本文截取自 互联网博客:The Scaling Book 并加入自己的翻译和理解。需要注意,目前翻译版本是适合我本人的阅读习惯和知识基础,如果读者有困惑,可以回到原文查看。
另外需要注意的是,原文章所讨论的主要基于 dense 模型,MoE 模型仅在课后习题 5、6 中有所涉及,作为翻译笔记,我并不会大量补充 MoE 模型在推理时的特征。另外我还补充了原博客 4、6 两个问题的答案,这是我基于对全文内容的理解做出的解答,仅供读者参考。
更佳的渲染请移步博客: All About LLM Inference。
在Transformer上进行推理与训练非常不同。部分原因在于推理增加了一个新的需要考虑的因素:延迟。在本节中,我们将从模型中采样单个新token开始,一直推导到高效地在多个 GPU/TPU 等 accelerator 切片上扩展大型Transformer的全部过程(这将作为推理引擎的一部分)。
1. The Basics of Transformer Inference
在过去,学术研究的重点是“模型训练得好不好”,而不是“模型推理快不快”,研究人员只需要看 loss 曲线下降、benchmark 得分的提升,就能发论文了——你可以在完全不涉及推理效率的情况下完成大量 Transformer 研究工作——LLM loss、multiple choice benchmarks 等都可以在没有合适的 KV cache 或 generation loop 的实现情况下完成研究。由于研究的重点是“模型能力”而非“推理速度”,所以学术代码库中的推理部分往往写得很粗糙,存在大量显而易见却未被利用的优化空间。
- multiple choice benchmarks(多项选择基准测试) 这是指像 MMLU、HellaSwag、ARC 这样的评估任务。在这类测试中,模型不需要真正”生成”文本,而只需要对几个候选答案(比如 A、B、C、D 四个选项)分别计算概率,然后选出概率最高的那个。这种评估方式只需要做一次前向传播,计算每个选项的似然度就够了,完全不需要实现自回归生成的循环。
- generation loop(生成循环) 这是指真正的文本生成过程的代码实现。你需要写一个循环:生成一个 token → 把它加到输入序列末尾→ 再生成下一个 token → 继续循环,直到生成结束标记或达到最大长度。这个循环的实现涉及 KV 缓存的管理、停止条件的判断、采样策略等诸多细节。
采样的概念很简单。我们输入一个序列, Transformer 就会输出 ,即所有可能的下一个 token 的对数概率。我们可以从这个分布中采样并获得一个新 token。将这个 token 追加到原本的 prompt 并重复这个过程,我们就得到了一个 token 序列,它是原始 prompt的延续。
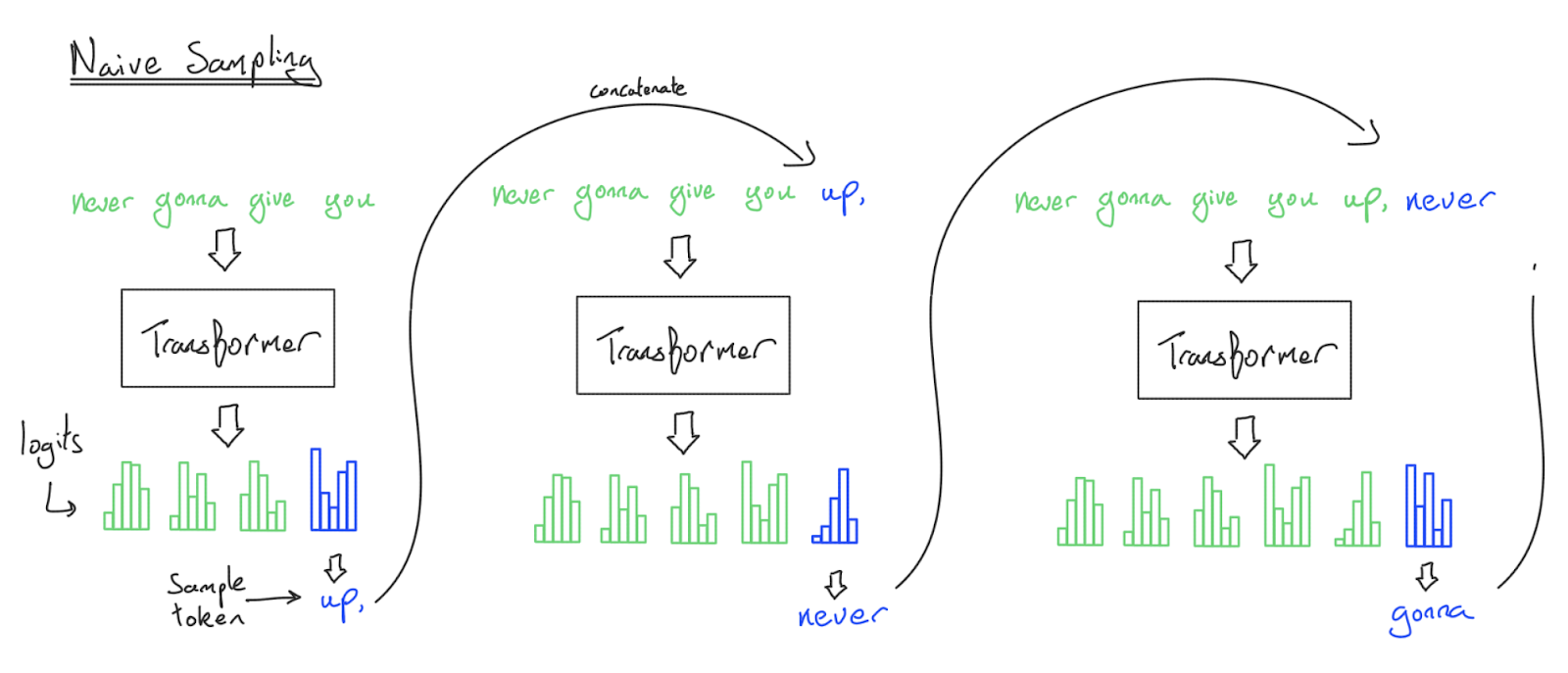
上图是从 Transformer 中采样的 naive 实现。蓝色的 logits 给出一个下一 token 的分布,从而用于采样。注意每一步都需要重新处理整个前缀(包括 input prompt+generated tokens),导致算法的运行时间为 。
虽然这种采样的朴素实现能工作,但我们在实践中从不这样做,因为我们每次生成一个 token 时都在重新处理整个序列。这个算法每生成 个 token,在 FFN上复杂度是 的,在注意力机制上是 的!
如何避免这种情况? 与其每次都做完整的前向传播,不如保存每次前向传播中的一些中间激活值,这样就能避免反复处理之前的 token 序列。具体来说,由于给定的 token 在 attention 计算期间只关注之前的 token,我们可以简单地将每个 token 的 key-value pair 的投影写入一个称为 KV Cache的新数据结构。一旦我们为过去的 token 保存了这些键值投影,未来的 token 就可以简单地计算它们自身的 乘积,而无需对早期 token 执行任何重复的计算。
从 KV Cache 的思想出发,推理可以分为两个关键部分:
- 预填充(Prefill):给定一个长提示词,我们同时处理提示词中的所有 token,并将产生的激活值保存在”KV Cache”中。同时还保存最后一个 token 的 logits。
- 生成(Generation):给定一个 KV 缓存和之前的 logits,我们从 logits 中逐步采样一个 token,将该 token 反馈回 Transformer,并为下一步产生一组新的 logits。同时还需要将该新 token 的 KV activations 追加到 KV 缓存中。重复这个过程,直到遇到一个终止符(
<EOS>token)或达到某个最大长度限制。
下图就是结合了 KV Cache 技术的采样:
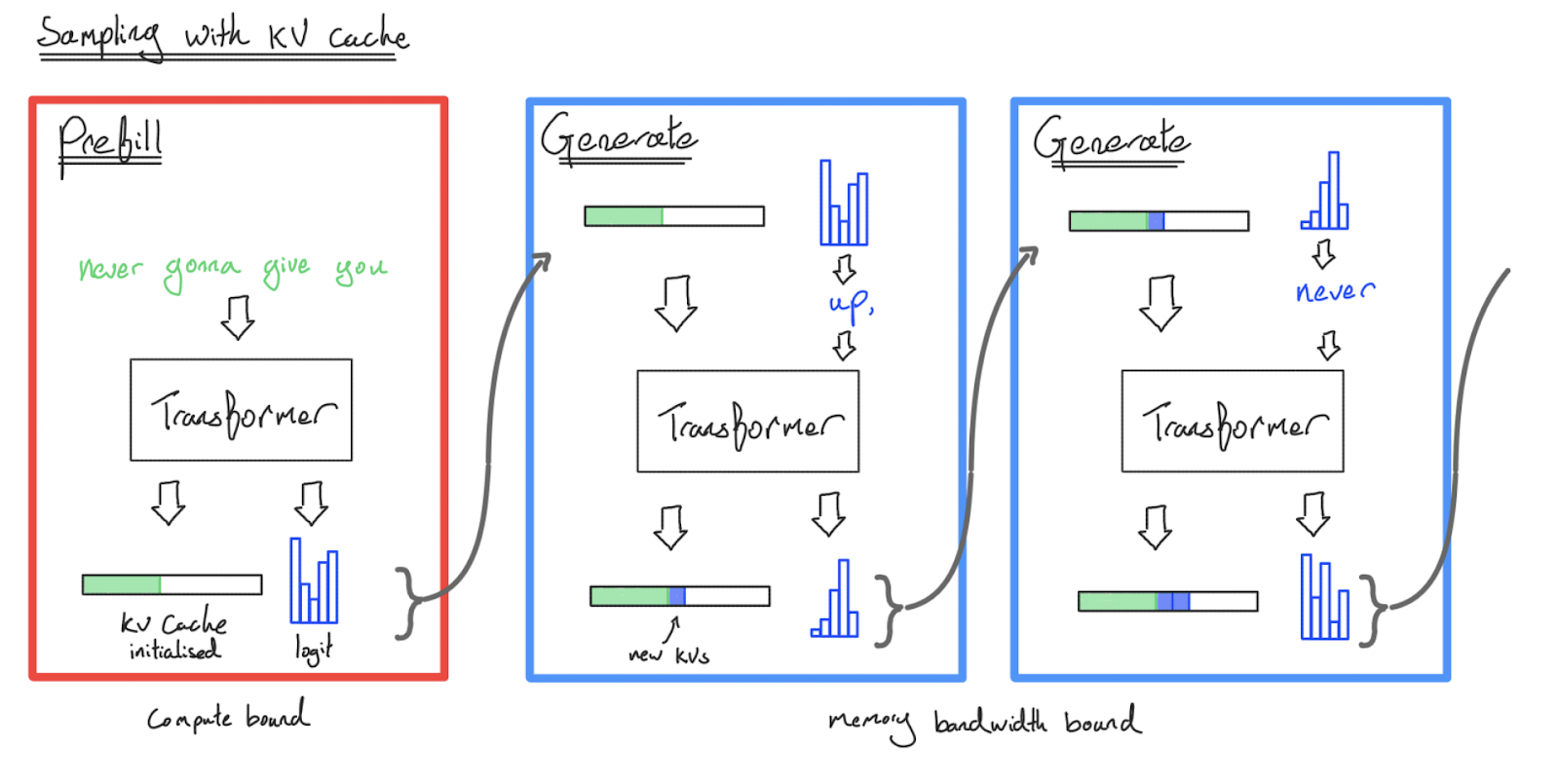
上图中表明,Prefill 阶段处理我们的 prompt 并将每个 token 对应的 key-value 激活值保存在缓存中。Generate 阶段接受这个缓存(以及最后一个 token 的 logits):先采样得到一个新 token,然后将该新 token 传回给模型进行一次前向传播——在这个过程中,新 token 的 query 向量会与缓存中的所有历史 KV 向量进行注意力计算,同时将新 token 的 key-value投影也追加回缓存中。这样一来,在生成 个新 token 时,FFN 部分的总计算量是 的。
一次完整的前向传播:
- 新 token 先经过 embedding 层得到向量表示
- 这个向量依次通过每个 Transformer 层
- 在每一层中,它要经过 attention 和 FFN 两个子模块(注意 FFN 的本质是一个 MLP)
- 最终在最后一层输出新的 logits
通过引入 KV Cache 机制进行采样,我们避免了对历史序列的重复计算,从而将生成 个 token 的累积时间复杂度显著降低:在 FFN 部分降低至 ,在 Attention 部分降低至 。尽管如此,生成一个完整的序列仍然需要经历多次前向传播过程——当你与 Gemini 或 ChatGPT 交互并看到文字流式输出时,其底层逻辑正是如此。通常情况下,每一个新 token 的产生都代表着对超大规模 Transformer 模型的一次独立调用(尽管利用了部分缓存的激活值)。
我们很快就会发现,预填充 (Prefill) 与 生成 (Generation) 阶段在计算特性上存在巨大差异——Transformer 推理本质上是两种性质截然不同的任务。与模型训练过程相比,KV Cache 的引入不仅改变了数据流,还成为了推理复杂性的核心来源。
What do we actually want to optimize?
在深入探讨之前,必须明确推理任务中一个与训练完全不同的维度:延迟 (Latency)。在训练阶段,核心指标是吞吐量 (Throughput)(即单个芯片每秒处理的 token 总数);而在推理阶段,我们必须关注生成 token 的速度,这包括 首字延迟 (Time To First Token, TTFT) 以及 单 token 延迟 (Per-token Latency)。根据应用场景的不同,优化侧重点也各异:
- 离线批处理推理 (Offline Batch Inference):常见于模型评估或大规模合成数据生成。此类场景主要关注推理的总成本(即吞吐量),对单个样本的响应延迟并不敏感。
- 聊天界面与流式任务 (Chat Interfaces / Streaming Tasks):这类场景要求在大规模部署时兼顾低成本与用户体验,必须具备极低的 TTFT,且 token 生成速度需超过人类的阅读效率。
- 边缘侧推理 (Edge Inference):例如在个人笔记本上运行
llama.cpp。其目标通常是满足单用户的极低延迟体验,且往往面临严苛的硬件算力与内存带宽限制。
虽然最大化硬件利用率(如 MFU)对于降低成本和 TTFT 依然至关重要,但与训练不同的是,高利用率并不总是等同于更好的用户体验。在算子加速、系统调度以及模型架构等多个层面,我们经常需要在延迟、吞吐量、上下文长度甚至模型质量之间进行复杂的权衡 (Trade-off)。
到目前为止,我们通常将 Transformer 视为一系列 FFN 的堆叠。虽然从 FLOPs 和内存占用的角度看这种理解是合理的,但它不足以精确刻画推理的底层机制。你会发现推理任务对性能瓶颈的容忍度远低于训练:推理时的有效 FLOPs 通常较低,Batch Size 的提升空间有限,且对延迟极其敏感。KV Cache 的存在也极大地增加了内存管理的复杂性。回顾 Transformer 前向传播 的过程,其计算负载主要由以下三部分组成:
- 线性算子 (Linear Operations):包括 MLP 层的权重矩阵(, )以及注意力机制中的 QKV 投影和输出投影()。其底层实现逻辑涉及从 HBM (显存/高带宽内存) 中读取权重参数和激活值张量,在运算核心中执行矩阵乘法,最后将结果写回 HBM。
- 点积注意力 (Dot-product Attention):这需要从 HBM 读取缓存的 Key-Value 投影以及当前的 Query 激活值,执行内积运算与 Softmax 操作,最后将注意力加权后的结果写回 HBM。
- 辅助算子 (Everything Else):包括 Layer Norm、激活函数、Token 采样、KV Cache 更新以及位置编码等。虽然这些操作也会消耗 FLOPs,但其计算开销通常被上述主算子掩盖,或通过 算子融合 (Operator Fusion) 技术合并处理。
在接下来的几节中,我们将在 Prefill 和 Generate 的情景下,查看上述的每一类算子的各自性能瓶颈。
Linear operations: what bottlenecks us?
