Perceptron Hypothesis Set
Formulate in Linear Algebra
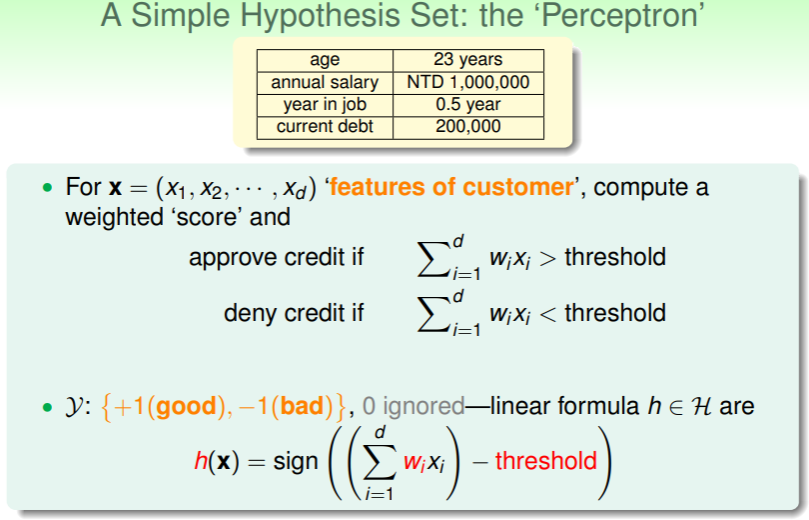
- 每个客户的数据都组成一个向量 ,其中的每一个分量 即是客户的特征,如年龄、年薪、工龄、负债情况…
- 对每一个分量 赋以权重 ,二者相乘后求和,即可得到该客户的特征——从而验证能否通过批准信用卡的阈值 threshold ,
- 对客户特征与阈值 threshold 取差值,差值为正即允许批准信用卡的申请,为负则不批准,若是为 0 ?事实上,这种情况很少见,剔除后也不会造成影响;
对以上符号和想法用线性代数中的运算表示,如下:
- 假设 对样本数据 的关系式:

- 这里为了将 threshold 纳入向量运算中,延伸一个第 0 维的分量 和 。
Linear Classifier
进一步地,这个假设函数 可否图形化?

- 若只取两个分量 ,即得到二维空间 (取更多分量则得到更高维的图形 ),
- 对用户样本的判断称作加标签(label),+1 记作蓝色圆圈,-1 记作红色叉,
- 用户的特征向量和对应标签即是这个二维空间中的一个点 ,
- 假设函数 在二维空间中的图形就是一个直线,对直线两侧的点进行预测,一侧为正,一侧为负,
- 这就是线性分类器;
练习:判断垃圾邮件可以哪些维度?

Perceptron Learning Algorithm
所谓 PLA ,即是在假设集 中选择出对目标函数 f 的最佳估计 g 的过程。
Choose Right Hypothesis
现在的问题就是如何从无穷大的 中尽可能高效地取出尽可能准确的 g 作为 f 的估计:
- f 是未知的, 的空间又是无穷大的,因此取出准确的 g 相当困难,
- 目标是找出理想的 g ,使得 ,
- 一个好的方法是,先任意地选择一个 g 作为起始,然后根据数据样本逐步地修正使用它发生的错误,直到发生错误的概率足够小——起始的估计称为 ,其有权重向量 ,因此简化地将起始估计取其权重向量,并记作 。
Correct the Known Mistakes
现在,从 (可以随意设置权重,比如全为 0)开始,逐步地修正它:

- 如果 并不是当前数据集中一个完美的估计,那么就一定存在一个样本 能够使对其预测的结果和真实的标签并不相同: ➡ 这就是“犯错”
- 如何“修正错误”?如果实际的 label 是+1,但是预测却是 -1,那就在预测的权重向量 上加一个 ,这里 y 是+1;反之亦然
- 那么每一轮 t 都进行这样的错误点查找、纠正,直到越来越接近正确值、不再预测错误,那么最后一轮的这个 就是在训练集中最佳的 g .
PLA 的过程是周期性的:

下图是一个 PLA 计算过程的示例:
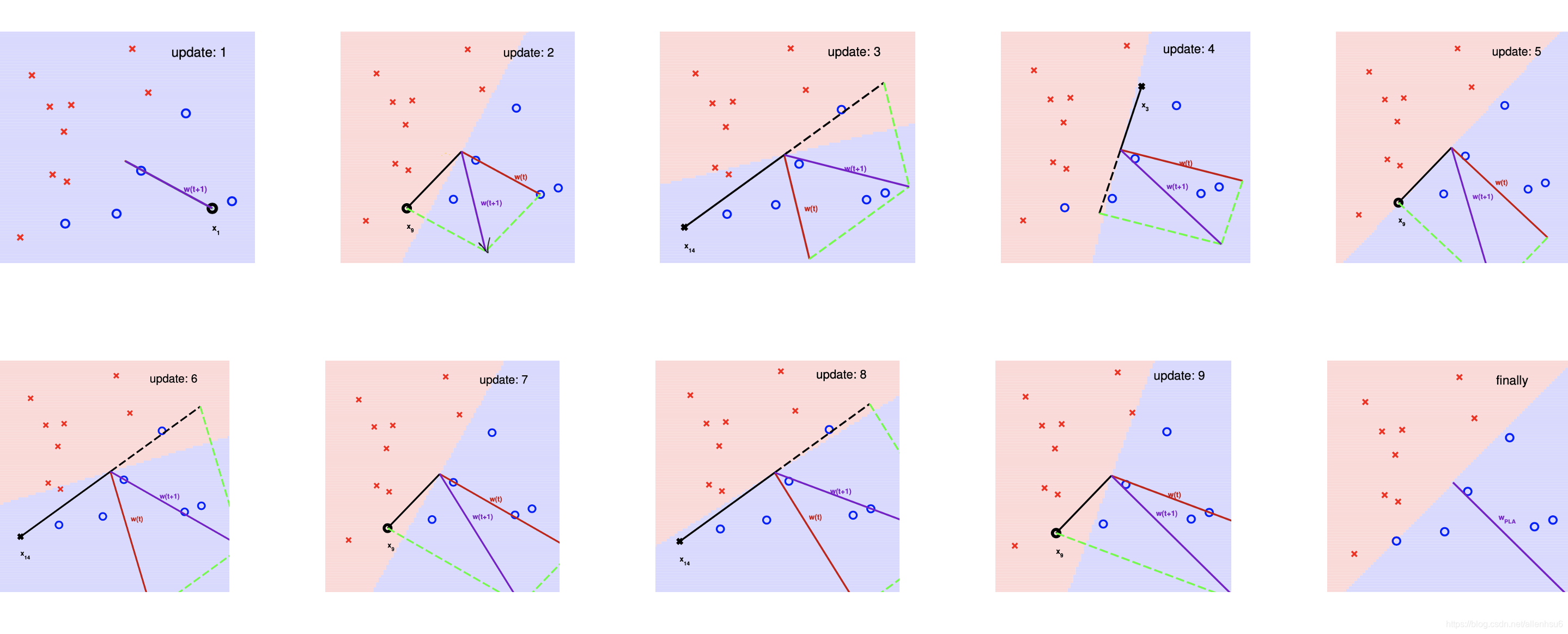
练习:思考迭代的真实含义

- 这个练习题能够进一步理解每轮迭代都进行了怎样的工作——第三个选项代表了下一轮的分数更大,超出阈值更多,也更有可信度。
Linear Separability
Further Thinking
线性可分性:如果 PLA 能够停止,当且仅当训练集 能够被某个权重 划分且(在训练集上)不再出错,并且由于数据样本的各维分量是一阶的,因此对分类器图形化的话会得到一个线性的分类器:
- 下图左边是线性可分的,中间和右边不是线性可分的:
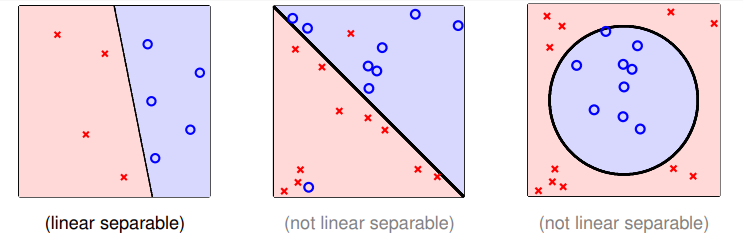
- 对第 2 个问题——只有训练集满足线性可分,才能够确保 PLA 最终能够停止。
Guarantee of PLA
PLA Fact
- PLA 的过程就是 当前轮次的权重 越来越接近 目标函数的权重 的过程,
- 而训练集 的线性可分性能够保证,一定存在完美的 使得对所有训练集中样本的估计 成立,
- 另外,PLA 关键在于遇错更新,这也导致 的增长并不会太快,即不会线性地、成倍数的增加。
基于目标函数的定义可以导出如下的数学关系: 对所有的 的判断都是正确的,即所有样本点都与划分直线有距离(不在直线上):
- 这里 指的就是样本点距离划分直线的带正负号距离,而正确的估计就是
正距离*(+1),负距离*(-1),因此总体上总是正的; - 而 是 PLA 每一轮迭代时选择的错误点的距离;
每一轮更新样本点 时,实际上就是做这样的运算:,将右项展开,前一项 没有意义,后一项才是关键——由 不等式(*) 可知:
这个式子说明,每一轮迭代,向量内积都在逐渐增大,意味着两个向量越来越接近,即 越来越接近 —— 这个说法其实有些片面,因为内积增大不仅可能是方向上越来越接近,也可能是向量长度的成比例变化。
要证伪后者,则需要回顾到 PLA 的最关键性质:遇错更新。所谓遇错,即是 ,而考查向量的长度:
- 其中之所以是小于等于,是因为错误会导致 ,而最后一行 的取值不外乎+1 或-1,因此平方后都可以舍去;
- 这也就表明,由于只有犯错才会更新,而犯错同时也限制了增长速度,即不会比上一轮的 超过 ,那么这里的含义就是最多增长最“长”的 的距离;
联立 (1), (2) 式,可以得知,从 开始迭代,经过 T 次犯错,有这样的关系:
- 这里左边是两个单位长度的向量内积,确实表现了它们角度有多么靠近,靠近的速度就是中式中的 constant 的值。
- 可能无限靠近吗?不会,单位向量的内积最大长度也不过是 1,因此总会停止下来。
