Linear Models for Binary Classification
回想之前学过的三种线性模型,它们的共同点是计算分数的 scoring function 都是线性的: ,最关键的差别就是对这个 score 的处理函数,并由此导致错误估计的不同:
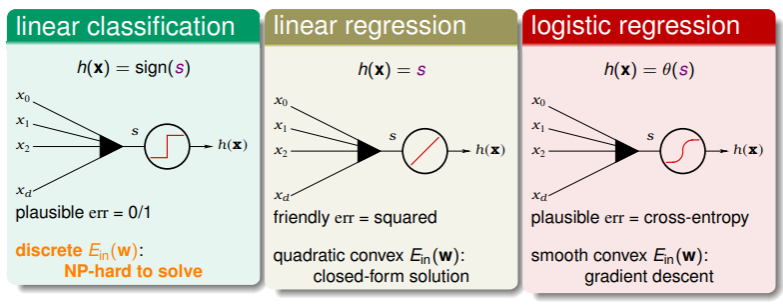
- 我们曾考虑使用 线性回归策略 缩短二元分类问题的迭代时间, Logistic Regression 的梯度下降策略也可以快速地找到最小的 (至少比 NP-hard 复杂度高效得多),如何使用 Logistic Regression 优化二元分类问题呢?我们接下来就探讨这个。
Summary for Error Evaluating
来回顾一下这三个模型在二元分类问题上的错误评估函数:

- 将三者用相同的参数统一表达,我们得到了上面的错误评估函数形式,其中 的物理意义是分类问题中分类正确的程度,其正负表明分类是否正确,其值越大则越正确;
将这三个函数可视化:
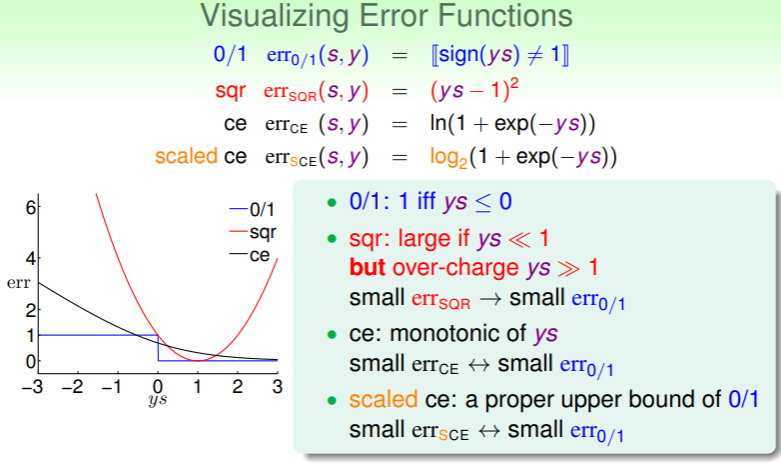 可以总结出以下这些结论:
可以总结出以下这些结论:
- 当 时,线性回归的错误评估 很小,但在 时,反而增大(无论正负),回想之前说 是 的宽松上界,在 较大时尤为如此,在 时才勉强可以认为 ;
- Logistic Regression 的错误评估 是一个单调递减的函数,不过根据图像可知,当 足够小时,也可以认为 ;
- 另外原始的 是 形式的,它与 有两个交点,我们换底成 形式,则转换成下图:
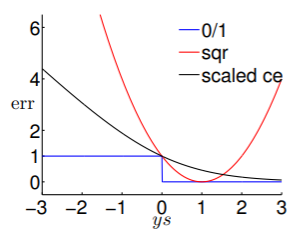
由此,我们再对错误评估函数做一些放缩:考虑到
,可以认为在 上满足
,从而在 上满足
,因此回想之前 VC Dimension 中关于 和 的关系:
,我们可以放缩 为:
