2-3 递增扩容分析
证明:在最坏情况下,单次操作中消耗于扩容的分摊时间为Θ(n),其中 n 为向量规模。
解答:假定每次追加 d 个单元。于是,只要每隔固定的常数 k 次操作就发生一次扩容,则初始容量为 的向量在经过连续的 N >> k) 次操作之后,容量将增加至: 在此过程中,所有扩容操作消耗于数据转移的时间合计为: 均摊至单次操作,所需时间为:
2-5 分摊分析——二进制整数递增
对一个无符号 32 位整型发量 ,其功能是作为计数器,不断地递增(count++,溢出后循环)。每经一次递增,count 的某些比特位都会在 0 和 1 之间翻转。比如,若当前有: count = 43 (10) = 0… 0101011 (2) 则下次递增之后将有: count = 44 (10) = 0… 0101100 (2) 在此过程中,共有(最末尾的)三个比特发生翻转。 现在,考查对 c 连续的足够多次递增操作。纵观这一系列操作,试证明:
-
==每经过 2^k 次递增,则 反转一次== 每经过 2^k 次递增,计数器的数值恰好增加 2^k。体现在其二进制展开中,对应于数位 的 (由 0 到 1 或由 1 到 0)翻转。
-
==对于每次递增操作,就分摊意义而言,只有 O (1)个比特位反转== 不妨从 0 开始,考查该计数器的连续 N >> 2 次递增操作。我们将在此期间的所有数位翻转, 分别“记账”至对应的数位。于是根据以上 (1)所证的性质,所有数位的翻转次数总和为:
因此就分摊意义而言,单次递增操作仅引发 O (1)次数位翻转。
与基于加倍策略的可扩充向量同理,这里的关键在于参与累计的各项构成(以 1/2 为倍数的)几何级数,正如我们已知的,就渐进意义而言其总和同阶于其中的最大项。因此无论这里的计数器有多少个二进制数位组成,上述性质与结论均可成立。实际上,即便假设计数器拥有无穷个数 位(故永不溢出),亦是如此。
2-6 permute 生成随机排列
template<typename T> void permute(Vector<T> &V){
// 随机置乱向量,可以使各元素等概率地出现在各位置
for(int i=V.size();i>0;i++)
swap(V[i-1],V[rand()%i]);//V[i-1]与V[0,i)中某随机元素交换
}
试证明:
- ==通过反复调用 permute ()算法,可以生成向量
V[0, n)的所有 n! 种排列== 可以通过对向量规模 n 的数学归纳予以证明。假定该命题对于规模不足 n 的任意向量均成立。 作为归纳的基础,规模 n = 1 的情况不证自明。以下考查规模为 n 的任意向量V[]: 任取该向量的一个排列: 只需证明,该排列有可能被 permute ()算法生成。
实际上,在该算法的第一次迭代中,有可能取 。于是,首次参与交换的将是 和 ,且如此交换之后的向量成为:
不难看出,自此之后的计算过程完全等效于,对于其中前 n - 1 个元素组成的子向量置乱。 也就是说,可等效于将向量: 置乱为:
由归纳假设,permute ()算法可以生成长度为 n - 1 的该排列(以及长度为 n 的整个排列)。
- ==由该算法生成的排列中,各元素处于任一位置的概率均为 1/n== 可以按照各元素在 permute ()算法中(自后向前)就位的次序,归纳证明这一命题。
首先,鉴于 rand ()的随机均匀性,最早就位的元素 必以相等的概率选自整个向量,故原向量中每个元素最终出现在该位置的概率为 1/n。
不妨假定该命题对前 k 个(0 ⇐ k < n)就位的元素均成立,即它们均是以 1/n 的等概率取自原向量中各元素。以下,考查下一个就位的元素 。
 如图所示,按照算法流程,元素 X 应随机地选自当时的前 n - k 个元素(包含其自身),且其中各元素被选中的概率均为 1/(n - k)。
请注意,当时的这前 n - k 个元素均有可能参与过此前的 k 次随机交换。这些元素都是截至当前尚未就位者,原向量中的任何一个元素,都有 (n - k)/n 的概率成为它们中的一员。因此,原向量中每个元素接下来被随机选中且随即交换成为 的概率应是:
(n - k)/n x 1/(n - k) = 1/n
如图所示,按照算法流程,元素 X 应随机地选自当时的前 n - k 个元素(包含其自身),且其中各元素被选中的概率均为 1/(n - k)。
请注意,当时的这前 n - k 个元素均有可能参与过此前的 k 次随机交换。这些元素都是截至当前尚未就位者,原向量中的任何一个元素,都有 (n - k)/n 的概率成为它们中的一员。因此,原向量中每个元素接下来被随机选中且随即交换成为 的概率应是:
(n - k)/n x 1/(n - k) = 1/n
- ==该算法生成各排列的概率均为 1/n!== 既然以上已经证明,原向量中各元素最终就位于各位置的概率均等,permute ()算法就应以相等的概率,随机地生成所有可能的排列。
对于规模为 n 的向量,可能的排列共计 n! 种,故概率分别为 1/n!。
2-7 伪随机无法实现 permute ()
//在 C 语言标准库中,Brian W. Kernighan 和 Dennis M. Ritchie 设计的随机数发生器如下
unsigned long int next = 1;
/* rand: return pseudo-random integer on 0..32767 */
int rand(void)
{
next = next * 1103515245 + 12345;
return (unsigned int)(next/65536) % 32768;
}
/* srand: set seed for rand() */
void srand(unsigned int seed)
{
next = seed;
}
-
==理解原理== 该算法维护一个 32 位的无符号长整数 next,随着 next 的“随意”变化,不断输出伪随机数。 通过 srand (seed),可以设置 next 的初始值(随机种子)。 此后 rand ()的每一次执行过程,均如图所示。
.png) 首先,在 next 当前值的基础上乘以 1103515245 = 3^5 x 5 x 7 x 129749,并加上 12345。 然后,通过整除运算在该长整数的二进制展开中截取高 16 位,进而通过模余运算抹除最高比特位。 经如此的“混沌化”处理之后,即可作为“随机数”返回
首先,在 next 当前值的基础上乘以 1103515245 = 3^5 x 5 x 7 x 129749,并加上 12345。 然后,通过整除运算在该长整数的二进制展开中截取高 16 位,进而通过模余运算抹除最高比特位。 经如此的“混沌化”处理之后,即可作为“随机数”返回 -
==证明该 rand ()无法实现 permute ()中元素出现在任意位置概率相同== 不难注意到,以上 rand ()算法的返回值尽管具有一定的随机性,但远非理想的随机。实际上更严格地讲,其返回值是确定的:只要知道当前的 next 值,即可确定地得出下一 next 值。
反观上题中的 permute 算法,其对每一个向量的置乱结果,应完全取决于其间对 rand ()函数 n = V.size ()次调用所返回的 n 个“随机数”。但使用如上实现的 rand (),这些返回值完全取决于所设定的起始种子 seed。
permute ()算法如需兑现上题中结论全排列和等概率的性质,本应保证能够通过 rand ()获得 n 个彼此独立的随机数。然而不幸的是,由以上分析可见这一条件并不成立。实际上甚至可以确定,如此可能获得的长度为 n 的“随机数”序列有多少个——其总数不超过 seed 的取值范围,就此例而言即为: 2^16 = 65,536 < 9! = 362,880
这就意味着,即便是长度 n = 9 的向量,借助该版本的 rand ()也无法枚举出所有可能的置乱排列;而对于更长的向量,这个算法就更是无能为力了。
- ==事实上,该类伪随机发生器都无法实现 permute ()的等概率和全排列== 由以上分析可知,只要继续沿用这种“种子 + 迭代”的模式,增加 rand ()输出整数的位宽亦是徒然——这种“改进”并不能有效地克服上述缺陷。比如,不难验证有: 2^64 = 2^(60 + 4) < 20 x 10^18 < 21! = 51,090,942,171,709,440,000
也就是说,即便使用 64 位的无符号整数,在向量的规模超过 20 之后,借助这种模式的随机数发生器就无法覆盖所有可能的置乱排列。进一步地,随着向量规模 n 的进一步扩大,如此可枚举出来的排列,在所有 n! 种排列中所占的比例将迅速下降,并很快趋近于零。
2-12-a deduplicate ()最好、最坏的时间复杂度
最好情况:所有元素都互不相同,则只需要一次遍历即可确定,此时需要 O (n)时间进行判断。确定过程可以通过 hash table 的插入进行判断,以空间换时间, 若所有操作都没有发生冲突,意味着所有元素互异。
最坏情况:元素集中存在大量重复,因此主要时间耗费在元素的删除、移动中,对于元素 _elem[k],若需做删除操作,则为此需花费 O (n - k) 时间移动所有的后继元素,因此各轮迭代至少需要 Ω(min (n - k, k)) 时间,累计 Ω(n^2)。
2-12-d deduplicate ()可以改进到什么地步?
