Introduction
数据中心(Data Center)这个事实上在 1960s 就已经存在于各大研究机构或大学中,经过 30 年的算力发展后,在 90 年代中叶最高层(Tier 4)的数据中心终于建立,数据中心的概念也被正式提出。2006 年,Google CEO 提出了云计算的概念,其是一个基于数据服务和架构在“云”服务器上的模型——只要拥有访问权限,你可以正当地通过浏览器等软件随时随地访问“云”。同年,Amazon 引入弹性计算云(Elastic Compute Cloud)的概念,“弹性”的含义指的就是网络服务的计算能力可以动态调整。
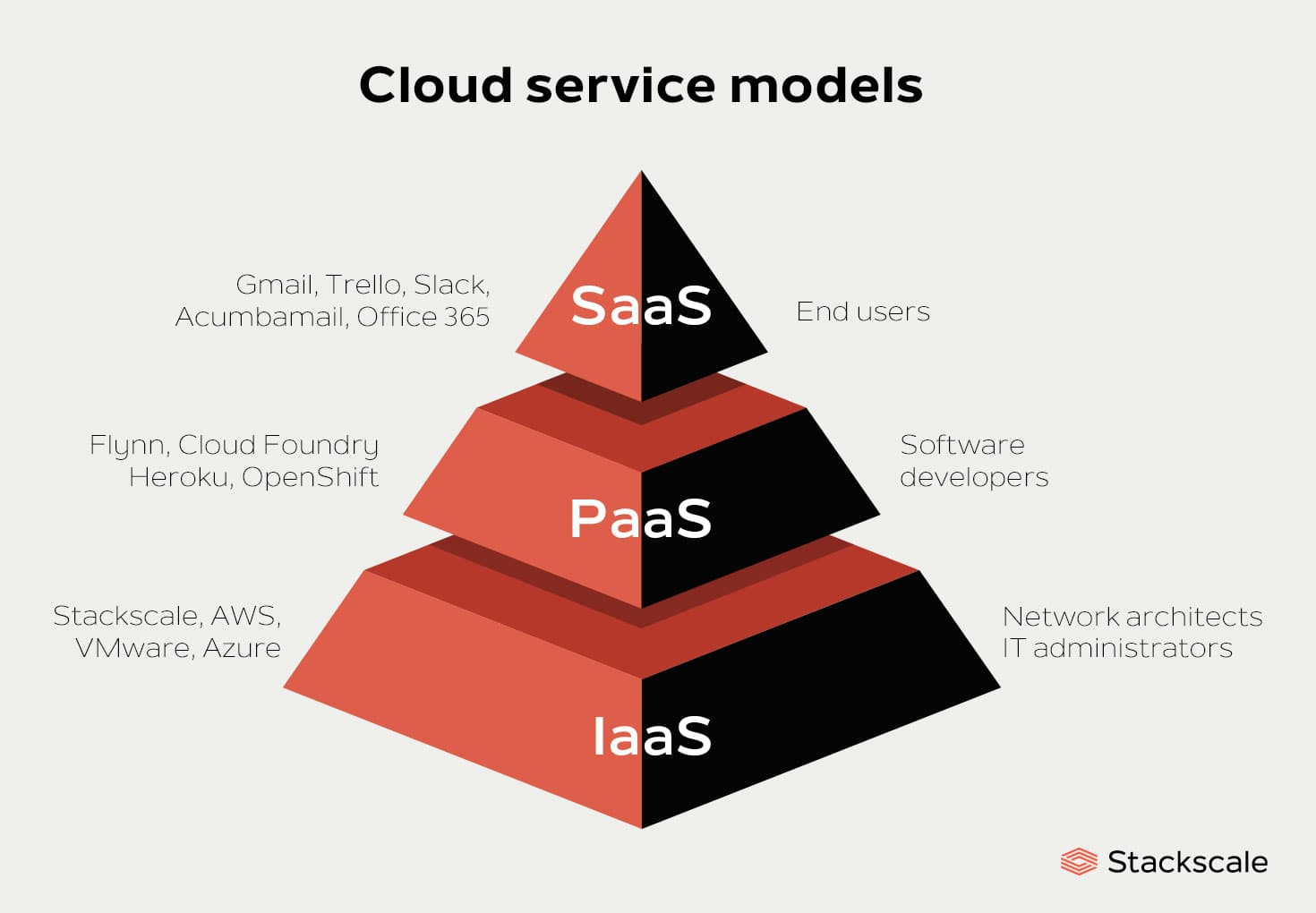
在维基百科中,术语“云计算”涉及提供动态可扩展(dynamically scalable)且经常虚拟化(virtualized)的资源作为互联网上的服务。在计算机科学中,云计算是网络上的分布式计算(distributed computing over a network)的同义词,这意味着能够在许多相互连接的计算机上同时运行程序或应用程序。一般来说,云计算是一个服务模型,租户可以根据服务级协议 (service-level agreements,SLAs) 按需获取资源。依据云计算提供资源的等级,可以划分为:IaaS(Infrastructure-as-a-Service)、PaaS(Platform)、SaaS(Software)、XaaS(Anything,X 可以代表 network, database, communication 等)、DCaaS(Data Center)。
数据中心的电信基础设施标准(即 ANSI/TIA-942-2005) 将数据中心定义为:容纳计算机房间及其支持区域的建筑或建筑的一部分。Google 将数据中心定义为:出于共同的的环境要求和物理安全需求,为便于维护而存放多个服务器和通信设备的建筑。基于这两种定义,计算机房间是数据中心的核心物理环境,它包括进行数据处理的计算设备,其他区域为计算机房间提供支持服务。支持服务主要包括电源系统、冷却系统、照明系统、电缆系统、消防系统和安全系统,以及一定数量的维护者。
数据中心网络(Data Center Network)在计算和通信中起着至关重要的作用。DCN 将数据中心(例如服务器、交换机)的物理组件连接到电缆和光纤组成的特定拓扑中,数据中心的效率和性能在很大程度上取决于 DCN。SIGCOMM 于 2008 年首先在数据中心网络上设置议题,架构设计已成为提高 DCN 效率和性能的一个非常活跃的研究领域。许多新颖的架构已经被设计和介绍,许多新颖的设备已经连接到 DCN ,如无线天线和光开关。
在本文中,我们全面关注 DCN 的特征、硬件和体系结构,包括它们的逻辑拓扑连接和物理组件分类。
Overview of production data centers
Representative production data centers
生产数据中心(production DC)已成为大型 IT 公司不可或缺的一部分。Google 在全球拥有 36 个数据中心,其中 19 个在美国、12 个在欧洲、3 个在亚洲、1 个在俄罗斯、1 个在南美洲,这些数据中心为 Google 的服务(gmail,searching,maps)提供支持。除 Google 外,Microsoft、IBM、Amazon、Dell、Apple 等公司在全球都各自部署了多处数据中心以支持其服务。
Size of production data centers
为了满足逐渐增长的云计算服务的需求,数据中心的规模也在快速增长。数据中心的规模由占地面积和体积比()两个因素决定,通常体积比越小,代表数据中心的利用率越高。
Infrastructure tiers of data centers