,因此我们有理由相信,足够小的 也能够得到足够小的 。
Regression for Classification
此时,无论线性回归还是 Logistic Regression,我们都论证了其用于二元分类问题的可行之处:

- 综合起来,我们可以用线性回归找到较好的 作为起始,然后再运行 PLA/pocket/Logistic Regression 这些算法。
Stochastic Gradient Descent
我们学习了两种迭代式的优化方法,一种是 PLA 风格的,一种是 pocket 或 Logistic Regression 风格的,不过这两者在每轮迭代的时间复杂度相去甚远:

Decrease the Iterative Complexity
如何将 Logistic Regression 的每轮复杂度也降低到 呢?回想其迭代的公式:
,我们想要更新方向是趋于单位长度的,这里经过连加后求平均的式子是 的罪魁祸首。
因此为了优化复杂度,我们选择在 n 个输入中随机地挑选一个,那么在期望上是接近平均值的(类比:要求 1~999 的平均数,连加起来复杂度很高,而随机抽一个数,这个数在平均数 500 附近的概率就会服从均匀分布),这就是 stochastic gradient :在随机的 上做偏微分 ,此时,真正的微分形式就变成:
Understand SGD
如何理解 SGD?实际上,随机梯度可以看作是真实梯度和“噪音”的混合:
,因此将真实梯度换作随机梯度,就是随机梯度下降。
- 经过足够轮次的迭代,我们可以期望地认为, ;
- SGD 的优势是简单、高效,尤其是在大量数据和在线学习两种情况中;但是相应的,会导致运行过程不够稳定,因此只能通过增加迭代轮次来提高稳定结果的概率;
SGD 的迭代公式可以写作:
,这看起来与 PLA 的迭代公式十分类似:
,实际上 SGD Logistic Regression 可以看作“soft”PLA ;或者在 且当 足够大时,可以认为 ;
