Data Structures
This chapter describes some things you’ve learned about already in more detail, and adds some new things as well.
More on Lists
The list data type has some more methods. Here are all of the methods of list objects:
list.append(x):
- Add an item to the end of the list.
- Equivalent to
a[len(a):] = [x].
list.extend(iterable):
- Extend the list by appending all the items from the iterable.
- 通过追加可迭代数据结构中的所有项目来扩展列表
- Equivalent to
a[len(a):] = iterable.
list.insert(i, x):
- Insert an item at a given position. The first argument is the index of the element before which to insert,
- 第一个参数 i 是要插入元素在列表中的位置索引
- so
a.insert(0, x)inserts at the front of the list, anda.insert(len(a), x)is equivalent toa.append(x).
list.remove(x):
- Remove the first item from the list whose value is equal to x .
- It raises a
ValueErrorif there is no such item.
list.pop([i]):
- Remove the item at the given position in the list, and return it.
- If no index is specified,
a.pop()removes and returns the last item in the list. - It raises an
IndexErrorif the list is empty or the index is outside the list range.
list.clear():
- Remove all items from the list. Equivalent to
del a[:].
list.index(x[, start[, end]]):
- Return zero-based index in the list of the first item whose value is equal to x. Raises a
ValueErrorif there is no such item. - 返回一个从零开始的索引,在列表中该索引处的项的值与 x 相等,如果没有这样的项,就报错
ValueError。 - The optional arguments start and end are interpreted as in the slice notation and are used to limit the search to a particular subsequence of the list. The returned index is computed relative to the beginning of the full sequence rather than the start argument.
- 可选参数 start 和 end 是用于限制列表中项的查找范围,但是返回的索引与整个序列有关,而不是基于 start 参数的偏移量。
list.count(x):
- Return the number of times x appears in the list.
- 计数 x 在列表中出现了多少次。
list.sort(*, key=None, reverse=False):
- Sort the items of the list in place (the arguments can be used for sort customization, see
sorted()for their explanation).
list.reverse():
- Reverse the elements of the list in place.
list.copy():
- Return a shallow copy of the list.
- Equivalent to
a[:].
An example that uses most of the list methods:
>>> fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
>>> fruits.count('apple')
2
>>> fruits.count('tangerine')
0
>>> fruits.index('banana')
3
>>> fruits.index('banana', 4) # Find next banana starting at position 4
6
>>> fruits.reverse()
>>> fruits
['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange']
>>> fruits.append('grape')
>>> fruits
['banana', 'apple', 'kiwi', 'banana', 'pear', 'apple', 'orange', 'grape']
>>> fruits.sort()
>>> fruits
['apple', 'apple', 'banana', 'banana', 'grape', 'kiwi', 'orange', 'pear']
>>> fruits.pop()
'pear'You might have noticed that methods like insert, remove or sort that only modify the list have no return value printed — they return the default None.1 This is a design principle for all mutable data structures in Python.
insert,remove,sort这样只修改列表的方法实际上也有返回值,默认是None,这是 Python 中所有可变数据结构的设计原则。
Another thing you might notice is that not all data can be sorted or compared. For instance, [None, 'hello', 10] doesn’t sort because integers can’t be compared to strings and None can’t be compared to other types. Also, there are some types that don’t have a defined ordering relation. For example, 3+4j < 5+7j isn’t a valid comparison.
不同类型的值一般不能直接进行排序(因为涉及到比大小的问题),这里需要注意,
None不可以与任何类型的值进行(直接)比较。 还有一些类型不支持直接比较,如复数3+4j与5+7j,这需要手动重载运算符来实现。
Using Lists as Stacks
The list methods make it very easy to use a list as a stack, where the last element added is the first element retrieved (“last-in, first-out”). To add an item to the top of the stack, use append(). To retrieve an item from the top of the stack, use pop() without an explicit index. For example:
用 list 维护栈非常方便,
append()当作压栈,pop()默认弹出最后一个元素,是为弹栈,栈顶是列表末尾,栈底是列表开头。
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]Using Lists as Queues
It is also possible to use a list as a queue, where the first element added is the first element retrieved (“first-in, first-out”); however, lists are not efficient for this purpose. While appends and pops from the end of list are fast, doing inserts or pops from the beginning of a list is slow (because all of the other elements have to be shifted by one).