如果没有其它的附加条件,那么在图灵机等通常的计算模型下,可以证明“无序向量唯一化”问题的复杂度下界(难度)为 Ω(nlogn)。为此,我们可以借助归约的技巧。
线性规约
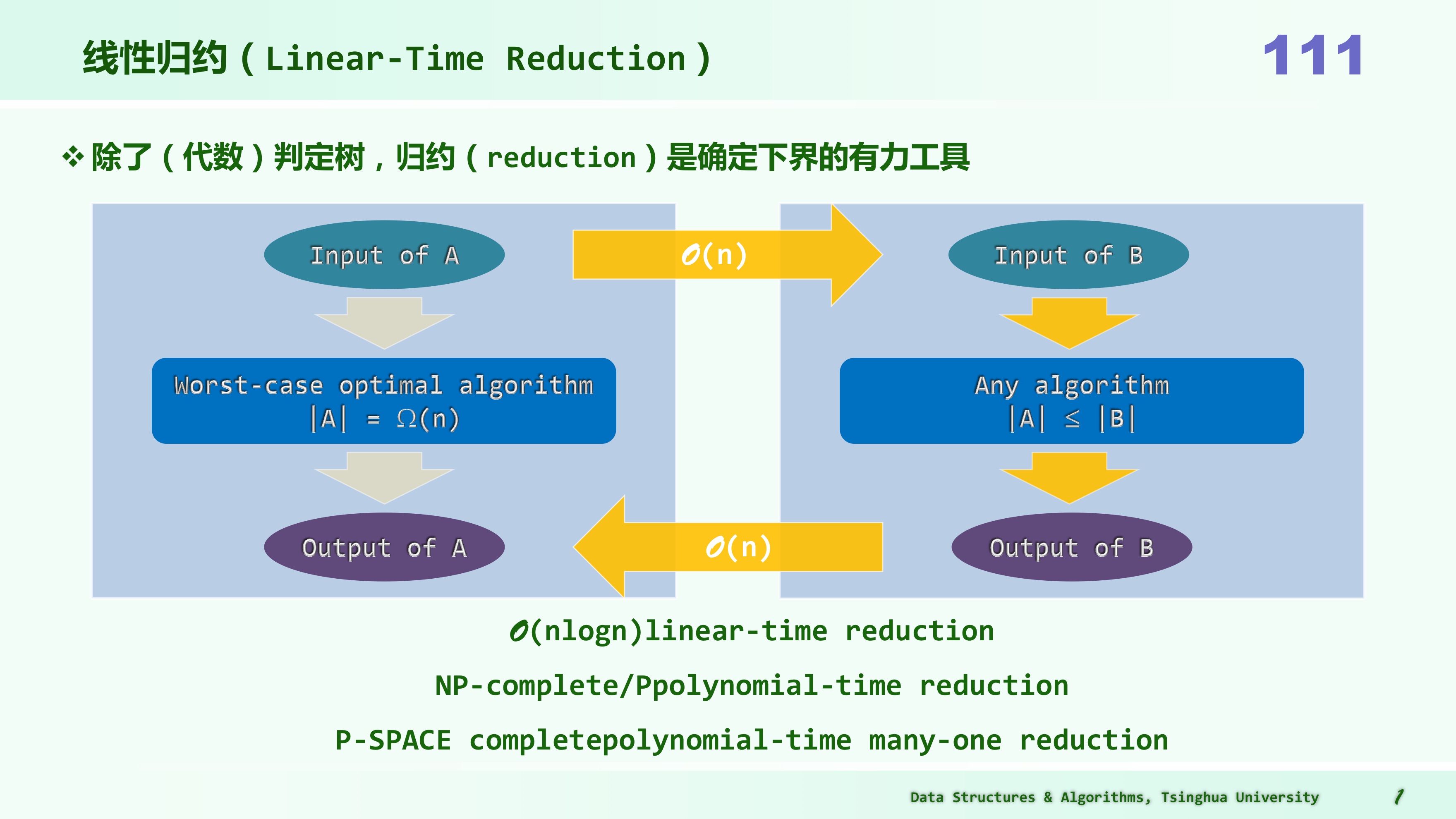
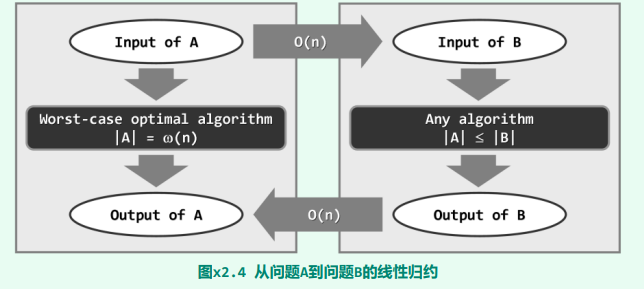
规约 reduction 是确定下界的另一工具。
规约的详细定义
一般地,考查难度待界定的问题 B。若另一问题 A 满足以下性质: 1)问题 A 的任一输入,都可以在线性时间内转换为问题 B 的输入 2)问题 B 的任一输出,都可以在线性时间内转换为问题 A 的输出 则称“问题 A 可在线性时间内归约为问题 B”,或简称作“问题 A 可线性归约为问题 B”,或者称“从问题 A 到问题 B,存在一个线性(时间)归约(linear-time reduction)关系”,记作:
此时,若问题 A 的难度(记作|A|)已界定为严格地高于Ω(n),亦即: |A| = Ω(f (n)) = ω(n) 则问题 B 的难度(记作|B|)也不会低于这个复杂度下界,亦即: |B| >= |A| = Ω(f (n)) 实际上,若问题 A 果真可以线性归约为问题 B,则由后者的任一算法,必然同时也可以导出前者的一个算法。这一结论,可由图直接看出:为求解问题 A,可将其输入转化为问题 B 的输入,再调用后者的算法,最后将输出转化为前者的输出。
因此,假若问题 B 具有一个更低的下界,则至少存在一个 o (f (n))的算法,于是由上可知, 问题 A 也存在一个 o (f (n))的算法——这与问题 A 已知的 ω(n)下界相悖。
归纳起来,为运用线性归约界定问题 B 的难度下界,须经以下步骤: 1)找到难度已知为 ω(n)的问题 A 2)证明问题 A 可线性归约为问题 B——其输入、输出可在线性时间内完成转换
指向原始笔记的链接


就本题而言,“无序向量唯一化”即是难度待界定的问题 B,将其简记作 UNIQ。作为参照,考查所谓的元素唯一性(Element Uniqueness,简称 EU)问题 A:对于任意 n 个实数,判定其中是否有重复者——作为 EU 问题的输入,任意 n 个实数都可在线性时间内组织为一个无序向量,从而转换为 UNIQ 问题的输入;另一方面,一旦得到 UNIQ 问题的输出(即去重之后的向量),只需花费线性时间,核对向量的规模是否依然为 n,即可判定原实数中是否含有重复者(亦即,得到 EU 问题的输出)。
因此,EU 问题可以线性归约为 UNIQ 问题,亦即: 实际上,算法复杂度理论业已证明,EU 问题具有 Ω(nlogn)的复杂度下界,故这也是 UNIQ 问题的一个下界。反过来,以上所给的 O (nlogn)算法(先排序,后 uniquify),已属最优。
2-15 CBA 算法下界分析
-
==对 4 个整数排序,最坏情况下不少于 5 次比较== 既然是考查最坏情况,不妨假定所有整数互异,此时的 CBA 式算法经每次比较之后,在对应的比较树(comparison tree)中只有两个有效的分支。 此时共有 4! 种可能的输出,故算法对应的比较树至少拥有 24 个叶节点,因此树高至少是:
-
设计一种 CBA 算法在最坏情况也只需要 5 次比较 归并排序(mergesort)算法。如图所示,当输入规模为 4 时,归并排序算法的递归深度为 2。
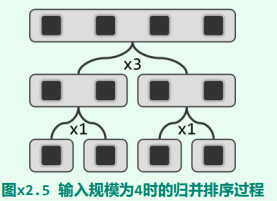 底层的两次二路归并,各自仅需 1 次比较;顶层的一次二路归并,最坏情况下只需 3 次比较。总体合计,不过 5 次比较。
底层的两次二路归并,各自仅需 1 次比较;顶层的一次二路归并,最坏情况下只需 3 次比较。总体合计,不过 5 次比较。
2-18 binSearch 查找长度分析
背景:以 binSearch-A 针对独立均匀分布于 [0,2n] 内的整数目标,在固定的有序向量{1,3,5,…, 2n-1}中查找。
- ==若将平均成功和失败查找长度分别记作 S 和 F,试证明:(S + 1)∙n = F∙(n + 1);==
对向量规模 n 做数学归纳。
假定对于规模小于 n 的所有向量,以上命题均成立。以下考查规模为 n 的向量。
实际上,我们可以考查 binSearch ()算法对应的比较树。一般地,若向量的规模为 n,则对应的比较树应由 n 个内部节点(成功的返回)以及 n + 1 个叶节点(失败的返回)。
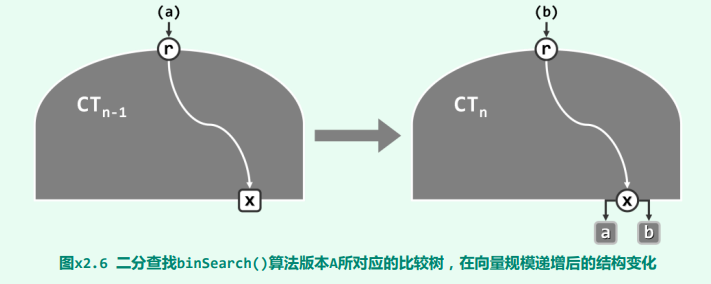
特别地,规模为 n - 1 和 n 的向量所对应的比较树( 和 )应该分别如图所示。二者之间的差异仅在于,前者的某一外部节点 x,被替换为由一个内部节点 x 和两个外部节点 a 与 b 组成的子树。也就是说,原先的某一查找失败情况,现在对应于一种成功情况,另加两种失败情况。综合而言,成功情况及失败情况各自增加一种。
比如,对于向量{ 1, 3 },共计有 2 种成功情况{ 1, 3 }以及 3 种失败情况{ 0, 2, 4 };而对于向量{ 1, 3, 5 },则共计有 3 种成功情况{ 1, 3, 5 }以及 4 种失败情况{ 0, 2, 4, 6 }。
设在 中,失败情况 x 所对应的查找长度为 d。于是根据算法流程,在 中成功情况 x 对应的查找长度应为 d + 2,而新的两种失败情况对应的查找长度为 d + 1 和 d + 2。
若在 中,内部节点、外部节点所对应的成功查找总长度、失败查找总长度应分别为:S∙(n - 1), F∙n 则在 中,内部节点、外部节点所对应的成功查找总长度、失败查找总长度应分别为: S∙(n - 1) + (d + 2) F∙n + (d + 1) + (d + 2) - d = F∙n + (d + 3)
于是在 中,成功查找、失败查找的平均长度应分别为: S’ = [S∙(n - 1) + (d + 2)]/n F’ = [F∙n + (d + 3)]/(n + 1) 故有: (S’ + 1)∙n = (S + 1)∙(n - 1) + (d + 3) F’∙(n + 1) = F∙n + (d + 3) 根据归纳假设,应有: (S + 1)∙(n - 1) = F∙n 故有: (S’ + 1)∙n = F’∙(n + 1)
- 上述结论是否适用于 binSearch ()其他版本?是否适用于 fibSearch ()? 仍然适用。
- 证明方法完全类似,只不过在从 转换至 时,内部节点、叶节点所对应的成功、失败查找长度的计算口径不同。