从底层逻辑看,无论是在 MLP 模块还是在 Attention 模块中,所有的线性算子(Linear Operations)在数学本质上是完全一致的。它们的 算术强度 高低直接取决于 Batch Size。为了深入理解这一点,我们可以分析一个典型的矩阵乘法:将 的激活值矩阵与 的权重矩阵相乘。这涵盖了从庞大的 MLP 映射(, )到较小的注意力投影()的所有场景。在执行此 MatMal 算子时,加速器必须从 HBM (高带宽内存) 将这两个数组加载到 MXU (矩阵运算单元) 中,完成乘加运算后,再将结果写回 HBM。我们可以通过以下公式量化其计算耗时()与通信耗时():
现代加速器(如 TPU/GPU)通常支持计算与加载的并行流水线化,以实现两者重叠。因此,若要使算子进入 计算受限 (Compute-bound) 状态,必须满足 。以 TPU v5e 为例,代入公式可得:
等式右侧为 TPU v5e 硬件本身的算术强度,约为 ,可以理解为每读取一个字节的数据的时间,可以进行 240 次浮点数运算。
在实际的大模型推理场景中,隐藏层维度 和 通常远大于 ( 通常在 500 以下,而 往往超过 10,000)。基于此,我们可以对分母的访存项进行简化:。简化后的不等式揭示了一个关键结论:
这里的 即为 临界批大小 (Critical Batch Size)。
当引入量化技术或改变计算精度时,临界 Batch Size () 会相应调整。例如,若将权重参数量化至 int8 或 fp8,则单次权重加载的数据量减半, 也随之降低至原来的 1/2;反之,若在 int8 或 fp8 精度下执行计算(通常硬件算力会翻倍), 则会增加 2 倍。进一步地,定义参数与激活值的比特比 ,以及硬件算术强度 ,则实际临界 Batch Size 为 。
核心结论: Transformer 中的矩阵乘法算子处于计算受限状态的充要条件是:每个芯片承载的 Token Batch Size 必须大于 。该临界值可表示为硬件算术强度 与精度系数 的乘积(即 )。在使用 BF16 精度时,TPU v5e 的 约为 240 个 token,而 NVIDIA H100 则约为 280 个 token。
在训练阶段,由于在极大的 Batch 上复用相同的权重,矩阵乘法始终保持极高的算术强度。这种高算术强度的特性能自然延伸至推理的预填充(Prefill)阶段,因为用户输入的 Prompt 通常包含数百甚至数千个 Token。 正如前文所述,TPU v5e 的硬件算术强度为 240。因此,当长度超过 240 个 Token 的序列在 bf16 精度下输入稠密模型(Dense Model)时,系统将自动进入计算受限状态,从而实现高效运行。对于极短的 Prompt,技术上可以通过 Batching 方式合并多个请求以提高利用率,但在实际部署中这通常并非必要。
核心结论: 在预填充(Prefill)阶段,所有矩阵乘法操作基本都处于计算受限状态。因此,优化目标应单纯聚焦于最大化硬件利用率或模型算力利用率(MFU),这直接等同于优化单芯片吞吐量(成本)和首字延迟(TTFT)。除非 Prompt 极短,否则针对 Prompt 级别的 Batching 往往会增加延迟,而对预填充吞吐量的提升却微乎其微。
然而,在解码生成(Generation)阶段,由于计算步骤之间存在严格的串行依赖(Sequential Dependency),每个请求在每一时刻只能进行单个 Token 的前向传播。这意味着,若要获得理想的算力利用率,唯一的途径是通过 Batching 机制将多个并发请求组合在一起,在 Batch 维度上实现并行。虽然我们后续会详细讨论,但事实上在不破坏延迟体验的前提下大规模合并并发请求极具挑战。因此,在生成阶段让硬件 FLOPs 达到饱和(Saturation)要困难得多。
核心结论: 在生成阶段,总体的 Token Batch Size 必须大于 ,才能使线性/FFN层算子进入计算受限状态(例如 TPU v5e 在 bf16 下需 240 个并发 Token)。由于生成过程是逐 Token 串行执行的,这迫使我们必须进行多请求并发调度(Continuous Batching),而这在工程实践中难度极大。
值得关注的是这个临界值的量级: 240 的生成 Batch Size 意味着需要 240 个并发请求同时生成,且对于稠密模型而言,这意味着需要维护 240 个独立的 KV Cache。在实际生产环境中,除了离线批处理(Bulk Inference)场景外,极难达到如此高的并发度。相比之下,在预填充阶段一次性处理超过 240 个 Token 则是常规操作(尽管在涉及稀疏性模型时需要额外优化)。
补充说明:该数值会随量化策略和硬件规格的变化而改变。 GPU/TPU 通常在低精度下提供更高的算力峰值。例如,如果采用 int8 权重但维持 bf16 计算精度,由于访存压力减半,临界 Batch Size 会降至 120。而如果激活值和权重均采用 int8(全量化),由于 TPU v5e 在 int8 x int8 模式下的峰值算力提升至 400 TOPS,临界 Batch Size 将重新回升至 240。
What about attention?
当我们考虑 attention 算子时,分析过程会变得更加复杂,这主要是因为必须考虑 KV Cache 的显存访问开销。以标准的 MHA 中的单个 Head 为例,在典型的 Flash Attention 算子融合实现中1,其底层数据流向及计算逻辑如下:
- 从 HBM 中读取形状为 的查询向量 激活值。
- 从 HBM 中读取 KV Cache,即一对形状为 的张量(键向量 与值向量 )。
- 执行 矩阵乘法,计算量为 FLOPs。得益于 Flash Attention 技术,我们无需将形状为 的注意力分数矩阵回写至 HBM。
- 执行注意力权重与 的乘法( matmul),计算量同样为 。
- 将最终生成的 结果张量回写至 HBM。
综合上述步骤,我们可以推导出多头注意力的算术强度公式:
在预填充(Prefill)阶段,由于执行的是自注意力计算,此时 ,公式简化为 。这一特性非常有益,意味着预填充阶段 Attention 的算术强度与序列长度 呈线性关系 。因此,只要 Prompt 序列长度达到一定规模,Attention 算子就能够轻松进入计算受限状态。
然而在解码生成(Generation)阶段,由于每次只处理一个 Token,其序列维度极小()。此时 和 维度在分子分母中抵消,公式可近似为:
这一结果揭示了一个严峻的挑战:在生成阶段,我们无法通过增加 Batch Size 等手段来提升 Attention 的算术强度。即便需要加载庞大的 KV Cache 历史数据,所执行的有效计算量(FLOPs)却微乎其微。因此,在生成阶段的 Attention 计算几乎始终处于访存带宽受限(Memory Bandwidth-bound)状态。
核心结论: 在预填充阶段,只要序列长度合理(通常大于 480 Tokens),Attention 往往是计算受限的;而在生成阶段,算术强度极低且固定,导致系统始终受限于访存带宽。
从底层逻辑来看,为什么会这样?根本原因在于,模型线性层之所以能实现 compute-bound,是因为模型参数(这些是访存负担最重的部分)在 Batch 维度的所有请求中是共享且复用的。然而,KV Cache 是每个请求私有的。增加 Batch Size 意味着必须同步加载等比例增加的 KV Cache 数据。除非对模型架构进行激进调整,否则这一访存特征决定了其难以摆脱 memory bound。
这也意味着,一旦 KV Cache 占用的显存访存量与模型参数的访存量不相上下,继续增加 Batch Size 带来的吞吐量提升将呈现边际效用递减(Diminishing Returns)。这种收益递减的严重程度取决于单个序列中模型参数与 KV Cache 字节数的比例,即 。考虑到 ,该比例大致取决于模型隐藏层扩展维度 与序列长度 的比值。此外,该瓶颈还受到 KV Cache 的架构优化(如 GQA、MLA 等旨在缩小 KV Cache 的技术,后文将详细展开)的影响。
如何理解 BatchSize 提升带来的边际递减?
1. 核心概念定义
在推理的 生成阶段(Generation),每一轮迭代需要从 HBM 加载到计算单元的数据主要由两部分组成:
权重参数 (Params Memory): 模型本身的权重(如 等)。
- 特点: 静态、共享。无论你的 Batch Size () 是 1 还是 256,每一层都要加载一次完整的权重。
KV 缓存 (KV Cache Memory): 存储的历史 Token 的 Key 和 Value 张量。
特点: 动态、私有。每个请求都有自己独立的 KV Cache。如果 增加,KV Cache 的数据量会线性增加。
2. 为什么增加 Batch Size 通常能提升吞吐量?
在 Batch Size 较小时,性能受限于权重加载。
因为权重很大,而计算量很小(只算一个 Token),此时硬件大部分时间在等权重从内存传到计算核心。当我们增加 时,同一份加载到核心的权重被多个 Batch Item 复用。
算术强度 (Arithmetic Intensity): 。
只要 远小于 ,分母就近似为常数。此时 越大,算术强度越高,吞吐量提升越明显。
3. 什么是 “Comparable”(量级可比)?
当 增加到一定程度,使得 的大小接近或超过了模型权重的物理大小时,情况就变了。
我们可以写出生成阶段每一轮迭代的总访存量 ():
所谓 “Comparable”,就是指等式右边的第二项不再能被忽略,甚至开始占据主导地位:
初期: (权重是瓶颈,增加 有奇效)。
中期 (Comparable): (两者共同决定带宽消耗)。
后期: (KV Cache 变成带宽消耗的绝对主力)。
4. 为什么会出现“收益递减” (Diminishing Returns)?
吞吐量(Throughput)的简化公式是:
将 代入:
当 很小时: 吞吐量 。由于分母近似不变,吞吐量随 线性增长。
当 极大(KV Cache 占据主导)时: 吞吐量 。
结论: 当 KV Cache 的访存开销与参数量可比时,吞吐量曲线会从“快速上升”转为“平缓”,最终进入平台期。此时,无论你如何增加 ,硬件带宽都被源源不断的、无法复用的 KV Cache 数据占满了,你增加多少 Batch, 维度的并行收益就被等比例增加的访存耗时抵消了。
5. 总结
这句话的本质是提醒开发者:Batching 并不是万能药。在长序列( 很大)或大并发( 很大)的场景下,KV Cache 会吞噬掉原本用来平摊权重的带宽红利。这就是为什么工业界需要 GQA(分组查询注意力) 或 MLA(多头潜在注意力) 的原因——它们的本质目的都是为了减小 KV Cache 的体积,从而推迟“收益递减”临界点的到来。
Theoretical estimates for LLM latency and throughput
基于前文的数学建模,我们可以为推理中单步用时的优化推导出清晰的性能边界。在生成阶段,当 Batch Size 较小时(这是生产环境的常态),我们可以假设 Attention 和 MLP 块均处于Memory Bandwidth-bound 状态,从而得出单步迭代延迟的下界:
相应地,单位时间内的 Token 吞吐量下界为:
随着 Batch Size 的进一步增加,MLP 层涉及的计算量(FLOPs)将超过参数加载的耗时,系统进入计算受限状态。因此,更具普适性的单步步时计算公式(公式 1)如下:
在上述公式中,左侧的 Attention 组件由于其算术强度极低,几乎永远不会达到计算瓶颈,因此无需考虑算力 Roofline 限制。该公式是进行 AI 基础设施能力封底估算的利器。
案例分析: 假设我们使用包含 16 颗芯片的 TPU v5e(4x4 拓扑)运行一个 30B 参数的稠密模型,采用 int8 权重和 bf16 计算。已知上下文长度为 8192,每个 Token 的 KV Cache 为 100 kB。当 Batch Size 为 4 时,合理的延迟下界是多少?当 Batch Size 增加到 256 时又如何?
解答: 在 int8 量化下,模型参数占用空间为 30 GB。根据给定规格,每个请求的 KV Cache 总量为 。16 颗 TPU v5e 的总带宽为 ,总算力峰值为 。
- 当 Batch Size = 4 时,系统处于极致访存受限状态,步时约为 。
- 当 Batch Size = 256 时,MLP 块已进入计算受限区间,步时由 Attention 访存项和 MLP 计算项组成:。
由此可见,推理性能在吞吐量与延迟之间存在明显的权衡(Tradeoff)。小 Batch 能够提供极低的延迟,但硬件利用率低下;大 Batch 虽然导致单步延迟增加,却能显著提升单位成本的计算效率。下图展示了 PaLM 系列模型在不同配置下的延迟-吞吐量 Pareto Frontier 表(图源 ESTI paper):
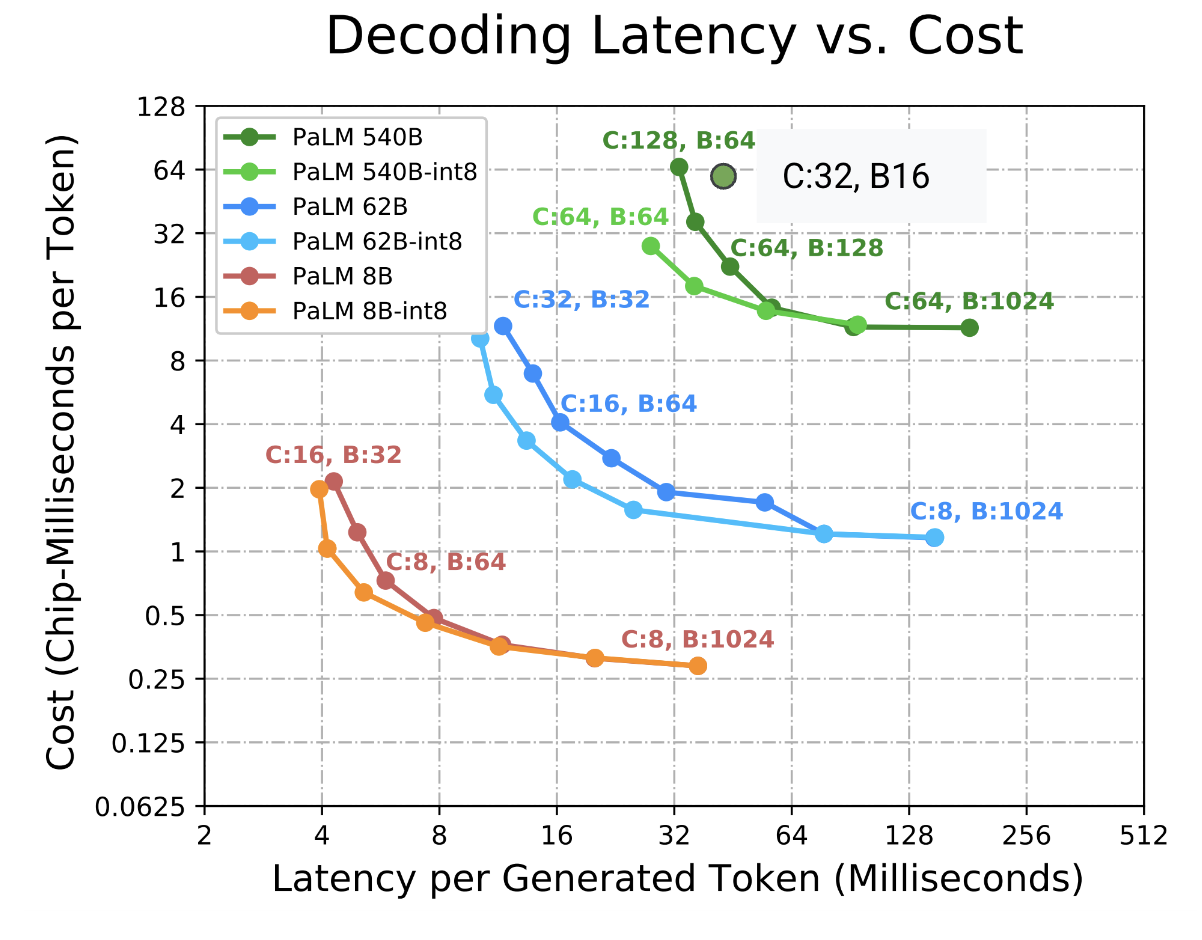 图表解析: 该曲线描绘了多个 PaLM 变体的成本(即吞吐量的倒数)与延迟之间的关系。芯片数量(C)和 Batch Size(B)的调整会使系统在 pareto frontier 上移动,除了绿点 (PaLM 540B 的 C: 32 B:16),那里可用内存阻碍了设置足够的 batch size,导致吞吐量下降。值得注意的是,吞吐量通常在 Batch Size 达到 240(硬件算术强度临界点)后趋于平缓。此外,采用 int8 权重量化可以显著优化延迟-吞吐量的帕累托最优状态,但并不能提高硬件理论上的最大吞吐量。
图表解析: 该曲线描绘了多个 PaLM 变体的成本(即吞吐量的倒数)与延迟之间的关系。芯片数量(C)和 Batch Size(B)的调整会使系统在 pareto frontier 上移动,除了绿点 (PaLM 540B 的 C: 32 B:16),那里可用内存阻碍了设置足够的 batch size,导致吞吐量下降。值得注意的是,吞吐量通常在 Batch Size 达到 240(硬件算术强度临界点)后趋于平缓。此外,采用 int8 权重量化可以显著优化延迟-吞吐量的帕累托最优状态,但并不能提高硬件理论上的最大吞吐量。
除了利用 Batch Size 这一调节杠杆外,当我们受到 HBM 容量限制时,往往倾向于采用更大规模的硬件拓扑(集群规模),以便容纳更大的 Batch。
核心结论: 若业务目标是最大化生成吞吐量,应尽可能提升单芯片的 Batch Size。当单芯片 Batch Size 超过硬件算术强度阈值 (通常为 120 或 240)时,硬件利用率最高。为了达到这一数值,可能需要扩展计算拓扑。相反,较小的 Batch Size 适合在牺牲吞吐量的前提下追求极致的响应延迟。
现实生产中实际上无法达到之前的理论分析
上述分析主要基于理想模型。在工程实践中,性能表现往往无法完全贴合标准的 Roofline 折线,原因包括:
编译器的局限性: 我们假设 HBM 访存操作能与算力执行完美流水化重叠(Overlap),但在 XLA 等编译器生成底层算子指令时,这种理想状态难以百分之百实现。
分片通信开销: 对于采用张量并行(Tensor Parallelism)的模型分片,XLA 往往难以实现芯片间互联(ICI)通信与矩阵乘法 FLOPs 的高效重叠。在分布式推理中,当 Batch Size 超过 32 后,通信延迟往往开始显著拖累线性层的表现。
非理想重叠的收益: 即便 Batch Size 超过了理论 Roofline 的临界点,由于访存与计算重叠的不完美,继续增加 Batch 往往仍能带来一定的吞吐量增益。尽管如此,上述公式仍是极佳的性能预测启发式方法。
What about memory?
