用“保存 latent、反向重算上投影”的策略,那么每层每 token 的“核心可保存表示”可以粗略对齐为:
前向计算仍会在某个阶段得到最终用于注意力的 (例如每头维度 的 Q/K,以及 的 V)。收益来自:这些量不一定要作为激活长期保存——可以通过重计算与 kernel 融合,把“该存的大量激活”替换成“存 latent + 反向重算”。
另外一个关键点是:训练时 级别的 logits/softmax 中间量是否被物化,会极大影响显存与带宽;FlashAttention/FlashMLA 这类 kernel 的价值在于减少这类中间量的显存/访存开销。MLA 本身不改变注意力的几何维度(每头仍是 ),但它能显著降低 Q/K/V 相关的激活与重算成本,从而更容易把训练做成“算力密集”而不是“显存受限”。
-
参数/优化器状态:低秩参数化降低 KV 相关权重规模 我们在上文已经单独比较了 KV 相关参数量:MLA 用低秩分解显著减少了 KV 侧的投影参数。训练时这不仅减少参数显存,也往往会连带减少优化器状态(例如 Adam/AdamW 的动量/方差)与梯度相关的开销(它们通常与参数量线性相关)。
-
吞吐与稳定性:收益取决于瓶颈(带宽 vs. 算术)与实现 训练是否“更快”并没有一条必然结论:MLA 引入了额外的下投影/上投影与重计算,但也降低了激活保存与带宽压力,并为 kernel 融合创造空间。工程上常见的组合是:
- 激活重计算(减少保存,增加反向算术)
- 更强的 attention kernel(在线 softmax、分块、减少中间量)
- 混合精度(如 FP16/BF16/FP8)与缩放策略(在相同显存预算下换更大 batch / 更长 )
至于“低秩约束是否带来正则化/泛化收益”,这更偏经验现象:可以把它理解为一种结构性归纳偏置(information bottleneck 的味道),但是否成立取决于任务、超参与训练配方,通常需要实证支持。
-
定长训练 vs. 变长推理:差异在“主导的随长度增长项” MLA 在定长训练和变长推理中都有收益,且收益都随序列长度增加而放大。区别在于主导瓶颈不同:
- 训练时(定长):当显存瓶颈主要由注意力相关激活(如 Q/K/V 中间表示)主导,且采用激活重计算策略时,MLA 使得需要持久化保存的核心表示从 降至 (KV)与 (Q),从而显著降低激活内存随 增长的斜率。当然实际收益还取决于 kernel 实现(例如是否物化 注意力矩阵)与并行策略。
- 推理时(变长):主导瓶颈是 KV cache 与内存带宽;MLA 把每 token 的 cache 从 量级压到 ,使长上下文推理与高吞吐解码更可行。
因此可以这样总结:训练阶段 MLA 的价值主要体现在激活与工程实现(重计算 + kernel)上;推理阶段 MLA 的价值主要体现在 KV cache 与带宽上。 两者都与长度相关,但瓶颈主导项不同。
MLA 对比 GQA 的优势及归因
参考资料:苏剑林 《缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA》。 下文记作“苏神博客”。
结论先行:三者都在优化推理时 KV cache,但采取的约束不同,导致“压缩率 vs. 表达能力”落点不同。
为便于统一对比,先约定符号:
- head 数:
- 每头 Key/Value 维度:(DeepSeek-V3 常见为 ,并额外拼接 RoPE 分量 )
- GQA 的分组数:(每组共享一份 KV)
- MLA 的 KV latent 维度:(对应
kv_lora_rank)
-
三种方法分别“共享/压缩”了什么? (a) MQA:所有 head 共享同一份 KV(最激进的共享)
在苏神博客的记法里:即所有 head 都用同一组 。因此 KV cache 的量级从 降为:
优点是 cache 最小;代价是 KV 表达被强共享约束,可能损伤模型效果(实践上通常靠更大模型/更强训练配方来弥补)。
(b) GQA:把 head 分成 组,组内共享 KV(平滑折中)
苏神博客写作:可理解为:每个 token 只需要缓存 份 KV,于是:
当 时退化为标准 MHA,当 时退化为 MQA。
(c) MLA:不做“硬共享”,而是把 KV 映射到低维 latent,再按 head 线性重建(低秩约束)
苏神博客把 GQA 进一步改写成:并提出用一个更低维的 替代“拼起来的 KV”,令:
这等价于把 KV 的自由度限制在 维 latent 空间(低秩/低维流形),然后用 (按 head 切片)重建出“每头不同”的 。
-
为什么说 MLA 在“效果-压缩”上比 MQA/GQA 更灵活? MQA/GQA 的约束是“共享”(共享得越多,KV 越缺少 head-specific 的表达)。
MLA 的约束是“低秩”(允许每个 head 仍然拥有不同的 ,差异由这些上投影矩阵承载;共享的只是低维 latent )。 直观上:- MQA/GQA 是“减少 KV 的份数”(从 份变成 份)
- MLA 是“每份 KV 都很小”(把内容信息压到 维 latent,再重建)
-
计算侧的关键:矩阵吸收/算子重排,让解码不必显式重建历史 K/V 如果直接“先算 再做注意力”,MLA 反而可能更慢。苏神博客给出的关键技巧是把注意力写成等价形式(可理解为把 吸收到 Query 侧或输出侧):
于是历史侧只需要 cache 低维的 (对应本文的 ),而不是 cache/物化高维的 。这与我们前面讨论的“在 latent 空间做点积/加权、最后再上投影”的推导是一致的,也是 FlashMLA 这类 kernel 能做高吞吐的数学基础。
-
与 RoPE 的关系:MLA 通过解耦把“位置分量”从 KV latent 路径里拿出来 如果把 RoPE 直接作用在“内容 Key”上,会破坏上述吸收/融合的优化空间。DeepSeek 的 MLA 用解耦 RoPE 分量 (跨 head 共享)把“位置”与“内容”拆开:
- 内容: 负责(可极致压缩、可吸收)
- 位置: 负责(维度小、共享、独立 RoPE)
MLA 并不一定比 MQA “更省 cache”
以 DeepSeek-V3 为例,标准 MHA 的 cache/token 约为 ;MLA 约为 (约 压缩);但若用 MQA(共享一份 KV)且 ,则 cache/token 约为 ,理论上仍小于 。
MLA 的优势更多体现在:在大幅压缩的同时,仍能通过按 head 的上投影保留更接近 MHA 的表达能力与效果稳定性。
Footnotes
Footnotes
-
在标准 MHA 中,嵌入维度、模型维度、每个注意头维度 x 注意头数量三者在数值上相等。但在 MLA 中,这个关系不再成立,具体请看下文。 ↩
-
Transformer 作者团队开源 DroPE,将如何影响大模型长上下文能力? - 4567 的回答 - 知乎 ↩