本文截取自 互联网博客:The Scaling Book 并加入自己的翻译和理解。需要注意,目前翻译版本是适合我本人的阅读习惯和知识基础,如果读者有困惑,可以回到原文查看。
这里我们将探讨 LLM 训练中常用的四种主要并行方案:数据并行(Data Parallelism)、全分片数据并行(Fully-Sharded Data Parallelism, FSDP)、张量并行(Tensor Parallelism) 以及流水线并行(Pipeline Parallelism)。针对每种方案,我们将定量计算在何种临界点下,通信开销会成为制约计算效率的瓶颈。
1. What Do We Mean By Scaling?
“模型扩展(Model Scaling)”的核心目标是:通过增加参与训练或推理的芯片数量,实现吞吐量的等比例线性增长,这种理想状态被称为强扩展性(Strong Scaling)。在单芯片维度,性能表现取决于内存带宽(Memory Bandwidth)与算力峰值(FLOPs)之间的权衡;而在集群维度,性能表现则取决于能否通过计算与通信的重叠来掩盖片间通信(Inter-chip Communication)延迟。
实现这一点极具挑战,因为随着芯片数量的增加,整体通信负载会加剧,而分配到每个设备上的计算任务(可用以掩盖通信的有效计算 FLOPs)反而会减少。正如我们在 Section 3. 中讨论的,分片矩阵乘法通常需要调用代价高昂的 AllGather 或 ReduceScatter 算子,这些同步通信操作还可能会阻塞计算单元(如 TPU/GPU),导致算力闲置。本节旨在探索通信开销在何时会变得“过于昂贵”,从而打破强扩展性。
在本节中,我们将重点分析四种主流的并行方案:
- (纯)数据并行(Data Parallelism)、
- 全分片数据并行(FSDP / ZeRO Sharding)、
- **张量并行(Tensor Parallelism,亦称模型并行)
- 以及简要讨论流水线并行(Pipeline Parallelism)。
我们将推导每种方案产生的通信成本,并确定其何时会成为计算成本的瓶颈。我们的分析将集中在通信边界(Communication Bounds) 上——尽管显存容量的限制同样关键,但在预训练阶段,通过结合重算机制(Rematerialization / Activation Checkpointing) 和大规模集群部署,容量通常不会成为第一瓶颈。
此外,本文暂不讨论混合专家模型(MoE)中的专家并行(Expert Parallelism),因为它会显著增加设计空间,我们仅聚焦于稠密 Transformer 的基础情形。在本节讨论中,您可以仅关注片间通信成本,因为只要单芯片上的 Batch Size 足够大,从显存(HBM)到计算单元(如 TPU 的 MXU)的数据传输开销通常已被计算逻辑所掩盖。
为了简化后续推导,我们将统一使用以下符号:
为了简化模型,我们将 Transformer 抽象为一系列 MLP 块的堆叠。正如我们在 Section 4. 中所观察到的,对于超大规模模型,Attention 所占的 FLOPs 比例相对较小。同时,我们也将忽略门控算子(Gating Matmul),从而为每一层构建如下简单的结构:
![]()
上图是简化后的 Transformer 单层结构。我们将每个前馈网络块视为两个矩阵的组合:(升维投影)和 (降维投影),输入激活值为 。
以下是在无并行状态下,该简化 Transformer 模型的完整运算逻辑:
前向传播: 目标是计算损失函数
反向传播: 目标是计算权重梯度 和
- (为前一层计算所需)
提供上述基准逻辑是为了与后续引入通信开销的并行算法进行对比。
以下是我们即将讨论的四种并行方案。每种方案都可以通过对上述架构中的输入 In、权重 W in、W out 以及输出 Out 进行特定的分片(Sharding)来定义:
- 数据并行 (Data Parallelism): 激活值沿 Batch 维度分片,而模型参数和优化器状态在每个设备上完整复制。通信仅发生在反向传播阶段(用于梯度聚合)。
- 全分片数据并行 (FSDP 或 ZeRO-3): 激活值沿 Batch 维度分片(与纯数据并行一致),但模型参数也沿相同的网格轴进行分片,并在前向传播使用前即时地通过
AllGather进行收集。优化器状态同样沿 Batch 维度分片。该方案显著降低了冗余的显存消耗。
- 张量并行 (Tensor Parallelism,又称 Megatron sharding 或模型并行): 激活值沿隐藏层维度 分片,模型参数则沿 FFN 维度 分片。在每个计算块的前后需要对激活值进行
AllGather和ReduceScatter操作。此方案可与 FSDP 叠加使用。
- 流水线并行 (Pipeline Parallelism): 权重沿模型层(Layer)维度进行分片,激活值被切分为微批次(Micro-batches)并在不同层的设备间流动。流水线阶段间的通信开销极小(仅涉及相邻阶段间的激活值单跳传输)。在此借用上述符号表示为:
Data Parallelism
算子表达式:
如果模型规模足以装入单块芯片的显存,即便 Batch Size 极小(只要超过 240 Token 以确保达到计算密集型区间),数据并行就是首选方案。 纯数据并行的核心逻辑是将激活值切分并分布到任意数量的 TPU 上,前提是 TPU 的总数不超过 Batch Size 的总 Token 数。在这种模式下,前向传播不涉及任何跨设备通信;但在每一轮迭代结束时,每个 TPU 必须对其本地梯度(Local Gradients)执行 AllReduce 操作,以在更新模型参数前实现全局同步。
When your model fits on a single chip with even a tiny batch size (>240 tokens, so as to be compute-bound), you should always use simple data parallelism. Pure data parallelism splits our activations across any number of TPUs so long as the number of TPUs is smaller than our batch size. The forward pass involves no communication, but at the end of every step, each TPU performs an AllReduce on its local gradients to synchronize them before updating the parameters.
