Introduction
在大规模 GPU 集群的数据中心中开发、训练 LLM 模型会遇到很多问题,诸如:
- 频繁的硬件故障(frequent hardware failures),
- 复杂的并行化策略(intricate parallelization strategies),
- 较长的排队延迟(long queuing delay):
- 远程存储集群的瓶颈(remote storage bottleneck),
- 模型性能反馈的延迟(delayed feedback on model performance),
- 不稳定的训练过程(unstable training progress), etc
并且 LLM 开发与传统的 DL 任务不同,它具有以下特点:
- Paradigm Transition. DL 任务通常是 task-specific 的范式,它会在特定领域的数据集上训练模型以完成特定任务;而 LLM 是在广泛数据上进行自监督训练来生成基础模型(foundation model),并进一步适应不同的下游任务——这引入了如 pretraining、alignment 等特殊的开发阶段。
- Tailored Software Stack. LLM 的尺寸过大,因此有如 Deepspeed、Megatron、Alpa 等定制化的技术通过 hybrid parallelism 或 state-sharding optimizer 来加速训练。
- Unified Architecture. 传统 DL 的模型种类繁多(如 CNN、RNN 等),而 LLMs 几乎都是 transformer-based、decoder-only 的架构(其他新兴架构还未广泛应用),因此结构的同质性表明 LLM 开发流水线在不同数据中心之间具有高度的统一性和相似度。
为了更细致地分析 LLM 开发的特征,文章依托上海 AI Lab 的数据中心 Acme 进行了深入研究:
经过深入研究后,总结出以下几个 LLM 开发的关键特征:
- Shorter Job Duration.
- Unfair Job Queuing Delay.
- Imbalanced Resource Usage. 这种不平衡主要体现在几个方面:
- Long GPU Idle Time in Evaluation Workload.
- Frequent Job Failures.
为了解决这些问题,文章中设计了两个系统并集成在 PJLab 的 LLM 框架 中以提升 LLM 开发的鲁棒性和效率。这两个系统分别实现了两个关键目标:
- One for fault-tolerant pretraining.
- The other for decoupled scheduling for evaluation.
Background
LLM Development Pipeline

Fig 1 展示了大语言模型开发的完整流程,包括五个不同的阶段(蓝色块),从零开始到服务(跟随蓝色箭头)。灰色圆形箭头表示预训练阶段能够进行定期的对齐和评估,以评估中间模型并动态调整配置。
- Data Preparation. 数据准备阶段可以分为两个部分:
- ① 数据预训练(pretraining):由从公共或私人来源获取的大量未标记语料库组成,并通过去毒化和去重复等过程进行精选;
- ② 数据对齐(alignment):包括一个较小的高质量标注语料库,用于使模型与特定任务对齐。这些数据通常通过昂贵的人工标注或标记获得。此外,所有数据必须进行分词(tokenized)处理,以确保与模型输入的兼容性。
- Pretraining. 预训练阶段是在大规模精选数据上进行自监督训练,这需要占用整体开发工作流中的大部分资源
- 大规模地高效训练 LLM 需要各种系统创新,例如状态分片优化器(state-sharding optimizers),以及使用数据、流水线和张量并行性进行细致的模型布局(PipeDream, Megatron, Alpa 等)。
- Alignment. 对齐阶段旨在通过用户意图来使 LLM 适应广泛下游任务中的应用。通常使用两种主要的对齐范式:
- ① 提示工程(prompt engineering):通过指定提示(即输入)而不修改模型参数;
- ② 微调(fine-tuning):通过在特定任务的数据集上更新模型参数,以提高在特定领域的表现。
- 此外,从人类反馈中的强化学习(RLHF)进一步增强了对齐效果,并且提出了如 LoRA 等参数高效技术来降低微调的代价。
- Evaluation. 仅凭单一指标如训练损失来评估模型质量不能准确地衡量 LLM 的性能,还需要考虑如准确率、公平性和毒性等诸多因素。因此:
- 需要提供一系列多样化的评估标准,
- 并且在多任务中也要能够评估性能,
- 还要在预训练阶段进行定期评估,以及时提供模型质量的反馈。
- Deployment. 部署 LLM 阶段为了满足严格的经济限制和应用延迟要求,要采用一些技术来实现高效的模型服务,如 quantization、distillation、CUDA kernel optimization、model parallelism、memory management 等。
Acme Overview
Acme 中有专门用于 LLM 开发的两个集群:Seren 和 Kalos ,
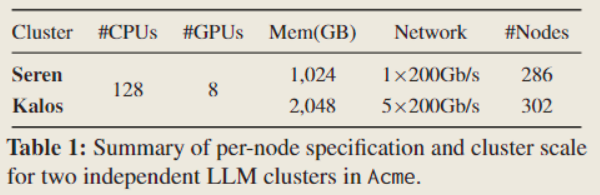
设备详情:
Seren和Kalos分别拥有 2,288 和 2,416 个 GPU。- 每个节点配备了 8 个 NVIDIA A100-SXM 80 GB GPU和 2 个 Intel Xeon Platinum 8358P CPU(总共 128 个线程)。
- GPU 通过 NVLink 和 NVSwitch 相互连接,节点间通信通过 NVIDIA Mellanox 200 Gbps HDR InfiniBand 实现。
- 与
Seren相比,Kalos是一个相对较新的集群,具有更高级的网络配置。Kalos中的每个结点拥有更大的主存(2 TB),并配备了四个专门用于应用程序通信的 InfiniBand HCAs1,以及一个专用于存储的额外 HCA。- 此外,分布式存储系统对于工作负载性能也至关重要。
Acme采用 all-NVMe shared parallelism file system 以实现快速的数据访问和存储。- 为了支持日新月异的多样化集群环境,
Seren和Kalos上的资源调度系统分别基于 SLURM 和 Kubernetes 构建。为 LLM pretraining 提供资源保障,调度器启用了资源隔离和配额预留功能,还进一步引入了尽力而为(best-effort)的作业机制,以提高资源利用率。
LLM 任务种类:
- A collection2 of LLMs 1 ranging from 7 B to over 123 B parameters.
- All of these models follow the transformer-based decoder-only architecture, similar to the GPT and LLaMA series.
Acmeencompasses tasks in the aforementioned general LLM development pipeline.- Note that
Acmedoes not involve any serving jobs, as LLMs are deployed on a separate cluster specifically for serving purposes.
