Introduction
大数据的爆炸式增长促进了各领域智能应用的发展,但这些数据通常分散在孤立的各方,由于隐私问题和法规限制而无法整合。 McMahan 等人1提出利用 Federated Learning 实现保护隐私的协作学习,即数十亿台移动设备在云端中央服务器的协调下协作训练一个共享的机器学习模型,同时将训练数据保存在客户端。
跨设备(cross-device)FL 和跨组织(cross-silo)FL 都专注于客户和各方通过带宽受限的域间网络(跨广域网)与中央服务器通信 ML 模型的场景。除这两种 FL 外,本文发现新的 FL 形式——域内(intra-domain)FL。在这种情况下,孤立的各方位于同一局域网(如共享的数据中心)中,它们拥有充足的带宽资源,但由于各方之间的计算设备不同(异构性),因此计算能力也不尽相同。域内 FL 通过实现密集的联合计算(federated computing)扩展了服务计算(service computing)的功能。例如,一个研究中心的团队将他们的机器集中起来,建立一个共享数据中心,然后他们可以向中心外的团队或用户提供面向联合计算的网络服务。 这些外部团队可以是:a) 来自不同的机构(如企业、大学);b) 期望合作,但出于隐私和知识产权方面的考虑,不允许共享数据;c) 共享高质量的网络服务,但由于混合了异构计算设备(如 CPU、GPU、ASIC、FPGA),因此具有异构计算能力。
怎样理解 cross-device & cross-silo FL?
Single Organization, Model-Centric & Cross-Device Federated Learning.
Multiple Organizations, Model Centric & Cross-Silo Federated Learning. We’re now looking to unlock the value of data that is more widely distributed, for example between hospitals, banks, perhaps distributed aggregate data from consumer wearables in different fitness app businesses.
Whilst the goal is typically stated as the same for Cross-Silo — to update and improve a central, and in this case shared, model, there are arguably greater challenges on the security side. At the same time, there’s scope to use more consistent, powerful & scalable compute within each organisation (Hadoop/Spark clusters etc.)
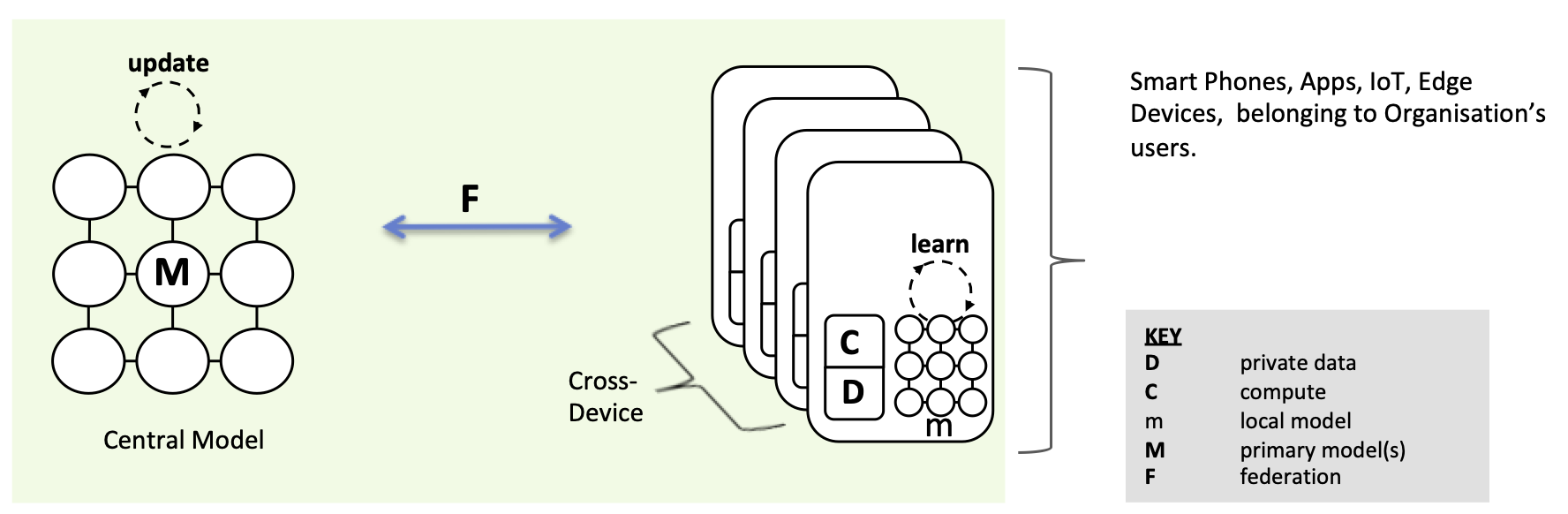

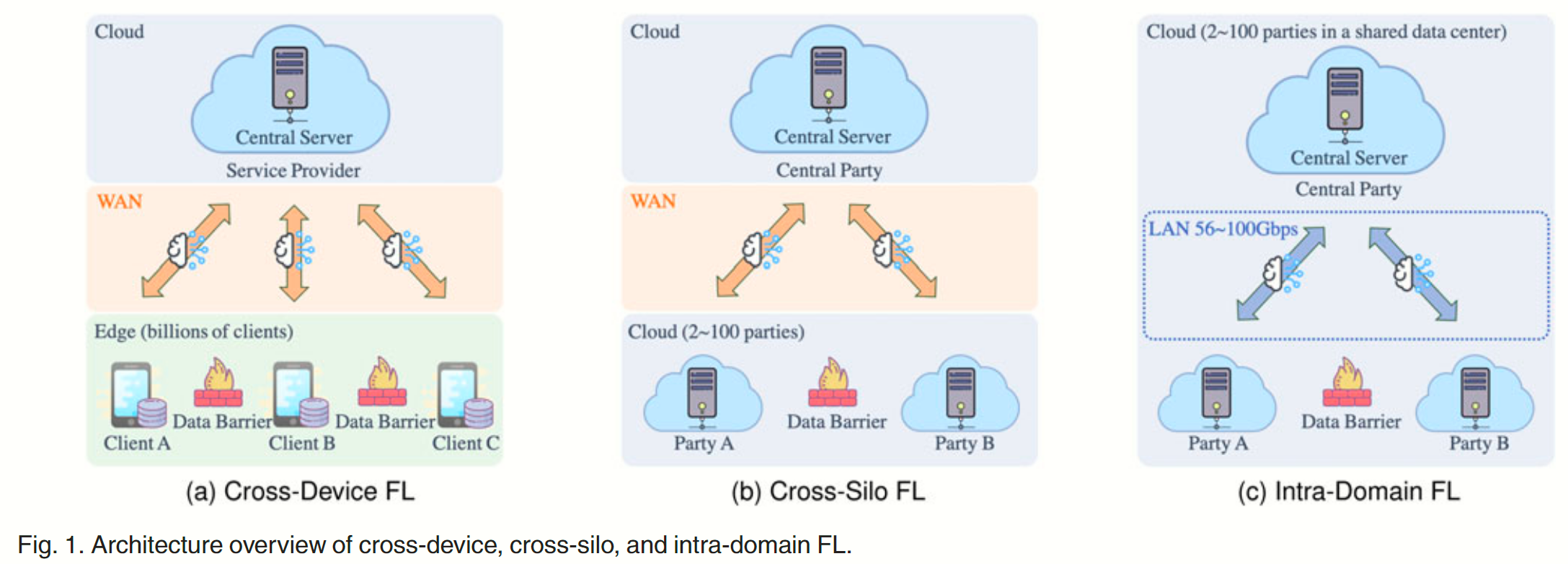
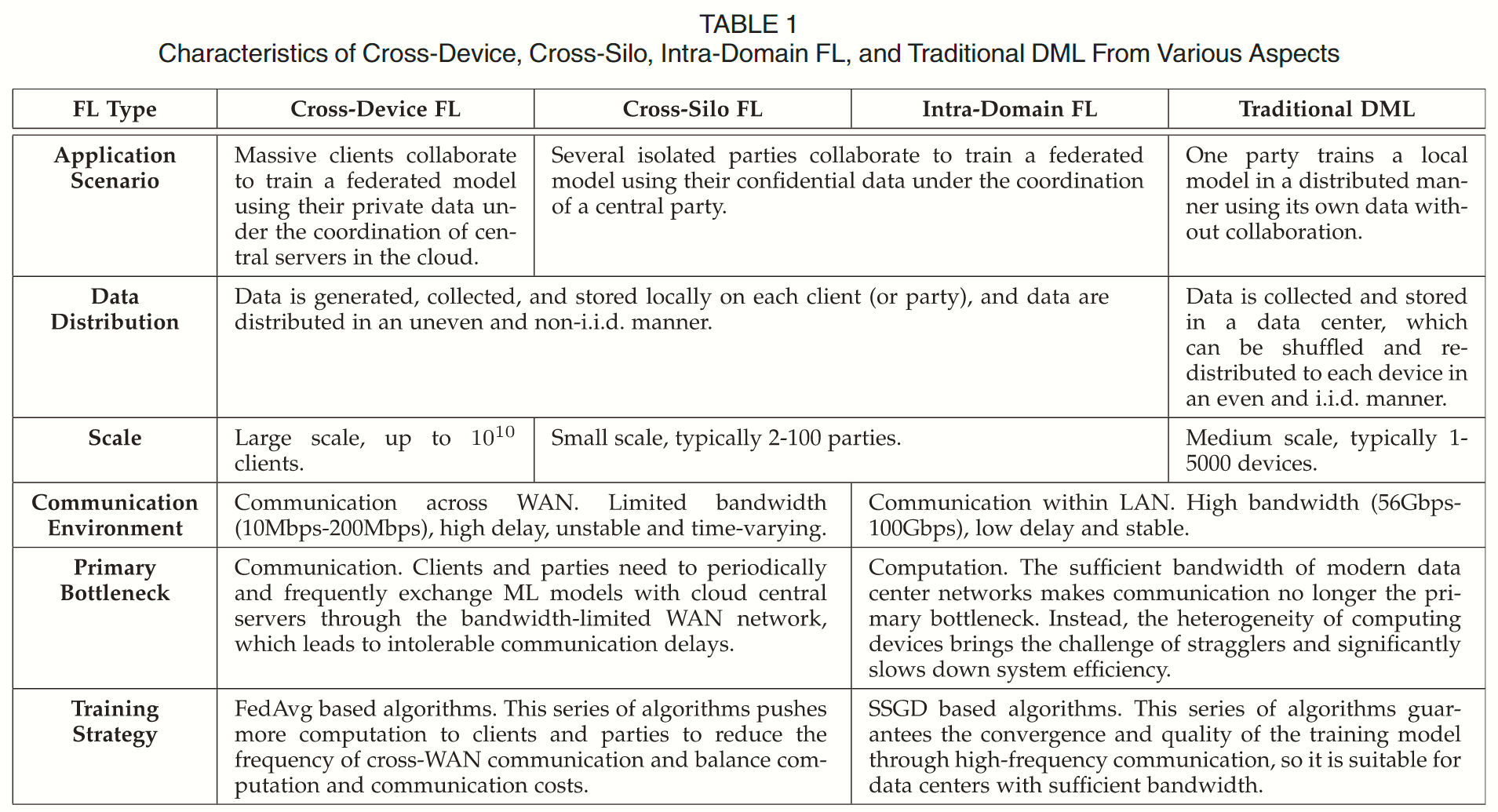
跨设备 FL、跨组织 FL、域内 FL、传统 Distributed ML 的图示和对比如 Fig 1 和 Table 1 所示。总的来说,域内 FL 在参与实体(即孤立的各方)、数据分布(即不均衡和非独立随同一分布 non-i.i.d)和联邦规模(即通常为 2-100 个参与方)方面与跨组织 FL 具有相似的特征,但域内 FL 的各参与方位于共享的数据中心,并通过高速局域网络互连。
现有的文献都致力于减轻跨设备和跨组织 FL 的通信瓶颈,McMahan 提出将更多计算推卸给客户端的 FedAvg 技术来减少同步频率。然而 Yao 等人2的论文发现,FedAvg 会给模型聚合带来梯度偏差,从而导致收敛性变差。例如在 CIFAR10 数据集上想要训练到 80% 的分类准确率,FedAvg 需要 1400 个 epoch(280 个同步轮次),而 SGD 只需要 36 个 epoch 。因此基于 FedAvg 的算法不是域内 FL 的好选择,因为域内 FL 并没有通信瓶颈。
由于没有通信瓶颈的限制,基于高频率同步 SSGD 的算法由于出色的收敛性,更适合在域内 FL 中使用。然而,此时巨大的计算异质性成为主要瓶颈——各参与方提供的机器具有不同能力的计算设备,而更换所有过时机器的成本高昂且不切实际,因此导致共享数据中心的异构性。异质性带来了严重的效率低下,功能强大的机器在每次同步中因滞后的机器(straggling machine)而阻塞,直到越过障碍。
解决拖后腿问题可以分为同步和异步两类方法:
- 同步方法选择计算能力相近的各方,使同步各方趋于一致。 Bonawitz 等人3的方案接受在指定时间窗口内提交的模型,并丢弃超时的模型。 Chai 等人4的方案将各参与方分组为多个层级,每个层级中的各方具有相同的计算能力,该方案根据概率选择一个层级进行同步。但这些方法都不一而同地使滞后方无法贡献自己的模型,削弱了全局模型的泛化能力。
