举例说明,最好情况是什么,时间复杂度又是多少?
当所有元素均彼此雷同时,即属于该算法的最好情况。此时,deduplicate ()算法依然需要执行 O (n)步迭代,但可以证明每一步只需 O (1)时间。
实际上,根据以上所指出的不变性,当前节点 p 始终只有 1 个前驱(并且与之雷同)。因此,每步迭代中的 find ()操作仅需常数时间。
由此也可顺便得出最坏情况——所有元素彼此互异。在此种情况下,当前节点 p 的前驱数目(亦即各次 find ()操作所对应的时间)将随着迭代的推进线性地递增,平均为 O (n),算法总体的时间复杂度为 O (n^2)。
改进算法到 O (nlogn)
最简明的一种改进方法是:首先调用 sort ()接口,借助高效的算法在 O (nlogn)时间内将其转换为有序列表;进而调用 uniquify ()接口,在 O (n)时间内剔除所有雷同元素。
引入以上策略之后,子集中元素所对应的节点,很快会“自适应地”集中至列表的前端。在此后相当长的一段时间内,其余的元素几乎可以忽略。于是,在此期间此类列表的访问效率,将主要取决于该子集(而非整个全集)的规模,因此上述改进的实际效果非常好。—— Splay Tree
3-10 插入排序性能分析
背景:序列中 n 个元素的数值为独立均匀地随机分布。证明:
==列表的插入排序算法平均做 (n^2)/4=O (n^2)次元素比较操作==
首先,平均意义下的比较操作次数,也就是概率意义下比较操作的期望次数。
该算法共需执行 O (n)步迭代,故根据期望值的线性律(linearity of expectation),比较操作总次数的期望值,应该等于各步迭代中比较操作次数的期望值之和。
==向量插入排序算法平均做 (n^2)/4=O (n^2)次元素移动操作==
与列表不同,向量的插入排序中 search ()查找接口可以采用二分查找之类的算法,从而使其复杂度从线性降低至 O (logn)。
然而另一方面,在确定适当位置之后为将新元素插入已排序的子序列,尽管列表只需 O (1)时间,但向量在最坏情况下我们不得移动 O (n)个节点,而且平均而言亦是如此。故与 1) 同理,总体而言,平均共需执行 O (n^2)次元素移动操作。
序列的插入排序算法过程中平均有 expected-O (logn)个元素无需移动
同样地,既然该算法由多步迭代构成,故其间无需移动的元素的期望数目,就应该等于各步迭代中,待插入元素无需移动的概率总和。
根据该算法的原理,对于任意 k∈[0,n),在第 k 步迭代启动之初,当前元素 A[k]的 k 个前驱应该业已构成一个有序的子序列 A[0, k)。不难看出,若 A[k]无需移动即使得 A[0, k]仍为有序子序列,则其充要条件是,A[k]在 A[0, k]中为最大元素。
既然假定所有元素都符合独立且均匀的随机分布,故作为前 k + 1 个输入元素中的普通一员,A[k]在其中为最大元素的概率应与其它元素均等,都是 1/(k +1)。于是,这一概率的总和即为:
k=0∑n−1k+11=k=1∑nk1=Θ(logn)
3-11 逆序对与插入排序分析
template <typename T> void List<T>::insertionSort( ListNodePosi<T> p, Rank n ) {
for ( Rank r = 0; r < n; r++ ) { //逐一引入各节点,由Sr得到Sr+1
insert( search( p->data, r, p ), p->data ); //查找 + 插入
p = p->succ; remove( p->pred ); //转向下一节点
} //n次迭代,每次O(r + 1)
} //仅使用O(1)辅助空间,属于就地算法
若所有逆序对的间距不超过 k,则插入排序的运行时间为 O (k * n)
算法进入到 A[j]所对应的那步迭代时,该元素(在输入序列中)的所有前驱应该业已构成一个有序子序列 A[0, j)。既然其中至多只有 k 个元素与 A[j]构成逆序对,故查找过程 search ()至多扫描其中的 k 个元素,即可确定适当的插入位置,对应的时间不超过 O (k)。
实际上,每一步迭代均具有如上性质,故累计运行时间不超过 O (k * n)。
在教材 12.3 节对希尔排序高效性的论证中,这一结论将至关重要。
若共有 I 个逆序对,则关键码的比较次数不超过 O (I)