软件栈:
- 为了支持千级别的 GPUs 集群,上海 AI Lab 构建了 InternEvo23 系统,其中集成了许多不同的系统优化策略,如 FlashAttention、3D parallelism、zero redundancy optimization、mixed precision training、selective activation recomputation、fine-grained communication overlap 。
- 此外,还支持如模型微调和模型评估等其他任务。
Traces from Acme
跟踪数据的来源:
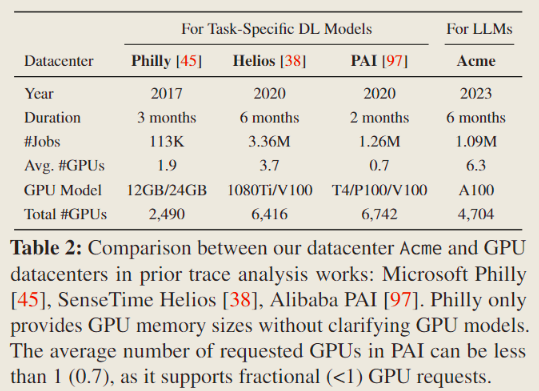
- Our characterization study is based on traces collected from two LLM clusters in
Acme. The traces span 6 months from March to August 2023.Serencontains 368K CPU jobs and 664K GPU jobs, whileKalosjob trace consists of 42K CPU jobs and 20K GPU jobs.- 性能改进的对比对象:负载传统 DL 任务的传统数据中心集群
- The data sources for the traces used in paper’s study:
- Job Log. 从调度器数据库中收集的作业日志,其中包含每个作业的详细信息——包括作业的执行时间(提交、开始和结束)、最终状态(完成、取消、失败)、请求的资源(CPU、GPU、主存)、工作目录以及其他相关数据。
- Hardware Monitor Data. 这包括从各种来源获取的长期、多维硬件数据:从 Prometheus 数据库中收集 CPU、主存和网络使用数据,从 NVIDIA DCGM 中获取与 GPU 相关的指标,以及从 IPMI 中获取与电力相关的数据。这些数据的采样间隔设置为 15 秒。
- Runtime Log. 在任务执行期间从 LLM 框架中捕获标准输出(
stdout)和标准错误(stderr)日志。- Profiling Data. 对于一部分具有代表性的作业,通过使用 DCGM 等工具进行细粒度的性能分析,对这些痕迹多维度地协同分析能够帮助全面理解 LLM 作业在数据中心中的特征。
Data Center Characterization
本章对数据中心中 LLM 开发的特征进行全面分析,对比对象是传统 DL 工作负载。
LLM vs. Prior DL Workloads
Shorter Job Duration
作业持续时间反而变短了?!
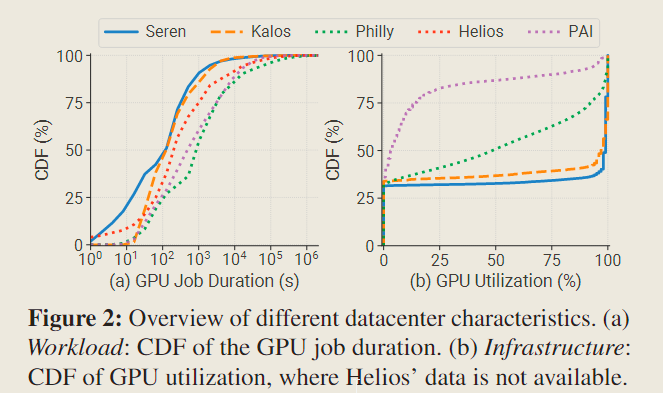
与刻板印象里 LLM 是长期任务不同,根据下图 Fig 2(a) 中 Seren 和 Kalos 的数据,LLM 的平均作业持续时间(GPU jdSsob durations,专指作业运行时间,不包括排队延时)较过去其他数据中心的 DL 任务的平均作业持续时间,缩短了 2.7 至 12.8 倍。具体地说,作业持续时间的中位数大约是 2 min,这比其他数据中心的数据是缩短了 1.7 至 7.2 倍。
To provide an explanation for this observation, we outline four potential factors:
- Hardware upgrade. GPU 的迭代更新、摩尔定律等。
- Abundant resources.
Acme中用户能够请求更多的 GPU 资源(averaging 5.7 GPUs in theSerenand 26.8 GPUs in theKalos,数据来自 Table 2)- Extensive associated workloads. LLM 开发流程包含大量的小规模相关联的任务,例如 evaluation 任务等,这在 下一节 会详述。
- High incompletion rate. 大约 40% 的 LLM 作业会失败,完成的作业仅仅占用 20%~30%的 GPU 资源。 This highlights the urgent need for a fault-tolerant system.
Polarized GPU Utilization
GPU 利用率变得更极端!
由 Fig 2(b),在 Acme 的两个集群中,GPU 利用率呈现出一种极端的模式——集中在两个完全不同的状态:0% 和 100% 。这种极化(polarization)现象主要源于集群中的 LLM 作业拥有相似的架构——Transformer-based。相比之下,Philly 和 PAI 两个集群的利用率范围更加广泛。此外,在比较中位数的 GPU 利用率时,Seren 和 Kalos 分别为97%和99%,而 Philly 和 PAI 分别为48%和4%。
这一观察结果与普遍认知相符,即LLM 具有较高的计算密集性。这也意味着基于 GPU 共享的调度技术(如 Lucid,Gandiva,AntMan,Salus 等)可能不适用于 LLM 的开发。 后文 还有比 GPU 利用率更精确的分析。
High-skewed Workload Distribution
工作负载的分布极度不均衡!
