Introduction
本章重点介绍数据并行,当存在大量数据可供应用程序同时计算时,我们称之为数据级并行性。数组是一个常见的例子。虽然它是科学应用的基础,但它也被多媒体程序使用。前者使用单精度和双精度浮点数据,后者通常使用 8 位和 16 位整数数据。
[! note] 多媒体扩展 MMX 1997 年的英特尔多媒体扩展( M M X ) 使 SIMD 流行起来。它们通过 1999 年的流媒体 SIMD 扩展(SSE , Streaming SIMD Extensions)和 2010 年的高级向量扩展(AVX)得到了接受和扩展。 MMX 的名声在英特尔 的一则广告中得到了宣扬,该广告的内容是一种采用彩色干净套装的半导体产品线的光纤工作者在跳迪斯科 ( https://www.youtube.com/watch?v=paU16B-bZEA )。
最著名的数据级并行架构是单指令多数据(SIMD,Single Instruction Multiple Data)。SIMD 最初的流行是因为它将 64 位寄存器的数据分成许多个 8 位、16 位或 32 位的部分,然后并行地计算它们。操作码提供了数据宽度和操作类型。数据传输只用单个(宽)SIMD 寄存器的 load 和 store 进行。
把现有的 64 位寄存器进行拆分的做法由于其简单性而显得十分诱人。为了使 SIMD 更快,架构师随后加宽寄存器以同时计算更多部分。由于 SIMD ISA 属于增量设计阵营的一员,并且操作码指定了数据宽度,因此扩展 SIMD 寄存器也就意味着要同时扩展 SIMD 指令集。将 SIMD 寄存器宽度和 SIMD 指令数量翻倍的后续演进步骤都让 ISA 走上了复杂度逐渐提升的道路,这一后果由处理器设计者、编译器编写者和汇编语言程序员共同承担。一个更老的,并且在我们看来更优雅的,利用数据级并行性的方案是向量架构。本章解释了我们在 RISC-V 中使用向量而不是 SIMD 的理由。
向量计算机从内存中中收集数据并将它们放入长的,顺序的向量寄存器中。在这些向量寄存器上,流水线执行单元可以高效地执行运算。然后,向量架构将结果从向量寄存器中取出,并将其并分散地存回主存。向量寄存器的大小由实现决定,而不是像 SIMD 中那样嵌入操作码中。我们将会看到,将向量的长度和每个时钟周期可以进行的最大操作数分离,是向量体系结构的关键所在:向量微架构可以灵活地设计数据并行硬件而不会影响到程序员,程序员可以不用重写代码就享受到长向量带来的好处。此外,向量架构比 SIMD 架构拥有更少的指令数量。而且,与 SIMD 不同,向量架构有着完善的编译器技术。
向量架构比 SIMD 架构更少出现,因此知晓向量 ISA 的读者也更少。因此,本章会比前几章更加具有教程的风格。如果你想深入了解向量架构,请阅读 [Hennessy and Patterson 2011] 的第 4 章和附录 G。RV32V 还有一些简化了 ISA 的新颖功能。即使你已经熟悉了向量架构,也可能需要阅读我们的进一步解释。
向量计算指令
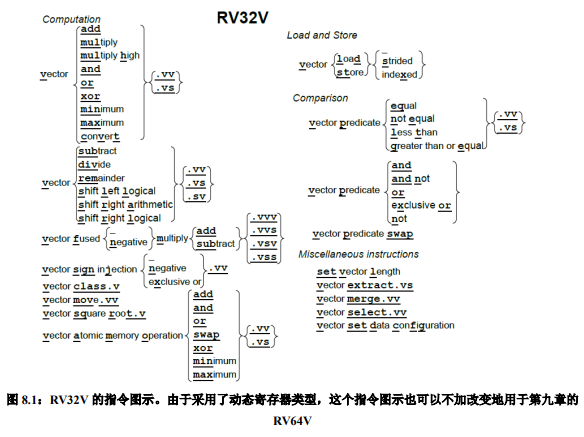 图 8.1 是 RV32V 扩展指令集的图形表示。RV32V 的编码尚未最终确定,所以本版不包含通常的指令布局图。
图 8.1 是 RV32V 扩展指令集的图形表示。RV32V 的编码尚未最终确定,所以本版不包含通常的指令布局图。
前面章节提到的每一个整数和浮点计算指令基本都有对应的向量版本:图 8.1 中的指令继承了来自 RV32I、RV32M、RV32F、RV32D 和 RV32A 的操作。每个向量指令都有几种类型,具体取决于源操作数是否都是向量(.vv 后缀),或者源操作数包含一个向量和一个标量(.vs 后缀)。一个标量后缀意味着有一个操作数来自 x 或 f 寄存器,另一个来自向量寄存器(v)。比方说,我们的 DAXPY 程序(见第 55 页第五章图 5.7)计算 Y=a*X+Y。其中 X 和 Y 是向量,a 是标量。对于向量-标量操作,rs1 域指定了要访问的标量寄存器。