- 考查在从 转换至 后,(二者有所差异的)局部子树对成功、失败查找总长度的贡献。实际上在命题中恒等式的两端,只要这两方面的贡献相互抵消,恒等式即可继续成立。
- ==若待查找的整数按照其它分布于
[0,2n],则如何调整上述结论?== 命题中的恒等式需加入各种情况对应的概率权重。
2-19 fibSearch 取 mi 的替代策略
描述:返几种替代策略,综合性能各有什么优劣?为什么?
- 按照黄金分割比,取 mi =
- 按照近似的黄金分割比,取 mi =
- 按照近似的黄金分割比,取 mi =
fibSearch ()算法中,首先需要调用 Fib 类的初始化接口,
找到一个尽可能小,却亦足够覆盖整个向量 V[0, n) 的 Fibonacci 数,作为初始查找范围的宽度:
如代码 x1.12 (递归 fib)所示,Fib 类对象的初始化只需 时间(分摊至后续的查找过程,每次递归仅增加 O (1)时间)。接下来在迭代式逐层深入地查找过程中,还需通过一个内循环确定合适的黄金分割点——实际上每个分割点只需不超过两次迭代。
尽管以上足以说明 fibSearch ()算法的高效性,但就算法流程的简洁性而言,却远不如标准的二分查找 binSearch ()算法。 究其原因在于,目前实现的版本对 Fibonacci 查找思想的理解和贯彻过于机械。实际上,本题所建议的几种方式都能在保持渐进效率的前提下适当地灵活变通,使算法的流程得以简化和清晰。建议的三种改进方案中,
- 方案 a)采用近似值快速地估算出切分点,
- 方案 b)可更好地发挥整数运算的优势,
- 方案 c)则通过移位操作替代更为耗时的乘、除法运算。
2-20 对比 binSearch-A 与 fibSearch
问题:推导二者失败查找长度的公式,并分析性能
可以证明:对于规模为 n 的有序向量,二分查找在失败情况下的平均比较次数不超过: 为此,我们采用数学归纳法。作为归纳基,这一命题对长度为 1 的向量显然。
.png) 考查二分查找的第一步迭代,如图所示无非两种情况。
首先,考查左、右子向量规模均为 n 的情况。此时如图 (a)所示,左侧子向量总共包含 n + 1 种失败情况,由归纳假设,其平均比较长度不超过:1 + 1.5∙log_2 (n + 1) 右侧子向量也总共包含 n + 1 种失败情况,由归纳假设,其平均比较长度不超过:2 + 1.5∙log2 (n + 1)
综合所有失败情况,总体的平均查找长度不超过:
考查二分查找的第一步迭代,如图所示无非两种情况。
首先,考查左、右子向量规模均为 n 的情况。此时如图 (a)所示,左侧子向量总共包含 n + 1 种失败情况,由归纳假设,其平均比较长度不超过:1 + 1.5∙log_2 (n + 1) 右侧子向量也总共包含 n + 1 种失败情况,由归纳假设,其平均比较长度不超过:2 + 1.5∙log2 (n + 1)
综合所有失败情况,总体的平均查找长度不超过:
再考查左、右子向量规模分别为 n 和 n - 1 的情况。此时如图 (b)所示,左侧子向量总共包含 n + 1 种失败情况,由归纳假设,其平均比较长度不超过:1 + 1.5∙log_2 (n + 1) 右侧子向量总共包含 n 种失败情况,由归纳假设,其平均比较长度不超过:2 + 1.5∙log_2 (n) 综合所有失败情况,总体的平均查找长度不超过: [(n + 1)∙(1 + 1.5∙log2 (n + 1)) + n∙(2 + 1.5∙log2n)] / (2n + 1) = [(3n + 1) + 1.5∙((n + 1)∙log2 (n + 1) + n∙log2n)] / (2n + 1) ~ [(3n + 1) + 1.5∙2∙(n + 1/2)∙log2 (n + 1/2)] / (2n + 1) = (3n + 1)/(2n + 1) + 1.5∙log2 (n + 1/2) ~ 1.5∙[1 + log2 (n + 1/2)] = 1.5∙log2 (2n + 1)) = O (1.5∙log (2n))
类似地还可以证明:Fibonacci 查找在失败情况下的平均比较次数不超过:λ∙log2 (n + 1) = O (λ∙logn)
其中
λ = 1 + 1/Φ^2 = (2 + Φ)/(1 + Φ) = 3 - Φ = 1.382
Φ = ( 5 + 1) / 2 = 1.618
我们依然采用数学归纳法。作为归纳基,这一命题对长度为 1 的向量显然。以下如图所示,设向量长度为 n = fib (k) - 1,考查 Fibonacci 查找的第一步迭代。
.png) 此时,左侧子向量共计 fib (k - 1)种失败情况,由归纳假设,其平均比较长度不超过:1 + λ∙log_2 (fib (k - 1)) 右侧子向量共计 fib (k - 2)种失败情况,其平均比较长度不超过:2 + λ∙log_2 (fib (k - 2))
此时,左侧子向量共计 fib (k - 1)种失败情况,由归纳假设,其平均比较长度不超过:1 + λ∙log_2 (fib (k - 1)) 右侧子向量共计 fib (k - 2)种失败情况,其平均比较长度不超过:2 + λ∙log_2 (fib (k - 2))
综合所有失败情况,平均查找长度不超过: [fib (k-1)∙(1 + λ∙log2fib (k-1)) + fib (k-2)∙(2 + λ∙log2fib (k-2))] / fib (k) = [(fib (k) + fib (k-2)) + λ∙(fib (k-1)∙log2fib (k-1) + fib (k-2)∙log2fib (k-2))] / fib (k) ~ [λ∙fib (k) + λ∙fib (k)∙(log2fib (k) - 1)] / fib (k) = λ∙log2fib (k)
由上可见,就失败情况而言,尽管两种查找算法的渐进时间复杂度均为 O (logn),但常系数却又一定的差异——Fibonacci 查找的λ = 1.382,较之二分查找的 1.5 更小。
2-21 指数查找 expSearch
描述:设 A[0, n)为一个非降的正整数向量。试设计并实现算法 expSearch (int x),对于任意给定的正整数 x ⇐ A[n - 1],在该向量中找出一个元素 A[k],使得 A[k] ⇐ x ⇐ A[min (n - 1, k^2)]。若有多个满足返一条件的 k,只需返回其中任何一个,但查找时间不得超过 O (log (logk))。