同样 list 也可以构造(双端)队列,尽管这并不高效——因为在队列末尾插队和出队的操作很快速,大致 的时间,但是在队列开头处插队和出队却很慢,大致 时间,因为所有其它元素都要逐个向后移动。
To implement a queue, use collections.deque which was designed to have fast appends and pops from both ends. For example:
因此更推荐使用
collections.deque中的队列,它专门为双端的插入与删除操作进行了优化:
>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])List Comprehensions
List comprehensions2 provide a concise way to create lists. Common applications are to make new lists where each element is the result of some operations applied to each member of another sequence or iterable, or to create a subsequence of those elements that satisfy a certain condition.
列表推导式提供了精简的方法来创建列表,例如:
- 创建新的列表,其中每个元素都是对另一个序列或可迭代数据结构的每个成员进行某些操作的结果,
- 或者创建满足特定条件的元素的子序列。
For example, assume we want to create a list of squares, like:
>>> squares = []
>>> for x in range(10):
... squares.append(x**2)
...
>>> squares
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]Note that this creates (or overwrites) a variable named x that still exists after the loop completes. We can calculate the list of squares without any side effects using:
需要注意的是,上面代码中会创建一个
x变量,并且即使循环结束,x也仍然存在。下面利用 lambda 表达式可以避免类似副作用:
squares = list(map(lambda x: x**2, range(10)))or, equivalently:
squares = [x**2 for x in range(10)]which is more concise and readable.
A list comprehension consists of brackets containing an expression followed by a for clause, then zero or more for or if clauses. The result will be a new list resulting from evaluating the expression in the context of the for and if clauses which follow it. For example, this listcomp combines the elements of two lists if they are not equal:
列表推导式包裹在
[]之中,其中首先是计算列表项的表达式,紧跟着是若干for或if语句用于处理列表的每个项。例如下面的语句就是返回两个列表中两两不同元素的组合:
>>> [(x, y) for x in [1,2,3] for y in [3,1,4] if x != y]
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]and it’s equivalent to:
>>> combs = []
>>> for x in [1,2,3]:
... for y in [3,1,4]:
... if x != y:
... combs.append ((x, y))
...
>>> combs
[(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]Note how the order of the for and if statements is the same in both these snippets.
If the expression is a tuple (e.g. the (x, y) in the previous example), it must be parenthesized. :
要注意,如果表达式是一个 tuple ,那么需要包裹在
()之中,否则会报错SyntaxError。
>>> vec = [-4, -2, 0, 2, 4]
>>> # create a new list with the values doubled
>>> [x*2 for x in vec]
[-8, -4, 0, 4, 8]
>>> # filter the list to exclude negative numbers
>>> [x for x in vec if x >= 0]
[0, 2, 4]
>>> # apply a function to all the elements
>>> [abs (x) for x in vec]
[4, 2, 0, 2, 4]
>>> # call a method on each element
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip () for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
>>> # create a list of 2-tuples like (number, square)
>>> [(x, x**2) for x in range (6)]
[(0, 0), (1, 1), (2, 4), (3, 9), (4, 16), (5, 25)]
>>> # the tuple must be parenthesized, otherwise an error is raised
>>> [x, x**2 for x in range (6)]
File "<stdin>", line 1
[x, x**2 for x in range (6)]
^^^^^^^
SyntaxError: did you forget parentheses around the comprehension target?
>>> # flatten a list using a listcomp with two 'for'
>>> vec = [[1,2,3], [4,5,6], [7,8,9]]
>>> [num for elem in vec for num in elem]
[1, 2, 3, 4, 5, 6, 7, 8, 9]List comprehensions can contain complex expressions and nested functions:
>>> from math import pi
>>> [str (round (pi, i)) for i in range (1, 6)]
['3.1', '3.14', '3.142', '3.1416', '3.14159']Nested List Comprehensions
The initial expression in a list comprehension can be any arbitrary expression, including another list comprehension.
列表推导式中的初始表达式可以是任意的表达式,包括另一个列表推导式。
Consider the following example of a 3x4 matrix implemented as a list of 3 lists of length 4:
>>> matrix = [
... [1, 2, 3, 4],
... [5, 6, 7, 8],
... [9, 10, 11, 12],
... ]The following list comprehension will transpose3 rows and columns:
>>> [[row[i] for row in matrix] for i in range (4)]
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]As we saw in the previous section, the inner list comprehension is evaluated in the context of the for that follows it, so this example is equivalent to:
>>> transposed = []
>>> for i in range (4):
... transposed.append ([row[i] for row in matrix])
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]which, in turn, is the same as:
>>> transposed = []
>>> for i in range (4):
... # the following 3 lines implement the nested listcomp
... transposed_row = []
... for row in matrix:
... transposed_row.append (row[i])
... transposed.append (transposed_row)
...
