本文截取自 互联网博客:The Scaling Book 并加入自己的翻译和理解。需要注意,目前翻译版本是适合我本人的阅读习惯和知识基础,如果读者有困惑,可以回到原文查看。
我们将简要回顾 Transformer 架构的基础实现,重点探讨如何精确估算浮点运算次数(FLOPs)、访存字节数(Bytes)以及其他关键性能指标。
1. Counting Dots
首先,定义参与运算的向量 、 以及矩阵 、 的维度形状(Shape):
- 两个向量的点积 涉及 次乘法与 次加法,总计产生 次浮点运算(FLOPs)。
- 矩阵-向量乘法 本质上是对矩阵 的每一行与向量 进行点积,共计执行 次点积运算,其总运算量为 FLOPs。
- 矩阵-矩阵乘法 可以视作对矩阵 的 个列向量分别进行矩阵-向量乘法,因此其总运算量为 FLOPs。
- In general, if we have two higher dimensional arrays and , where some dimensions are CONTRACTING and some are BATCHING. (e.g. ) then the FLOPs cost of this contraction is two times the product of all of the and dimensions where the batch and contraction dimensions are only counted once, (e.g. ). Note that a dimension is only batching if it occurs in both multiplicands. (Note also that the factor of 2 won’t apply if there are no contracting dimensions and this is just an elementwise product.)
- 推广至通用高维张量:假设存在两个高维张量 和 进行张量收缩(Contraction),其中部分维度为收缩轴(),部分为批次轴()。例如,对于维度为 的 和维度为 的 ,该收缩操作的 FLOPs 开销等于所有维度乘积的 2 倍。在计算时,批次轴与收缩轴的维度仅计算一次(这个例子中为 )。需注意,只有当某一维度同时出现在两个参与运算的张量中时,才可能被视为批次轴;此外,若运算不涉及收缩轴(如逐元素逐位相乘 Element-wise product),则无需乘以系数 2。
值得注意的是,在矩阵乘法运算中,计算开销按三次方阶 增长,而数据搬运开销仅按二次方阶 增长。这意味着随着矩阵规模的扩大,其算术强度不断提升,系统更容易达到Compute-bound的峰值性能,即进入计算饱和区。这一特性在计算科学中极为罕见,也从底层逻辑上解释了为何现代 AI 架构普遍采用以矩阵乘法为主导的设计——因为它们具有极佳的可扩展性(Scalability)。
Forward and reverse FLOPs
在深度学习训练阶段,我们不仅关注矩阵乘法的前向输出结果,更关注其梯度的推导。这意味着在反向传播过程中,会产生显著高于前向传播的 FLOPs 开销。
假设 B 是神经网络中的权重矩阵,A 为输入激活值(Activations),前向计算为 C = AB。根据链式法则,损失函数 L 对权重 B 的梯度计算如下:
该梯度运算通过对 维进行收缩,需要 2NPM FLOPs 的计算量。同理,损失函数对输入激活值 A 的梯度为:
由于 dL/dC 的维度为 ,此项运算同样需要 2NPM FLOPs。尽管对 A 的梯度并非直接针对参数,但它是将梯度反向传播至前一层所必需的中间变量(正如 dL/dC 被用于计算上述 dL/dB 一样)。 is again 2NPM FLOPs since dL/dC is a matrix of size . While this quantity isn’t the derivative w.r.t. a parameter, it’s used to compute derivatives for previous layers of the network (e.g. just as dL/dC is used to compute dL/dB above).