我们令 k 从 1 开始不断递增(A[k]亦相应地非降变化),直至 A[k]首次超过查找目标 x。当然,这里不能采用顺序的逐一递增(k = k + 1)模式:k = 1, 2, 3, 4, 5, 6…
显然,在抵达 A[k] ⇐ x ⇐ A[k + 1]之前,必然已经花费了 O (k)时间。可见,为尽快抵达目标位置,必须加大各试探位置的间距。然而类似地,采用一般的递增模式仍不足够,比如加倍的递增(k = 2 * k)模式:k = 1, 2, 4, 8, 16, 32, … 因为在抵达 A[k] ⇐ x ⇐ A[2k]之前,如此必然已经花费了 O (logk)时间。
为进一步加大各次试探位置的间距,可以采用指数递增(k = k * k)模式:k = 1, 2, 4, 16, 256, 65536, … 如此,在抵达 A[k] ⇐ x ⇐ A[k^2]之前,仅需试探的步数为:
2-22 马鞍查找——二维向量查找
题目:设 A[0, n)[0, n)为整数矩阵(即二维向量),A[0][0] = 0 且任何一行(列)都严格递增。
- ==试设计一个算法,对于任一整数 x >= 0,在 O (r + s + logn)时间内,从该矩阵中找出并报告所有值为 x 的元素(的位置),其中 A[0][r](A[s][0])为第 0 行(列)中不大于 x 的最大者。==
saddleback( int A[n][n], int x ) {
int i = 0; //不变性:有效查找范围始终为左上角的子矩形A[i, n)[0, j]
int j = binSearch(A[0][], x); //借助二分查找,在O(logn)时间内,从A的第0行中找到不大于x的最大者
while ( i < n && -1 < j ) { //以下,反复根据A[i][j]与x的比较结果,不断收缩查找范围A[i, n)[0, j)
if ( A[i][j] < x ) i++; //矩形区域的底边上移
else if ( x < A[i][j] ) j--; //矩形区域的右边左移
else { report( A[i][j] ); i++; j--; } //报告当前命中元素,矩形区域的底边上移、右边左移
}
}
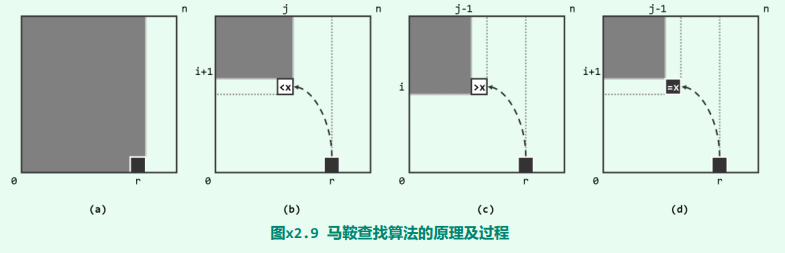 该算法的原理及过程,如图所示。若将待查找矩阵 A 视作二维矩形区域,则在算法的每一次迭代中,搜索的范围始终可精简为该矩形左上角的某一子矩形(以阴影示意)。当然,该子矩形在初始情况下即为矩阵对应的整个区域。
该算法的原理及过程,如图所示。若将待查找矩阵 A 视作二维矩形区域,则在算法的每一次迭代中,搜索的范围始终可精简为该矩形左上角的某一子矩形(以阴影示意)。当然,该子矩形在初始情况下即为矩阵对应的整个区域。
算法:
- 首先通过二分查找,花费 O (logn)的时间在首行 A[0][]中确定起始元素 A[0][j = r]。于是如图 (a)所示,根据该矩阵的单调性,查找范围即可收缩至 A[i = 0, n)[0, j = r]。
- 接下来,反复地根据子矩形右下角元素 A[i][j]与目标元素 x 的大小关系,不断收缩子矩形。
- 既然该矩阵在两个维度均具有单调性,故若 A[i][j] < x,则如图 (b)所示,意味着当前子矩形的底边可以向上收缩一行;
- 若 x < A[i][j],则如图 (c)所示,意味着当前子矩形的右边可以向左收缩一列;
- 而倘若 A[i][j] = x,则如图 (d)所示,不仅意味着找到了一个新的命中元素,而且当前子矩形的底边和右边可以同时收缩。
总而言之无论如何,每经过一次迭代,搜索的范围都可有效地收缩。由此可见,该算法也采用了减而治之(decrease-and-conquer)的策略。为估计这一过程所需进行的迭代次数,我们不妨考查观察量:k = j - i。
- 开始迭代之前,设二分查找返回值为 j = r < n,则当时应有:k = j - i = r - 0 < n
- 此后每经过一次迭代,或者 j 减一,或者 i 加一,或者二者同时如此变化。总而言之,无论如何观察量 k 都至少减一。
- 另一方面根据循环条件,最后一次迭代中必然有 i = s 和 0 ⇐ j ,即:k = j - i >= 0 - s > - n
- 由此可见,这个过程中的迭代次数不超过:r + s < 2n
请注意,单调性在此扮演了重要的角色。实际上,如果将矩阵理解为某一地区,将其中各单元的数值视作对应位置的高度,则该地区的地形将类似于马鞍的形状,该算法也因此得名。
从这一视角来看,所有命中的元素应该就是输入指定高度 x 所对应的一条等高线。于是,上述查找过程,则等效于从某一端的起点出发,逐点遍历该等高线。因为元素数值的严格单调性,该等高线与每一行、每一列至多相交于一个单元。这些单元也就是算法需要遍历并检查的单元,若等高线的起点和终点分别为 A[0][r]和 A[s][0],则其包含的单元应不超过 r + s 个。这一结 论,与前面的分析殊途同归。
- 若 A 的各行(列)只是非减(而不是严格递增),原算法需做何调整?复杂度有何变化? 如果带查询矩阵的严格单调性不能保证,则在 A[i][j] = x 的情况下不能继续有效地收缩查找范围。实际上在此种条件下,命中的元素可能多达 Ω(n^2 )个,故仅在上述算法的基础上做修补,已很难保证整体的效率。 为此,不妨改用其它策略,比如采用第 8 章的 kd-树结构或四叉树等数据结构及相应的算法。
2-23 判断分支深入的代价严重不对称的查找
描述:在某些特殊场合,沿前、后两个方向深入的代价并不对称,甚至其中之一只允许常数次。比如,在仅能使用直尺的情况下,可通过反复实验,用鸡蛋刚能摔碎的下落高度(比如精确到毫米)来度量蛋壳的硬度。尽管可以假定在破裂之前蛋壳的硬度保持不变,但毕竟破裂是不可逆的。故若仅有一枚鸡蛋,则我们不得不从 0 开始,以 1 毫米为单位逐步增加下落的高度。若蛋壳的硬度不超过 n 毫米,则需要进行 O (n)次实验。就效率而言,等价于退化到无序向量的顺序查找。
- 若拥有两枚鸡蛋(假定它们硬度完全相同),所需实验可减少到多少次?试给出对应的算法; 不妨以 √n 为间距,将区间[1, n]均匀地划分为 √n 个区间。于是,借助第一枚鸡蛋,即可在 O ( √n )时间内确定其硬度值所属的区间。接下来,再利用第二枚鸡蛋,花费 O (√n)时间在此区间之内精确地确定其硬度值。两步合计,共需花费 O (2∙√n) = O (√n)时间。
为什么是以√n 为间距?