我们已经深入探讨了带宽(Bandwidth)与算力(FLOPs),但尚未详细分析显存占用。在推理阶段,由于 KV Cache 这一新数据结构的引入,内存占用的逻辑与训练阶段截然不同。本节以 LLaMA 2-13B 模型为例,展示推理过程中的内存占用特征:
| 超参数 | 含义 | 数值 |
|---|---|---|
| L | 层数 (num_layers) | 40 |
| D | 模型维度 (d_model) | 5,120 |
| F | 前馈层维度 (ffw_dimension) | 13,824 |
| N | 查询头数量 (num_heads) | 40 |
| K | KV 头数量 (num_kv_heads) | 40 |
| H | 每个头的维度 (qkv_dim) | 128 |
| V | 词表大小 (num_embeddings) | 32,000 |
在推理过程中, 显存的主要消耗者首先是模型权重参数。具体计算如下:
| 参数项 | 计算公式 | 占用大小 (Bytes) |
|---|---|---|
| FFW 参数 | (3 为了 GeLU 和输出投影所乘) | |
| 词表参数 | ||
| Attention 参数 |
将上述各部分求和,总计约为 13B (8.5e9 + 4.2e9 + 0.3e9) 个参数,与模型名称相符。在训练阶段,若采用 bfloat16 权重配合 float32 优化器状态(Optimizer State),显存占用可能达到 100GB 左右;如果进一步考虑梯度检查点(Gradient Checkpoints)存储的激活值,显存需求甚至会攀升至数 TB。
推理阶段的显存需求有何不同? 推理时,我们仅需维护一份权重副本。以 bfloat16 为例,占用空间仅为 26GB(实际部署中常通过量化技术进一步压缩)。此时,无需维护优化器状态或梯度信息。由于不需要执行反向传播,推理过程无需缓存中间激活值。特别是在 Flash Attention 的底层实现中,通过算子融合避免了大型注意力矩阵(Score Matrix)在显存中的实例化存储(Materialization),使得预填充和生成阶段的激活值占用极低。例如,在处理 8k Token 的预填充时,单个激活张量仅需 。对于更长上下文,可通过将预填充任务拆分为多个微批次(Micro-batches)执行,从而避免显存溢出。而在生成阶段,每次仅处理少量 Token,激活值的开销几乎可以忽略不计。
什么是 materialization?
在标准的注意力机制(Attention)计算中,我们需要计算 。如果序列长度是 ,那么这个得分矩阵(Score Matrix)的大小是 。
常规做法(Materializing): 算子会先计算出这个巨大的 矩阵,把它从计算单元(寄存器/SRAM)写回到显存(HBM)中。后续执行 Softmax 和与 相乘时,再重新从 HBM 中读取。这个“写回再读取”的过程,就是把逻辑上的矩阵变成了内存中实实在在的数据,即“物化/实例化存储”。
Flash Attention 的做法(Avoid Materializing): 它通过 Tiling(分块) 技术,在芯片内部的 SRAM(高速缓存)中直接完成 、Softmax 和与 的乘法。由于整个过程是分块流式处理的,那个巨大的 矩阵从始至终都没有完整地存在过。它只存在于逻辑计算中,而没有在显存里占据空间。
推理阶段显存消耗的核心差异在于 KV Cache。KV Cache 存储了历史所有 Token 的 Key 和 Value 投影值,其规模随序列长度 线性增长。对于 个 Token,其总占用空间计算公式如下:
其中 为 Head 维度, 为 KV 头数, 为层数,倍数 2 代表同时存储 Key 和 Value。
KV Cache 的增长速度极快。在 LLaMA-13B 模型中,若采用 bf16 精度处理长度为 8,192 的单条序列,其 KV Cache 占用高达:
这意味着仅需 4 个并发请求,其 KV Cache 占用的显存就会超过模型参数本身的规模(26GB)! 需要指出的是,LLaMA 2 尚未针对长上下文场景进行 KV Cache 优化(在 LLaMA 3 中,通过将 的数量大幅削减,这一情况得到了显著缓解),但该案例清晰地表明:在进行内存估算或延迟建模时,绝对不能忽视 KV Cache 的影响。
Modeling throughput and latency for LLaMA 2-13B
为了量化性能边界,我们考察在由 8 颗 TPU v5e 组成的计算集群(提供 128 GiB HBM 总显存、6.5 TiB/s 总带宽以及 1600 TFLOPS 总算力)上,以理想并行效率运行 LLaMA 2-13B 生成任务的表现。我们将 Batch Size 从 1 扩展至前文推导的硬件临界算术强度点()。
| Batch Size (批大小) | 1 | 8 | 16 | 32 | 64 | 240 |
|---|---|---|---|---|---|---|
| KV Cache 显存 (GiB) | 6.7 | 53.6 | 107.2 | 214.4 | 428.8 | 1608 |
| 总显存占用 (GiB) | 32.7 | 79.6 | 133.2 | 240.4 | 454.8 | 1634 |
| 理论单步延迟 (ms) | 4.98 | 12.13 | 20.30 | 36.65 | 69.33 | 249.09 |
| 理论吞吐量 (tokens/s) | 200.61 | 659.30 | 787.99 | 873.21 | 923.13 | 963.53 |
分析数据可见,尽管增加 Batch Size 能够提升系统总吞吐量,但边际效用递减(Diminishing Returns) 现象非常显著。受限于 128 GiB 的 HBM 总容量,当 Batch Size 超过 16 时,系统将发生显存溢出(OOM)。若要达到 以实现硬件利用率最大化,所需的显存容量将比现有配置高出一个数量级。虽然可以通过扩展硬件拓扑(增加芯片数量)来优化延迟,但单芯片的吞吐量增益已触及物理瓶颈。
假设我们在保持总参数量不变的前提下,通过架构优化(例如引入 1:5 的 Grouped-Query Attention, GQA)将 KV Cache 的体积压缩至原来的 1/5。这意味着 40 个 Query Head 将共享 8 个 KV Head。优化后的性能预测如下:
| Batch Size (批大小) | 1 | 8 | 16 | 32 | 64 | 240 |
|---|---|---|---|---|---|---|
| KV Cache 显存 (GiB) | 1.34 | 10.72 | 21.44 | 42.88 | 85.76 | 321.6 |
| 总显存占用 (GiB) | 27.34 | 36.72 | 47.44 | 68.88 | 111.76 | 347.6 |
| 理论单步延迟 (ms) | 4.17 | 5.60 | 7.23 | 10.50 | 17.04 | 52.99 |
| 理论吞吐量 (tokens/s) | 239.94 | 1,429.19 | 2,212.48 | 3,047.62 | 3,756.62 | 4,529.34 |
在缩减 KV Cache 规模后,虽然吞吐量的增长曲线仍存在边际效用递减趋势,但单芯片的理论吞吐量能够持续扩展至 。在 128 GiB 的 HBM 限制下,我们现在能够轻松支持 的并发度,且在所有 Batch 配置下,迭代延迟均得到了显著优化。简而言之,延迟表现、最大吞吐量以及最大承载并发量均获得了跨越式提升。事实上,后续的 LLaMA 迭代完整采用了这一优化思路——例如 LLaMA-3 8B 便配置了 32 个 Query Head 与 8 个 KV Head。
核心结论: 除模型参数量外,KV Cache 的规模是决定推理最终性能的关键因素。在实际部署中,必须通过架构设计(如 GQA)与运行时优化(如 PagedAttention 等)相结合,将其维持在可控范围内。
2. Tricks for Improving Generation Throughput and Latency
自从 Transformer 的奠基性论文《Attention is All You Need》问世以来,学术界与工业界开发了大量旨在提升模型运行效率的技术,其中绝大多数优化手段都指向了 KV Cache。从底层逻辑来看,缩减 KV Cache 的显存占用具有多重收益:它允许在不牺牲延迟的前提下,进一步提升生成阶段的 Batch Size 和上下文长度上限;同时,它也显著减轻了 Transformer 周边系统(如请求调度与缓存管理机制)的工程实现负担。在暂不考虑模型生成质量损耗的前提下,主流的优化路径如下:
分组查询注意力 (Grouped-Query Attention, GQA): 在 Attention 机制中,我们可以通过削减 KV 头(KV Heads)的数量,让多个 Query 头共享同一组 KV 对。在极端情况下(即 Multi-Query Attention, MQA),所有 Query 头可以共享同一个 KV 头。相比于标准的多头注意力(MHA),这种方法按 Query 与 KV 的比例( Ratio)等比例地缩减了 KV Cache 的显存占用。研究表明,模型性能对这种架构改变表现出较强的鲁棒性(Insensitivity)。
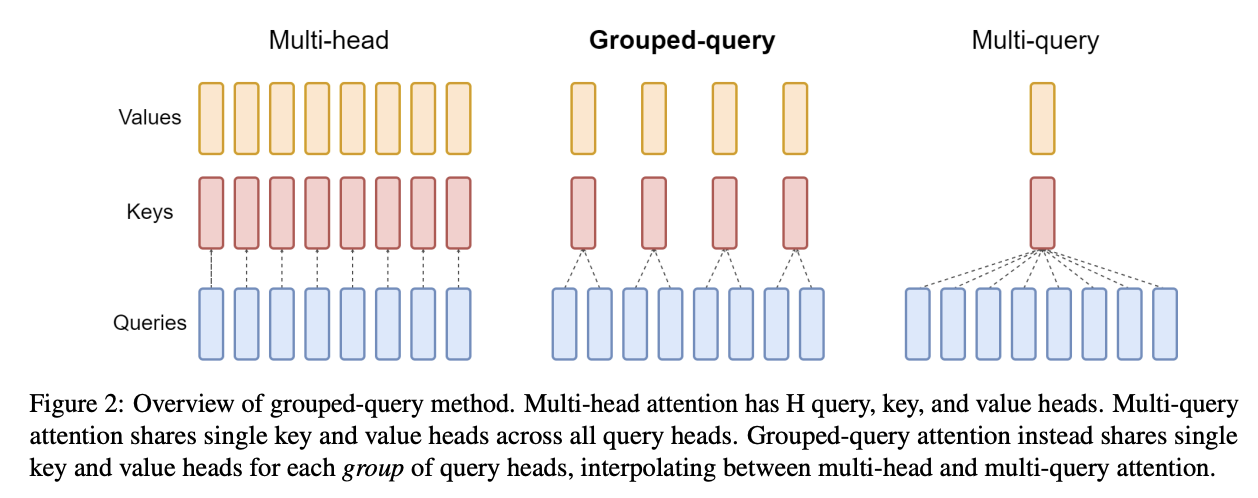
此外,减少 KV 数据量有效地提升了注意力计算的算术强度,因为单次访存加载的 KV 数据现在支撑了更多的计算任务。
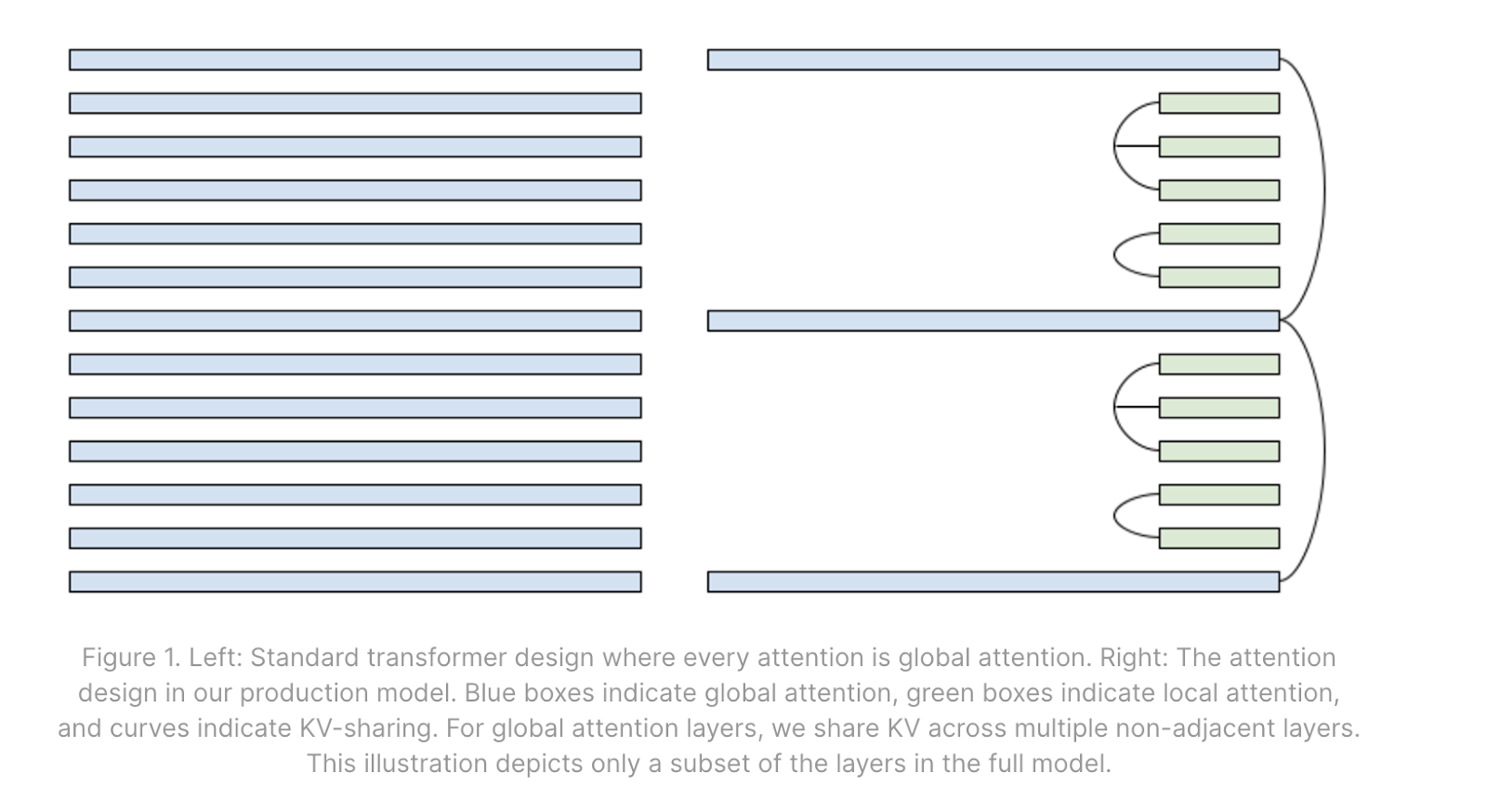
引入局部注意力层 (Local Attention Layers): 局部注意力机制将 Token 关注的上下文窗口限制在一个固定范围内。在训练和预填充阶段,这表现为将注意力权重矩阵掩码处理为对角带状(Diagonal Strip) 而非传统的下三角矩阵。这实际上为局部注意力层设定了 KV Cache 的容量上限。通过在模型中交替配置局部注意力层与全局注意力层,当处理超过局部窗口长度的上下文时,总体的 KV Cache 规模将显著减小。
跨层 KV 共享 (Cross-layer KV Sharing): 模型可以通过特定拓扑或学习模式,在不同层之间共享相同的 KV Cache。虽然这种方式确实降低了显存占用,并在提升 Batch Size、优化请求缓存及离线存储方面具有优势,但由于共享的 KV Cache 可能需要在不同计算阶段多次从 HBM 中读取,它并不一定会直接缩减单步迭代的耗时(Step Time)。
量化 (Quantization): 推理过程对参数和 KV Cache 的数值精度通常具有较高的容忍度。通过将权重和 KV Cache 量化至低比特表示(如 int8, int4, fp8 等),我们可以显著节省显存带宽。这不仅降低了达到算力受限(Compute-bound)状态所需的临界 Batch Size,还释放了更多显存以承载更高的并发。量化的另一大优势在于,即使模型最初并非针对量化进行训练,通常也可以通过后训练量化(Post-Training Quantization, PTQ)有效实施。
不规则 HBM 读取与分页注意力 (Ragged Reads & PagedAttention): 在前文的理论计算中,我们假设为每个 KV Cache 分配了完整的 8k 上下文空间。但在实践中,完全没有必要从显存读取整段 KV 缓存。由于不同请求的长度分布极不均匀且通常远小于模型的最大上下文上限,我们可以通过优化算子内核(如 Flash Attention 的变体)来仅读取非填充(Non-padding) 部分的 KV 缓存。
分页注意力(PagedAttention) 是这一思路的进阶方案。它借鉴了操作系统的虚拟内存页表(Page Tables) 机制来管理 KV Cache,从根本上消除了显存碎片和不必要的填充开销。虽然这增加了推理引擎运行时的复杂性,但它确保了每个 Batch 仅消耗其实际所需的内存。作为一种纯粹的运行时优化(Runtime Optimization),它与模型架构本身是解耦的。
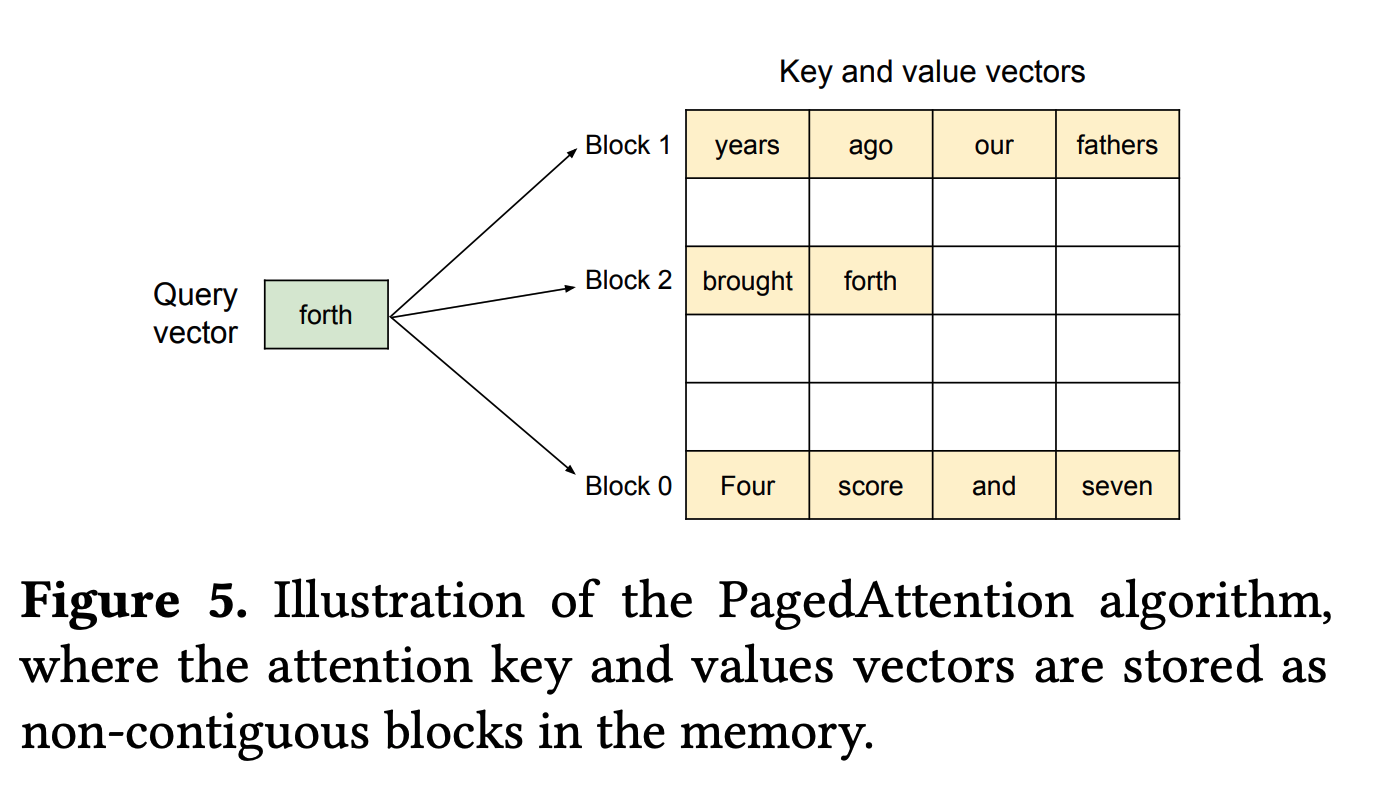
如何理解 PagedAttention?