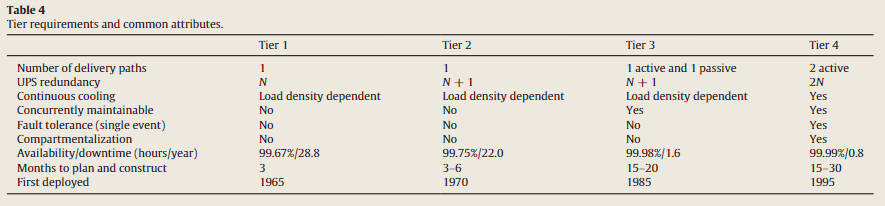
分层(tier classification)对于准备施工预算的数据中心规划者很重要。Uptime Institute 最初在白皮书中定义了四个数据中心基础设施层,名为 Tier Classification Define Site Infrastructure Performance 。
一般来说,数据中心的层级别取决于最弱的基础设施系统(木桶原理)。例如,如果电力系统在第 3 层,而冷却系统在第 2 层,则数据中心在第 2 层。
Modular data centers

传统数据中心坐落于固定的花费数年时间建造的建筑中,但这在规模的可扩展性上不佳。为了使数据中心能够轻松地搬迁、灵活部署以满足商业需求,模块化数据中心(Modular Data Center,MDC)应运而生,MDC 被放置在可运输的容器中,每个容器中的 MDC 包含服务器、存储设备、机架中的网络设备、UPS、冷却系统等等部分。
MDC 的优缺点如下:
- 优点:首先,即插即用(plug-and-play),部署周期短,只要电力、冷却和互联网系统连接后,即可轻松快速地部署以满足客户的要求;其次,它可以在相同大小的空间中,支持比传统数据中心多六倍以上的服务器(40-2000 台服务器);第三,通过使用更好的冷却系统(optimal cooling system),可以实现较低的功耗使用效率(Power Usage Effectiveness)来减小功率成本;最后,它对空间的利用率可以达到 100%,以减少供应商和租户的 CAPEX(Capital Expenditure)和 OPEX(Operational Expenditure)。
- 缺点:首先,服务器兼容性问题——MDC 由不同的供应商生产并配备专有服务器,因此在十数年的使用后难以修缮;其次,它的空间紧凑,难以维护;第三,价格仍然很昂贵;最后,它的部署需要大量的空间和巨型起重机。
MDC 能够提供的服务器数量有限,消耗的电力也有限,因此适合用于小型活动使用。
Green data centers
绿色数据中心指的就是能源高效型数据中心,其会采用节约能源的技术(模块化设计、高级电源单元 advanced power unit)、绿色管理和可再生资源等措施。
PUE1 是能源效率的关键指标, ,理想情况下该值越接近 1 代表能源利用效率越高,但显然很难实现:

这些数据中心为了实现较低的 PUE 都采用了各种各样的高级技术,如 HP 的 EcoPOD 采用了自补偿自适应冷却技术(self-compensating adaptive cooling technology),Facebook 的 Prineville 采用大规模的太阳能阵列作为电源,Yahoo 在纽约的数据中心利用 Buffalos microclimate 为服务器完全使用风冷散热……
Hardware of data center networks
Switch
交换机是 DCN 架构的骨干,如 Fat-tree、VL2 等都是三层交换机的网络架构,这三层交换机分别是核心层交换机(core layer)、聚合层交换机(aggregation layer)、边缘层交换机(edge layer,通常称为 ToR,即 Top-of-Rack)。
一些交换机的样貌与参数如下:

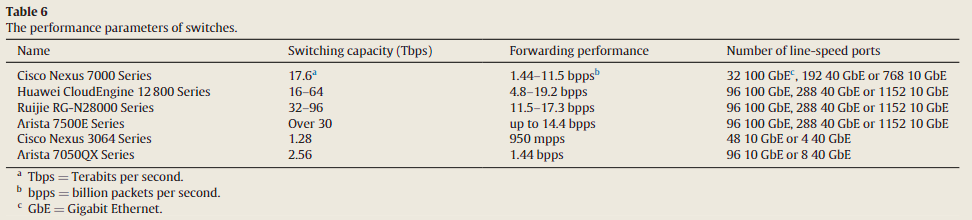
Four kinds of core switches are Cisco Nexus 7000 Series data center switches, Huawei Cloud Engine 12 800 Series switches, Ruijie RG-N 18000 Series switches, and Arista 7500 E Series switches, respectively.
