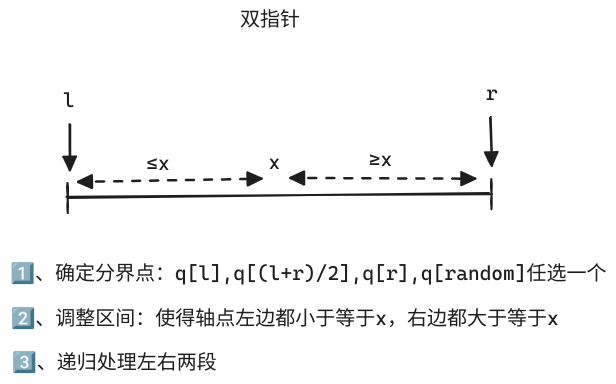
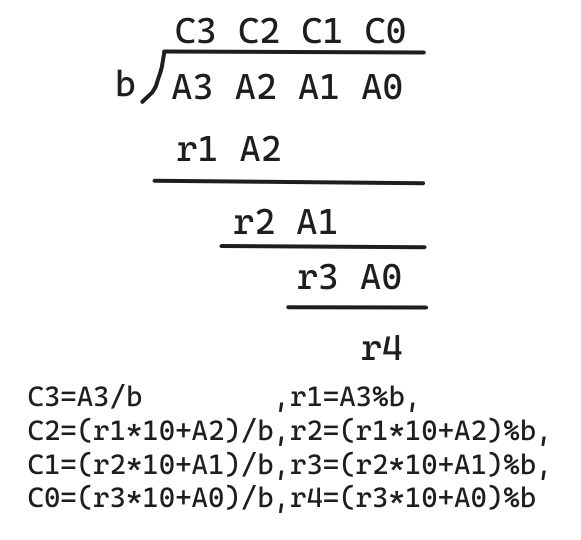void quick_sort(int q[], int l, int r){ if (l >= r) return; // 递归基 int i = l - 1, j = r + 1, x = q[l + r >> 1]; // 设置哨兵、分界点 while (i < j) { do i ++ ; while (q[i] < x); do j -- ; while (q[j] > x); // 分别从左右两端开始,一直找到不符合区间要求的点 if (i < j) swap(q[i], q[j]); // 交换之 } quick_sort(q, l, j), quick_sort(q, j + 1, r); // 递归处理}
//使用三数取中法进行改进#include <algorithm> // For std::swap#include <iostream>// Utility function to find the median of three valuesint medianOfThree(int a, int b, int c) { if ((a < b) ^ (a < c)) return a; else if ((b < a) ^ (b < c)) return b; else return c;}void quickSort(int q[], int l, int r) { if (l >= r) return; // Base case // Middle of three method for pivot selection int mid = l + (r - l) / 2; int pivot = medianOfThree(q[l], q[mid], q[r]); int i = l, j = r; while (i <= j) { while (q[i] < pivot) i++; while (q[j] > pivot) j--; if (i <= j) { std::swap(q[i], q[j]); i++; j--; } } // Recursively sort the two partitions if (l < j) quickSort(q, l, j); if (i < r) quickSort(q, i, r);}// Example usageint main() { int arr[] = {9, -3, 5, 2, 6, 8, -6, 1, 3}; int n = sizeof(arr) / sizeof(arr[0]); quickSort(arr, 0, n - 1); for (int i = 0; i < n; i++) { std::cout << arr[i] << " "; } std::cout << std::endl; return 0;}
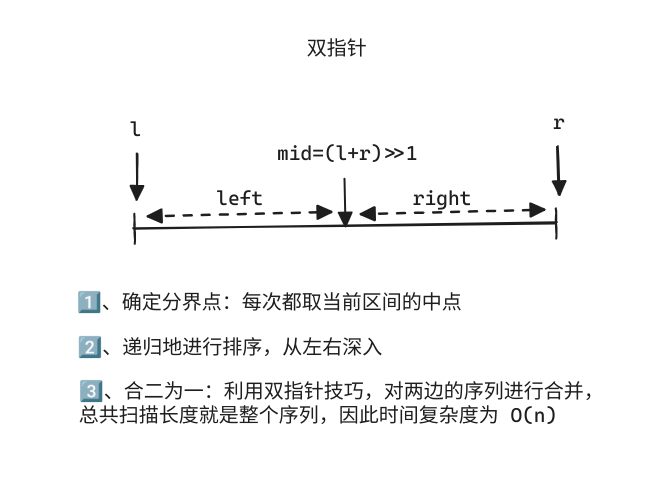
归并排序
void merge_sort(int q[], int l, int r){ if (l >= r) return; // 递归基 int mid = l + r >> 1; merge_sort(q, l, mid); merge_sort(q, mid + 1, r); // 递归 int k = 0, i = l, j = mid + 1; //k用于计数已经完成了多少个合并,i和j分别表示左右边界 while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ]; else tmp[k ++ ] = q[j ++ ]; while (i <= mid) tmp[k ++ ] = q[i ++ ]; //有剩余元素的话直接接到末尾 while (j <= r) tmp[k ++ ] = q[j ++ ]; for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];}
