RISC-V 指令系统概述
RISC-V 架构特点
-
指令集架构简单
- 指令集——238 页,特权级编程手册——135 页,其中 RV32I 只有 16页
- 作为对比,Intel 的处理器手册有 5000 多页
- 新的体系结构设计吸取了经验和最新的研究成果
- 指令数量少,基本的 RISC-V 指令数目仅有 40 多条,加上其他的模块化扩展指令总共几十条指令。
-
模块化的指令集设计
- 不同的部分还能以模块化的方式组织在一起
- ARM 的架构分为 A、R 和 M 三个系列,分别针对于 Application(应用操作系统)、Real-Time(实时)和 Embedded(嵌入式)三个领域,彼此之间并不兼容
- RISC-V 嵌入式场景,用户可以选择 RV32IC 组合的指令集,仅使用 Machine Mode(机器模式);而高性能操作系统场景则可以选择譬如 RV32IMFDC 的指令集,使用 Machine Mode(机器模式)与 User Mode(用户模式)两种模式,两种使用方式的共同部分相互兼容
RISC-V 模块化设计
- RISC-V 的指令集使用模块化的方式进行组织,每一个模块使用一个英文字母来表示
- RISC-V 最基本也是唯一强制要求实现的指令集部分是由 I 字母表示的基本整数指令子集,使用该整数指令子集,便能够实现完整的软件编译器
- 其他的指令子集部分均为可选的模块,具有代表性的模块包括 M/A/F/D/C:
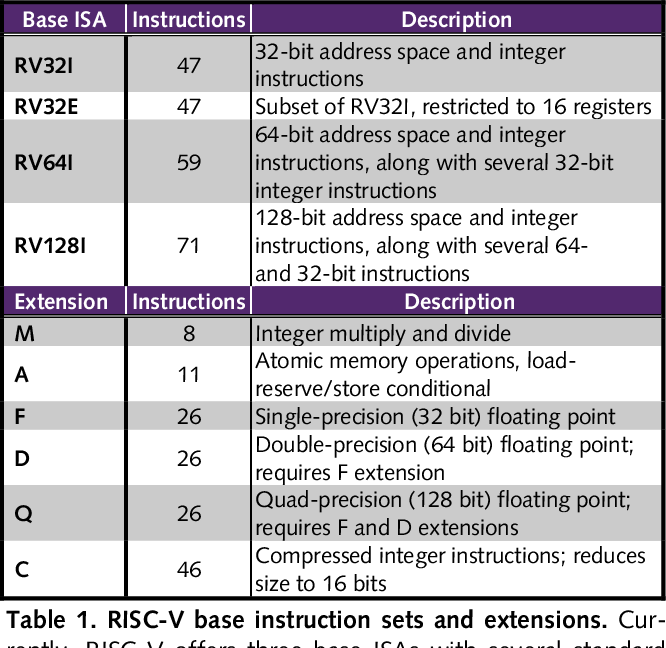
 用户可以扩展自己的指令子集,RISC-V 预留了大量的指令编码空间用于用户的自定义扩展,同时,还定义了四条 Custom 指令可供用户直接使用,每条 Custom 指令都有几个比特位的子编码空间预留,因此,用户可以直接使用四条 Custom 指令扩展出几十条自定义的指令。
用户可以扩展自己的指令子集,RISC-V 预留了大量的指令编码空间用于用户的自定义扩展,同时,还定义了四条 Custom 指令可供用户直接使用,每条 Custom 指令都有几个比特位的子编码空间预留,因此,用户可以直接使用四条 Custom 指令扩展出几十条自定义的指令。
可配置的通用寄存器组
寄存器组主要包括通用寄存器(General Purpose Registers)和控制状态寄存器(Control and Status Registers)
通用寄存器:
- 32 位架构 (RV32I) 32 个 32 位的通用寄存器,64 位架构 (RV64I) 32 个 64 位的通用寄存器
- 嵌入式架构 RV32E 有 16 个 32 位的通用寄存器
- 支持单精度浮点数(F),或者双精度浮点数(D),另 外增加一组独立的通用浮点寄存器组,f0~f31
控制状态寄存器:
- CSR 寄存器用于配置或记录一些运行的状态(后续异常和中断处理中会详细描述)
- CSR 寄存器是处理器核内部的寄存器,使用专有的12位地址码空间
规整的指令编码
- 所有通用寄存器在指令码的位置是一样的,方便译码阶段的使用
- 所有的指令都是 32 位字长,有 6 种指令格式:寄存器型,立即数型,存储型,分支指令、跳转指令和大立即数:

特权模式
RISC-V 架构定义了三种工作模式,又称特权模式 (Privileged Mode):
- Machine Mode:机器模式,简称 M Mode