- 异步方法允许计算能力强的参与方立即更新全局模型,而不必等待拖后腿的参与方(如 ASGD),因此这种方案天然适合异构计算。但这种方案使用陈旧模型更新全局模型,导致准确度下降。 Zheng 等人5提出利用泰勒展开补偿陈旧梯度,Xie 等人6则通过降低权重来抑制陈旧模型的贡献。他们的方法在弱异质性条件下效果很好,但仍无法挽救域内 FL 的精度,因为当异质性较强时,陈旧的噪声会完全淹没有价值的信息。
为了解决强异构情境中的域内 FL 中滞后方的问题,同时保证准确性不受损失,本文提出了一种高效的同步机制,可以自适应地避免滞后方造成的阻塞。其核心思想是让有计算能力强的参与方在阻塞时间内探索更高质量的模型,即建议计算能力强的各方在滞后方完成一次迭代之前尽可能多地进行迭代训练。为实现这一想法,需要一种在线调度机制来自适应地协调各方的局部迭代次数。
因此本文的贡献在:
- 提出了一种新的 FL——域内 FL,在这种 FL 中,孤立的各方在具有强大计算异构性的共享数据中心中协作训练 ML 模型。 我们总结了现有的跨设备 FL、跨组织 FL 和传统 DML,并将它们与所提出的域内 FL 进行了比较。
- 提出了一种新型调度器 State Server,用于协调各方的同步步伐。State Server 实时监测各方的状态和进度,可以在环境改变时自适应地调整调度决策。
- 提出了一种针对强异构环境的高效同步算法 ESync。在 State Server 的协调下,ESync 允许各参与方依据各自的资源在本地迭代训练不同的轮次,从而解决滞后者问题以及加速训练过程。
- 给出了权重发散和最优性差距的边界,分析了收敛精度和通信效率之间的权衡,证明在强异构环境下 ESync 比 FedAvg 具有更高的效率和更好的精度。
- 进行了广泛的实验,比较了 ESync 与 SSGD7、ASGD8、DC-ASGD5、FedAvg1、FedAsync6、FedDrop3 和 TiFL4,数值结果表明 ESync 可以在不损失精度的情况下实现极快的速度。
Related Work
滞后者问题(straggler)在 FL 和传统 DML 中都存在,但由于数据孤立的特点,非独立同一分布的数据只存在于 FL 中。已有许多方案用于解决滞后者问题和非独立同一分布的数据,因此对这些方案做一些总结。
Cross-Device and Cross-Silo FL
滞后者问题。
- 同步算法 FedAvg 是最广泛使用的联邦优化算法,其需要所有参与方在本地训练模型 个 epoch 后再对各自的本地模型进行同步,然而计算设备的异质性会导致滞后者问题的出现,其会造成长时间的阻塞,显著降低训练效率和资源利用率。
- FedDrop 算法通过设置 DDL 和时间窗口过滤滞后者。对 FedDrop 的改进中,Kairouzet 等人的方案允许各方在一个固定的时间窗口内进行多次局部迭代训练; Reisizadeh 等人的方案要求各方在 DDL 前上传本地模型。
- 另一些同步方案则尝试平衡所有方的计算时间以避免阻塞。如 TiFL 在每个训练轮次中对相同计算能力的参与方进行采样,从而完成同步;Smith 等人的方案为每个参与方给予近似解决其子问题的灵活度。Li 等人的方案为各方隐式地容纳可变的 -inexactness 。
- FedAsync 算法是异步的联邦优化算法,允许各参与方通过加权平均立即更新全局模型,并且引入混合超参数来缓解因滞后性(staleness)引起的错误。
非独立同一分布数据问题。与传统 DML 不同,不同孤立方的数据并不统一,拥有不同的分布。Yao 的论文2指出梯度偏差会损害 FedAvg 的错误边界,尤其是在非独立统一分布的数据时。Zhao 等人的论文通过定义权重发散,进一步分析了 FedAvg 在倾斜的 non-i.i.d. 的数据上的性能下降。
- 为了减轻 non-i.i.d. 数据的影响,一些方法尝试调整超参数并添加目标约束。Yu 的论文建议减少局部迭代次数,以抑制梯度偏差。Li 的论文建议衰减学习率以保持收敛速度。 Li Tian 的论文在目标损失中添加了一个近端项,以迫使局部模型更接近全局模型。
- 其他方法扩展了各方的局部数据,以减少数据分布的差异。扩展数据可以是各方共享的一小部分数据、少量蒸馏数据或由共享生成模型生成的假数据。 由于需要共享可能包含原始数据隐私的数据,这些方法存在隐私泄露的风险。
Traditional DML
滞后者问题。没有通信瓶颈的限制,传统 DML 倾向于使用基于高频同步 SSGD 的算法,因为它们比 FedAvg 收敛速度快很多。但是计算设备的快速升级导致部分研究中心无法及时升级所有老旧设备,这导致数据中心中的滞后者问题并且阻塞整个系统。
