Motivation and Primal Problem
Soft-Margin SVM
前三节讨论的都是 Hard-Margin SVM ,即要求所有对样本的判断都要正确:
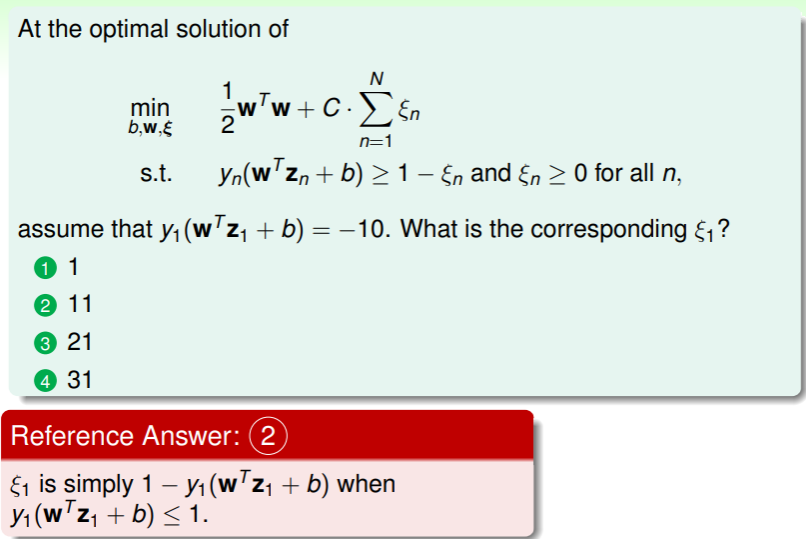
这样的缺点就是在有噪音的数据集中,会导致过拟合现象发生:

因此,为了避免过拟合现象,我们必须考虑舍弃这些噪音样本。回想 pocket 算法中对噪音样本的处理: ,我们可以结合 pocket 和 hard-margin SVM ,以实现对噪音容忍的 soft-margin SVM :
- 这里目标中的 作用是对 SVM 的 margin 宽度和噪音容忍度的权衡,
- 限制条件中对正确的样本点要判断正确,而对噪音点的样本判断结果不至于过大;
Solution of Soft-Margin SVM
对 soft-margin SVM 的假设仔细察看,可以很容易发现,这里 并不是线性的条件,它是对每个样本的 label 和预测的正误判断,因此就不是 QP 问题,而之前讨论的 Dual SVM 、Kernel SVM 在这里也就不再适用。😢
并且,我们这样笼统地说判断结果与实际 label 的差异不致于过大(即, ),这也未免太过宽松。毕竟,有的预测可能仅与 boundary 差距毫厘,而有的预测却谬之千里,我们上面的 soft-margin SVM 不能很好地区分这两种预测错误,因此势必要对 soft-margin SVM 的假设做进一步改进。
我们提出对判断与 label 差距程度的考量,即 margin violation ,记作 ,通过对 margin violation 的惩罚代替犯错数的限制,从而转化为 linear constraints 的 QP 问题。于是 soft-margin SVM 的假设修改为:
这里 的作用仍然没有变化,但是更进一步地可以理解为调节 margin length 和 margin violation 的权重:
- 大 代表对噪音的容忍度更低;
- 而小 代表更大的 margin ,提高对噪音的容忍度;
于是,soft-margin SVM 就转化为 个变量、 个条件限制的 QP 问题,我们可以从此推导出 Dual Soft-Margin SVM ,进行更细致的考量。
练习:理解 margin violation
Dual Problem
实现 soft-margin SVM 的对偶问题转化,同样离不开拉格朗日函数:
- 这里 即是计算拉格朗日函数的两个限制的系数;
同理,我们要得到的拉格朗日对偶问题,形式如下:
类似地,我们要求解这个对偶问题,首先要进行化简。先要在 中找到极小值,因此极小点处有:
和之前一样,我们按图索骥:直接将 作为限制,于是可以移除拉格朗日对偶问题中的 :
- 这里之所以 的限制变为 ,是因为 发生了变化,并且要保证 ;
Simplify Lagrange Dual
现在,我们再细细查看简化后的拉格朗日对偶问题,似乎和之前 Dual hard-margin SVM 有些相似?仔细对比,实际上二者差异仅仅是限制条件,因此我们可以依葫芦画瓢,进一步实现化简:
- 由于极小值点 ,因此我们可以得到限制条件 ;
- 并且 ,我们可以得到限制条件 ;
因此,最终化简后的 Soft-Margin SVM Dual 为:
- 其中暗含的条件就是 和
这样,我们通过对偶问题的转化,得到了仅有 个变量、 个限制的 QP 问题。
练习:理解 primal 问题中 C 的影响