这张图示源自 PagedAttention 的开创性论文(vLLM 框架的核心技术),它形象地展示了如何借鉴操作系统中的虚拟内存管理思想来解决大模型推理中的显存瓶颈。
1. 图示元素深度拆解:从逻辑到物理
该图展示了在生成阶段(Generation),单个 Token 如何与历史 KV Cache 进行交互:
查询向量 (Query Vector): 图中左侧绿色的
forth是当前正在处理的第 10 个 Token。在生成当前位点时,它产生的 Query 向量需要与前面 9 个 Token 的 Key/Value 向量进行点积计算。非连续的物理块 (Non-contiguous Blocks): 观察右侧黄色部分的存储结构,KV Cache 被划分为固定大小的“块”(Block)。请注意块的物理索引:Block 1 Block 2 Block 0。
- 在传统方案中,这 9 个 Token 必须在显存中占据一段**连续(Contiguous)**的空间。
- 而在 PagedAttention 中,物理存储可以是离散的。例如,“Four score and seven” 存储在物理索引为 0 的块中,而接下来的文本可能被分配到了物理索引为 1 的块,甚至地址空间并不相邻。
块的填充与预留: 每个块(Page)被设定为容纳 4 个 Token。图中 Block 2 仅存储了
brought和forth两个 Token,还有两个空位。这种设计允许系统以更细的粒度(Page-level)来按需申请内存。
2. 底层逻辑重构:为什么要“分页”?
这张图背后隐藏的核心技术逻辑是为了解决 显存碎片化 (Memory Fragmentation):
消除预分配浪费 (Internal Fragmentation): 在没有 PagedAttention 之前,系统通常会根据模型的最大上下文长度(如 8k 或 32k)为每个请求预先分配一段连续显存。如果用户只写了 10 个 Token,剩下的空间也会被“锁死”,无法给其他请求使用。图中展示的块化管理,使得系统只需为当前已生成的 Token 分配块,极大地提升了显存利用率。
动态增长机制: 当 Block 2 的 4 个位置填满后,PagedAttention 会从显存池中随机捞取一个新的空闲物理块(如 Block 5),并将其映射到逻辑序列的末尾。这种逻辑连续、物理离散的映射关系,是由底层的 Block Table (块表) 维护的,类似于操作系统内核中的页表。
3. 技术价值:它如何改变推理效能?
结合我们之前学习的内容,PagedAttention 的引入直接改变了公式中的变量:
突破 Batch Size 上限: 由于消除了预分配导致的显存空洞(碎片),同一个 GPU 现在可以容纳比以前多出 2x - 4x 的并发请求(Batch Size)。这意味着推理引擎能更容易地达到我们之前提到的临界 Batch Size ,从而让硬件进入**计算受限(Compute-bound)**的高效状态。
显存按需加载: 图注提到的“avoid loading or storing more memory than we need to”,本质上是减少了 HBM 访存压力。在执行 Attention 算子时,CUDA Kernel 会根据索引只加载实际存在的块,而不需要读取大段的 Padding(填充)数据。
PagedAttention 不仅仅是一个内存管理技巧,它实际上重新定义了 LLM 推理系统的调度逻辑。它使得“连续批处理(Continuous Batching)”成为可能,因为不同长度的请求现在可以像操作系统中的进程一样,动态地共享和回收物理显存页。
延伸阅读
- Continuous Batching in vLLM:从 static batching 的缺陷推导迭代级调度(continuous batching),并解释它与 PagedAttention 的“强绑定”关系。
宏观视角: 综上所述,通过组合使用这些 KV Cache 优化手段,相较于传统的 MHA Transformer,我们可以将 KV Cache 的体积缩减一个数量级以上。这直接推动了 Transformer 模型整体推理成本(Cost-per-token)实现数量级的优化。
3. Distributing Inference Over Multiple Accelerators
到目前为止,我们仅简化讨论了单芯片的性能边界。本节将沿袭第 5 章关于训练的讨论框架,深入探讨将推理任务扩展至多加速器芯片时的不同分布式策略及其权衡。与之前相同,我们将分别针对预填充 (Prefill) 和解码生成 (Generation) 两个阶段进行分析。
Prefill
从 Roofline 模型来看,预填充阶段的计算特征与模型训练几乎完全一致,因此训练中的绝大多数分布式技术和权衡逻辑在此均适用——包括张量并行 (Megatron-style Tensor Parallelism)、序列分片 (Sequence Sharding,适用于长上下文场景)、流水线并行 (Pipelining),甚至全分片数据并行 (FSDP) 都是可行的方案。唯一的区别在于预填充完成后,需要将生成的 KV Cache 留存在显存中以便后续解码。与训练类似,增加芯片数量可以提供更高的峰值算力(FLOPs/s),从而有效降低首字延迟(TTFT),但也会引入额外的通信开销,可能导致单芯片的有效吞吐量下降。
预填充阶段的分片通则: 在处理单条序列的预填充(无 Batch 维度)时,通常遵循以下规则:
-
模型分片 (Model Sharding): 优先采用模型并行(张量并行)。初始扩展时,模型并行效果最好,直到触及芯片间互联(ICI)带宽瓶颈。正如 Section 5 所述,对于单轴并行,当并行度达到 左右时(通常为 4-8 路分片),通信将成为瓶颈。
-
序列并行 (Sequence Parallelism): 在模型并行达到瓶颈后,应引入序列并行(类似于数据并行,但在序列维度进行切分)。虽然序列并行在计算 Attention 时会引入额外的通信需求,但在长上下文场景下,这种开销通常在可接受范围内。与训练阶段相同,我们可以通过算子融合(如 Megatron 中的 Collective Matmuls 或 Ring Attention)来实现通信与计算的流水线重叠。
核心结论: 在预填充阶段,任何在训练中行之有效的分布式策略均可沿用。基本策略是:先进行模型并行直至触及 ICI 瓶颈,随后引入序列并行。
Generation
解码生成阶段的分布式架构比预填充复杂得多。首先,生成阶段很难获得极大的 Batch Size(需要累积大量并发请求);其次,生成阶段对延迟的要求更为苛刻。这些因素导致生成阶段通常处于极致的访存受限 (Memory-bound) 状态,且对通信开销极度敏感,这大大限制了分片策略的选择:
- FSDP 无法应用: 由于性能瓶颈在于将参数和 KV Cache 从 HBM 加载到计算单元(MXU),而芯片间互联(ICI)的带宽比 HBM 慢数个数量级,我们绝不希望通过 ICI 传输模型权重。分布式推理的核心原则是“移动激活值,而非模型权重”。因此,类似于 FSDP 这种需要在计算前收集权重的方案在生成阶段是完全不可行的。如果在推理时错误地保留了 FSDP 配置,通常会导致性能出现量级上的衰减。
- 纯数据并行失去意义: 纯数据并行会在每颗芯片上复制完整的参数,这并不能加速参数的加载过程。相比之下,更好的做法是运行多个独立的模型副本(即在多个服务器上以较小的 Batch Size 运行),在模型层面实施数据并行通常是效率最低的选择。
- 序列分片失效: 由于解码时序列维度 ,序列分片已失去了物理基础。
数据并行与模型副本的区别
1. 为什么“纯数据并行”在推理中是“无效”的?
在训练中,DP 是为了平摊梯度聚合的开销;但在推理的生成阶段(Generation),瓶颈是 HBM 访存带宽。
访存效率: 如果你有 4 颗芯片跑 DP,每颗芯片都在独立加载 100% 的模型权重来处理各自的 个请求。正如你所理解的,这种方式完全没有减轻单芯片的访存压力。
通信浪费: 传统的 DP 框架(如 DDP)通常包含一些同步机制或全局管理逻辑。在推理这种对延迟(Latency)极度敏感的场景下,这些额外的软件栈开销不仅没带来加速,反而可能增加首字延迟。
结论: 在生成阶段,DP 并没有通过“并行”缩短单次迭代(Step Time)的时间。
2. “独立模型副本 (Independent Replicas)” vs. “数据并行 (DP)”
作者建议“运行多个独立副本(Spinning up multiple servers)”,这在分布式系统设计中被称为 Replication(副本扩展),它与 DP 的区别如下:
维度 纯数据并行 (Data Parallelism) 独立模型副本 (Independent Replicas) 系统抽象 视为“一个”分布式模型实例在运行。 视为“多个”完全独立的单机服务。 请求调度 调度器需要管理跨芯片的 Batch 切分和同步。 负载均衡器(LB)简单地将请求分发给不同节点。 容错性 一个芯片故障可能导致整个 DP 组挂掉。 单个副本挂掉不影响其他副本,可用性更高。 软件栈 需要复杂的分布式通信库(如 NCCL)。 只需最简单的单机推理后端(如单卡 vLLM)。 作者的真实意图: 如果你无法通过模型并行(Model Parallelism)来拆分权重(因为通信太慢),那就不要折腾复杂的分布式 DP 框架。直接起 8 个独立的进程,每个进程只看自己的显卡,反而更高效且简单。
3. 真正被推崇的替代方案:模型并行 (Model Parallelism)
这段话背后其实是在对比 DP 和 模型并行(MP/TP)。这是解决生成瓶颈的“正确答案”:
模型并行 (MP/TP): 将 100GB 的模型拆分到 8 颗芯片,每颗芯片只负责加载 12.5GB 权重。
性能提升: 虽然 变大了,但每颗芯片加载的数据量变小了。8 颗芯片的 HBM 带宽被聚合起来服务同一个请求(或同一批请求),从而大幅缩短了 中的访存项,降低了单 Token 的生成延迟。
4. 总结:高性能推理的架构演进路径
在构建大规模推理集群时,通常遵循以下优先级策略:
第一步 (MP): 先在 ICI(高速芯片间互联,如 NVLink)带宽允许的范围内实施 模型并行。目的是利用聚合带宽降低延迟,让单芯片吞吐量达到瓶颈。
第二步 (Replication): 当模型并行度达到 ICI 瓶颈(如 8 路张量并行已经占满单机 NVLink)后,如果还需要更高的总吞吐量,则通过 运行多个独立副本(或多个 MP 组) 来进行水平扩展。
核心逻辑: > 只有模型并行(MP)能帮你“加载参数更快”(因为每人只 load 一部分);
而“独立副本”是为了在不增加复杂度的前提下,线性堆叠吞吐量。
“数据并行 (DP)”这种介于两者之间的中间态,在推理场景下显得既不节能也不增效。
因此,稠密模型生成阶段的分布式方案基本仅剩下模型并行(Model Sharding)及其变体。与预填充类似,最基础的操作是实施模型并行(激活值全量复制,MLP 权重在隐藏层维度切分)。通常在 4-8 路并行时会触及 ICI 瓶颈。然而,由于生成阶段受限于内存带宽,我们实际上可以突破这一常规瓶颈来进一步优化延迟。