二分搜索
整数二分
bool check(int x) {/* ... */} // 检查x是否满足某种性质// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:int bsearch_1(int l, int r){ while (l < r) { int mid = l + r >> 1; if (check(mid)) r = mid; // check()判断mid是否满足性质 else l = mid + 1; } return l;}// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:int bsearch_2(int l, int r){ while (l < r) { int mid = l + r + 1 >> 1; if (check(mid)) l = mid; else r = mid - 1; } return l;}
int bin_search(int *arr, int target, int lo, int hi) { // [lo,hi) while (lo < hi) { int mi = lo + (hi - lo) / 2; if (arr[mi] < target) lo = mi + 1; else if (arr[mi] > target) hi = mi; else return mi; } return -1;}
#include <iostream>using namespace std;const double eps = 1e-8;double cubic_root(double x) { double l, r; if (x == 0.000000) { return 0.000000; } else if (x > 0) { l = 0.000000, r = x + 1; // 处理0<x<1的部分,下面同理 while (r - l > eps) { double mid = (l + r) / 2; if (mid * mid * mid > x) r = mid; else l = mid; } } else { l = x - 1, r = -0.000000; while (r - l > eps) { double mid = (l + r) / 2; if (mid * mid * mid > x) r = mid; else l = mid; } } return l;}int main() { double n; cin >> n; double res = cubic_root(n); printf("%.6f", res); //cout<<fixed<<setprecision(6)<<res; // 记得添加iomanip头文件来使用这条语句 return 0;}
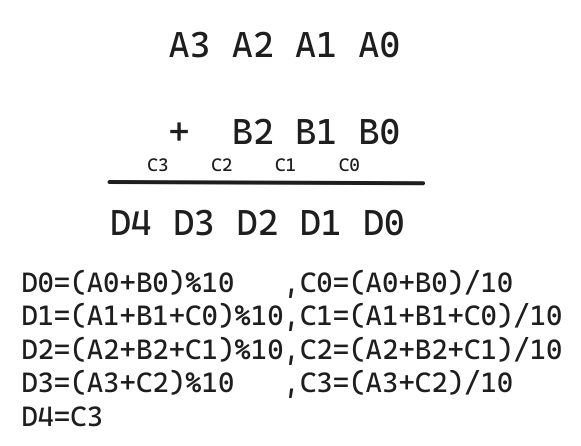
高精度计算
数据存储
数组存大整数,并且小端存法——数组低位存放数据的低位。
int main() { string a, b; vector<int> A, B; cin >> a >> b; // a = "123456" for (int i = a.size() - 1; i >= 0; i--) A.push_back(a[i] - '0'); // A = [6,5,4,3,2,1],之所以要减'0',是为了将字符转换为int for (int i = b.size() - 1; i >= 0; i--) B.push_back(b[i] - '0'); auto C = add(A, B);}
