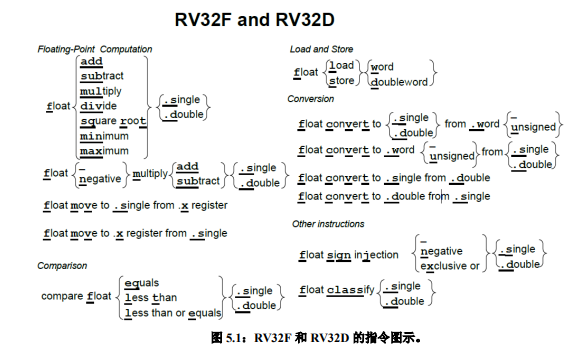
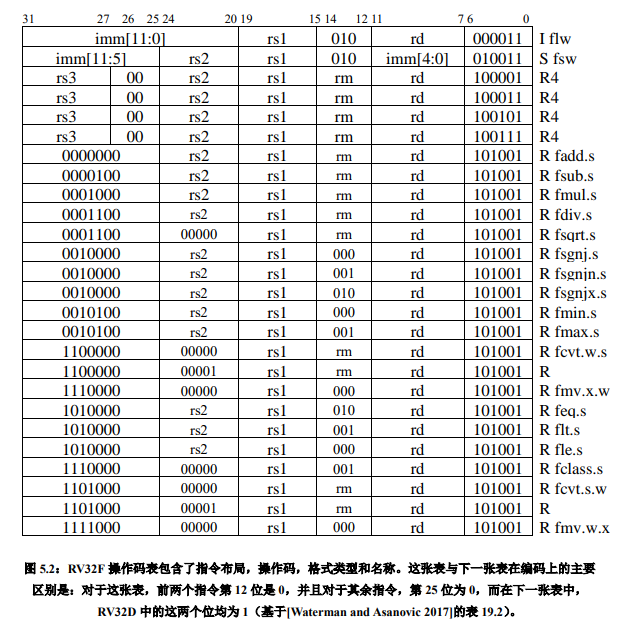
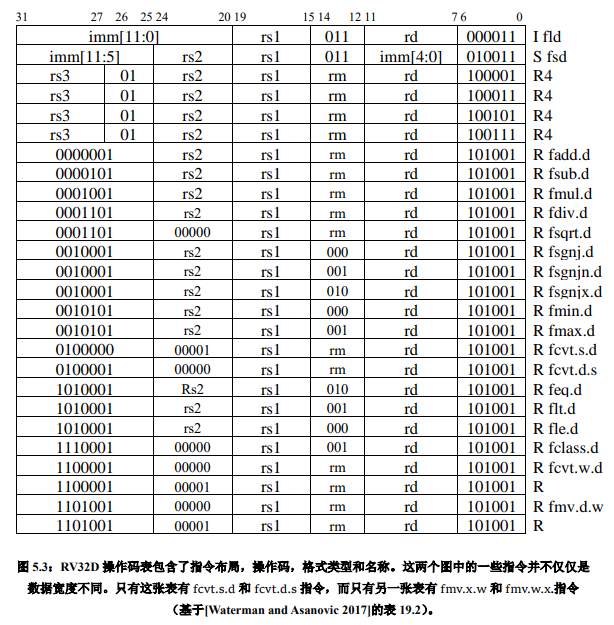
尽管 RV32F 和 RV32D 是分开的,单独的可选指令集扩展,他们通常是包括在一起的。 为简洁起见,我们在一章中介绍了几乎所有的单精度和双精度(32 位和 64 位)浮点指令。 图 5.1 是一个 RV32F 和 RV32D 扩展指令集的图形表示。图 5.2 列出 RV32F 的操作码,图 5.3 列出了 RV32D 的操作码。和几乎所有其他现代 ISA 一样,RISC-V 服从 IEEE 754-2008 浮点标准。
浮点寄存器
RV32F 和 RV32D 使用 32 个独立的 f 寄存器而不是 x 寄存器。使用两组寄存器的主要原因是:处理器在不增加 RISC-V 指令格式中寄存器描述符所占空间的情况下使用两组寄存器来将寄存器容量和带宽是乘 2,这可以提高处理器性能。
使用两组寄存器对 RISC-V 指令集的主要影响是,必须要添加新的指令来加载和存储数据 f 寄存器,还需要添加新指令用于在 x 和 f 寄存器之间传递数据。图 5.4 列出了 RV32D 和 RV32F 寄存器及对应的由 RISC-V ABI 确定的寄存器名称。
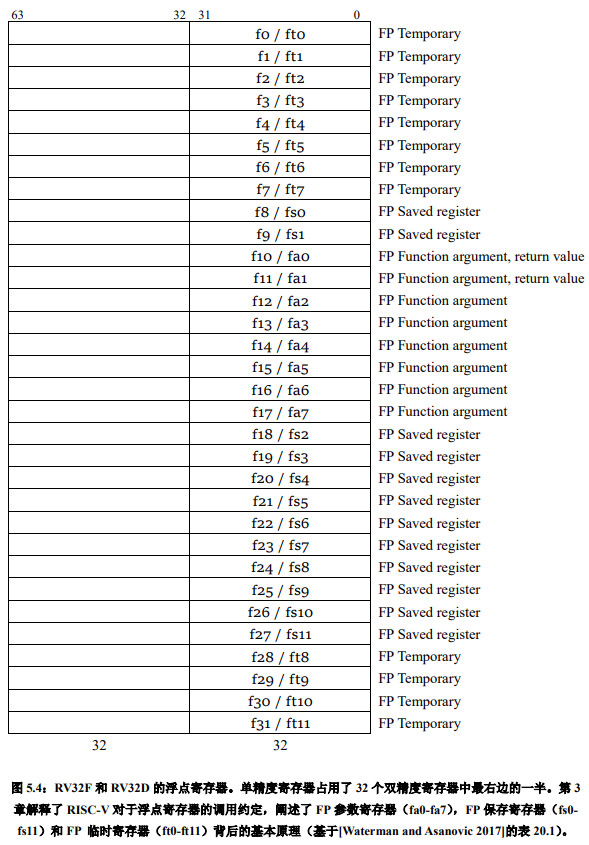
如果处理器同时支持 RV32F 和 RV32D 扩展,则单精度数据仅使用 f 寄存器中的低 32 位。与 RV32I 中的 x0 不同,寄存器 f0 不是硬连线到常量 0,而是和所有其他 31 个 f 寄存器一样,是一个可变寄存器。
IEEE 754-2008 标准提供了几种浮点运算舍入的方法,这有助于确定误差范围和编写数值库。最准确且最常见的舍入模式是舍入到最近的偶数(RNE)。舍入模式可以通过浮点控制和状态寄存器 fcsr 进行设置。图 5.5 显示了 fcsr 并列出了舍入选项。它还包含标准所需的累积异常标志。

有什么不同之处?
- ARM-32 和 MIPS-32 都有 32 个单精度浮点寄存器但都只有 16 个双精度寄存器。它们都将两个单精度寄存器映射到双精度寄存器的左右两半。
- x86-32 浮点数算术没有任何寄存器,而是使用堆栈代替。堆栈条目是 80 位宽度提高精度,因此浮点数负载将 32 位或 64 位操作数转换为 80 位,对于存储指令,反之亦然。x86-32 的一个后续版本增加了 8 个传统的 64 位浮点寄存器以及相关的操作指令。