>>> transposed
[[1, 5, 9], [2, 6, 10], [3, 7, 11], [4, 8, 12]]In the real world, you should prefer built-in functions to complex flow statements. The zip() function would do a great job for this use case:
>>> list (zip (*matrix))
[(1, 5, 9), (2, 6, 10), (3, 7, 11), (4, 8, 12)]See Unpacking Argument Lists for details on the asterisk4 in this line.
The del statement
There is a way to remove an item from a list given its index instead of its value: the del statement. This differs from the pop() method which returns a value. The del statement can also be used to remove slices from a list or clear the entire list (which we did earlier by assignment of an empty list to the slice). For example:
del语句可以用于删除列表中的项——前提需要知道该项的索引。- 与
pop()方法不同,pop()会返回项的值,但del语句不会。del语句还可以用于删除列表中的片段或清除整个列表。
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]del can also be used to delete entire variables:
>>> del aReferencing the name a hereafter is an error (at least until another value is assigned to it). We’ll find other uses for del later.
del语句删除列表a之后,就不可以再引用它,否则会报错,除非新的a被赋值。
Tuples and Sequences
We saw that lists and strings have many common properties, such as indexing and slicing operations. They are two examples of sequence data types (see Sequence Types — list, tuple, range). Since Python is an evolving language, other sequence data types may be added. There is also another standard sequence data type: the tuple.
列表和字符串有许多共同属性,例如索引和切分操作。它们是序列数据类型的两个例子(其余序列数据类型还有:list、tuple、range)。由于 Python 是一种不断发展的语言,因此可能会添加其他序列数据类型。
A tuple consists of a number of values separated by commas, for instance:
tuple 通过
,分隔各项,并且可以嵌套,不可修改。但如果 tuple 嵌套了可修改的其他类型,如 list ,那么对该项是可以修改的:
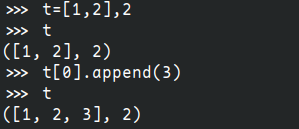
>>> t = 12345, 54321, 'hello!'
>>> t[0]
12345
>>> t
(12345, 54321, 'hello!')
>>> # Tuples may be nested:
... u = t, (1, 2, 3, 4, 5)
>>> u
((12345, 54321, 'hello!'), (1, 2, 3, 4, 5))
>>> # Tuples are immutable:
... t[0] = 88888
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> # but they can contain mutable objects:
... v = ([1, 2, 3], [3, 2, 1])
>>> v
([1, 2, 3], [3, 2, 1])As you see, on output tuples are always enclosed in parentheses, so that nested tuples are interpreted correctly; they may be input with or without surrounding parentheses, although often parentheses are necessary anyway (if the tuple is part of a larger expression). It is not possible to assign to the individual items of a tuple, however it is possible to create tuples which contain mutable objects, such as lists.
Though tuples may seem similar to lists, they are often used in different situations and for different purposes. Tuples are immutable, and usually contain a heterogeneous5 sequence of elements that are accessed via unpacking (see later in this section) or indexing (or even by attribute in the case of namedtuples). Lists are mutable, and their elements are usually homogeneous6 and are accessed by iterating over the list.