关于生成阶段 ICI 瓶颈的特殊说明: 在训练阶段,我们追求达到 compute-bound,因此 Roofline 模型关注的是 ICI 通信耗时何时超过 FLOPs 计算耗时。但在生成阶段,如果性能受限于模型加载的内存带宽,我们可以通过增加模型并行度(Model Sharding)来利用更多芯片的 HBM 总带宽,从而降低延迟,并且保证单芯片吞吐量的损失却相对较小。在这种场景下,算力(FLOPs)不再是瓶颈,我们真正需要担心的是 ICI 通信耗时是否超过了参数加载耗时。 我们可以推导在不成为瓶颈的前提下,能承担的最大模型并行度 :
此处 为从 HBM 加载权重所需的耗时, 为芯片间同步激活值所需的通信耗时, 为 HBM 带宽与 ICI 带宽之比(即 ,在 TPU v5e/v6e 上约为 8)。例如,若隐藏层维度 ,Batch Size ,理论上我们可以实施高达 64 路的模型并行,而不会对总吞吐量产生严重负面影响(前提是 KV Cache 也能实现同等程度的分片,这在实践中具有挑战性)。
在注意力层中,我们同样采用 Megatron 方式在 Head 维度对 和 进行模型分片。由于 KV 权重相对较小,将其全量复制通常比超出 路(KV 头数)的分片方案更具成本效益。
核心结论: 生成阶段的唯一分布式选择是模型并行的变体。其核心目标是移动体积较小的激活值,而非庞大的模型参数或 KV Cache。当 Batch Size 较大时,模型并行度受限于算力-互联瓶颈();当 Batch Size 较小时,可以通过提高模型并行度来压低延迟。若所需的并行路数超过了 KV head 数,还可以考虑在 Batch 维度对 KV Cache 进行进一步分片。
Sharding the KV cache
除了模型参数外,我们还需要对另一个核心数据结构进行分片——即 KV Cache。 同样地,基于性能考量,我们应尽可能避免在不同芯片间复制缓存,因为访存延迟是注意力机制性能的核心瓶颈。在实现层面上,我们首先沿袭 Megatron 方案,在 Head 维度对 KV Cache 进行分片。然而,这种方式的并行度受限于 (KV 头数)。对于 KV 头数较少的模型(如采用 GQA 或 MQA 架构的模型),在 Head 维度分片潜力耗尽后,我们会进一步引入 Batch 维度的分片。逻辑表示为 。通过这种多维分片方式,KV Cache 可以在大规模集群中实现完全分布式存储。
的含义
在分布式张量分片(Tensor Sharding)中,这种表示法描述了一个五维张量如何在硬件网格(Device Mesh)上进行分布:
- :代表 Key 和 Value。在推理引擎中,通常将 K 和 V 存储在同一个连续张量中,或者作为一个 Pair 处理。
- :Batch 维度在 轴上的分片。这意味着 Batch 被切分到了设备网格的 轴。例如,如果你有 8 个 GPU 组成 的网格(),那么 Batch 就会被分给这 4 个 轴设备处理。
- :Sequence Length(序列长度)。通常在生成阶段,这个维度表示历史 Context 的长度。
- :KV 头维度在 轴上的分片。对应 Megatron-style 的模型并行(Tensor Parallelism),即不同的 KV Heads 被分布在不同的芯片上。
- :Head Dim(每个头的大小),通常是 64, 128 等固定值。
之所以这样设计,是因为当模型采用 GQA(分组查询注意力)或 MQA 时,KV 头数 非常小。如果仅在 维度分片,并行度(Degree of Parallelism)很快就会达到上限。因此,必须引入 Batch 维度分片 () 来进一步平摊显存和带宽压力。
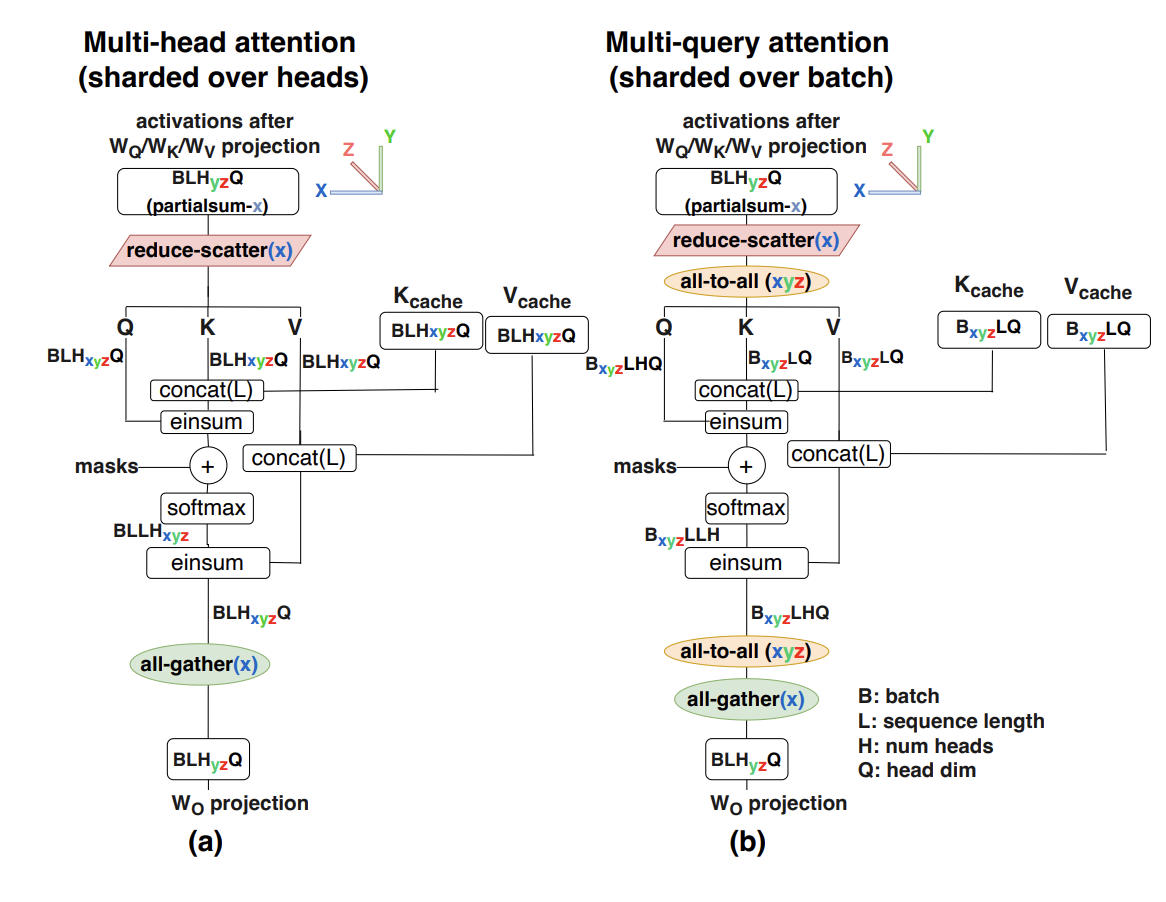
上图对比了两种注意力机制的分片方案:(a) 采用纯模型分片的多头注意力 (MHA);(b) 结合 Batch 分片的多查询注意力 (MQA)。值得注意的是,在方案 (b) 中,为了使激活值(Activations)能够与 Batch 分片后的 KV Cache 进行运算,我们需要额外引入两次 AllToAll 通信算子,将激活值在模型并行域和 Batch 并行域之间进行转换。
这种分片方案的开销在于每一层注意力机制都会引入两次 AllToAll 通信:第一次是将 (Query)激活值转换至 Batch 分片布局,以匹配 KV Cache 的物理分布并执行计算;第二次则是将 Batch 分片后的注意力输出转换回纯模型并行布局,以便后续算子的执行。
对这两次 All2All 加深理解
这两次 AlltoAll 通信直觉上很好理解,但是具体做了什么还需要仔细思考——这两次通信操作本质上是为了解决 “计算逻辑”与“数据存储”之间的布局冲突。
第一次
All-to-All:激活值布局转换(布局对齐)
- 冲突点:在前向传播中,线性层(如 )通常是按模型并行(Model Parallelism)切分的,即 激活值在所有 GPU 上是按 Head 维度 分片的(对应图中 )。
- 需求:但我们的 KV Cache 是按 Batch 维度 分片存储在不同 GPU 上的。
- 动作:为了让某个 GPU 上的 Query 能找到对应的 Key 和 Value,必须进行一次
All-to-All。它将数据从“按 Head 分片”转变为“按 Batch 分片”。- 这就是通常说的 Dispatch(分发) 阶段。它把原本在物理上不属于该芯片的特定 Batch 对应的 向量,从其他芯片“拉”过来。
第二次
All-to-All:结果回归模型布局
- 冲突点:Attention 计算完成后,得到的输出张量仍然是按 Batch 维度 分片的(对应图中 )。
- 需求:随后的输出投影层()和接下来的 MLP 层通常期望输入是按 模型/头维度 分片的。
- 动作:因此,需要第二次
All-to-All将结果从“Batch 布局”切回“模型布局”。- 这对应 Combine(组合) 阶段,将各个 GPU 上计算出的局部 Batch 结果重新按照模型并行的逻辑组织起来。
不过不要理解错误,这里并不是 Micro-batching,Micro-batch 通常用于 Pipeline Parallelism(流水线并行),通过时间上的重叠来提高利用率。而是 SPMD 分片,属于 SPMD (Single Program, Multiple Data) 并行模式。大的 Batch 不是被“拆解成 micro-batch 顺序处理”,而是被物理地 Sharded 存储在不同的 HBM 颗粒中。
以下是完整的算子执行逻辑。该算法展示了在 和 两个并行维度上的注意力机制实现细节。为方便表述,我们定义 (即每个 KV 头对应的 Query 头数)。
- 激活值准备: 为上一层输出的激活值(在当前维度未分片)。
- KV Cache 状态: 与 矩阵已按照 Batch 维度执行分布式存储。
- 计算 Query: 通过线性映射生成分片后的 :
- 布局转换 (Comm 1): 执行 AllToAll 算子,将 从模型并行域重新分布到 Batch 并行域:
- 维度重塑: 调整 的张量形状以匹配多头/分组注意力计算:
- 计算 Attention Score: 执行 与 的矩阵乘法:
- 归一化: 在序列维度执行 Softmax:
- 聚合 Value: 与 矩阵相乘得到注意力输出:
- 布局转换 (Comm 2): 执行第二次 AllToAll 算子,将输出结果从 Batch 并行域切回模型并行域:
- 维度还原: 重塑输出张量:
- 输出投影: 执行 线性映射:
- 同步: 通过 AllReduce 完成最终结果的跨芯片同步:
尽管该流程较为复杂,但其核心优势在于:虽然引入了激活值层面的通信开销,但由于激活值的数据量远小于固定的 KV Cache,这种交换极大地减少了加载 KV Cache 所需的内存带宽消耗。
- 序列分片 (Sequence Sharding): 当 Batch Size 极小或上下文长度(Context Length)极长时,我们可以选择在序列维度对 KV Cache 进行分片。在这种模式下,我们需要承担跨分片聚合注意力结果的集合通信开销。具体流程通常包括先对 激活值执行 AllGather,随后采用类似于 Flash Attention 的逻辑在各分片间累加计算结果。
4. Designing an Effective Inference Engine
在前文中,我们分别探讨了如何对预填充(Prefill)和解码生成(Generate)操作进行独立的性能优化与分片。然而,在实际应用中,我们需要设计一个推理引擎,将这两类操作有机结合,并根据业务需求在延迟与吞吐量的帕累托前沿(Pareto Frontier)上寻找最优平衡点。
最直观的方法是采用“批处理切换”模式:即先执行一波预填充 Batch,随后连续执行该 Batch 的生成操作。
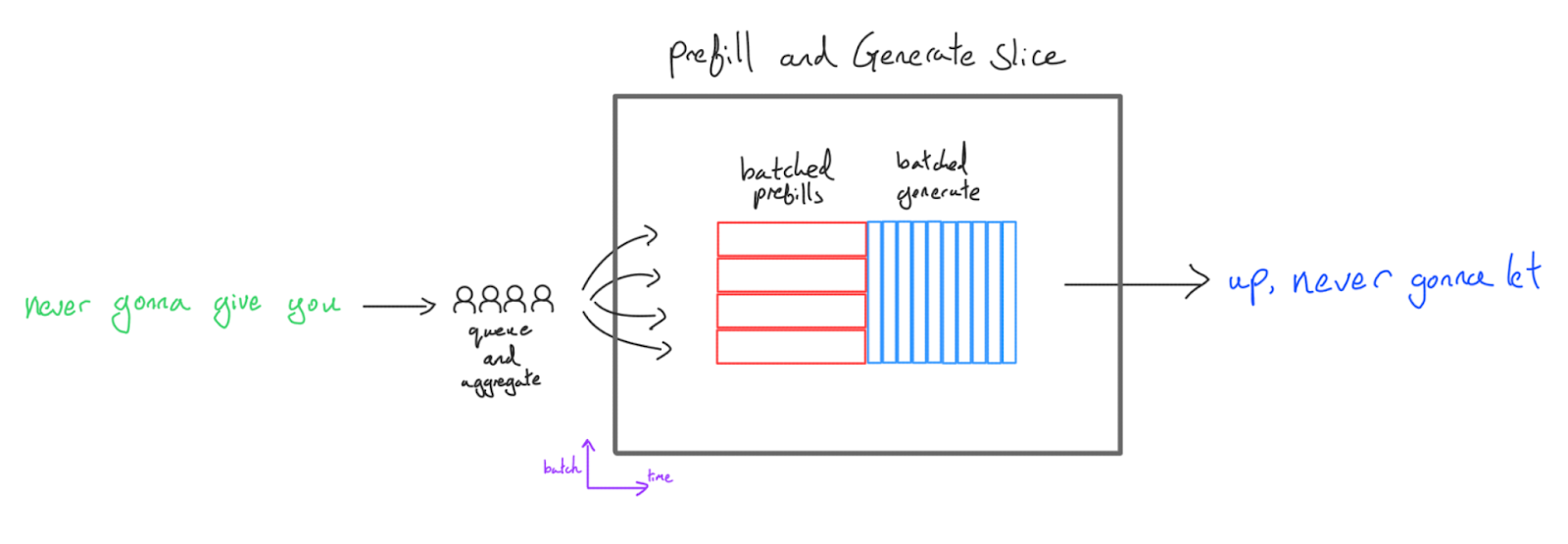
在这种基础配置下,系统会对请求进行聚合(Aggregation)。服务器在运行一组预填充任务和调用生成函数之间交替切换,直到该 Batch 内的所有序列全部完成生成。
这种方案虽然实现简单,通常作为大多数推理框架的初始版本,但其底层机制存在诸多局限性:
- 延迟表现极差: 该方案将预填充与生成的 Batch Size 强行耦合。在大 Batch 预填充时,首字延迟 (TTFT) 显著增加,因为必须等待 Batch 内所有请求完成预填充后,用户才能看到第一个输出 Token。反之,若为了降低 TTFT 而缩小 Batch Size,则会严重损害生成阶段的吞吐量。
- 短序列受限于长序列:短序列会比长序列更早完成,生成长度不一会导致“气泡”产生。短序列请求完成后,对应的 Batch Slot 会空置,导致硬件算力浪费。随着 Batch Size 和生成长度的增加,这种效率损失会进一步加剧。
- 预填充存在无效填充 (Padding):所有的预填充请求必须被填充到当前 Batch 内的最长序列长度,导致了大量的无效计算。虽然技术上存在优化方案,但受限于 XLA 编译器对静态形状(Static Shapes)的依赖,跳过这些无效 FLOPs 在工程实现上极具挑战。
- 分片策略冲突: 预填充与生成被迫共享相同的硬件拓扑与分片方案(除非在显存中维护两份权重副本)。这在性能调优上非常不利,例如生成阶段通常需要更高程度的模型分片(Model Sharding)来对齐内存带宽瓶颈,而预填充则更侧重于计算饱和。
因此,这种方法仅推荐用于边缘应用(通常只需服务单一用户,且硬件的算术强度较低),或用于模型开发早期的原型快速迭代。
一种更优的演进方案是交织(Interleaved)配置。其核心思想是在预填充阶段采用 (此时该请求的 token 数 可以很大,算子依然是计算受限的,且能保证合理的延迟),但在生成阶段将多个请求合并处理。
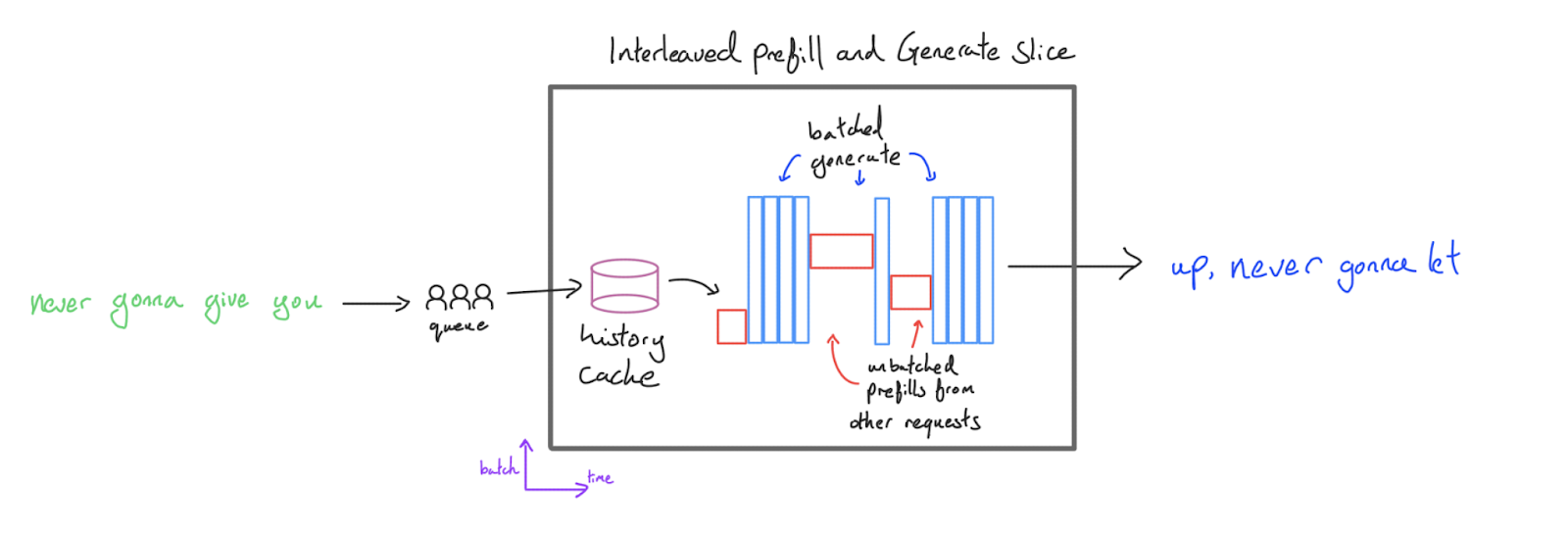
这种配置通过规避批处理预填充来优化 TTFT,同时维持了生成阶段的高吞吐量。它非常适合离线批处理(Bulk Generation)或基准测试(Evaluation)等以吞吐量为核心目标的场景。推理引擎的任务编排器(Orchestrator) 可以配置为:一旦生成队列出现空位,立即插入新的预填充请求。由于预填充不再与其他请求强行成批,也避免了序列填充(Padding)带来的算力浪费。