加法
通常是两个大整数相加,各自的位数在 106 量级;
// C = A + B, A >= 0, B >= 0vector<int> add(vector<int> &A, vector<int> &B){ if (A.size() < B.size()) return add(B, A); vector<int> C; int t = 0; for (int i = 0; i < A.size(); i ++ ) { t += A[i]; if (i < B.size()) t += B[i]; C.push_back(t % 10); t /= 10; } if (t) C.push_back(t); return C;}
减法
通常是两个大整数相减,各自的位数在 106 量级;
// C = A - B, 满足A >= B, A >= 0, B >= 0// 如果不满足 A >= B 呢?只需要计算 -(B - A) 即可vector<int> sub(vector<int> &A, vector<int> &B){ vector<int> C; for (int i = 0, t = 0; i < A.size(); i ++ ) { t = A[i] - t; if (i < B.size()) t -= B[i]; C.push_back((t + 10) % 10); // 当t<0时需要借位,此时要+10,否则不必借位,因此将这两种情况合起来写 if (t < 0) t = 1; else t = 0; } while (C.size() > 1 && C.back() == 0) C.pop_back(); // 去掉前缀的0 return C;}
// 判断 A 和 B 的大小bool cmp(vector<int> &A, vector<int> &B) { if (A.size() != B.size()) return A.size() > B.size(); for (int i = A.size() - 1; i >= 0; i--) if (A[i] != B[i]) return A[i] > B[i]; return true;}
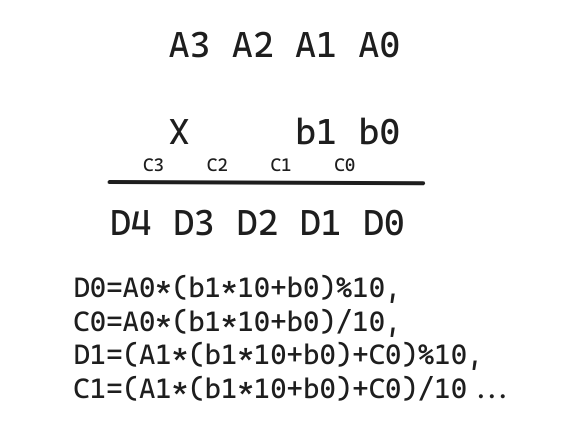
乘法
通常是一个大整数乘一个稍小的数,大整数的位数在 106 量级,稍小数的数值在 106 量级;
// C = A * b, A >= 0, b >= 0vector<int> mul(vector<int> &A, int b){ vector<int> C; int t = 0; for (int i = 0; i < A.size() || t; i ++ ) { if (i < A.size()) t += A[i] * b; C.push_back(t % 10); t /= 10; } while (C.size() > 1 && C.back() == 0) C.pop_back(); return C;}
除法
通常是一个大整数除以一个稍小的数,大整数的位数在 106 量级,稍小数的数值在 106 量级;
// A / b = C ... r, A >= 0, b > 0vector<int> div(vector<int> &A, int b, int &r){ vector<int> C; r = 0; for (int i = A.size() - 1; i >= 0; i -- ) { r = r * 10 + A[i]; C.push_back(r / b); r %= b; } reverse(C.begin(), C.end()); while (C.size() > 1 && C.back() == 0) C.pop_back(); return C;}