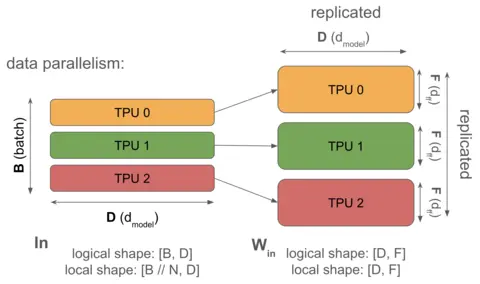
上图是纯数据并行的示意图(前向传播阶段)。激活值(左侧)沿 Batch 维度进行了完整分片,而模型权重在所有设备间完全复制,即每个 TPU 都持有权重的相同副本。这意味着权重占用的总内存随设备数量 等比例增加,但在前向传播过程中无需任何通信开销。
Pure Data Parallelism Algorithm (纯数据并行算法): 以下是前向和反向传播的完整算法流程。为了表述简洁,我们略微放宽符号严谨性,将损失函数对输出的导数 简记为 。
(其中 分别表示沿对应维度做 contraction; 表示 DP 组内每个分片/设备上的局部结果;AllReduce 用于跨 DP 组聚合梯度。)
此处我们忽略了损失函数的具体实现细节,并将中间状态简写为 。需要注意的是,尽管最终的 Loss 是通过 AllReduce(Loss[B_X]) 得到的平均值,但我们只需在反向传播过程中对权重梯度执行 AllReduce 以实现梯度平均。
We ignore the details of the loss function and abbreviate \text{Tmp} = W_\text{in} \cdot \text{In}. Note that, although our final loss is the average AllReduce (Loss[B X]), we only need to compute the AllReduce on the backward pass when averaging weight gradients.
值得注意的是,前向传播过程中完全没有通信——通信开销全部集中在反向传播阶段!此外,反向传播还具有一个优良特性:AllReduce 并不在计算的“关键路径(Critical Path)”上。这意味着 AllReduce 可以在任何合适的时机异步执行,而不会阻塞后续的算子操作。尽管如此,如果总通信成本超过了总计算成本,它仍然会成为瓶颈,但在工程实现上,它比张量并行要灵活得多(后者通常具有同步阻塞特性)。
Note that the forward pass has no communication — it’s all in the backward pass! The backward pass also has the great property that the AllReduces aren’t in the “critical path”, meaning that each AllReduce can be performed whenever it’s convenient and doesn’t block you from performing subsequent operations. The overall communication cost can still bottleneck us if it exceeds our total compute cost, but it is much more forgiving from an implementation standpoint. We’ll see that model/tensor parallelism doesn’t have this property.
何时采用 DP?纯数据并行通过在 Batch 维度上切分激活值,有效缓解了激活值带来的显存压力。只要有足够的芯片来分担 Batch 维度,我们几乎可以无限制地增加 Batch Size。在训练阶段,激活值往往占据了显存消耗的大部分,因此这种方案非常有效。
何时无法采用 DP?纯数据并行无法缓解模型参数或优化器状态(Optimizer States)带来的显存压力。这意味着对于大规模模型,如果其 参数量+优化器状态 超过了单体 TPU 的显存容量,纯数据并行就失去了实用价值。为了直观说明:若使用 Adam 优化器,参数采用 bf16 格式(2字节),优化器状态采用 fp32 格式(包含一阶矩和二阶矩,共 字节),则每个参数需占用 10 字节显存。以拥有 96GB HBM 的 TPUv5p 为例,在纯数据并行模式下,其能承载的最大模型约为 参数。
Takeaway: 使用 Adam 优化器和纯数据并行时,可训练的最大模型参数量为 。对于 TPU v5p,上限约为 90 亿参数。需要注意,由于该估算未包含梯度检查点(Gradient Checkpoints)等额外开销,且假设 Batch 为 1 个 Token 的极端情况,因此这只是一个理论上的绝对下限。
为了在实际大规模训练中发挥作用,我们至少需要对模型参数或优化器状态进行部分分片(Sharding)。
When do we become bottlenecked by communication? 如前文所述,每一层有两个 AllReduce 操作,每个操作涉及的数据量为 字节(针对 bf16 权重)。那么,数据并行在何时会受到通信限制?