然而,交织配置的主要缺陷在于:当服务器执行某个请求的预填充时,由于该操作会占据绝大部分计算资源,导致同一机器上所有其他正在进行生成的请求被迫暂停。用户 A 的解码过程会被新进入的用户 B 的预填充操作所阻塞。这意味着虽然 TTFT 得到了改善,但 Token 的生成速率会出现明显的抖动(Jittery),平均生成速度变慢。在实时交互应用中,这种不连贯的生成体验是不可接受的——其他用户的预填充操作进入了当前请求的总延迟关键路径(critical path)。
为了彻底解决上述冲突,我们引入了分离式推理(Disaggregated Serving) 架构。虽然单服务器可以完成全部推理流程,但从延迟优化的角度看,将预填充和生成任务分配给两组不同的算力集群(TPU/GPU)更为理想。在这一架构中,预填充服务器负责生成初始 KV Cache,并通过高速网络将其传输至解码生成服务器;后者负责将多个 KV Cache 聚合进行高并发解码。
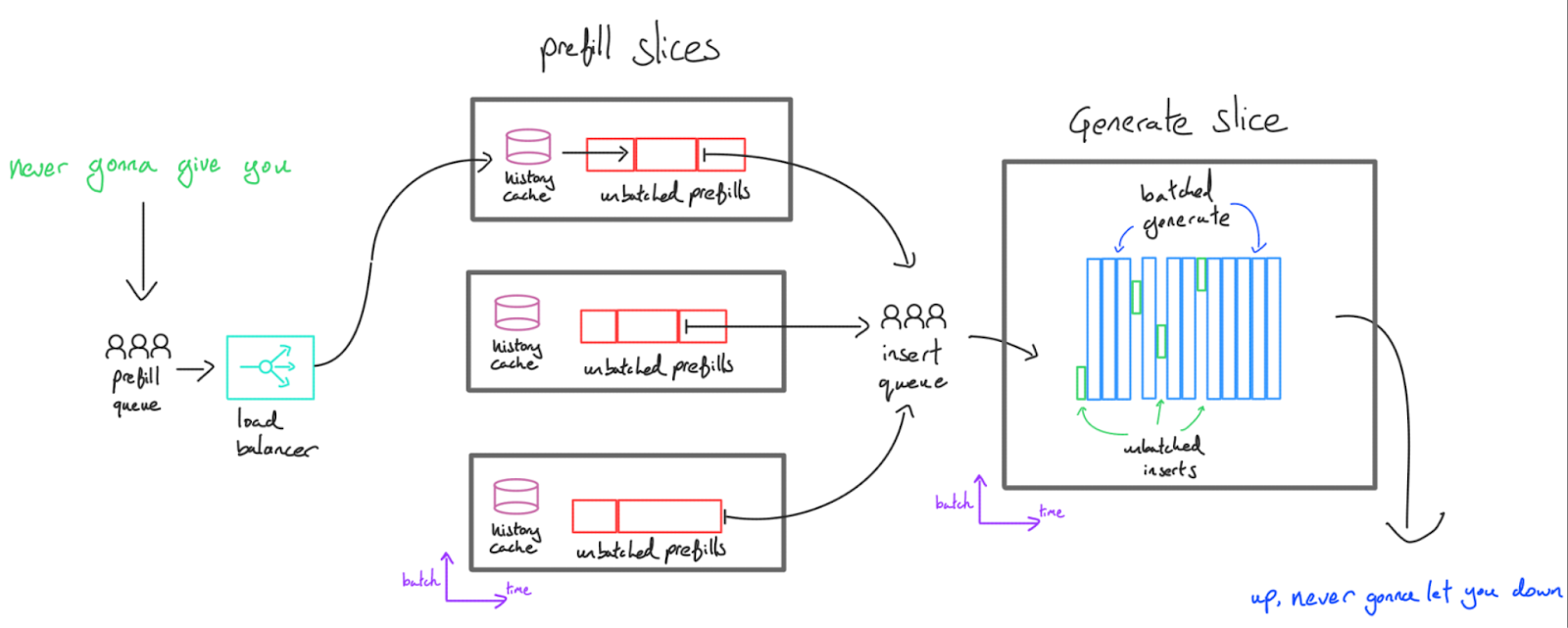
分离式推理具备以下核心优势:
-
大规模下的极低延迟: 除非预填充集群算力耗尽,否则用户的请求永远不会被其他用户的解码操作阻塞。请求在完成即时预填充后,会立即被调度至生成集群的缓冲区。我们可以根据并发流量,独立对预填充和生成服务器的数量进行调整(scale),确保用户不会在预填充队列中长时间堆积。
-
专业化调度策略: 预填充与生成阶段往往需要不同的参数调度策略及硬件拓扑结构以实现最低延迟(例如,生成阶段更适合采用模型并行化方案,而预填充阶段则不然)。若强制两个阶段采用相同的参数配置,不仅会制约双方性能,还会因存储多套权重参数而增加内存占用。通过将预填充阶段独立部署至专用服务器,该服务器仅需维持当前处理任务的键值缓存,无需保留历史缓存数据。此举可释放大量内存空间,既能支持更完善的历史缓存机制(详见下节),又能提升预填充阶段的计算效率。
唯一的挑战在于 KV Cache 在网络间的传输开销,这通常可以通过 InfiniBand 或 RoCE 等高速互联来缓解,但也进一步体现了缩减 KV Cache 体积对于高性能推理的重要性。
核心结论: 对于对延迟高度敏感且要求高吞吐的服务场景,业界最佳实践是将预填充与生成阶段在服务器级别进行分离。预填充以 模式运行以保证 TTFT,而生成阶段则通过大规模 Batching 提升整体吞吐量。
Continuous batching
针对前文提到的问题 (2)——即长短序列混合导致计算槽位空置的“木桶效应”,业界引入了连续批处理 (Continuous Batching) 的概念。在该模式下,推理引擎会针对性地优化并编译以下核心组件:
- 预填充算子库: 支持多种可变上下文长度(Variable Context Lengths)的预填充函数。执行时,算子将生成的 KV 数据插入到预定义的 KV 缓冲区(KV Buffer)中,该缓冲区受限于最大 Batch Size 以及预设的最大上下文长度或分页数量。
- 生成算子: 该函数负责接入当前的 KV Cache 状态,并为所有处于活跃状态的并发请求同步执行单步解码。
随后,系统通过一个编排器 (Orchestrator) 将这些算子有机结合:编排器负责维护请求队列,根据生成槽位(Generate Slots)的可用性动态调度预填充与生成任务,同时管理历史缓存(详见 Part 8)并以流式输出 Token。

Prefix caching
由于预填充阶段属于计算密集型任务且资源开销巨大(导致系统的冗余容量/Headroom 较小),降低成本的最有效手段就是“减少重复计算”。基于大语言模型的自回归特性,Query [“I”, “like”, “dogs”] 与 [“I”, “like”, “cats”] 的前两个 Token 产生的 KV Cache 是完全一致的。这意味着,如果我们先计算前者的缓存,再计算后者,理论上后者仅需执行 1/3 的计算量。通过复用已有的缓存,可以省去绝大部分工作,这在以下场景尤为高效:
- 聊天机器人 (Chatbots):对话通常呈现严格的增量式追加(Appends)模式。如果能保存每一轮对话的 KV Cache,我们只需为最新产生的 Token 执行计算。
- 少样本提示 (Few-shot Prompting):固定的 Few-shot 示例或系统指令(System Instructions)可以被缓存并无限次免费复用。
实现该技术的核心障碍在于内存容量约束。正如前文所述,KV Cache 占用空间巨大(动辄数十 GB),且为了保证缓存的有效性,必须将其驻留在内存中直到后续查询到达。通常,预填充服务器上未被占用的 HBM 可用作本地缓存系统。此外,加速器节点通常配备容量巨大的主机内存(Host DRAM),例如一台 8xTPUv5e 服务器拥有 128GiB HBM,但 Host DRAM 高达约 450GiB。虽然 Host DRAM 的带宽远低于 HBM,不足以支持实时生成,但其速度足以支撑缓存的读取与回传。
实际部署中的关键考量:
- 亲和性路由 (Affinity Routing):由于 KV Cache 存储在处理初始请求的特定 TPU 节点上,需要实现某种形式的亲和性路由,确保后续查询被分发至同一个副本(Replica),但这可能给负载均衡带来挑战。
- KV Cache 规模的影响:更紧凑的 KV Cache 结构不仅能增加单位空间的存储上限,还能缩短缓存读取的耗时。
- 管理机制:KV Cache 及其检索逻辑可以自然地存储在树状结构或前缀树 (Trie) 中,并采用 LRU (最近最少使用) 算法执行缓存淘汰。
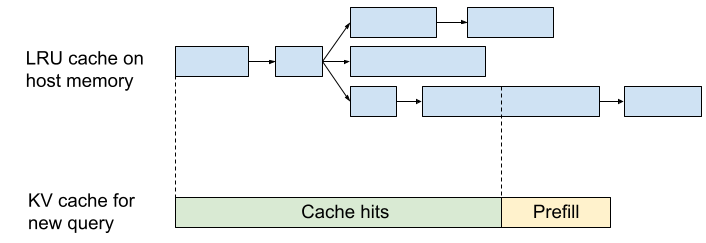
基于 LRU Trie 的 Prefix KV Cache 机制详解
在大规模语言模型推理中,预填充 (Prefill) 阶段由于是计算受限 (Compute-bound) 且开销巨大,优化核心在于“减少重复计算”。基于 LRU Trie 的缓存机制是实现这一目标的高效手段。
1. 核心架构:前缀树 (Trie) 的组织逻辑
正如图片上方“LRU cache on host memory”所示,系统将 KV Cache 以块 (Block) 为单位组织成一棵 Trie (前缀树):
- 节点即前缀:树中的每个蓝色方块代表一段 Token 序列及其对应的 KV Cache 向量。
- 路径共享:具有相同前缀的不同请求(例如相同的系统提示词 System Prompt 或 Few-shot 示例)会共享树中的祖先节点。这避免了为相同的前缀在内存中存储多份重复的 KV 向量。
- 多层级存储:由于加速器 HBM 空间有限,该机制通常利用 Host Memory (主机内存/DRAM) 作为二级缓存。虽然 Host Memory 的访存速度慢于 HBM,但对于缓存读取(Cache Read)而言已足够快。
2. 工作原理:从匹配到计算
图片下方的“KV cache for new query”展示了新请求进入系统时的处理流程:
- 前缀匹配 (Cache Hits):
- 当新查询进入时,编排器 (Orchestrator) 会在 Trie 树中检索其前缀。
- 图中绿色区域 “Cache hits” 对应 Trie 树中已存在的路径。系统直接从 Host Memory 或 HBM 中提取这部分 KV 向量,完全跳过相关的矩阵乘法计算。
- 增量预填充 (Prefill):
- 图中黄色区域 “Prefill” 代表 Trie 树中未命中(即新出现)的 Token。
- 系统仅需对这部分新增 Token 执行预填充计算。
- 效率增益:如果一个长 Prompt 只有最后几个 Token 是新的,计算量可缩减至原先的极小比例(例如 甚至更低)。
3. 内存管理:LRU 淘汰机制
由于内存容量受限,无法无限期保留所有缓存,因此引入了 LRU (Least Recently Used) 策略:
动态置换:系统会追踪每个节点(路径)的访问频率。当内存(HBM 或 Host DRAM)达到阈值时,会优先移除“最近最少使用”的叶子节点及其分支。
空间换时间:这种机制在处理聊天机器人 (Chatbots) 或 固定指令集 任务时表现极其强大,因为它将增量对话的计算量限制在每一轮新增的 Token 上。
底层实现笔记:这种机制在 vLLM 等高性能推理引擎中常与 PagedAttention 结合使用。PagedAttention 负责将逻辑上的 Trie 节点映射到物理上的非连续显存块中,从而彻底解决显存碎片问题。
Let’s look at an implementation: JetStream
Google 开源的 JetStream 库完整实现了上述逻辑。该系统由单一控制器(Controller)统一编排,内部包含部署在不同 TPU 分片上的“预填充引擎”和“生成引擎”。系统架构中,预填充操作运行在独立的“ prefill thread”中,而生成操作运行在“ generate thread”中。此外,系统还包含一个专门的“传输线程( transfer thread)”,负责将 KV Cache 从预填充分片跨网络复制到生成分片。
etStream 定义了一个通用的引擎接口 (Engine Interface,here),任何适配该框架的大模型都必须提供以下核心方法:
- prefill (预填充):接收输入 Token 序列并生成初始 KV Cache。
- insert (插入):将生成的 KV Cache 注入到生成队列的活跃 Batch 中。
- generate (生成):对 Batch 中的所有 KV Cache 执行一步解码,并为每个请求追加新生成的单 Token KV 数据至解码状态中。
此外,针对 PyTorch 生态,JetStream 也提供了相应的支持 here。
5. Worked Problems
在本节中,我们将基于 LLaMA-2 13B 构建一个虚拟模型,并以此展开一系列关于模型架构、显存占用及分布式性能的定量分析。模型具体超参数如下:
| hyperparam | value |
|---|---|
| L (num_layers) | 64 |
| D (d_model) | 4,096 |
| F (ffw_dimension) | 16,384 |
| N (num_heads) | 32 |
| K (num_kv_heads) | 8 |
| H (qkv_dim) | 256 |
| V (num_embeddings) | 32,128 |
问题 1:上述模型拥有多少参数?在 int8 精度下,每个 Token 的 KV Cache 占用多大空间?(注:假设输入 Embedding 与输出 Projection 矩阵共享权重)
参数量计算:
- MLP 参数量:
- Attention 参数量:
- 词表参数量:(由于矩阵共享)
总参数量计算公式为 。代入数值:。因此,该模型约为 18.4B (184 亿) 参数。
在 int8 精度下,每个 Token 的 KV Cache 大小为 ,即 ,约为 262kB/Token。
问题 2:若将该模型部署在 TPU v5e 4x4 拓扑(16 颗芯片)上,并对 KV Cache 进行完全分片。在全量 int8 精度(模型参数与缓存)且支持 128k 上下文长度的前提下,系统能承载的最大 Batch Size 是多少?若将 KV 头数 降至 1,结果会有何变化?