综合上述各项,我们可以得出:在训练阶段,总运算量为 6NPM FLOPs(前向传播 2NPM,反向传播 4NPM),而推理阶段仅需 2NPM。由于 代表矩阵中的参数总量,这便构成了 Transformer 训练量估算中经典的近似公式:。即对于每个 Token,其训练开销约为 FLOPs。下文将提供更严谨的推导过程。
2. Transformer Accounting
Transformer 架构代表了深度学习的未来。事实上,它早已成为当下的主流范式。几年前,它或许还只是众多模型架构中的一种,但时至今日,深入掌握其架构的每一个技术细节已成为研究者的必修课。本文不再对其基础架构做重复性介绍,初学者可以参考 Jay Alammar 的博客或 Transformer 原始论文作为辅助资料。
下图展示了 Transformer Decoder(解码器)架构的基础逻辑:
![]()
该图展示了标准 Transformer 内部一个典型层的计算流向,遵循自顶向下的逻辑顺序。我们采用单字母约定来描述张量的形状与布局:其中红色标注代表收缩维度(Contracting Dimensions),蓝色标注代表批次维度(Batching Dimensions)。在具体的算子操作中,左上方标明输入张量的维度,右上方标明参数(权重)张量的维度,下方则为输出张量的维度。例如,在门控爱因斯坦求和(Gating Einsum)操作中,输入维度为 (BatchSize, Sequence Length, Embedding Dimension),对应的权重维度为 (Dimension, FFN Hidden Dimension)。
Note 1 [gating einsum]: 上图采用了“门控爱因斯坦求和( gating einsums)”机制(通常指 SwiGLU 等变体),即通过将传统的升维投影矩阵拆分为两个独立的矩阵(如上图中的 和 ),并将两者的输出进行逐元素相乘(Element-wise Product)以实现门控机制。并非所有大语言模型(LLM)都采用此方案,部分模型仅使用单个 矩阵,此时 MLP 层的总参数量为 而非 。在这种情况下,通常会相应放大 或 的数值,以保证总参数量与三矩阵方案持平。话虽如此,门控机制目前已成为主流,被 LLaMA、DeepSeek 等众多前沿模型广泛采用。
Note 2 [MHA attention]: 在自注意力机制中,Key-Value 序列长度 与 Query 序列长度 相等;但在交叉注意力中,两者可能不同。在标准的多头注意力(MHA)中,query head 数 与 kv head 数 相等。而在为了优化推理性能而提出的变体中,多查询注意力(Multi-Query Attention, MQA)将 设为 1,即所有查询共享一组 KV;而组查询注意力(Grouped MQA, GQA)则要求 能够被 整除,通过分组共享 KV 来平衡计算效率与模型表达能力。
3. Global FLOPs and Params Calculation
为了简化表述,下文将重点计算单层(Per-layer) 的 FLOPs 开销,从而避免在所有公式中重复出现层数因子 。
MLPs
Transformer 中的 MLP 块通常由两个并行的升维投影矩阵(其输出进行逐元素结合)以及一个降维输出矩阵组成:
Attention
针对采用不同 Q 和 KV 头数的通用组查询注意力(GQA)场景,我们假设 Q、K、V 投影算子的 head 维度 相同。首先估算四个线性投影矩阵(QKVO)的开销:
The dot-product attention operation is more subtle, effectively being a matmul batched over the , dimensions, a softmax, and a matmul again batched over the , dimensions. We highlight the batched dims in blue: 点积注意力(Dot-product Attention)本身的运算量更为细微,它实际上包含了两个主要步骤:首先是 的矩阵乘法(计算 ),随后是 Softmax 归一化,最后是 的矩阵乘法(乘以 )。这些操作均在 (Batch)和 (Heads)维度上进行批处理。我们在下式中以蓝色标出批次维度:
Note [causal masking]: 目前大多数 Transformer 模型采用因果掩码(Causal Mask)而非全双向注意力。在这种情况下,点积运算中的有效浮点运算量会减少约 。在底层实现中,我们需要使用专门的 Attention Kernel(如 FlashAttention)来优化此逻辑,而非直接调用朴素的 Einsum 算子。
Other Operations
There are several other operations happening in a Transformer. Layernorms are comparatively cheap and can be ignored for first-order cost estimates. There is also the final enormous (though not per-layer) unembedding matrix multiply. Transformer 中还包含其他操作。例如,层归一化(LayerNorm)的开销相对极低,在一阶成本估算中通常可以忽略不计。此外,在模型顶层还存在一个规模巨大的 Unembedding 矩阵乘法(将隐藏向量映射回词表空间),尽管它不是逐层出现的。
General rule of thumb for Transformer FLOPs
在短文本训练场景下,若忽略点积注意力的二次方开销,则所有层的总 FLOPs 可近似表示为:
这便是业界估算稠密(Dense)Transformer 模型运算量的经典准则:在忽略注意力算子本身开销的情况下,训练 FLOPs 约为参数量的 6 倍与 Token 数的乘积。(Unembedding 层的 6BTDV FLOPs 与其 DV 参数量也符合这一 6 倍关系准则。)
Fractional cost of attention with context length
若我们将点积注意力的开销纳入考量,并设定典型参数结构 , 且 (标准 MHA):