- 解决方案依旧可以分为同步和异步两种。对于同步方案,Chen 等人的论文提出了备份工作者(backup worker)并放弃来自滞后者的落后模型。Yang 等人的论文提出通过最小最大整数规划(min-max integer programming)9来平衡基于计算能力的小批量(mini-batch)的规模。其他方案则使用冗余信息还原滞后者的信息,例如 Ferdinand 等人的论文中将数据分解为若干固定的块,再将每个块分发给多个工作者,通过限制计算时间,这个方法可以通过其他工作者的冗余数据恢复滞后者上丢失的数据。Tandon 等人的论文还表明,复制数据块和跨梯度编码可为同步算法提供对滞后者的容忍度。基于冗余编码的方法在传统 DML 中效果很好,但由于共享数据块,这些方法侵犯了隐私,因此不适合域内 FL。
- 以 ASGD 为代表的异步方案允许滞后者更新全局模型而不阻塞其他工作者,因此对异构计算有天然的容忍度。但是 ASGD 更新全局模型时使用的是陈旧梯度,因此模型和梯度之间的分歧会混淆优化公式,导致精度下降。为了抑制陈旧梯度的影响,有 3 种方法通过精心设计的学习率对陈旧梯度进行惩罚。 Ho 等人的方案允许计算能力强的工作者在一定的迭代次数内比滞后者更快。 MXNet-G 将工作者划分为同质组,在组内和组间分别采用 SSGD 和 ASGD,并根据每个梯度的陈旧程度分配一个加权因子。还有一些方法试图对陈旧梯度进行补偿,其中最具代表性的是 Zheng 等人提出的方法(DC-ASGD),他们利用梯度函数泰勒展开的一阶项对陈旧梯度进行补偿。
非独立同一分布数据问题。在传统的 DML 中,训练数据是 i.i.d. 的、混合的数据,但在域内 FL 中,由于各方之间的数据隔离,非 i.i.d. 数据仍然存在。幸运的是,Koloskova 等人证明了 SSGD 在非 i.i.d. 数据上与 i.i.d. 数据上具有相同的收敛率。因此,在域内 FL 中,高频同步算法是首选。
ESync 的优点在于:
- 没有丢弃的滞后者中的信息;
- 没有共享数据块
- 没有陈旧的梯度
- 没有额外的超参数
- 无需调整超参数
- 可以适应动态资源。
通过这种方式,ESync 可以加快收敛速度,同时保护隐私并无损地保持准确性。
Architectures Design
同步需要等待工作者的所有更新。 为了避免阻塞,工作者需要决定本地迭代次数,以平衡计算时间。但是,工作者之间不知道彼此的状态和进度,因此无法独立决定本地迭代次数。本文在 Parameter Server 架构中引入了新式调度器 State Server,用于共享状态和进度,协调所有工作者的同步节奏。
Overview
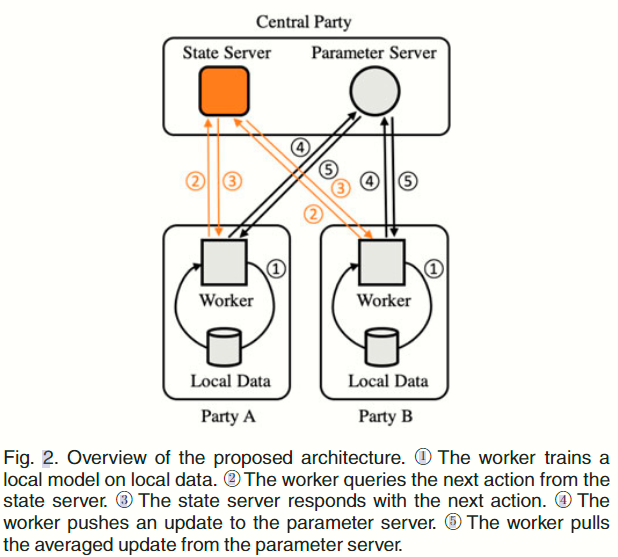
架构概略图如 Fig 2 所示,包含 State Server、Parameter Server、几组 worker,其中 State Server 和 Parameter Server 都位于中央参与方(central party)中,而每个 worker 则位于拥有私有数据的参与方中.
worker 在本地数据上对本地模型进行多次迭代训练,迭代次数由 State Server 自适应地协调,然后将更新推送到 Parameter Server 进行同步。Parameter Server 会对更新进行平均处理,并将平均后的更新同步给所有工作者。请注意,当 worker 数量较多时,可以使用多个 Parameter Server 来平衡流量负载。在这种情况下,每个 Parameter Server 管理不同部分的同步更新。
State Server 监控所有 worker 的实时状态和进度,并查询的 worker 决定其本地迭代次数。为了支持高并发状态查询,State Server 使用轻量级状态控制消息与 worker 交互,并使用多线程任务引擎来操作无锁状态表。
由于共享数据中心存在资源竞争,各方的计算能力和带宽可能会随时间发生变化。为了适应动态资源, State Server 会响应下一个行动,而不是静态设置的本地迭代次数,工作流程可以用下面的序列表示:
worker 无论本地迭代 何时结束,都应向 State Server 查询下一个动作
每当完成一次本地迭代 时,worker 就应向 State Server 查询下一个动作 。然后,当收到下一个动作是 TRAIN 时,它继续本地迭代 ,并在收到 SYNC 时同步更新 。这样,本地迭代次数 就会根据接收到 TRAIN 的次数自适应地变化。
State Server
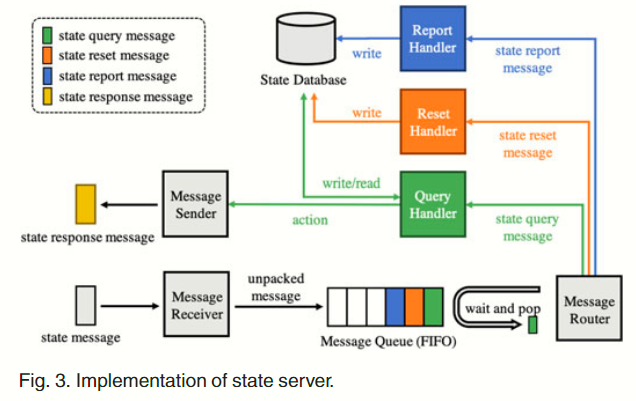
如 Fig 3 所示,State Server 包含消息接收方、消息发送方、FIFO 消息队列、消息路由器、状态数据库、以及一系列消息管理者(掌管报告、重置、查询等职)。在实现中,基于 ZeroMQ 消息库构建了发送方和接收方。
消息队列用于缓冲接收到的消息、平滑峰值工作负载。接收方监听来自 worker 的消息,并且在消息队列中缓冲这些收到的消息。这些缓冲的消息在被消息路由器处理前会一直保存在消息队列中。消息路由器会根据 msg_type 字段将消息发送给对应的处理程序。以查询处理程序(query handler)为例,查询处理程序会根据消息所附的字段更新状态数据库中查询工作者的记录。如果查询处理程序能在滞后者上传更新之前执行另一次迭代,查询处理程序就会输出动作 TRAIN(否则,输出操作 SYNC)。然后,消息发送方会将该操作封装到状态响应消息中,并将消息回复给查询工作者。
