Introduction
100K+ GPU 规模下实现高效协调的新挑战:
- 规模爆炸 :Llama 3训练用了2.4万张GPU,Llama 4需要10万+ GPU,协调难度呈指数级增长。
- 网络复杂 :这些GPU分布在不同机架(Rack)、不同AI Zone(数据中心内的区域)、甚至不同建筑(Building)中。跨区域的网络延迟和带宽差异巨大(后文提到跨建筑延迟是机架内的30倍)。
- 同步要求 :训练时所有GPU必须严格同步(木桶效应)。推理时则需要极低延迟来快速响应用户请求。
因此为了支撑 Llama4 的开发部署,Meta 提出了基于 NCCL 的 NCCLX 通信库,其有三个 feature:
- 可扩展性与性能 :支持10万+ GPU,满足训练(高吞吐)和推理(低延迟)的双重需求。
- 训练场景 :所有GPU同步工作、训练初始模型,任何通信延迟都会拖慢整体进度。在大规模训练时,NCCLX 可以提供快速初始化、容错通信机制,有效支撑高效的训练效率。
- 推理场景 :用户请求需要毫秒级响应,通信延迟直接影响用户体验,因此需要保证低延迟通信。
- 支持多样化模型的定制功能 :训练和推理不同的模型需要不同并行策略(TP/PP/EP)、不同集合通信操作、甚至定制功能,因此需要不同的通信模式支持。NCCLX 提供灵活的 API 接口和集合通信原语,能够高性能地支撑多样化模型需求。
- 易于编程 :让开发者能方便地插入新算法、新传输后端和优化方案,以满足不同的模型需求。
Table 1. NCCLX 为 Llama4 负载提供的所有创新点及其解决的问题
| 阶段 | 问题与需求 | NCCLX特性 |
|---|---|---|
| 通用 | 模型通信需求多样化,需要定制算法 | Host-driven定制 (4.1节):把通信控制从GPU内核移到CPU线程,更灵活 |
| 通用 | 计算/通信重叠时,通信占用GPU算力资源 | Zero-copy数据传输 (4.2节):数据直接从用户缓冲区走网络,不经过中间FIFO,不占用GPU的SM(流处理器) |
| 通用 | PyTorch内存管理与zero-copy的协同 | Tensor注册管理 (4.3.1节):与PyTorch显存分配器协作,自动管理内存注册 |
| 通用 | 大规模并发流量导致网络拥塞 | CTran与网络协同设计 (4.4节):动态负载均衡,避免交换机缓冲区溢出 |
| 训练 | Pipeline Parallelism的跨节点延迟高 | Zero-copy和 SM-free 的Send/Receive (5.1节):PP的P2P通信零拷贝、零SM占用 |
| 训练 | Tensor Parallelism需细粒度计算通信重叠 | RMA Put (5.2节):用远程内存访问实现更精细的AllGather-GEMM流水线 |
| 训练 | 10万卡故障率高,需要弹性训练 | 容错AllReduce (5.3节):部分节点故障时,其他节点继续训练(Hybrid Sharding) |
| 推理 | MoE的AllToAll在CUDA Graph下padding浪费大 | GPU-resident collectives (6.1节):元数据放GPU,运行时动态获取真实数据量,避免padding |
| 推理 | 小消息的CPU开销占比高 | 低延迟优化 (6.2节):简化控制流、双缓冲、快速路径等,降低CPU准备时间 |
| 控制面 | 10万卡初始化时间太长(分钟级) | 可扩展初始化 (7.1节):延迟连接、环形拓扑优化,提速11倍 |
| 工具 | 资源占用过高 | 资源管理 (7.2节):延迟分配通道、Slab分配器,显存占用从10GB降到4.2GB |
| 工具 | 故障定位困难 | 故障定位器 (7.3节):自动追踪集体操作,快速定位故障节点 |
NCCLX 的生态位在 PyTorch 之下,管理训练和推理过程中的所有通信。NCCLX 提供三种执行模式: Host-initiated APIs 、 Host-initiated APIs with GPU-resident metadata 、 Device-initiated APIs 。以及丰富通信语义选择: 集体通信 、 点对点 (P2P)和 远程内存访问 (RMA)。
为支持这些通信语义,Meta开发了名为 CTran 的host-driven的定制传输层。CTran支持多种通信算法,具备基于拓扑结构的多样化优化方案、零拷贝和无流多处理器(SM-free)传输机制,以及容错等定制功能。该传输层包含NVLink、InfiniBand/RoCE(IB)及socket后端,通过不同的硬件例程支持底层通信原语,并为IB/RoCE后端提供了独特的负载均衡优化方案。
[! NOTE] NCCLX 的生态位
传统NCCL的问题 :所有通信由GPU内核发起(kernel-driven),CPU只负责启动。这种模式简单但不够灵活,无法支持动态通信模式(比如MoE中每个token发送给哪些专家是运行时决定的)。
NCCLX的三种模式 :
- 纯Host-initiated :CPU线程完全控制通信,GPU内核只负责”等待”(stall)。好处是CPU可以灵活决策,适合大规模训练。
- Host-initiated + GPU-resident metadata :元数据(如发送多少数据)放在GPU上,CPU发起通信但GPU可以动态修改参数。适合MoE这种输入数据决定通信量的场景。
- Device-initiated :GPU内核直接发起通信,类似NVSHMEM。适合需要极致低延迟的小消息场景(推理)。
性能表现(compare to NCCL):
- 在Llama4训练评估中,NCCLX使每步延迟降低至多12%(在不同规模的模型训练中),96K规模下初始化提速11倍(from 4min to 20s)。推理延迟改善15%-80%。
总的来说,NCCLX的核心创新可以概括为: 在NCCL基础上,通过Host-driven架构和Zero-copy传输,解决了10万+ GPU集群下的三大痛点 :
- 资源冲突 :通信不再占用GPU的SM和HBM带宽
- 延迟爆炸 :通过动态拓扑感知和负载均衡,跨数据中心也能高效通信
- 故障与效率 :弹性训练+快速初始化+自动化工具,让超大规模系统可运维
Background
这一节是 NCCLX 的设计动机——从三个维度看通信库的现状:
上层 ML 训练和推理框架的并行模式
训练时 大LLM涉及 多维模型并行 ,产生多个并发的中到大规模网络流,且性能特征各异。内层并行(如TP)的通信在训练执行时完全暴露,保持在高带宽的通信域内;中层并行(EP、PP)的通信域引入中等消息大小的部分隐藏通信,但可能暴露开销可能被串行化;外层并行(FSDP、DP)数据量大但能被被内层掩盖。
以Llama 4为例,可能同时存在5种并行:
- Tensor Parallelism (TP) :把单层神经网络拆分到多个GPU。比如矩阵乘法W×X,把W按列切分,每个GPU算一部分。这种通信最频繁,每次前向/反向都要AllGather或ReduceScatter,但 只在单机内8卡之间 (H100 NVLink带宽600GB/s),延迟极低。
- Pipeline Parallelism (PP) :把不同层放到不同GPU。比如第一层在GPU0,第二层在GPU1…像工厂流水线,一个microbatch在GPU0算完后发给GPU1继续算。这里的send/recv可能 跨机架甚至跨数据中心 ,延迟高(后文提到跨DC延迟是机架内30倍)。
- Expert Parallelism (EP) :把不同专家放在不同GPU。每个token被路由到top-k个专家,需要AllToAll通信。这种通信 数据量不确定 (取决于路由结果),且需要动态传递元数据。
- Fully Sharded Data Parallel (FSDP) :把模型参数、优化器状态分片到所有GPU,训练时通过AllGather收集参数。通信数据量巨大(数百MB/次),但 跨节点带宽高 (400Gbps RoCE)。
- Data Parallel (DP) :最外层并行,每个GPU处理不同数据但模型相同,反向传播后需同步梯度(AllReduce)。
这些并行不是串行的,而是 同时发生、互相干扰 。比如一个GPU可能在给邻居发TP数据(NVLink),同时给远端节点发PP数据(跨DC网络),还要等FSDP的AllGather完成。传统通信库无法针对这种 混合流量 做全局优化。这些任务要跨建筑调度,导致 多层网络拓扑 (rack→AI Zone→DC building),不同层级延迟和拥塞容忍度差异巨大。这对集体通信库提出了拓扑感知的要求。
推理时 需要低延迟的小到中型消息通信。MoE AllToAll是典型例子,每次传几MB,因此没有通信瓶颈。CPU准备网络请求的开销可能比数据传输本身还长(这是因为虽然GPU对之间的网络传输可实现重叠,但用于准备网络请求的CPU指令需串行执行,其耗时可能超过数据传输本身)。NVSHMEM通过低开销指令和多GPU线程并行化(即多 GPU 线程向对等节点并行发送指令的能力)解决此问题。
[! question] CPU 瓶颈与 NVSHMEM 的解决方案
CPU瓶颈 :MoE的AllToAll需要给所有节点发消息(比如128个节点)。传统方式用 单CPU线程 串行准备128个RDMA请求,每个请求准备开销Tc≈1-2μs,总共128μs,而实际传输10MB数据只需25μs(400Gbps网络)。 CPU准备时间 >> 数据传输时间 。
NVSHMEM的解决方案是 Device-initiated :让GPU的多个线程并行准备这128个请求,把CPU开销降为O(1)。但NVSHMEM有 致命缺陷 :需要对称内存,与PyTorch显存管理不兼容,且维护两套通信栈(NCCL+NVSHMEM)复杂度高。因此 NCCLX 的目标是用 Host-driven 也能达到 NVSHMEM 的低延迟,同时与 PyTorch 无缝集成。
中层通信库的缺陷
NCCL 采用host-initiated模型,CPU调度通信,输入参数是CPU变量。适合传统DL/ML的批量同步,提供各种并行策略中广泛使用的集合通信原语,如 AllReduce、AllGather 等。这些集合通信操作通常涉及中等到大规模的数据量,NCCL 优先考虑带宽利用率和数据流熵,而非延迟优化。
NCCL的成功在于 简单粗暴 :
- Host-initiated :CPU调用
ncclAllReduce(),把GPU buffer指针、数据大小、数据类型传给NCCL。 - Kernel-driven :NCCL启动一个CUDA kernel,所有GPU线程参与数据拷贝和网络通信。
- Copy-based :数据从用户buffer先拷到NCCL内部FIFO,再走网络。
NCCL 的缺陷:
- 动态参数支持差 。NCCL的执行模型专为规则集合通信模式设计,其通信参数(如数据大小、数据类型)可静态表示为host 端参数。虽然该模型非常适合传统深度学习/机器学习场景,并简化了模型开发者的集合操作定义,但对于动态通信场景(如通信参数由前置计算动态生成且不断变化的情况)则缺乏灵活性。
- 将此类参数传递给NCCL集合操作需要将数值从GPU内存复制到主机内存,这不仅会引入额外的CPU同步(可能延迟后续内核调度),而且与CUDA图不兼容,通常需要采用代价高昂的数据填充作为解决方案。
- 假设GPU kernel算出了每个专家要发多少token(send_counts),存到GPU显存。NCCL AllToAllv需要这个参数,但因为它只能接受CPU指针,就必须:1.