因此,只有当序列长度 时,点积注意力的 FLOPs 才会成为训练的主导开销。对于模型维度 的模型,这一临界值约为 64k Tokens。这表明随着 MLP 规模的增大,注意力机制的相对算力负担会有所减轻。对于超大规模模型,注意力的二次方开销并不是长文本训练的绝对瓶颈;但对于较小的模型(如 Gemma-27B,),当序列长度超过 32k 时,注意力开销就会占据主导。此外,Flash Attention 等技术极大缓解了长文本的算力与访存压力,相关细节详见附录 A。
4. Miscellaneous Math
Sparsity and Mixture-of-Experts
有必要简要探讨混合专家模型 (Mixture of Experts, MoE)。该架构通过一组可动态路由的独立 MLP 专家模块,替代了标准 Transformer 中的单个稠密 MLP 层。从直觉来看,MoE 架构可以视作在每层部署了 个 MLP 块的稠密模型。在计算过程中,每个 Token 仅会激活其中的 个专家(通常 )。 的比值被称为稀疏度 (Sparsity),在主流设计中通常处于 8 到 64 之间(例如 DeepSeek-V3 实际采用了 的配置)。与相同规模的稠密模型相比,MoE 将总参数量提升了 倍,但每个 Token 实际激活的参数量仅倍增了 倍,从而在维持计算开销可控的同时大幅提升了模型容量。
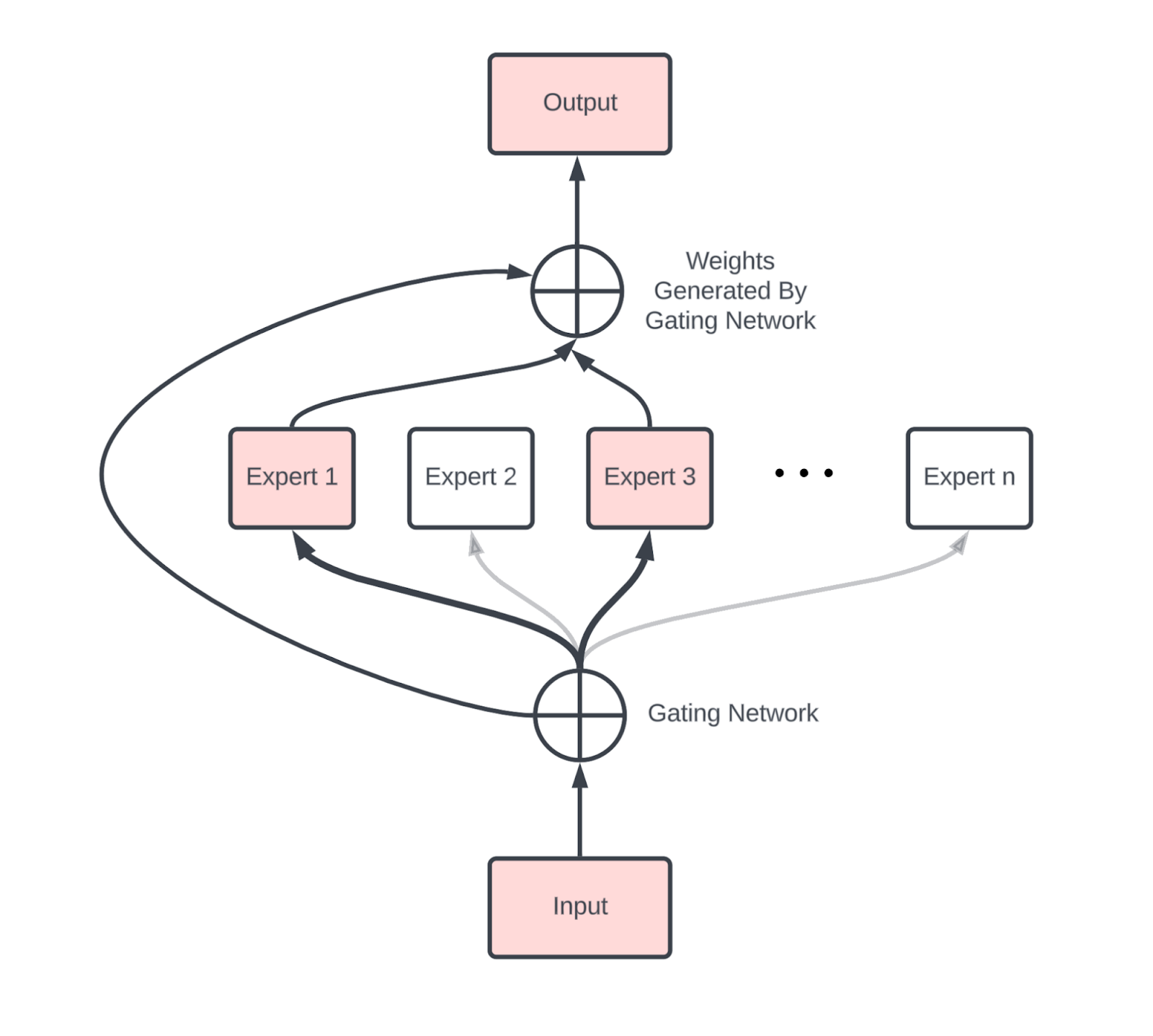
上图是包含 个专家的 MoE 层示例。门控专家(Gating Expert)负责将每个 Token 路由至 个选定的专家模块,随后将这些 MLP 的输出进行加权求和。该架构的总参数量由所有专家的规模总和决定,但对于特定 Token,仅有被激活的 个专家参与实际计算。
与稠密模型不同,MoE 引入了额外的通信开销,主要体现为两次AllToAll:一次用于将 Token 路由至目标专家所在的算力节点,另一次用于将计算结果收回到原始设备。从技术底层实现来看,只有当数据并行或序列并行轴与专家并行轴重合时,这种通信才会触发。然而,正如 Section 3 所述,在双向环形拓扑中,单次 AllToAll 的通信成本仅为同规模轴上 AllGather 操作的 1/4。 Compared to a dense model, an MoE introduces new comms, primarily two AllToAlls (one before and one after the MoE block) that route tokens to the correct expert and bring them back to their home device.Technically, this only happens if we are data or sequence sharded along the same axis as our experts. However as we saw in the previous section, the cost of each AllToAll is only 1/4 that of a comparable AllGather along a single axis (for a bidirectional ring).