Message Format & Message Type
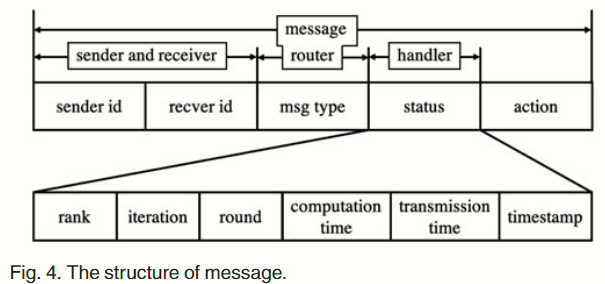
Fig 4 展示了消息的结构——包含发送方标识 sender_id、接收方标识 recver_id、消息类型 msg_type、最新状态 status、下一动作 action 。
sender_id和recver_id字段用于索引发送方和接收方的套接字通道。msg_type字段用于信息路由器将信息转发给相应的处理程序。可选值为{RESET, REPORT, QUERY, RESPONSE}。action字段用于通知查询工作者下一步要执行的操作。- 只有当
msg_type为RESPONSE,且可选值为{TRAIN, SYNC}时,该字段才有意义。 status字段由处理程序用来更新状态数据库中的记录,包括 worker 的等级 (rank)、本地迭代计数器 (iteratioin)、同步轮计数器 (round)、本地迭代的计算时间 (computation time)、推送一个更新到 parameter server 的传输时间 (transmission time)、以及当这条消息被发送时的时间戳 (timestamp)。
State Server 有四种信息,包括状态重置(state reset)信息、状态报告(report)信息、状态查询(query)信息和状态响应(response)信息。
- 状态重置消息由 Parameter Server 发起,用于初始化状态数据库中的记录。
- 状态报告消息由 worker 发起,目的是将其状态和进度(附在消息的
status字段中)同步到 State Server 。 - 状态查询消息由 worker 发起,目的是查询 State Server 以获取下一步操作,并在消息的状态字段中附加最新的状态和进度。
- 状态响应消息由 State Server 用来通知查询 worker 下一步操作。
State Database
消息处理程序的运行过程是单线程的,一次只能处理一条消息,这导致消息在消息队列中累积。为了减少查询信息的响应延迟,状态数据库使用多线程异步任务引擎来运行无锁状态表。
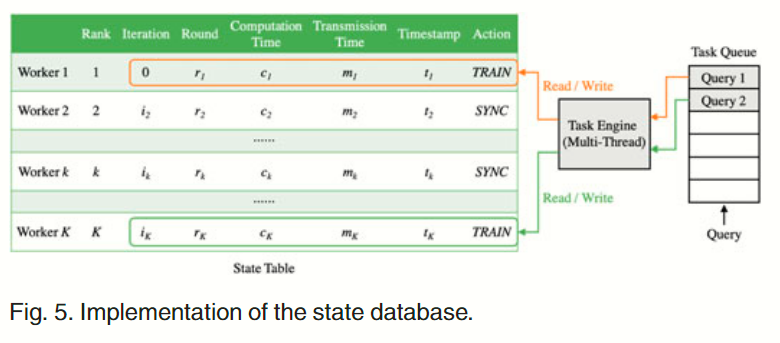
如 Fig 5 所示,状态数据库包含一个任务队列、一个任务引擎和一个状态表。消息处理程序将任务推送到任务队列,并继续处理下一条消息,然后这些任务等待任务引擎处理。
任务队列将消息处理程序和任务引擎分离开来。消息处理程序可以更高效地处理消息,避免消息的累积和丢失。另一方面,任务引擎会将队列中的任务提交给线程池,并运行多个空闲线程来并行执行这些任务。这些线程同时读写无锁状态表。状态表记录了 status 字段中的所有字段(即 rank 、iteration 、round 、computation time 、transmission time 、timestamp )以及正在执行的操作(action )。
不同线程同时读写同一字段可能会造成混乱。我们分析了可能出现的情况,并在算法 1 中进行了修正,以确保读写混淆不会导致查询结果错误。
假设一个滞后者的 rank 是 ,并且延迟定义为计算时间和传输时间之和 ,延迟满足 ( 是所有 work 的数量, 在很小范围内变动)。为了确定查询 worker 的下一动作,任务引擎使用消息所附带的状态 来更新状态表,遍历状态表就可以找到滞后者 :
并将滞后者的状态六元组 返回给查询处理程序。查询处理程序会给出滞后者 何时提交其更新的估计时间 :
并检查查询工作者 是否在 时间内再进行一轮迭代:
这里 是查询处理程序上的当前时间戳。如果此式成立,则消息发送方返回一个状态响应消息 action=TRAIN 给查询工作者 ( 就可以多进行一次训练),否则发送 action=SYNC 要求其更新全局模型。
Modeling and Algorithm
给出数学建模以及 State Server 协调的算法。
Problem Modeling
首先来定义域内 FL 问题,其有 个孤立的参与方,在共享数据中心内协作训练一个 -class 的分类模型。参与方 拥有 个采样: ,采样遵循分布 ,并且这些采样被划分为尺寸 的小组。本文的目标是最小化 (a) 全局损失(global loss)和 (b) 阻塞时间(blocking time)。
Minimize Global Loss
定义函数 ,其通过权重参数 ,将输入 映射到概率向量 ,并用 表示分类 的概率,使用交叉熵损失作为损失函数 ,则
接着,定义参与方 在本地数据集 上训练本地模型 的损失函数为
为了简化分析,忽略了正则项 。全局损失函数 的定义为
这里 是所有数据集 的采样总数。因此,最小化全局损失的目标就是使得 最小且找到最优权重
Minimize Blocking Time
对于参与方 ,其有计算耗时 和传输耗时 ,故总的延迟为 。找出计算耗时和传输耗时中的极值:, 。定义计算异构性为 ,通信异构性为 。

Fig 7 展示了所提出算法 ESync 的时间线,其核心思想是利用阻塞时间让计算能力强的一方训练更多的轮次。因此,参与方 的阻塞时间可以定义为