设定 为单芯片计算峰值(FLOPs), 为双向网络带宽, 为 Batch 分片的设备数。假设 Batch 分片在 ICI 网格上进行,相关带宽即为 。我们分别计算矩阵乘法所需的时间 和通信所需的时间 。由于该方案在前向传播中无通信,我们只需关注反向传播。
Communication time: 根据前文结论,在 1D 网格中执行 AllReduce 的时间仅取决于数组的总字节数和 ICI 带宽 ;具体公式为 。由于每层需对 和 分别执行 AllReduce,总计两次。每个权重矩阵包含 个参数,对应 字节。综上,单层 AllReduce 的总时间为:
Matmul time: 每一层在前向传播中有两次矩阵乘法,在反向传播中有四次,每次运算量为 次浮点运算。因此,单层反向传播的计算时间为:
由于计算与通信可以重叠,单层的总耗时取决于这两者中的较大值:
当 时,系统进入计算密集型状态,即:
核心结论是:为了在数据并行下保持计算密集型状态,单设备 Batch Size () 必须超过 ICI 的操作强度 。这本质上是因为计算时间随单设备 Batch Size 线性缩放,而通信时间(由于传输的是模型权重)与此无关。注意 与单设备 compute-bound 规则 的相似性:在这两种情况下,规则都源于计算时间随 Batch Size 缩放,而数据传输量在特定尺度下(如 )与 Batch Size 独立。
让我们代入实际数值:对于 TPUv5p,其单芯算力 ,ICI 带宽 。在 1D 数据并行下,单芯片 Batch Size 必须达到至少 2,550 个 Token 才能避免通信瓶颈。由于我们可以跨多个轴进行数据并行,如果将 TPUv5p Pod 的全部三个轴都用于数据并行,带宽 将提升 3 倍,此时单 TPU 的 Batch Size 可降至 850 个 Token。这意味着在由 8,960 颗芯片组成的完整 Pod 上,总 Batch Size 达到 760 万个 Token 即可。这说明在实际应用中,纯数据并行很难遇到通信瓶颈!
Note [context parallelism]: 在本节中, 始终指代以 Token 为单位的总 Batch Size。显然,一个 Batch 由许多不同的序列组成,这如何运作?
- 对于 MLP 层而言,Token 就是 Token!无论它们属于同一序列还是不同序列,处理逻辑都是一致的。因此,我们可以自由地在 Batch 维度和序列(Sequence)维度上执行数据并行:这被称为上下文并行(Context Parallelism)或序列并行(Sequence Parallelism),但本质上可以视作数据并行的变体。
- 相比 MLP,Attention 的处理更为复杂,因为它涉及跨序列计算,但这可以通过在 Attention 计算期间收集 KV 或 Q 向量,并精细地重叠计算与通信(通常采用“环形注意力 Ring Attention”)来解决。在本节后续内容中,我们将忽略序列维度,统称为某种形式的数据或序列并行。
Note on multiple mesh axes: 我们需简要说明多个 mesh 轴如何影响可用带宽——当一种并行策略跨越多个硬件网格轴时,会获得更高的聚合带宽。
- Definition: ( 等) 是给定并行策略跨越的硬件网格轴的数量。
- Effect : 使用 个轴可提供(约 倍)聚合链路带宽,因此集体通信时间与 成正比缩放。
Fully-Sharded Data Parallelism (FSDP)
算子表达式:
全分片数据并行(通常称为 FSDP 或 ZeRO 分片)将模型的优化器状态(Optimizer States)和权重分片存储在不同的数据并行副本中,并根据计算需求高效地进行收集(Gather)和散播(Scatter)。与纯数据并行相比,FSDP 在引入极低额外开销的前提下,极大地降低了单设备的显存占用,并节省了反向传播中的无效计算。
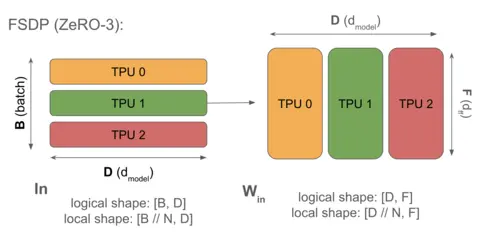
上图展示了 FSDP 沿数据维度对 的收缩维和 的输出维进行分片。这降低了显存占用,但(如 Section 3 所述)要求我们在执行矩阵乘法前先收集权重 。请注意,激活值(左侧)并未沿收缩维分片,这是导致必须执行收集操作的原因。同样,权重的优化器状态也沿收缩维进行了分片。
依照 Section 3 所述,一个 AllReduce 算子可以分解为一个 AllGather 和一个 ReduceScatter。这意味着,我们无需像标准数据并行那样对全局梯度执行完整的 AllReduce,而是可以将权重和优化器状态分片存储在各芯片上,在前向传播的每一层执行 AllGather 并在反向传播中对权重执行 ReduceScatter。这样做在总通信量上与 AllReduce 等价,没有额外成本。