cudaMemcpyGPU→CPU(同步,几μs到几十μs)2. CPU调用NCCL API3. NCCL再启动kernel。这破坏了 CUDA Graph (要求所有参数在图捕获时固定)。CUDA Graph是推理优化的核心,它把一系列kernel打包成一个图,一次性提交给GPU,消除CPU调度开销。NCCL的参数拷贝导致无法捕获整个计算-通信流水线。
- 资源占用多 。NCCL kernel占用大量SM线程做数据拷贝,与计算kernel(如GEMM)竞争资源。在GPU上,SM是稀缺资源,H100只有144个SM,NCCL可能占用4-8个,导致计算吞吐量下降。 但缺乏动态通信的灵活性。传递GPU生成的参数需要拷贝到CPU,延迟高且与CUDA Graph不兼容。
NVSHMEM 采用device-initiated语义,通信从设备kernel发起,参数是设备变量。适合低延迟、动态通信,可直接在GPU 计算kernel内启动数据传输并发送至网络,而无需中间拷贝步骤,从而最小化调度延迟。这些优势(包括低延迟和内核执行)使 NVSHMEM特别适合开发细粒度计算与通信流水线 。但缺点是需要对称内存区域,与PyTorch不兼容,占用大量显存。
NVSHMEM特点:
- Device-initiated :在CUDA kernel里调用
nvshmem_put(),直接发数据。也因此,前序内核计算生成的参数可以直接传递 - Zero-copy :数据直接从用户buffer走网络,不经过中间拷贝。
- 动态参数 :GPU算出的参数可以直接传给NVSHMEM,无需CPU同步。
致命缺陷:对称内存
NVSHMEM要求所有GPU rank分配一块 相同大小、相同虚拟地址 的对称内存区域,并在所有 GPU 节点上向网络注册。这块内存由NVSHMEM管理,PyTorch无法使用。对于10万GPU集群,如果每卡分1GB给NVSHMEM,总共浪费100TB显存!严重限制模型扩展能力。对于Llama 4这种显存密集的模型,这是不可接受的。
Dual communication runtime 问题:
目前业界普遍混用NCCL和NVSHMEM(TP用NVSHMEM,DP用NCCL),导致:
- 代码复杂 :两套API、两套内存管理
- 资源争抢 :NCCL和NVSHMEM各自占SM和显存,限制了性能优化的上限
- 运维困难 :两套监控、调优、故障排查工具
NCCLX的统一方案 :在单一栈中支持Host-initiated和Device-initiated两种语义,NCCLX内部统一调度。
底层网络拓扑的复杂性
100K+GPU 集群需要多栋建筑,为支撑此等规模,Meta设计了一套多建筑网络,能够将邻近数据中心建筑中的数十万块GPU整合至统一的高性能RoCE架构中。
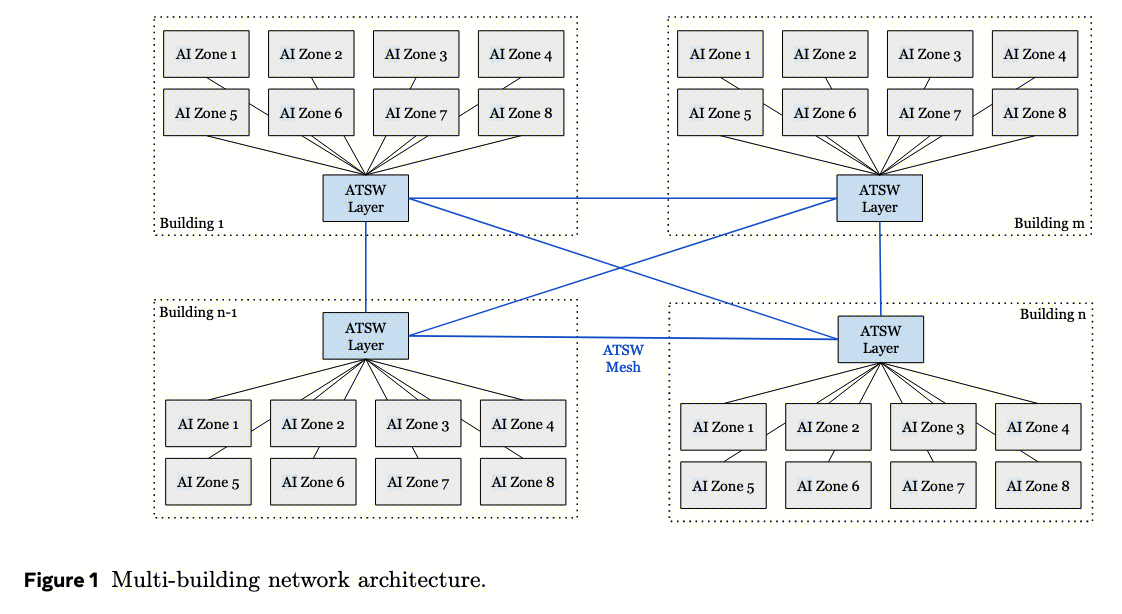 这是Meta为Llama 4专门设计的 多建筑RoCE、三层 Clos网络 (图1):
这是Meta为Llama 4专门设计的 多建筑RoCE、三层 Clos网络 (图1):
- RTSW(Rack Training Switch) :机架内64-128卡互联,延迟≈5μs
- CTSW(Cluster Training Switch) :一个AI Zone内所有机架互联,延迟≈35μs(7倍)
- ATSW(Aggregator Training Switch) :跨AI Zone和跨建筑,延迟≈75μs(15倍)到150μs(30倍)
相比Llama 3的1:7跨Zone拥塞比,Llama 4网络降到 1:2.8 ,意味着跨Zone带宽更充足,能支持更大规模的TP/PP并行。
Llama3 网络的拓扑
而跨数据中心的流量与跨AI区域流量具有相同的oversubscription(1:2.8)。该架构具备可扩展性,可在同一RoCE网络结构内支持数十万GPU的规模扩展,并支持数据中心随时间推移逐步增容。
带宽延迟积(BDP)问题 :
跨DC链路带宽400Gbps=50GB/s,延迟150μs,BDP=50GB/s × 0.00015s=7.5MB。这意味着:
- 消息<7.5MB :网络没打满,延迟主导
- 消息>7.5MB :网络打满,带宽主导。当然也不能过大,导致网络拥塞
NCCLX的DQPLB(动态QP负载均衡)就是为解决BDP问题而设计的,4.4节会详述。
这一章通过 层层递进 的方式,揭示了为什么必须重新设计NCCLX:
- 上层 :ML框架的流量模式变得 多维、并发、动态 (TP/PP/EP/FSDP同时存在)
- 中层 :现有通信库 各自为政 (NCCL简单粗暴,NVSHMEM生态不兼容),无法满足统一需求
- 底层 :网络拓扑的 异构性 (延迟差异30倍)和 规模 (10万卡)放大了所有问题
NCCLX的设计哲学 :
- Host-driven :解决灵活性和生态兼容性问题
- Zero-copy :解决资源冲突和延迟问题
- CTran :解决异构网络下的流量工程问题
- 工具链 :解决超大规模下可观测性和可运维性问题
NCCLX Communication Stack Overview
NCCLX的核心目标是为多样化的应用模型需求和多样化的网络后端提供高性能、可扩展且可定制的集体通信框架,同时让通信开发者更容易编程。
NCCLX在PyTorch层之下运行,管理训练和推理过程中的所有通信。NCCLX为用户提供了丰富的通信语义选择,分为三种执行模式:Host-initiated APIs, Host-initiated APIs with GPU-resident metadata, and Device-initiated APIs。每种模式都支持集体通信、点对点通信和远程内存访问(RMA)操作。
- 三种执行模式的本质区别 :
- Host-initiated APIs :传统模式。CPU调用API,所有参数(buffer指针、数据类型、操作类型)都在CPU内存。适合静态、大消息的集体通信(如FSDP的AllGather)。不过消除了 CPU 和 GPU 直接不必要的同步
- Host-initiated APIs with GPU-resident metadata :混合模式。CPU发起调用,但关键参数(如send_counts)放在GPU显存。这样GPU kernel可以在运行时动态修改这些参数。这是解决MoE动态路由决策的关键(6.1节详述)
- Device-initiated APIs :纯设备模式。GPU kernel直接调用通信原语,无需CPU参与。类似NVSHMEM,适合需要极致低延迟的小消息场景(如推理中的AllToAll),利好自定义 kernel 的需求 [1]
- 支持三种语义 :collective(AllReduce)、P2P(send/recv)、RMA(put/get)。RMA是MPI-2的概念,允许单边操作(一个GPU直接读写另一个GPU的内存),在TP重叠中非常有用。
CTran 传输框架 :该框架遵循host-driven通信框架的设计原则,在可能的情况下推广零拷贝和无SM通信。与NCCL的kernel-driven本质区别。NCCL每次通信都启动CUDA kernel占用SM资源,而CTran用CPU后台线程调度RDMA,GPU kernel只负责流同步(stall)
CTran在四个方面进一步扩展了基线NCCL:
- 首先,CTran通过统一的通信框架支持所有三种执行模型;
- 其次,CTran支持多种通信算法,不仅包括具有基于拓扑优化的标准集体通信和零拷贝P2P,还包括自定义集体通信(例如容错)和远程内存访问(RMA);
- 第三,虽然提供NVLink、InfiniBand/RoCE(IB)和socket后端以通过不同的硬件例程支持底层通信原语,但特别为RoCE后端提供了高级负载均衡解决方案(DQPLB,Dynamic QP Load Balancing,RoCE基于以太网,缺乏IB的端到端流控,容易在交换机缓冲区堆积,DQPLB通过限制每个连接的未完成消息数,避免流量突发);
- 最后,通信关键路径经过高度优化以最小化软件开销,从而确保在小消息场景下的低延迟。例如,对小消息场景,CPU软件开销占比极高。CTran通过内联函数、批量提交、快速路径等,将每消息CPU开销从μs级降到100ns级。
当模型层调用NCCLX通信时,NCCLX将通信分派到基线NCCL或CTran代码路径。对于自定义通信操作(例如RMA、GPU驻留集体通信),这些在基线NCCL中没有实现,它们直接分派到CTran。对于经典的NCCL集体通信和点对点通信,我们允许用户通过环境变量显式选择底层基线或CTran算法。在部署到准备运行的模型时,我们经常将NCCLX与离线自动调优结合使用,以便可以自动选择最优算法。
CTran: The Custom transport in NCCLX
使用 NCCL 在 Llama4-scale 规模下进行训练时有两个根本性限制: kernel-driven 的设计 和 copy-based 的数据传输 。而 Meta 开发的 CTran 解决了这些限制——基于 zero-copy 和 SM-free 的通信,并且是 host-driven 的算法框架。
- “内核驱动设计”指什么? NCCL的通信逻辑在CUDA kernel中执行。每次AllReduce都要启动kernel,占用SM资源做数据拷贝、规约、网络收发。这就像让工厂里的技术工人(SM)既要做产品(计算)又要搬运货物(通信),效率低下
- “基于拷贝的数据传输”指什么? 数据从用户buffer→NCCL内部FIFO→网络→对端FIFO→目标buffer,多两次device-to-device拷贝(图4a)。这不仅消耗HBM带宽(600GB/s),还导致Pipeline难以优化
- “无SM通信”如何实现? 对于纯网络传输,CTran用CPU线程提交RDMA;对于NVLink传输,用GPU的Copy Engine(复制引擎)。H100的Copy Engine是独立硬件单元,不占用SM资源
Host-driven customization
在NCCL中集合通信算法大多在CUDA内核内执行,内部RDMA操作由主机代理线程调度,因此称之为 kernel-driven、host-initiated 的模式。CTran 与之不同,采用 host-driven 的框架来实现 host-initiated 的集合通信,具体来说:CTran为每个通信器启动一个专用的 CPU后台线程 ,当用户程序调用NCCL集体通信时,CTran在CPU线程上调度集体算法,同时在用户指定的流上启动一个stall kernel(该stall内核确保通信遵循流排序语义),内核与CPU端算法之间的同步通过通信开始和结束时使用的主机锁定标志(host-pinned flag)实现轻量级同步。协调机制具体如下图:
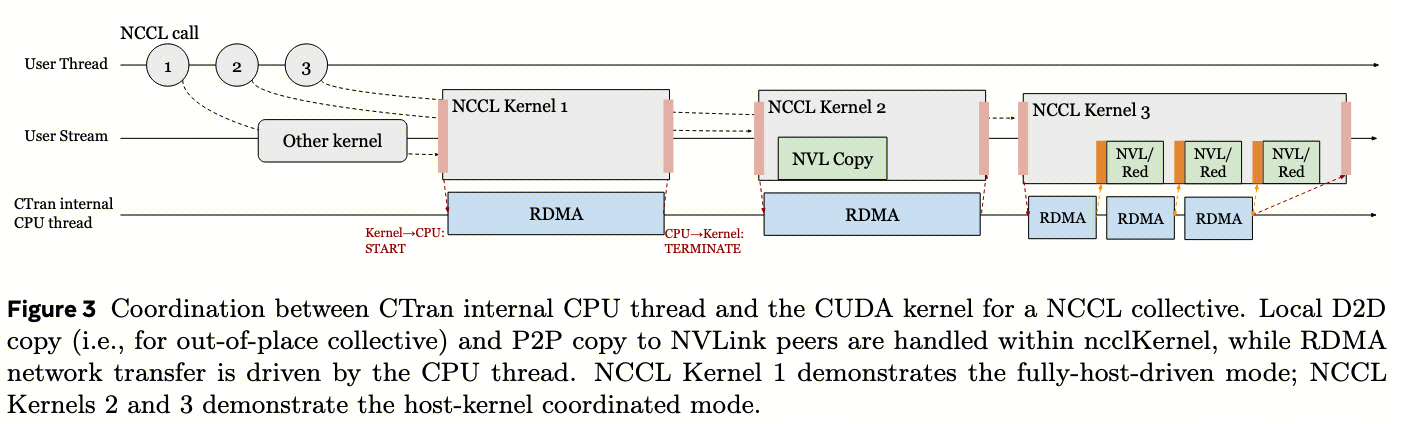
- CPU后台线程机制 :每个NCCL communicator(通信域)对应一个pthread。当调用
ncclAllReduce()时:- CPU主线程把请求加入队列,通知后台线程
- 后台线程解析参数,计算网络拓扑,决定算法(Ring/Tree/Bruck)
- 后台线程批量提交RDMA work request到网卡
- 同时启动一个极简GPU kernel(stall kernel),只做一件事:等待通信完成
- Stall kernel的巧妙之处 :它看起来像普通CUDA kernel,因此遵守CUDA stream语义(前面kernel没完成它不会启动)。但它内部几乎不干活,只轮询host-pinned flag。这确保了:
- PyTorch的stream依赖关系自动生效
- 不占用SM资源(只占1个warp或更少)
- CPU可以通过flag精确控制GPU的等待/继续
CTran 可以做到:
- 快速部署用于大规模训练的经典集体算法,这些算法可以在训练流水线中隐藏通信时间——4.3.2 节
- 与模型算法共同设计自定义通信例程,包括用于TP的细粒度计算-通信流水线——4.4 节
CTran 的三种协调模式:
- 对于仅涉及网络数据传输的集体通信(例如,FSDP中的仅节点间AllGather,PP中的点对点通信),每个RDMA操作可以直接从CPU线程发布,无需与内核侧进行任何同步,显著降低了中小消息大小集体通信的延迟。这种通信模式被其归类为 完全主机驱动模式 (fully-host-driven mode)。图3中的NCCL Kernel 1演示了这种模式。
- 对于需要网络和NVLink数据传输的集体通信,我们扩展调度框架以支持 主机-内核协调模式 (host-kernel-coordinated mode)。例如,如果没有依赖关系,内核将直接执行NVLink拷贝,同时CPU端执行RDMA。MoE 模型中的AllToAll就属于这种模式(见图3中的NCCL Kernel 2)。
- 对于具有特定操作依赖关系的算法(例如,DP中的节点间AllReduce,其中内核中的reduce和网络RDMA是流水线的;详见第5.3节),内核和CPU线程通过从主机锁定内存分配的轻量级生产者-消费者标志进行同步。图3中的NCCL Kernel 3说明了这种模式(不妨称为 主机-内核流水线模式 ,host-kernel pipeline mode,GPU kernel 做 reduce,CPU 线程做 RDMA,通过 flag 同步)。我们测量到同步开销始终小于一微秒,即使在复杂的流水线算法中也可以被隐藏。
- “同步开销<1μs” 是量化结果。host-pinned内存的PCIe延迟约500ns,CPU写flag后GPU通过PCIe读到,总开销在亚微秒级。相比AllReduce的整体延迟(ms级),可忽略
Zero-copy data transfer
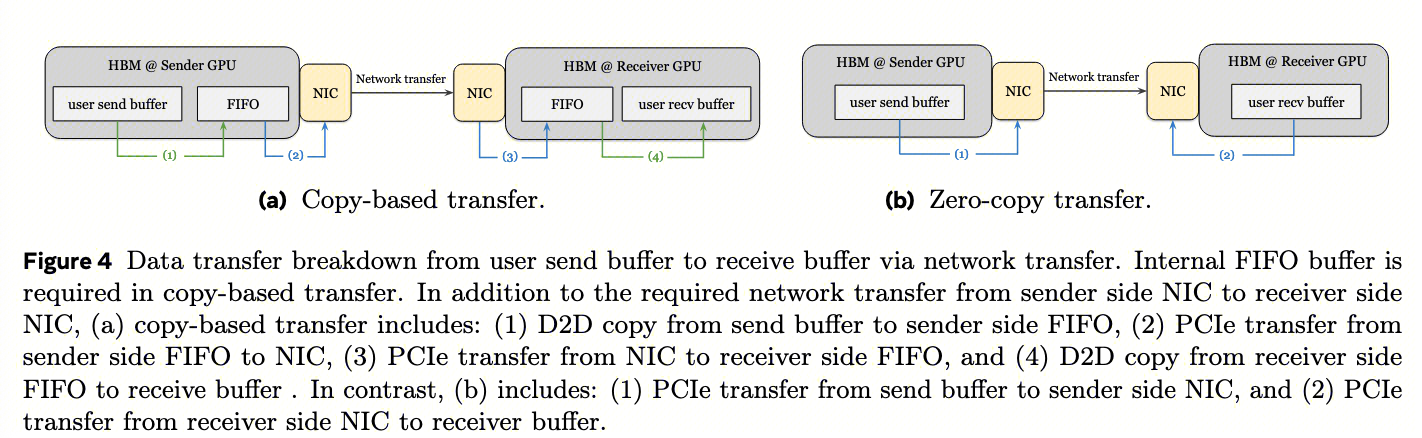
NCCL 的 copy-based 数据传输机制 :如图 4a 所示,该机制需要在发送方和接收方都进行额外的设备到设备拷贝(步骤 1 和 4)。
- 具体步骤描述:为了启动传输,发送方rank将数据从用户缓冲区复制到预注册网络的NCCL内部’FIFO缓冲区’中,然后通过RDMA将数据从发送方的FIFO缓冲区传输到接收方的相应FIFO缓冲区,最后,接收方rank将数据从其FIFO缓冲区复制到目标用户缓冲区。在NVLink域内的GPU之间也采用了类似的基于拷贝的数据传输方法。
- 请注意,用户缓冲区与FIFO缓冲区之间的拷贝操作(图4a中的步骤(1)和(4))由集体内核的流处理器(SMs)处理,并利用高带宽内存(HBM)带宽。相比之下,PCIe传输(步骤(2)和(3))由NIC的DMA引擎执行,由内部CPU代理线程的RDMA请求触发。因此,这些PCIe传输不需要GPU的参与。
copy-based 传输机制在数据分块、流水线化中的复杂性 :由于在设备内拷贝带宽显著高于网络或NVLink传输速度,为了将高速的 D2D 拷贝与低速的网络传输 overlap,故而基于拷贝的数据传输方法需要细粒度的数据分块和流水线化。 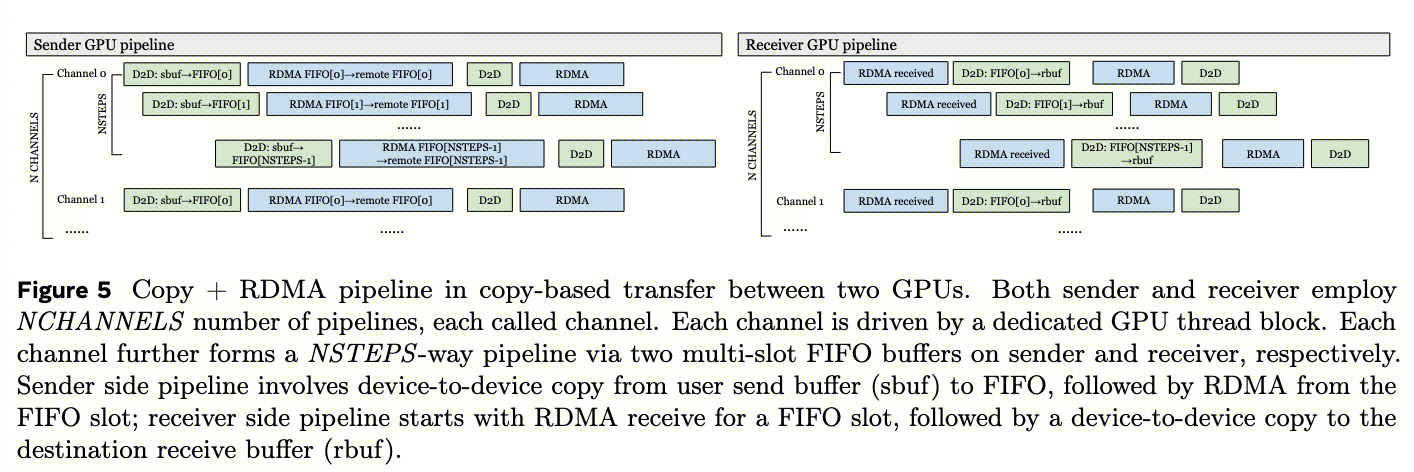 图5说明了两台GPU之间基于拷贝的send-receive操作的拷贝-RDMA流水线。该流水线存在三个限制:
图5说明了两台GPU之间基于拷贝的send-receive操作的拷贝-RDMA流水线。该流水线存在三个限制:
- 首先,基于拷贝的方法 消耗GPU计算资源 (SMs) 和HBM带宽 用于用户缓冲区与FIFO缓冲区之间的拷贝操作。这会导致与并发计算的资源争用,并导致性能下降,迫使用户在通信和计算之间权衡资源。每个channel(线程块)占用1个SM block(640 threads),10个channel就占10个SM。H100共144个SM,通信占7%,计算吞吐量下降5-10%。Copy-based必须把数据切成128KB-512KB小块才能pipeline。对于跨DC的150μs延迟,512KB chunk只能达到512KB/150μs=3.4GB/s,远小于50GB/s带宽上限
- 其次,这种方法 需要将数据分段并通过多个RDMA请求传输 ,以建立copy-RDMA流水线。此过程需要在每个流水线阶段进行GPU-CPU同步,更重要的是,将每个RDMA操作限制为单个数据块。因此,它限制了网络利用率,并且难以实现完全的网络饱和,特别是在高延迟环境(例如跨AI区域或跨数据中心建筑场景)中。
- 最后,每个流水线由专用线程块管理,称为’通道’(Channel)。 流水线与线程块之间的这种静态绑定要求为每个独立流水线分配单独的FIFO缓冲区 。因此,增加线程块的数量以加速集体操作会导致更高的GPU内存消耗(参见第7.2节关于内存使用的讨论)。每个channel需要独立的FIFO buffer。64个channel × 2MB FIFO = 128MB浪费。10个并行组就是1.28GB
为了解决这些基本限制,具有零拷贝和无SM通信设计的CTran栈应运而生。现代GPU系统,例如NVIDIA H100,支持通过InfiniBand/RoCE网络和NVLink域在用户缓冲区之间直接数据传输(即,NIC直接读写GPU 显存) 。图4b说明了零拷贝传输中涉及的数据移动。
使用零拷贝,整个数据可以直接卸载到网络传输层(图 4b 的步骤 1,此时不需要 SM 参与),无需通过内部FIFO缓冲区进行额外拷贝。
zero-copy 如何解决 copy-based 的三个限制:
- 无SM占用 :CPU线程通过ibv_post_send提交RDMA,网卡DMA直接读写用户buffer。GPU SM完全不参与数据传输
- 大消息优势 :可以一次性提交100MB消息,网卡自动分片成多个MTU(4KB)包。RDMA的可靠性由网卡硬件保证,无需应用软件层面的ACK
- 内存效率 :不需要FIFO buffer,节省显存
zero-copy 设计的优点:
- 最小化了并发通信和计算之间的资源争用 。对于仅网络的集体通信,我们直接从用户源缓冲区到目标缓冲区发出RDMA操作,消除了内核参与的需要。对于NVLink域内的集体通信,我们在可能的情况下通过自定义面向用户的API利用CopyEngine。
- 虽然零拷贝是传统HPC CPU通信中成熟的优化技术,但在PyTorch生态系统中实现高效的GPU缓冲区注册而不产生明显开销带来了独特挑战——Zero-copy需要用户buffer被注册(pinned并建立物理地址映射)。PyTorch的内存分配器是动态、异步的,tensor的生命周期由Python GC管理。NCCLX必须与PyTorch的Cache Allocator深度集成,才能实现透明注册
- 促进了灵活的网络配置和优化 。使用零拷贝,整个数据可以卸载到网络传输层,无需通过内部缓冲区进行额外拷贝。网络传输层然后可以决定将数据拆分为多个RDMA包,并分配给多个QP以实现网络流量平衡。在这种情况下,算法层不需要流水线化,CPU线程通过考虑网络饱和度来处理RDMA包拆分(参见第4.4节中的流量负载均衡细节)。
CTran Design details
Tensor registration management for zero-copy
对于零拷贝操作,用户缓冲区需要注册以支持NVLink或网络直接传输。考虑到模型应用中的隐式生命周期管理,这颇有难度,需要与 PyTorch 的内存分配器共同设计:
具体来说, 网络缓冲区注册 通常需要 low-level 的网络驱动程序识别发送和接收缓冲区的物理地址范围,以便NIC能够访问它们。此过程通常涉及在内核级别进行物理页查找和锁定
- 注册(Registration)的本质 :RDMA网卡需要知道GPU显存的物理页地址和权限。操作系统要把虚拟地址翻译物理地址,并锁定页面防止被swap out。常见的 LLM 工作负载中,中等大小缓冲区的注册开销通常在100μs-1ms之间
- 100ms延迟异常 :作者发现真实场景中注册GPU缓冲区时,我们观察到了显著的注册时间峰值,偶尔会延长至100毫秒,GPU驱动(nvidia-peermem)有全局锁。当多个进程同时注册时,会串行化等待。这在10万卡集群上是大问题(可能同时有上千个进程注册)
考虑到开销问题,Meta扩展了PyTorch中的CUDA缓存分配器(CCA),提供了两种注册模式:
- 第一种模式是 自动注册 ,其中PyTorch后端跟踪并缓存分配器分配的所有CUDA segment。“张量缓存”在CTran栈内管理,通过扩展ncclCommRegister API实现。CTran仅在调用ncclCommRegister时缓存这些跟踪的张量地址。张量的实际网络注册仅在首次在集体通信中使用时发生。称之为” 延迟注册 ”
- 优点 :对PyTorch用户完全透明。分配tensor时自动注册,第一次使用时完成实际注册