- 与 RV32FD 和 MIPS-32 不同,ARM-32 和 x86-32 忽视了在浮点和整数寄存器之间直接移动数据的指令。唯一的解决方案是先将浮点寄存器的内容存储在内存中,然后将其从内存加载到整数寄存器,反之亦然。
[! note] RV32FD 允许逐条指令设置舍入模式 这被称为静态舍入,当你只需要更改一条指令的舍入模式时,它可以帮助提高性能。 默认设置是在 fcsr 中使用动态舍入模式。静态舍入所选择的模式是作为指令可选的最后一个参数,如 fadd. s ft0,ft1,ft2,rtz,将向零舍入,无论 fcsr 如何。图 5.5 的标题列出了不同舍入模式的名称。
浮点加载,存储和算术指令
对于 RV32F 和 RV32D,RISC-V 有两条加载指令(flw,fld)和两条存储指令(fsw, fsd)。他们和 lw 和 sw 拥有相同的寻址模式和指令格式。
添加到标准算术运算中的指令有:(fadd.s,fadd.d,fsub.s,fsub.d,fmul.s,fmul.d,fdiv.s,fdiv.d),RV32F 和 RV32D 还包括平方根(fsqrt.s,fsqrt.d)指令。它们也有最小值和最大值指令(fmin.s,fmin.d, fmax.s,fmax.d),这些指令在不使用分支指令进行比较的情况下,将一对源操作数中的较小值或较大值写入目的寄存器。
许多浮点算法(例如矩阵乘法)在执行完乘法运算后会立即执行一条加法或减法指令。因此,RISC-V 提供了指令用于先将两个操作数相乘然后将乘积加上(fmadd.s,fmadd.d) 或减去(fmsub.s,fmsub.d)第三个操作数,最后再将结果写入目的寄存器。它还有在加上或减去第三个操作数之前对乘积取反的版本:fnmadd.s,fnmadd.d,fnmsub.s,fnmsub.d。 这些融合的乘法 - 加法指令比单独的使用乘法及加法指令更准确,也更快,因为它们只(在加法之后)舍入过一次,而单独的乘法及加法指令则舍入了两次(先是在乘法之后,然后在加法之后)。这些指令需要一条新指令格式指定第 4 个寄存器,称为 R4。图 5.2 和 5.3 显示 了 R4 格式,它是 R 格式的一个变种。
RV32F 和 RV32D 没有提供浮点分支指令,而是提供了浮点比较指令,这些根据两个浮点的比较结果将一个整数寄存器设置为 1 或 0:feq.s,feq.d,flt.s,flt.d,fle.s,fle.d。这些指令允许整数分支指令根据浮点数比较指令设置的条件进行分支跳转。例如,这段代码在 f1 < f2 时,则分支跳转到 Exit:
flt x5,f1,f2 # if f1<f2, x5=1; else x5=0