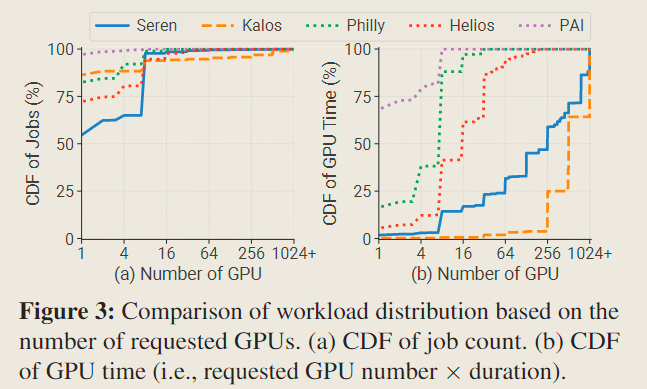
对于作业请求 GPU 数量的情况分布,所有集群都呈现出相似的模式——大多数作业是单 GPU 作业,仅不到7%的作业请求超过 8 个 GPU 。然而,在考察GPU时间时,单 GPU 作业在 Seren 和 Kalos 中仅占不到 2% 的资源,而在 PAI 中却占据了超过68%的 GPU 时间。与此形成鲜明对比的是,大规模作业(≥ 256个GPU)在 Kalos 中主导了 GPU 时间,占据了超过 96% 的资源。
这种更为陡峭的分布给集群调度器的设计带来了巨大的挑战:
- 大部分资源被分配给少数预训练任务,这可能导致 HoL(head-of-line)阻塞问题,并造成严重的排队延迟
- 现有的深度学习集群调度器(Tiresias、Themis、Pollux、Gandiva、ASTRAEA 等)通常依赖于抢占(preemption)机制,然而,由于恢复开销过大,不适用于 LLM 任务
因此考虑到整个流程的工作负载特征,针对 LLM 集群迫切需要设计全新的调度系统 Decoupled Scheduling for Evaluation。
Workload Categories
考察不同类别的工作负载对资源占用、资源需求、时间占用的情况。
Irrelevance of Job Count and Resource Usage
对于不同种类的作业而言,作业数量与资源利用并不相关。
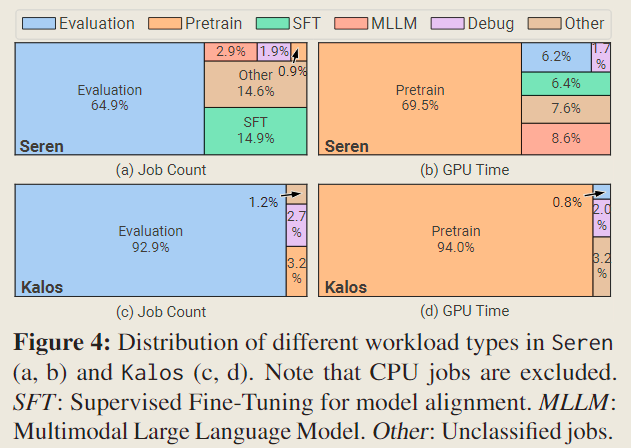
显然,评估任务在两个集群中的总任务数量中占大多数,但它们消耗的资源相对较少(在 Kalos 中仅占 0.8%)。相比之下,预训练任务仅占总任务数量的 0.9% 和 3.2%,但在 Seren 和 Kalos 中分别消耗了总 GPU 时间的 69.5%和 94.0%。
Job Type Correlates with GPU Demand
作业类型与 GPU 需求强相关。
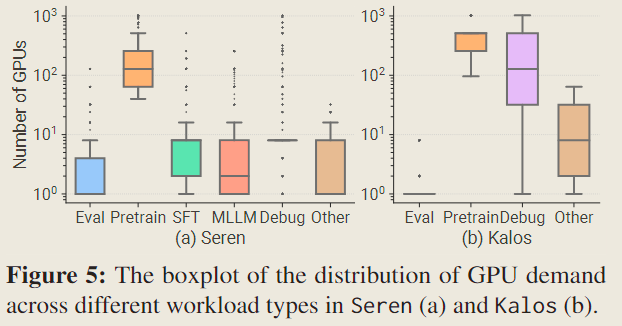
Each box is framed by the first and third quartiles, while the median value is indicated by the black line within the box. Both whiskers are defined at 1.5× the InterQuartile Range (IQR).
与通常需要少于 4 个图形处理器的评估任务相比,预训练任务通常需要超过 100 个图形处理器。这一观察部分解释了为什么在 Fig 4(d) 中,Kalos 中的评估任务仅消耗了极少的资源。
此外,调试(Debugging)作业对 GPU 的需求分布很广,这与测试(testing)作业通常需要处理各种类型的工作的事实相符。
Similar Temporal Distribution
不同类型任务在时间分布上大体接近,但存在不公平现象。
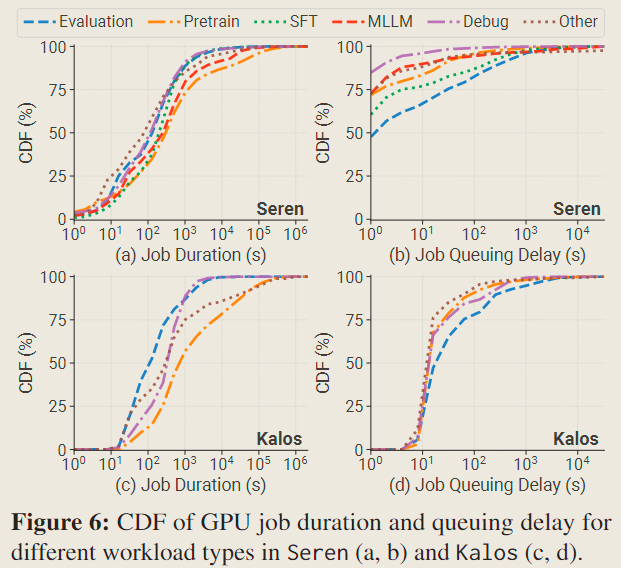
在任务持续时间方面,尽管预训练任务的持续时间最长,但它们的中位数时间超过其他类型工作的中位数时间仍在一个数量级以内,并且在两个集群中均只有不到 5% 的任务持续时间超过一天。这是由于预训练过程中频繁的失败,这一点将在后文 Failure Analysis 一节中进一步探讨。
关于任务排队延迟,与之前的报告所指出的——规模较大的任务会经历更长的等待时间——相反,Acme 中观察到评估任务的排队延迟最长,尽管它们对 GPU 的需求最低且任务持续时间最短。这种差异是由于大部分资源被预留给预训练任务以最小化其排队延迟,而评估任务通常以较低优先级批量提交,只能利用有限的闲置资源。
Infrastructure
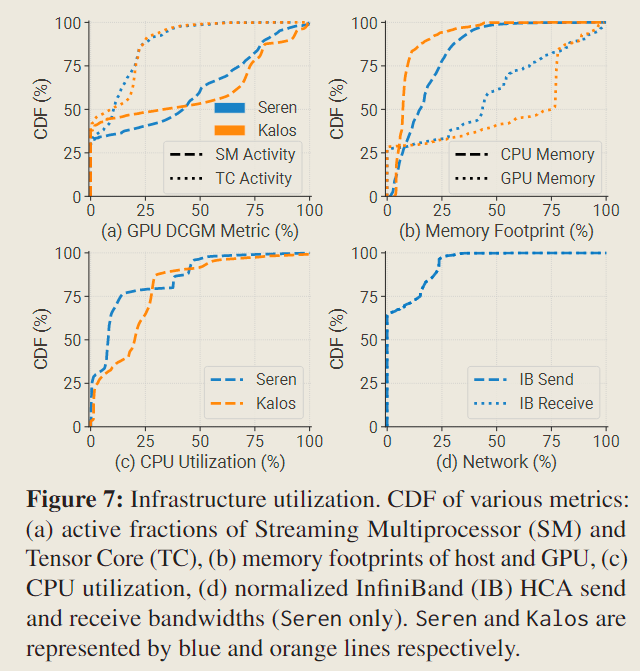
DCGM 是英伟达提供的数据中心 GPU 管理器,通过 DCGM 能够收集细粒度的性能计数器指标,包括 SM 活动4(
PROF_SM_ACTIVE)、TC 活动5(PROF_PIPE_TENSOR_ACTIVE)、GPU 主存占用(DEV_FB_USED)等。
Higher GPU Utilization
