本文截取自 互联网博客:The Scaling Book 并加入自己的翻译和理解。需要注意,目前翻译版本是适合我本人的阅读习惯和知识基础,如果读者有困惑,可以回到原文查看。
在硬件上运行算法1时,性能通常受限于三个核心物理指标:硬件的峰值算力(单位为 OPs/s)、数据传输的内存带宽(单位为 Bytes/s)以及用于存储数据的内存容量(单位为 Bytes)。这些约束构成了所谓的 “Roofline(瓶颈线)” 模型,使我们能够定量地估算特定计算任务执行时间的上界与下界。
1. Where Does the Time Go?
首先探讨一个基础问题:为什么一个算法的运行耗时是 50ms,而不是 50s 或 5ms?在模型执行过程中,究竟是哪些操作消耗了大量时间?我们又该如何预测其理论耗时?
计算开销(Computation): 深度学习模型在底层本质上是大量的矩阵乘法(Matrix Multiplications)运算,每一个矩阵乘法都由一系列浮点乘加操作(FLOPs)组成。加速器(如 GPU 或 TPU)的算力水平直接决定了这些计算任务的理论执行时间,其公式如下:
例如,NVIDIA H100 的 bfloat16 峰值算力约为 FLOPs/s,而 TPU v6e 约为 FLOPs/s。在实际工程中,H100 和 B200 通常只能达到理论峰值算力的 80%-85%,而 TPU 在常规负载下可以接近 95% 的利用率。这意味着在 H100 上执行 次浮点运算大约需要 ms,在 TPU v6e 上则需 1.1 ms。
芯片内通信(Communication within a chip): 在单个加速器内部,张量(Tensors)需要在片上显存(HBM,高带宽内存)与计算核心(Compute Cores)之间进行频繁搬运。该链路的传输速率被称为“HBM 带宽”。在 NVIDIA H100 上,该带宽约为 3.35 TB/s;而在 TPU v6e 上约为 1.6 TB/s。
芯片间通信(Communication between chips): 当模型采用分布式架构部署在多个加速器上时,张量必须在不同芯片之间进行传输。硬件系统通常提供多种互联方案,如 ICI(内部连接接口)、DCN(数据中心网络)或 PCIe 路径,各方案具备不同的带宽表现。
无论是芯片内还是芯片间的通信,我们统一使用字节每秒(Bytes/s)作为衡量指标,并使用以下公式估算总通信时间:
通常情况下(虽然并非绝对),芯片内的计算过程可以与芯片内或芯片间的通信过程实现重叠(Overlap)执行。这意味着,我们可以通过计算时间与通信时间的最大值来界定训练或推理耗时的理论下界(Lower Bound):
同时,我们也可以用两者的代数和作为耗时的上界(Upper Bound):
在实际工程优化中,我们倾向于以 作为目标。这是因为不仅其代数关系更简洁,而且通过合理的流水线调度实现计算与通信的深度重叠,系统的实际表现往往能够逼近这一理论下界。
如果我们以 这一指标作为性能优化的核心基准,那么系统执行时间的下界(完全重叠)与上界(完全串行)之间的理论差距最大不会超过 2 倍。这种代数关系源于不等式 的物理约束。在此估算基础上,为了进一步提升预测精度,我们需要对特定模型在目标系统上的性能画像(Profiling)进行深度分析,通过对计算与通信的“重叠区间(Overlap Regions)”以及各类系统额外开销(Overheads)进行精细化建模,从而获得更符合实际运行情况的性能数据。
假设通信与计算可以完美重叠:当 时,硬件算力资源被充分利用,这种状态被称为“计算受限(Compute-bound)”;反之,当 时,系统处于“通信受限(Communication-bound)”状态,加速器的一部分算力资源会因为等待数据传输而处于闲置状态。判断一个操作属于哪种受限类型,关键在于观察其“算术强度(Arithmetic Intensity)”或称“运算强度(Operational Intensity)”。