因为是两枚鸡蛋。之所以以√n 为间距划分区间,是为了最小化所需的实验次数。关键在于平衡了两个方面的考虑:
- 区间划分的精度:如果我们划分的区间太大,每次实验时,可能会浪费掉很多高度范围,从而需要更多次的实验才能精确确定摔碎的高度。相反,如果区间划分得太细,每次实验需要检测的高度范围会很小,但实验次数会增加。
- 鸡蛋的数量:我们只有两枚鸡蛋,因此需要谨慎地选择区间划分来最小化实验次数。
以√n 为间距划分区间的好处在于,它平衡了上述两个方面的考虑。每次实验都能够确定鸡蛋的摔碎高度所在的区间,而不会浪费太多实验次数。这样,总的实验次数被最小化,时间复杂度为 O (√n)。
- 如果拥有三枚鸡蛋呢? 仿照上述思路,以 n^(1/3) 为间距,将区间[1, n]均匀地划分为 n^(1/3)个区间(宽度各为 n^(2/3);然后,再将每个区间继续均匀地细分为 n^(1/3)个子区间(宽度各为 n^(1/3))。
类似地,借助第一枚鸡蛋,在 O (n^(1/3))时间内将查找范围缩减至 n^(2/3);接下来,再利用第二枚鸡蛋,在 O (n^(1/3))时间内将查找范围缩减至 n^(1/3);最后,利用第三枚鸡蛋,花费 O (n^(1/3))时间在此区间之内精确地确定硬度值。
综合以上三步,总共耗时不过: O (3∙n^(1/3)) = O (n^(1/3))
- 推广到 d 个鸡蛋。 将以上方法推广,也就是对区间[1, n]逐层细分。每深入一层,都将当前层的每个子区间均匀地细分为 n^(1/d)个更小的子区间。累计共分为 d 层。
查找也是逐层进行,不断深入:每花费 O (n^(1/d))时间,查找范围的宽度都收缩至此前的 n^(1/d)。纵观整个查找过程,共计 d 次复杂度为 O (n^(1/d))顺序查找,累计耗时不过:O (d∙n^(1/d)) = O (n^(1/d))
需特别留意的是,为实现子区间的分层细分,只需根据输入参数 d 确定规则,并不需要进行实质性的计算,因此这部分时间无需考虑。
2-24-c 插值查找搜索区间与复杂度分析
背景:在实际应用中,有序向量内元素不仅单调排列,而且往往服从某种概率分布。若能利用这一性质,则可以更快地完成查询。 以查阅英文字典为例,单词”Data”应大致位于前 1/5 和 1/4 之间,而”Structure”则应大致位于后 1/5 和 1/4 之间。对元素的分布规律掌握得越准确,这种加速效果也就越加可观。
- 试证明:对此类向量,每经一次插值和比较,待搜索区间的宽度大致以平方根的速度递减; 设查找的目标为 Y。该算法通过不断迭代逐步逼近最终位置,故不妨考查其中第 j 步迭代 ,j = 1, 2, …。 若此步迭代对应于子区间 ,区间宽度 ,则按照上述估计公式,接受比较的元素的秩为:, 其中,
这里的 ,既可看作 Y 在区间 内的相对位置,同时也是均匀分布于 之内的每一随机变量取值不大于 Y 的概率。将 中不大于 Y 的元素数目记作 。既然该区间内的 个元素相互独立,故 应该就是它们取值不大于 Y 的概率总和。更准确地, 可视作一个符合二项式分布的随机变量,于是 的 期望值为 ,方差为 。 再来考察查找目标 Y,将其在整个区间中的秩记作 K* —— 亦即,总共恰有 K* 个元素不大于 Y。 于是,在查找范围业已收缩至 Vj 时, 就是上述符合二项式分布的随机变量。因此若如上将第 j 个接受比较的元素的秩记作 ,则按照该算法的原理, 即是在经过此前各步迭代而进入状态 的情况下,取 K* 的条件期望,亦即:
以下考查前后相邻的两次试探位置的间距,令: 实际上,根据该算法的原理不难看出,以下两个等式中,总是必有其一成立: 相应地,以下两式之一也必然成立: 因此无论如何,总是有: 由以上的定义,还可以导出:
由柯西不等式可知:
D_{j}^{2} &= [E (K^{*}- K_{j} | S_{1}, S_{2}, ..., S_{j}, S_{j+1})]^{2}\\ &\le [E([K^{*}-K_{j}]^{2}|S_{1},S_{2},...,S_{j},S_{j+1})] \end{aligned}根据条件期望值的性质,进一步地有:
由 (1)式,在依次转入 S1, S2, …, Sj 状态后,随机变量 K* 的期望值为 Kj,故上式也就是 K* 在此时的条件方差。于是由 (2)式,继续有:
最后,再次根据柯西不等式,并利用条件期望值的性质,由 (3)式有:
亦即: 这就意味着,从进入第一步迭代之后,随后各步迭代所对应查找自区间的宽度,将以平方根的速度逐次递减。 实际上,第一步迭代所对应的子区间也具有这一性质。
- 试证明:对于长度为 n 的此类向量,插值查找的期望运行时间为 O (loglogn); 针对宽度为 n 的向量做插值查找时,记所需的时间为 T (n)。于是有以下边界条件及递推方程: T (1) = O (1) T (n) = T (√n) + O (1) 令:S (n) = T (2^n) 则有: S (1) = O (1) S (n) = S (n/2) + O (1) 解之可得: S (n) = O (logn) 对应地: T (n) = S (logn) = O (loglogn)
2-26 证明 mergeSort ()时间复杂度
教材中已针对该算法,给出了如下边界条件及递推方程: T (1) = O (1) T (n) = 2xT (n/2) + O (n) 或等价地 T (n)/n = T (n/2)/(n/2) + O (1) 以下若令: S (n) = T (n)/n 则有: S (1) = O (1) S (n) = S (n/2) + O (1) = S (n/4) + O (2) = … = S (n/(2^k)) + O (k) = O (logn) 于是有: T (n) = n∙S (n)= O (nlogn) 归并排序的边界条件及递推方程,在算法复杂度分析中非常典型,以上解法也极具有代表性。
2-27 改进 mergeSort ()适应于大致有序情况
背景:基础版 mergeSotr 在即便输入已是完全(或接近)有序的情况下,仍需 时间。如何改进?