- 缺点 :依赖PyTorch CCA的segment复用。理想情况下,相同的物理地址范围将频繁用于通信调用,从而使初始缓冲区注册成本可以忽略不计。但如果内存碎片严重(模型经常使用CCA的可扩展段模式时,此模式允许将已分配的物理内存范围重新映射到不同的虚拟地址空间以管理碎片),物理地址频繁变化,会导致反复注册(例如 PP 中高内存使用率时,可能触发频繁重映射,导致重复通信调用(send/recv)使用不同的物理内存范围)
- 适用场景 :适用具有常规内存使用模式且没有高内存压力的训练阶段(例如每个训练步骤开始时FSDP的AllGather),每步使用相同大小的buffer,物理地址稳定
- 为了减轻频繁的注册开销,Meta实现了 内存池模式 。即,预分配和注册一个大型内存池,所有通信张量都从中分配
- 优点 :注册一次,终身使用。物理地址永不变化
- 缺点 :需要从计算显存中划出固定区域,如果通信池太大,留给模型的显存变少;还需要显式标记要从这个独立池分配的张量,虽然CUDA Graph可能潜在地自动化张量关系理解和标记,但其部署带来了单独的挑战,尚未在Meta的预训练工作负载中启用
- 增强 :当模型显存Out-of-Memory时,可以从通信池”偷”空间。这需要修改PyTorch CCA逻辑(修改PyTorch的CUDA allocator源码(torch/csrc/cuda/allocator.cpp),实现hook机制,已合并到PyTorch主分支)
Diverse collective algorithms at host CPUs
DP域中的AllGather和ReduceScatter集体通信在大规模工作负载中面临严峻挑战,因为跨CTSW和跨zone网络域的网络延迟很高(见2.3节的网络拓扑)。直到NCCL 2.23版本引入PAT算法之前,NCCL仅有Ring算法。为了在我们的早期大规模训练中在PAT可用之前解除阻塞,我们移植了延迟优化的Brucks和Recursive Doubling算法用于AllGather,递归向量减半距离加倍算法用于ReduceScatter,以及Tree算法用于Broadcast。得益于CTran的主机驱动框架,移植经典CPU通信算法变得简单直接。
- Ring 算法的缺点 :延迟高且传输量大。Ring算法的复杂度是O(N),在10万卡下需要10万步才能传递完数据。AllGather的消息量是N×M(M是每卡数据量),Ring总传输量是(N-1)×M,对于64K卡×1GB数据=64TB传输量,不可接受
- Bruck AllGather :复杂度O(log N)。每轮i,每个节点与距离2^i的节点交换数据。64K卡只需16轮,但每轮数据量翻倍。适合小消息
- Recursive Doubling AllGather :类似Bruck,但数据移动模式不同。每轮后,每个节点拥有2^i倍的数据
- Recursive Vector-Halving ReduceScatter :ReduceScatter的反向操作。每轮数据量减半,适合大消息
- Tree Broadcast :二叉树传播,复杂度O(log N)
- Host-driven的优势 :这些算法原本为MPI设计,运行在CPU上。NCCL的kernel-driven架构难以实现(CUDA kernel内不能做复杂逻辑和循环)。CTran的CPU线程可以轻松实现这些算法逻辑
CTran and network co-design
在超过100K GPU的规模下,GPU到GPU的 通信延迟随着网络跳数显著增加 ,基线NCCL内的两阶段拷贝机制进一步放大了网络延迟的影响。在此机制中,从接收方到发送方的clear-to-send控制消息被置于关键路径上,因此,当最内层并行层的延迟敏感集体通信穿越跨DC链路时,训练性能会遭受显著降级。即使通常对网络延迟更具容忍性的DP集体通信,在使用基线NCCL时也会受到不利影响。为了克服这些限制,我们在本节中引入了几项优化。
- 如 4.1 节所述,为了缓解两阶段拷贝解决方案的高控制消息延迟,实现了 zero-copy 集体通信。这些使NIC能够在源和目标缓冲区之间执行RDMA,消除了集体库中的中间缓冲区,并避免了额外的GPU-GPU拷贝。因此,GPU到GPU交换只需要从接收方到发送方的单个控制消息,显著减少了网络往返次数。
- 减少了多少网络往返次数?一半! 两阶段拷贝机制,NCCL为了防止overrun,采用”发送方等待接收方ready”的协议:发送方把数据拷到FIFO,发控制消息”我有数据要发”;接收方收到控制,把FIFO地址发给发送方;发送方通过RDMA写数据到对端FIFO;接收方把数据从FIFO拷到用户buffer;这导致2次RTT延迟(控制+数据),严重影响小消息性能。Zero-copy的单控制消息:接收方提前把接收buffer地址注册好并广播给所有发送方。发送方只需等待接收方”ready”信号(一次性),就可以直接RDMA写数据到对端用户buffer
- 零拷贝通信的一个 缺点 是,整个消息一次性移交给网络硬件, 完全依赖网络结构进行流控和拥塞控制 。这种方法不适合我们的拥塞控制策略。如先前工作(RoCE,Gangidi等人,2024)所述,我们不采用传统的拥塞控制机制(如DCQCN,DCQCN 收敛慢,不适合训练时的突发流量)来限制交换机缓冲区占用。相反,Meta使用深缓冲区的交换机(几百 MB)吸收瞬态突发,并利用集体库中的接收方驱动流控(receiver-driven flow control)来防止持续性拥塞。然而,零拷贝通信减少了接收方反馈的机会,增加了单次发布较大消息的可能性,可能导致网络过载和过多的缓冲区累积。我们的评估证实了这一分析: 仅使用零拷贝通信会导致次优性能。相比之下,基于拷贝的通信由于临时缓冲区大小限制,固有地将数据分割成较小的块,从而提供了隐式的流控 。
- 为了结合两种方法的优势,我们 采用零拷贝通信,同时在内部将数据划分为较小的消息段,并限制在途段的数量 。为此,我们开发了动态队列对负载均衡(DQPLB)技术,这是CTran内的一种设计,用于在每个连接和每个拓扑的基础上配置未完成数据的数量,允许跨DC或跨AIZone链路设置更高的限制,其中带宽延迟积(BDP)大于AIZone内或机架内链路。这种细粒度控制能够更有效地管理缓冲区累积。与先前工作中的网络负载均衡改进(RoCE,Gangidi等人,2024)和脊交换机虚拟输出队列(VOQ)调优相结合,与Llama3训练相比,我们在Llama4使用的RoCE网络中将交换机缓冲区累积减少了一个数量级——Llama3训练时交换机缓冲区瞬时占用可能达到100MB,导致丢包和重传。Llama4通过DQPLB降低到10MB,显著降低队头阻塞。
[! note] DCQCN 的缺陷与 Meta 方案的对比
DCQCN的核心缺陷在10万卡规模下会被放大:
- 收敛时间不可接受
- DCQCN的AIMD(加性增、乘性减)算法需要 RTT×N 时间收敛。跨DC的RTT=150μs,若发生拥塞,从检测到降速到恢复可能需要 数十至数百毫秒 。而Llama 4的训练迭代步长仅几百毫秒,一次拥塞可能导致 整次迭代失败 (由于同步等待)。
- 论文引用的Gangidi et al., 2024是Meta自己的RoCE网络部署经验,文中明确指出:“DCQCN的收敛时间在跨数据中心链路中超过10ms,导致训练吞吐量下降5-8%。”
- 配置与运维复杂度
- DCQCN需要精确调参(AI, MI, KMAX, KMIN等),且不同网络层级(机架/Zone/DC)需不同配置。10万卡集群涉及 数千台交换机 ,配置一致性和版本管理是噩梦。
- ECN标记需要端到端支持 :跨建筑链路可能租用运营商光纤,中间设备不支持ECN标记,导致机制失效。
- 与集体通信模式不匹配
- DCQCN设计用于通用流量,而 集体通信是burst-on/off模式 。比如AllReduce是”所有节点同时发→同时结束”,DCQCN可能在流量结束后才完成降速,反而影响下一轮。
深缓冲区+接收方流控的优势:
- 确定性 :接收方基于本地队列深度直接限流, 无收敛过程 。软件控制每个连接的未完成消息数(S+C),网络缓冲区占用完全可预测(论文提到”reducing switch buffer build-up by an order of magnitude”)。
- 可软件定义 :DQPLB的参数(QP数、未完成消息上限)可通过环境变量动态调整,无需交换机重启。Meta可以快速实验不同策略。
- 硬件成本更低 :Meta使用 标准以太网交换机 ,仅需支持PFC(Priority Flow Control)防丢包,无需昂贵的ECN-capable ASIC。深缓冲区(几十MB per port)是现代数据交换机的标配。
DQPLB Design
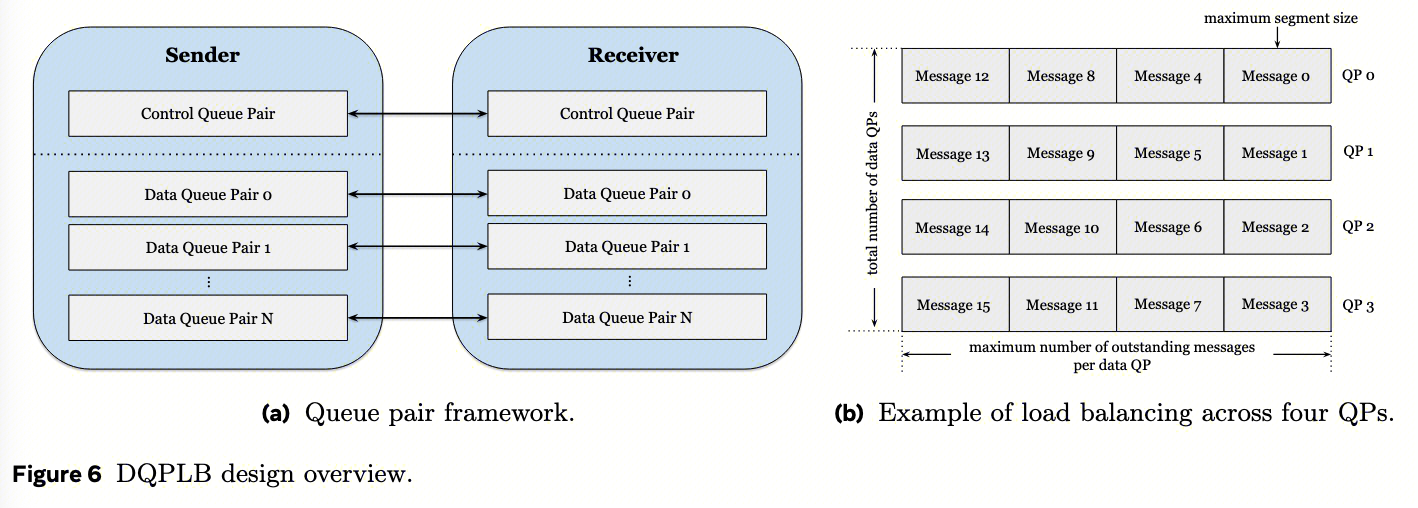
如图6a所示,DQPLB使用一个控制QP和多个数据QP。控制QP负责在集体操作开始时交换内存地址,而数据QP通过scale-out进行数据传输,这是DQPLB负载均衡机制的核心。
- 控制QP与数据QP分离 :控制QP走可靠连接,传输元数据(buffer地址、大小、密钥),轻量、低频;数据QP:走不可靠连接,传输实际数据,需要负载均衡和流控
- 数据QP的数量可配置 ,可根据网络拓扑和性能要求进行调整。我们的观察表明,使用零拷贝通信时,允许端点发送无限数据并不总能产生最佳性能。相反,限制每个连接的总未完成数据量有助于减少结构中的拥塞并加快集体通信完成速度。因此,如图6b所示,我们按连接类型限制数据QP的总数、每个数据QP的最大未完成(未确认)消息数以及最大段大小。
DQPLB定义了 四类连接类型 :同一机架内、同一区域内跨机架、同一DC内跨区域以及跨DC。基于GPU的相对接近程度,为每个连接调整未完成消息限制。 对于较近的连接,使用更保守的设置以适应较低的BDP (如果太多未完成消息会加剧 NVLink 竞争)。相反,对于远距离连接,采用更激进的配置——例如更多的数据QP和更高的最大未完成消息数——以更好地利用更高的网络BDP(BDP 大意味着容忍更多的 in-flight 未完成消息,避免停等浪费带宽)。
| 连接类型 | 延迟 | BDP | 数据QP数 | 每QP未完成消息 | 最大段大小 | 策略逻辑 |
|---|---|---|---|---|---|---|
| 机架内 | 5μs | 0.3MB | 1-2 | 1-2 | 1MB | 保守,避免NVLink拥塞 |
| 跨机架同Zone | 35μs | 2MB | 4-8 | 2-4 | 4MB | 适度并发 |