对诸如减法和除法之类的非对称运算,他们还会使用向量指令的第三种变体。其中第一个操作数是标量,第二个是向量(.sv 后缀)。像 Y = a − X 这样的操作就会使用这种变体。这种变体对于加法和乘法等对称运算来说是多余的,因此这些指令没有.sv 的版本。融合的(fused)乘法-加法指令有三个操作数,因此它们有着最多的向量和标量选项的组合:.vvv、.vvs,.vsv 和.vss。
读者可能会注意到,图 8.1 忽略了向量运算的数据类型和宽度。下一节解释了这么做的原因。
向量寄存器和动态类型
RV32V 添加了 32 个向量寄存器,它们的名称以 v 开头,但每个向量寄存器的元素个数不同。该数量取决于操作的宽度和专用于向量寄存器的存储大小,而这取决于处理器的设计者。比方说,如果处理器为向量寄存器分配了 4096 个字节,则这足以让这些 32 个向量寄存器中有 16 个 64 位元素,或者 32 个 32 位元素,或者 64 个 16 位元素,或 128 个 8 位元素。
为了在向量 ISA 中保持元素数量的灵活性,向量处理器会计算会最大向量长度 (mvl),即在给定的容量限制下,向量程序使用这个向量寄存器可以运算的最大向量长度。向量长度寄存器(vl)为特定操作设定了向量中含有的元素数量,这有助于数组维度不是 mvl 的整数倍时的编程。我们将在下面的小节中更详细地演示 mvl,vl 和 8 个谓词寄存器(vpi)的应用。
RV32V 采用了一种新颖的方法,即将数据类型和长度与向量寄存器而不是与指令操作码相关联。程序在执行向量计算指令之前用它们的数据类型和宽度标记向量寄存器。使用动态寄存器类型会减少向量指令的数量。这一点很重要,因为每个向量指令通常有六个整数版本和三个浮点版本,如图 8.1 所示。我们将在第 8.9 节看到,当我们面对众多的 SIMD 指令时,使用动态寄存器类型的向量架构减少了汇编语言程序员的认知负担以及编译器生成代码的难度。
动态类型的另一个优点是程序可以禁用未使用的向量寄存器。此功能可以将所有的向量存储器分配给已启用的向量寄存器。比如,假设只启用了两个 64 位浮点类型的向量寄存器,处理器有 1024 字节的向量寄存器空间。处理器将这些空间对半分,给每个向量寄存器 512 字节(512/8=64 个元素),因此将 mvl 设置位 64。因此我们可以看到,mvl 是动态的,但它的值由处理器设置,不能由软件直接改变。
源寄存器和目标寄存器决定了操作的类型和大小以及结果,因此动态类型隐含了转换。例如,处理器可以将双精度浮点数的向量乘以单精度标量,而无需先将操作数转换为相同的精度。这个额外的好处减少了向量指令的总数和实际执行的指令的数量。
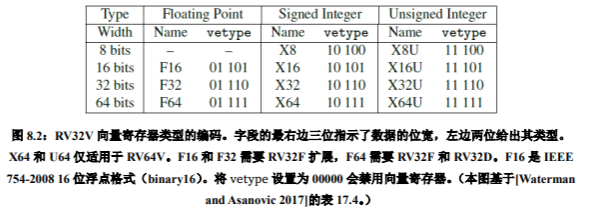 可以用 vsetdcfg 指令来设置向量寄存器的类型。图 8.2 显示了 RV32V 可用的向量寄存器类型以及 RV64V 的更多类型(见第九章)。RV32V 要求向量浮点运算也有标量版本。因此,要使用 F32 类型,你也必须用到 RV32FV;要使用 F64 类型,你也必须用到 RV32FDV。RV32V 引入了 16 位浮点类型 F16。如果一个实现同时支持 RV32V 和 RV32F,则它必须支持 F16 和 F32 类型。
可以用 vsetdcfg 指令来设置向量寄存器的类型。图 8.2 显示了 RV32V 可用的向量寄存器类型以及 RV64V 的更多类型(见第九章)。RV32V 要求向量浮点运算也有标量版本。因此,要使用 F32 类型,你也必须用到 RV32FV;要使用 F64 类型,你也必须用到 RV32FDV。RV32V 引入了 16 位浮点类型 F16。如果一个实现同时支持 RV32V 和 RV32F,则它必须支持 F16 和 F32 类型。
RV32V 可以快速切换上下文
向量架构不如 SIMD 架构受欢迎的一个原因是:大家担心增加大型向量寄存器会延长中断时保存和恢复程序(上下文切换)的时间。
动态寄存器类型对此很有帮助。程序员必须告诉处理器正在使用哪些向量寄存器,这意味着处理器需要在上下文切换中仅保存和恢复那些寄存器。RV32V 约定在不使用向量指令的时候禁用所有向量寄存器,这意味着处理器既可以具有向量寄存器的性能优势,又仅会在向量指令执行过程中发生中断时才会带来额外的上下文切换开销。早期的向量架构在发生中断时,不得不忍受保存和恢复全部向量寄存器的最大的上下文切换开销。