虽然元组看起来与列表相似,但它们通常用于不同的情况和不同的目的:
- 元组是不可变的,通常包含一个异构的元素序列,可通过拆包(见本节后面)或索引(甚至在
namedtuples的情况下通过属性)进行访问- 列表是可变的,其元素通常是同质的(约定而非语法强求),通过对列表进行迭代来访问
A special problem is the construction of tuples containing 0 or 1 items: the syntax has some extra quirks to accommodate these. Empty tuples are constructed by an empty pair of parentheses; a tuple with one item is constructed by following a value with a comma (it is not sufficient to enclose a single value in parentheses). Ugly, but effective. For example:
tuple 的独特风格在于包含 0 个或 1 个元素时:
- 空的 tuple 有一对空括号构成
- 包含 1 个元素的 tuple 由一个 元素的值+逗号
,构成(仅仅用括号包含一个值是不够的)虽然不够美观,但调用起来非常方便。
>>> empty = ()
>>> singleton = 'hello', # <-- note trailing comma
>>> len (empty)
0
>>> len (singleton)
1
>>> singleton
('hello',)The statement t = 12345, 54321, 'hello!' is an example of tuple packing: the values 12345, 54321 and 'hello!' are packed together in a tuple. The reverse operation is also possible:
t = 12345, 54321, 'hello!'会创建一个包含三个元素的 tuple ,这个过程称为 tuple packing(元组打包);式子反过来就是 tuple unpacking(元组解包),将元组中的各项拆分到对应的变量中
>>> x, y, z = tThis is called, appropriately enough, sequence unpacking and works for any sequence on the right-hand side. Sequence unpacking requires that there are as many variables on the left side of the equals sign as there are elements in the sequence. Note that multiple assignment is really just a combination of tuple packing and sequence unpacking.
其它序列也可以进行类似的解包,不过要注意赋值符号左端的变量数量要与右端的序列的项数相等。
Sets
Python also includes a data type for sets. A set is an unordered collection with no duplicate elements. Basic uses include membership testing and eliminating duplicate entries. Set objects also support mathematical operations like union, intersection, difference, and symmetric difference.
Python 中的集合是无序的、不含重复元素的数据结构。其最基本的用途包括成员测试和消除重复条目。集合对象还支持数学运算,如并集、交集、差集和对称差集。
Curly braces or the set() function can be used to create sets. Note: to create an empty set you have to use set(), not {}; the latter creates an empty dictionary, a data structure that we discuss in the next section.
大括号
{}或set()函数可用于创建集合。注意:要创建空集,必须使用
set(),而不是{};后者会创建一个空字典,我们将在下一节讨论这种数据结构。
Here is a brief demonstration:
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print (basket) # show that duplicates have been removed
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # fast membership testing
True
>>> 'crabgrass' in basket
False
>>> # Demonstrate set operations on unique letters from two words
...
>>> a = set ('abracadabra')
>>> b = set ('alacazam')
>>> a # unique letters in a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # letters in a but not in b
{'r', 'd', 'b'}
>>> a | b # letters in a or b or both
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # letters in both a and b
{'a', 'c'}
>>> a ^ b # letters in a or b but not both
{'r', 'd', 'b', 'm', 'z', 'l'}集合的运算操作如上:
- 集合求差:
setA - setB- 求并集:
setA | setB- 求交集:
setA & setB- 求一者有而另一者没有:
setA ^ setB,也就是对各项求异或。
Similarly to List Comprehensions , set comprehensions are also supported:
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}Dictionaries
Another useful data type built into Python is the dictionary (see Mapping Types — dict). Dictionaries are sometimes found in other languages as “associative memories” or “associative arrays”. Unlike sequences, which are indexed by a range of numbers, dictionaries are indexed by keys, which can be any immutable type; strings and numbers can always be keys. Tuples can be used as keys if they contain only strings, numbers, or tuples; if a tuple contains any mutable object either directly or indirectly, it cannot be used as a key. You can’t use lists as keys, since lists can be modified in place using index assignments, slice assignments, or methods like append() and extend().
词典也是 Python 内置的非常有用的数据类型,在其他语言中有时也称为“关联式数组/存储器”。与序列通过一定范围内的数字进行索引不同,词典通过键来索引——键可以是任何不可变的类型:
- 字符串、数字都可以作为键
- tuple 如果只包含字符串、数字、其它 tuple 也可以作为键,但如果包含 list 等可变类型的元素,就不可以作为键
- list 是可变类型,因此不能作为键
It is best to think of a dictionary as a set of key: value pairs, with the requirement that the keys are unique (within one dictionary). A pair of braces creates an empty dictionary: {}. Placing a comma-separated list of key: value pairs within the braces adds initial key: value pairs to the dictionary; this is also the way dictionaries are written on output.
更准确的理解是将词典看作
key: value键值对的集合,并且此集合中key应当是互斥唯一的。使用空大括号
{}可以创建一个空的词典,词典中利用逗号,分隔键值对,词典输出时也是这样的规则。
The main operations on a dictionary are storing a value with some key and extracting the value given the key. It is also possible to delete a key: value pair with del. If you store using a key that is already in use, the old value associated with that key is forgotten. It is an error to extract a value using a non-existent key.