这里 指的是滞后者, 和 分别是滞后者与参与者的查询时间,并且阻塞时间 总是成立的。
由于数据中心网络的特点是强计算异构性()、弱通信异构性()、拥有充足的带宽,因此为了简便,认为 式 8 中的 (查询时间较计算耗时和通信耗时可忽略)并且 。
因此最小化阻塞时间的目标,等价于寻找一个最佳策略 来协调每个 worker 的本地迭代次数 使得整体阻塞时间最小:
Algorithm Design
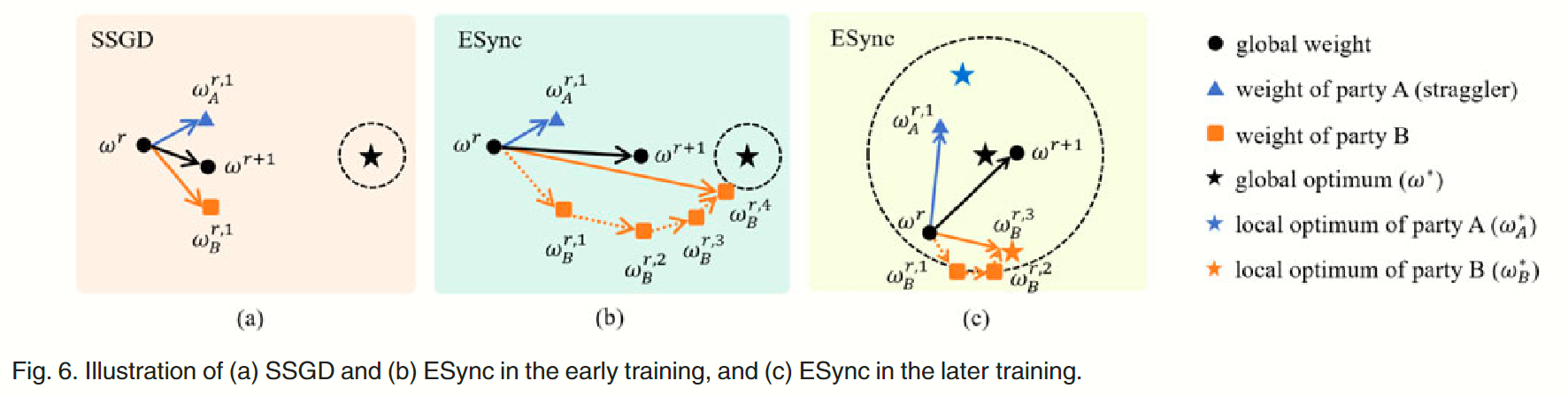
如 Fig 6(a) 所示,SSGD 强迫所有 worker 在每轮迭代时同步各自的本地模型,因此计算能力强的 worker 就会被拖后腿者阻塞,直到滞后者完成更新。阻塞时间对计算能力强的 worker 而言是极大的资源浪费,因此它们更希望利用这段时间进行更多的迭代,追求更高质量的本地模型,这就是 ESync 算法的目标。
如 Fig 6(b) 所示,ESync 允许计算能力强的 worker 尽可能训练更多的轮次,而不必等待滞后者,此时本地迭代次数 自适应地由 State Server 协调。
我们定义第 r 轮训练的全局模型为 ,此时 worker 的本地模型为 ,而经过 轮本地迭代后本地模型记为 ,初始模型 由 Parameter Server 随机初始化。
ESync 的经典步骤包括三步:(1). 本地训练 (2). 状态查询 (3). 全局同步。
Local Training
在第 轮训练开始时,worker 从 Parameter Server 拉取全局模型 并在本地保存一个副本 。接下来,对第 轮本地训练迭代,worker 从本地数据 中采样获得一批数据 ,并计算交叉熵损失以获取梯度
在更新本地模型 时使用基准 SGD 优化算法:
此处 是本地学习率。除了 SGD 还可以使用其他优化算法,例如 RMSProp、Adam、Momentum 等。
本地训练的协调算法如下(看完后面的 Algo 1 和 Algo 2 再回来看):
State Querying
worker 需要向 State Server 发起查询以获得下一步动作的指示,因为它自己并非全知。因此 worker 向 State Server 发送查询信息,其中包含当前状态的六元组 。在 State Server 上的状态查询伪代码如下所示,决定发起查询的 worker 下一步动作的详细细节已由前文公式 (1)、(2)、(3) 描述:
状态回复信息中附带的动作 将会指导 worker 做出相应的动作。如果 ,则 worker 有足够的时间完成新的一轮训练 ;否则将会收到 ,这意味着要么滞后者 完成其训练,要么 worker 没有足够的时间再完成一轮训练,此时的 worker 已经到达了局部训练的目标,满足了第二个目标——最大化利用阻塞时间(反过来说就是最小化阻塞时间的浪费),因此应立即进行同步当前已有的数据。
Global Synchronization
如果收到 ,worker 会计算其本地更新
然后将该更新上传至 Parameter Server 进行合并:
接下来被合并的更新会被 worker 们拉取并更新全局模型
这里 是全局学习率(默认设置为 1)。最新的全局模型 接下来会同步给所有 worker,开启下一轮的迭代训练直到训练轮次达到最大 。全局同步的伪代码如下:
上述流程(Algo 2)实现了第一个目标(最小化全局损失)。等式 11 通过梯度下降减少局部损失 来训练局部模型 ,等式 13、14 则合并参与方们的更新并优化全局模型 ,减少全局损失率 。通过重复这些操作,可以最小化全局损失 并找到一个全局模型 作为最佳模型 的近似。
回到以 high level 的角度观察训练,Fig 6(b) 展示了早期训练中的一个轮次,其中计算能力强的 方在有限的时间内进行了多轮训练得到了本地模型 ,它已经非常接近全局最佳模型 ,在一定程度上推动了滞后者 方的模型 并使其更接近全局最佳模型,从而加速了收敛和避免了阻塞。
同时,ESync 在后续的训练()中并不会陷入局部最佳陷阱,如 Fig 6(c) 所示,powerful party 的本地模型 经过多轮迭代已经到达其局部最佳 ,但滞后方 仍在慢慢推动全局模型 离开 的局部最佳(因为 差距过大,显然是有错误的),最终全局模型 抵达了全局最佳模型 附近的动态平衡点。
ESync 在有限带宽的 cross-silo FL 中亦可以有效运行,这是因为其同时向上游和下游发送更新信息,更新信息可以通过稀疏化技术进行压缩。Lin 等人的论文发现,99.9% 的梯度是多余的,丢弃这些梯度对精度的影响可以忽略不计。因此,我们可以对上下游的冗余更新进行稀疏压缩,从而减少 95% 需要传输的更新。
Convergence Analysis10
本节将从理论上分析 ESync 算法的收敛精度和收敛速率,并将 ESync 与 SSGD 和 FedAvg 的比较进行说明。
定义 为联邦训练中第 轮的模型, 为集中训练中第 轮的模型,因此二者之差别 用于量化精度差距,模型差距越小,则收敛精度越高。
Assumption 1. 给定 个 worker 和 个样本 ,并将 样本 按照 non-i.i.d. 、 的分布分配给 个 worker 。对于 中的每个类 , 个 worker 的总体数据分布 与人口分布 是相同的。