解答:
只需将原算法中的
merge (lo, mi, hi);
一句改为:
if ( _elem[mi - 1] > _elem[mi] ) merge (lo, mi, hi);
实际上按照原算法的流程,在即将调用 merge ()接口对业已各自有序的向量区间[lo, mi)和[mi, hi)做二路归并之前,_elem[mi - 1]即是前一(左侧)区间的末(最靠右)元素,而_elem[mi]则是后一(右侧)区间的首(最靠左)元素。于是,若属于本题所指(业已整体有序)的情况,则必有 _elem[mi - 1] ⇐ _elem[mi];
反之亦然。因此只需加入如上的比较判断,即可在这种情况下省略对 merge ()的调用。不难看出,如此并不会增加该算法的渐进时间复杂度。
2-28 改进 mergeSort ()的动态内存申请成本
背景:事路归并算法 merge (),反复地通过 new 和 delete 操作申请和释放辅助空间。然而实验统计表明,这类操作的实际时间成本,大约是常规运算的 100 倍,故往往成为制约效率提高的瓶颈。如何减少此类操作?进一步优化整体效率?
可以在算法启动时,统一申请一个足够大的缓冲区作为辅助向量 B[],并作为全局变量为所有递归实例公用;归并算法完成之后,再统一释放。 如此可以将动态空间申请的次数降至 O (1),而不再与递归实例的总数 O (n)相关。当然,这样会在一定程度上降低代码的规范性和简洁性,代码调试的难度也会有所增加。
Transclude of 20-Vector#^b86745
2-30 理解 mergeSort ()流程控制逻辑
这里之所以引入了较为复杂的控制逻辑,目的是为了统一对不同情况的处理。尽管如此可使代码在形式上更为简洁,但同时也会在一定程度上造成运行效率的下降。 实际上,二路归并算法过程中可能出现的情况,如图所示无非四种。
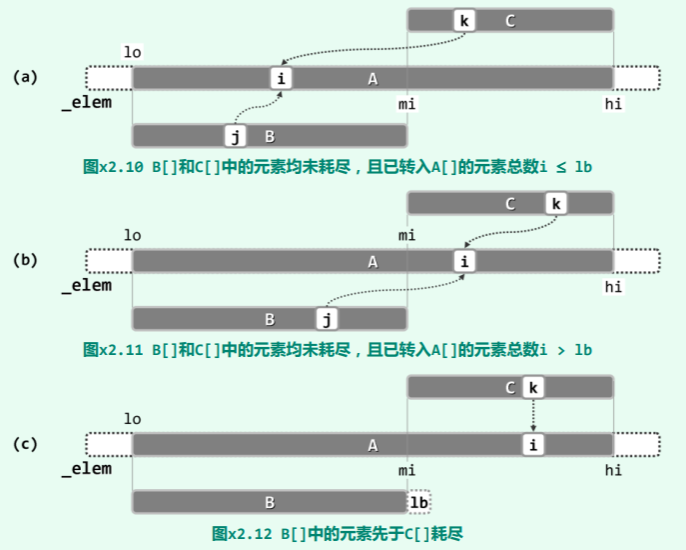
就本章特定的二路归并而言,在情况 (c)下 C[]中剩余元素已不必移动。 此时,为更好地理解循环体内的控制逻辑“lb <= j || (C[k] < B[j])”,不妨假想地设置一个哨兵 B[lb] = +∞。如此,“lb <= j”即可作为特殊情况归入“C[k] < B[j]”。
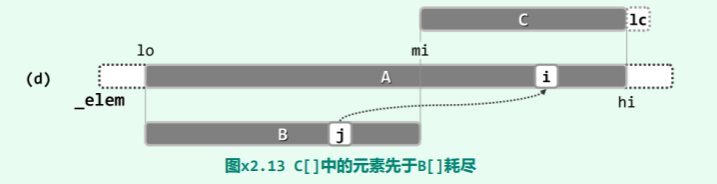 类似地,此时为更好地理解循环体内的控制逻辑“
类似地,此时为更好地理解循环体内的控制逻辑“lc <= k || (B[j] <= C[k])”,不妨假想地设置一个哨兵 C[lc] = +∞,即可将“lc <= k”作为特殊情况归入“B[j] < C[k]”。
2-34 Bitmap 分析
Bitmap 的实现:
class Bitmap {
private:
char* M;
int N; //位图所存放的空间M[],容量为N*sizeof(char)*8比特
protected:
void init ( int n ) { M = new char[N = ( n + 7 ) / 8]; memset ( M, 0, N ); }
public:
Bitmap(int n = 8 ) { init ( n ); } //按指定或默认规模创建位图
Bitmap ( char* file, int n = 8 ) {
//按指定或默认规模,从指定文件中读取位图
init ( n );
FILE* fp = fopen ( file, "r" );
fread ( M, sizeof ( char ), N, fp );
fclose ( fp );
}
~Bitmap(){delete []M;M=NULL;}
void set( int k ){ expand ( k ); M[k >> 3] |= ( 0x80 >> ( k & 0x07 ) ); };
void clear( int k ){ expand ( k ); M[k >> 3] &= ~ ( 0x80 >> ( k & 0x07 ) ); };
bool test( int k ){ expand ( k ); return M[k >> 3] & ( 0x80 >> ( k & 0x07 ) ); }
void dump ( char* file ) {
//将位图整体导出至指定文件,以便对此后的新位图批量初始化
FILE* fp = fopen ( file, "w" );
fwrite ( M, sizeof ( char ), N, fp );
fclose ( fp );
}
char* bits2string ( int n ) {
//将前n位转换为字符串
expand ( n - 1 ); //此时可能被访问的最高位为bitmap[n - 1]
char* s = new char[n + 1]; s[n] = '\0'; //字符串所占空间,由上局调用者负责释放
for ( int i = 0; i < n; i++ ) s[i] = test ( i ) ? '1' : '0';
return s; //返回字符串位置
}
void expand ( int k ) {
//若被访问的Bitmap[k]已出界,则需扩容
if ( k < 8 * N ) return; //仍在界内,无需扩容
int oldN = N; char* oldM = M;
init ( 2 * k ); //与向量类似,加倍策略
memcpy_s ( M, N, oldM, oldN );
delete [] oldM; //原数据转移至新空间
}
};
这里使用了一段动态申请的连续空间 M[],并依次将其中的各比特位与位图集合中的各整数一一对应:若集合中包含整数 k,则该段空间中的第 k 个比特位为 1;否则该比特位为0。 在实现上述一一对应关系时,这里借助了高效的整数移位和位运算。鉴于每个字节通常包含 8 个比特,故通过移位运算:k >> 3 即可确定对应的比特位所属字节的秩;通过逻辑位与运算:k & 0x07 即可确定该比特位在此字节中的位置;通过移位操作:0x80 >> (k & 0x07) 即可得到该比特位在此字节中对应的数值掩码(mask)。
得益于这种简明的对应关系,只需在局部将此字节与上述掩码做逻辑或运算,即可将整数 k 所对应的比特位设置为 1;将此字节与上述掩码做逻辑与运算,即可测试该比特位的状态;将此字节与上述掩码的反码做逻辑位与运算,即可将该比特位设置为0。
这里还提供了一个 dump ()接口,可以将位图整体导出至指定的文件,以便对此后的新位图批量初始化。例如在后面 9.3 节实现高效的散列表结构时,经常需要快速地找出不小于某一整数的最小素数。为此,可以借助 Eratosthenes 算法,事先以位图形式筛选出足够多个候选素数,并通过 dump ()接口将此集合保存至文件。此后在使用散列表时,可一次性地读入该文件,即可按照需要反复地快速确定合适的素数。
与可扩充向量一样,一旦即将发生溢出,这里将调用 expand ()接口扩容。可见,这里采用的也是“加倍”的扩容策略。
根据以上分析,set ()、clear ()和 test ()等接口仅涉及常数次基本运算,故其时间复杂度均为 O (1)。可见,这种实现方式巧妙地发挥了向量之“循秩访问”方式的优势。
此外,相对于四则运算等常规运算,这里所涉及的整数移位和位运算更为高效,因此该数据结构实际的运行效率非常高,该结构也是一种典型的实用数据结构。
这里,位图向量所占的空间线性正比于集合的取值范围——在很多应用中,这一范围就是问题本身的规模,故通常不会导致渐进空间复杂度的增加。
2-34-c Bitmap 通过校验环快速初始化
首先考查简单的情况:位图结构只需提供 test ()和 set ()接口,暂且不需要 clear ()接口:
class Bitmap { //位图Bitmap类:以空间作为补偿,节省初始化时间(仅允许插入,不支持删除)
private:
Rank* F; Rank N; //规模为N的向量F,记录[k]被标记的次序(即其在栈T[]中的秩)
Rank* T; Rank top; //容量为N的栈T,记录被标记各位秩的栈,以及栈顶指针
protected:
inline bool valid ( Rank r ) { return ( 0 <= r ) && ( r < top ); }
public:
Bitmap ( Rank n = 8 ) {
N = n;
F = new Rank[N];
T = new Rank[N];
top = 0;
} //在O(1)时间内隐式地初始化
~Bitmap() { delete [] F; delete [] T; }
// 接口
inline void set ( Rank k ) {
if ( test ( k ) ) return; //忽略已带标记的位
F[k] = top++; T[ F[k] ] = k; //建立校验环
}
inline bool test ( Rank k ) //测试
{ return valid ( F[k] ) && ( k == T[ F[k] ] ); }
};
首先,将原代码中 Bitmap 类的内部空间 M[],代替换为一对向量 F[]和 T[],其中元素均为 Rank 类型,其规模 N 均与(逻辑上的)位图结构 B[]相同。实际上,T[]的工作方式将等效于栈,栈顶由 top 指示,初始 top = 0。
请注意,与原代码相比,这里对两个向量均未做显式的初始化。此后,每当需要调用 set (k)标记新的 B[k]位时,即可将 k 压入栈 T[]中,并将该元素(当前的顶元素)在栈中的秩存入 F[k]。
如此产生的效果是,在 k 与 T[ F[k] ]之间建立了一个校验环路。也就是说,当 F[k]指向栈 T[]中的某个有效元素(valid (F[k]),而且该元素 T[ F[k] ]恰好就等于 k 时,在逻辑上必然等效于 B[k] = true;更重要的是,反之亦然。因此如新代码所示,test (k)接口只需判断以上两个条件是否同时成立。
经如此改造之后,位图结构的一个运转实例如图所示。
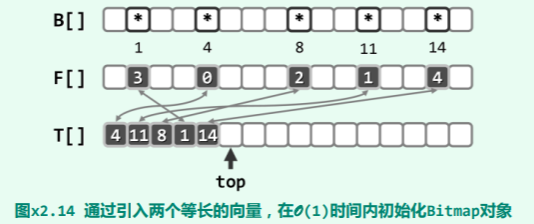 按以上方法,首先在 O (1)时间内对该位图结构做初始化。接下来,依次标记:
B[4], B[11], B[8], B[1], B[14], …
相应地依次压入栈 T[]中的分别是:
T[0] = 4, T[1] = 11, T[2] = 8, T[3] = 1, T[4] = 14, …
向量 F[]中依次存入的秩为:
F[4] = 0, F[11] = 1, F[8] = 2, F[1] = 3, F[14] = 4, …
按以上方法,首先在 O (1)时间内对该位图结构做初始化。接下来,依次标记:
B[4], B[11], B[8], B[1], B[14], …
相应地依次压入栈 T[]中的分别是:
T[0] = 4, T[1] = 11, T[2] = 8, T[3] = 1, T[4] = 14, …
向量 F[]中依次存入的秩为:
F[4] = 0, F[11] = 1, F[8] = 2, F[1] = 3, F[14] = 4, …
不难看出,整个过程中,凡可通过 test (k)逻辑的任何比特位 k,均被标记过;反之亦然。由上同时可见,经如上改造之后的 test ()和 set ()接口,各自仍然仅需 O (1)时间。
当然,以上方法仅限于标记操作 set (),尚不支持清除操作 clear ()。如需兼顾这两个接口,就必须有效地辨别两种无标记的位:从未标记过的,以及曾经一度被标记后来又被清除的。否则,每次为无标记的位增加标记时,若简单地套用目前的 set ()接口为其增加一个校验环,则栈 T[]的规模将线性正比于累积的操作次数,从而无法限制在 N 以内(尽管向量 F[]仍可以),整个结构的空间复杂度也将随着操作次数的增加严格单调的增加。
能够有效区分以上两种无标记位的一种 Bitmap 类,可实现如下:
class Bitmap { //位图Bitmap类:以空间作为补偿,节省初始化时间(允许插入和删除)
private:
Rank* F; Rank N; //规模为N的向量F,记录[k]被标记的次序(即其在栈T[]中的秩)
Rank* T; Rank top; //容量为N的栈T,记录被标记各位秩的栈,以及栈顶指针
protected:
inline bool valid ( Rank r ) { return ( 0 <= r ) && ( r < top ); }
inline bool erased ( Rank k ) {
//判断[k]是否曾被标记过,且后来又被清除
//这里约定:T[ F[k] ] = - 1 - k
return valid ( F[k] ) && ! ( T[ F[k] ] + 1 + k );
}
public:
Bitmap ( Rank n = 8 ) {
N = n;
F = new Rank[N];
T = new Rank[N];
top = 0;
} //在O(1)时间内隐式地初始化
~Bitmap() { delete [] F; delete [] T; }
// 接口
inline void set ( Rank k ) {
if ( test ( k ) ) return; //忽略已带标记的位
if ( !erased ( k ) ) F[k] = top++; //若系初次标记,则创建新校验环
T[ F[k] ] = k; //若系曾经标记后被清除,则恢复原校验环
}
inline void clear ( Rank k ) {
if ( test ( k ) ) T[ F[k] ] = - 1 - k;
} //忽略不带标记的位
inline bool test ( Rank k ) //测试
{ return valid ( F[k] ) && ( k == T[ F[k] ] ); }
};
这里的 clear ()接口并非简单地破坏原校验环,而是将 T[ F[k] ]取负之后再减一。也就是说,可以在与正常校验环不相冲突的前提下,就地继续保留原校验环的信息。基于这一约定,set (k)接口只需调用 erased (k),即可简明地判定[k]究竟属于哪种类型。若系从未标记过的,则按此前的方法新建一个校验环;否则可以直接恢复原先的校验环。
不难再次确认,在扩充后的版本中,各接口依然保持常数的时间复杂度。 最后,考查经改进之后 Bitmap 结构的空间复杂度。尽管表面上看,F[]和 T[]的规模均不超过 N,但这并不意味着整个结构所占空间的总量渐进不变。关键在于,两个向量的元素类型已不再是比特位或逻辑位,而是秩。二者的本质区别在于,前一类元素自身所占空间与整体规模无关,而后者有关。具体来说,这里 Rank 类型的取值必须足以涵盖 Bitmap 的规模;反之,可用 Bitmap 的最大规模也不能超越 Rank 类型的取值范围。比如,若 Rank 为四个字节的整数,则 Bitmap 的规模无法超过 2^31 - 1 = O (10^9),否则 Rank 自身的字宽必须相应加大。所幸,目前的多数应用尚不致超越这个规模,因此仍可近似地认为以上改进版 Bitmap 具有线性的空间复杂度。与之相关的另一问题是,目前的版本仍不支持动态扩容。我们将这一任务留给读者,并请读者对可扩容版 Bitmap 结构的空间、时间复杂度做一分析。
2-39 CBA: 插入两元素到有序序列的比较次数分析
题目:任给 12 个互异的整数,其中 10 个已组织为一个有序序列,现需要插入剩余的两个以完成整体排序。若采用 CBA 式算法,最坏情况下至少需做几次比较?为什么?