#include <iostream>using namespace std;const int N = 100010;int main() { ios::sync_with_stdio(false); int n, m; cin >> n >> m; int arr[N] = {0}; int sum[N] = {0}; for (int i = 1; i <= n; i++) { cin >> arr[i]; sum[i] = sum[i - 1] + arr[i]; } int l, r; for (int i = 1; i <= m; i++) { cin >> l >> r; cout << sum[r] - sum[l - 1] << endl; } return 0;}
#include <iostream>using namespace std;const int N = 1010;int main() { int n, m, q; cin >> n >> m >> q; int arr[N][N], sum[N][N] = {0}; for (int i = 1; i <= n; i++) { for (int j = 1; j <= m; j++) { cin >> arr[i][j]; sum[i][j] = arr[i][j] + sum[i][j - 1] + sum[i - 1][j] - sum[i - 1][j - 1]; } } int x1, x2, y1, y2; for (int i = 0; i < q; i++) { cin >> x1 >> y1 >> x2 >> y2; cout << sum[x2][y2] - sum[x2][y1 - 1] - sum[x1 - 1][y2] + sum[x1 - 1][y1 - 1] << endl; } return 0;}
位运算
整数二进制表示的第 k 位的值
int kth_val(int x){ return (x>>k)&1;}
整数的最后一位 1
// x = 1010...100...00// ~x = 0101...011...11// ~x+1 = 0101...100...00// x & (~x+1) = 0000...100...00// -x == ~x+1 (-x 就是取补码操作) int lowbit(int x){ return x & -x;}
二进制中 1 的个数
int countOnes( unsigned int n ) { //O(ones):正比于数位1的总数 int ones = 0; //计数器复位 while ( 0 < n ) { //在n缩减至0之前,反复地 ones++; //计数(至少有一位为1) n &= n - 1; //清除当前最靠右的1 } return ones; //返回计数}
还可以使用 lowbit() 来实现:
int countOnes(unsigned int n){ int ones=0; while(n) n -= lowbit(n),ones++; // 每次减去n的最后一位1 cout<<res<<endl;}
快速幂
// recursive styleinline __int64 sqr(__int64){return a*a;}__int64 power2(int n){ //计算幂函数2^n if(0==n) return 1;//递归基,否则视n的奇偶分别递归 return (n&1)?sqr(power2(n>>1))<<1 : sqr(power2(n>>1));} // O(logn)=O(r),r为输入指数n的比特位数// recurrent style__int64 power2_I ( int n ) { //幂函数2^n算法(优化迭代版),n >= 0 __int64 