词典的主要用法就是用某个键存储一个值,以及提取给定键所对应的值 。
- 可以使用
del语句删除键值对。- 如果要存储的键值对已经存在(即
key已在词典中),那么key对应的值就会被覆盖。- 如果要提取不存在的 key 所对应的值,就会报错。
Performing list(d) on a dictionary returns a list of all the keys used in the dictionary, in insertion order (if you want it sorted, just use sorted(d) instead). To check whether a single key is in the dictionary, use the in keyword.
使用
list(d)可以按插入顺序返回词典中所使用的所有键的列表(如果要排序,只需使用sorted(d)) 要检查特定的键是否存在,使用in运算符。
Here is a small example using a dictionary:
>>> tel = {'jack': 4098, 'sape': 4139}
>>> tel['guido'] = 4127
>>> tel
{'jack': 4098, 'sape': 4139, 'guido': 4127}
>>> tel['jack']
4098
>>> del tel['sape']
>>> tel['irv'] = 4127
>>> tel
{'jack': 4098, 'guido': 4127, 'irv': 4127}
>>> list (tel)
['jack', 'guido', 'irv']
>>> sorted (tel)
['guido', 'irv', 'jack']
>>> 'guido' in tel
True
>>> 'jack' not in tel
FalseThe dict constructor builds dictionaries directly from sequences of key-value pairs:
dict()构造函数可以从 key-value 的序列中直接创建词典。
>>> dict ([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'guido': 4127, 'jack': 4098}In addition, dict comprehensions can be used to create dictionaries from arbitrary key and value expressions:
同样词典也有推导式。
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}When the keys are simple strings, it is sometimes easier to specify pairs using keyword arguments:
如果键是字符串(没有特殊符号),就可以使用对
dict()构造函数传递关键字参数的方法来构造词典。
>>> dict (sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'guido': 4127, 'jack': 4098}Looping Techniques
When looping through dictionaries, the key and corresponding value can be retrieved at the same time using the items() method.
在词典中循环时,可以使用
items()方法同时检索键及其对应的值。
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print (k, v)
...
gallahad the pure
robin the braveWhen looping through a sequence, the position index and corresponding value can be retrieved at the same time using the enumerate() function.
类似地,在序列中同时遍历位置索引和对应的值,则使用
enumerate()方法。
>>> for i, v in enumerate (['tic', 'tac', 'toe']):
... print (i, v)
...
0 tic
1 tac
2 toeTo loop over two or more sequences at the same time, the entries can be paired with the zip() function.
如果想要同时遍历两个及以上的序列,则应使用
zip()将条目成组地包裹起来。
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip (questions, answers):
... print ('What is your {0}? It is {1}.'.format (q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.To loop over a sequence in reverse, first specify the sequence in a forward direction and then call the reversed() function.
若要逆序地遍历序列,则在
reversed()函数的参数中传递正向序列。
>>> for i in reversed (range (1, 10, 2)):
... print (i)
...
9
7
5
3
1To loop over a sequence in sorted order, use the sorted() function which returns a new sorted list while leaving the source unaltered.
在排序后的序列中循环,如果使用
sorted()函数,则会返回一个排序后的新序列,而原来的序列没有改变。
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for i in sorted (basket):
... print (i)
...
apple
apple
banana
orange
orange
pearUsing set() on a sequence eliminates duplicate elements. The use of sorted() in combination with set() over a sequence is an idiomatic way to loop over unique elements of the sequence in sorted order.
在序列上使用
set()函数可以去除其中的重复元素,同时还可以结合sorted()函数,达成按顺序遍历序列中所有种类元素的效果。
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted (set (basket)):
... print (f)
...
apple
banana
orange
pearIt is sometimes tempting to change a list while you are looping over it; however, it is often simpler and safer to create a new list instead. :
更推荐在循环 list 等序列并对其中元素做出改动时,创建一个新的 list,而不是在原 list 操作。
>>> import math
>>> raw_data = [56.2, float ('NaN'), 51.7, 55.3, 52.5, float ('NaN'), 47.8]
>>> filtered_data = []
>>> for value in raw_data:
... if not math.isnan (value):
... filtered_data.append (value)
...
>>> filtered_data
[56.2, 51.7, 55.3, 52.5, 47.8]More on Conditions
The conditions used in while and if statements can contain any operators, not just comparisons.