更高的 GPU 利用率(memory、SM activity、TC activity)。
与 PAI 中大部分 GPU 主存未被充分利用(少于 25%)的情况相比,在 Kalos 中的观察显示,50%的 GPU 中的主存占用超过 75%(60 GB)。此外,Kalos 和 Seren 中的 SM 活动的中位数约为 40%,这是 PAI 中报告的 20%的两倍之多。
这些发现说明 LLM 开发的特点是主存密集型(memory-intensive)和计算密集型(compute-intensive)的。
Underutilized Associated Resources
与 LLM 开发密切相关的其他资源(CPU、主机主存、网络)的利用并不充分。
在 Fig 7 (b) 中,CPU 主存利用率始终低于 50% ,显然未充分利用。尽管 GPU 内存卸载(ZeRO-Offload)技术提高了 CPU 主存利用率并缓解了 GPU 内存限制,但由于 PCIe 带宽有限,它也阻碍了训练吞吐量。因此,我们不采用卸载机制。
如图 7 (c) 所示,由于 CPU 与 GPU 的数量比例较高(每 GPU 对应 16 个 CPU),CPU 通常处于未充分利用状态,。
在图 7 (d) 中,通过测量 Seren 中 IB 的网络发送和接收带宽,发现两条线几乎重叠,这是因为 IB 在 LLM 执行期间用于对称通信。此外观察到,网卡超过 60%的时间处于空闲状态,活跃带宽很少超过 IB 提供的最大带宽的 25% 6 。
Environment Impact
LLM 开发会产生大量的电力需求及二氧化碳释放。
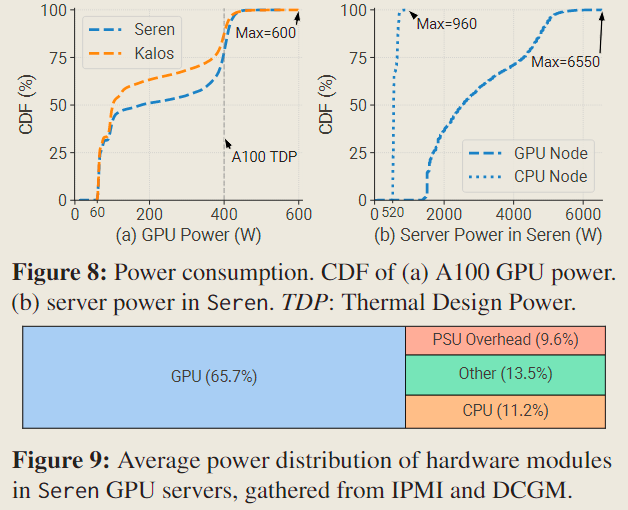
从 Fig 8(a) 中可以观察到,大约 30%的 GPU 处于空闲状态,但仍需消耗 60w 的电力。此外,由于密集的计算需求,Seren 和 Kalos 中分别有 22.1%和 12.5%的 GPU 消耗超过 400 瓦(TDP7),其中一些甚至达到 600 瓦。这可能会导致一些亚稳态(metastable)问题的风险。
Fig 8(b) 展示了 Seren 中所有 GPU 服务器的功耗分布,以及额外的 6 台仅 CPU 服务器的功耗分布。可以发现 GPU 服务器平均消耗的电力是 CPU 服务器的 5 倍。此外,Fig 9 显示,在 GPU 服务器中,GPU 约占总电力消耗的 2/3,而 CPU 仅贡献了 11.2%,电源供应单元(PSUs)在电压转换过程中消耗了 9.6%的能量。这些观察结果符合刻板印象中 GPU 是 LLM 开发中主要的电力消耗者。
Workload Profiling
细粒度地考察代表性任务的资源利用情况,分别是 pretraining jobs(资源密集型的任务)和 evaluation jobs(数量密集型的任务)。
Pretraining Workload
GPU SM Utilization
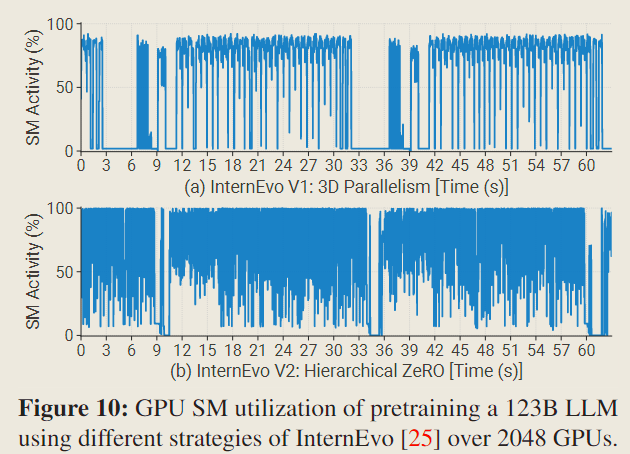
Fig 10 展示了在不同训练策略下,相同大语言模型的 GPU SM 利用率。两个版本保持相同的批量大小(batchsize),并根据各自的配置进行了优化。显然,相对于 InternEvo V1,V2 的峰值 SM 利用率更高一筹,并且空闲时段更少,加速了大约 16% 。
InternEvo V1 的三维并行(3D parallelism)的利用率相对较低,主要是由于混合并行引入的通信影响了关键路径,例如流水线并行(pipeline parallelism)中的气泡。
GPU Memory Footprint
For a model comprising 8 parameters, in the mainstream mixed precision training using Adam optimizer, the memory footprint of the parameters, gradients, and optimizer states are , , and , respectively. To reduce memory cost, ZeRO effectively shards redundant memory of these elements across global GPU workers.