Two kinds of ToR switches are Cisco Nexus 3064 Series and Arista 7050 QX Series switches, respectively
除了传统交换机外,光网络交换机近年来逐渐引起关注。光网络交换机能够实现将光纤中的信号和集成电路中的信号互相转发,不过由于高昂的价格和较大的延迟,DCN 中还没有广泛部署光网络交换机2,不过在高性能计算系统中光模块已经得到广泛应用。
Server
服务器是 DCN 架构核心中的核心,其对数据运行、分析、存储、传输,直接决定了 DCN 的性能好坏。根据服务器的形状,可以大致划分为三类:塔式服务器、机架服务器、刀片服务器:
- Tower servers:最先被应用在数据中心中,其形状更大,性能比常规计算机高若干倍,几台塔式服务器就能满足小规模商用需求,但是由于大体积和灵活性不佳,不适合于云计算数据中心使用。
- Rack servers:现代数据中心的主流选择,机架服务器是放置在机架3上的标准节省空间和可维护的主机。机架服务器在空间节省和管理上比塔式服务器更有优势,但由于密集地放置导致散热困难并且电缆连线高度复杂。
- Blade servers:呈刀片状、成本较低可用性较高、高密度的服务器,专为通信、军事、医疗等应用而设计。其支持热插拔,能够显著降低集群计算时的维护时间,因此近年来颇受研发关注,是下一代的主流服务器。
一些服务器的样貌与参数如下:

Seven kinds of rack servers are ThinkServer RD 630 , Dell PowerEdge R 720 rack server , HP ProLiant DL 385 p Gen 8 Server , IBM System x 3650 M 4 Server , ASUS RS 724 Q-E 7/RS 12 server , FUJITSU Server PRIMERGY RX 600 S 6 , and PowerLeader PR 2012 RS Mass Storage Server , as shown in Fig. 7 (a)–(g), respectively.
Two kinds of blade servers are Huawei Tecal BH 640 V 2 Blade Server and PowerEdge M 820 Blade Server , as shown in Fig. 7 (h); (i), respectively.
Storage
数据中心中两种传统的存储系统是 NAS(network-attached storage)和 SAN(storage area network):
- NAS 是面向文件的存储网络,为异构的计算机系统群组提供存储访问,存储内容直接附加到局域网中。
- SAN 是一种高速的存储网络,其为服务器提供对合并、块级、文件级数据的访问。Fiber Channel、Internet Small Computer System Interface、Fiber Channel over Etehrnet 都支持 SAN 。
一些存储系统的样貌和参数如下:


We introduce five kinds of typical storage systems, which are EMC Symmetrix VMAX 40 K , HP 3 PAR StoreServ 10 000 Storage , Huawei OceanStor N 8500 , NetApp FAS 6200 Series , and IBM System Storage N 7950 T , as shown in Fig. 8 (a)–(e), respectively. In Table 8, we show the main performance parameters, including storage type, storage capacity and cache capacity.
不过随着数据中心里数据量的快速增加以及非结构化数据(视频、照片、音频)增长迅速,传统 NAS/SAN 的中心化管理策略不再适合云计算数据中心,因此为大规模数据提出分布式的、高效的管理策略势在必行:
- 在以太网上 RDMA 技术的帮助下,由普通服务器构建的分布式存储系统,如 Windows Azure Storage、Amazon Simple Storage Service(Amazon S3)等服务已经成为新趋势。
- 另一个新趋势是软件定义存储(software-defined storage,SDS),它包括具有数据服务特性的存储池,可以用这些存储池来满足服务管理结构(service management interface)指定的要求。
Rack
机架用于放置服务器、交换机、存储设备,好的机架应当能够方便设备管理以及解决空间。主要有两类机架,开放式机架和储藏式机架:
- 开放式机架的安装、配置、管理很方便,又可以进一步分为双柱架和四柱架,四柱机架在布线方面更有优势。
- 储藏式机架则更加安全、稳定。
一些机架的样貌和参数如下:


Generally, the height of a rack is between 42 and 48 U (1 U = 1.75 in = 44.45 mm), the width is between 600 and 800 mm, and the depth is between 1100 and 1200 mm. The standard width of devices placed in a rack is 19 in (=482.6 mm).
We pick five kinds of 19 in racks used in DCN’s, which are Emerson Network Power DCF Optimized Racks , Siemon V 600 Data Center Server Cabinet , Black Box Freedom Rack Plus with M 6 Rails , Dell PowerEdge 4820 Rack Enclosure, HP 11642 1075 mm Shock Universal Rack, as shown in Fig. 9 (a)–(e), respectively.
Black Box Freedom Rack is a four-post open rack, and the rest four are all cabinets.