为了避免上下文切换时间过慢,英特尔尽量避免在原始 MMX SIMD 扩展中添加寄存器。它只是重用现有的浮点寄存器,这意味着没有额外的上下文切换,但程序无法同时出现浮点和多媒体指令。
向量的 Load 和 Store 操作
向量 Load 和 Store 操作的最简单情况是处理按顺序存储在内存中的一维数组。向量 Load 用以 vld 指令中地址为起始地址的顺序存储的数据来填充向量寄存器。向量寄存器的数据类型确定数据元素的大小,向量长度寄存器 vl 中设置了要取的元素数量。向量 store 执行 vld 的逆操作。
例如,如果 a0 中存有 1024,且 v0 的类型是 X32,则 vld v0, 0(a0)会生成地址 1024, 1028,1032,1036,……直到达到由 vl 设置的限制。
对于多维数组,某些访问不是顺序的。如果二维数组以行优先序存储,且对列元素进行顺序访问,则相邻列元素之间的地址差正好是行大小。向量架构通过跨步数据传输来支持 vlds 和 vsts 数据访问。
- 对于 vlds 与 vsts,虽然可以通过将步长设置为元素大小来达到与 vld 和 vst 相同的效果,但 vld 和 vst 保证了所有的访问都是顺序的,这可以提供更高的内存带宽。
- 另一个原因是,对于常见的按单位步长访问,使用 vld 和 vst 可以缩减代码长度,并减少执行的指令数。毕竟使用 vlds 和 vsts 指令来需要指定两个源寄存器,一个给出起始地址,另一个给出以字节为单位的步长,而对于单位步长的访问,多花指令来设置第二个寄存器,无遗是一种浪费。
例如,假设 a0 中的起始地址是地址 1024,且 a1 中行的长度是 64 字节。vlds v0, a0, a1 会将这个地址序列发送到内存:1024, 1024 + 1 × 64, 1024 + 2 × 64, 1024 + 3 × 64,以此类推,直到向量长度寄存器 vl 告诉它停止。返回的数据被顺序写入目标向量寄存器的各个元素。
到目前为止,我们都假设该程序在对密集数组进行操作。为了支持稀疏数组,向量架构用 vldx 和 vstx 提供索引数据传输。这些指令的一个源寄存器是向量寄存器,另一个是标量寄存器。标量寄存器具有稀疏数组的起始地址,向量寄存器的每个元素包含稀疏数组的非零元素的字节索引。 假设 a0 中的起始地址是地址 1024,向量寄存器 v1 在前四个元素中有这些字节索引:16,48,80,160。vldx v0, a0, v1 会将这个地址序列发送到内存:1024 + 16, 1024 + 48, 1024 + 80, 1024 + 160。它将返回的数据顺序写入目标向量寄存器的元素中。
以上我们把稀疏数组访问作为索引 Load 和 Store 操作的主要支持目标,但是还有许多 其他算法通过索引表来间接访问数据。
向量操作期间的并行性
虽然简单的向量处理器一次操作一个向量元素,但由于元素操作根据定义是独立的, 所以理论上处理器可以同时计算所有这些元素。RV32G 的数据位宽最大位 64 位,而如今 的向量处理器通常在每个时钟周期内操作两个、四个或八个 64 位元素。当向量长度不是每个时钟周期执行的元素数量的倍数时,由硬件处理处理这些边缘情况。
与 SIMD 一样,对于较小数据的操作数量是较窄数据的位宽和较宽数据的位宽之比。 因此,每个时钟周期计算 4 个 64 位操作的向量处理器通常每个时钟周期可以做 8 个 32 位,16 个 16 位或 32 个 8 位操作。
在 SIMD 中,ISA 架构师在设计过程中决定了每个时钟周期可以并行操作的最大数据 数和每个寄存器的元素个数。相比之下,RV32V 处理器设计人员无需更改 ISA 或编译器就可以选择它们的值,而对于 SIMD,寄存器每增加一倍都会使 SIMD 指令的数量翻倍,并 且需要修改 SIMD 编译器。这种隐藏的灵活性意味着相同的 RV32V 程序不用改变,就可以 在最简单或最复杂的向量处理器上运行。
向量运算的条件执行
一些向量计算包括 if 语句。向量架构不依赖于条件分支,而是包含了一个掩码,这个 掩码禁止向量操作作用于某些元素。图 8.1 中的谓词指令在两个向量或向量和标量之间执 行条件测试,如果条件成立则在掩码向量的每一个元素中写入一个 1,反之写入 0。(掩码 向量必须和向量寄存器有相同的元素个数。)任何后续的向量指令都可以使用这个掩码。第 i 位为 1 表示元素 i 会被向量运算更改,为 0 表示该元素不会由向量运算改变。