定义: 算法的算术强度是指其执行的总计算量(FLOPs)与所需搬运的总数据量(Bytes)之比。搬运的数据量可以涵盖芯片内 HBM 访问或芯片间网络传输。
算术强度衡量了单位数据传输所支撑的浮点运算次数。通常情况下,当算术强度较高时, 远大于 ,此时能充分发挥硬件性能。反之,系统则将大量时间消耗在数据搬运上,造成算力浪费。性能由通信受限向计算受限转换的临界点被称为硬件的“峰值算术强度”,即硬件峰值算力与带宽的比值:
代表了加速器达到峰值性能所需的最低算术强度。以 TPU v5e 的矩阵乘法单元 (MXU2) 为例,其算术强度阈值约为 240 FLOPs/byte(基于其 FLOPs/s 的峰值算力和 Bytes/s 的 HBM 带宽得出)。如果算法的算术强度低于 240 FLOPs/byte,其瓶颈将锁定在访存带宽上,导致硬件算力无法被充分挖掘。
需要注意,这里 240 FLOPs/byte 的硬件算术强度存在特定的前提条件:即算法逻辑涉及从 HBM (高带宽显存) 加载权重项,并由 MXU (矩阵乘法单元) 执行。但在实际的硬件架构中,存储与计算单元具有多样性:正如后文所述,我们有时可以将参数驻留在 VMEM (向量存储器) 中,其访存带宽远高于 HBM。此外,许多非矩阵类算法是在 VPU (向量处理单元) 上运行的,该单元具有截然不同的性能表现。
我们下面来看一个算法示例以帮助理解:
算例分析(点积运算): 考虑两个 BF16 精度向量的点积运算:,其中输入为两个维度为 的向量。该过程需要从显存加载 和 (各占 字节),执行 次乘法和 次加法,最后将 2 字节的结果写回 HBM。
随着向量维度 趋于无穷大,点积运算的算术强度收敛于 0.5 FLOPs/byte。这意味着每加载 1 字节数据仅能支撑 0.5 次浮点运算,远低于硬件的瓶颈阈值,因此点积运算是典型的访存密集型任务。需要补充的是,点积通常在 VPU 而非 MXU 上执行。例如 TPU v5p 的 VPU 峰值算力约为 FLOPs/s,其对应的硬件临界强度约为 3。即便如此,点积的 0.5 依然远低于此阈值。总之,由于此类算子算术强度极低且呈常数特性,在绝大多数高性能硬件上都难以达到计算饱和。
Visualizing rooflines
为了直观地展现显存带宽与算力之间的权衡关系,我们通常采用 Roofline 模型图。该图表在双对数坐标系下,以算法的算术强度为横轴,以算法在硬件上能达到的峰值吞吐量(FLOPs/s)为纵轴。
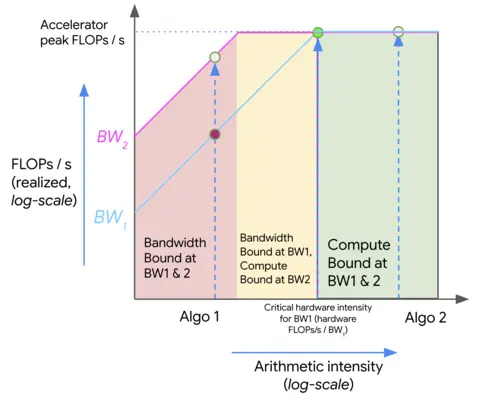
上图展示了在不同带宽(BW1 和 BW2)条件下,两种具有不同算术强度的算法(Algo 1 和 Algo 2)的理论性能表现。
- 红色区域(访存受限区): 无论处于 BW1 还是 BW2 的带宽条件下,算法均受限于访存瓶颈。此时,硬件的峰值算力被大量闲置。
- 黄色区域: 该区域属于过渡区。算法在低带宽(BW1)下表现为访存受限,而在高带宽(BW2)下可能转化为计算受限。
- 绿色区域(计算受限区): 在此区域内,算法在所有预设带宽下均能达到硬件的算力上限。此时,单纯通过增加带宽或提升算术强度已无法进一步获取性能增益。
在上述图表中,随着算术强度从左向右增加,算法的吞吐量(FLOPs/s)起初呈线性增长。这种增长会一直持续到触及硬件的临界算术强度(Critical Arithmetic Intensity)——在 TPU v5e 架构下该值为 240。
- 左侧区间: 任何算术强度低于该阈值的算法都属于 访存密集型(Bandwidth-bound),其性能被显存带宽死死限制(如图中红色斜线部分)。