假定 Assumption 1 成立,并且对于 中的每个类 , 是 -Lipschitz11 的。 工作者 每进行 次本地迭代,就会同步更新一次。 那么,ESync 的权重发散的边界为
此处 ,,,并且 。
Proof. 令 ,则会得到
Experimental Evaluation
我们在 MXNET 上制作了 ESync 的原型,在各种设置(不同模型、数据集、数据分布、计算异构性)下进行了大量实验,并将其与传统 DML 和 cross-silo FL 的基准算法进行了比较。
Experimental Setup
环境设置。测试平台建在一个共享数据中心内,拥有 1 Gbps 带宽的局域网网络。 我们使用 3 台机器来模拟 12 个隔离方。 这些机器共有 6 个 GTX 1080 TI GPU 和 6 个英特尔 E 5-2650 v 4 CPU。 我们分别为 12 方运行 12 个 docker 容器,每方贡献 1 个 Worker。 因此,我们有 6 个 GPU Worker 和 6 个 CPU Worker 来训练联合模型。 除非另有说明,计算异质性默认为 hc 1/4 150,即当 CPU 工作者完成一次局部迭代时,GPU 工作者可以训练 150 次局部迭代。 此外,我们随机选择一台机器运行两个额外的容器,其中一个用于参数服务器,另一个用于状态服务器。
模型和数据集。我们在实验中使用了多种卷积模型,包括经典的 AlexNet、ResNet、Deep ResNet、Inception 以及 6 中使用的轻量级模型。我们使用最广泛使用的 CIFAR10 和 Fashion-MNIST 数据集进行实验。CIFAR10 是一个图片分类数据集,由 10 个类别的 50,000 个训练样本和 10,000 个测试样本组成。 Fashion-MNIST 是一个服装分类数据集,由 10 个类别的 60,000 个训练样本和 10,000 个测试样本组成。训练样本按照表 2 所示的 i.i.d. 或非 i.i.d. 设置平均分为 12 个工人。 我们默认使用 i.i.d.设置,以突出 ESync 对计算异质性的优势。
基准算法。域内 FL 是本文提出的一个新概念,因此我们使用传统 DML 算法(SSGD [10]、ASGD [13]、DC-ASGD [14])和 cross-silo FL 算法(FedAvg [2]、FedDrop [11]、TiFL [12]、FedAsync [15])作为基准,比较它们的收敛精度、训练效率、数据吞吐量、流量负载和计算平衡。
训练超参数。我们使用 SGD 优化器进行局部训练,并在以下实验中默认设置局部学习率 、全局学习率 、批量大小 、局部 epoch 数 。
Numerical Results
ESync 与传统 DML 算法对比

训练效率。我们使用不同的模型和数据集来比较 ESync 与高频同步 SSGD、ASGD 和 DC-ASGD 算法的训练效率。 图 9 a 显示了在 ResNet 18 模型和 i.i.d. Fashion-MNIST 数据集上测试准确率随时间变化的曲线。 结果表明,ESync 在训练初期的训练效率与 ASGD 和 DC-ASGD 相近,并能在很短的时间内收敛到最先进的精度(SOTA)。 同时,当测试精度达到 0.8 时,ESync 比 SSGD 节省了 85% 的时间。 图 9 b 对 AlexNet 模型进行了更复杂的设置,使用 i.i.d. CIFAR 10 数据集。 结果表明,ESync 可以在更复杂的任务中实现更高的加速度,其中 ESync 的训练效率远远超过 SSGD、ASGD 和 DC-ASGD。 需要注意的是,由于散兵游勇导致效率低下,SSGD 远未在相同时间内收敛。
 时间节省。我们在多个模型上重复 ESync 和 SSGD 的实验,并比较测试准确率达到 0.8 时的训练时间。 图 10 显示了使用 i.i.d. FashionMNIST 数据集的 ResNet 50-v 1、ResNet 50-v 2、AlexNet 和 Inception-v 3 模型的测试准确率随时间变化的曲线,表 3 给出了测试准确率达到 0.8 所需的时间。 结果表明,在 AlexNet 模型上,ESync 比 SSGD 最多缩短了 96% 的时间。 原因是 ESync 利用阻塞时间处理更多样本,加速了公式(20)中 m 的增加,因此收敛速度比 SSGD 快。
时间节省。我们在多个模型上重复 ESync 和 SSGD 的实验,并比较测试准确率达到 0.8 时的训练时间。 图 10 显示了使用 i.i.d. FashionMNIST 数据集的 ResNet 50-v 1、ResNet 50-v 2、AlexNet 和 Inception-v 3 模型的测试准确率随时间变化的曲线,表 3 给出了测试准确率达到 0.8 所需的时间。 结果表明,在 AlexNet 模型上,ESync 比 SSGD 最多缩短了 96% 的时间。 原因是 ESync 利用阻塞时间处理更多样本,加速了公式(20)中 m 的增加,因此收敛速度比 SSGD 快。