这也被称为 “ZeRO 分片”,源于 “Zero Redundancy Optimizer(零冗余优化器)”,因为我们避免了任何不必要的重复计算或状态存储。ZeRO-1、2、3 分别指代对优化器状态、梯度和权重的分片。由于它们的通信成本在量级上是相同的(从技术上讲,FSDP 在前向传播中增加了纯数据并行所没有的通信,但其比例与反向传播一致,不会改变通信的 roofline 模型。关键在于 ZeRO-3 将反向传播的 AllReduce 拆分为 AllGather 和 ReduceScatter,总通信量保持不变),我们几乎总是可以直接采用 ZeRO-3 分片。
何时采用 FSDP? 标准数据并行存在大量的冗余工作:每个 TPU 都要 AllReduce 全量梯度,然后更新全量优化器状态(每个 TPU 做的活儿一模一样),最后更新参数(依然是完全重复)。而在 ZeRO 分片模式下,你可以通过 ReduceScatter 聚合梯度,仅更新你负责的那一小部分优化器状态和参数分片,最后在前向传播需要时再通过 AllGather 收集参数。
When do we become bottlenecked by communication? 我们的计算(FLOPs)与通信成本的比例与纯数据并行完全一致,因为反向传播中的每个 AllReduce 只是被拆分成了 AllGather + ReduceScatter。而 AllReduce 本身就是由这两个操作组成的,各占一半开销。这里我们以前向传播为例建模,因为它的计算通信比与反向传播相同:
因此,与纯数据并行一样,当 时,系统处于计算密集型状态。对于 TPUv5p 而言,这一临界值约为 2,550。这非常理想,意味着只要你的单设备 Batch Size 足够支持纯数据并行的计算效率,你就可以无缝切换到 FSDP,从而节省巨量的参数和优化器状态显存,而无需担心掉出 compute-bound 区间。虽然前向传播增加了通信步骤,但由于它可以与前向计算完全重叠,这一成本基本可以忽略不计。
Takeaway: 在 TPUv5 上,当单设备 Batch Size 小于 ( 为网格轴数)时,FSDP 和纯数据并行都会进入 bandwidth-bound 区间。
例如,DeepSeek-V2(近期少数公布训练 Batch Size 的强力模型之一)使用了约 4,000 万个 Token 的 Batch Size。这允许我们将其扩展到约 47,000 颗芯片(约 5 个 TPUv5 Pod),而不会触及带宽瓶颈。 For example, DeepSeek-V2 (one of the only recent strong models to release information about its training batch size) used a batch size of ~40M tokens. This would allow us to scale to roughly 47,000 chips, or around 5 TPUv5 pods, before we hit a bandwidth limit.
对于 LLaMA-3 70B,其训练总算力需求约为 FLOPs。如果我们通过 3 轴并行,将 batchsize 为 1,600 万 Token 的 Batch 分配到约 颗芯片(约 2 个 Pod)上,假设模型 FLOPs 利用率(MFU)为 50%,大约只需 17 天即可完成训练。表现相当不错!但让我们看看如何进一步优化。
Note on critical batch size: 稍微有些反直觉的是,在芯片数量固定的情况下,总 Batch Size 越小,通信瓶颈反而越严重。只要能不断增加 Batch Size,数据并行和 FSDP 理论上可以扩展到任意数量的芯片。但在实践中,Batch Size 的增加会带来收益递减,因为梯度会变得过于“无噪(noise-free)”,甚至导致训练不稳定。因此,在“算力无限”的假设下,寻找最优分片方案的规律通常是:先根据Scaling Laws确定一个固定的 Batch Size,并在已知的(大规模)芯片集群上,找到一种能让这个“较小”的 Batch Size 高效运行的划分方式。
Tensor Parallelism
算子表达式: (此处使用 轴,以便后续与 FSDP 的 轴结合)
在FSDP的 AllReduce 过程中,我们在芯片间传递的是权重。另一种方案是:对模型的 FFN 维度进行分片,并在计算层内部传递激活值——这被称为“1D 模型并行”或 Megatron 分片。这种方式可以实现在单个 Pod 上以更小且高效的 Batch Size 进行训练。下图展示了单矩阵按此方式分片的示例:
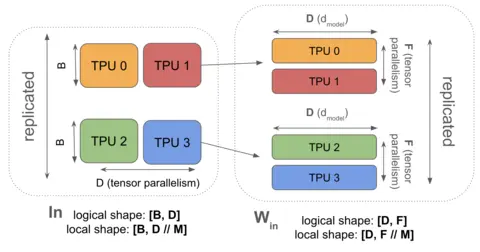
上图是基础张量并行示例。由于我们仅沿 轴对激活值进行分片(不同于 FSDP 沿 轴分片),激活值会在 轴上复制。使用我们的标准算子语法表示为:。由于我们仅在其中一个收缩维上进行分片,通常需要在矩阵乘法之前对激活值执行 AllGather。
如前所述, 意味着我们必须在第一次矩阵乘法前收集激活值。当激活值的数据量小于权重时,这种方式比 ZeRO 分片更高效。 ——通常只有在叠加了一定程度的 ZeRO 分片(以减少收集的数据量)时,这一结论才成立。这也是我们倾向于将 ZeRO 分片与张量并行混合使用的原因之一。