- Supervisor Mode:监督模式,简称 S Mode
- User Mode:用户模式,简称 U Mode
RISC-V 架构定义 M Mode 为必选模式,另外两种为可选模式。通过不同的模式组合可以实现不同的系统
在异常和中断处理中会详细讨各个特权模式的机制
RISC-V 指令集与汇编语言概述
汇编格式
汇编指令格式 op dst, src1, src2
- 1 个操作码,3 个操作数
- op 操作的名字
- dst 目标寄存器
- src1 第一个源操作数寄存器
- src2 第二个源操作数寄存器
通过一些限制来保持硬件简洁。
- 每一条指令只有一个操作,每一行最多一条指令
- 汇编指令与 C 语言的操作类似(= , + , -, * , /, &, |, 等)
- C 语言中的操作会被分解为一条或者多条汇编指令
- C 语言中的一行会被编译为多行 RISC-V 汇编程序
寄存器概述
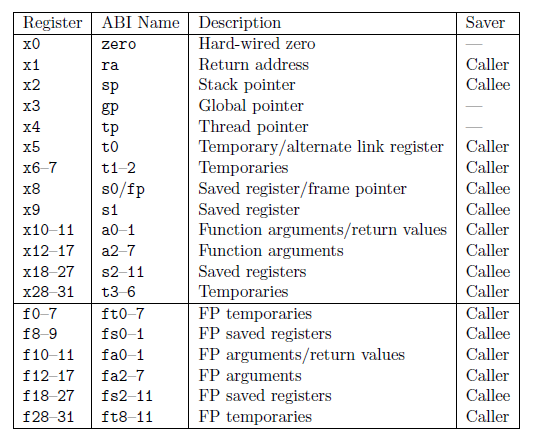
- 在 RISC-V 中有 32 个寄存器(x0-x31)
- 每个寄存器的长度为 32位
- X0 是一个特殊的寄存器,只用于全零
- 每一个寄存器都有自己的别名,用于软件的使用的惯例,但是实际的硬件并没有任何区别
算术、逻辑、移位
加减法
变量 a,b 和 c 被分别放置在寄存器 x1, x2,和 x3中
- 整数的加法(add)C: a = b + c
- RISC-V: add x1, x2, x3
- 整数的减法(sub)C: a = b – c
- RISC-V: sub x1, x2, x
#a->x1, b->x2, c->x3, d->x4, e->x5
#compile C program `a = (b+c)-(d+e)` into riscv asm
add x6, x4, x5 # tmp1 = d + e
add x7, x2, x3 # tmp2 = b + c
sub x1, x7, x6 # a = (b + c) – (d + e)
指令执行顺序反映了源程序的计算过程,指令中可以看到如何使用临时寄存器,# 符号后面是程序的注释。
[! note] 特殊的寄存器 zero 0 在程序中很常见,拥有一个自己的寄存器 x0,或者 zero。
这是一个特殊的寄存器,只拥有值 0,并且不能被改变
注意,在任意的指令中,如果使用 x0 作为目标寄存器, 将没有任何效果,仍然保持 0 不变
使用样例:
add x3, x0, x0 # c=0 add x1, x2, x0 # a=b add x0, x0, x0 # nop
立即数
数值常数被称为是立即数(immediates)
立即数有特殊的指令语法:opi dst, src, imm
- 操作码的最后一个字符为 i 的,会将第二个操作数认为是一个立即数(经常用后缀来指明操作数的类型,例如无符号数 unsigned 的后缀为 u)
- 指令举例
addi x1, x2, 5 # a=b+5addi x3, x3, 1 # c++ p
[! question] 问题:为何没有 subi 指令? 和 ARM-32 不同,RV32I 中立即数总是进行符号扩展,这样子如果需要,可以用立即数表示负数,正因为如此,并不需要一个立即数版本的 sub
如何处理溢出?