Cable
线缆用于连接数据中心中的其它部件,并在其中传输电信号或光信号。线缆通常根据介质分为铜线或光纤。线缆要根据不同应用场景谨慎选择,这些场景的考量需要包括线缆的使用寿命、数据中心规模、线缆系统的容量、设备供应商的推荐或指定。
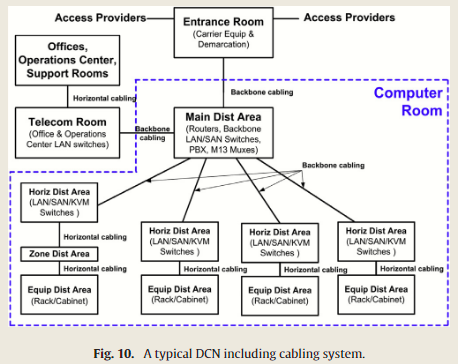
线缆方案主要有两种,主干线缆和水平线缆,经典的 DCN 线缆系统示意图如下:
以太网标准指定的线缆参数如下:

Architectures of data center networks
DCN 实现数据中心中设备之间物理上的连接,这其中涉及的设备数达百万级甚至更多,并且 DCN 还要为这些设备提供充分的带宽以保证云计算服务的质量,以及需要足够灵活、可靠、高密度以确保各种应用程序稳定高效地运行。
传统 DCN 是三层的、多根的树形结构,如下图所示:
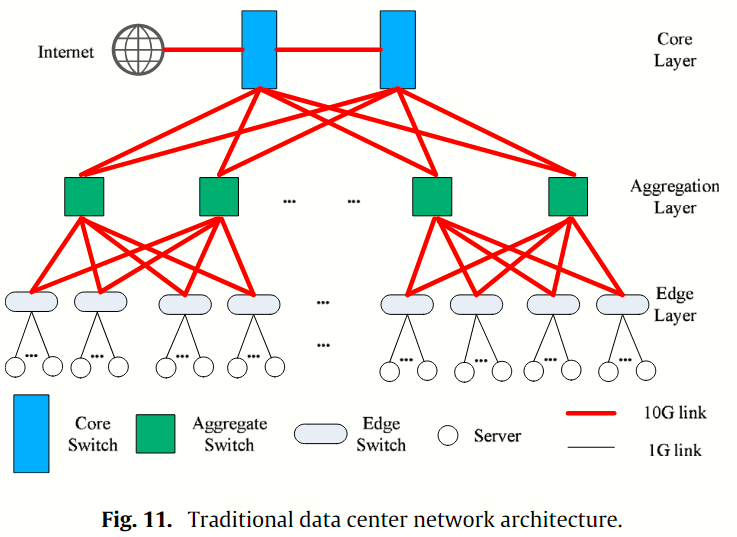 三层指的是核心层、聚合层、边缘层,三层自上而下,包含各自的交换机。核心层的上行链路将数据中心与互联网连接起来;核心层和聚合层的交换机互相连接,逻辑上构建 10 G 速率链路的二分图;边缘层的交换机与服务器直接连接,链路速率 1 G 左右4。
三层指的是核心层、聚合层、边缘层,三层自上而下,包含各自的交换机。核心层的上行链路将数据中心与互联网连接起来;核心层和聚合层的交换机互相连接,逻辑上构建 10 G 速率链路的二分图;边缘层的交换机与服务器直接连接,链路速率 1 G 左右4。
传统 DCN 难以满足云计算服务日益增长的需求,主要有以下劣势:
- Limited bandwidth:当 ToR 交换机的 8 个下行链路只能路由到 1 个上行链路时,服务器的带宽就会变得很有限(这个现象称为 oversubscription5)当工作负载达到峰值时,核心层交换机就会成为链路瓶颈(bottleneck),可能会导致 DCN 的性能骤然下降甚至崩溃。
- Poor flexibility:核心层交换机的端口数决定了多根树形架构的 DCN 能够支持服务器的最大数量。如果实际使用中需要支持更多的服务器,就必须更换对应的交换机,这种增量部署既耗时又昂贵。
- Low utilization:传统 DCN 在第 2 层会划分许多域(domain)来保证安全性和可管理性,但这种设置会导致大量资源碎片化,这并不适用于大规模的云计算场景;另外传统 DCN 还会根据各应用的最大流量来静态分配特定的机器和固定带宽,因此大部分时间里资源处于闲置,利用滤极低。
- Complex cabling:大规模的 DCN 中线缆非常复杂。
- High cost:DCN 的成本可以分为硬件购买的成本和运营时电力成本,尤其是核心层和聚合层交换机通常是企业级的设备,价格昂贵且耗电过高。
为了突破传统 DCN 的限制,不同论文中给出了不同的策略,这些现代 DCN 的架构可以按如下图示总结:
 根据结构特点,这些 DCN 架构可以划分为三类:
根据结构特点,这些 DCN 架构可以划分为三类:
Switch-centric architectures
在以交换机为中心的架构中,交换机承担了 networking 和 routing 的需求,服务器只用于提供计算支持。根据结构特点,以交换机为中心的架构可以分为树状、扁平和非结构化的架构。
Tree-like switch-centric architectures
树形的以交换机为中心的架构中,交换机之间互联以构成一棵多根树,经典的架构有 Fat-tree、VL2、Diamond、Redundant fat-tree、Aspen Trees、F10、 Tree、Facebook 的 four-post、Google 的 Jupiter。
Fat-tree 是经典的三层多根树架构,只由商用交换机(每个端口的速率都是 1 Gbps)构建,能够支持数万台服务器的聚合带宽。Fat-tree 是一种折叠式的 Clos 网络6,设计灵感来自于 86 年的 Fat-tree 论文7。