Gradient checkpointing
Backpropagation as an algorithm trades memory for compute. Instead of a backward pass requiring FLOPs, it requires memory, saving all intermediate activations generated during the forward pass. While this is better than quadratic compute, it’s incredibly expensive memory-wise: a model with (4M total tokens per batch), L=64, and D=8192 that avoids all unnecessary backward pass compute would have to save roughly of activations in bfloat16. 20 comes from (roughly) counting every intermediate node in the Transformer diagram above, since e.g. 反向传播算法在本质上体现了“以空间换时间”的权衡逻辑。为了避免反向传播产生 阶的冗余浮点运算,该算法默认消耗 的内存开销,用于存储前向传播过程中产生的所有中间激活值 (Activations)。
尽管这规避了二次方级的计算量,但其显存占用极其庞大。以一个 (每 batch 400 万 Token)、层数 、维度 的模型为例,若要保存所有中间变量以消除重复计算,在 bfloat16 精度下大约需要缓存 的激活值。公式中的系数 20 是对 Transformer 计算图中所有中间节点(如算子输出、缓存项)的估算,理由如下:
例如,计算 时,为了在求导时直接利用中间结果而无需重新计算,必须在前向传播中同时保留 和 。为了缓解这种内存压力,我们可以选择仅缓存部分中间激活值,并采用以下重算(Rematerialization)策略:
- Block remat (块重算):仅保留每一层的输入张量作为检查点。这是最激进的策略,每层仅需一个 Checkpoint。在上述示例中,这能将内存占用降至 4.2TB。但这会导致在反向传播时必须重新执行几乎所有的前向计算,使总 FLOPs 从 增加到约 。
- Big matmuls only (仅保留大矩阵乘法):另一种简易策略是仅保存大规模矩阵乘法算子的输出。这样可以避免在反向传播中重复执行耗时巨量的 Matmul,但仍需重算激活函数和 Attention 的部分逻辑。这能将每层保留的中间节点数从 20 个降低至约 7 个。
- Big matmuls only: another simple policy is to only save the outputs of large matmuls. This lets us avoid recomputing any large matmuls during the backward pass, but still makes us recompute other activation functions and parts of attention. This reduces 20 per layer to closer to 7 per layer.
上述方案并非详尽无遗。在 JAX 框架下,此类逻辑通常由 jax.remat 或 jax.checkpoint 高阶函数统一调度。(you can read more here).
Key-Value (KV) caching
正如 Section 7. 所述,大语言模型推理过程分为两个关键阶段:预填充 (Prefill) 与解码生成 (Generation)。
- Prefill (预填充):并行处理输入的 Prompt,并将 Attention 模块产生的中间变量存储在 KV Cache 中。具体存储对象为 Attention 块中的 Key 和 Value 投影向量。
- Generation (生成):对多个请求的 KV Cache 进行批处理,逐个采样生成新的 Token。
每个请求的 KV Cache 逻辑上是一个维度为 的张量,其中系数 2 分别对应 Key 和 Value。这一开销非常显著。以 int8 精度计算,总容量为 。对于一个上下文长度 8k、层数 64、维度 的中等规模模型,其单请求 KV Cache 占用约为 。这正是为何工业界倾向于采用组查询注意力 (GQA/GMQA) 技术,通过使 来大幅压缩访存开销的原因。
5. What Should You Take Away from this Section?
- Transformer 的总参数量与 FLOPs 估算相对直观。下表汇总了标准多头注意力(MHA)架构下的各项指标(假设 Batch Size 为 ,词表大小为 ,序列长度为 ,模型维度 ,MLP 维度 ):
- 在序列长度 的情况下,MLP 块的参数量在总参数量中占主导地位,且其 FLOPs 开销也占据了算力预算的大部分。
- 在常规上下文长度下,训练阶段的总 FLOPs 预算可以很好地通过公式 进行近似。
- 在推理阶段,每个请求的 KV Cache 占用约为 (其中 为 KV 头数),不过通过架构优化(如 MQA/GQA)可以有效降低这一数值。
6. A Few Problems to Work
Question 1: 假设一个模型配置为 ,,,,其总参数量是多少?其中注意力参数占比多少?每个 Token 的 KV Cache 占用多大?(假设 ,采用标准 MHA 以及 int8 格式存储 KV Cache)
解答:
- 总参数量约为 。带入数值:,即 16B (160亿) 参数。
- 注意力参数占总参数量的比例通常为 。即大约 1/4 的参数用于注意力机制。
- 在 int8 精度下,每个 Token 的 KV Cache 为 Bytes,即 512kB / token。
Question 2: 在配置为 {'X': 4, 'Y': 8, 'Z': 4} 的硬件拓扑上执行矩阵乘法 ,总共需要多少 FLOPs?每台 TPU 执行多少 FLOPs?