溢出是因为计算机中表达数本身是有范围限制的,计算的结果没有足够多的位数进行表达。
RISC-V 忽略溢出问题,高位被截断,低位写入到目标寄存器中
乘除法
积的长度是乘数和被乘数长度的和。将两个32位数相乘得到的是64位的乘积。 因此,为了正确地得到一个有符号或无符号的64位积,RISC-V 中带有四个乘法指令。
- 要得到整数 32 位乘积(64 位中的低 32 位)就用 mul 指令。
- 要得到高 32 位,如果操作数都是有符号数,就用 mulh 指令;
- 如果操作数都是无符号数,就用 mulhu 指令;
- 如果一个有符号一个无符号,可以用 mulhsu 指令;
- 如果需要获得完整的 64 位值,建议的指令序列为
mulh [[s]u] rdh, rs1, rs2; mul rdl, rs1, rs2- (源寄存器必须使用相同的顺序, rdh 要注意和 rs1和 rs2都不相同。这样底层的微体系结构就会 把两条指令合并成一次乘法操作,而不是两次乘法操作)
除法指令:
div x5, x6, x7 # x5 = x6/x7
rem x5, x6, x7 # x5 = x6 mod x7
位操作
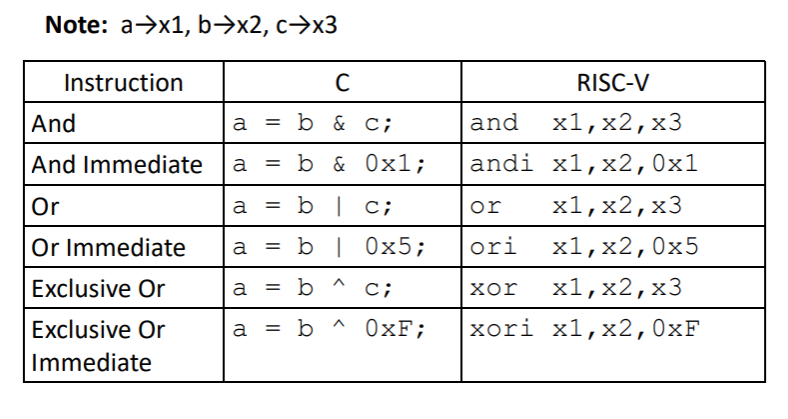
移位
- 左移相当于乘以2,左移右边补0,左移操作更快
- 逻辑右移:在最高位添加0
- 算术右移:在最高位添加符号位
- 移位的位数可以是立即数或者寄存器中的值
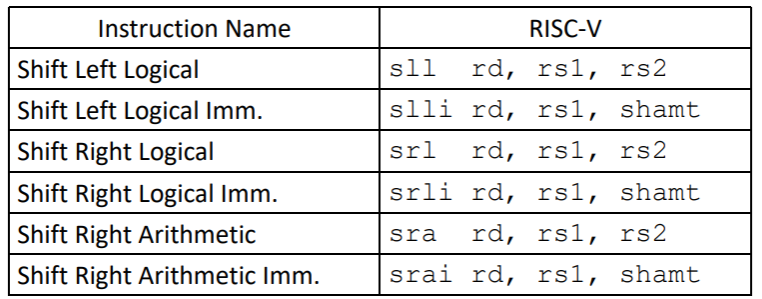
- slli, srli, srai 只需要最多移动63位 (对64位寄存器),只会使用 immediate 低6(2^6=64)位的值(I 类型指令)
数据传输指令
专用内存到寄存器之间传输数据的指令,其它指令都只能操作寄存器。
简化硬件设计
-
支持字节(8 位),半字(16 位),字(32 位),双字(64 位,64 位架构)的数据传输
-
推荐但不强制地址对齐
-
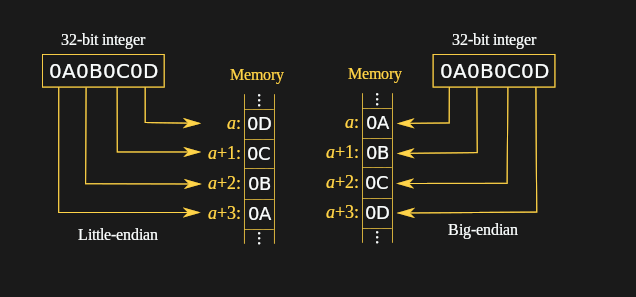
小端机结构:
-
C 语言中的变量会映射到寄存器中;而其它的过长的、动态的数据结构,例如数组会映射到内存的栈中
-
内存是一维的数组,地址从 0 开始
-
只有 load/store 指令可以操作内存:
- Store 指令:从寄存器到内存
- Load 指令:从内存到寄存
load/store 指令格式
数据传输指令的格式 memop reg, off(bAddr)
- memop = 操作的名字(load 或者 store)
- reg = 寄存器的名字,源寄存器或者目标寄存器
- bAddr = 指向内存的基地址寄存器 (base address)
- off = 地址偏移,字节寻址,为立即数 (offset)