 收敛精度。我们使用 SGD 优化器用完整的时尚-MNIST 数据集(CSGD)训练了一个集中模型,并在表 3 中给出了 CSGD 和 ESync 的收敛精度。 结果表明,ESync 并没有影响收敛精度,令人惊讶的是,ESync 甚至比 SSGD 获得了更高的收敛精度。 原因可能是 ESync 的权重发散引入了适量的噪声,有助于全局模型从尖锐最小值逃逸到平坦最小值,而平坦最小值往往具有更好的泛化效果。
收敛精度。我们使用 SGD 优化器用完整的时尚-MNIST 数据集(CSGD)训练了一个集中模型,并在表 3 中给出了 CSGD 和 ESync 的收敛精度。 结果表明,ESync 并没有影响收敛精度,令人惊讶的是,ESync 甚至比 SSGD 获得了更高的收敛精度。 原因可能是 ESync 的权重发散引入了适量的噪声,有助于全局模型从尖锐最小值逃逸到平坦最小值,而平坦最小值往往具有更好的泛化效果。
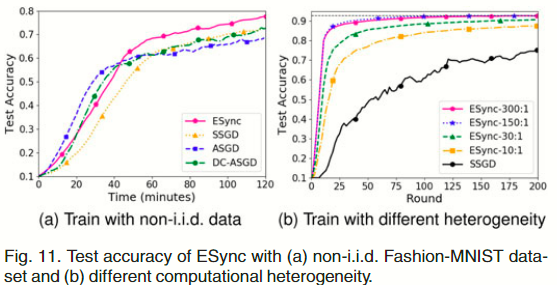 Non-i.i.d 数据上的性能表现。图 11 a 显示了在非 i.i.d 的时尚-MNIST 数据集上,ESync、SSGD、ASGD 和 DC-ASGD 在 AlexNet 模型上的表现。 非 i.i.d. 数据放大了 ASGD 和 DC-ASGD 梯度延迟的影响,导致训练效率急剧下降。 虽然 ASGD 和 DC-ASGD 在训练初期仍有较高的效率,但其准确率很快就被 SSGD 超越,从而失去了效率优势。 ESync 也受到非 i.i.d. 数据的影响,但它在早期训练中的效率仍然接近 ASGD 和 DC-ASGD,准确率也始终优于 SSGD。
Non-i.i.d 数据上的性能表现。图 11 a 显示了在非 i.i.d 的时尚-MNIST 数据集上,ESync、SSGD、ASGD 和 DC-ASGD 在 AlexNet 模型上的表现。 非 i.i.d. 数据放大了 ASGD 和 DC-ASGD 梯度延迟的影响,导致训练效率急剧下降。 虽然 ASGD 和 DC-ASGD 在训练初期仍有较高的效率,但其准确率很快就被 SSGD 超越,从而失去了效率优势。 ESync 也受到非 i.i.d. 数据的影响,但它在早期训练中的效率仍然接近 ASGD 和 DC-ASGD,准确率也始终优于 SSGD。
应对不同异构性的能力。我们通过设置 docker 容器的 CPU 可获取资源来调整一些 worker 的计算能力,以微调计算异构性 。图 11 b 显示了在 ResNet 18 模型上使用 i.i.d. Fashion-MNIST 数据集的测试准确率随轮变化的曲线,其中 h c 从 10 增加到 300。 结果表明,随着 hc 的增加,ESync 的训练效率不断提高,并最终稳定在最佳效率。 我们发现,即使在 hc 1/4 300 : 1 的情况下,ESync 也不会带来精度损失。 这是因为当进行了足够多的局部迭代后,由于局部模型已陷入局部最优,此后的更多迭代将毫无用处,但滞后模型仍能将局部模型推出局部最优。 然而,当 hc 减小到 1 : 1 时,ESync 最终会退化为 SSGD,从而适应同质环境。
ESync 与 cross-silo FL 算法对比
FedAvg 因其高效的通信而被广泛应用于跨分站 FL 中,但它也会受到散兵游勇造成的训练效率低下的影响,特别是当阻塞时间淹没了通信效率的提高时。 有人提出了解决杂波的方法,其中 FedAsync、TiFL 和 FedDrop 被用作基准。

ESync vs. FedAsync. FedAsync 使用加权平均法异步更新全局模型。 我们在实验中使用了 FedAsync 建议的设置。 模型由 4 个卷积层和 1 个全连接层组成。 训练样本被裁剪成 的形状,并分成 50 个批次。 推荐的多项式函数(FedAsync +Poly)和铰链函数(FedAsync+Hinge)用于衰减混合超参数 (0.6 或 0.9),推荐的超参数 a 1/4 0:5 用于 FedAsync+Poly 和 a 1/4 10, b 1/4 4 用于 FedAsync+Hinge。 图 12 a 显示了 ESync、FedAvg 和 FedAsync 使用 i.i.d. Fashion-MNIST 数据集测试的准确率。 FedAsync 通过异步更新避免了阻塞,在早期训练中比 FedAvg 实现了更高的效率。 然而,强大的计算异质性 hc 1/4 150 : 1 加剧了延迟更新的影响,严重破坏了准确性,最终使 FedAsync 被 FedAvg 超越。 相反,在所有推荐设置下,ESync 在效率和准确性方面都优于 FedAvg 和 FedAsync,因为 ESync 是一种没有延迟更新的同步算法。