问题 1 已经计算得出,1 个 token 的 KV Cache 大小为 262kB;而对于 128k tokens 的序列,单个 Batch 的 KV Cache 大小为 。每颗 TPU v5e 拥有 16GB HBM,16 颗芯片总容量为 256GB。扣除模型参数占用的 18.4GB,可用于缓存的剩余空间为 ,因此最大 Batch Size 为 。若 ,则 KV Cache 缩小 8 倍,最大 Batch Size 可提升至约 56。
问题 3:在 int8 参数全分片状态下,将所有模型参数从 HBM 加载到 MXU 需要多久?(注:该数值是单步迭代延迟的理想下界)
总参数量为 18.4B 字节。单芯片 HBM 带宽为 ,总带宽为 。假设带宽利用率为 100%,耗时约为 。
问题 4:若要在 TPU v5e 4x4 拓扑上以全量 int8 精度(包括 FLOPs、参数和激活值)运行此模型。应如何针对预填充和解码阶段进行分片?这种分片策略下单步解码的估算延迟是多少? (提示:思考 4x4 拓扑的 ICI 互联特性、张量并行的 Roofline 限制以及 KV Cache 的分片方式。)
- Prefill 阶段的分片策略:在 Prefill 阶段,目标是最大化计算利用率,降低 TTFT
- 策略 1:采用 TP=16,沿隐藏层维度 切分权重。在 16 颗芯片上可以实现 的分片,每个 shard 负责 的投影与计算(TP 的本质是对 QKV projection 和 attention 计算输出的 hidden dimension 进行切分),该切分恰好可映射到 heads,使每 shard 覆盖 2 heads 的等效计算量。
- 策略 2:依旧采用 TP,根据 section 5 的经验,当并行度达到 时会触及 ICI 带宽瓶颈,因此选用 TP=8 的方式,作为计算/通信的平衡点;另外 8 颗芯片用于独立的模型 replica 组,从而拓展出 1 个独立的模型副本(即,前文提到的推理中不使用纯 DP,而是独立的模型副本)
- Prefill 阶段的 KV Cache 暂不分布存储,因为此时 Batch Size 很小(通常为 1),存储开销尚可接受。
- Generation 阶段的分片策略:在 Generation 阶段,目标是最大化显存带宽的利用率,降低单步延迟
- 策略:结合前文对模型并行度的分析,根据公式 ,对于典型的 Batch Size = 32,则模型并行度最大为 64 ,不过这仅仅是个 theoretical bound,毕竟芯片数只有 16,无法实现这么大的模型并行
- 不过由于 (KV 头数)小于芯片数 16,不能仅靠 Head 维度分片,应采用多维分片布局 ——在 轴分片 KV 头 (),在 轴分片 Batch ()。这样结合 KV Cache 分片,利用两次 AllToAll 通信进行激活值的布局转换,就是目前这个问题的最优解。
- 这里可能会有困惑,为什么可以从 head 和 kvcache 两个维度做联合分片,实现充分的芯片利用?首先 MHA 的各 head 在 、、 投影之前是完全独立的,head 维度是 attention 机制天然的并行轴,只要满足 head 数 ≥ TP 数就没问题,否则就要另行扩展,以充分利用芯片的并行能力;另外 KV Cache 的本质是一个逻辑张量 ,只要能够保证每个 Query token 再计算 attention 时能够看到所有历史 KV,那么 KV 存储在哪、如何切分,都只是工程实现的问题,而不构成语义、理论正确性上的问题。因此总的来说,这种联合分片的策略是一种在 Generation 阶段 时工程实现上的标准做法,是一个合法的 SPMD 变换。
- 这种策略下,可以聚合 16 颗芯片的 HBM 带宽(约为 Bytes/s),从而压低单步延迟——这与 DeepSeek V3 中采用 EP320 的 Decoding 阶段有异曲同工之妙。
- 单步解码延迟估算:
- 结合 1.4 节 中的通用理论步时计算公式(1), ,这里 int8 量化下总参数量占用 GB 显存,单个 128k 上下文的请求的 KV Cache Size 为 ,总内存带宽是 Bytes/s,总算力 FLOPs/s,假设生成时 BatchSize=1 的边界情况(意味着该估算是严格的、per-request 的 per-step 耗时):
- Attention 部分的计算用时 ms ,注意实际KV Cache已分片,加载时每个芯片仅加载本地分片,但总数据量不变,总带宽为聚合带宽,因此该公式仍适用。不过这里是一个悲观估计,假设了每生成一个 token,都要将 KV Cache 完整地重新加载到显存中,而不考虑任何 cache hit 和 streaming kvcache 、cache resident 等优化手段,如果考虑这些优化的话,应当是 。
- MLP 部分的计算用时:注意临界 BatchSize ,而当前 BatchSize=1 远小于临界 ,因此处于访存受限阶段。故而 ms 。
- 激活值大小为
- 通信开销主要是 TP 引入的 AllReduce 通信,每层约 的耗时,KV Cache 分片引入两次 AllToAll,每次通信量约 ,因此对于 ,通信量较小,处于延迟受限。估算每跳引入 1μs 的通信延迟,总的 单层通信延迟约为 量级,因此对于 64 层的模型, ms
- 因此,总步时 ms/token
问题 5: 假设该模型为MoE 模型,其可视为拥有 个 FFN 副本的稠密模型,每个 Token 激活其中的 个专家并加权输出。设 ,那么:
- 模型总参数量和单 Token 激活参数量是多少?(激活量指的是对任意给定 token 所使用的参数量)
- 在 TPU v5e 上达到计算受限(FLOPs-bound)所需的 Batch Size 是多少?
- 每个 Token 的 KV Cache 大小如何变化?
- 个 Token 的一次前向传播涉及多少 FLOPs?
(1) 参数量: MoE 模型的每个 MLP 块扩展为原来的 倍,即 。总参数量公式变为 ,约为稠密版的 12 倍。对于激活参数量,每层仅涉及 个专家而不是所有 个专家,因此总计约 ,增幅不足 2 倍。
(2) 临界 Batch Size: 由于参数加载量(访存)增加了 倍,而计算量仅增加 倍,HBM 硬件 Roofline 阈值()相应增加 倍。在 TPU v5e 上,这需要约 个 Token 才能进入 compute-bound 状态。
(3) KV Cache: MoE 仅改变 MLP 结构,不影响 Attention 机制,因此 KV Cache 大小不变。
(4) 计算量: 单 Token 计算量约为 ,因此个 Token 的计算量约为 FLOPs。
问题 6: 对于 MoE,我们可以进行“专家分片 (Expert Sharding)”,即将专家按照 TPU 组网的维度进行分片。假设第一个 FFN 的权重形状为 ,我们将其分片为 ,其中 仅在训练期间用作我们的 FSDP 维度。假设我们在 TPU v5e 的 8x16 切片上进行推理,其中:
- 权重加载耗时是多少?每颗 TPU 剩余多少可用显存?
- 权重加载耗时: 这里的 “HBM weight loading time” 指的是TPU 在执行推理计算时,从 HBM 中把模型权重读入计算管线(MXU)的时间下界。在真实硬件上,推理的每一步只读取当前层所需的权重,且这些权重早已根据分片策略分布在各自芯片的 HBM 中,因此我们需要考虑经过 Expert Sharding 之后,每个芯片上持有多少权重。
- MoE的MLP权重形状为 ,分片为 。由于 维未使用,实际分片为 。而 ,即 Z 轴的每芯片负责1个专家(完整);。
- 因此每芯片每层MLP权重大小: M个参数,int8下约25.2 MB。所以对于 64 层 MoE 模型来说,应当占用 GB
- Attention参数(为了最大化芯片的计算强度,采用每芯片都全层复制策略):而每层约 M参数,int8下约83.9 MB。故而全模型的参数总量为 G
- 词表参数(全复制): M参数,int8下约131.6 MB。这个只需要一层就行。
- 每芯片总参数量:约 GB。
- 权重加载耗时: ms
- 注意这里的策略:在MoE推理这个特定场景下,主要的矛盾是巨量的专家通信与严苛的生成延迟。此时,将相对不大的Attention参数进行全复制,是一个“用充裕的显存空间,购买珍贵的延迟时间”的经典优化策略。
- 每芯片的剩余显存:
- TPU v5e 单片 HBM 为 16 GB。剩余显存 (可用于存放 KV Cache 或实现 Prefix Caching)。
- 考虑 KV Cache 占用(假设单个请求的上下文长度为 128k,采用 int8 量化):问题 1 和 2 中已经计算出每 token 的 KV Cache 占用为 ,每个请求的 KV Cache 占用为 。对 KV Cache 按照 进行分片,其中 ,即每芯片存储一个头;,假设 BatchSize=32,则 ,每芯片处理 2 个 Batch,因此每芯片 KV Cache 大小为 GB
- 也就是说,按照这种分片策略,16x8 的 TPU v5e 集群,恰好能并发的提供 32 个上下文为 128k 的请求的推理服务。不过剩余空间已经极其有限,几乎无法容纳前向传播中的激活值、编译器临时缓冲区等 runtime 内存,很可能 OOM,需要做一些限制。
- 权重加载耗时: 这里的 “HBM weight loading time” 指的是TPU 在执行推理计算时,从 HBM 中把模型权重读入计算管线(MXU)的时间下界。在真实硬件上,推理的每一步只读取当前层所需的权重,且这些权重早已根据分片策略分布在各自芯片的 HBM 中,因此我们需要考虑经过 Expert Sharding 之后,每个芯片上持有多少权重。
- 容纳该模型所需的最小 TPU 组网切片规模是多少?
- 权重所占用的显存约束: 模型总参数量 ,单芯片容量 。因此仅存放权重就要占用 。
- 考虑 KV Cache 存储:如果我们按照上下文 128k 的配置不变,且要求单个完整请求的 KV Cache 全部驻留,那么单次请求就需要 33.5GB,考虑到 ,剩余空间极有可能不够激活值、编译器临时缓冲区等 runtime 内存占用,很有可能 OOM。
- 故而,最小切片应该是 4x4 ,并且要对用户请求的上下文做一定限制,或者对 KV Cache 做一些优化才能够正常提供服务。
问题 7 [2D 模型分片]: 本题探讨 ESTI 论文 提出的 2D 权重驻留分片 (2D Weight-stationary Sharding)。其核心思想是同时沿维度 和 对权重进行分片,使每个分片块接近正方形。这种方式能有效降低通信负载并提升扩展性。这是 2D 权重驻留分片的算法描述:
简要说明
- 首先通过 操作沿 轴收集输入分片(步骤 1)。
- 然后在局部 轴上进行投影矩阵的乘法(步骤 2)。