- 右侧区间: 算术强度超过阈值的算法能够完全释放硬件算力(如图中绿色水平线部分)。
- 对比: 算法 1 处于通信/访存受限状态,仅能利用硬件理论算力的一小部分;而算法 2 则处于计算受限状态。
通常情况下,提升算法性能的路径有两条:一是通过优化算子逻辑来提高算术强度;二是通过硬件升级或架构优化来提升可用带宽(即从 BW1 跃迁至 BW2)。
Matrix multiplication
矩阵乘法(Matmul)是深度学习中最核心的操作。设矩阵运算为 ,其维度定义如下:,,。
执行该运算时,底层算子需从显存加载权重与激活值(共 字节),执行约 次浮点运算(包括 次乘法与 次加法),最后将结果写回 HBM( 字节)。
注: 虽然 Matmul 的中间累加值通常采用 FP32 以保证精度,但在写回 HBM 前通常会下采样至 BF16。
基于此,矩阵乘法的算术强度公式定义为:
在 Transformer 架构的计算中,如果假设单批次处理量 远小于特征维度 和 (这是一个常见场景),公式可以大幅简化:
结合 TPU v5e 的硬件特性,若要使 Matmul 进入计算密集区,需满足:
在现代大模型中,即使 和 通常大于 8000,单副本(Per-replica) 的 Batch Size(此处的单位是 Token 总数而非 Sequence 数量)通常在 1024 以下。因此,我们得出了一个极其简洁的经验法则:当单芯片承载的 Token 批大小超过 240 时,矩阵乘法通常能进入计算受限状态。
之所以强调“单副本 (per-replica)”这一概念,是因为当我们通过模型切分 (Model Sharding) 等并行技术增加参与矩阵乘法的芯片数量时,系统的总算力峰值与总显存带宽是按相同比例同步扩展的。这意味着硬件层面的临界算术强度并不会因为集群规模的扩大而改变。因此,对于每一份独立的模型权重副本(或物理分片)而言,上述临界 BatchSize 依然适用且保持恒定。
核心要点: 为了在主流 TPU 上实现 BF16 矩阵乘法达到计算受限,单副本的 Token BatchSize 需大于 240。这里的 BatchSize 并非传统意义上的序列数(Sequences),而是总 Token 数。Roofline 模型的表现主要取决于 Token 总量,无论这些 Token 属于同一序列还是分布在不同序列中。例如:在 128 颗 GPU 上运行 512 条序列、每条序列 4096 个 Token 的任务,全局 Token BatchSize 为 ,而分配到每颗芯片的局部 BatchSize 为 Token。
工程边界与限制: 在实际生产中,有几个值得注意的例外情况:
- 量化影响: 如果对权重/激活值采用量化(如 INT8/FP8),但计算仍维持高精度,算术强度会因访存量减少而改变。
- GPU 差异: 对于 NVIDIA GPU,这一临界 BatchSize 的数值通常略高(接近 300),但量级和逻辑一致。
- 分块(Tiling)效应: 在底层实现中,大型矩阵乘法会被切分为更小的 Tile 以适配 VMEM/SMEM/TMEM 等片上高速缓存。这会导致特定数据块被重复加载,实际访存开销会高于理想的 ,从而降低实际的算术强度。
Tiled GEMM
我们从最常见的矩阵乘开始:
tiled GEMM 的第一步不是“优化”,而是重新组织计算。我们在三个维度上引入 tile 尺寸:
- :M 维 tile 高度
- :N 维 tile 宽度
- :K 维 reduction 的分块大小
假设整除,有:
这意味着:整个 GEMM 被拆成了 个输出 tile,每个输出 tile 的大小是 。
对任意一个输出 tile ,它并不是一次算完的,而是沿着 K 维慢慢累加:
这里每一项都是一个小矩阵乘:
- :
- :
- 结果累加到 :