- 访问的内存地址为
bAddr + off - 必须指向一个合法的地址
内存寻址方式
在现代计算机中操作以8bits 为单位,即一个字节
- 一个 word 的定义依据不同的体系结构定义不同,这里定义 1 word = 4 bytes = 32 bits
- 内存是按照字节进行编址的,不是按照字进行编址的
字地址之间有4个字节的距离
- 字的地址为其最低位的字节的地址
- 按字对齐的话地址最后两位为 0(地址为 4 的倍数)
- C 语言会自动按照数据类型来计算地址,在汇编中需要程序员自己计算
使用举例
# addr of int A[] -> x3, a -> x2
lw x10,12(x3) # x10 = A[3] ,装入一个字
add x10,x2,x10 # x10 = A[3]+a
sw x10,40(x3) # A[10] = A[3] + a , 写出一个字
内存和变量大小
lw reg, off(bAddr) sw reg, off(bAddr)
- off+bAddr 必须按照字进行对齐,即 4 的倍数
- 例如整数的数字,每个整数 32 位=4 字节
[! question] 如何传输 1 个字符的数据?或者传输一个 short 的数据(2 个字节)? 这些都不是 4 个字节的整数倍。
实际上,还是使用字类型指令,配合位的掩码来达到目的
lw x11,0(x1)andi x11,x11,0xFF # lowest byte p或者,使用字节传输指令
lb x11,1(x1)sb x11,0(x1)字节传输指令无需字对齐
字节传输指令
lb/sb 使用的是最低的字节
- 如果是 sb 指令,高 24 位被忽略
- 如果是 lb 指令,高 24 位做符号扩展

半字传输指令

lh reg, off(bAddr)# “load half”sh reg, off(bAddr)# “store half”- off (bAddr)必须是 2 的倍数
- sh 指令中高 16 位忽略
- lh 指令中高16位做符号扩展
无符号的版本:
lhu reg, off(bAddr)# “load half unsigned”lbu reg, off(bAddr)# “load byte unsigned”- l(b/h)u 指令, 高位都做0扩展
比较、分支、跳转
比较指令
Set Less Than (slt) - slt dst,reg1,reg2
- if value in src1 < value in src2, dst = 1, else 0
Set Less Than Immediate (slti) - slti dst,reg1,imm
- If value in reg1 < imm, dst = 1, else 0
如何完成无符号数的比较?