| 跨Zone同DC | 75μs | 4MB | 8-16 | 4-8 | 8MB | 激进,填充管道 |
| 跨DC建筑 | 150μs | 8MB | 16-32 | 8-16 | 16MB | 最激进,充分利用带宽 |
[! note] QP 及相关数据的来源
表格中 QP 相关的数据是推导,并非原文披露。这些数字是基于以下约束推导的:
- 机架内 :NVLink带宽600GB/s,RoCE网卡400Gbps,不是瓶颈。保守用1-2个QP避免浪费NIC资源
- 跨Zone :可用带宽受限于ATSW的上联。假设1:2.8收敛比,有效带宽约140Gbps。需要8-16个QP才能饱和
- 跨DC :延迟最高,BDP最大,需要最多QP填充管道。但受限于QP总数,分配16-32是合理折中
DQPLB Operation
DQPLB通过利用 序列编号 、 即时数据编码 和 乱序消息跟踪 ,在多个数据QP上实现有序消息传递。
- DQPLB的 动态分配 :以轮询方式将消息分发到数据QP,当数据QP的待处理工作队列达到其配置的限制时,消息传输将暂停直到在相应的完成队列(CQ)上接收到完成队列元素(CQE);接收到CQE后,系统恢复并为该QP发送工作队列元素(WQE)。这种动态分配使网络争用较低的QP能够更有效地传输数据,使它们能够处理更大的流量负载。
- 为了确保有序消息传递,DQPLB维护 两个序列计数器 :发送方跟踪要传输的下一个序列号,而接收方跟踪下一个期望的序列号。
- 在DQPLB模式下传输消息时,发送方使用IBV_WR_RDMA_WRITE_WITH_IMM操作码进行InfiniBand发送操作,而不是标准的IBV_WR_RDMA_WRITE。这使得可以 在32位即时数据字段中嵌入控制信息 :位0-23编码顺序消息编号,位30表示快速路径使用(稍后详细解释),位31用作多包消息最后写入的通知标志。当消息超过最大段大小时,它会被划分为多个WQEs,每个分区分配连续的序列号;只有最终片段在即时数据字段中标记通知位。
- 在接收方,算法 通过检查传入消息的即时数据来提取序列号和通知标志,从而支持乱序传递 。序列号超出下一个预期值的乱序数据包会暂时存储在按序列号索引的哈希映射中,布尔值指示每个数据包是否携带通知标志。然后算法应用滑动窗口协议,持续检查下一个预期序列号的到达;当它被接收时,算法处理它以及存储在哈希映射中的任何后续连续数据包,为标记有通知标志的那些递增通知计数器,并从哈希映射中删除已处理的条目。这种方法确保仅在序列中所有先前消息都已接收后才触发通知,从而在由于跨多个数据QP分布而导致数据包乱序到达时保持严格的有序语义。
序列号机制保证可靠传输
DQPLB在应用层实现可靠传输,替代了RoCE的不可靠连接+重排序开销。每个消息有24位序列号,因此计数器支持1600万消息不绕回。
1600 万消息不不绕回并非说全局不绕回,而是有 per-QP 重置、滑动窗口大小限制等机制来保护。否则根据估算,以Llama 4 405B,64K GPU为例,每步通信时:
- FSDP AllGather :每层1次 × 80层 = 80次/卡。每步总量 = 64K卡 × 80 = 512万次RDMA操作
- TP AllGather :每层7次 × 80层 = 560次/卡。但TP通常限制在8卡一组,跨节点RDMA次数 = (64K/8) × 560 = 448万次
- MoE AllToAllv :每层1次 × 80层 = 80次/卡。总量 = 64K × 80 = 512万次
- 其他(PP send/recv等) :约 100万次
总计 ≈ 每训练步 1500万次RDMA写操作
DQPLB还包含 针对高频操作的快速路径优化 ,使消息能够绕过多QP分发,直接在专用的数据QP(通常是数据QP 0)上发送。在接收方,这些消息通过直接递增接收下一个序列计数器和更新通知计数器来处理,无需乱序跟踪(哈希表和滑动窗口逻辑)。快速路径最小化了每个RDMA操作的CPU开销,特别适用于具有多个小到中等RDMA操作的算法,例如推理用例(参见第6节)。
Evaluation for Zero-copy
这里对点对点通信进行基准测试,并将其与基线NCCL中的基于拷贝方法进行比较。零拷贝点对点通信涉及接收缓冲区地址交换(即握手),以及从发送方到接收方的数据传输,遵循经典的会合协议。由于每次集体通信只需一次缓冲区交换,并且如果缓冲区被显式重用(例如,在推理用例中使用CUDA Graph,参见第6节)可以进一步优化,因此将握手耗时从报告数字中排除。
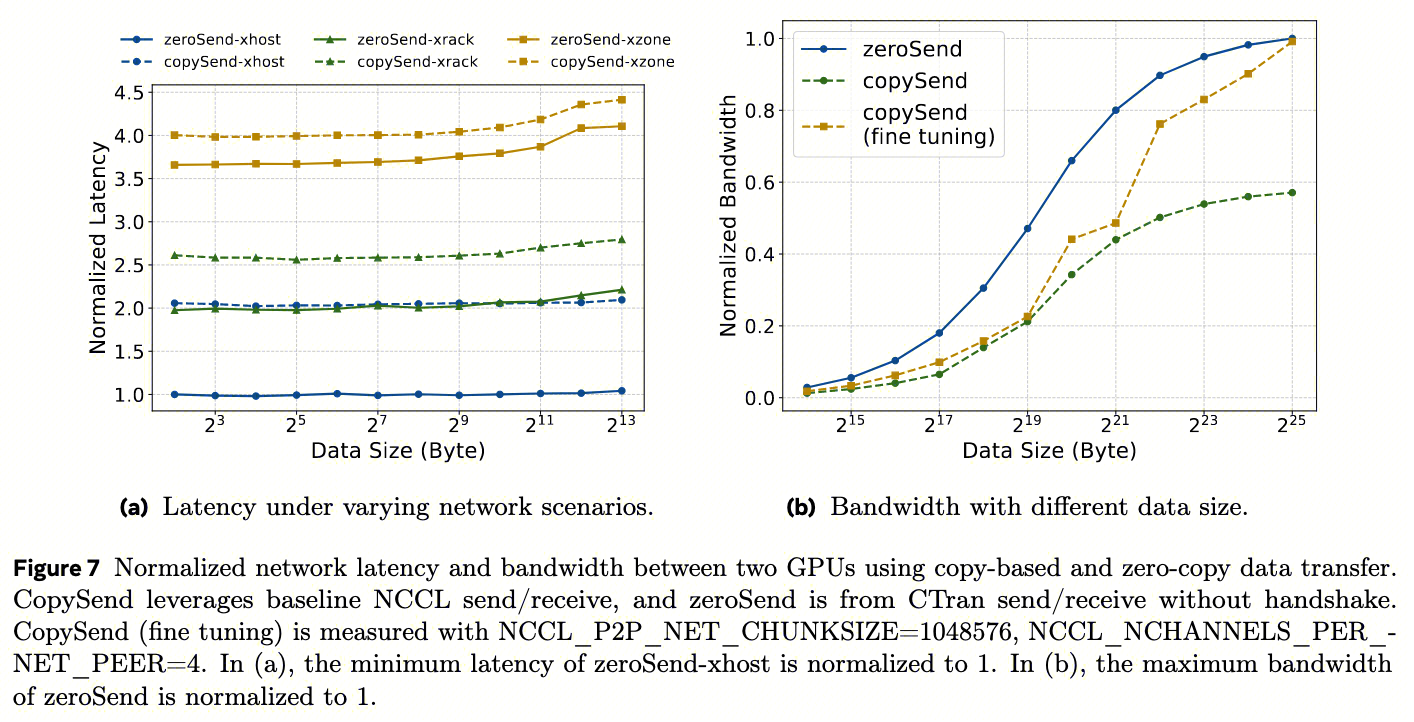
图7a和图7b分别比较了跨节点GPU之间使用零拷贝和基于拷贝数据传输的延迟和带宽。对于延迟,我们进一步详细列出了跨主机、跨机架和跨区域在Meta DC中的结果。
显然,
- 基于拷贝的方法由于额外的拷贝而引入了每次传输的恒定延迟开销 。在跨主机设置中,这种开销甚至可能使整体数据传输时间增加2倍。
- 如图7b所示, 拷贝还由于算法级别的分块而损害大消息带宽 。zero-copy可以发大消息,让网卡自动分片,充分填充电缆和交换机;copy-based的chunk大小受限,pipeline不能充分填充长延迟管道,即使在仔细的NCCL超参数微调之后,也无法为中消息大小实现合理的网络性能。此外, 这种微调性能只能在基准测试级别实现,而在生产使用中不实用 。这是因为某些超参数必须全局应用,可能会降低同一模型中其他集体通信的性能。例如,NCCL_P2P_NET_CHUNKSIZE控制copy块大小,调大确实能提升带宽,但会影响MoE AllToAll。因为AllToAll需要频繁切换,大块会导致内部buffer频繁重分配,反而增加延迟。
Large-scale Training Customization
PP: Zero-copy and SM-free Send/Recv
PP 通信特征:
- 跨长距离 :PP将模型的层分布在多个GPU设备或节点上,这种配置使得不同的micro-batch在遍历模型的各个阶段时同时进行前向传播和反向传播。PP大量使用了P2P的发送和接收操作,这些操作经常跨越CTSW层级,甚至可能穿越AIZone。因此,要在这些跨层级的通信路径上实现低延迟通信,优化是必不可少的。
- 跨层级高延迟导致的带宽下降 :PP跨层发送,比如Stage 0在第1个Zone的机架A,Stage 1在第2个Zone的机架B,数据路径: GPU0 → RTSW → CTSW → ATSW → CTSW → RTSW → GPU1 ,延迟可达150μs。128KB块的理论带宽=128KB/150μs=0.85GB/s,远未打满400Gbps(50GB/s)。
- 与计算 kernel 紧密交错 :PP中的通信通常紧随其后的就是并发的计算内核(例如GEMM)。在这种情况下,网络操作应被调优以最小化其对GPU资源的消耗,从而减少资源争用并提升整体效率。
- 消息大小中等 :1-128MB
使用 基线NCCL 的基于拷贝的发送和接收操作有 两个主要缺点 :
- 首先,基于拷贝的方案将数据切分为小块(128KB-512KB),这不足以掩盖数据中心网络的高延迟(在CTSW层级和跨AI区域的延迟比机架内延迟高7到15倍,参见4.4节,BDP 在 2-8 MB)。虽然增大块大小可以缓解这一问题,但由于copy-based 的数据传输流水线利用率差,会导致额外的暂存拷贝开销(详见图5)。这还会增加内部GPU缓冲区的使用量,从而减少模型可用的内存。
- 其次,额外的暂存拷贝需要NCCL内核占用GPU流式多处理器(SMs),通常使用4个线程块,每个块640个线程,用于仅涉及网络传输的发送/接收操作。这种资源占用会拖慢并发的计算内核,例如GEMM。
为了完全避免GPU SM资源的消耗,Meta按照CTran的zero-copy方案重新实现了发送/接收操作:
- CPU 直驱 :在这种方法中,接收方rank的CPU线程与发送方rank交换接收缓冲区的RDMA注册信息,然后,发送方直接从用户发送缓冲区向远程用户接收缓冲区发起RDMA写操作。这使得整个消息传输完全由CPU线程处理,消除了GPU资源的使用,并将完整消息暴露给网络 [^2] 。因此,中等大小的发送/接收操作(数十MB)可以 达到峰值网络带宽 。
- PP发送/接收中使用的用户发送张量和接收张量通常被分配到不同的底层内存地址范围,这在使用张量自动注册模式时会导致较高的启动成本(即,注册所有被触及的段),因此对 PP应用了内存池模型 ,以确保这种启动成本被隐去。
[! NOTE] CPU 如何提交 RDMA 消息到 GPU 显存?
这依赖硬件特性 GPUDirect RDMA 。流程:
- CPU调用
ibv_reg_mr()注册GPU显存,驱动锁定物理页,网卡获得直接访问权限- CPU构建WR(work request),包含源地址(GPU显存物理地址)、目标地址(对端GPU显存)、长度、密钥
- CPU调用
ibv_post_send(),网卡DMA引擎从GPU显存读数据并通过InfiniBand发送
整个过程DMA引擎直接访问HBM,GPU SM不参与。
TP: RMA Put for fine-grained communication and computation overlap
与网络级瓶颈不同,内域集体通信在分布式训练中提出了独特的挑战。
TP的挑战 :
- 数据量大 :在TP中,并行化的最内层维度跨设备划分输入和模型参数,在运行时交换大量数据(每步数十 GB)。
- Overlap困难性 :为了实现高计算效率,需要利用TP重叠来有效重叠计算和通信,并利用SM-free 的数据传输来避免资源争用。
- 传统方案:例如NVIDIA的Transformer Engine(Nvidia, 2025b)、Pytorch Async TP(Wang等人,2024)和Bytedance的Flux(Chang等人,2024)。然而,这些实现仅限于单机环境(张量并行度TP ≤8在H100或更老平台上),因为它们 依赖于CUDA进程间通信 (IPC)。此外,xFormers(Lefaudeux等人,2022)和Flux等解决方案通过利用设备发起的通信实现重叠,这种方法 需要修改GEMM内核 ,可能会降低计算效率,因为自定义内核通常与高度优化的NVIDIA cuBLAS库相比表现不佳。
[! NOTE] CUDA IPC
CUDA IPC允许同一节点内不同进程共享GPU显存指针。跨节点时,显存地址无意义(不同机器的物理内存)。虽然可以用NVLink P2P,但跨节点的NVLink需要复杂的地址翻译和网络桥接,目前仅支持8卡互联。TP>8时必须跨节点,此时CUDA IPC失效。