在使用 SGD 时有两点值得注意:
- 何时停止?由于 SGD 的原理,我们不方便计算确切的梯度,因此考虑运行足够多轮次时就停止;
- 取何值?经验上, 比较合适;
练习:应用 SGD 策略

- 从物理意义上讲,残差越大就更新越多,所谓残差就是 与 的差值,代表着实际与预测的差距;
Multiclass via Logistic Regression
那么如何从之前学习过的模型应用到多分类问题呢?为了表述明确,我们称为 分类问题:
首先考虑线性分类模型,对一个特定分类 设定为 +1 ,剩余其它分类为 -1 ,迭代 次即可得到:
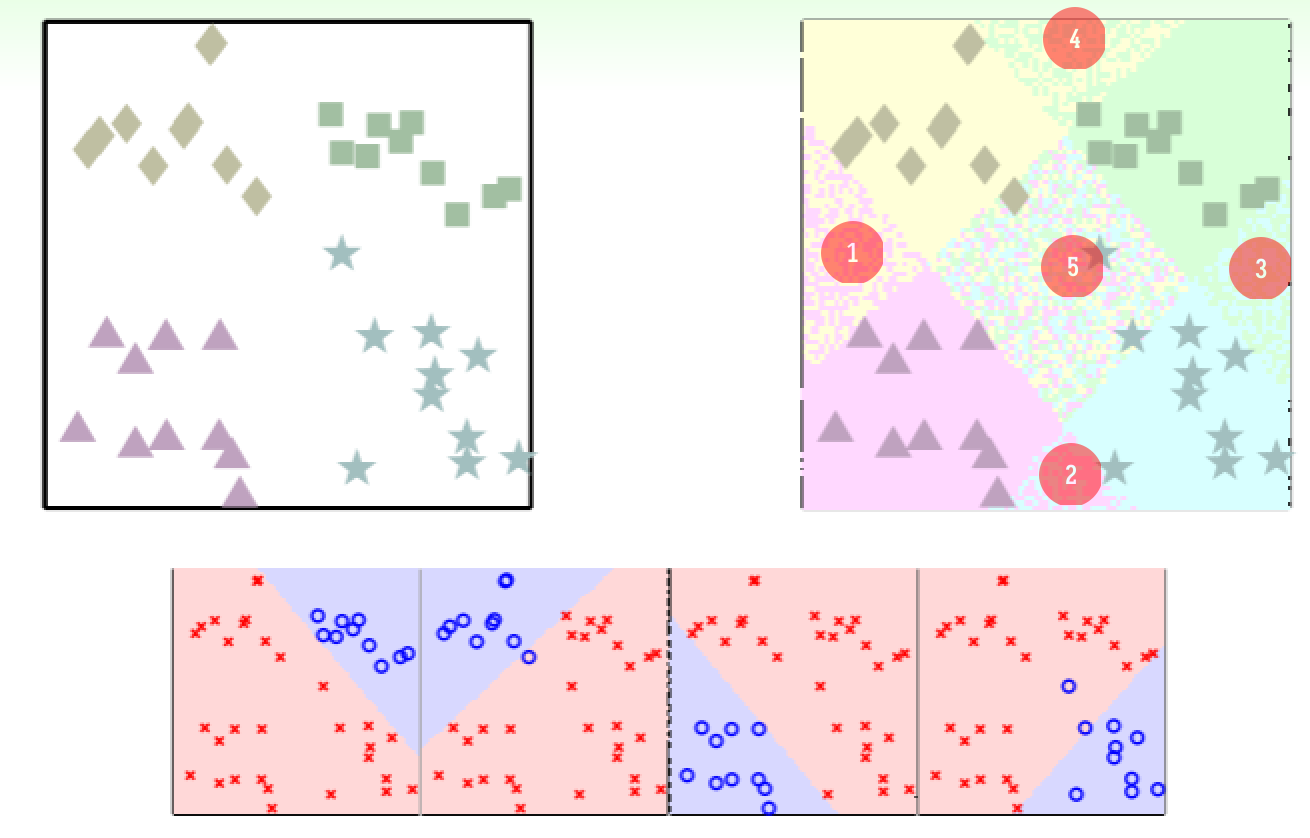
- 在每轮迭代时,都将目标分类的样本与其它样本剔除开来,这样得到的结果就实现了多分类。但是问题是,在聚集区域表现良好,但是在临界区域表现较差,上图中 1~5 这五个临界区要么发生争抢、要么被所有分类都拒绝。
于是考虑 Logistic Regression 这个软分类模型,依旧是每轮都对特定分类进行区分,迭代 次,但区别在于每轮中给出的是样本属于特定分类的概率,根据概率的大小再进行分类:
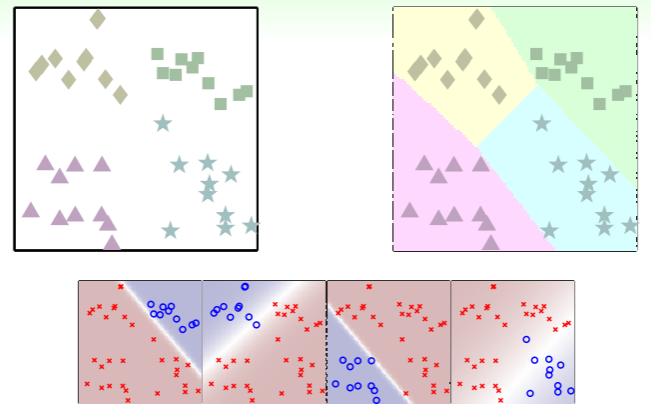
- 实现起来,就是每轮的分类器对所有样本作出属于该分类与否的概率 (于是得到 个概率),然后选择其中最大概率作为该样本的分类:
One-Versus-All Decomposition
直观上看,使用 Logistic Regression 的准确率更高,对这种方法我们整理一下流程:
- 每一轮在数据集上运行一次 Logistic Regression —— ,因此得到一个权重向量组 ,
- 对每一个样本,都返回权重向量组中计算得到的最大概率值:
这种策略的优势是高效准确、是组合应用 Logistic Regression 风格的方法实现的,但缺点是当分类数 较大时,不够平衡,比如有 100 个分类,每轮分类器都简单的全部否认,那么准确率仍然有 99% ,这显然不合理。
之所以叫 One-Versus-All (OVA) ,就是因为分类的选取是从 个里选一个。更高级的 OVA 扩展思路,可以看:multinomial logistic regression 。
练习:理解 OVA 的思路

Multiclass via Binary Classification
OVA 中最大的缺点是处理分类数 较大时不够平衡的问题,要解决这个问题,可以采用一对一的比较策略:
- 每轮只对目标分类和任一其它分类做比较,而其余 个分类都视作不存在:
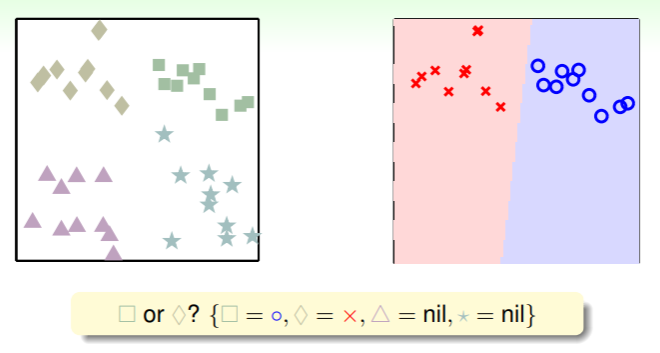
- 当 时,则要经过六轮比较:
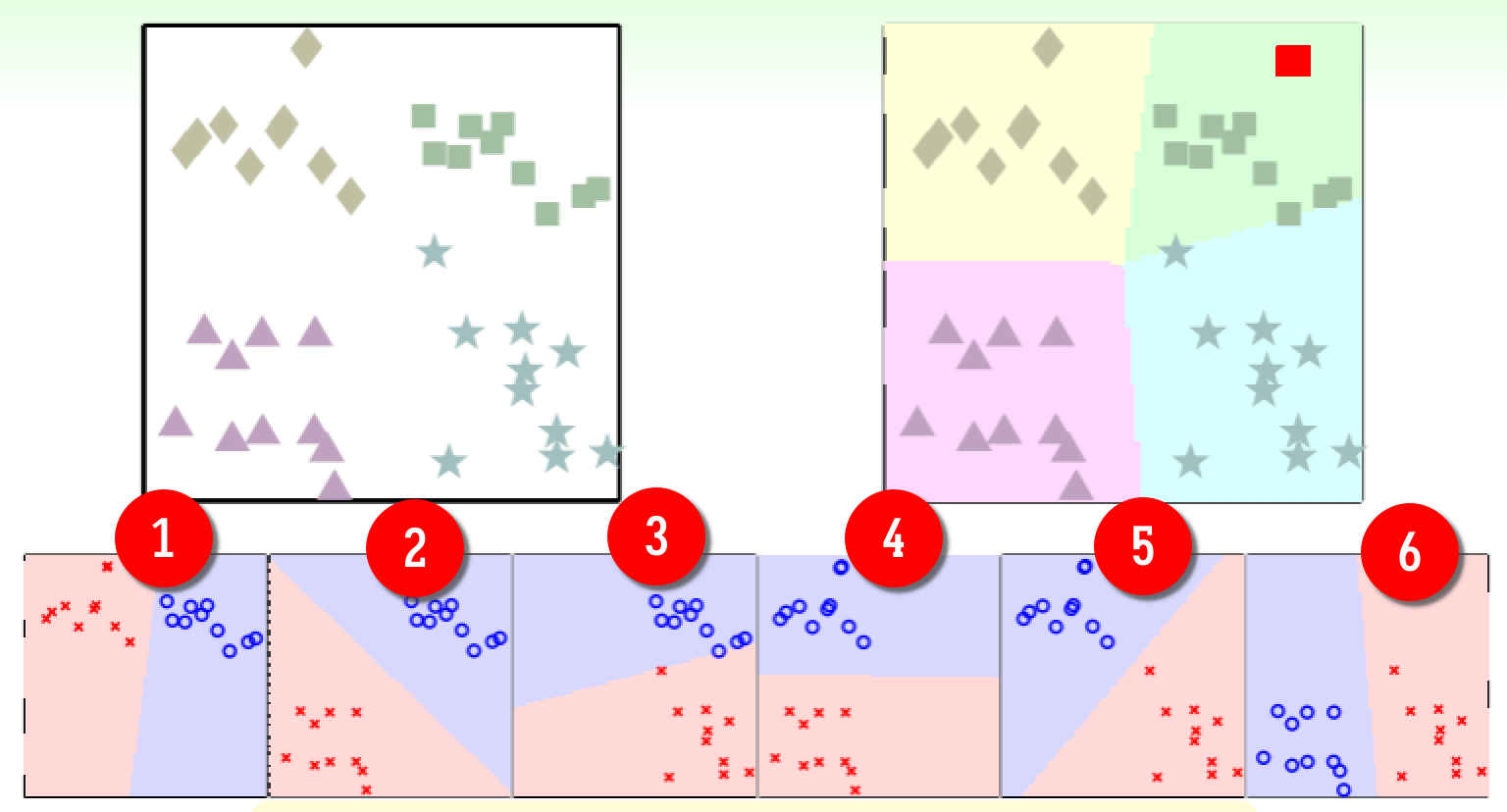 通项公式是 ;
通项公式是 ; - 那么经过六轮比较后,如何选取呢?类似锦标赛一样,得票数高者获胜:上图中对于样本(红色方块)六轮比较中 1、2、3 轮将其分类到方块类,4 轮分类到菱形类,5、6 轮分类到星形类,三角形类没有轮次分类到,即得票数 ,因此该样本是属于方块类的;
One-Versus-One Decomposition
综合上面的思路,我们整理一下 One-Versus-One (OVO) 策略的流程:
- 每一轮分类,在数据集上运行线性分类算法: ,这里 ,表示每个分类对其它分类 1v1 比较后的结果,则有 ,由此得到元素为权重向量的一个二维矩阵 ;
- 考查二维矩阵中每一个票数,选择最大者: ;
显然,OVO 策略比 OVA 策略更加稳定,是组合应用二元线性分类方法实现的;缺点就是计算效率太低,要得到二维权重矩阵 ,需要耗时 。
练习:计算 OVO 训练耗时
OVO 一定比 OVA 更耗时吗?
下题就表明 OVA 可能耗时比 OVO 更多。