相减看是否溢出。
Unsigned versions of slt(i):
sltu dst,src1,src2: unsigned comparisonsltiu dst,src,imm: unsigned comparison against constant
addi x10,x0,-1 # x10 = 0xffffffff
slti x11,x10,1 # x11 = 1 (-1<1)
sltiu x12,x10,1 # x12 = 0 (2^32-1 >>>1)
有符号和无符号的对比
-
Signed vs. unsigned bit extension 符号扩展
- lb,lh
- lbu, lhu
-
Signed vs. unsigned comparison 比较
- slt, slti
- sltu, sltiu
-
Signed vs. unsigned branch 比较
- blt, bge
- bltu, bgeu
条件跳转指令
C 语言中有控制流——比较语句/逻辑语句确定下一步执行的语句块
RISC-V 汇编无法定义语句块,但是可以通过标记 (Label)的方式来定义语句块起始
- 标记后面加一个冒号(main: )
- 汇编的控制流就是跳转到标记的位置
- 在 C 语言中也有类似的结构,但是被认为是坏的编程风格 (C 语言有 goto 语句,跳转到标记所在的位置)
Branch If Equal (beq)
beq reg1,reg2,label- If value in reg1 = value in reg2, go to label
Branch If Not Equal (bne)
bne reg1,reg2,label- If value in reg1 ≠ value in reg2, go to label
- 注意没有依据标志位的跳转(与 x86 不同)
jal 将某一条指令的地址放到寄存器 ra(无条件跳转指令)
- RISC-V: 指令是 4 字节长度,内存是按照字节编址的
0x0040061C jal newMoney
0x00400620 (add 4)
伪指令
伪指令可以给程序员更加直观的指令,但不是直接通过硬件来实现,而是通过汇编器来翻译为实际的硬件指令。
伪指令举例:
- Load Immediate (li) 装入一个立即数
li dst,imm,装入一个 32 位的立即数到 dst- 被翻译为:
addi dst x0 imm
- Load Address (la) 装入一个地址
la dst,label,装入由 Label 指定的地址到 dst- 翻译为:
addi dst, x0, label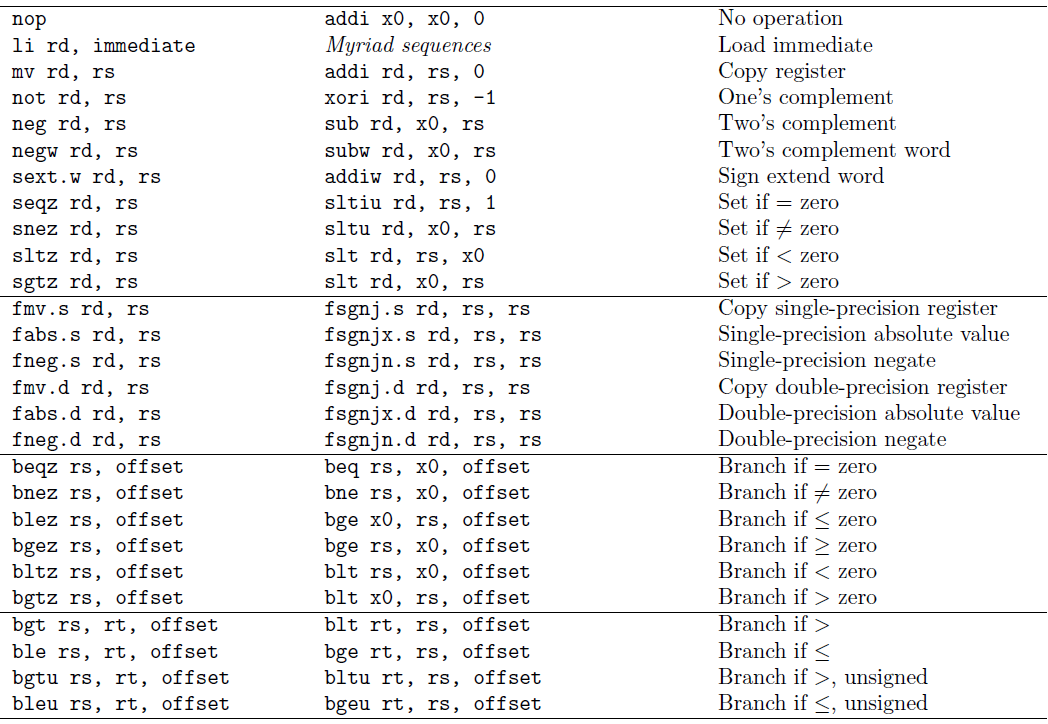
[! note] 伪指令 vs. 硬件指令
- 硬件指令(TAL,True Assembly Language)