张量并行的一个优雅之处在于它与 Transformer 前向传播中的两个连续矩阵乘法配合得非常好。朴素做法是在每个矩阵乘法后都执行一次 AllReduce。但在上述流程中,我们先执行 ,紧接着执行 。这意味着我们只需在开头 AllGather 输入,在结尾 ReduceScatter 输出,而无需在中间插入额外的 AllReduce。
How costly is this? 我们仅以前向传播建模——这里的反向传播只是各算子的转置。在 1D 张量并行中,我们在第一个矩阵乘法前 AllGather 激活值,在第二个之后 ReduceScatter,每次传输 2 字节(bf16)。让我们推导通信瓶颈的临界点:
为了保持计算密集型(计算成本 > 通信成本),需满足:
例如,在 TPUv5p 上,bf16 格式下的 。因此,张量并行的并行度必须限制在 之内。若利用多个 ICI 轴,通信时间 会按比例 缩减,此时约束条件变为 。
Takeaway: 当张量并行度 时,系统将受通信带宽限制。对于大多数模型,张量并行的有效范围通常在 8 到 16 路之间。
注意,这并不取决于计算精度。 例如在使用 int8 时,TPUv5p 的 比值为 5100(算力翻倍),但同时通信数据量也减半了,这两个“2 倍”因子相互抵消,结论保持不变。
案例分析:
- 对于 LLaMA 3-70B(),在 TPUv5p 上我们可以轻松运行 8 路张量并行,但若增加到 16 路则会遭遇通信瓶颈。实现 8 路模型分片所需的 临界值为 20k。
- 对于 Gemma 7B(),通信瓶颈出现在 19 路张量并行。
Combining FSDP and Tensor Parallelism
Syntax:
FSDP 与TP结合的精妙之处在于:通过在两个轴上同时对 和 进行分片,我们能够同时优化显存占用与计算效率。由于 Batch 维度 沿 轴分片,这减小了模型并行中 AllGather 的数据规模;而 FFN 维度 沿 轴分片,则降低了 FSDP 的通信开销。这种双重分片策略使我们能够支持比前述方案更小的有效 Batch Size(Effective Batch Size)。
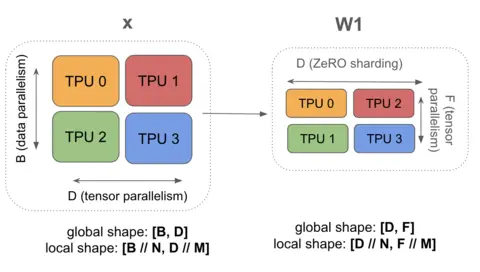
上图是 FSDP + TP的混合并行示意图。与其他案例不同,该方案在各设备间完全不存在模型参数的冗余。
以下是 FSDP + TP 混合并行的完整算法。尽管通信算子较多,但由于激活值已按 Batch 分片,且权重也进行了深度张量分片,所有的 AllGather 和 ReduceScatter 涉及的数据量都显著变小了。
What’s the right combination of FSDP and TP? 一个简单但核心的准则是:FSDP 传输权重,而张量并行传输激活值。这意味着随着总 Batch Size 的缩小(尤其是当增加数据并行度时),张量并行的成本会降低,因为每个分片的激活值规模减小了。
- TP 执行 ,数据量随 增加而减少。
- FSDP 执行 ,数据量随 增加而减少。
因此,结合两者可以进一步压低单副本的最小 Batch Size。我们可以通过以下方式计算 FSDP 和 TP 的最优配比:
设 为分配给 FSDP 的芯片数, 为分配给 TP 的芯片数。该集群切片的总芯片数为 。 和 分别为 FSDP 和 TP 跨越的网格轴数(在 3D 网格中两者之和通常为 3)。我们以前向传播建模(因其单位算力的通信密度最高),累加算法中的通信开销得:
同时,总计算时间为:
为简化分析,我们假设:第一, 和 可以取非整数(只要能满足 即可);第二,假设 轴和 轴的通信可以完全重叠。在第二种假设下,总通信时间为:
在计算临界 Batch Size 之前,先寻找使总通信最小的最优 和 。由于 与 的具体分配无关,最优配置即为使 最小的配比。将 写为关于 和 (固定的系统芯片数)的函数:
由于 随 单调递增,而 随 单调递减,当两者相等时最大值最小。由此求得最优 为:
这个公式非常实用!它告诉我们在给定的 下,FSDP 的最优并行度是多少。代入典型值:(4x4x4 芯片阵列),,,得出 。因此我们会选择 ,这与理论最优值非常接近。
Takeaway: 通常情况下,训练时的最优 FSDP 并行度为 。.
现在回到核心问题:在何种条件下系统进入计算密集区间? 只有当 时成立。定义 为 ICI 的操作强度,简化不等式:
代入 使左侧两项相等,可以得到:
箭头右侧部分,小于号左侧与通信时间成正比,右侧与计算时间成正比。请注意,虽然计算时间随 BatchSize 线性增长(无论是否并行,都是如此),但通信时间随批次大小的平方根增长。因此,计算时间与通信时间的比值也随 BatchSize 的平方根增长:
为了保证该比值大于 1,我们需要满足:
代入近似数值:(3D 网格典型值),得到 。相比于纯数据并行(或 FSDP)要求的 ,混合并行方案将临界 Batch Size 降低了约 8 倍。
Takeaway: 将张量并行与 FSDP 结合,可将单芯片 Batch Size 下限降至 。这使得我们每颗芯片仅需处理约 100 个 Token 即可保持计算密集,比仅使用 FSDP 强了约 8 倍。