 一个 k-ary 的 fat-tree 拓扑结构包含 个 k 端口核心层交换机、 个 Pod、 个服务器。每个核心层交换机通过一个端口连接到一个 Pod (核心层交换机的第 个端口连接到第 个 Pod )。每个 Pod 中, 个 k 端口聚合层交换机与 个边缘层交换机互联,构成一个完全二分图。每个 Pod 中第 个聚合层交换机的 个端口都连接到第 个 核心层交换机中。每个边缘层交换机都连接到 个服务器。通过足量的核心层交换机,fat-tree 拓扑可以保证 oversubscription 的比例为 ,从而保证服务器间的非阻塞通信,显著提升 DCN 的性能。
Fat-tree 架构通过两级前缀查找路由表(two-level prefix lookup routing table)实现了均匀分布的流量模式,使得二分带宽很高,流量分布尽可能均匀。那些匹配第一级前缀但不符合任意第二级后缀的传入(incoming)数据包会直接路由到相应的输出端口,而那些符合第一级前缀和第二级后缀的传出(outgoing)数据包先与后缀匹配,再路由到出输出端口。许多生产级 DC 已经采用 Fat-tree 作为数据中心架构而构建。
一个 k-ary 的 fat-tree 拓扑结构包含 个 k 端口核心层交换机、 个 Pod、 个服务器。每个核心层交换机通过一个端口连接到一个 Pod (核心层交换机的第 个端口连接到第 个 Pod )。每个 Pod 中, 个 k 端口聚合层交换机与 个边缘层交换机互联,构成一个完全二分图。每个 Pod 中第 个聚合层交换机的 个端口都连接到第 个 核心层交换机中。每个边缘层交换机都连接到 个服务器。通过足量的核心层交换机,fat-tree 拓扑可以保证 oversubscription 的比例为 ,从而保证服务器间的非阻塞通信,显著提升 DCN 的性能。
Fat-tree 架构通过两级前缀查找路由表(two-level prefix lookup routing table)实现了均匀分布的流量模式,使得二分带宽很高,流量分布尽可能均匀。那些匹配第一级前缀但不符合任意第二级后缀的传入(incoming)数据包会直接路由到相应的输出端口,而那些符合第一级前缀和第二级后缀的传出(outgoing)数据包先与后缀匹配,再路由到出输出端口。许多生产级 DC 已经采用 Fat-tree 作为数据中心架构而构建。
PortLand 是一种规模可扩展、高效、容错的 DCN 第 2 层路由、转发和寻址协议,尤其适用于多根拓扑结构(如 fat-tree)。PortLand 将拥有 100,000 多台服务器的 DCN 视为一个即插即用结构,其中每台服务器都包含多个虚拟机(VM)。逻辑上集中的结构管理器支持地址解析协议(ARP)解析、容错和组播。为实现高效转发、路由选择和虚拟机迁移,为服务器分配了分层伪 MAC(PMAC)地址(每台服务器都有一个唯一地址)。
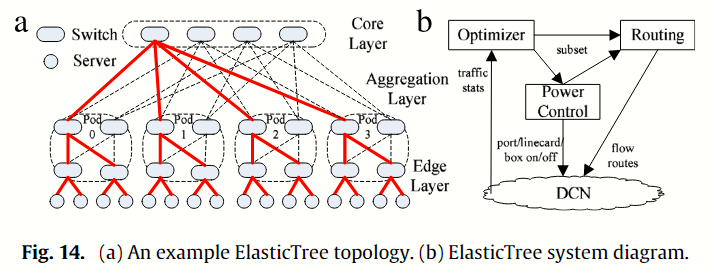
ElasticTree 是一种用于 DCN 的节能系统。DCN 需要能够处理高峰工作负载,但在大多数情况下,其工作负载相对较低,许多网络设备和链路未得到充分利用或处于闲置状态。ElasticTree 通过直接关闭当前不需要的交换机和链路,尽可能缩小网络子网的规模,以适当支持当前的流量模式。简单的 ElasticTree 拓扑如上图 Fig 14 (a) 所示,与 20 个交换机和 48 个链路全部处于活动状态的完整胖树相比,ElasticTree 只开启了 13 个交换机和 28 个链路(用粗实线标出的子树),节省了 38% 的网络功耗。然而,在瞬息万变的网络环境中,简单地开关交换机和链路可能会降低 DCN 的性能和可靠性。图 Fig 14 (b) 中的 ElasticTree 系统由优化器、路由和功率控制模块组成。
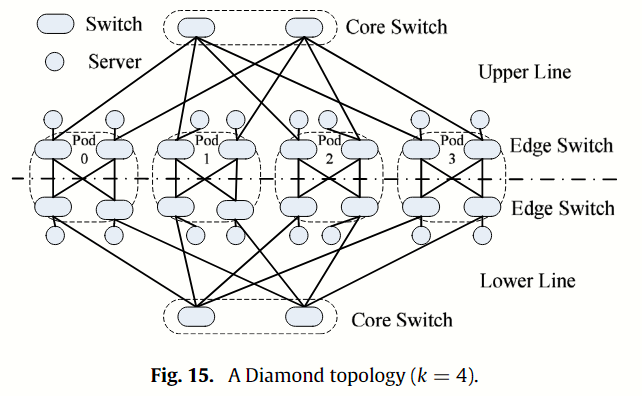
Diamond 是一种改进的 fat-tree 架构,只有核心和边缘两层的 k 端口交换机。如上图 Fig 15 所示,Diamond 网络被一条切割线分为两部分,在每个部分中, 个核心层交换机连接到 个边缘层交换机;在每个 Pod 中,k 个边缘层交换机直接连接到服务器(一个 fat-tree Pod 包含 个聚合层交换机和 个边缘层交换机)。在支持相同数量服务器的情况下,Diamond 的平均路径长度比 fat-tree 减少了 10%。