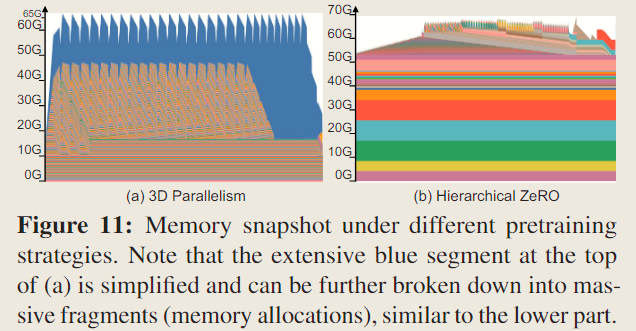
Fig 11 展示了由 PyTorch 主存快照工具捕获的实际 GPU 主存使用情况随时间的变化。上方的动态部分代表活性值和梯度,而下方的静态部分代表由参数和优化器状态占用的主存。需要注意的是,图中仅展示了已分配的主存,而保留的主存未呈现。
分析表明,与分层 ZeRO 相比,3D 并行中活性值对主存的需求显著更高,即高效的活性值主存管理是提升 3D 并行中批量大小和吞吐量的关键因子。
Imbalance in Activation Sizes
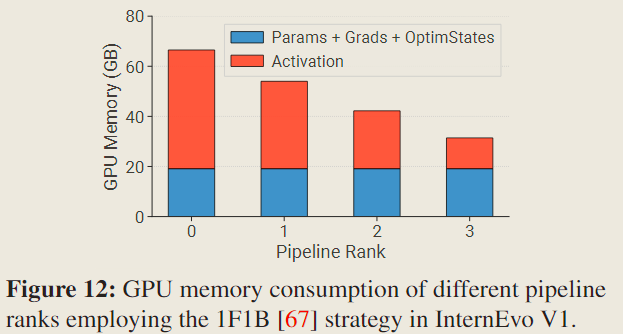
在使用流水线并行时,每个 rank9 需要持有不同数量的激活值(activations,用于反向传播),因为各个流水线 rank 中等待反向传播计算的微批次(micro-batches)数量不同。
Fig 12 绘制了不同流水线 rank 上的不平衡问题,这表明应该采用一种专门的划分机制来解决流水线并行中不同 rank 之间主存使用不平衡的问题,以实现更高的效率,例如重新计算激活值。
Evaluation Workload
LLM 在预训练的过程中会不断产生 checkpoint,必须在 checkpoint 产生时进行评估,才能使得 LLM 导向预期的训练目标。因此 evaluation 是 LLM 训练中数量最多的任务,它也由此产生
2个资源利用相关的问题。
High Model Loading and Data Preprocessing Overhead
模型加载和数据预处理的开销过大。
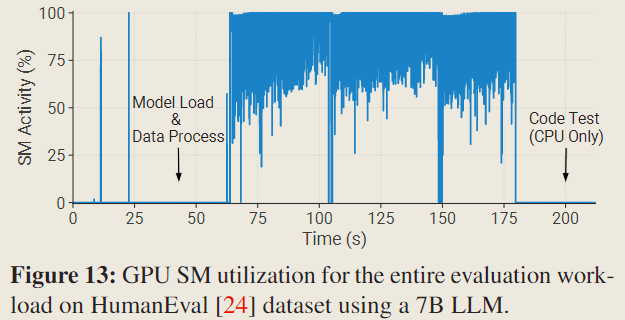
在评估任务的启动阶段,必须为每个任务加载模型检查点(对应上图 Model Load 部分)。此外,数据预处理阶段(对应上图 Data Preprocess 部分),特别是词元化(tokenization)过程,占据了大量的时间。这些因素导致分配的 GPU 资源在相当长的时间内未被充分利用。如 Fig 13 所示,评估任务在实际 GPU 进行推断之前消耗了超过 1 分钟的时间,占评估总时长的 29.5%。这种开销可能会随着模型或数据集的增大而增加。
为了解决预处理开销问题,
- 一种有效的策略是缓存词元化后的数据。
- 此外,评估任务是灵活的,可以将多个评估任务(数据集)整合到一个任务中。这种整合可以有效减少评估过程中模型加载阶段的相对时间开销。
High Metric Computation Overhead
指标计算的开销过大。
评估过程通常涉及复杂且耗时的指标计算。例如,需要在 HumanEval 和 MBPP 等数据集上进行复杂的程序正确性测试。此外,还需调用 OpenAI GPT-4 API 来评估模型对话的性能。这些过程可能需要长达 30 分钟,在此期间 GPU 处于空闲状态。因此,我们可以观察到 GPU 使用的不同阶段,包括需要 GPU 进行推断和生成的阶段,以及不需要 GPU 进行指标计算和验证的阶段。
以 HumanEval 基准为例,如 Fig 13 所示,GPU 在最后 42 秒处于空闲状态,浪费了约 19.0%的总 GPU 时间。
Failure Analysis
本节通过运行时日志(runtime logs)和硬件监视数据(hardware monitor data)对作业失败进行全面分析。
Failure Category
对故障进行分类。
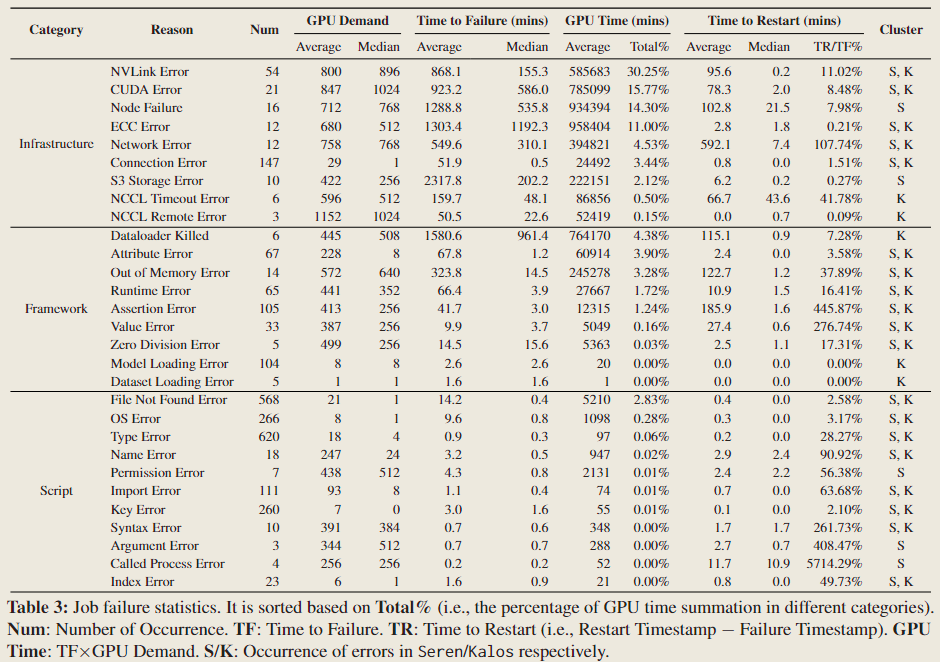
上述 Table 3 提供了 Acme 数据中心中常见故障的总结,包括它们的发生频率和重启时间。这些故障大体地分为三类:
- Infrastructure. 基础设施相关的故障源于计算平台或远程存储中的潜在问题。这些故障主要发生在作业执行过程中途,尤其是在预训练任务中。由于恢复过程费时费力,它们严重影响了训练进度。
- Framework. 几种运行时错误,如 RuntimeError、ValueError 和 AttributeError,可能与张量操作、形状、数据类型或意外行为有关。这些错误通常在任务的初始阶段发生,并且通常通过修复配置来解决。
- Script. 脚本错误通常源于编程错误或用户疏忽。它们是大多数故障的来源,通常通过修改代码来解决。
Failure Characterization
本节总结故障的特征。
Infrastructure Failures Cause Most Severe Impact.