bne x5,x0,Exit # if x5 != 0, jump to Exit
浮点转换和搬运
RV32F 和 RV32D 支持在 32 位有符号整数,32 位无符号整数,32 位浮点和 64 位之间浮点进行所有组合的转换(只要这个转换是有用,有意义的)。图 5.6 按源数据类型以及 转换后的目的数据类型,罗列了这 10 条指令。
![]()
RV32F 还提供了将数据从 f 寄存器(fmv.x.w)移动到 x 寄存器的指令,以及反方向移 动数据的指令(fmv.w.x)。
其它浮点指令
RV32F 和 RV32D 提供了不寻常的指令,有助于编写数学库以及提供有用的伪指令。(IEEE 754 浮点标准需要一种复制并且操作符号并对浮点数据进行分类的方式,这启发我们添加了这些指令。
符号注入指令
它从第一个源操作数复制了除符号位之外的所有内容。符号位 的取值取决于具体是什么指令:
- 浮点符号注入(fsgnj.s,fsgnj.d):结果的符号位是 rs2 的符号位。
- 浮点符号取反注入(fsgnjn.s,fsgnjn.d):结果的符号位与 rs2 的符号位相反。
- 浮点符号异或注入(fsgnjx. s,fsgnjx. d):结果符号位是 rs1 和 rs2 的符号位异或的结果。
除了有助于数学库中的符号操作,基于符号注入指令我们还提供了三种流行的浮点伪指令(参见第 37 页的图 3.4):
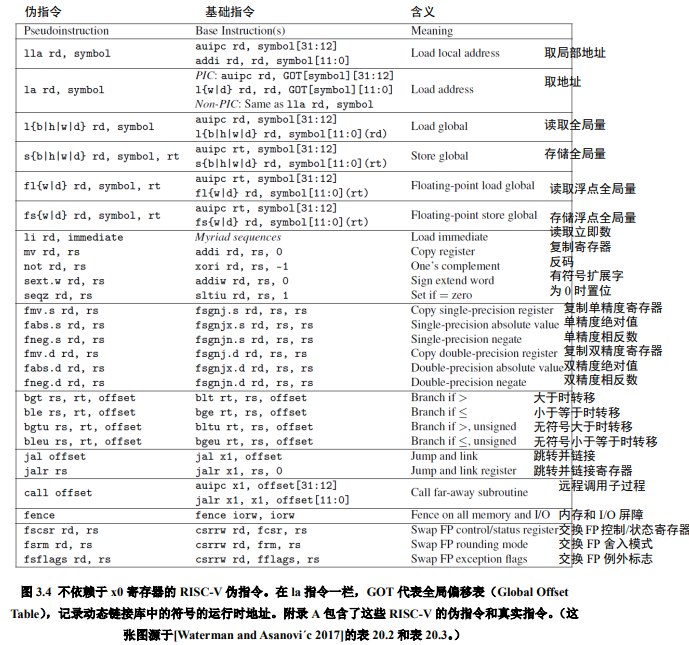{kind=link}
- 复制浮点寄存器:
- fmv. s rd,rs 事实上是 fsgnj. s rd,rs,rs
- fmv.d rd,rs 事实上是 sgnj.d rd,rs,rs。
- 否定:
- fneg. s rd,rs 映射到 fsgnjn. s rd,rs,rs
- fneg. d rd,rs 映射到 fsgnjn. d rd,rs,rs。
- 绝对值(因为 0⊕0= 0 且 1⊕1= 0):
- fabs. s rd,rs 变成了 fsgnjx. s rd,rs,rs
- fabs.d rd,rs 变成了 sgnjx.d rd,rs,rs。
分类指令
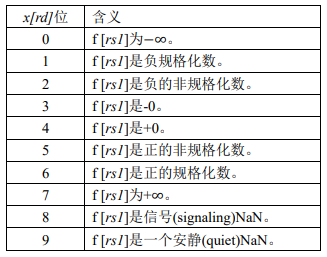
classify 分类指令(fclass.s,fclass.d)对数学库也很有帮助。他们测试一个源操作数来看源操作数满足下列 10 个浮点数属性中的哪些属性 (参见下表),然后将测试结果的掩码写入目的整数寄存器的低 10 位。十位中仅有一位被设 置为 1,其余为都设置为 0。