VL2(虚拟二层网络)也是一种三层折叠式 Clos 网络,由 Greenberg 等人提出,其雏形是 Monsoon 。 与 Fat-tree 不同的是,VL2 将 端口中间交换机、 端口聚合交换机和 ToR 交换机互连起来组成三层的核心网络(core network),以支持 台服务器,如上图 Fig 16 所示。核心网络可视为一个巨大的二层交换机。 个中间交换机与 聚合交换机相互连接,在逻辑上形成一个完整的双向图。每个 ToR 交换机连接 2 个聚合交换机和 20 台服务器。 VL2 还具有 1:1 的 oversubscription 。 VL2 采用大容量链路,布线复杂度低于 fat-tree ,而高层交换机的路由成本则高于胖树。 VL2 采用三层路由框架以实现虚拟的二层网络。它采用 Valiant 负载平衡(VLB)来缓解 DCN 中的负载不平衡,将交换机和服务器视为一个整体资源池,并动态地为服务器分配 IP 地址和工作负载。
GRIN 是对现有 DCN(如 VL2、multihomed topology)的一种简单而经济的改进,它将同一机架上具有空闲端口的服务器连接起来,形成“邻居”,以最大限度地提高每台服务器的带宽。Subways 是另一种将服务器连接到相邻 ToR 交换机的廉价解决方案。它可以减少拥塞,改善负载平衡,提高容错能力。
Redundant fat-tree 降低了无阻塞多路多播 DCN 的成本。 k-redundant fat-tree 意味着每个服务器都有其他 k - 1 个冗余服务器,它们必须与不同的 ToR 交换机连接。通过理论分析,当 fat-tree DCN 为 k-redundant 时,无阻塞组播通信的核心交换机数量的充分条件()可以大大降低。
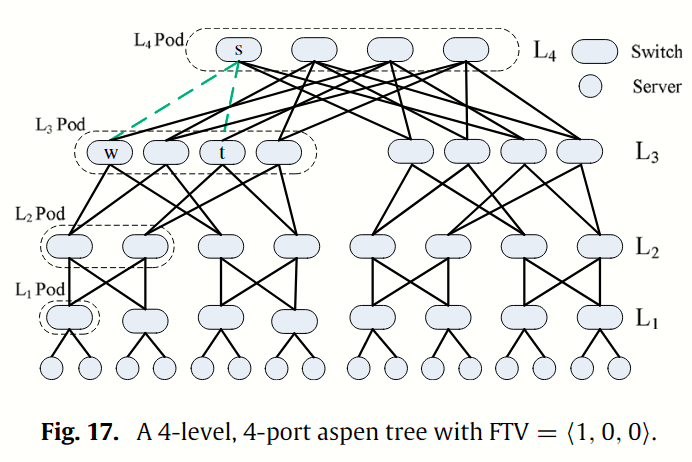
Aspen trees 是一组改进的多根树,用于平衡 DCN 中的容错性、可扩展性和成本。其主要目标是大大减少多根 fat-tree 上发生链路故障时的重新收敛时间。Aspen tree 通过在 fat-tree 的相邻层之间添加冗余链路来实现容错。 n 级 k 端口的 Aspen tree 是一组 n 级修改过的 fat-tree ,由 k 端口交换机和服务器组成,并带有容错向量(Fault Tolerant Vector,FTV)。 第 i 层 Pod(用 表示)指连接到同一组 Pod 的 交换机的最大集合,而一个 Pod 只有一个 交换机。 例如,FTV = ⟨1, 0, 0⟩表示一棵 Aspen tree 在 处有 1 次容错,即 和 交换机之间有 2 个链接。 图 Fig 17 显示了一棵 4 层 4 端口、FTV = ⟨1,0,0⟩ 的 Aspen tree 。当两条虚线中的任何一条链路出现故障时,稳健的路由机制可确保交换机在短时间内将数据包重新路由到其他链路。与相同规模的 fat-tree 相比,由于存在冗余链路,aspen tree 只能支持一半的服务器。如果需要支持相同数量的服务器,则应使用更多的交换机。

F10 是一种用于解决 DCN 故障的容错工程系统,由 AB Fat-Tree、故障转移和负载平衡协议以及故障检测器组成。作为 F10 的核心,AB Fat-Tree 具有许多与 fat-tree 类似的有利特性,但通过引入有限的非对称性,其恢复性能比 fat-tree 好得多。图 18 中的 AB Fat-Tree 有两种类型的子树 pod(称为 A 型和 B 型),它们以两种不同的方式(实线表示 A 型,虚线表示 B 型)连接到父树(核心交换机)。 核心层和聚合层之间的不对称有利于故障恢复。在 AB FatTree 的基础上,设计了一系列故障切换协议,以实现级联和互补。即使出现多个故障,F10 也能几乎瞬间实现本地重路由和负载平衡。仿真结果表明,在网络链路和交换机发生故障后,F10 的 UDP 流量拥塞丢包率不到 PortLand 的 1/7。 MapReduce 追踪评估显示,由于数据包丢失率较低,F10 的应用速度比 PortLand 提高了 30%。