Meta 的 CTran RMA 方案 :利用 CTran 的组件实现细粒度 TP overlap
- CtranWindow :
- 预注册共享内存,实现单边 Put API :在CtranWindow中,每个rank预先注册一个相同大小的专用内存区域,并将其对应的地址和访问密钥传播给communicator中的所有其他对等节点。这种设计使任何rank都能使用交换的地址和密钥向任意对等节点发起单边Put操作。Put API的实现利用SM-free CopyEngine处理节点内NVL传输,利用RDMA处理节点间通信。
- 双 window 实现双缓冲并发 :在TP overlap中,分配两个CtranWindow以启用AllGather和ReduceScatter阶段的重叠。在AllGather流水线中,窗口缓冲区接收来自其他TP ranks的输入张量(图8b中的X1),允许部分GEMM计算在数据到达后立即开始。类似的流水线在第二个GEMM操作和随后的ReduceScatter阶段中实现。

- Put API :Put API抽象了从发送方源缓冲区到接收方目标缓冲区的数据传输,本质上分别映射到 节点内传输的NVL CopyEngine操作 或 节点间传输的RDMA写操作 。这种抽象通过将拓扑感知的数据移动与高层TP重叠逻辑解耦,增强了自定义模型模块的可编程性。
- Pipeline Algo :得益于CtranWindow和Put抽象的高可编程性,基本的Ring流水线可以扩展到拓扑感知的Tree流水线,通过在后续流水线阶段启用更大的张量计算来提高GEMM效率,同时通过高速NVL块传输掩盖昂贵的跨节点RDMA传输。
- 图8b从2个节点、每个节点4个GPU的TP配置中rank 0的视角说明了树流水线过程。具体来说,在第一步(s1)中,大小为S的块与相邻的节点内rank交换(例如,rank 0和rank 1交换X1[0]和X1[1]),然后对该块执行GEMM操作。在第二步(s2)中,从rank 2传输两个块,使得随后可以对2S大小的张量进行GEMM计算。在s1和s2描述的节点内树交换的同时,第三步(s3)等待从远程节点上的rank 4接收块X1[4]。由于通过RDMA的节点间传输速率比节点内NVL传输慢约8倍,因此在Rank 0上完成所有节点内通信和计算后,才接收到X1[4]。因此,通过每节点设置8个H100 GPU,RDMA块传输的延迟可以通过所有这些节点内操作有效隐藏
- 本质上是优先在节点内(NVLink)传输小数据,跨节点RDMA传大数据以掩盖延迟。节点外RDMA带宽是节点内NVLink的1/8,当每节点8卡时,可用7次节点内操作(~100μs)掩盖1次跨节点操作(800μs)
HSDP: Fault tolerant AllReduce
HSDP 提出的动机 :
- FSDP 无状态冗余的特点无法应对单点故障 :在100K设备的规模下,由于硬件故障训练作业经常停止和重启。为了保持高训练效率(衡量标准为 有效吞吐量 goodput,即有效训练时间与总运行时间之比)——弹性训练至关重要。在DP训练中,由于所有 worker 之间需要同步,所以单个故障会破坏整个DP组。先前的工作在worker具有冗余模型状态时启用了弹性域大小自适应,然而,当前的FSDP方案会跨worker对模型参数和优化器状态进行分片,这使得worker之间没有冗余的模型参数和权重,从而使弹性适应更加困难。
HSDP的方案 :
- 采用二维方法,将 64K 卡分为 16 组 x 4K 卡,在每个内组(副本组)中,使用FSDP对模型参数和优化器状态进行分片,而输入张量跨副本组分布。每个副本组独立训练完整模型,并仅在每步结束时组间通过 AllReduce 同步梯度。
- 此设计允许系统在训练期间容忍部分副本组的梯度丢失,提高整体鲁棒性。当 组内发生故障时,只有受影响的组关闭,而其余组继续训练 (收缩阶段)。一旦故障机器被替换,新的4K-GPU组形成并重新集成到训练中(增长阶段)。
[! NOTE] HSDP 的内存开销
FSDP:64K rank分片,每卡存1/64K权重
HSDP:分16组×4K rank,每卡存1/4K权重,组间冗余16份
内存开销 = 16倍。对于Llama 4 405B(约800GB),FSDP每卡需12.5GB,HSDP需200GB(超过H100的80GB显存)。实际中HSDP与FSDP 混合使用 :最外层HSDP,内层FSDP,平衡冗余与内存。
FTAR (Fault Tolerant AllReduce)实现robust的梯度平均:
- FTAR与全局协调器一起运行,该协调器通过专用网络通道与副本领导者通信。 协调器负责故障检测和动态组管理 。当副本组内的机器发生故障时,协调器识别受影响的组,并指示剩余副本以减少的组大小继续训练(“收缩阶段”)。相反,当新机器可用时,协调器协调这些新机器的重新集成,相应地扩展训练组(“增长阶段”)。
- CTran 这一主机驱动算法框架 简化了故障管理 ,包括从CPU线程管理的超时和错误处理。此框架还便于记录每步计时器和错误日志,这对于了解大规模训练中的性能和故障至关重要
- 鉴于FTAR设计为跨不同zone和DC建筑通信,它们经常遇到高oversubscription和有限bisection带宽的交换机,为了防止网络拥塞, 必须调节FTAR内并发数据包的数量,同时保持网络饱和 。经典Ring算法非常适合此目的,因为每个GPU在环中仅与其两个直接邻居通信,从而最小化并发网络流量
- FTAR受网络带宽限制,因此Meta设计了一个流水线协议,将内核中的copy和reduction与网络RDMA重叠,如图9所示
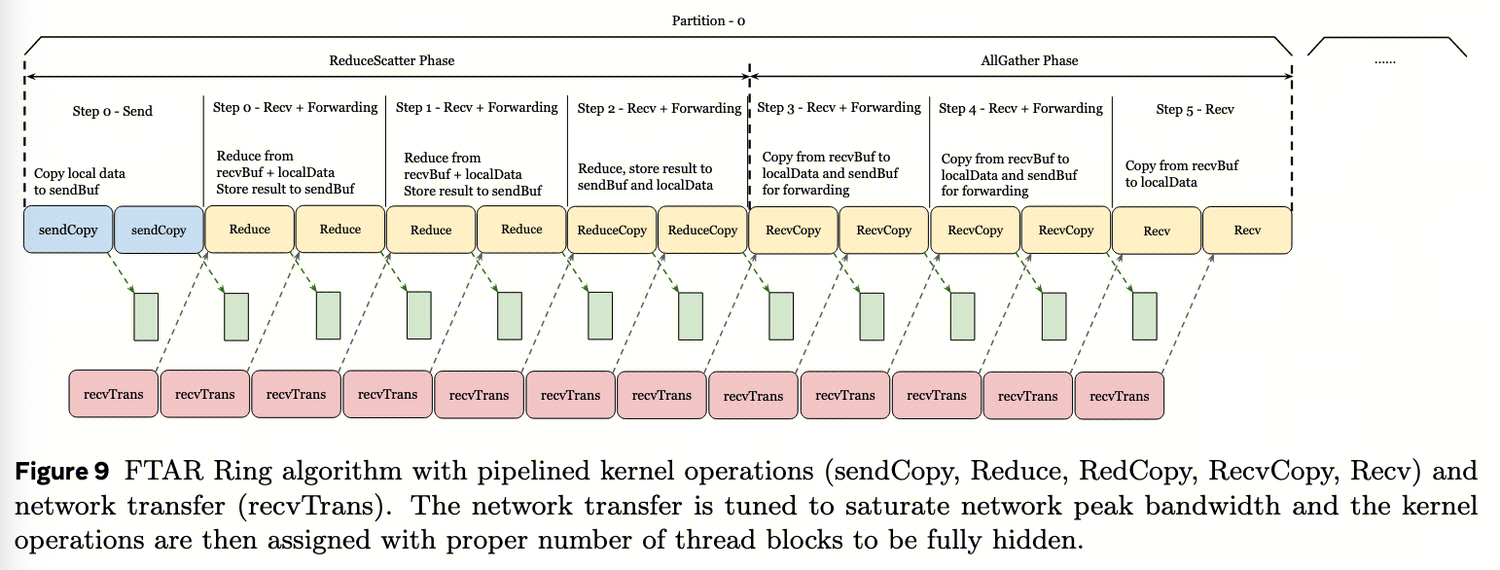 与NCCL AllReduce需要共同调优SM和网络块大小不同, FTAR使用固定的块大小(S)和块数(C) 。此方法有几个优点:首先,它提供确定性的并发流量,任何两个peer之间交换的最大并发数据包为SxC字节,确保可预测性;其次,它分离性能调优,系统允许独立优化copy/reduction 的kernel操作和网络传输操作的吞吐量。开发人员可以通过调整给定块大小的线程块数量来优化GPU内拷贝/规约的吞吐量,并单独通过修改队列对数量和其他传输特定超参数来调整网络传输吞吐量。
与NCCL AllReduce需要共同调优SM和网络块大小不同, FTAR使用固定的块大小(S)和块数(C) 。此方法有几个优点:首先,它提供确定性的并发流量,任何两个peer之间交换的最大并发数据包为SxC字节,确保可预测性;其次,它分离性能调优,系统允许独立优化copy/reduction 的kernel操作和网络传输操作的吞吐量。开发人员可以通过调整给定块大小的线程块数量来优化GPU内拷贝/规约的吞吐量,并单独通过修改队列对数量和其他传输特定超参数来调整网络传输吞吐量。 - 在流水线基础建立后,每个内核步骤可以微调到速度比重叠网络RDMA更快,同时最小化所需的GPU SM。例如,我们在Ring的ReduceScatter阶段组合规约和转发拷贝(在图9中命名为ReduceCopy),这减少了CPU-内核同步,并避免了冗余的HBM加载。我们还在中间转发步骤中避免了不必要的HBM存储。此外,我们增强了指令级并行性,以在不依赖扩展SM数量的情况下最大化拷贝和规约速度。综合所有优化,我们确定8MB块大小可饱和我们的网络带宽,仅需要两个threadblock(每个块512个线程)即可隐藏GPU拷贝和规约。进一步减少内核级开销没有好处,如果这需要更多SM,因为AllReduce已经是网络的瓶颈。
[! NOTE] 流水线协议采用 ring 算法的原因
跨Zone网络oversubscription 比为1:2.8,bisection带宽有限。若用Tree AllReduce,根节点同时接收N/2个连接,瞬时buffer需求大。Ring每节点只2个连接,并发流量=2×(S+C)=32MB(8MB块×2在途×2方向),交换机buffer可精确规划, 避免拥塞导致的丢包和重传 。
Network topology-aware optimizations
为训练作业实现的网络拓扑感知优化:
- 拓扑感知的作业放置 :我们的训练作业调度器(MAST,Choudhury等人,2024)是拓扑感知的,它 将训练作业内的连续ranks分配给网络距离尽可能近的节点 ,从而使集体通信库能够针对实际网络结构进行优化。此外,用户可以 为每个作业指定在不同网络拓扑级别(例如,机架、AI区域和DC)分配的GPU数量约束 。这种灵活性允许用户将特定形式的并行(例如,TP、EP、PP)映射到指定的网络拓扑级别。 拓扑感知集体通信 :不使用具有线性复杂度的不可扩展集体算法——例如基于ring结构的算法——而是采用对数复杂度的延迟隐藏算法,如recursive doubling和halving。对于all-gather集体通信的递归加倍实现,我们探索了几种策略,包括最近优先、最远优先和混合方法。通过经验评估,我们确定为oversubscription的网络确定了 最远优先 策略是最优的。
[! NOTE] 最远优先策略为什么在 oversubscription 的网络中最优?
最远优先策略 指recursive doubling时,第1步让rank i与rank i+N/2通信(跨最远节点)。 oversubscription 指下游带宽大于上游(如机架1000Gbps下行,28Gbps上行)。若用最近优先,大部分流量在机架内,上行链路闲置。最远优先让流量优先跨机架,饱和上行骨干链路,整体吞吐量更高。
Evaluation for former optimizations
- P2P通信 :
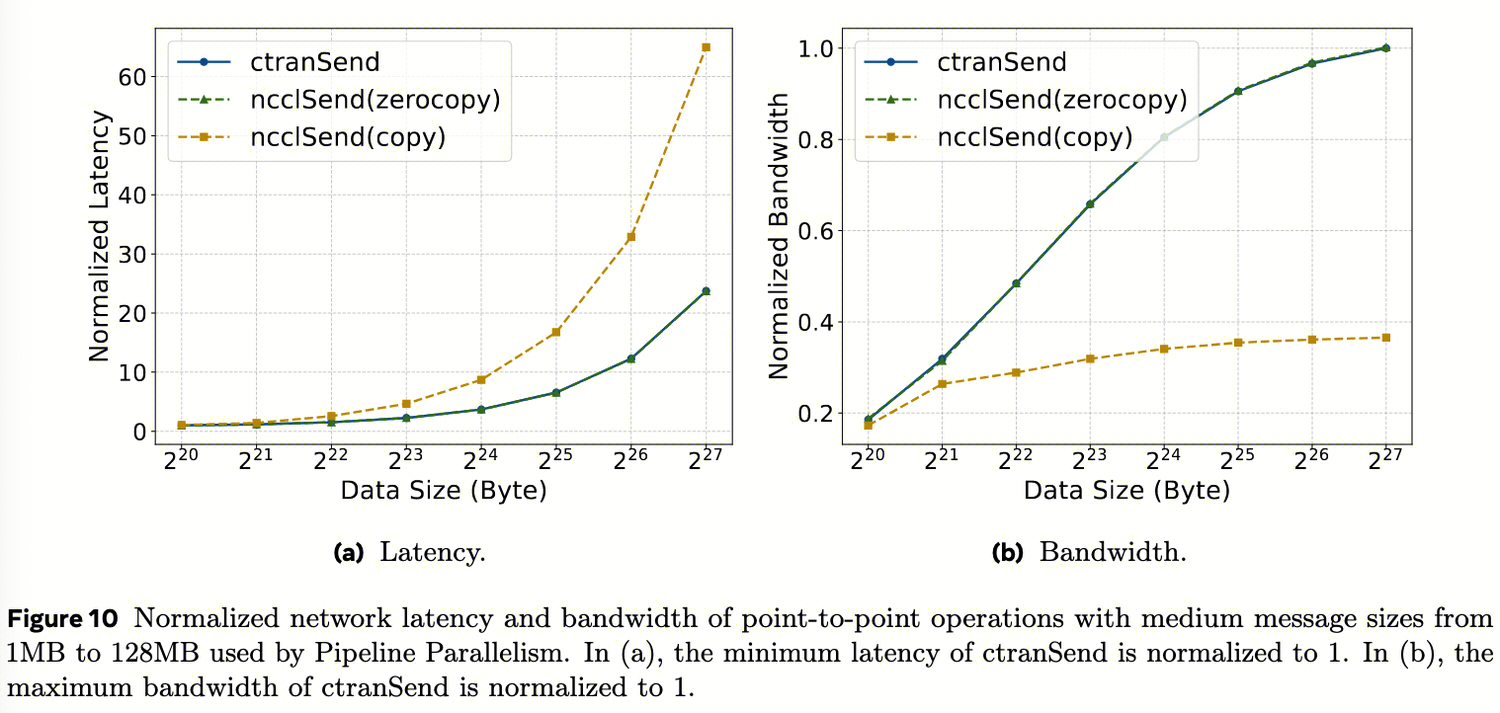 ctranSend和NCCL零拷贝在目标中消息范围(1MB到128MB)内明显优于基于拷贝的发送,实现了1.09倍到2.7倍的加速,这两种零拷贝的实现性能相近,符合预期。然而,由于使用PyTorch缓存分配器的可扩展段模式时次优的缓冲区注册支持,无法在实际生产的工作负载中启用NCCL零拷贝。
ctranSend和NCCL零拷贝在目标中消息范围(1MB到128MB)内明显优于基于拷贝的发送,实现了1.09倍到2.7倍的加速,这两种零拷贝的实现性能相近,符合预期。然而,由于使用PyTorch缓存分配器的可扩展段模式时次优的缓冲区注册支持,无法在实际生产的工作负载中启用NCCL零拷贝。 - TP Overlapping :