解答: 该操作的“理论”总 FLOPs 为 。然而,由于计算并未在 维度上进行切分(Sharding),我们实际上多做了 倍的冗余计算,即总计 FLOPs。由于计算在其他维度上进行了切分,单台设备的计算量约为 。
Question 3: 执行张量收缩 涉及多少 FLOPs?
解答:根据前文准则, 和 是收缩维度(Contracting Dimensions),而 是非收缩维度。此操作不含“批次维度”(Batching Dimensions),因此 FLOPs 等于所有轴维度的乘积之倍:。如果存在共享的批次轴,则该轴维度仅计算一次。
Question 4: 自注意力机制(不计 Q/K/V/O 投影层)的算术强度是多少?(请给出关于查询长度 和 KV 长度 的函数) 在何种上下文长度下,注意力机制会进入计算受限(FLOPs-bound)状态?结合 TPU 的 HBM 带宽,请描述随着上下文长度增长,注意力机制相对于前馈网络(FFW)块的实际成本变化。
解答:
自注意力运算涉及加载 激活值,计算 ,并将结果写回 HBM。在使用 Flash Attention 优化的情况下,计算逻辑如下(bf16 精度):
总访存量为 。总 FLOPs 为 ,则算术强度为
简而言之:在 Prefill(预填充) 阶段,,算术强度约为
在 Generation(解码生成) 阶段,,算术强度为
\frac{4BSKGH}{4BHK \cdot (G+S)}=\frac{SG}{G+S} \rightarrow G $$(假设 $S$ 非常大)。 根据对问题的理解,在 Prefill 或训练阶段,若不进行序列切分,当 $S=240$ 左右时 self-attention 即进入计算受限状态。而在解码阶段,由于 $G$ 值较小,我们几乎永远处于访存受限状态。尽管如此,增加 $G$ 可以使我们更接近计算受限的理想状态。 --- **Question 5:** 当序列长度达到多少时,自注意力机制(Self-attention)本身的 FLOPs 会与 QKVO 线性投影层的 FLOPs 持平? **解答:** 这本质上是一个等式求解问题,即:$24BTDNH = 12BT^2NH$。 简化后可得 $2D = T$。 例如,当隐藏层维度 $D=4096$ 时,临界序列长度为 $8192$。这表明对于大多数常规的上下文长度,线性投影层的算力开销依然占据主导。 --- **Question 6:** 假设在前向传播中,我们仅保存 Transformer 单层中 7 个核心矩阵乘法算子(Q, K, V, O 投影以及 FFW 的三个权重矩阵)的输出结果。在反向传播过程中,我们需要通过“重算(Rematerialize)”额外增加多少 FLOPs? **解答:** 若仅保存这 7 个矩阵乘法的输出($Q, K, V, O, W_1, W_2, W_3$),则在反向传播阶段,为了计算对输出权重矩阵的梯度 $\frac{\partial L}{\partial W_{O}}$,必须重新计算两次注意力相关的矩阵乘法:QK^T \quad \text{与} \quad \text{softmax}(QK^T)V
每次操作都是在 $B$ 个序列和 $N$ 个头维度上进行的 $T \times T$ 矩阵乘法,因此额外增加的 FLOPs 为:4BT
其他需要重算的算子包括: 1. 为了计算 $\frac{\partial L}{\partial W_{In1}}$ 和 $\frac{\partial L}{\partial W_{In2}}$,需重算 $O(BTD)$ 的逻辑。 2. 为了计算 $\frac{\partial L}{\partial W_{Out}}$,需重算 $O(BTF)$ 的逻辑。 --- **Question 7:** 根据 DeepSeek-V3 的技术报告,该模型在 14.8T Token 上消耗了 279 万 H800 GPU 小时进行训练。已知其单 Token 激活参数量(Activated parameters)为 37B,请估算其达到的硬件算力利用率(MFU/HFU)约为多少?_(提示:注意 DeepSeek 使用了 FP8 精度,且未使用结构化稀疏)_ **解答:** 根据 [H800 规格参数页](https://lenovopress.lenovo.com/lp1814.pdf)显示,H800 在开启稀疏化时提供 3,026 TFLOPs/s 的 FP8 性能;而在常规(非稀疏)情况下,其理论峰值通常减半,约为 $1.513 \times 10^{15}$ FLOPs/s。 