Message behind Soft-Margin SVM
得到对偶 soft-margin SVM 后,我们就能照例引入 kernel function 来进一步祛除对 的依赖,现在 kernel soft-margin SVM 的计算流程如下:

- 这与 hard-margin SVM 的 kernel 形式几乎一致,不过在边界处理和对噪音点处理上更加灵活;
Determine Parameter
不过上图中有一个参数的确定与 hard-margin SVM 不太一样,那就是 。回想 hard-margin SVM 的参数 的求解过程,在 KKT 条件下,要从如下条件中解出 :
因此只要找到任意一个 的 SV ,就可以求得 。类似地,要从如下条件的 soft-margin SVM 中解出 :
除了要满足 才能得到 外,还要满足 ,即 margin violation 的程度 ,这意味着是在 soft-margin SVM 的 boundary 内部的 SV ,通常称为 free SV 。
因此,综合起来,求解 soft-margin SVM 中参数 的方法是:对任意 free SV ,求得:
Role of Parameter
另一方面,soft-margin SVM 中参数 的直观意义是如何呢?
- 通过 Gaussian Kernel Function 简化的 soft-margin SVM 如下:
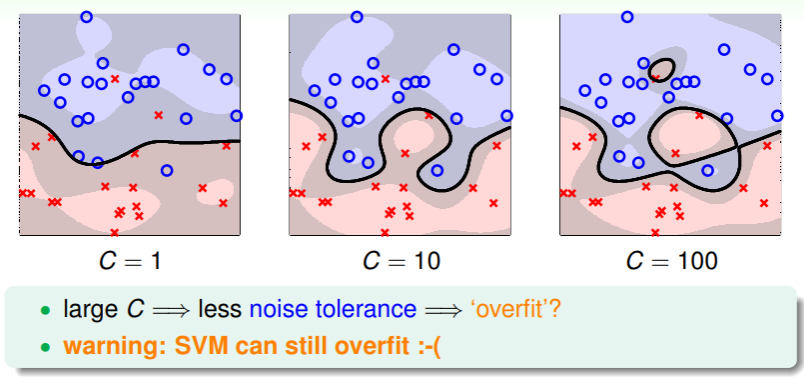
- 这表明,即使是 soft-margin SVM ,仍有过拟合的风险,因此我们要小心地考虑参数 的抉择;
Physical Meaning of
从物理意义上看,参数 的具体意义又是什么?
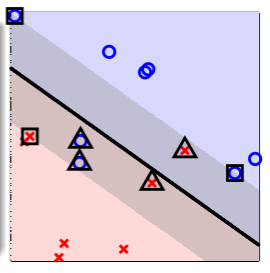
- 上图显示了一个 soft-margin SVM 与各种 SV 样本点、非 SV 样本点的分布情况,
- 非 SV 样本点,不受到 SVM 的限制,故而 ,从而 ,
- free SV 样本点是 的那些样本,其对应的 ,即没有违反 margin 限制,它们都位于 SVM 的边界 boundary 上,
- bounded SV 样本点是 的那些样本,其对应的 ,即在 soft-margin SVM 中违反 margin 限制的程度,它们位于边界 boundary 内部;
练习:计算 SVM 的数据集内错误率