下图展示了在典型的 4x4x4 芯片阵列上,最优混合 FSDP+TP 策略的计算通信比,并与仅使用 TP 或仅使用 FSDP 的情况进行了对比。虽然纯 FSDP 并行在非常大的 BatchSize 时仍为主流方案,但在 BatchSize 与芯片数量之比在约 100 到 850 的范围内,需要混合 FSDP+TP 策略才能使计算成为瓶颈。
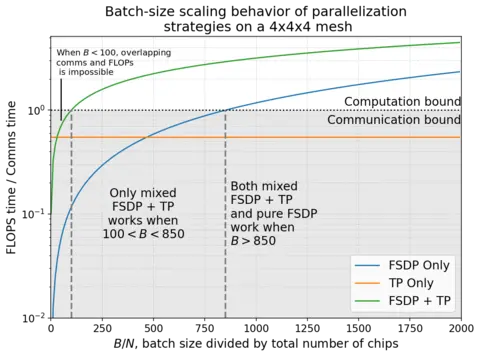
上图表示在 的 TPUv5p 4x4x4 切片上,最优混合 FSDP/TP 的计算通信比。正如我们的推导,张量并行的比例随 Batch Size 固定;理想混合方案随 缩放;而 FSDP 随 缩放。然而,在中等 Batch Size 区间内,只有 FSDP + TP 能实现大于 1 的比例(即计算掩盖通信)。
这是另一个 TPU v5p 16x16x16 集群的示例,展示了不同分片方案下计算时间和通信时间随 Batch Size 的变化关系:
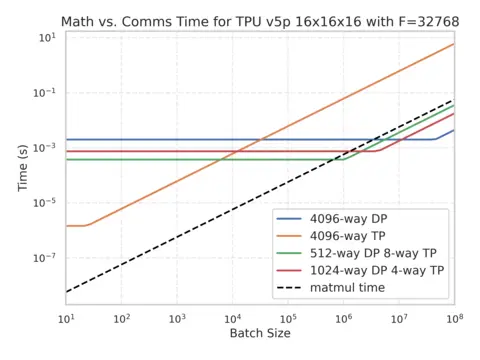 上图是不同并行方案的通信耗时。黑色虚线代表矩阵乘法(计算)所需时间,任何位于此线之上的曲线都处于通信受限状态。我们注意到所有策略在 Batch Size 小于 时都会进入通信受限区,这与我们预期的 基本一致。
上图是不同并行方案的通信耗时。黑色虚线代表矩阵乘法(计算)所需时间,任何位于此线之上的曲线都处于通信受限状态。我们注意到所有策略在 Batch Size 小于 时都会进入通信受限区,这与我们预期的 基本一致。
这里有一个交互式动画可以用来展示不同 batchsize 的总计算时间和通信时间: MLP Rooflines for Llama 3-70B on TPU v5p 16x16x16 (single layer)
可以看到动画里展示的与我们前文推算一致(最小值在 FSDP=256,TP=16 附近),由于每个轴的数量略有不同会有一些波动。
Pipelining
你可能已经注意到,在前几节中我们完全没有提及流水线并行(Pipelining)。流水线并行是 GPU 并行计算中的主流策略,但在 TPU 上其必要性相对较低。简而言之,流水线训练涉及将模型的不同层拆分并部署到多个设备上,在前向和反向传播过程中,在各个流水线阶段(Pipeline Stages)之间传递激活值。
算法逻辑大致如下:
- 在 TPU 0 上初始化数据,并将权重沿模型层维度进行分片(若结合 FSDP 和张量并行,权重表示为 )。
- 在 TPU 0 上执行第一层运算,然后将生成的激活值复制到 TPU 1,以此类推,直到传导至最后一颗 TPU。
- 计算损失函数 及其导数 。
- 在最后一个流水线阶段,计算导数 和 ,然后将 传回前一个流水线阶段,重复此过程直至回到 TPU 0。
以下是一段(可运行的)Python 伪代码。该代码可在 Cloud TPU VM 上执行。虽然其效率不高且不符合生产实际,但它能让你直观感受数据如何在设备间传播。
batch_size = 32
d_model = 128
d_ff = 4 * d_model
num_layers = len(jax.devices())
key = jax.random.PRNGKey(0)
# 假设每一层仅为一个简单的矩阵乘法
x = jax.random.normal(key, (batch_size, d_model))
weights = jax.random.normal(key, (num_layers, d_model, d_model))
def layer_fn(x, weight):
return x @ weight
# 假设层数等于流水线阶段数 (num_layers == num_pipeline_stages)
intermediates = [x]
for i in range(num_layers):
x = layer_fn(x, weights[i])
intermediates.append(x)
if i != num_layers - 1:
# 将激活值移动到下一个设备
x = jax.device_put(x, jax.devices()[i+1])
def loss_fn(batch):
return jnp.mean(batch ** 2) # 构造一个虚假的损失函数
loss, dx = jax.value_and_grad(loss_fn)(x)
for i in range(num_layers - 1, -1, -1):
_, f_vjp = jax.vjp(layer_fn, intermediates[i], weights[i])
dx, dw = f_vjp(dx) # 计算 VJP (向量雅可比积) 以获得梯度
weights[i] = weights[i] - 0.01 * dw # 更新权重
if i != 0:
# 将梯度 dx 传回上一个设备
dx = jax.device_put(dx, jax.devices()[i-1])何时采用 PP? 流水线并行具有多重优势:其阶段间的通信开销极低,这意味着即便在低带宽互连环境下也能训练超大规模模型。这在 GPU 集群中非常有用,因为 GPU 并不像 TPU 那样通过 ICI 实现极高密度的互连。
PP 的缺点、痛点何在? 你可能已经注意到,在上述伪代码中,TPU 0 绝大多数时间都处于闲置状态!它仅在流水线的起始步和最后步执行计算。这种闲置时间被称为流水线气泡(Pipeline Bubble),处理起来非常棘手。通常我们首先通过微批次(Microbatching) 技术来缓解这一问题,即将数据切分为多个小 batch 并行进入流水线,从而在很大程度上提升 TPU 0 的利用率。
第二种方法是精细地重叠前向传播的矩阵乘法 、反向传播的激活值梯度()计算 以及权重梯度()计算 。由于每项操作都涉及 FLOPs 计算,我们可以通过交错执行来完全掩盖气泡。下图来自 DeepSeek-V3 的论文,展示了其“无气泡(Bubble-free)”流水线调度方案:
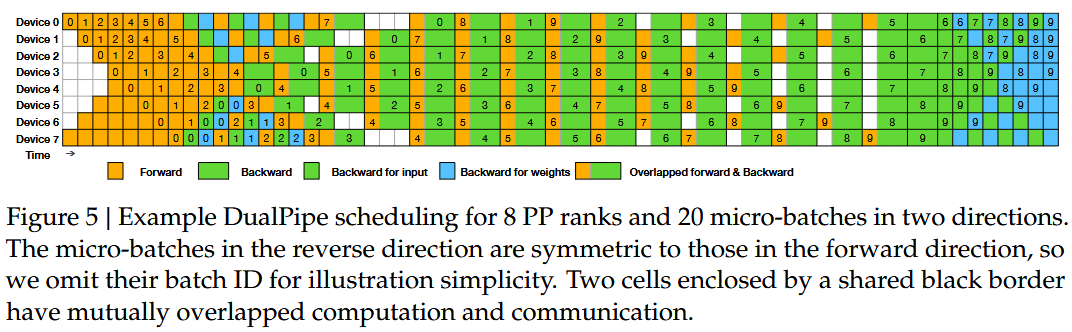
这是 DeepSeek-V3 的 DualPipe 流水线调度方案。橙色代表前向矩阵乘法,绿色代表 矩阵乘法(计算激活值梯度),蓝色代表 矩阵乘法(计算权重梯度)。通过优先处理反向 计算,可以有效避免算力“搁浅”。
由于流水线并行在 TPU(拥有大规模互连 Pod)上的紧迫性较低,我们不会在此深入展开,但理解其核心瓶颈(如气泡效应)对系统架构设计大有裨益。
Scaling Across Pods
TPU 的最大单体切片是包含 8,960 颗芯片(以及 2,240 台主机)的 TPU v5p SuperPod。若要进一步扩展,就必须跨越 DCN 边界。每台 TPU 主机配备一个或多个网卡,通过以太网将主机连接至其他 TPU v5p Pod。如 Section 2. 所述,每台主机拥有约 200Gbps(25GB/s)的双向 DCN 带宽,折合每颗 TPU 约 6.25GB/s 的双向出口带宽。
通常,在跨越单 Pod 进行扩展时,我们会在 ICI 域内部署模型并行或 FSDP,并在 Pod 之间采用纯数据并行。设 为总 TPU 数, 为每个 ICI 互连切片的 TPU 数。跨 DCN 执行 AllReduce 时,可以在 Pod 集合间执行 ring-reduction,其反向传播耗时如下:
与 ICI 不同,DCN 的总带宽随 线性增长,因为随着 ICI 域的扩大,我们会获得更多的网卡。简化后可知,当满足以下条件时,(即计算掩盖通信):
对于 TPU v5p, 的比值约为 71,360。这告诉我们,为了在 DCN 上实现高效扩展,每个 ICI 域(即每个切片)必须承担足够大的 Batch Size,以满足节点的出站带宽匹配。
这个问题有多严峻? 以具体案例说明:假设要在 TPU v5p 上训练 LLaMA-3 70B,总 Batch Size 为 200 万 Token,其 。根据前述分析:
- 张量并行度 最高可达约 。
- 只要 ,即可使用 FSDP。这意味着若要在 3 轴数据并行下训练 200 万 token 规模的 Batch,最多只能使用约 2,400 颗芯片,仅为 TPU v5p Pod 的四分之一。
- 当结合 FSDP 与张量并行时,通信瓶颈临界值降至 ,这允许我们扩展到约 18,000 颗芯片!由于单个 Pod 上限为 8,000 颗芯片,超出部分必须走 DCN。
总而言之,对于 100 万 Batch 的训练,我们有一套成熟的方案: 且 。而当 Batch 增加到 200 万时,我们需要跨越 DCN。如上所述,DCN 的操作强度要求为 71,360,我们只需确保每个 ICI 域(Pod)的 Batch Size 超过此数值即可。在本例中,2 个 Pod 意味着每个 Pod 承担 100 万 Token,单 TPU Batch Size 约为 111,这完全符合要求(虽然略微接近临界值,但在理论上是稳健的)。
Takeaway: 只要每个 Pod 承担的 Batch Size 达到至少 7.1 万个 Token,利用纯数据并行跨多个 TPU Pod 进行扩展就是非常简单直接且高效的。
2. Takeaways from LLM Training on TPUs
- 提升并行度或减小 Batch Size 都会使系统更趋向于受通信限制,因为这两种做法都会减少单芯片分担的计算量。
- 在合理的上下文长度内(约 32k),我们可以将 Transformer 简化建模为一系列 MLP 块的堆叠,并根据每层中两到三个主要矩阵乘法(Matmuls)的分片方式来定义各种并行方案。
- 在训练过程中,我们主要考虑四种并行方案,每种方案都有其特定的带宽和计算需求:数据并行、全分片数据并行、张量并行 以及混合 FSDP + 张量并行。
- 以下是各并行方法的算子表达式:
- 每种策略都存在通信瓶颈的临界点,这取决于单设备的计算与通信比。下表展示了每个 Transformer 层的计算量与通信量(假设 为 FSDP 并行度, 为张量并行度):