pow = 1; //O(1):累积器初始化为2^0 __int64 p = 2; //O(1):累乘项初始化为2 while ( 0 < n ) { //O(logn):迭代log(n)轮,每轮都 if ( n & 1 ) //O(1):根据当前比特位是否为1,决定是否 pow *= p; //O(1):将当前累乘项计入累积器 n >>= 1; //O(1):指数减半 p *= p; //O(1):累乘项自乘 } return pow; //O(1):返回累积器} //O(logn) = O(r),r为输入指数n的比特位数
双指针策略
for (int i = 0, j = 0; i < n; i ++ ){ while (j < i && check (i, j)) j ++ ; // 具体问题的逻辑}
常见问题分类:
对于一个序列,用两个指针维护一段区间
对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
优势:将暴力方法中的逐项枚举,通过某种单调性质优化到 O(n)
// brute forcefor (int i = 0; i < count; i++){ for (int j = 0; j < count; j++) { /* code */ }} // O(n^2)
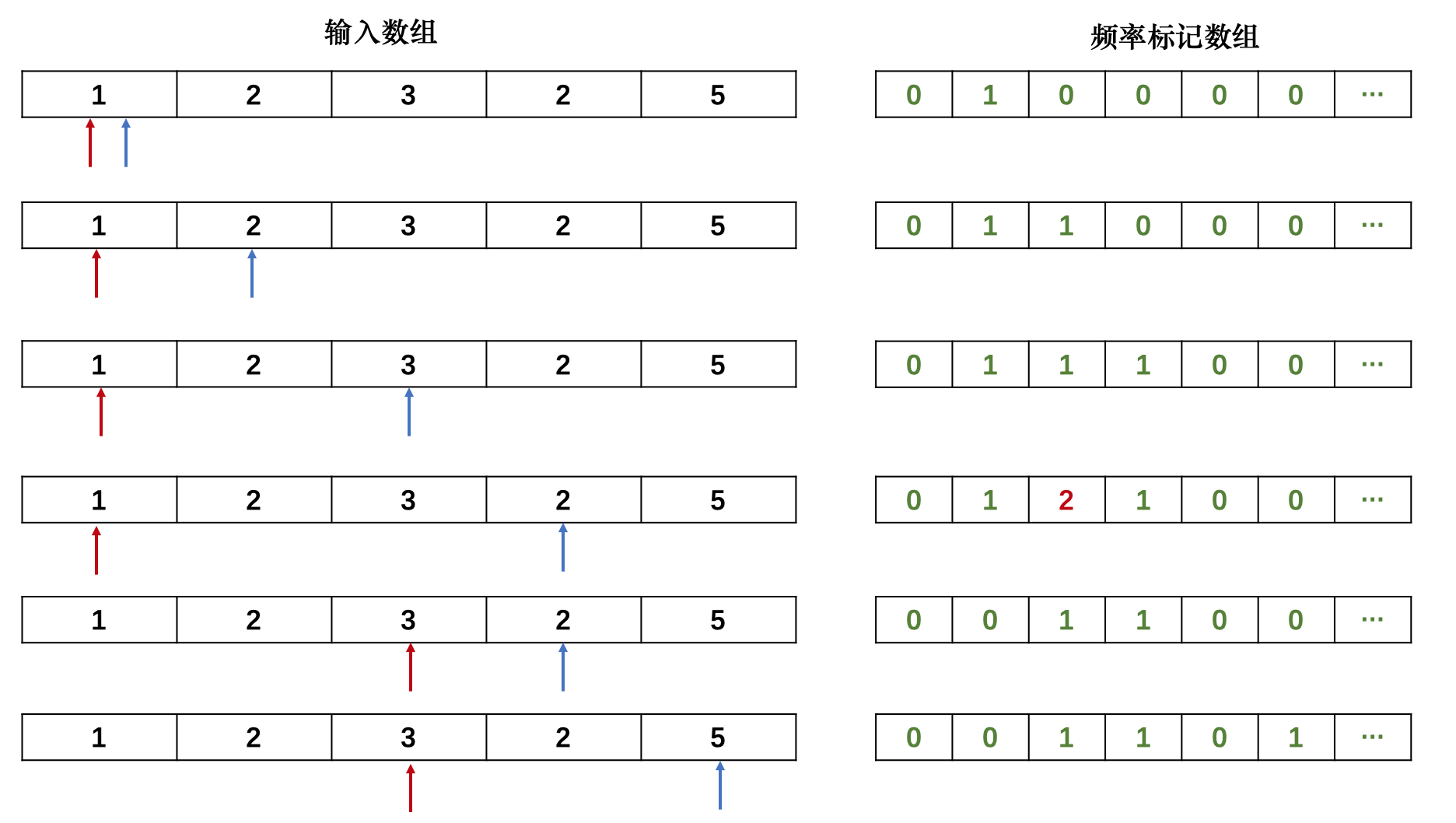
#include <iostream>#include <unordered_set>using namespace std;const int N = 100010;int main() { int n; cin >> n; int arr[N]; for (int i = 0; i < n; i++) cin >> arr[i]; unordered_set<int> seen; int l = 0, r = 0, cnts = 0, max_length = 0; while (r < n) { if (seen.find(arr[r]) == seen.end()) { seen.insert(arr[r]); cnts = r - l + 1; // Update the length of current subsequence max_length = max(max_length, cnts); r++; } else { seen.erase(arr[l]); // Remove element at left pointer l++; } } cout << max_length << endl;}
/*核心思路:遍历数组a中的每一个元素a[i], 对于每一个i,找到j使得双指针[j, i]维护的是以a[i]结尾的最长连续不重复子序列,长度为i - j + 1, 将这一长度与r的较大者更新给r。对于每一个i,如何确定j的位置:由于[j, i - 1]是前一步得到的最长连续不重复子序列,所以如果[j, i]中有重复元素,一定是a[i],因此右移j直到a[i]不重复为止(由于[j, i - 1]已经是前一步的最优解,此时j只可能右移以剔除重复元素a[i],不可能左移增加元素,因此,j具有“单调性”、本题可用双指针降低复杂度)。用数组s记录子序列a[j ~ i]中各元素出现次数,遍历过程中对于每一个i有四步操作:cin元素a[i] -> 将a[i]出现次数s[a[i]]加1 -> 若a[i]重复则右移j(s[a[j]]要减1) -> 确定j及更新当前长度i - j + 1给r。注意细节:当a[i]重复时,先把a[j]次数减1,再右移j。*/# include <iostream>using namespace std;const int N = 100010;int a[N], s[N];int main(){ int n, r = 0; cin >> n; for (int i = 0, j = 0; i < n; ++ i) { cin >> a[i]; ++ s[a[i]]; while (s[a[i]] > 1) -- s[a[j++]]; // 先减次数后右移 r = max(r, i - j + 1) ; } cout << r; return 0;}