The comparison operators in and not in are membership tests that determine whether a value is in (or not in) a container. The operators is and is not compare whether two objects are really the same object. All comparison operators have the same priority, which is lower than that of all numerical operators.
比较运算符
in和not in是用于确定某个值是否在容其中的测试; 运算符is和is not用于比较两个对象是否是同一对象; 所有比较运算符的优先级相同,低于所有的数值运算符。
Comparisons can be chained. For example, a < b == c tests whether a is less than b and moreover b equals c.
表达式中的比较是链式的,比如
a < b == c的含义就是测试 a 是否小于 b,而且 b 是否等于 c 。
Comparisons may be combined using the Boolean operators and and or, and the outcome of a comparison (or of any other Boolean expression) may be negated with not. These have lower priorities than comparison operators; between them, not has the highest priority and or the lowest, so that A and not B or C is equivalent to (A and (not B)) or C. As always, parentheses can be used to express the desired composition.
- 比较运算符可以使用布尔运算符
and和or进行组合,比较运算的结果(或任何其他布尔表达式的结果)可以使用not进行否定。- 布尔运算符的优先级低于比较运算符;在它们之间,
not的优先级最高,而or的优先级最低,因此A and not B or C等同于(A and (not B)) or C。
The Boolean operators and and or are so-called short-circuit operators: their arguments are evaluated from left to right, and evaluation stops as soon as the outcome is determined. For example, if A and C are true but B is false, A and B and C does not evaluate the expression C. When used as a general value and not as a Boolean, the return value of a short-circuit operator is the last evaluated argument.
布尔运算符
and和or也可以用作短路:因为它们的计算都是从左到右,因此如果运算到某一步时整个表达式的结果已经确定,那么就会在此处停止。短路运算符用作一般值而非布尔值时,其返回值是最后一个已求值参数。
It is possible to assign the result of a comparison or other Boolean expression to a variable. For example, :
>>> string 1, string 2, string 3 = '', 'Trondheim', 'Hammer Dance'
>>> non_null = string 1 or string 2 or string 3
>>> non_null
'Trondheim'Note that in Python, unlike C, assignment inside expressions must be done explicitly with the walrus operator :=. This avoids a common class of problems encountered in C programs: typing = in an expression when == was intended.
要注意 Python 与 C 的不同:在表达式内的赋值必须显式地使用
:=7 。这避免了一系列 C 程序中常见的问题,比如在表达式中输入=,而本来要用==进行判断而非赋值。
Comparing Sequences and Other Types
Sequence objects typically may be compared to other objects with the same sequence type. The comparison uses lexicographical8 ordering: first the first two items are compared, and if they differ this determines the outcome of the comparison; if they are equal, the next two items are compared, and so on, until either sequence is exhausted. If two items to be compared are themselves sequences of the same type, the lexicographical comparison is carried out recursively. If all items of two sequences compare equal, the sequences are considered equal. If one sequence is an initial sub-sequence9 of the other, the shorter sequence is the smaller (lesser) one. Lexicographical ordering for strings uses the Unicode code point number to order individual characters. Some examples of comparisons between sequences of the same type:
序列对象通常可以与具有相同序列类型的其他对象进行比较。 比较使用词典序:
- 首先比较前两个项目,如果它们不同,则决定比较结果;
- 如果它们相等,则比较下两个项目,依此类推,直到任何一个序列被穷尽。
如果要比较的两个项目本身是同一类型的序列,则会递归地进行词典序比较。如果两个序列的所有项目比较结果相同,则认为这两个序列相同。如果一个序列是另一个序列的初始子序列,则较短的序列是较小(较少)的序列。
字符串的词典序使用 Unicode 码点号对单个字符进行排序。
(1, 2, 3) < (1, 2, 4)
[1, 2, 3] < [1, 2, 4]
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)Note that comparing objects of different types with < or > is legal provided that the objects have appropriate comparison methods. For example, mixed numeric types are compared according to their numeric value, so 0 equals 0.0, etc. Otherwise, rather than providing an arbitrary ordering, the interpreter will raise a TypeError exception.
请注意,使用
<或>比较不同类型的对象是合法的,前提是这些对象具有适当的(通常还需要用户自定义的)比较方法。例如,混合数值类型根据其数值进行比较,因此 0 等于 0.0 等。否则,解释器将引发TypeError异常,而不是提供一个武断地排序结果。