所以 tiled GEMM 的本质是:把一个大 GEMM,拆成很多个“对同一个 反复做的小 GEMM”。
对一个 乘 的小 GEMM,计算量是:
而这样的计算一共发生在:
个 tile 组合上,因此总 FLOPs 是:
这件事非常重要但也很容易被忽略的事实:tiling 不会减少 FLOPs。它只是改变了这些 FLOPs 在时间和空间上的组织方式。
性能的关键不在算力 FLOPs,而在访存 bytes。在典型的 tiled GEMM 数据流中,对一个固定的输出 tile :
- 沿 K 维循环
- 每一步:
- 读一个 ,大小
- 读一个 ,大小
- 在整个 K 循环中:
- 一直保存在片上
- 只在开始时 load 一次,结束时 store 一次
因此,对单个 tile 的数据访问量是:
把所有输出 tile 乘起来,并考虑 load + store,对应你给出的总 bytes:
这条公式背后隐含的核心假设可以一句话概括:A 和 B 在 K 维上被反复读取,而 C 在 K 维上被最大化复用。
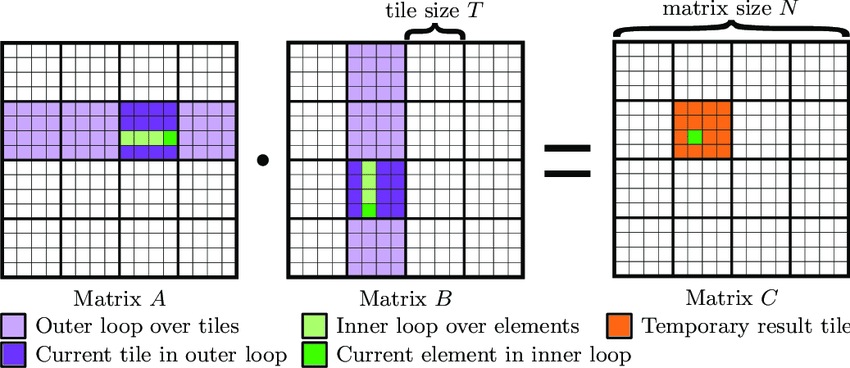
这正是 tiled GEMM 的“魔法”所在。
把 FLOPs 和 bytes 放在一起,就能看到 tiling 的效果。
对单个输出 tile,其算术强度大致为:
当 很大时,可以近似得到一个上界:
这一结果揭示了一个非常重要、也极具工程指导意义的事实:算术强度的上界主要由输出 tile 的形状 决定,而不是由 决定。换言之, 更多影响的是流水线深度、寄存器与片上存储压力以及并行度,而 决定了“每次把 A/B 的数据摊薄到多少次 FMA 上”。
在真实 GPU / TPU 实现中,这一逻辑 tile 会进一步映射到具体硬件层级:block-level tile 对应一个 thread block 或 program instance;warp-level tile 对应 warp 或子 warp 的协同计算;最内层则是寄存器级的 micro-tile,每个线程持有一个很小的 累加块。典型执行流程是:将 A/B tile 从 HBM 搬入 shared memory 或 scratchpad,在寄存器中完成多次 FMA,并在整个 K 循环结束后一次性写回 C tile。
从系统角度总结,tiled GEMM 的本质可以表述为:通过扩大输出维度上的复用窗口,用片上存储与寄存器压力换取更高的算术强度,从而将 GEMM 从带宽受限推向算力受限。你给出的 FLOPs 与 bytes 公式,已经完整刻画了这一机制;理解这些公式背后所假设的数据流模型,等价于理解 tiled GEMM 是如何在真实硬件上实现并取得高性能的。
Network communication rooflines
前文探讨的 Roofline 模型主要聚焦于单芯片内部的访存带宽限制。然而,在实际的大规模分布式训练与推理场景中,这并非唯一的性能边界。事实上,在构建高性能 AI 基础设施时,我们更关注的是片间通信(Inter-chip Communication) 引发的瓶颈,特别是当巨大的矩阵被切分(Sharded)并分布式部署在多个 TPU/GPU 节点上时产生的通信开销。
为了直观说明,我们设定一个典型的张量并行(Tensor Parallelism) 示例:假设需完成 与 的矩阵乘法,并将这两个矩阵沿内维 均匀切分到两个计算节点(TPU/GPU)上。 在这种并行方案下,每个节点各负责一半的计算任务:TPU 0 计算 ,TPU 1 计算 。计算完成后,各节点需交换生成的部分和(Partial Sums) 并进行累加以获得最终结果。 假设单节点的峰值算力为 FLOPs/s,跨节点双向通信带宽为 Bytes/s。我们来量化其计算耗时 与通信耗时 。