利用两个数组的升序性质,通过双指针的方式来减少时间复杂度。具体做法是从数组 A 的头部和数组 B 的尾部开始进行查找,逐步向中间移动指针,直到找到满足条件的元素对。
#include <iostream>using namespace std;const int N = 100010;int A[N], B[N];int main() { int n, m, x; cin >> n >> m >> x; for (int i = 0; i < n; i++) cin >> A[i]; for (int i = 0; i < m; i++) cin >> B[i]; int i = 0, j = m - 1; while (i < n && j >= 0) { if (A[i] + B[j] == x) { cout << i << " " << j; return 0; } else if (A[i] + B[j] < x) i++; else j--; } return 0;}
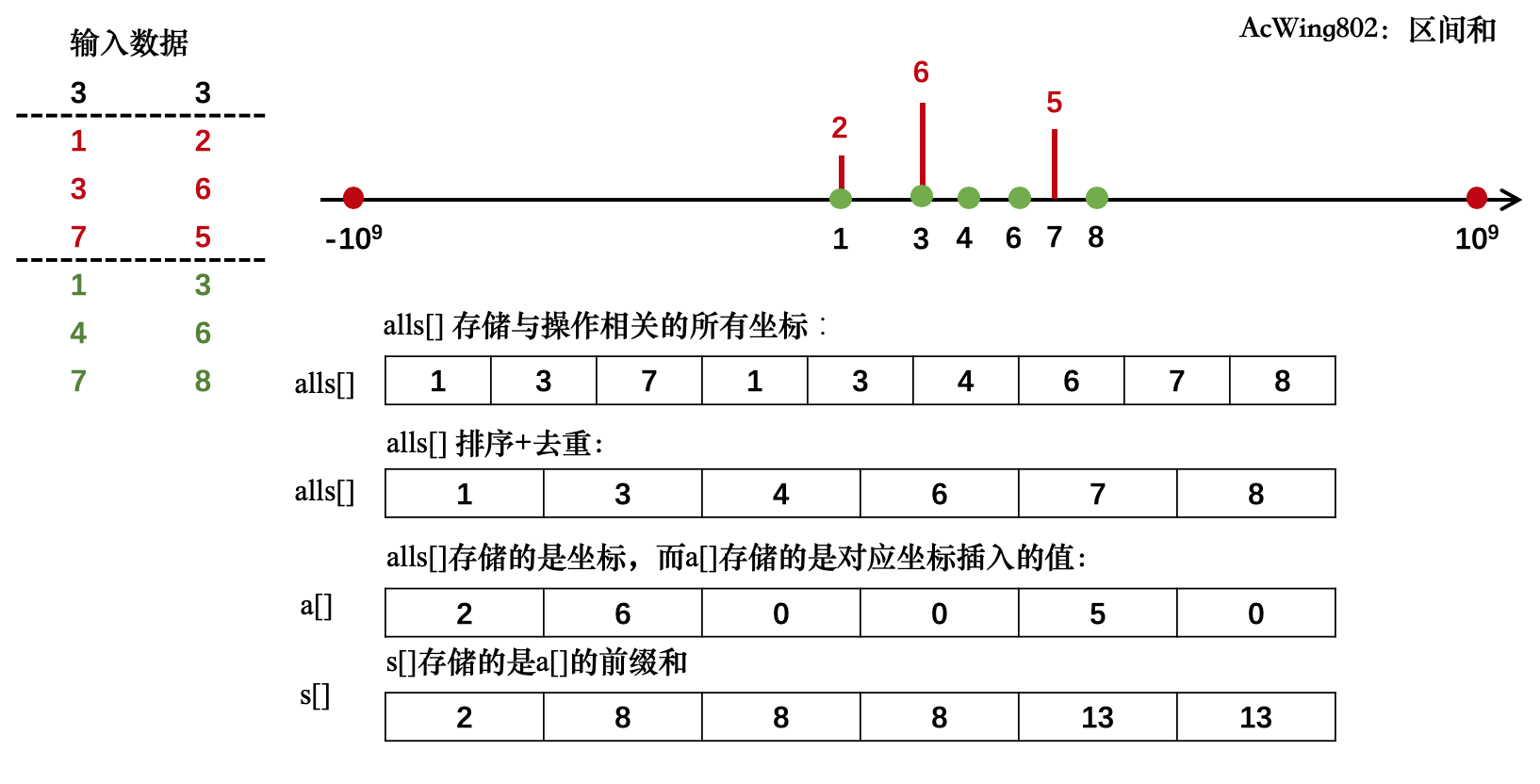
#include <algorithm>#include <iostream>#include <vector>using namespace std;const int N = 300010; // n次插入和m次查询相关数据量的上界int n, m;int a[N]; // 存储对应坐标插入的值int s[N]; // 存储数组a的前缀和vector<int> alls(N); // 存储(所有与插入和查询相关的)坐标vector<pair<int, int>> add, query; // 存储插入和查询的数据int find(int x) { // 返回输入坐标离散化后的新坐标 int l = 0, r = alls.size() - 1; while (l < r) { int mid = l + r >> 1; if (alls[mid] >= x) r = mid; else l = mid + 1; } return r + 1;}int main() { iso::sync_with_stdio(false); cin >> n >> m; for (int i = 0; i < n; i++) { int x, c; cin >> x >> c; add.push_back({x, c}); alls.push_back(x); } for (int i = 0; i < m; i++) { int l, r; cin >> l >> r; query.push_back({l, r}); alls.push_back(l); alls.push_back(r); } // 排序、去重 sort(alls.begin(), alls.end()); alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 执行前n次插入操作 for (auto item : add) { int x = find(item.first); a[x] += item.second; } // 计算前缀和 for (int i = 1; i <= alls.size(); i++) s[i] = s[i - 1] + a[i]; // 处理m次查询操作 for (auto &&i : query) { int l = find(i.first); int r = find(i.second); cout << s[r] - s[l - 1] << endl; } return 0;}