RV32V 为掩码向量提供了 8 个向量谓词寄存器(vpi)。vpand,vpandn,vpor,vpxor 和 vpnot 指令在它们之间执行逻辑运算,从而有效处理嵌套条件语句。
RV32V 指定 vp0 或 vp1 作为控制向量操作的掩码。要对所有元素执行一个正常的操 作,必须将这两个谓词寄存器中的一个设置为全 1。RV32V 中有一条 vpswap 指令,用于 将其他六个谓词寄存器的一个快速交换到 vp0 或 vp1。谓词寄存器也是动态启用的,禁用 它们可以快速清除所有谓词寄存器中的值。
例如,假设向量寄存器 v3 中的所有偶数元素都是负整数,所有奇数元素都是正整数。 考虑如下的代码:
vplt.vs vp0,v3,x0 # 将 v3 < 0 的掩码位置 1
add.vv,vp0 v0,v1,v2 # 将 v0 的掩码为 1 的对应元素替换为 v1+v2
这段代码将把 vp0 中所有的偶数位设为 1,奇数位设为 0,并且将把 v0 中所有的偶数元素 替换为 v1 和 v2 中对应元素的和。v0 中的奇数元素不会改变。
其它向量指令
除了之前提到过的设置向量寄存器数据类型的指令(vsetdcfg),其他指令还有 setvl,它将向量长度寄存器(vl)设置为源操作数和最大向量长度(mvl)中的较小值。 选择较小值的原因是,在循环中我们需要判断这些向量代码到底是可以按最大向量长度 (mvl)运行,还是要以一个较小值运行,从而能处理循环尾部剩下的元素。因此,为了 处理循环尾部的元素,每次循环迭代都执行 setvl。
RV32V 中还有三条指令可以操作向量寄存器中的元素。
- 向量选择(vselect)按第二个源向量(索引向量)指定的元素位置,从第一个源数据向量中取得元素,从而生成一个新的结果向量:
# vindices 存有 0 到 mvl-1 的值,它们用来从 vsrc 中选取元素
vselect vedst, vsrc, vindices
因此,如果 v2 的前四个元素是 8、0、4、2,那么 vselect v0, v1, v2 将用 v1 的第 8 个元 素替换 v0 的第 0 个元素;v1 的第 0 个元素替换 v0 的第 1 个元素;v1 的第 4 个元素替换 v0 的第 2 个元素;v1 的第 2 个元素替换 v0 的第 3 个元素。
- 向量合并(vmerge)类似于向量选择,但它用向量谓词寄存器来选择源向量中要用到元素。新的结果向量由根据谓词寄存器从两个源寄存器之一取得元素产生。若谓词向量寄存器元素为 0,则新元素来自 vsrc1;如果为 1,则来自 vsrc2。
# vp0 的第 i 位决定 vdest 中新元素 i 来自 vsrc1(若第 i 位是 0)
# 还是 vsrc2(第 i 位为 1)
vmerge, vp0 vdest, vsrc1, vsrc2
因此,如果 vp0 的前四个元素是 1、0、0、1,v1 的前四个元素是 1、2、3、4,v2 的前四 个元素是 10、20、30、40,那么 vmerge, vp0 v0, v1, v2 将把 v0 的前四个元素变为 10、 2、3、40。
- 向量提取指令从一个向量的中间开始取元素,并将它们放在第二个向量寄存器的开头:
# start 是一个标量寄存器,其中存储着从 vsrc 中取元素的起始位置
vextract vdest, vsrc, start
例如,如果向量长度 vl 是 64,而 a0 的值是 32,那么 vextract v0,v1,a0 会把 v1 中的后 32 个元素复制到 v0 的前三十二个元素。
对于任意的二元结合运算符,可以利用 vextract 指令以递归减半的方法进行缩减运算。例如,要对向量寄存器的所有元素求和,可以用 vextract 将向量的后半部分复制到另一个向量寄存器的前半部分,这就将向量长度缩短了一半。接下来,将这两个向量寄存器加到一起,并将它们的和作为新一轮递归的操作数,直到向量长度减少到 1。此时第零个元素中的结果就是原向量寄存器中所有元素的和。