计算耗时 : 由于工作负载被对半平摊,每个节点的计算量减半。尽管后续还涉及部分和的加法运算(约 次浮点加法),但相对于 复杂度的矩阵乘法,这部分 的开销在宏观上可忽略不计。
通信耗时 : 此时的通信不再是指片上访存,而是跨节点的网络数据交换。其耗时取决于各自的 partial sum 的数据量( 字节)与网络带宽的比值:
瓶颈判定: 当算法在跨节点维度上的算术强度超过网络的临界值时,系统将进入计算受限 状态。即:
关键发现: 与单芯片 HBM 受限场景(临界值取决于 Batch Size )不同,在分布式张量并行场景下,性能瓶颈的临界点取决于模型特征维度 。
理解这种基于网络通信的 Roofline 模型,对于评估特定算子在多 TPU/GPU 集群上的可并行性(Parallelizability) 具有决定性的指导意义。
2. A Few Problems to Work
Question 1 [int8 matmul]: 假设我们执行矩阵乘法 ,不过精度从 bfloat16(每参数 2 字节)降至 INT8(每参数 1 字节)。此处使用符号 表示在维度 上进行张量缩并(Contraction)。现代 GPU/TPU 架构在低精度下通常具备更高的吞吐量。
- 该算子需要从显存(HBM)加载多少字节?写回多少字节?
- 总共执行了多少次操作(OPs)?
- 该操作的算术强度是多少?
- 如何估算其 Roofline 模型的 与 ?该算子总运行时间的理论上下界是多少?
已知参数: HBM 带宽为 Bytes/s,INT8 峰值算力为 OPs/s(约为 BF16 的 2 倍)。
访存量: 由于采用 INT8 存储,每个参数占用 1 字节。因此,从 HBM 加载的数据量为 字节,写回数据量为 字节。
计算量: 逻辑运算量与精度无关,依然是 次操作(在 INT8 下称为 OPs,而非 FLOPs)。
算术强度: 公式为 。若延续前文假设(即 且 ),算术强度可简化为 。这意味着性能达标规则变为:。根据已知数据,硬件临界强度为 ,则要求 。可以看到,尽管采用了低精度,进入计算受限状态所需的 Batch Size 阈值几乎没有变化。
耗时估算:
- 理论下界为 ,理论上界为 。
Question 2 [int8 + bf16 matmul]: 在工业界实践中,权重与激活值通常采用不同的量化策略(例如 W8A16)。我们可能以低精度存储权重,但保留高精度的激活值和计算过程。假设权重采用 INT8,而激活值与计算过程保留 bfloat16。在这种情况下,Batch Size 达到多少时会进入计算受限状态?假设 BF16 峰值算力为 FLOPs/s。
提示: 具体的张量交互逻辑为 bfloat16[B, D] * int8[D, F] -> bfloat16[B, F],其中 为 Batch Size(Token 数)。
同样假设 较小,此时计算量仍为 (BF16 FLOPs)。但在访存方面,权重矩阵仅需加载 字节(INT8),而不再是 BF16 下的 字节。 计算临界点时,访存量的减少使得算术强度提升。根据 Roofline 推导,当 时,系统便进入计算受限状态。
Insight: 这一阈值显著降低(从 240 降至 120),意味着即使不切换到纯 INT8 计算 kernel,仅仅通过 权重量化(Weight-only Quantization) 技术,就能在更小的 Batch Size 下充分利用硬件算力,大幅提升推理效率。
Question 3: 基于思考题 2 的 W8A16 设置,请绘制峰值吞吐量(FLOPs/s)随 变化的 Roofline 曲线图。请分别考虑 和 两种情形。要求: 计算时请使用精确的访存字节数,不要使用简化近似值。
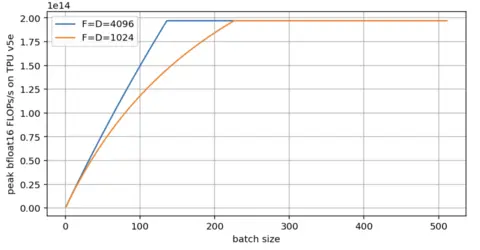