总训练时长为 279 万小时,则总提供的理论算力为:$2.79 \times 10^6 \times 1.513 \times 10^{15} \times 3600 \text{ (秒)} = 1.52 \times 10^{25}$ FLOPs。 基于 37B 激活参数量,该训练任务所需的有效计算量约为:$6 \times 37 \times 10^9 \text{ (参数)} \times 14.8 \times 10^{12} \text{ (Tokens)} = 3.3 \times 10^{24}$ FLOPs。 由此计算出硬件算力利用率约为:$3.3 \times 10^{24} / 1.52 \times 10^{25} \approx 21.7\%$。 --- **Question 8:** 混合专家模型 (MoE) 拥有 $E$ 个标准稠密 MLP 块的副本,每个 Token 仅激活其中的 $k$ 个专家。在 TPU v5e 上,若权重采用 int8 格式,需要多大的 Batch Size(以 Token 数计)才能使 MoE 块达到计算受限状态?对于拥有 256 个(路由)专家且 $k=8$ 的 DeepSeek 模型,这个数值是多少? **解答:** 由于我们拥有每个专家的 $E$ 个副本,在 int8 精度下,每个权重矩阵需要加载 $E \cdot D \cdot F$ 字节。因为每个 Token 激活 $k$ 个专家,对于每个权重矩阵,其产生的计算量为 $2 \cdot k \cdot B \cdot D \cdot F$ FLOPs。若要使 bfloat16 的计算达到受限状态,需要算术强度超过 240(TPU v5e 的典型阈值),即:\frac{2 \cdot k \cdot B \cdot D \cdot F}{E \cdot D \cdot F} > 240 \implies \frac{k \cdot B}{E} > 120
因此,我们需要 **$B > 120 \cdot \frac{E}{k}$** 才能达到计算受限。对于 DeepSeek 而言,这意味着 $B > 120 \cdot 256 / 8 = 3840$。在推理(Generation)阶段,这实际上是一个非常庞大的 Batch Size。 ## APPENDIX ### A: How does Flash Attention work? 传统观点认为,限制 Transformer 扩展至超长上下文的主要障碍在于:注意力机制的算力需求 FLOPs 和显存占用随序列长度呈二次方阶增长。虽然注意力机制中 $QK^T$ 乘积的张量形状确实为 $[B, T, S, N]$(其中 $B$ 是批大小,$T$ 和 $S$ 分别是 Query 和 Key-Value 的序列长度,$N$ 是头数),但这一结论在实际工程中存在几个重要的补充前提: 1. 正如前文所述,尽管是二次方增长,但只有当 $S > 8D$ 时,注意力 FLOPs 才会成为算力瓶颈。特别是在训练阶段,单个注意力矩阵的显存占用(尤其是在进行模型分片/切分后)与显存中驻留的权重及激活值检查点相比,比例仍然较小。 2. **我们并不需要在内存中显式地构建(Materialize)完整的注意力矩阵!** 通过计算局部和(Local Sums)与局部最大值,我们可以避免实例化除一小块数组之外的任何中间结果。虽然总 FLOPs 仍保持二次方增长,但这极大地缓解了显存带宽和容量的压力。 第二项观察最早由 [Rabe 等人 (2021)](https://arxiv.org/abs/2112.05682) 提出,随后在经典的 [Flash Attention 论文](https://arxiv.org/abs/2205.14135) (Dao et al. 2022) 中得到完善。其核心思想是将 K/V 划分为多个分块(Chunks),计算每个块的局部 Softmax 及相关辅助统计量,然后将其传递给下一个分块进行合并。具体而言,我们需要维护: 1. **M:** 序列维度上 $q \cdot k$ 的运行最大值(Running Max)。 2. **O:** 序列维度上完整的运行注意力 Softmax 结果。 3. **L:** 运行分母项(归一化因子) $\sum_i \exp(q \cdot k_i - M)$。 通过这些统计量,我们仅需常数级别的额外内存(Constant memory)即可计算新的最大值、新的运行和以及新的输出。简而言之,注意力机制的底层运算逻辑如下:\text{Attn}(Q, K, V) = \frac{\sum_i \exp(Q \cdot K_i - \max_j Q \cdot K_j) V_i}{\sum_l \exp(Q \cdot K_l - \max_j Q \cdot K_j)}