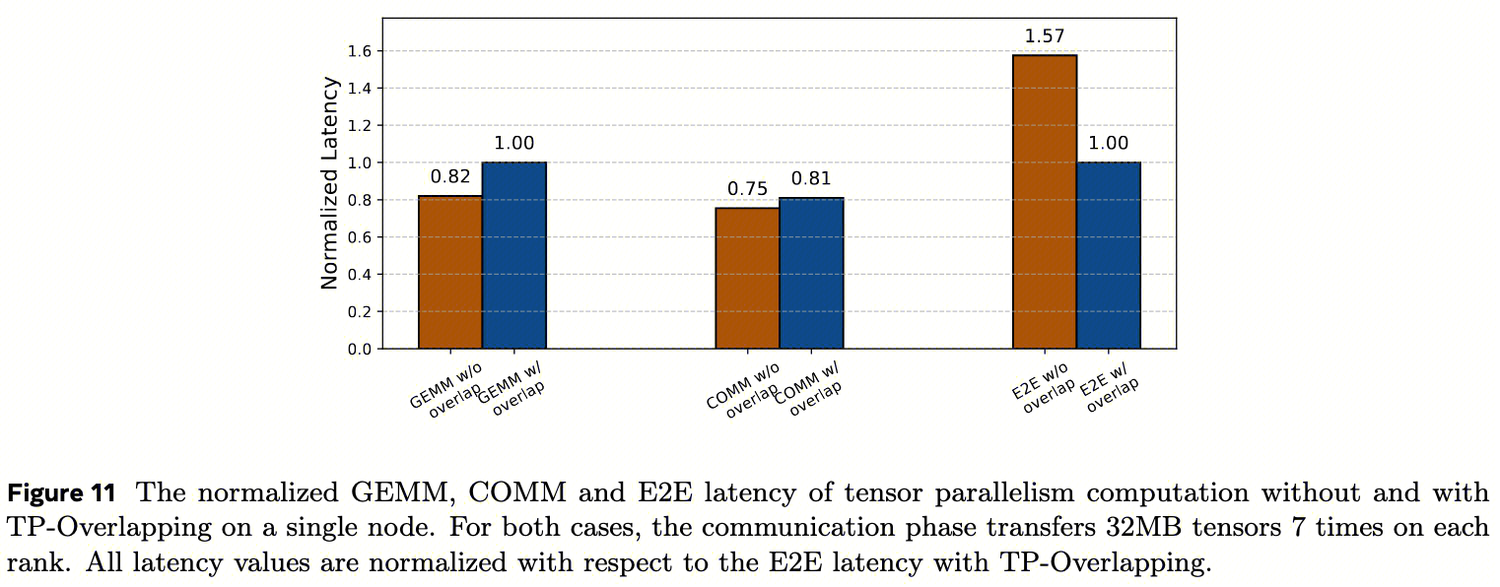 图11比较了单节点上TP工作负载在有和没有TP重叠的情况下的计算、通信和端到端(E2E)时间。对于张量传输通信时间,TP重叠和无重叠之间没有明显差异;对于计算时间,由于较小张量尺寸的计算效率降低,观察到轻微的GEMM性能下降,由于张量传输利用NVL CopyEngine,它不消耗SM线程,因此不会干扰计算;对于E2E时间,TP重叠与无重叠相比实现了1.57倍的更低延迟,因为通信被有效地流水线化到计算中。
图11比较了单节点上TP工作负载在有和没有TP重叠的情况下的计算、通信和端到端(E2E)时间。对于张量传输通信时间,TP重叠和无重叠之间没有明显差异;对于计算时间,由于较小张量尺寸的计算效率降低,观察到轻微的GEMM性能下降,由于张量传输利用NVL CopyEngine,它不消耗SM线程,因此不会干扰计算;对于E2E时间,TP重叠与无重叠相比实现了1.57倍的更低延迟,因为通信被有效地流水线化到计算中。 - Fault Tolerant AllReduce :
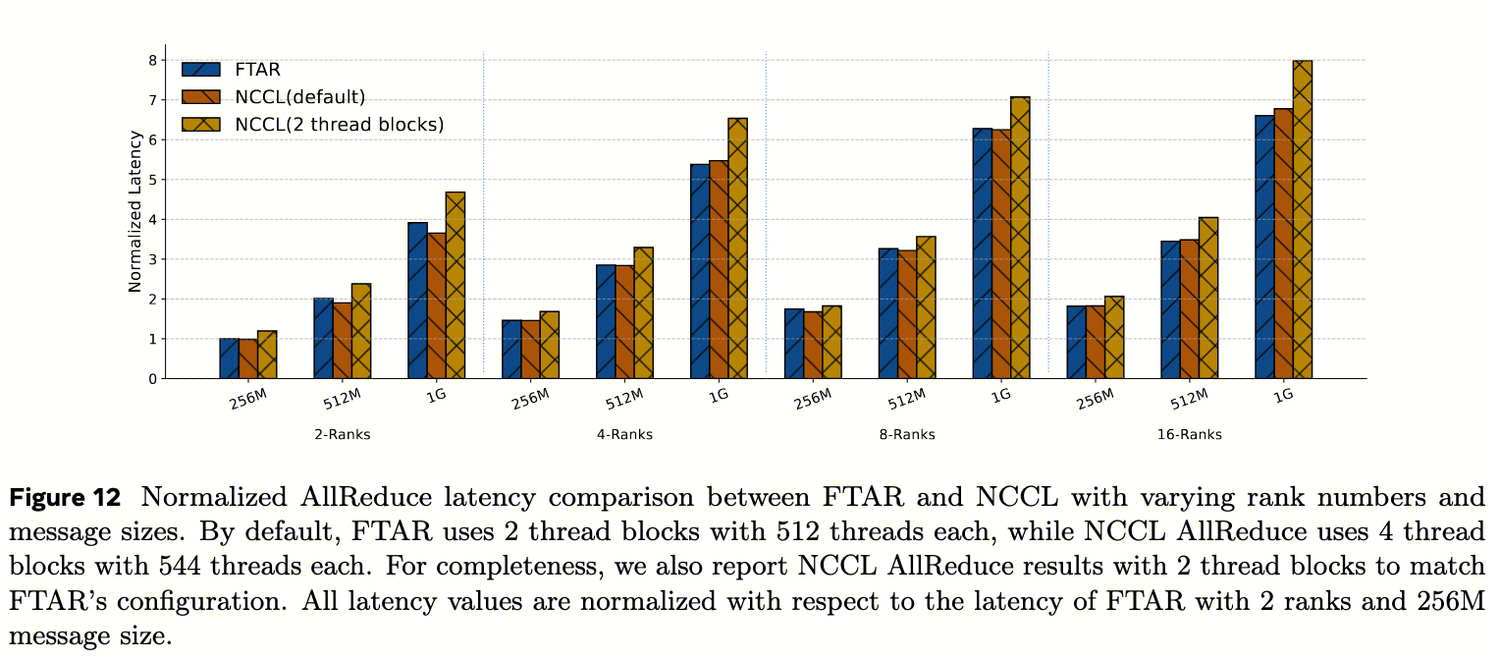 如图12所示,FTAR实现了与NCCL AllReduce相当的延迟,但仅使用一半的线程块(即,FTAR仅使用2个线程块,而AllReduce使用4个线程块)。如果将NCCL限制为使用与FTAR相同数量的线程块,FTAR比NCCL实现了9%-18%更低的延迟(得益于ReduceCopy 的流水线优化、固定的块大小、确定的并发数等) 。在全训练工作负载中,我们还确认FTAR不会对并发的内域计算产生可见的干扰,这得益于极低的SM占用。
如图12所示,FTAR实现了与NCCL AllReduce相当的延迟,但仅使用一半的线程块(即,FTAR仅使用2个线程块,而AllReduce使用4个线程块)。如果将NCCL限制为使用与FTAR相同数量的线程块,FTAR比NCCL实现了9%-18%更低的延迟(得益于ReduceCopy 的流水线优化、固定的块大小、确定的并发数等) 。在全训练工作负载中,我们还确认FTAR不会对并发的内域计算产生可见的干扰,这得益于极低的SM占用。
[! NOTE] NCCL zero-copy 为何与 PyTorch 不兼容?
NCCL zero-copy要求用户显式调用
ncclCommRegister()注册tensor。但PyTorch tensor生命周期由Python GC管理,可能随时释放。若NCCL仍持有已释放tensor的注册信息,会导致段错误。NCCLX的auto-registration通过hook PyTorch分配器解决了这个问题。
Multi-node Inference Customization
推理 vs 训练 :
- 小吞吐、低延迟 :虽然推理相比训练需要更少的网络吞吐量,但它要求极低的延迟以高效服务用户请求
- 高度并行化 :推理时需要在多个GPU和节点之间进行并行化,以支持更大的模型、更快的每节点计算和更大的批量大小。
- 然而, 同时实现低延迟和并行化并非易事 :多GPU/多节点之间的通信给延迟带来了新挑战,例如,MoE AllToAll是LLM推理中众所周知的昂贵集体通信,即使每次操作只有几MB的数据传输。在推理场景中广泛用于减少内核调度开销的CUDA graph尤其受此问题影响——由于CUDA图的特性,会传输额外的填充数据,从而导致高延迟。另外,尽管GPU pair之间的网络传输可以重叠,但准备网络请求的CPU指令是串行的,可能需要比数据传输本身更长的时间。
在本节中,我们首先深入探讨推理工作负载中的延迟问题。然后,我们介绍一种GPU驻留通信方案,该方案可以避免发送额外数据,并将网络传输量减少到实际所需大小,从而降低暴露的延迟。特别是,我们将深入探讨AllToAllvDynamic的实现细节,这是GPU驻留集体通信的第一个示例。然后,我们描述了几项优化,以改善小消息大小的延迟,这是推理中的常见用例。最后,我们展示了使用这些优化获得的端到端性能提升。
EP: GPU-resident collectives
传统的NCCL集体通信在日新月异的ML工作负载中存在局限性,以NCCL AllToAllv(ncclAllToAllv)为例。它从用户接收两种类型的参数:
- 1)数据,包含要发送给peer的主要内容;
- 2)元数据,包含如何发送和接收数据的信息,例如,发送缓冲区地址指示从何处读取发送数据,发送计数包含要发送给每个peer的数据量。
然而数据驻留在GPU上,元数据驻留在CPU上,这会带来新的问题:当集体通信入队时,例如在cuda图捕获模式下,元数据是固定的,即使集体通信尚未启动也无法修改。
- 问题根源 :CUDA Graph要求所有参数在图捕获时固定。MoE的路由结果在运行时才确定,AllToAllv无法获知发送计数(send_counts)
- 传统方案缺陷 :
- Eager模式:GPU→CPU同步send_counts,开销大
- Graph模式:发送max_counts,padding waste严重
让我们深入研究推理工作负载中的一个案例,该案例说明这种设计如何降低性能。特别是,我们研究了MoE中的MetaShuffling阶段(Li等人,2025)。MetaShuffling利用token选择机制来分发token。 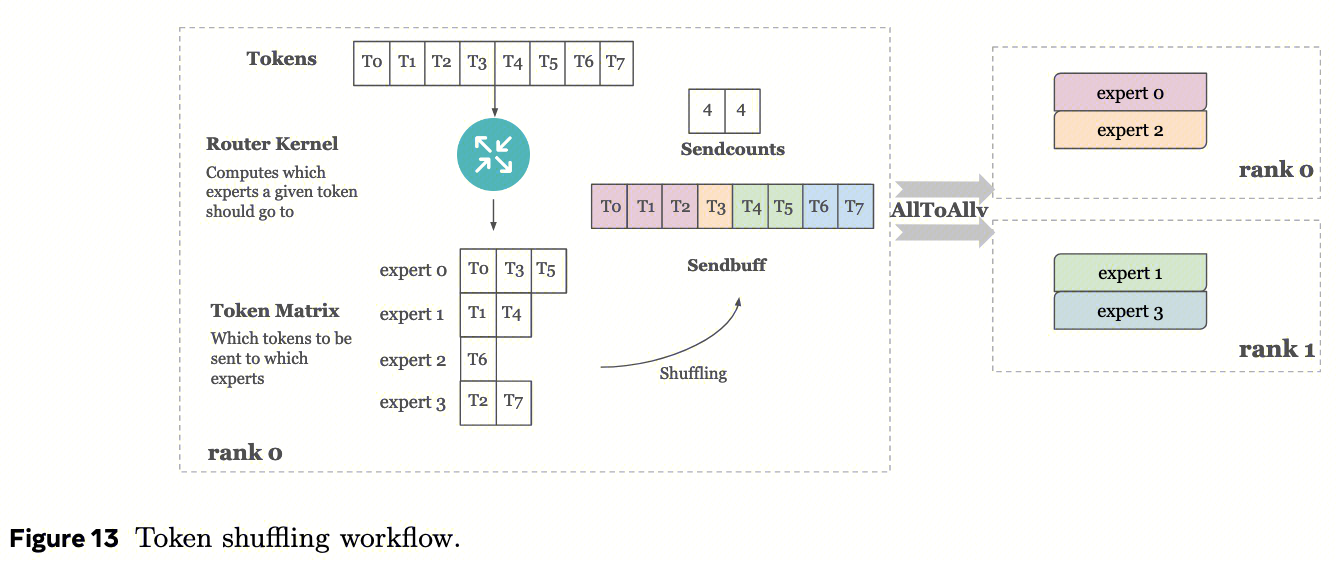 如图13所示,每个GPU都有一个路由kernel,计算给定token应该去往哪k个专家。然后路由内核生成一个token矩阵,即token与专家之间的映射。在shuffling后,生成一个sendbuff(包含发送数据)作为AllToAllv的输入,用于将token发送出去。
在这种情况下,AllToAllv操作的发送计数取决于输入数据和路由内核的决策。这些发送计数无法在集体通信入队时(例如训练中的eager模式)或图创建时(例如推理中的graph模式)计算。这是 因为在入队时或图创建时,所有操作(包括路由内核和AllToAllv)都在CPU上同时入队,而路由内核尚未在GPU上启动以完成计算 。
如图13所示,每个GPU都有一个路由kernel,计算给定token应该去往哪k个专家。然后路由内核生成一个token矩阵,即token与专家之间的映射。在shuffling后,生成一个sendbuff(包含发送数据)作为AllToAllv的输入,用于将token发送出去。
在这种情况下,AllToAllv操作的发送计数取决于输入数据和路由内核的决策。这些发送计数无法在集体通信入队时(例如训练中的eager模式)或图创建时(例如推理中的graph模式)计算。这是 因为在入队时或图创建时,所有操作(包括路由内核和AllToAllv)都在CPU上同时入队,而路由内核尚未在GPU上启动以完成计算 。
为了解决AllToAllv无法获知发送计数的问题,在eager模式下,可以在AllToAllv开始前在GPU和CPU之间同步发送计数, 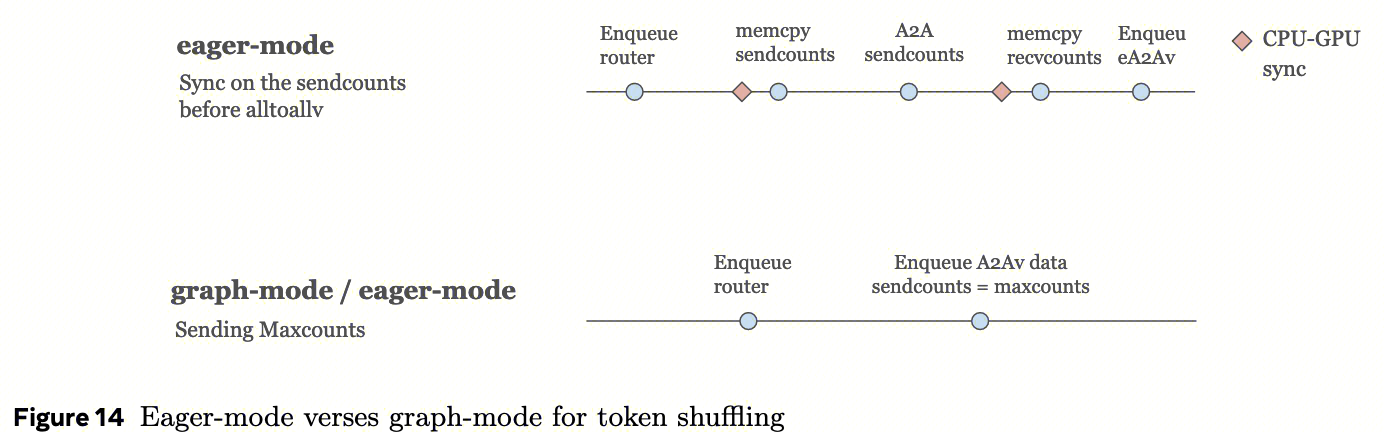 如图14所示。然而,GPU和CPU之间的过度同步可能会带来巨大开销,特别是对于小内核。此外,在cuda图中同步不是一个选项。相反,我们需要如图14所示在cuda图中发送最大可能计数(maxcounts)。maxcounts需要足够大,以应对最坏情况,即所有token被分配到同一专家,该值随token数量线性增长。这意味着会向peer发送大量带有垃圾值的数据填充(padding),导致延迟增加和带宽使用增加,严重影响性能,特别是对于需要实时响应的推理。
如图14所示。然而,GPU和CPU之间的过度同步可能会带来巨大开销,特别是对于小内核。此外,在cuda图中同步不是一个选项。相反,我们需要如图14所示在cuda图中发送最大可能计数(maxcounts)。maxcounts需要足够大,以应对最坏情况,即所有token被分配到同一专家,该值随token数量线性增长。这意味着会向peer发送大量带有垃圾值的数据填充(padding),导致延迟增加和带宽使用增加,严重影响性能,特别是对于需要实时响应的推理。
GPU-Resident collective
为了克服这些限制,我们引入了GPU驻留集体通信,这是一种元数据驻留在GPU上的定制集体通信。GPU上的元数据允许输入元数据在集体通信开始执行前的任何时间进行修改。这使得NCCLX能够使用实际的发送计数来传输数据,而不是传输最大发送计数,从而减少了实际传输的数据量。 AllToAllvDynamic是专注于AllToAllv的GPU驻留集体通信的第一个示例。其他示例(尚未实现)包括GPU驻留AllGather、GPU驻留AllGather和AllToAll。在本节的其余部分,我们以AllToAllvDynamic为例,概述GPU驻留集体通信的设计。 让我们首先看看传统的NCCL AllToAllv(ncclAllToAllv)如何工作。它无法接收先前内核所做的消息大小更改,因为传递给PyTorch和NCCLX的所有元数据都是按值传递的,即元数据信息在集体通信入队时被复制到内部PyTorch和NCCLX数据结构中,因此无法修改。 如图15所示,ncclAllToAllv在初始化和入队时复制元数据(例如,发送计数)。在它被CPU入队后,在GPU上先于ncclAllToAllv启动的其他应用程序(例如,路由内核)可以对原始数据结构中的元数据进行修改。当ncclAllToAllv在GPU上启动其内核时,它只能读取这些元数据的副本,因此只能使用旧元数据执行数据移动。 如图16所示,在GPU驻留集体通信的设计中,入队时,AllToAllvDynamic通过引用而不是复制来获取元数据。即使在其他应用程序内核修改元数据后,AllToAllvDynamic仍然可以使用原始数据结构读取更新后的值。此外,根据MoE情况下的新要求,我们更新其他元数据(如接收计数)并将它们返回给用户。我们还引入了几个新的元数据,如发送索引,将在下一节中详细介绍。
Implementation Dive-in
我们现在深入探讨AllToAllvDynamic的工作流程和实现。 AllToAllvDynamic工作流程 :要交换数据,节点间CPU端利用NCCLX框架中开发的RDMA put,节点内GPU端启动多个块以在NVLink上并行拷贝数据。 AllToAllvDynamic接收用户输入的元数据和数据,两者都驻留在GPU上。然后根据元数据拆分发送缓冲区,并与peer交换元数据和数据。图17通过示例说明了AllToAllvDynamic的工作原理。 每个rank接收四个参数来发送数据:sendbuff、sendSplitLengths、sendIndices和sendIndicesBlockLengths。