虽然两个模型最终都能达到硬件的峰值算力,但维度较大的模型()更早地进入了计算受限区。 相比之下,当维度缩小至 时,临界 Batch Size 几乎翻了一倍。这是因为在较小的矩阵维度下,输出矩阵写回()和输入激活值加载()在总访存中的占比增加,导致算术强度的增长变缓,需要更大的 才能填补计算核心的空置。
import matplotlib.pyplot as plt
import numpy as np
bs = np.arange(1, 512)
def roofline(B, D, F):
total_flops = 2*B*D*F
flops_time = total_flops / 1.97e14
comms_time = (2*B*D + D*F + 2*B*F) / 8.2e11
total_time = np.maximum(flops_time, comms_time)
return total_flops / total_time
roofline_big = roofline(bs, 4096, 4096)
roofline_small = roofline(bs, 1024, 1024)
plt.figure(figsize=(8, 4))
plt.plot(bs, roofline_big, label='F=D=4096')
plt.plot(bs, roofline_small, label='F=D=1024')
plt.legend()
plt.xlabel('batch size')
plt.ylabel('peak bfloat16 FLOPs/s on TPU v5e')
plt.grid()Question 4: 假设我们需要执行一种特殊的批次矩阵乘法 (Batch Matmul, BMM):。在这种场景下,Batch 中的每个样本都拥有各自独立的权重矩阵(而非共享同一组权重)。请推导该操作的算术强度。
我们首先量化该操作的总计算量与通信开销:
-
总计算量 (Total FLOPs): 虽然每个样本对应的权重不同,但计算逻辑仍包含 组维度为 的乘加运算,因此总计算量保持不变,依然是 。
-
总通信开销 (Total Comms): 由于每个 Batch 元素都需要加载独立的权重矩阵,访存开销显著增加,总计为 。
-
算术强度推导: 此时的算术强度公式变为 。在 和 较大的典型深度学习场景中, 项在分母中占据主导地位,导致算术强度趋近于常数 2。
这意味着算术强度不再随 Batch Size () 的增加而线性提升,而是被限制在一个极低的水平。无论如何增加 Batch Size,这类算子几乎永远处于通信受限 (Communication-bound) 状态,无法发挥加速器的计算性能。
Problem 5 [Memory Rooflines for GPUs]: 请根据 NVIDIA H100 SXM 官方规格表,计算在执行 bfloat16 矩阵乘法时,达到计算受限 (Compute-bound) 状态所需的临界 Batch Size。注意: 规格表中的 Tensor Core 算力通常标称的是开启结构化稀疏 (Structured Sparsity) 后的性能,这通常是常规稠密计算性能的两倍,计算时需取其一半。
根据 H100 SXM 的官方参数:
-
峰值算力: 规格表标注的 bfloat16 性能为 FLOPs/s(带星号标注“需开启稀疏”)。对于常规模型训练和推理(稠密计算),其实际算力约为该值的一半,即 FLOPs/s (1 PFLOPS)。
-
显存带宽: HBM3 的显存带宽为 3.35 TB/s,即 Bytes/s。
-
临界 Batch Size () 计算:
结论: 在 H100 上,当单副本 Token 批大小达到约 298 时,系统才能从访存受限转为计算受限。这一数值与前述 TPU 的估算结果(240)在量级上非常接近。