将 1) 中的分析方法作一般化推广,即不难看出:每个元素所涉及比较操作的次数,应恰好等于其逆序前驱的数目;整个算法过程中所执行的比较操作的总数,应恰好等于所有元素的逆序前驱的数目总和,亦即 I。
若共有 I 个逆序对,则运行时间为 O (n+I)
由以上分析,算法过程中消耗于比较操作的时间可由 O (I)界定,而消耗于移动操作的时间可由 O (n)界定,二者累计即为 O (n + I)。
既然此处实际的运行时间更多地取决于逆序对的数目,而不仅仅是输入序列的长度,故插入排序亦属于所谓输入敏感的(input sensitive)算法。
实际上更为精确地,每步迭代中的查找都是以失败告终或者找到不大于当前元素者,或者抵达 A[-1]\越界。若将这两类操作也归入比较操作的范畴,则还有一个 O (n)项。好在就渐进意义而言,这一因素可以忽略。
// 主算法template <typename T> void List<T>::mergeSort( ListNodePosi<T> & p, Rank n ) { if ( n < 2 ) return; //待排序范围足够小时直接返回,否则... ListNodePosi<T> q = p; Rank m = n >> 1; //以中点为界 for ( Rank i = 0; i < m; i++ ) q = q->succ; //均分列表:O(m) = O(n) mergeSort( p, m ); mergeSort( q, n – m ); //子序列分别排序 p = merge( p, m, *this, q, n – m ); //归并} //若归并可在线性时间内完成,则总体运行时间亦为O(nlogn)
==若为节省每次子列表的划分时间,直接令 m=min (c, n/2),c 为较小常数如 5,则总体复杂度反而上升至 O (n^2)==
做如此调整之后,在切分出来的两个子列表中,必有其一的长度不超过 c,而另一个的长度不小于 n - c。尽管如此可以在 O (c)时间内完成子任务的划分,但二路归并仍需 O (n)时间,因此其对应的递推方程应为:
T (n) = T (c) + T (n - c) + O (n)
解之可得:
T (n) = O (n^2)
template <typename T> void List<T>::reverse() { //前后倒置
ListNodePosi(T) p = header; ListNodePosi(T) q = trailer; //头、尾节点
for ( int i = 1; i < _size; i += 2 ) //(从首、末节点开始)由外而内,捉对地
swap ( ( p = p->succ )->data, ( q = q->pred )->data ); //交换对称节点癿数据项
}
这一实现方式的思路与策略,与教材代码 1.10 中的倒置算法如出一辙。具体地,这里通过一轮迭代,从首、末节点开始由外而内,捉对地交换各对称节点的数据项。
指针 p 和 q 始终指向一对位置对称的节点。请注意,尽管其初值分别为头、尾哨兵节点,但进入迭代之后,它们所指向的都是对外可见的有效节点。
// 教材代码1.10
void reverse ( int* A, int lo, int hi ) {
//数组倒置
while ( lo < hi ) //用while替换跳转标志和if,完全等效
swap ( A[lo++], A[hi--] ); //交换A[lo]和A[hi],收缩待倒置区间
} //O(hi - lo + 1)
性能分析
无论以上何种实现,计算过程无非都是一或两趟遍历迭代,每一步迭代都只涉及常数次基本操作,因此整体的时间复杂度均为 O (n)。另外,除了列表本身,这些实现方式均只需常数的辅助空间,故也都属于就地算法。
综合而言,最后一种实现方式的形式更为简明,但若数据类型 T 本身较为复杂,则节点 data 项的直接交换可能导致耗时的构造、析构运算。而前两种实现方式虽形式略嫌复杂,但因为仅涉及指针赋值,故在基础类型 T 较为复杂的场合将更为高效。
3-19 Josephus 环问题
描述:一个刚出锅的山芋,在围成一圈的 n 个孩子间传递。大家一起数数,每数一次,当前拿着山芋的孩子就把山芋转交给紧邻其右的孩子。一旦数到事先约定的某个数 k,拿着山芋的孩子即退出,并仍该位置起重新数数。如此反复,最后剩下的那个孩子就是幸运者。
初始时,将 n 个孩子组织为一个循环列表。此后借助后继引用,不难找到下一出列的孩子;其出列的动作,及对应于删除与之对应的节点。如此不断反复。
该算法时间、空间复杂度是多少?