- sendbuff 是GPU上的连续空间,包含要发送给所有rank的token。
- sendSplitLengths [s0,s1,s2,…,sn] 表示如何将sendbuff拆分为n个片段,每个片段包含si个token。sendSplitLengths可以由先前的路由内核动态更改,并驻留在GPU上。
- sendIndices [I00,I10,I20,…,I01,I11,I21,…] 表示将哪些索引从sendbuff发送到哪个rank,其中Iji表示专家j的片段sIji将被发送到rank i(因为专家j在rank i上)。这是一个概念上的二维数组,但为了便于实现被展平为一维,移除了rank维度。每个rank的子列表不需要包含连续的索引值。
- sendIndicesBlockLengths [l0,l1,l2,…] 表示如何读取sendIndices,并驻留在GPU上,其中li指示将发送多少个索引li给rank i,这等于该rank中的专家数量(可能包括冗余专家)。sendIndices的长度等于sum(sendIndicesBlockLengths)。
以图17中的rank 0为例,sendSplitLengths将sendbuff分成四个片段,每个片段分别包含128、256、256、128个数据,标记为索引{0,1,2,3}。根据sendIndicesBlockLengths,sendIndices中的前2个索引{0,1}发送给rank 0,接下来的3个索引{0,2,3}发送给rank 1。注意,由于重复专家,索引0被发送给rank 0和rank 1两者。
在接收方,每个rank获得两个需要由AllToAllvDynamic填充并返回给用户的参数: recvbuffs 和 recvAllSplitLengths 。
- recvbuffs 包含一个数组列表,为每个rank接收数据。在每个rank的数据中,保留填充以更好地在下一轮AllToAllAll中用作sendbuff。例如,在rank 1的接收方,从rank 0接收的数据包含索引1的填充。
- recvAllSplitLengths 包含从所有其他rank接收的分片长度。对于每个rank,它按顺序接收所有sendSplitLengths以获得填充信息。
实现挑战和解决方案 :我们需要解决几个实现挑战。首先,当元数据驻留在GPU上时,CPU无法访问它。然而,CPU上的RDMA操作需要读取元数据以确定向哪个rank发送多少数据以及发送哪些片段。其次,与传统NCCL不同,元数据被假设为在AllToAllvDynamic启动之前都可能更改,这意味着每个rank无法知道它将接收多少数据。这样的接收计数被GPU端拷贝使用,也需要返回给用户。
为了解决第一个挑战,我们将元数据从GPU复制到CPU缓冲区。对于第二个挑战,我们在数据之外还交换元数据(主要是发送计数)。然而,这些拷贝的工作流程容易出错,需要以特定顺序和自定义缓冲区完成。首先,在CPU线程启动之前,需要将元数据从GPU复制到CPU缓冲区,以便CPU可以使用更新后的值(①)。其次,除了复制到CPU缓冲区外,元数据还需要复制到注册的GPU缓冲区(即图18中显示的tmpbuf)以供CPU RDMA put使用(①)。第三,为了接收数据,我们还需要一个注册的GPU缓冲区来接收计数(③)。最后,GPU需要等待CPU和GPU都完成计数接收,然后将接收的计数拷贝回用户缓冲区(⑥)。图18详细说明了我们如何交换元数据。
Low-latency Optimizations
在我们的工作负载中,我们运行仅RDMA的AllToAll操作,其中每个节点只有一个GPU参与集体通信。在这种情况下,AllToAll通信比其他集体操作更容易成为CPU开销的瓶颈。这是因为AllToAll模式需要向通信器中的所有rank发出RDMA操作,增加了CPU的参与和开销。对于N个rank的AllToAll,延迟可以大致建模为T=Tc×(N−1)+S/BW,遵循经典LogP模型。我们将Tc定义为向远程rank发出消息的平均准备开销(称为软件开销),S是每rank的消息大小,BW是两个rank之间的网络带宽。NCCL和CTran中的实现都利用CPU线程来发出RDMA,其中Tc必须由N−1次串行化。我们假设对不同rank的RDMA流量理想重叠,因此总体有效负载传输时间为S/BW。显然,当N扩展而小S固定时,Tc×(N−1)可能成为主要瓶颈。 诸如DeepEP(DeepSeek AI, 2025)之类的现有工作利用NVSHMEM来处理这种N个rank小消息模式。NVSHMEM是设备发起的通信模型,其实现可以利用轻量级GPU线程并行化不同rank的RDMA准备。因此,准备开销可能不会随N−1增加而保持平坦。然而,通过CPU线程并行化可能会引入来自CPU调度的更重开销,对于主机驱动的RDMA实现来说不是最佳选择。先前来自MPI社区的工作已展示了在小消息准备中最小化CPU开销的实用方法(Raffenetti等人,2017),以及通过多CPU线程进一步并行化RDMA准备和发布的潜力(Si等人,2014)。受这些研究启发,我们专注于减少本工作中Tc。我们证明了通过仔细优化软件实现,主机驱动方法也可以实现与设备发起模型类似的低延迟。 我们首先分解准备开销。为简单起见,我们以AllToAll为例;AllToAllvDynamic遵循类似的工作流程。图19显示了CTran中的零拷贝AllToAll工作流程。首先,交换控制消息以从peer收集接收缓冲区地址。然后发出RDMA put来拷贝实际数据有效负载和元数据(如果适用)。最后,每个rank等待从所有peer接收完成通知。 表2显示了128个H100 GPU跨32节点的AllToAll中8MB消息大小的每个阶段的分析结果。为了放大RDMA准备开销,我们在分析研究中明确强制所有消息通过网络RDMA传输。不出所料,主要瓶颈落在准备开销中。下面,我们进一步对我们软件中的这种准备开销的主要来源进行分类。4
- 关键路径上过度软件复杂性 :深层调用栈、不必要的抽象层、细粒度读/写锁和冗余检查都增加了每次操作的CPU时间。
- 控制消息交换 :典型的零拷贝通信以一轮控制消息交换(通常称为握手,如图19中的步骤1和2所示)开始。交换有两个目的:交换接收缓冲区的内存句柄以进行RDMA传输,以及同步发送方和接收方,以便发送方可以确保接收方缓冲区准备好被更新(例如,先前消耗相同缓冲区的计算已完成)。此步骤引入了显著延迟,约占小消息机制中AllToAll总时间的约一半。
- RDMA put操作低效处理 :RDMA put路径(图19中的步骤3)由于簿记和负载均衡逻辑而产生高延迟,这些逻辑虽然对大消息和高吞吐量有益,但对小消息传输没有必要。此外,ibverbs级别的RDMA发布开销(即ibv_post_send函数的调用开销)在优化上述开销后变得可见。这本质上是由获取ibverbs内部关键部分的锁和按门铃通知网络接口卡(NIC)引起的。
为了解决小消息AllToAll操作中的瓶颈,我们实施了一系列针对性优化,涵盖软件设计和通信协议改进。 首先,我们通过通用C++和API优化专注于减少软件开销。关键路径上的函数被积极内联以最小化函数调用开销。此外,我们使错误检查成为条件性的,以在低延迟模式下可选地省略检查。所有低延迟条件都通过C++模板仔细传递到栈中,以避免任何额外的分支开销。 其次,我们通过代码设计与推理工作负载共同解决了控制消息交换的显著延迟(图19中的步骤1和2)。推理工作负载通常使用CUDA图来减少CPU开销(例如,CUDA内核启动)。CUDA图要求捕获阶段使用的数据张量在重放期间保持不变(Nvidia,2025a,2021)。因此,内存句柄可以在捕获时交换一次,然后在所有后续重复的集体通信中重用。然而,我们注意到控制消息还充当同步屏障。为了移除此屏障,我们为MoE算法引入了双缓冲,以使两个连续的AllToAll始终使用不同的接收缓冲区,避免缓冲区覆盖问题。 第三,我们做了两项优化以最小化RDMA put开销。我们首先引入了小消息快速路径,以绕过为高吞吐量场景设计的默认簿记和负载均衡逻辑。快速路径通过专用数据队列对(通常是数据队列对0)直接将数据作为单个RDMA发出。为了减少ibverbs级别的发布开销,我们通过实现工作请求链接(称为scatter list)优化了对多个非连续缓冲区的处理。链接允许将来自多个非连续发送缓冲区的RDMA传输一起发出,锁定和按门铃的成本仅一次。 我们将这些优化从AllToAll延续到类似的AllToAllvDynamic模式,大大减少了其准备开销,并促进了更高的整体效率。尽管这些优化针对推理工作负载中的挑战,但它们普遍适用于所有以小消息为主的通信。
Evaluation
我们评估了配备第6.2节所述低延迟优化的AllToAllvDynamic的端到端性能,并将其集成到token洗牌栈中。我们评估了其对解码时间延迟的改进。设置如下:
- 基线 :基线通信包含两个AllGather和一个AllToAll,计算内核与AllToAllvDynamic相同。为公平比较,我们在基线中启用了CTran。
- 比较维度 :我们专注于测试平衡工作负载,并在以下维度调整参数:token选择k = {1,4},批量大小 = {128,256},主机数 = {4,8,16}。
- 方法论 :我们省略第一轮结果,因为它在预热期间可能不准确。对于每个测试设置,我们运行性能分析工具三次,并获取所有三次运行中所有主机的平均数值。
表3显示了评估结果。与单节点相比,当k=1时,A2AvDynamic实现了高达43%的改进。与基线相比,不同设置下实现了15-80%的改进。随着传输数据量增加(更大的k),收益增加。
In this paper, we mainly focus on the underlying host-driven common communication stack and leave the rest of device-initiated model support as future work.
[^2]: 这里的”exposing the full message to the network”应理解为: 让网络传输层直接看到并处理完整消息,而非由软件将其切割成小块后逐个提交