减去最大值是为了保证数值稳定性(Numerical Stability),且由于恒等式 $\sum_i \exp(a_i + b) = \exp(b) \sum \exp(a)$ 的存在,这一操作不会改变最终结果。仅看分母部分,假设我们有两个连续的 Key 向量分块 $K_1$ 和 $K_2$,并分别为其计算局部 Softmax 累加和 $L_1$ 与 $L_2$:\begin{align} L_1 &= \sum_i \exp(Q \cdot K_{i1} - \max_j Q \cdot K_{j1})\
L_2 &= \sum_i \exp(Q \cdot K_{i2} - \max_j Q \cdot K_{j2}) \end{align}
L_{\text{combined}} = \exp(M_1 - \max(M_1, M_2)) \cdot L_1 + \exp(M_2 - \max(M_1, M_2)) \cdot L_2
其中 $M_1 = \max_j Q \cdot K_{j1}$ 和 $M_2 = \max_j Q \cdot K_{j2}$ 分别是两个分块的局部最大值。 该方法同样适用于完整的 Softmax 计算,从而使我们能够累加任意长度的序列。以下是来自 Flash Attention 论文的完整算法流程:  从硬件角度来看,这种方法允许我们将 Query 的一个分块驻留在向量内存(VMEM,即算法中所述的片上 SRAM)中,在每次迭代中仅需从 HBM 加载 KV 分块,从而大幅提升了算术强度。同时,运行时所需的统计量也可以保留在 VMEM 中。 One last subtle point worth emphasizing is an attention softmax property that’s used to make the Flash VJP (reverse mode derivative) calculation practical for training. If we define an intermediate softmax array as: 最后值得强调的一个微妙技术点是注意力 Softmax 的一个特殊性质,它使得 Flash VJP(向量-雅可比乘积,即反向模式导数)在训练中变得切实可行。我们将中间 Softmax 数组定义为:S_{ij} = \frac{e^{\tau q_i \cdot k_j}}{\sum_l e^{\tau q_i \cdot k_l}}
在注意力机制中,我们通过反向模式下的输出梯度 $dO$ 与 $V$ 数组获取 $dS$:dS_{ij} = dO_{id} \cdot dV_{jd} = \sum_d dO_{id} V_{jd}
d(q_i \cdot k_j) = (dS_{ij} - S_{ij} \cdot \sum_j dS_{ij}) S_{ij}
这里我们利用了一个恒等式,它允许我们将沿庞大的 **Key 长度** 维度的收缩运算,转换为沿**特征深度** 维度的局部收缩运算: $$S_{ij} \cdot \sum_j dS_{ij} = \frac{\sum_j e^{\tau q_i \cdot k_j}}{\sum_k e^{\tau q_i \cdot k_k}} \sum_d dO_{id} V_{jd} = \sum_d dO_{id} \frac{\sum_j e^{\tau q_i \cdot k_j}}{\sum_k e^{\tau q_i \cdot k_k}} V_{jd} = \sum_d dO_{id} O_{id} = dO_{id} \cdot dO_{id}$$ 这一转换对于实现 VJP 的序列分块**局部化** 计算至关重要,并为诸如 Ring Attention 等更精妙的分片/切分方案奠定了基础。