Tree 是一种容错架构,可大大缩短多根树形 DCN 的故障恢复时间。 Tree 只需重新布线少量链路以改善路径冗余,并更改少量交换机配置以进行本地重路由。 Tree 将聚合层或核心层同一 Pod 中的交换机连接成环形,这样可以为某条链路增加即时备份链路,确保发生故障时数据包的转发。 实验结果表明,与 Fat-tree 相比, Tree 可显著缩短故障恢复时间达 78% 。
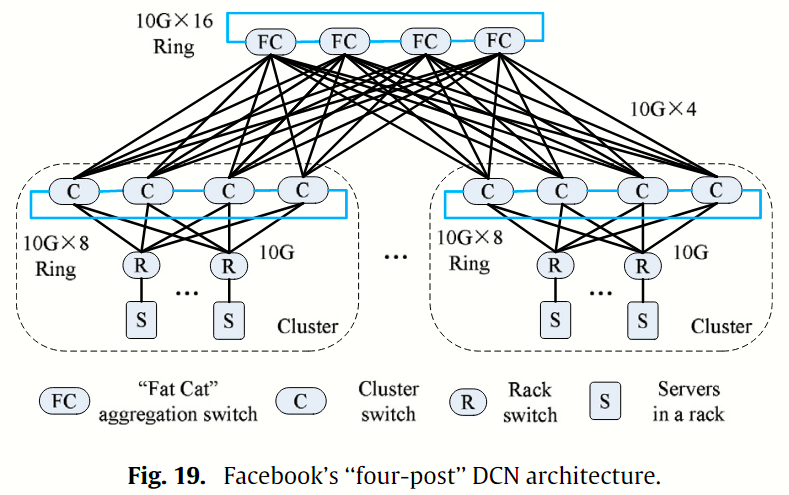
Facebook’s four-post 由 fat-cat 聚合交换机(FC)、集群交换机(C)、机架交换机(R)和机架上的服务器组成,如图 19 所示。 与 Fat-tree 相比,在每个集群中,一个 160 G 保护环(10 G × 16)连接到四个 FC 交换机,一个 80 G 保护环(10 G × 8)连接到四个 C 交换机。four-post 架构通过额外的连接大大消除了网络故障造成的服务中断。FC 交换机层减少了通过群集之间昂贵链路的流量。然而,模块化 C 交换机和 FC 交换机体积庞大、成本高昂,限制了可扩展性,成为潜在瓶颈。Facebook 曾考虑过许多替代架构(如 3D Torus 或 Fat-tree),以解决特定的网络挑战。
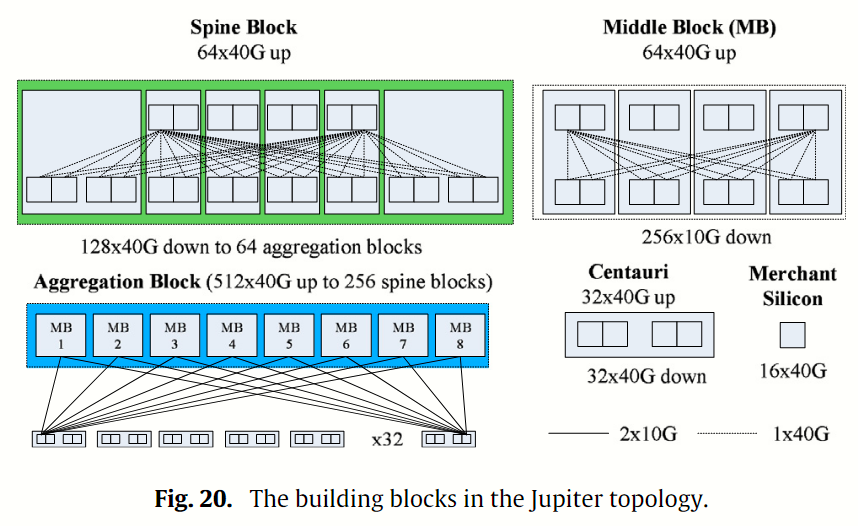
Google’s Jupiter 是基于 Clos 拓扑的第五代 DCN。最新一代的 Jupiter 是一个 40 G 数据中心规模的结构,配备了高密度的 40 G 商用芯片。Jupiter 拓扑的构建模块如图 Fig 20 所示。 一个 Centauri 交换机被用作 ToR 交换机(包括 4 个交换机芯片),四个 Centauri 交换机组成一个用于聚合块的中间块(Middle Block)。 MB 的逻辑拓扑结构是一个两级阻塞网络。每个 ToR 芯片通过 2 × 10 G 链路连接到 8 个 MB,形成一个聚合区块。 六个 Centauris 交换机用于构建一个 spine 区块。 Jupiter 中有 256 个 spine 区块和 64 个聚合区块。
MatrixDCN 是一种矩阵形的非树形的以交换机为中心的非阻塞网络架构,包含行交换机(row)、列交换机(column)、接入交换机(access)。行交换机和列交换机将每一行和每一列的接入交换机连接起来,形成一个类似矩阵的结构。例如,一个 2 × 3 MatrixDCN 有 2 个行交换机、3 个交换机和 6 个接入交换机。MatrixDCN 易于扩展或缩小规模,交换机/服务器比例与胖树类似。
Hypernetworks 是一种使用固定端口数的交换机构建以交换机为中心的大型 DCN 的新方法,它首先根据超图理论和横向块设计理论构建大型直接超图(direct hypergraphs),然后将直接超图转换为间接超图8。与 Fat-tree 相比,Hypernetworks 可以在使用相同数量交换机的情况下支持更多服务器。
Discussion about Tree-like switch-centric architectures
以交换机为中心的树状架构具有均衡的流量负载、强大的容错能力和多路由功能。 然而,它们仍有几个缺点:
- 首先,三层或更多层交换机增加了布线的复杂性,限制了网络的可扩展性。
- 其次,与高级交换机相比,商品交换机的安全性和容错性较差。
- 第三,当突发流量导致 DCN 中断时,集中式管理器会严重影响 DCN 性能。
Flat switch-centric architecture
扁平化架构的思路是将三层或更多的交换机层压缩到两层甚至一层,从而简化 DCN 的管理和维护成本。经典的扁平化架构有:FBFLY、FlatNet、C-FBFLY。
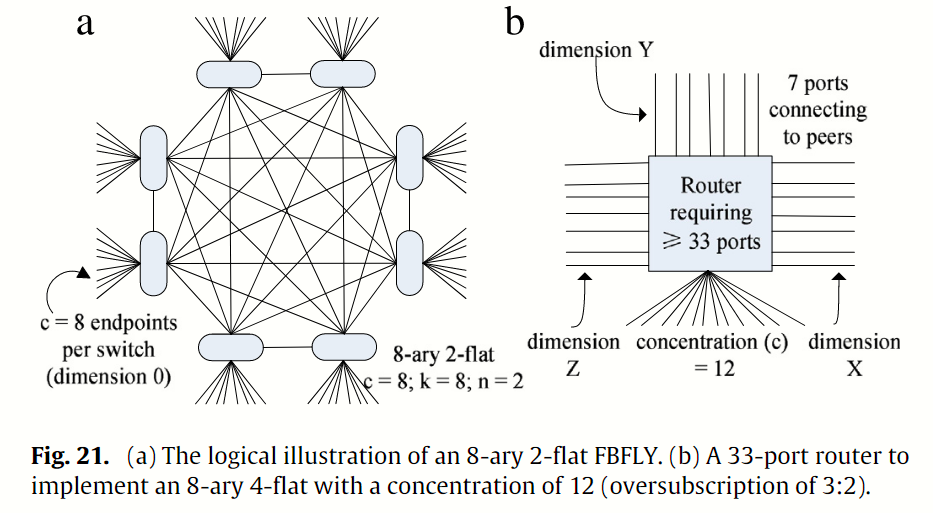