- 所有指令都是硬件可以直接执行的指令,在硬件中直接实现
- 伪指令
- 汇编语言程序员可以使用的指令(加上了部分硬件未真正实现的指令)
- 每一条伪指令指令会被翻译为 1 条或者多条 TAL 指令
- 硬件指令 ⊂ 伪指令
函数调用
流程
- 将参数放置在函数可以访问到的地方
- 将控制流转到函数中
- 函数获取任何其所需要的存储资源
- 执行函数体,完成功能
- 函数放置返回值,清理函数调用信息
- 控制流返回给函数调用者
对函数调用的支持
如果有可能,尽可能使用寄存器,寄存器要比内存快得多
- x10–x17:可以用来传递参数或返回值
- x1:返回地址寄存器,用于返回到起始点
- x2:sp 栈指针
- 传递参数的时候,顺序是有用的,代表了程序中的参数的顺序
- 如果寄存器空间不够,则需要借助于在内存中的栈进行传参
RICV-V 中的函数调用
- Jump and Link (jal)
jal label
- Jump and Link Register (jalr)
jalr src
- “and Link”: 在调到对应函数内部之前,将下一条指令的地址放置在寄存器 x1 中
- x1: ra,返回地址寄存器
指令地址
指令和数据都存放在同一个地址空间中,标记 Label 会被翻译为一个指令地址,jal 指令会把一条指令的地址放在寄存器 ra。
PC
程序计数器(PC)指向的是当前正在执行的指令(上下文不同的环境下,有时候也会说明为指向下一条指令,PC 经过更新后指向下一条将执行的指令)
- 值在指令执行第一个阶段就会被更新
- PC 值对于程序员是不可见的,但是可以被 jal 指令使用
- 所有的分支指令 (beq, bne, jal, jalr),跳转指令都是通过更新 PC 来完成功能
被调用者保存寄存器
Callee Saved Registers:
- s0-s11: x8-x9 + x18-x27 (callee saved registers)
- sp (stack pointer):必须要指向相同的位置,否则调用者就找不到当前的栈帧
- 如果寄存器不够用,则可以将原值保存在栈上,待函数返回的时候恢复
调用者保存寄存器
Caller Saved Registers:(Volatile Registers)
- 被调用的函数可以自由使用
- 调用者如果需要使用这些值的话,调用者必须要自己去保存
- X5-x7 + x28-x31: t0-t6 (temporary registers,临时寄存器)
- X10-x11: a0-a1 (return values,返回值):保存需要传回来的返回值
- x1: ra (return address
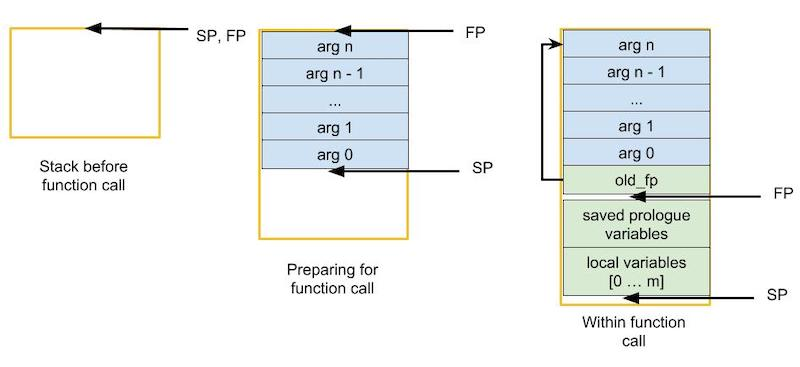
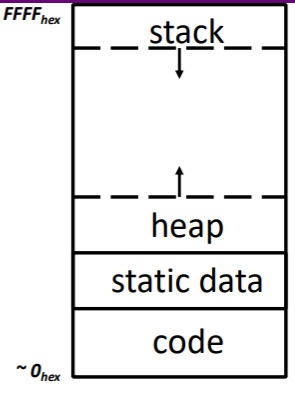
栈帧结构