解答:对于该问题的任一算法,都可以将其中所有的分支描述为一棵代数判定树。根据排列组合中基本知识,可能的输出数目应为:
前一整数可能的插入位置数 ✖ 后一整数可能的插入位置数 = 11 x 12 = 132 这也是该判定树应含叶节点数目的下限。
于是对应地,判定树的高度应至少是: 这也是此类算法在最坏情况下需做比较操作次数的下限。
2-40 CBA: 找出最大者、次大者
题目:经过至多 (n - 1) + (n - 2) = 2n - 3 次比较,不难从任何存有 n 个整数的向量中找出最大者和次大者。试改进这一算法,使所需的比较次数(即便在最坏情况下)也不超过 。
解答:可以采用分治策略,通过二分递归解决该问题。 算法的具体过程为:将原问题划分为两个子问题,分别对应于向量的前半部分和后半部分。以下,再递归地求解两个子问题(即找出两个子向量各自的最大和次大元素)后,只需两次比较操作,即可得到原问题的解(即确定整个向量中的最大和次大元素)。
实际上,若前一子向量中的最大、次大元素分别为 a1 和 a2,后一子向量中的最大、次大元素分别为 b1 和 b2,则全局的最大元素必然选自 a1 和 b1 之间。不失一般性地,设:a1 = max (a1, b1) 于是全局的次大元素必然选自 a2 和 b1,亦即:max (a2, b1) 若将该算法的运行时间记作 T (n),则根据以上分析,可得边界条件及递推方程如下: T (2) = 1 T (n) = 2 * T (n/2) + 2 若令: S (n) = [T (n) + 2]/n 则有: S (n) = S (n/2) = S (n/4) = … = S (2) = 3/2 故有: T (n) =
比如,若利用以上算法从任意 8 个整数中找出最大、次大元素,则即便是在最坏情况下,也只需 T (8) = 10 次比较操作。
请注意,这里的关键性技巧在于,为合并子问题的解,可以仅需 2 次而不是 3 次比较操作。否则,对应的递推关系应是:T (n) = 2 * T (n/2) + 3 解之即得:T (n) = 2n - 3 仍以 8 个整数为例,在最坏情况下可能需要进行 13 次比较操作。
2-41 基数排序思想
题目:试证明,对任一 nxm 的整数矩阵 M,若首先对每一列分别排序,再继续对每一行分别排序后,其中的各列将依然有序。

解答:因各行的排序独立进行,故只需证明以上命题对任意两行成立。
在已逐列排序的矩阵中,任取两行 A[0, m)和 B[0, m)。如图所示,不妨设 A[]位于 B[]之上方,于是在经逐列排序之后,对所有的 0 ⇐ k < m 均有 A[k] ⇐ B[k]成立。
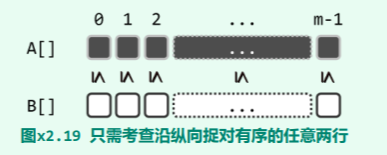
以下将通过两种方法证明,在继而再做逐行排序之后,两行的元素沿纵向依然捉对有序。
证法 A
不妨假想地采用起泡排序算法,同步地对各行实施排序。如此只需证明,该算法每向前迭代一步,A 和 B 中的元素沿纵向依次捉对的有序性,依然继续保持。
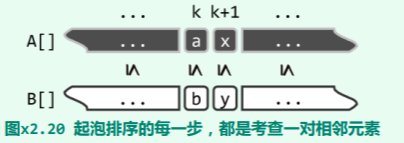 实际上如图 x2.20 所示,在每一步迭代中,该算法都仅逐行考查同一对相邻元素,比如:
A[k] = a 和 A[k + 1] = x
B[k] = b 和 B[k + 1] = y
不妨假设,在此之前已有:
a ⇐ b 和 x ⇐ y
实际上如图 x2.20 所示,在每一步迭代中,该算法都仅逐行考查同一对相邻元素,比如:
A[k] = a 和 A[k + 1] = x
B[k] = b 和 B[k + 1] = y
不妨假设,在此之前已有:
a ⇐ b 和 x ⇐ y
经过此步迭代之后,尽管 a 和 x 可能互换位置,b 和 y 也可能互换位置,但总体而言无非四种情况。其中,对于两行均无交换和同时交换的情况,命题显然成立。
故以下如图 x2.21 所示,只需考查其中只有一行交换的两种情况。
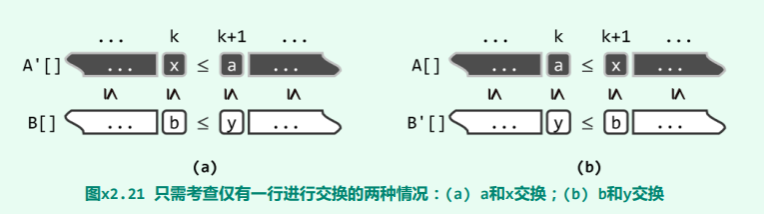 首先,设仅交换 a 和 x。于是如图 x2.21 (a)所示,必有:
A’[k] = x ⇐ A’[k + 1] = a ⇐ b = B[k] = B’[k]
A’[k + 1] = a ⇐ b ⇐ y = B[k + 1] = B’[k + 1]
反之,设仅交换 b 和 y。于是如图 x2.21 (b)所示,必有:
A’[k] = A[k] = a ⇐ A[k + 1] = x ⇐ y = B’[k]
A’[k + 1] = A[k + 1] = x ⇐ y = B’[k] ⇐ b = B’[k + 1]
原命题故此得证。
首先,设仅交换 a 和 x。于是如图 x2.21 (a)所示,必有:
A’[k] = x ⇐ A’[k + 1] = a ⇐ b = B[k] = B’[k]
A’[k + 1] = a ⇐ b ⇐ y = B[k + 1] = B’[k + 1]
反之,设仅交换 b 和 y。于是如图 x2.21 (b)所示,必有:
A’[k] = A[k] = a ⇐ A[k + 1] = x ⇐ y = B’[k]
A’[k + 1] = A[k + 1] = x ⇐ y = B’[k] ⇐ b = B’[k + 1]
原命题故此得证。
需特别强调的是,这里不能采用插入排序或选择排序等其它算法——它们与起泡排序不同,不能保证在排序过程中,各行之间能够严格同步地进行比较,故不能直接支持以上推导过程。
证法 B
反证。假设如图 x2.22 所示,在经逐行排序之后有:
A’[k] = a > b = B’[k]
自然地,A[](A’[])中的元素必然可以划分为两类:小于 a 的,以及不小于 a 的(含 a 本身)。而且,这两类元素互不重复,其总数应恰好为 m。
 然而根据以上假设条件,以下可以导出,这两类元素的总数不少于 m + 1,从而导致悖论。
首先考查并统计小于 a 的元素。为此可以注意到以下事实:
B’[0, k] ⇐ B’[k] = b < a = A’[k]
这就意味着,对于 B’[0, k](亦来自于原 B[])中的每一元素,在原 A[]中都应有一个不大于 b(亦即小于 a)的元素与之对应——也就是说,在 A[]中至少有 k + 1 个元素小于 a。
再来统计不小于 a 的元素。既然 a ⇐ A[k, m),故 A[]中至少有 m - k 个元素不小于 a。
因此,两类元素合计总数至少应为:(k + 1) + (m - k) = m + 1 > m
然而根据以上假设条件,以下可以导出,这两类元素的总数不少于 m + 1,从而导致悖论。
首先考查并统计小于 a 的元素。为此可以注意到以下事实:
B’[0, k] ⇐ B’[k] = b < a = A’[k]
这就意味着,对于 B’[0, k](亦来自于原 B[])中的每一元素,在原 A[]中都应有一个不大于 b(亦即小于 a)的元素与之对应——也就是说,在 A[]中至少有 k + 1 个元素小于 a。
再来统计不小于 a 的元素。既然 a ⇐ A[k, m),故 A[]中至少有 m - k 个元素不小于 a。
因此,两类元素合计总数至少应为:(k + 1) + (m - k) = m + 1 > m