设施故障产生的影响最严重。
如表 3 所示,由于基础设施问题而失败的作业通常需要大量的 GPU(GPU Demand),并且需要相当大的努力才能重新启动(Time to Restart)。它们占用了超过82%的 GPU 资源(GPU Time),但仅占11%的失败作业数量(Num)。这些作业大多是长期的预训练任务,可能会多次遇到硬件故障,例如 GPU 问题(如 CUDAError、ECCError)、NVLink 问题(NVLinkError)和网络系统问题(NCCLError、S3 Error)。
解决这些基础设施故障需要细致的诊断工作,以确定问题的根源,通常需要对故障硬件维护或更换,从而产生过高的重启开销。
Failures Caused by High Temperature.
高温也会导致故障。
GPU 过热可能会导致 NVLinkError 或 ECCError,这种现象在很大程度上是由于高度优化的通信的代价,使得 GPU 的空闲率极低,进而积热严重10。
Many Failures Induced by Auxiliary Services.
很多故障由辅助设备的服务所引起。
在预训练框架中,需要连接到外部组件或服务以进行指标报告、日志记录、监控和警报。这些辅助服务容易受到网络不稳定性的影响,可能导致超时(timeout)或故障(failure),从而减缓或中断训练过程。大量 ConnectionError 和 NetworkError 源于这些辅助服务。
Evaluation Jobs Rarely Encounter Errors.
评估作业很少遇到错误。
在 Kalos 中,只有 6.7%的评估任务遇到错误,并且 GPU 或 NVLink 故障的记录。低错误率可能归因于其较短的持续时间和对 GPU 和 NVLink 连接的较低压力。
Failure Recovery
有三种场景需要我们重启 LLM 训练的作业:
- 作业过程中出现了错误
- 训练指标(metric)出现了反常,例如 loss 曲线的反常增加(在此前是逐渐下降的)、并且一段时间内没有自动地恢复正常
- 训练过程出现了停滞阻塞
重启训练需要恢复到上一个 checkpoint ,此间的训练过程将会抛弃。当今的 LLM 框架并没有自动重启的机制,因此需要维护者随叫随到地监视运行情况,考虑是否重启作业。
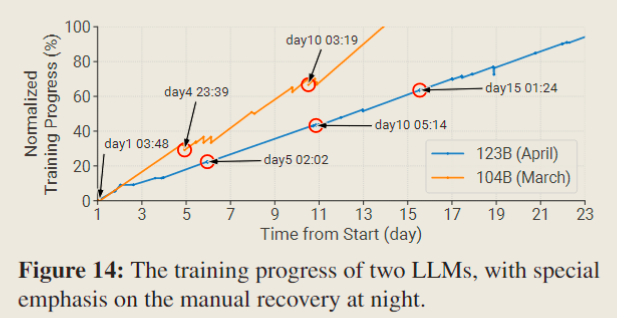
在 Fig 14 中记录了两种尺寸的 LLM 的训练过程,特别标出了夜间重启。
- 104B 模型是在框架仍处于开发阶段早期的尝试,因此,加载先前模型检查点的过程导致了整体训练过程中的重大损失。
- 相反,一个月后在训练 123B 模型时,改进了框架:采用更小的检查点保存间隔,此外新增功能使得可以在结束作业前优雅地终止作业,从而保留当前的训练结果。显然,123 B 模型的训练过程更加稳定,由于回滚导致的损失更少。需要注意,这一改进是有代价的,因为不同时间中断的作业必须迅速重新启动。
Depolyed LLM Systems
前面讲到 pretraining 和 evaluation 是 LLM 开发过程中最有代表性的两个工作,接下来对这两个工作进行改进。
Fault-tolerant Pretraining
通过引入 LLM 进行故障分析和自动重启,增强故障容忍度。
前文说到,保持维护者随叫随到地修复 LLM 训练过程中的错误虽然是当前业界主流的做法,但是对维护者的负担过大,并且 GPU 利用率不高。因此需要设计一种自动检测错误并恢复的系统来重启训练。
在文中的实现里,该系统无缝地融合进 LLM 预训练框架中,其中包含三个部分:
- Checkpointing, 通过更频繁的检查点保存机制,来缩小训练重启的损失
- Diagnosis, 通过启发式的规则与 LLM 的结合,精确地识别出不同错误发生的根本原因
- Recovery, 通过全面的检测工具定位问题节点,并且自动地从正确的检查点恢复、重启
要实现这个自动检测并恢复的系统需要实现这三个模块:
- Asynchronous Checkpointing. 频繁的检查点保存有效地减少了由意外故障引起的时间浪费。然而,由于 LLMs 可以产生 TB 级的模型状态,保存检查点本身可能会引入大量开销,导致训练时间减慢高达 43% 。为了解决这个问题,文章采用了异步检查点保存策略,该策略有效地将检查点保存过程与训练过程分离。 前文的观察 表明,CPU 主存在 LLM 训练时仍有大量空闲,因此通过利用这一点,可以将模型状态存储在 CPU 主存中,并利用一个单独的线程定期将这些状态保存到远程持久化存储器(remote persistent storage)中,从而容纳多个检查点。
