在 ML 中三个关键的锦囊妙计,一定要注意、遵循。
Occam’s Razor
如无必要,勿增实体
Entities must not be multiplied beyond necessity. ——William of Occam (1287-1347)
奥卡姆剃刀之意,就是除去所有不必要的东西,使得尽可能精简。这在之前的学习中也多有体现:尽可能使用最简单的模型来拟合数据。
简单的模型有两个角度的含义:
- 简单的假设 :这通常指模型的代价 简单, 的参数较少;
- 简单的假设集 :指该假设集中所含的假设数量较少,维度较低;
假设与假设集之间数量的联系是:
- 假设集的规模是 ,即假设 是由 个 位/参数 确定;
- 越小的 也就决定了越小的 ;
从直观上看,越简单就越好:越简单的假设集 得到的 越小,这样虽然完全拟合当前数据的概率 较小,但是在更广范围内拟合未知数据的概率却上升了:
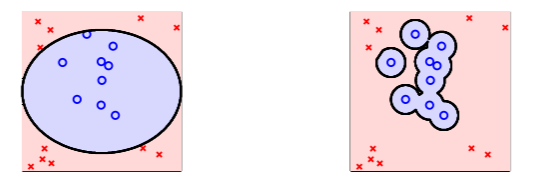
这给我们的经验是,在进行 ML 训练时,从线性模型做起,而不要选择过度复杂的模型。
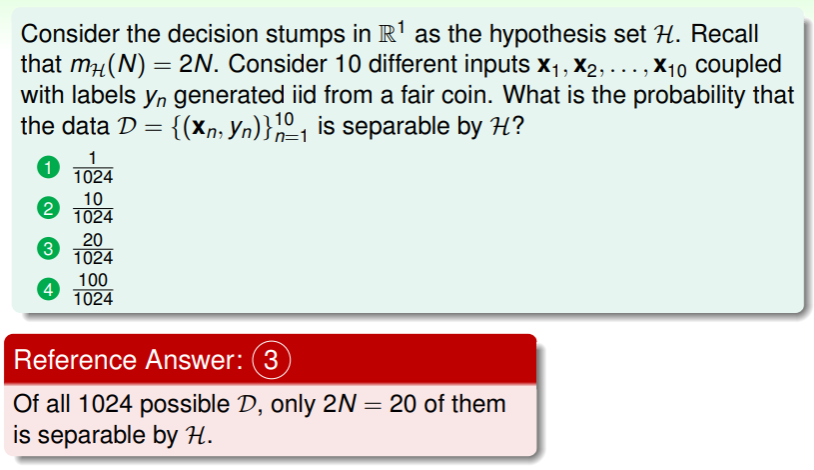
练习:计算数据集在假设集上可分的概率
Sampling Bias
无偏采样才能获得无偏模型
If the data is sampled in a biased way, learning will produce a similarly biased outcome.
从 VC Dimension 的角度看这句话,就是来自分布 的数据进行训练的模型,在测试时分布却是 ,这样分布的差异会导致 VC bound guarantee 失效。
因此,要使 VC bound 成立,训练、测试时应当处于同一分布 :
- 林老师举了一个自己遇到的例子:在 Netflix 的推荐系统改善竞赛中,林老师做出一个验证时改进了 的模型,但是在最终测试时却没有达到竞赛的要求,问题就是在于林老师的验证集是随机抽样的,但 Netflix 测试时选取的是用户最后观看影片的记录,其随着时间推移而权重上升:
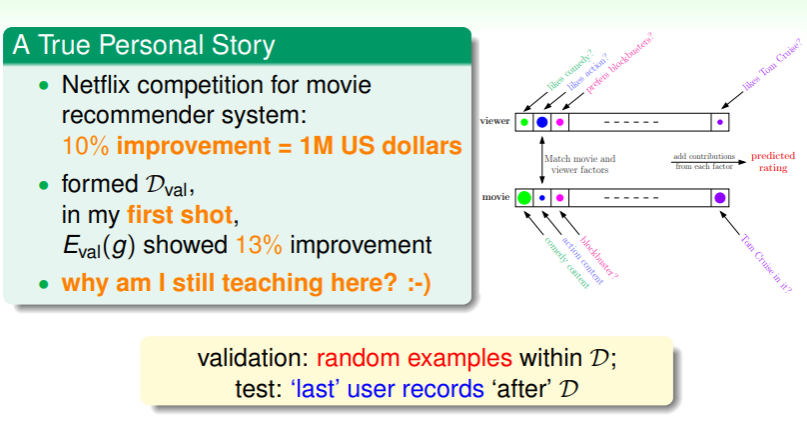
这给我们的经验是,尽量使得训练场景与测试场景相同(相近)。
练习:选择无偏估计的子集

- 不要引入任何偏见;
Data Snooping
要注意偷看数据的影响
If a data set has affected any step in the learning process, its ability to access the outcome has been compromised.
我们在前文提到,对数据集可视化后再选取模型,这样的行为是危险的,因为没有评估人在选择模型时的主观能动性,人的建模能力比算法要强得多。因此为了 VC bound 的可信,我们不能有偷看数据的行为。
这里 “偷看数据”之意其实远不止肉眼的观察,更细节的是在利用数据进行训练时:
- 这个问题中尝试对货币贸易数据进行评估,前 6 年做训练,后 2 年做测试,如果直接使用 8 年的数据进行训练,那就是“偷看了数据”(snooping),将会导致过于乐观的估计:
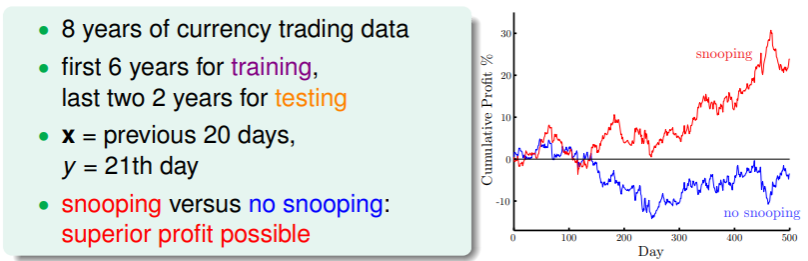
- 因此要避免偷看数据,就要确保训练集和测试集的分离,模型训练只能使用训练集,测试集一定要保证“干净、保密”
另外,我们在阅读论文并逐步改进时,也是一种 snooping:
- 这就是所谓“站在巨人的肩膀上”:

- 这时相当于所有的论文都组成一篇 big paper ,最终其 VC Dimension 是 ,越靠后的作者就会基于越多的前人数据,这样不可避免地就会导致偷看数据,进而导致 bad generalization
要解决偷看数据,就必须遵循以下几个原则:
- 尽量保证诚实,安全、隐秘地保存测试数据,
- 如果实在无法避免偷看数据,那就要小心地筛选验证集和使用它,
- 因此挑选模型时,不要根据数据的特点进行挑选、训练,而是保持 blind ,从线性模型一步步延伸下去,
- 保持怀疑思维,无论任何人的结论、抑或是自己的模型运行结果,都要仔细地分析、思考。