ESync vs. TiFL. TiFL 将具有相似延迟的工人分成若干层级,每轮选择一个层级,并从该层级中随机选择指定数量的工人参与训练。 我们将 12 个工人分为 2 层(T 1 和 T 2),其中 T 1 有 8 个 GPU 工人,T 2 有 4 个 CPU 工人。 我们使用静态层级选择算法,并将每个层级被选中的初始概率设为 P ðT 1Þ 1/4 0:5 和 P ðT 2Þ 1/4 0:5(简称为 TiFL:PðT 2Þ)。 为了减少整体训练时间,我们将 T 2 层的选择限制为最大次数 Credits 2 1/4 20(简称为 TiFL:CðT 2Þ)。 然后,从所选层级中随机抽取 4 名工人参与训练。 图 12 b 显示了 ESync、FedAvg 和 TiFL 在 ResNet 34 模型和 i.i.d. Fashion-MNIST 数据集上随时间变化的测试准确率。 结果表明,TiFL 只实现了训练效率的小幅提高。 原因是散兵也可能以概率 P ðT 2Þ 被采样,直到它们被选中 Credits 2 次,它们的长计算时间 E nc s b Credits 2 也会被添加到整体训练时间中。 假设 P ðT 2Þ ! 0 或 Credits 2 ! 0 是提高训练效率的好方法。 此时,落伍者被选中的可能性较小,但他们贡献更新的可能性也较小,这就使得落伍者的数据无法被使用,从而造成精度损失(图 13 b 中与 FedDrop 一起解释)。 相反,ESync 最大限度地利用了散兵和强力工人之间的重叠时间,散兵的计算时间可以视为不包含在整体训练时间中,因此 ESync 可以达到比 TiFL 更高的训练效率。

ESync vs. FedDrop. FedDrop 会在收到足够多的更新时更新全局模型,而未能及时报告更新的落伍者将被直接忽略。 测试平台有 8 个 GPU 工作者和 4 个 CPU 工作者,计算异质性为 h c 1/4 150 : 1。 设^K 为放弃的工人数,12 ^K 为接收时间窗口内接受的工人数。 为了实现更高的效率,我们将 ^K 从 4 增加到 11(称为 FedDrop ( ^K)),并在图 13 a 中绘制了使用 i.i.d. FashionMNIST 数据集的 ResNet 34 模型的测试准确率随时间变化的曲线。结果表明,FedDrop 可以通过淘汰滞后者在早期训练中有效加速,但过早收敛,精度较低。 图 13 b 显示了 FedDrop 在不同 ^K 条件下的收敛测试损失。 由于丢弃工人等同于丢弃训练数据,随着丢弃工人的增加,收敛损失会继续恶化,这意味着收敛精度也在恶化。 相反,ESync 仍然比 FedDrop 更高效、更准确,因为它不丢弃工人,收敛精度也比 FedAvg 更高(命题 2),其中 FedDrop ( ^K) ( ^K 4) 相当于规模较小的 FedAvg。
Footnotes
-
Mcmahan, H., et al. Communication-Efficient Learning of Deep Networks from Decentralized Data. ↩ ↩2
-
Yao, Xin, et al. “Federated Learning with Unbiased Gradient Aggregation and Controllable Meta Updating.” Cornell University - arXiv, Cornell University - arXiv, Oct. 2019. ↩ ↩2
-
Bonawitz, Kallista, et al. “Towards Federated Learning at Scale: System Design.” Proceedings of Machine Learning and Systems, Proceedings of Machine Learning and Systems, Apr. 2019. ↩ ↩2
-
Z. Chai et al., “TiFL: A tier-based federated learning system,” 2020, arXiv: 2001.09249. ↩ ↩2
-
Zheng, Shuxin, et al. “Asynchronous Stochastic Gradient Descent with Delay Compensation.” arXiv: Learning, arXiv: Learning, Sept. 2016. ↩ ↩2
-
Xie, Cong, et al. “Asynchronous Federated Optimization.” arXiv: Distributed, Parallel, and Cluster Computing, arXiv: Distributed, Parallel, and Cluster Computing, Mar. 2019. ↩ ↩2 ↩3
-
Zinkevich, Martin, et al. “Parallelized Stochastic Gradient Descent.” Neural Information Processing Systems, Neural Information Processing Systems, Dec. 2010. ↩
-
Dean, J. Michael, et al. “Large Scale Distributed Deep Networks.” Neural Information Processing Systems, Neural Information Processing Systems, Dec. 2012. ↩
-
懒得抄了,看原文吧,证明很复杂。 ↩