FBFLY Abts 等人[1]利用 k-ary n-flat FBFLY 建立了能量成正比的 DCN,其灵感来自扁平化蝴蝶(基于高梯度交换机的网络)[98,99,4]。 能量成正比意味着 DCN 的功耗与流量成正比。 例如,在不同的流量情况下,最大带宽为 40 Gbps 的链路可以失谐为 20、10、5 或 2.5 Gbps。 FBFLY 是一种多维有向网络,类似于环状网络(k-ary n-cube)。 每个高分交换机(大于 64 个端口)将服务器和其他交换机互连起来,形成一个广义的多维超立方体。 k-ary n-flat FBFLY 由 k-ary n-fly 传统蝴蝶衍生而来。 在这两个网络中,支持服务器的数量都是 N = kn。 在传统蝶形网络中,交换机的数量为 nkn-1,端口号为 2 k;在 FBFLY 中,交换机的数量为 N k = kn-1,端口号为 n (k - 1) + 1。 FBFLY 的尺寸为 n - 1。 图 21 (a) 显示了一个具有 15 个端口开关的 8 层 2 扁平 FBFLY。 虽然 FBFLY 类似于广义超立方体,但它的可扩展性更强,而且可以通过适度提高超量订购水平来节省能量。 图 21 (b) 显示了一个 33 端口交换机,在 8 层 2 扁平 FBFLY 中的集中度(服务器数量,用 c 表示)为 12(从 8 变为 12)。 FBFLY 的大小可从原来的 84 = 4096 扩展到 ckn-1 = 12 × 8 (4-1) = 6144。 超额认购的比例从 1:1 (8:7) 适度提高到 3:2 (12:7)。
Server-centric architectures
Enhanced architectures
Architecture comparision and discussion
The facility considerations for data centers
术语 网络关键物理基础设施 (NCPI,Network-Critical Physical Infrastructure)指的就是保障数据中心可靠地、稳定地运行的基础设施。
Cisco 指出以下七种基础设施:
- Power.
- Cooling.
- Cabling.
- Racks and physical structure.
- Management.
- Grounding.
- Physical Security and fire protection.
Intel 指出
Footnotes
-
Power Usage Effectiveness ↩
-
有待考察,因为这是 2016 年的论文,其信息可能已经 out of update. ↩
-
机架的排列类似抽屉,可以容纳数台服务器。 ↩
-
这些链路速率来自 Fig 11 所示的拓扑,其是 Cisco 2004 年的文献,因此与当前实际的速率已有较大偏差。 ↩
-
Oversubscription is the ratio between the servers’ bandwidth to the total uplink bandwidth at the access layer. ↩
-
Leiserson, CharlesE. “Fat-Trees: Universal Networks for Hardware-Efficient Supercomputing.” International Conference on Parallel Processing, International Conference on Parallel Processing, Jan. 1985. ↩
-
Qu, Guannan, et al. “Switch-Centric Data Center Network Structures Based on Hypergraphs and Combinatorial Block Designs.” IEEE Transactions on Parallel and Distributed Systems, vol. 26, no. 4, Apr. 2015, pp. 1154–64, https://doi.org/10.1109/tpds.2014.2318697. ↩