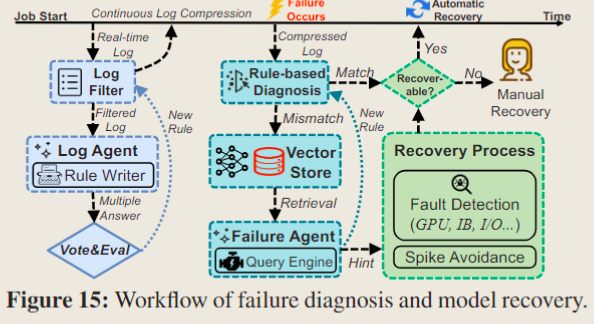
- Failure Diagnosis. 正如 前文 中所讨论的,故障可能由众多复杂的因素引起,确定故障是否可恢复对于自动恢复至关重要。一种常见的方法是结合启发式规则对故障作业的日志进行过滤和正则表达式匹配。然而,由于错误日志的广泛多样性和复杂性,这种方法往往证明是不准确的11。这说明通过一个特定的规则集匹配所有错误场景是不现实的。本文的方案如 Fig 15 所示,利用 LLMs 卓越的文本理解能力和广泛的知识库与基于规则的诊断相结合,自动识别不同故障的根本原因,以实现高效且准确的故障诊断。该过程主要包括以下两个步骤:
- Real-time Log Compression. 预训练任务生成大量的日志文件,主要由训练指标记录组成,可以达到数百 MB 的大小。为了加速诊断并满足 LLM 的上下文长度限制,首先需要进行日志压缩(log compression)。
- 系统会持续更新一组正则表达式,称为过滤规则(
Filter Rules)。这些规则高效地移除常规日志输出,如初始化信息、训练指标记录、框架输出和调试信息。 - 系统的一个重要组成部分是基于 LLM 的日志智能体(
Log Agent),其负责分析实时生成的日志片段,并识别遵循固定模式的数据。通过这种方式,Log Agent动态地编写正则表达式以更新Filter Rules,从而有效减小日志文件的大小。此外,Log Agent将识别出的错误消息转发给后续模块进行诊断。 - 此外,系统采用自洽性(self-consistency)方法来确保
Log Agent结果的鲁棒性,并保证这些结果的格式统一。这包括对每个日志段进行多次处理,并让另一个 LLM 对Log Agent的多个结果进行投票,通过正则表达式确保匹配的准确率。 - 随着时间的推移,
Filter Rules变得更加全面,使得日志过滤过程更加高效。此外,系统可以利用任务的元数据来识别重复或相似的任务,直接应用现有的Filter Rules进行日志过滤,从而避免重复工作。这一特征在大模型集群环境中尤为有益,因为在这种环境中,客户较少且任务重新提交较为常见。
- 系统会持续更新一组正则表达式,称为过滤规则(
- LLM-assisted Automated Diagnosis.
Log Agent高效地压缩运行时日志,隔离关键的错误日志,如 CUDAErrors 或 RuntimeExceptions 。尽管日志在到达此模块时已经过压缩,但误差日志可能仍然冗长。我们采用两步法来解决这一问题。- 首先,错误日志与已知的规则集(包含过去失败作业的误差诊断)进行比较。如果预定义的规则无法诊断问题,则通过嵌入模型将压缩的日志向量化(word2vec),并存储在向量检索库中。
- 随后,故障智能体(
Failure Agent)介入。它利用查询引擎搜索向量存储库,通过这一搜索,Failure Agent能够识别反映作业中断根本原因的日志数据,提取错误类型,并指示错误是否源自用户错误或基础设施故障,为恢复过程提供线索。此外,它还为用户或操作团队生成修复建议。Failure Agent还促进了故障诊断系统的持续学习。对于每一次新的故障,一旦被诊断并解决,Failure Agent会编写相应的正则表达式,并将其添加到基于规则的诊断(rule-based diagnosis)模块中。这一过程是迭代的,确保故障诊断系统不断进化,更擅长诊断故障并提出缓解方法。
- Real-time Log Compression. 预训练任务生成大量的日志文件,主要由训练指标记录组成,可以达到数百 MB 的大小。为了加速诊断并满足 LLM 的上下文长度限制,首先需要进行日志压缩(log compression)。
- Fast Fault Detection and Recovery. 基于故障诊断的结果分别进行恢复:
- 如果属于某种 基础设施故障 ,我们进行相应的检测测试以识别有问题的节点。例如,为了迅速解决频繁的 NVLinkError,我们采用类似于 DLRover 使用的两轮 NCCL 测试方法。首先,我们将所有节点分成多个 two nodes 组成节点对的集合12,并在每对中执行 AllGather 任务。如果在某个集合中 AllGather 任务失败,该集合中的节点可能是故障节点。然后,在第二轮中,我们将潜在故障节点与正常节点配对,形成新的集合。每个集合中的节点继续执行 AllGather 任务,从而识别出故障结点并将其隔离。
- 如果故障是由于 loss 的突然增加(即“loss peak”),这是由预训练框架自动触发的,所以应当选择较早的健康的 restart checkpoint 并跳过后续的这段数据批次。这种方法有效地保持了模型质量。
System Performance.