// 使用unordered_map优化版#include <iostream>#include <vector>#include <unordered_map>#include <algorithm>using namespace std;// 存储插入和查询操作的数据,不再需要alls数组vector<pair<int, int>> add, query;// 使用unordered_map来离散化坐标并直接映射值unordered_map<int, int> idxMap; // 存储坐标的新旧映射unordered_map<int, int> prefixSum; // 存储离散化坐标的前缀和int main() { ios::sync_with_stdio(false); int n, m; cin >> n >> m; // 读取插入操作 for (int i = 0; i < n; i++) { int x, c; cin >> x >> c; add.push_back({x, c}); } // 读取查询操作 for (int i = 0; i < m; i++) { int l, r; cin >> l >> r; query.push_back({l, r}); } // 离散化,使用vector来存储所有坐标,然后排序去重 vector<int> alls; for (auto& item : add) { alls.push_back(item.first); } for (auto& item : query) { alls.push_back(item.first); alls.push_back(item.second); } sort(alls.begin(), alls.end()); alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 建立坐标与新索引的映射 int idx = 0; for (int x : alls) { idxMap[x] = ++idx; } // 执行插入操作,直接使用映射更新值 for (auto& item : add) { int x = idxMap[item.first]; // 获取映射后的坐标 prefixSum[x] += item.second; } // 计算前缀和 for (int i = 1; i <= idx; i++) { prefixSum[i] += prefixSum[i - 1]; } // 处理查询操作 for (auto& item : query) { int l = idxMap[item.first] - 1; // 获取映射后的左坐标,并向前移动一个单位以适应前缀和的计算 int r = idxMap[item.second]; // 获取映射后的右坐标 cout << prefixSum[r] - prefixSum[l] << endl; } return 0;}
区间合并
按区间左端点进行排序
// 将所有存在交集的区间合并void merge(vector<PII> &segs){ vector<PII> res; sort(segs.begin(), segs.end()); int st = -2e9, ed = -2e9; for (auto seg : segs) if (ed < seg.first) { if (st != -2e9) res.push_back({st, ed}); st = seg.first, ed = seg.second; } else ed = max(ed, seg.second); if (st != -2e9) res.push_back({st, ed}); segs = res;}