整个算法所需的空间主要消耗于循环列表,其最大规模不过 O (n)。因为这里无需使用前驱引用,故实际上空间消耗还可进一步减少,但渐进地依然是 O (n)。
算法的执行时间,主要消耗于对游戏过程的模拟。每个孩子出列之前,都需沿着后继引用前进 k 步,故累计需要 O (n∙k)时间。
当然,在 n < k 时,可以通过取“k %= n”,进一步加快模拟过程。如此,时间复杂度应为:O (n∙mod (k, n)) = O (n^2)。
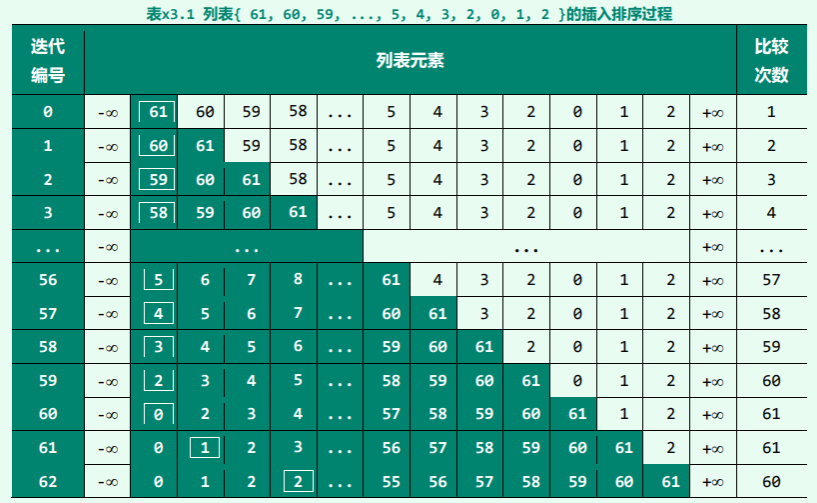 由该表可以看出,第 0 步迭代经过一次(当前元素 61 与头哨兵-∞的)比较,即可确定其适当的插入位置——当然,此步的插入操作其实可以省略,但为简化控制逻辑,算法中不妨统一处理。
实际上,从第 0 步至第 60 步迭代所插入的元素,在当时都是最小的,故每一查找过程 search ()都会终止于头哨兵-无穷大,而新元素都会被转移至最前端作为首元素。由此可见,这些迭代步所对应的比较次数,应从 1 至 61 逐步递增。
由该表可以看出,第 0 步迭代经过一次(当前元素 61 与头哨兵-∞的)比较,即可确定其适当的插入位置——当然,此步的插入操作其实可以省略,但为简化控制逻辑,算法中不妨统一处理。
实际上,从第 0 步至第 60 步迭代所插入的元素,在当时都是最小的,故每一查找过程 search ()都会终止于头哨兵-无穷大,而新元素都会被转移至最前端作为首元素。由此可见,这些迭代步所对应的比较次数,应从 1 至 61 逐步递增。