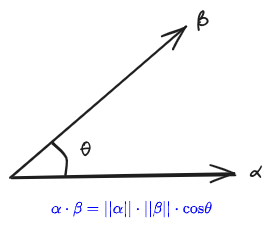
constant 具体是如何推导的呢?
(1)式的放缩:
(2)式的放缩:
练习:理解迭代次数 T 的上界
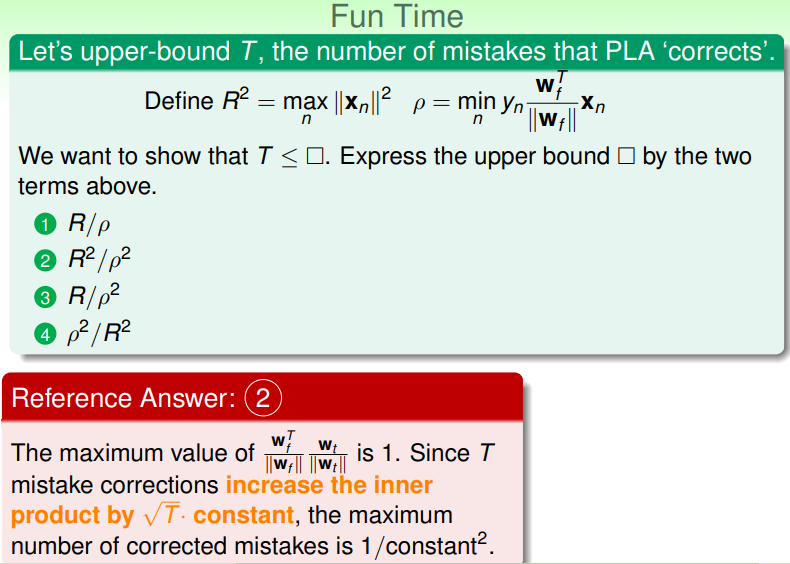
- 这个计算很简单,只需要把之前那个式子中的 constant 移到另一边后两边同时平方一下,即可得出;
- 但这里 和 的含义是什么?
- 前者是向量最大长度的平方,这个最大长度又称为半径;
- 后者是目标划分直线的法向量与每个样本点的向量的内积的最小值;
ρ 可以提前确定吗?
很遗憾,尽管我们能够得出以上的数学关系式,但 的具体数值仍由 向量所确定,因此只能确定 PLA 最终会停下来,但具体的次数在实际运行结束前是无法确定的。
Non-Separable Data
由前文论证可知,如果训练集 确实是线性可分的,并且是遇错更新的,那么必然有以下结论:
- 目标 和当前迭代轮次 的内积会快速地增加,即二者角度快速接近;而 又是遇错更新的,因此增长速度极慢;
- PLA 得到的“直线”必然越来越接近于 所对应的直线,直到最后停下来。
这样的 PLA 确实易于实现、高效、且对任意维度的向量 都能实现(二维乃至一百维,对程序来说并没有实质的差别)。那么,PLA 真的如此完美吗?显然不是:
- 我们在实际运行前,是不知道 究竟是不是线性可分的;
- 我们也不知道究竟要运行多久才会停下来,因为 是取决于 的——甚至一旦不是线性可分的,比如有噪音点或非线性可分区域,将无法停止。
- 对于非线性可分区域,我们可以改进模型解决,后续学习将会解决这个问题,
- 现在我们先来处理噪音点:
Learning with Noisy Data
当 中掺入噪音:
假设一个前提:噪音相对于可信数据是少量的(否则说明数据集不具有可信度)。
- 因此,即使对理想的 f ,也有可能犯错,但大多数情况下 还是成立的。
- 因此我们在运行中获得的 g ,对 也是大多数情况下成立的,那么选中一个 g ,使得 ,即取犯错最少的那个 g 作为估计,不是就能满足要求吗?
- 确实,但不幸的是,选择犯错最少的 g 的算法目前还是个 NP-hard 问题,即不存在多项式(polynomial)时间复杂度内解决的算法,它是 复杂度的。
如何解决?捡西瓜丢芝麻策略!(英语中通常称为 Pocket Algorithm)—— 保持最佳的 在手中,如果下一轮 的结果反而导致正确率下降,那么就舍弃之:

练习:Pocket 与 PLA 孰优?
在确实线性可分的 中分别运行 Pokcet 策略和 PLA,孰优?

- Pocket 策略由于每轮都要评估是否有所进步,因此耗时比 PLA 更久;