- 利用 沿 轴合并计算结果(步骤 3)。
- 再和后续权重分片进行乘法(步骤 4)。
- 最后通过 ,将输出重新分散到对应的 轴设备分片(步骤 5)。
这种 2D 分片策略能更均衡地利用集群的带宽和内存,显著提升大规模推理时的效率与可扩展性。
你的目标是计算这个算法的计算量和通信量,并找出它何时能优于传统的 3D 模型分片。
- 分析:由于所有 FLOPs 都是完全分片的,因此与传统的 3D 模型分片相同,有 。
- 分析:由于 AllReduce 的操作成本是传统 3D 模型分片的 AllGather 的2倍,并且由于每个操作都涉及多个轴,因此通信量需要乘以轴的数量。因此有:
假设我们自由选择拓扑,并且假设 (如 LLaMA-2),我们通过一些基本的微积分得出 的最佳值为 ,因此总通信量为
- 由上文的推导,1D 模型并行的通信量为 ,因此当 时,2D 权重驻留分片优于 1D 模型并行。
对于一般情况,我们有
因此,当我们有超过 81 颗芯片时,我们使用 2D 权重驻留分片更优。这其实有一点奇怪,过去的经验告诉我们当我们触及 ICI 瓶颈时,模型并行度应该在 20 路左右。但是这里,即使我们受限于通信,总通信量却仍然随着芯片数量增加而减少!这意味着我们可以持续增加芯片数量,增加batch大小,进行更多参数缩放,并看到延迟降低。
APPENDIX
A: How real is the batch size > 240 rule?
上文提到的“Batch Size 必须大于 240 个 Token 才能进入计算受限状态”这一经验法则在大方向上是准确的,但它忽略了硬件底层的一些优化机制。例如,TPU 能够在执行芯片间通信(Inter-device Communication)等不完全占用 HBM 带宽的操作时,并行执行权重的预取(Prefetch)。
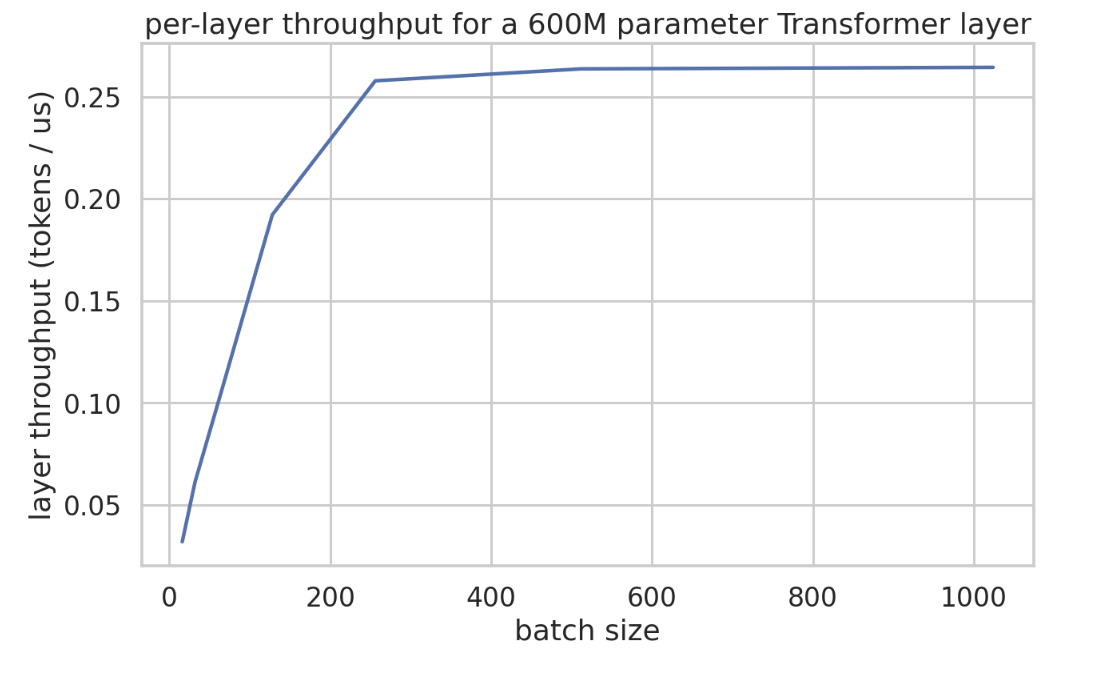
下图展示了一个小型 Transformer 模型(,每层仅包含 2 个矩阵乘算子)层耗时的实测数据。观察单步迭代时间(Step Time,单位:微秒)随 Batch Size 的变化曲线可以发现:在 Batch Size 达到 240 之前,耗时增长非常缓慢(处于访存受限区间,权重加载占主导);一旦超过 240,耗时开始随 Batch Size 线性增加(进入计算受限区间)。
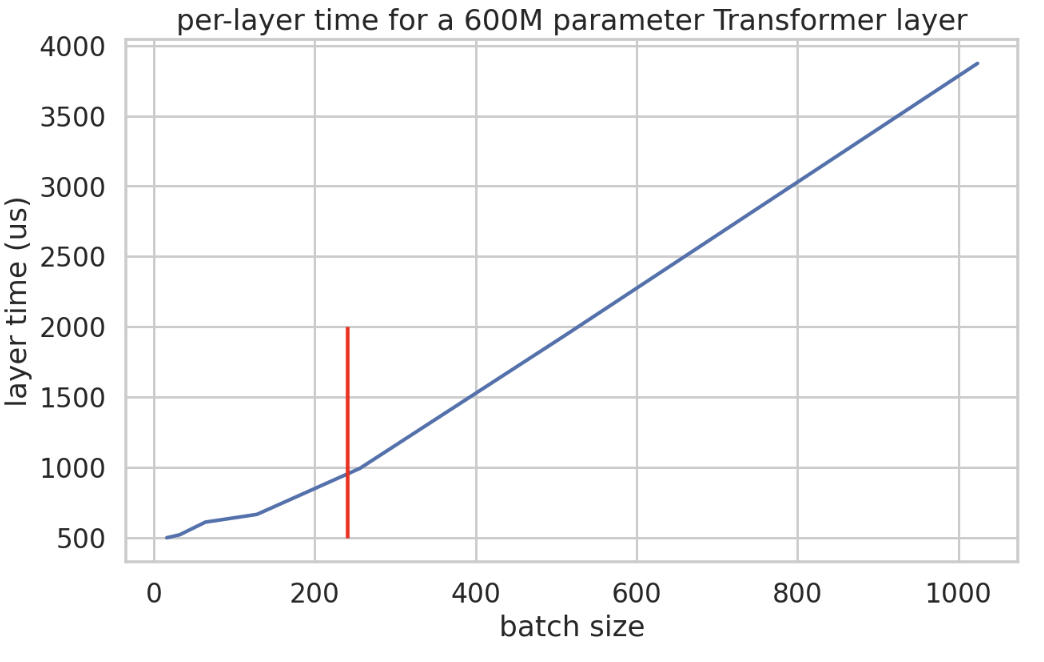
下图的吞吐量曲线则更直观地展示了这一点:吞吐量在每个数据并行分片达到约 240 Batch Size 时达到饱和。在该配置下,单层包含约 6 亿参数并分片至 4 颗芯片,理论最小延迟约为 365 微秒。
B: 2D Weight Stationary Sharding
随着硬件拓扑规模的扩大,如果利用高维网格(Mesh)架构(如 TPU 的多维互联),我们可以通过 “2D 权重分片” 进一步优化。这种方案引入了第二个分片轴,被称为 “2D 权重驻留 (2D Weight Stationary)” 分片,该方法在《Efficiently Scaling Transformer Inference》论文中有详细阐述。
在标准的 Megatron(1D)分片中,由于仅对隐藏层维度 进行切分,当芯片数量极多时,单个分片处理的 维度可能变得远小于 (模型维度 )。这意味着在大 Batch 推理场景下,在 MLP 第一层计算完成后,针对隐藏层维度执行部分集合通信(Collectives)会具有更高的经济性。
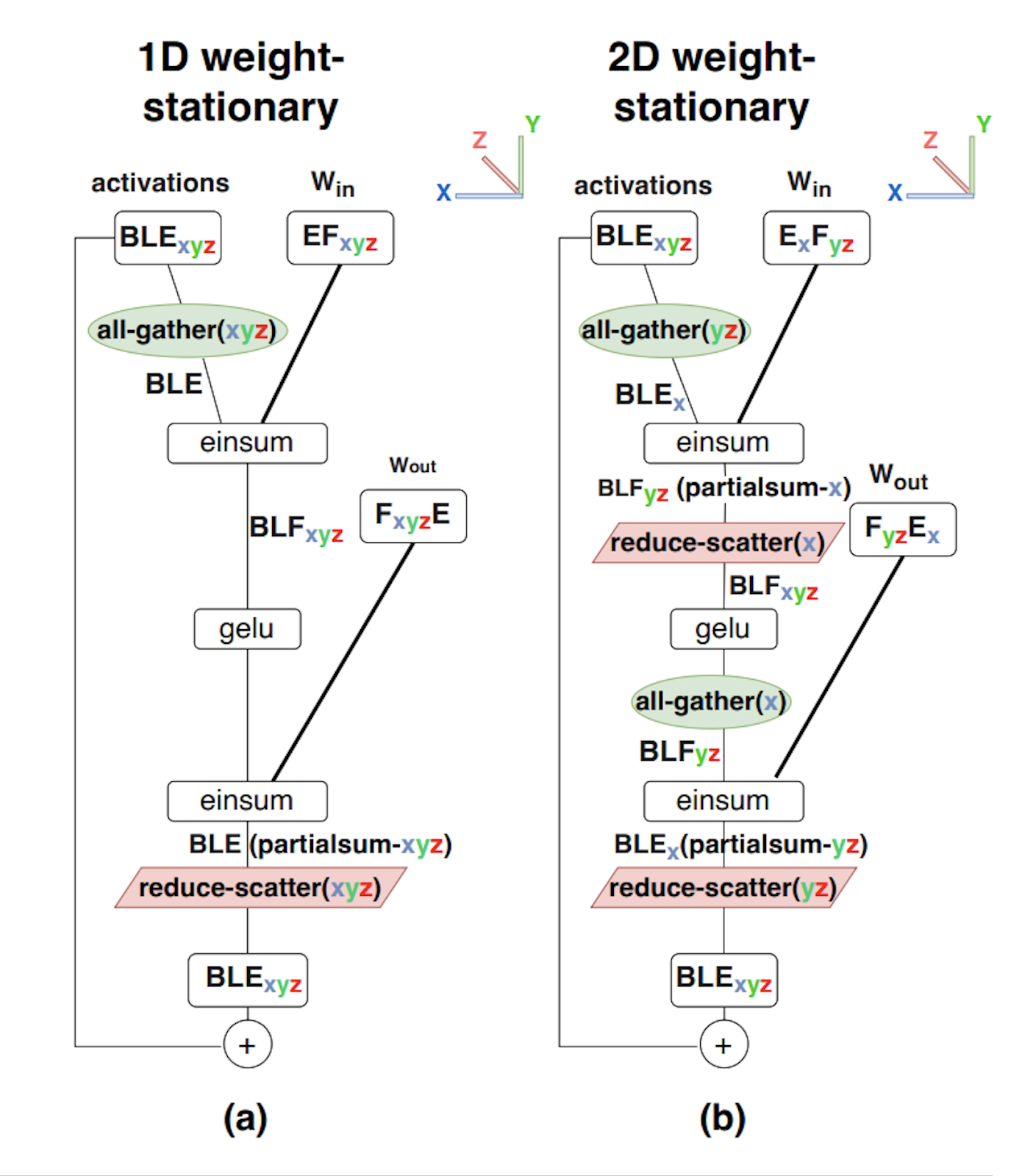
上图说明:
- 1D 权重驻留分片(即纯 Megatron 分片):在执行 AllGather 后,激活值在所有芯片上完全复制,而权重矩阵仅在隐藏层维度 上进行分片。
- 2D 权重驻留分片:权重矩阵在隐藏层维度 和 reduction 维度 上同时进行分片,激活值则在 维度上分片。底层执行逻辑为:在第一层计算前先在 (yz) 轴执行 AllGather,计算完成后在 (x) 轴执行 ReduceScatter。
对于注意力层(Attention Layer),在芯片数量较少时,Megatron 式的分片实现较为简单。但由于 Megatron 是针对 (头数)维度进行切分,这限制了并行的最大扩展空间。通过借鉴 2D 分片思路,对 维度进行多维切分,可以获得更强的扩展能力。
C: Latency bound communications
在第 3 节中,我们推导了在包含 颗芯片、全双工带宽为 、链路延迟为 的 1D 环形拓扑中,执行大小为 的张量 AllGather 所需的耗时公式。
对于较大的数据块 ,由于随着芯片数量增加,总带宽和数据搬运需求同步增长,其实际执行耗时基本保持恒定。

在针对延迟优化的推理场景中,由于搬运的数据量较小,激活值的集合通信通常受限于延迟项(Latency-bound),而非带宽项,在小 Batch 场景下尤为明显。通信延迟可以通过计算完成同步所需的跳数(Hops)来直观量化。
在 TPU 架构中,如果通信耗时中与张量大小相关的部分小于每跳 1 微秒(一跳指两颗相邻芯片之间的通信),系统瓶颈就会转变为调度集合通信的固定开销。以单向 ICI 带宽 Bytes/s 为例,当满足
对于 的 Megatron 分片,有
即单分片数据量小于 时,通信进入延迟受限区间。
在推理实践中,这个阈值并不低:例如在 、隐藏维度 且采用 int8 精度时,激活值总量仅为 ,这意味着通信已经处于延迟受限状态。
核心结论: 当总数据量 时,通信受限于链路延迟。例如在 int8 精度下实施 路模型并行,当 时,系统将进入延迟受限区间。
这和计算 Roofline 模型有相似之处:我们正在承担一些小型操作(通信延迟、矩阵乘内存带宽)的固定开销。
D: Speculative Sampling
若要极致压低端到端延迟,可以使用 “投机采样 (Speculative Sampling)”(即投机解码)。常规的 Transformer 推理是逐 Token 串行生成的。
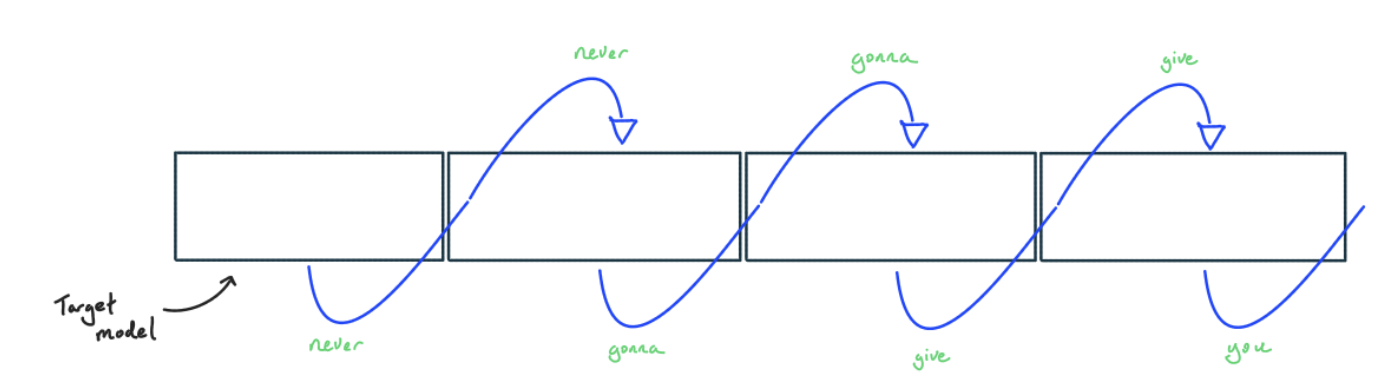
而投机采样利用一个参数量更小、成本更低的草稿模型(Draft Model)先行生成若干 Token,随后交由大模型进行并行校验。该机制在贪婪解码(Greedy Decoding) 模式下最易理解:
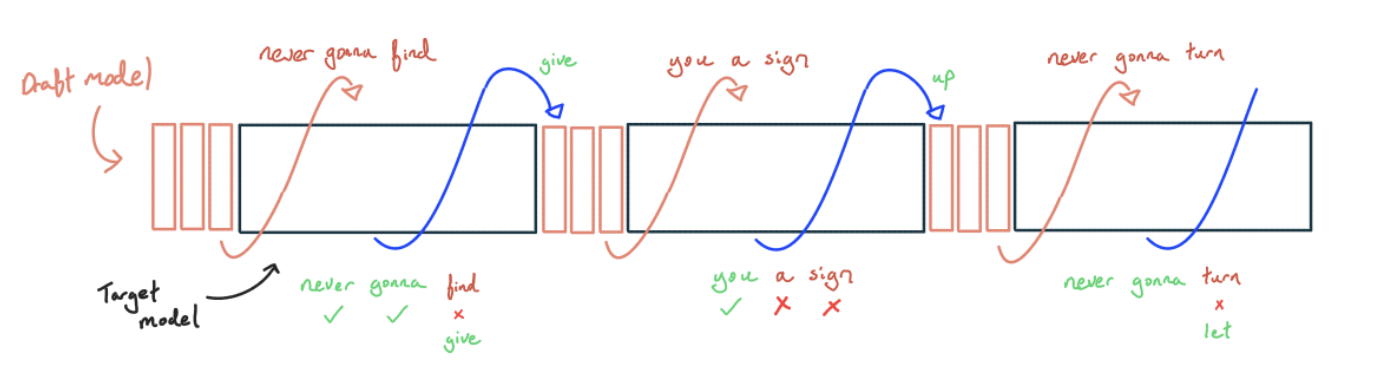
- 草稿生成:使用轻量化模型执行贪婪采样。理想情况下,该模型应通过蒸馏等手段与大模型对齐,但在某些场景下,简单的 N-gram 或语料匹配亦可胜任。
- 并行校验:当小模型生成 个 Token 后,将其作为 Batch 输入大模型,一次性计算这些位置的 next-token Logits。
- 接受与修正:检查小模型生成的 Token 是否对应大模型 Logits 中的最高概率项。若某个 Token 验证失败,则保留其之前的正确前缀,并用大模型的预测值修正首个错误 Token,随后返回步骤 1。若全部验证通过,则可利用大模型最后一位的预测多生成一个 Token,提高效率。
投机解码实现延迟优化的底层逻辑:尽管投机采样仍需大模型对每个 Token 执行同等量的 FLOPs 计算,但由于它将多个 Token 的计算任务合并为一个 Batch,大模型能够利用生成阶段非计算受限的算力余量(Headroom),以几乎相同的耗时完成多个 Token 的验证与评分,从而获得“免费”的 Token 产出。
虽然平摊到每个成功接受的 Token 上的 FLOPs 增加了(考虑到存在拒绝的情况以及草稿模型的开销),但该方案更充分地压榨了硬件的算力潜能。由于草稿模型计算成本极低,整体收益依然显著。此外,由于在多个 Step 间共享了 KV Cache 加载,投机解码在长上下文场景中也能提升总吞吐量。由于结果均经过大模型验证,因此不会改变模型的采样分布(尽管具体轨迹会因非贪婪解码而不同,但影响不大)。
传统的投机解码方法通常依赖于一个与目标大模型采样分布相似的小模型作为“草稿模型”,如用 LLaMA-2 2B 辅助 LLaMA-2 70B。但实际上,具备良好对齐的小模型常常不存在;即便找到了合适的小模型,若采纳率不高,其推理开销依然可能过大。因此,一种替代做法是在主模型内部嵌入草稿模块,例如在主模型的后几层增设专用的 drafter head(草稿输出头)。由于该头部多数参数与主模型共享,因此计算效率更高,且更容易对齐或拟合主模型的采样分布。
对于常规的自回归采样,每生成一个 Token 就对应一步计算(Step Time),即生成耗时等同于每步的耗时。按照前文算术强度(Arithmetic Intensity)一节的分析,这里的理论最小步长仍然受限于硬件性能。事实上,投机采样(Speculative Sampling)在每步耗时上通常比普通自回归采样更慢一些,但由于每步平均可以生成多个 Token,整体的 tokens/s 却能大幅提升。
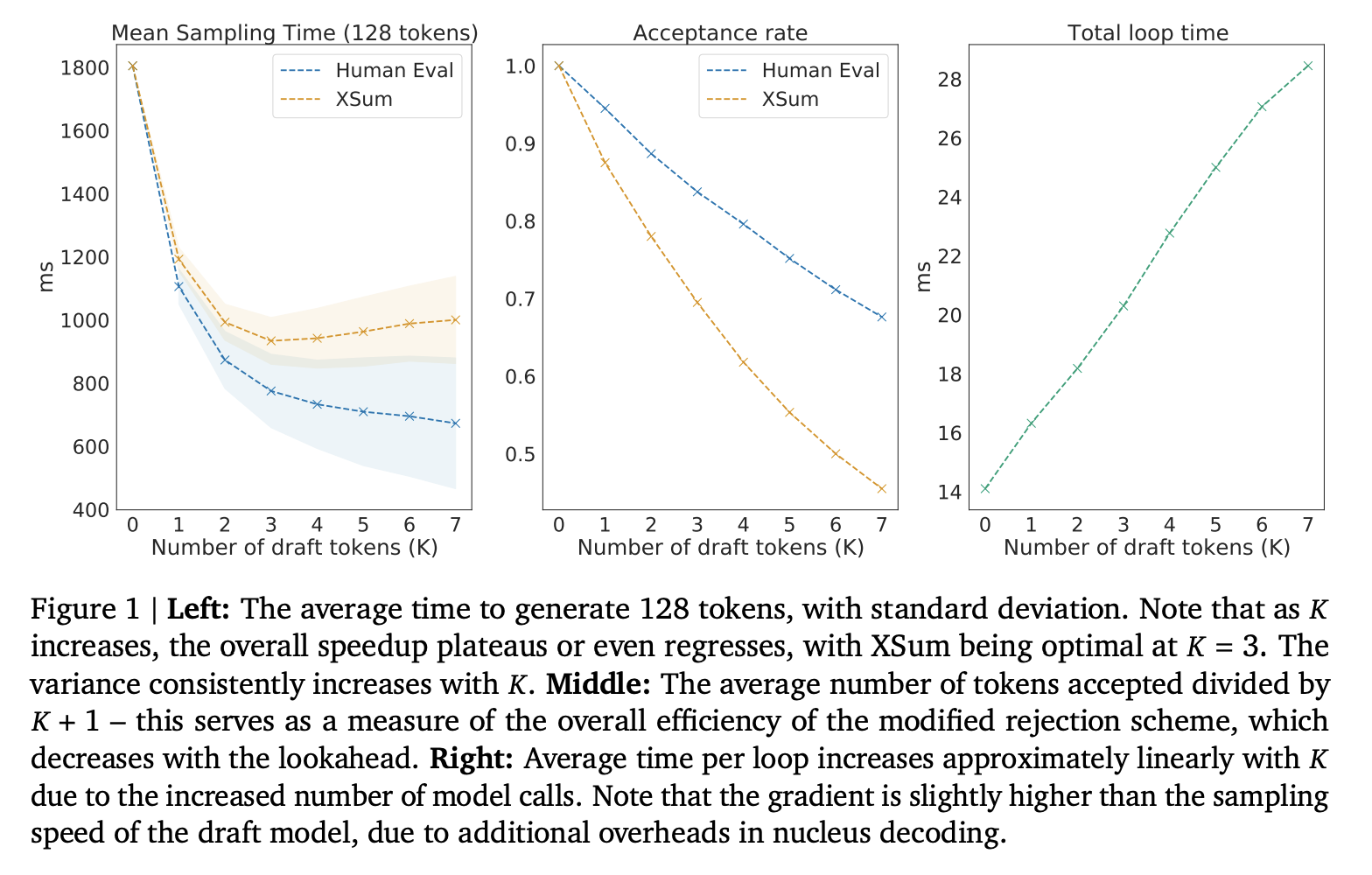
上图展示了 Chinchilla(一个来自 DeepMind 的 70B 模型)与一个 4B 参数的草稿模型(小模型)在每步耗时和投机成功率方面的表现。对于 XSum(一个自然语言数据集),理想的投机量约为 3-4 个 Token;而 HumanEval(一个编程数据集)则更可预测,更激进的投机策略也能带来收益。
非贪婪解码(如采样解码)情况下如何应用投机采样? 这一过程相对更为复杂,本质上可视为一种 Metropolis-Hastings 风格的算法。具体做法是:分别计算草稿模型与目标大模型对于每个候选 Token 的概率( 和 ,由 logits 推出),如果采样 Token 时两者概率之比低于某个阈值,则以一定概率拒绝该 Token,实现概率一致性的修正。
这是两篇有关投机推理的论文,可以阅读并理解其工作原理:[2211.17192] Fast Inference from Transformers via Speculative Decoding,[2302.01318] Accelerating Large Language Model Decoding with Speculative Sampling。
核心结论:投机采样是实现“以吞吐量换延迟”的强力手段。在 Batch Size 受限(如硬件资源不足或 KV Cache 过大)的场景下,它甚至能实现延迟与吞吐量的双赢。
References
Footnotes
-
为了简化分析,我们忽略了 Softmax、Mask 等非矩阵乘法(Non-matmul)算子的 FLOPs(这些算子通常应与计算或 HBM 读取重叠,但在某些代际的 TPU 上实现这一点并非易事)。即便忽略这些细节,核心结论依然成立:Attention 阶段的性能通常受限于访存。 ↩