Model Selection
我们又遇到了选择合适的模型的问题,现在以 Gaussian SVM 为例,我们考查其参数 对模型性能的影响:
- 下图横轴是参数 的大小,纵轴是参数 的大小:
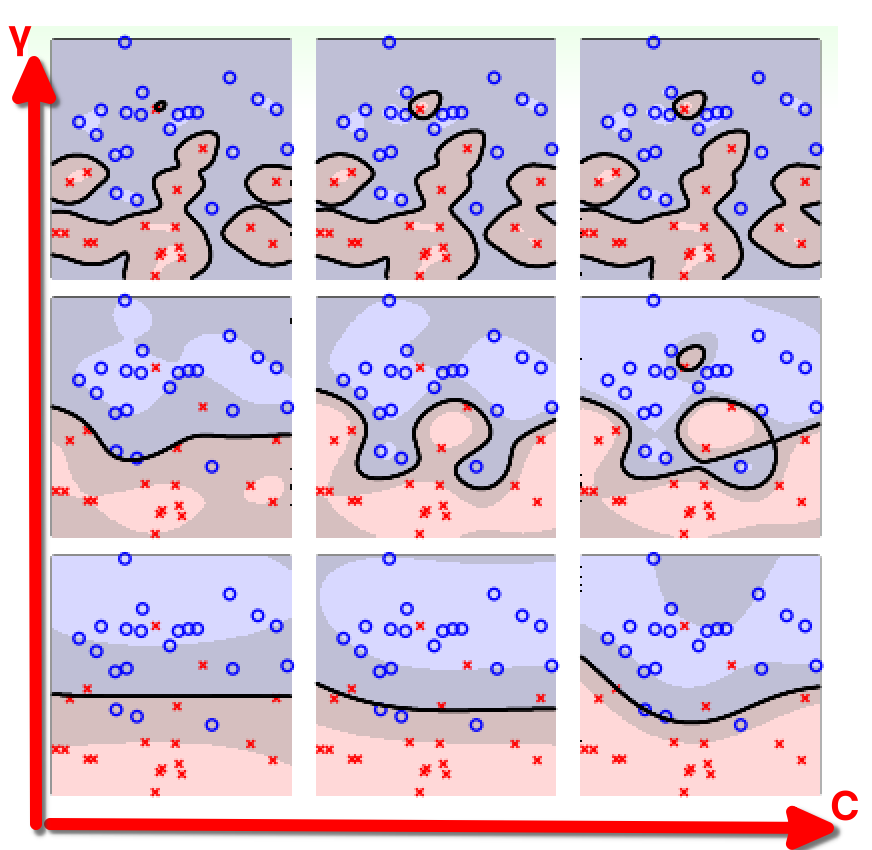
- 我们能够进行选择的依据,就是之前学习过的 交叉验证 ,不过在 SVM 中,交叉验证的犯错率 并不是平滑的、易求解最小值的函数,通常只能尝试不同的 的组合来试探:下图是用 V-Fold 交叉验证计算的各组合结果,则其最小者为目标模型即可

Leave-One-Out CV Bound
不过这样通过“逐个试探”的不仅效率低下,而且还容易出纰漏,因此我们有必要考查交叉验证时犯错的概率极限。回想最极端的交叉验证法—— 留一交叉验证 :
- 如果数据集中一个样本 在 SVM 的限制条件中最佳的 ,即意味着它是非支撑向量,那么即是祛除该样本,剩余的 个样本的 仍然是最优的(否则还可以从中取出一个 ,去掉之后仍然最优);
- 这意味着祛除该样本的留一交叉验证中,两个假设 与 没有区别,即 ,而对真正有用的支撑向量,其在留一交叉验证中的影响 ;
- 因此可以得到留一交叉验证在 SVM 中的犯错率 ,即犯错率的上限不超过支撑向量的数量在所有样本中的占比(N 的实际含义其实是 V-Fold 的折数,但在留一交叉验证中 N 在数值上等于样本数)
- 这就是在数学上证明了前面所说 SVM 中只有真正的 SV 才是有用的:
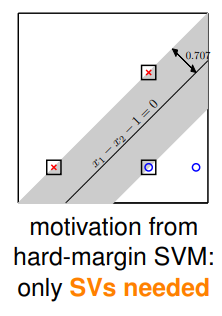
这个上界能够提供什么信息?
- 显然,支撑向量的实际数量 也并不是一个平滑函数,并且在查看过所有样本点外无法完全确定;
- 另外“上界”只能用于参考,比如抛弃 SV 数量最多的那一部分 SVM 模型,但“上界”终究只是“上界”,我们不能完全依赖它作以评判:
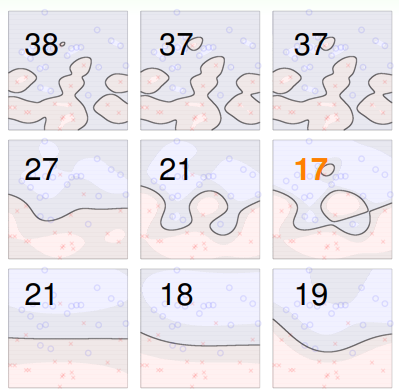
- 因此使用 作为 SVM 模型的一种安全检查是比较合理的;
练习:理解 SVM 的留一交叉验证错误率