- 异步检查点策略显著降低了检查点开销,7B 和 123B 大小模型的 checkpoint time 和 overhead percentage 分别减少了 3.6∼58.7 倍(间隔=30 分钟,异步检查点测量中不包括持久化到远程存储的时间)。
- LLM-based 的故障诊断系统将人工干预减少了约 90%,从而减轻了开发者的负担。
Decoupled Scheduling for Evaluation
通过任务分解和调度解耦,实现快速的性能反馈。
我们的大语言模型框架在数据中心的预训练阶段对每个检查点进行定期评估。这使得开发者能够跟踪模型训练的进度并识别最佳模型检查点。我们的目标是快速反馈,以便及时进行调整。
回顾之前对评估任务特点的 讨论 ,其由于获得的资源有限并且需要并发地提交大量实验,则要经历最长的排队延迟,因此有必要为了加速评估过程的速度进行特殊设计。文中提出了试验协调器(trial coordinator)来协调集群调度器和 LLM 框架之间的操作,协调器采用了三种关键技术:
- 解耦远程模型加载;
- 解耦指标计算;
- 基于先验知识的弹性调度。

- Decoupling Remote Model Loading. 鉴于 LLMs 尺寸巨大,从远程存储中检索和加载它们是一个极耗时的过程。此外,大量评估任务(约 60 个数据集)的并发执行会因争用加剧而进一步延长加载时间。Fig 16(left) 展示了在
Seren中进行的一系列并发评估试验中的平均模型加载速度。结果显示,当单节点上单 GPU 试验的数量从 1 增加到 8 时,由于 NIC 的带宽限制(25 Gb/s),加载速度大幅下降。另一方面,当试验数量在 8 到 256 个之间时,加载速度趋于稳定。由这一观察启发,不再将每个评估数据集作为一个单独的试验提交,而是将模型加载过程与评估过程分离,如 Fig 16(right) 所示。具体来说,试验协调器首先从集群调度器中检索可用节点列表,然后为每个节点生成一系列前驱作业。这些作业将模型从远程存储加载到本地共享主存中。随后,协调器向调度器提交评估作业,这些作业通过高带宽的 PCIe 加载模型。这种方法有效利用了空闲的主机主存。评估完成后,协调器会清除文件。 - Decoupling Metric Computation. 如 Fig 13 所示,如图 13 所示,评估过程通常涉及复杂且耗时的指标计算。例如,必须在 HumanEval 和 MBPP 等数据集上执行复杂的程序正确性测试。为解决这一问题,将指标计算过程与评估试验解耦。当模型推断在 GPU 上执行后,其输出被迅速保存到文件中,终止推断任务。由于输出通常是基于文本的(small size),因此文件转储过程非常迅速。随后,生成 CPU 任务来执行指标计算。这种方法有效减少了 GPU 空闲时间并加速了评估过程,还利用了 CPU 的算力。
- Prior-based Elastic Scheduling. 除了解耦方法外,文章还注意到,关于每个评估数据集的 approximate trial runtime 的先验知识非常可靠,此外,这些数据集具有灵活性,故可以将多个数据集批量处理为一个试验,以规避模型多次加载的额外开销。还可以分解大型数据集并解耦指标计算。因此,试验协调器可以通过分解来最大化 GPU 占用率,利用先验信息平衡每个 GPU 的工作负载,并在排序后的作业队列上采用轮询(round-robin)分配策略。此外,在作业队列中优先处理具有较长 CPU 指标计算的评估试验,以更好地重叠其计算。这种方法不仅增强了工作负载的平衡,还最小化了试验切换的开销。
System Performance.
- 针对一个 7B 大小的大语言模型,涉及对 63 个数据集的工作负载进行评估。在两种不同条件下测量完成所有评估试验所需的时间跨度:单个结点(代表有限资源)和四个结点(代表相对充足的资源)。试验协调器分别可以将时间跨度减少 1.3 倍和 1.8 倍。
Discussion
Related Work&Paper
Scope Limitations
Limitations include:
- 文章的分析集中在模型服务之前的开发过程,
Acme不包含任何服务任务(即部署阶段的工作负载)。 - 主要集中分析 GPU 任务,对 CPU 任务的分析空间有限。
- 主要描述基于 transformer 的、仅解码器架构的模型(如 GPT-3 和 LLaMA 2)。对于较新的模型架构,如混合专家模型(Mixture of Experts)、多模态大语言模型(Multimodal LLM)涉及较少。
Appendix
Noted PDF
Footnotes
-
Host Channel Adapter ↩
-
Model: https://huggingface.co/internlm ↩
-
在 Nvidia DCGM(Data Center GPU Manager)中,SM activity 是指流式多处理器(Streaming Multiprocessor, SM)在 GPU 上的活动率。具体来说,它衡量了 GPU 上的 SM 在给定时间内处于活跃状态的百分比。SM 是执行计算任务的核心单元,它负责处理线程并执行计算密集型任务。因此,SM activity 反映了 GPU 的计算资源利用率。如果该值较高,意味着 GPU 正在处理大量的计算任务,资源利用率较高;而如果该值较低,说明 GPU 在计算方面处于空闲或负载较低的状态。 ↩
-
在 Nvidia DCGM 中,TC activity 指的是张量核心(Tensor Core)的活动率。张量核心是 NVIDIA GPU 中专门设计用于加速深度学习运算的硬件单元,特别是在矩阵运算和浮点运算方面具有显著性能优势。TC activity 指标的作用主要包括:1. 性能监控:通过监测张量核心的活动率,可以评估深度学习任务是否充分利用了张量核心的计算能力。较高的 TC 活动率通常表明模型训练或推理过程中的计算负载较高。 2. 优化调优:分析 TC 活动可以帮助开发者识别潜在的性能瓶颈,进而调整模型架构或优化训练代码,以便更有效地利用 GPU 资源。3. 资源分配:在多 GPU 环境中,TC 活动的监控可以帮助用户决定如何分配计算任务,以确保每个 GPU 都能高效地执行深度学习任务。 ↩
-
这里似乎与 Alibaba HPN 的结论有冲突?其实不是,Alibaba HPN 中的占用率指的是吞吐量(throughput),这里的占用率指的是带宽(bandwidth)。 ↩
-
Thermal Design Power,热设计功耗。指一个组件(如 GPU)在正常运行时所产生的最大热量。它通常以瓦特(W)为单位表示,反映了散热系统需要处理的热量,以确保设备在安全温度范围内运行。TDP 的意义包括:1. 散热设计:帮助设计人员和工程师确定适当的散热解决方案,以防止过热。2. 功耗评估:TDP 也可以用作估算设备在高负载条件下的功耗,尽管实际功耗可能会有所不同。3. 系统兼容性:在构建或升级计算系统时,TDP 可帮助用户选择合适的电源和散热设备,以确保系统稳定运行。 ↩
-
代表的是神经网络模型的参数数量,这些参数是通过训练过程学习到的。 ↩
-
rank 是指特定 GPU 或计算节点在整个并行计算系统中的编号或位置。每个 rank 代表一个独立的计算单元,在流水线并行中,不同的 rank 负责处理不同的计算阶段或不同部分的数据。 ↩
-
狠狠 PUSH GPU 导致的(确信 ↩
-
在许多情况下,可能没有特定的错误声明,但多个错误可能同时存在。例如,一个作业可能因包含 NCCLTimeoutError、CUDAError 和多种 RuntimeError 的消息而失败,而根本原因是 CUDAError。 ↩
-
如果服务器的总数为奇数,我们将一个集合的大小设为 3 。 ↩