- 纯数据并行(Pure DP) 的实用性较低,因为模型及其优化器状态占用的显存字节数约为参数量的 10 倍。这意味着单设备显存很难容纳超过几十亿参数规模的模型。
- 当单分片 Batch Size 小于网络算术强度 时,数据并行和 FSDP 会受通信限制。对于片间互连(ICI),该阈值为 2,550;对于数据中心网络(DCN),约为 71,000。通过增加并行轴可以提升此上限。
- 当张量并行度 时会受通信限制。对于大多数模型,这一临界值在 8 到 16 路之间。该瓶颈与 Batch Size 无关。
- 混合 FSDP + 张量并行 方案允许我们将单芯片 Batch Size 压低至约 个 Token,这一数值低得惊人,极大拓展了强扩展性的边界。
- 跨 Pod 的数据并行要求每个 Pod 承担至少约 7.1 万个 Token 的 Batch Size,否则会受限于 DCN 带宽。
- 基本上,如果你的 Batch Size 足够大或者模型规模较小,并行方案的选择非常简单:直接使用数据并行,或者在跨 DCN 时使用 FSDP + 数据并行。真正具有挑战性且有趣的部分在于两者之间的平衡区域。
3. Some Problems to Work
本节我们以 LLaMA-2 13B 模型为基准进行分析。模型超参数详情如下:
注:LLaMA-2 采用独立的嵌入层(Embedding)与输出投影层(Output Projection),并使用了门控 MLP 块(Gated MLP)。
Question 1: LLaMA-2 13B 究竟包含多少参数?注意:参考 Transformer Math 章节,LLaMA 架构的前馈网络(FFW)包含 3 个核心矩阵:两个升维投影矩阵(Up-projection,含门控)和一个降维投影矩阵(Down-projection)。虽然本节此前忽略了两个“门控”相关 Einsum 矩阵,但其在并行计算中的行为与 完全一致。
- FFW 参数量: (8.5B)
- Attention 参数量: (4.2B)
- 词表参数量: (0.33B)
- 总计: 。符合预期。
Question 2: 假设我们使用 Adam 优化器训练总 Batch Size 为 Tokens 的模型。暂时不考虑并行策略,模型参数、优化器状态和激活值总共占用多少显存?假设:参数以 bf16 存储,优化器状态以 fp32 存储,且每层在三个核心矩阵乘法算子后设置激活值检查点。
- 权重与优化器显存: 对于 bf16 权重(2 字节)和 Adam 的两个优化器状态(fp32,即一阶和二阶矩累计,共 字节),每个参数占用 字节。总开销为 。
- 激活值显存: 根据前述 Transformer 结构图,前两次矩阵乘法后的激活值形状为 ,最后一次为 。在 层中,bf16(2 字节)激活值的总内存占用为 。由于 规模巨大,其余激活值开销可忽略不计。
Question 3: 假设在 TPUv5p 16x16x16 切片上训练 32k 序列长度、总 Batch 为 3M Tokens 的模型。硬件配置和精度要求同上。
- 能否使用纯数据并行? 为什么?
- 能否使用纯 FSDP? 为什么?若使用纯 FSDP,单设备显存占用是多少?(假设仅在 3 个大 FFW 矩阵后进行梯度检查点重算)。
- 能否使用混合 FSDP + 张量并行? 为什么?如果可以,最优的 (FSDP 并行度)和 (TP 并行度)应是多少?单设备存储开销是多少?仅基于 Roofline FLOPs 估算并忽略 Attention,在 40% MFU(模型算力利用率)下,每个训练步(Step)耗时多久?
答案:首先明确基础数据:TPUv5p 16x16x16 切片共有 4,096 颗芯片,总 HBM 容量为 。
- 不能。 纯数据并行要求在每个芯片上完整复制参数和优化器状态。由问题 2 可知其占用约 130GB,已超过单芯片 96GB 的 HBM 上限。
- 显存层面可行,但通信层面受阻。 将 代入计算,总激活值显存约 7.86TB,加上优化器状态总额约 8TB,远低于切片总容量 393TB。然而,4,096 颗芯片在 3 轴并行下,FSDP 保持计算密集的最小 Batch Size 为 Tokens。我们的 3M Batch 低于此阈值,意味着系统将进入通信受限状态。因此结论是不能仅依赖纯 FSDP。
- 可行。 混合并行可大幅降低算术强度门槛。
- 并行度配置: 利用公式 ,代入计算 。实际部署中我们会取 (DP/FSDP), (TP)。
- 显存与耗时: 单设备显存参考前述分片比例。每步耗时计算:。
APPENDIX
A: Deriving the backward pass comms
在前文中,我们将 Transformer 层的前向传播简化为 。那么,我们该如何推导反向传播所需的通信量呢?
这可以从单矩阵乘法 的求导法则自然推导而出:
基于此,我们得到以下公式(设 为 的中间结果):
请注意,上述公式是纯粹的数学表述,尚未涉及任何分片逻辑。反向传播的核心任务就是计算这四个量。为了确定所需的通信量,我们只需查阅并行方案中定义的各变量(, , , )的分片方式,并应用分片矩阵乘法规则即可推导出通信需求。注意, 的分片方式通常与 完全一致。