单元测试概述
软件工程开发经验不足的人,可能会选择先把代码都拼接起来,再进行测试。但实际上,这样相当于将编码中可能出现的错误都累积到最后阶段再做检查,这必然会导致错误数量庞大、难以定位、难以纠错的问题:
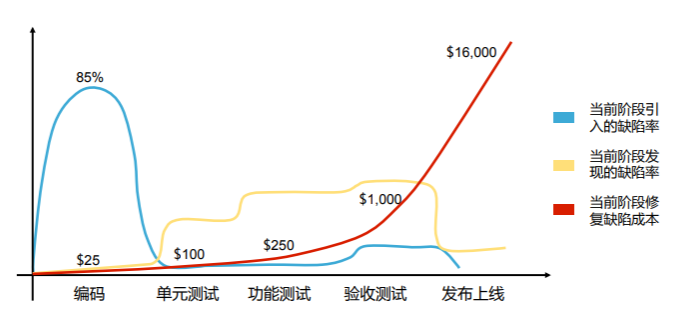
因此我们需要单元测试——单元是构造软件系统的基础,只有使每个单元得到足够的测试,系统的质量才能有可靠的保证,即单元测试是构筑产品质量的基石。
单元测试(Unit Testing)是对软件中的最小可测试单元进行检查和验证,这是程序员对自己代码质量负责的基本承诺。代码质量通常与单元测试质量呈正相关。
单元测试内容
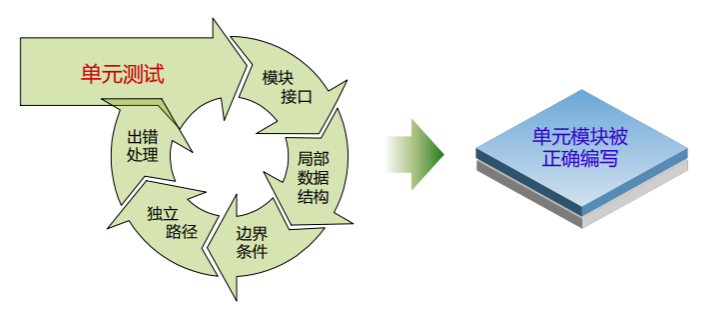
单元测试应当检查如下项目:
- 模块接口:对通过所有被测模块的数据流进行测试
- 局部数据结构:检查模块中的数据结构是否正确定义和使用
- 边界条件:检查数据流或控制流中条件或 数据处于边界时的出错可能性
- 独立路径:检查由于计算错误、判定错误、控制流错误导致的程序错误
- 出错处理:检查可能引发错误处理的路径以及进行错误处理的路径
单元测试原则
- 快速的:单元测试应能快速运行,如果运行缓慢,就不会愿意频繁运行它
- 独立的:单元测试应相互独立,某个测试不应为下一个测试设定条件。当测试相互依赖时,一个没通过就会导致一连串的失败,难以定位问题
- 可重复的:单元测试应该是可以重复执行的,并且结果是可以重现的
- 自我验证的:单元测试应该有布尔输出,无论是通过或失败,不应该查看日志文件或手工对比不同的文本文件来确认测试是否通过
- 及时的:及时编写单元测试代码,应恰好在开发实际的单元代码之前
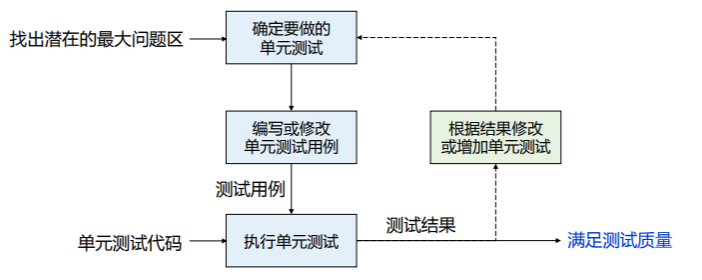
单元测试过程
单元测试质量评估
对单元测试质量的评价,通常有两个方面:
- 测试通过率:指在测试过程中执行通过的测试用例所占比例,单元测试通常要求测试用例通过率达到 100%
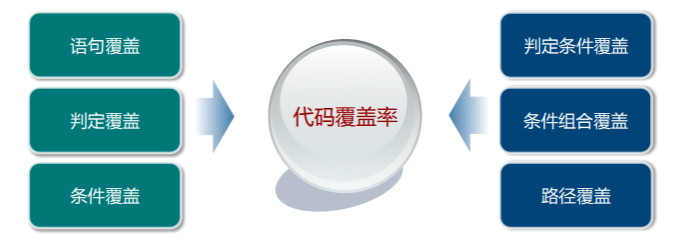
- 测试覆盖率:是用来度量测试完整性的一个手段,通过覆盖率数据,可以了解测试是否充分以及弱点在哪里。代码覆盖率是单元测试的一个衡量标准,但也不能一味地去追求覆盖率,一般在 70%~80% 就足够
单元测试方法
单元测试的方法从是否真是地执行代码来看,有两类:
- 静态测试:通过人工分析或程序正确性证明的方式来确认程序正确性
- 动态测试:通过动态分析和程序测试等方法来检查和确认程序是否有问题
从是否理解代码真实含义的角度来看,也可以分为两类:
- 黑盒测试(black box testing):
- 又称功能测试,它将测试对象看做一个黑盒子,完全不考虑程序内部的逻辑结构和内部特性,只依据程序的需求规格说明书,检查程序的功能是否符合它的功能说明
- 白盒测试(white box testing):
- 又称结构测试,它把测试对象看做一个透明的盒子,允许测试人员利用程序内部的逻辑结构及有关信息,设计或选择测试用例,对程序所有逻辑路径进行测试
另外,我们对特定模块进行测试时,它往往并非独立存在,而是有可能调用了下层模块、也有可能被上层模块调用,此时对被测模块进行单元测试的整体结构为:
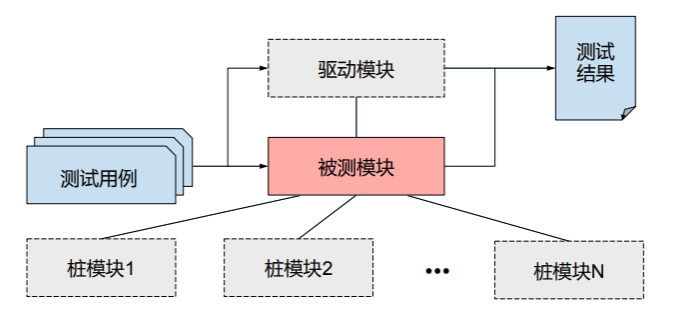
- 形象地,下层模块被称为桩模块、上层模块称为驱动模块;
xUnit
实现单元测试有不同的工具:
统称为 xUnit 。但是 xUnit 并非万能的:
- xUnit 通常适用于以下场景的测试:
- 单个函数、一个类或者几个功能相关类的测试
- 尤其适用于纯函数测试或者接口级别的测试
- xUnit 无法适用于复杂场景的测试:
- 被测对象依赖关系复杂,甚至无法简单创建出这个对象
- 对于一些失败场景的测试
- 被测对象中涉及多线程合作
- 被测对象通过消息与外界交互的场景
Mock 测试
Mock 的本义是“愚弄、欺骗、模拟的”,在单元测试中即是在测试过程中对于某些不容易构造或者不容易获取的对象,用一个虚拟的对象来代替以便完成测试的方法。
在这些场景中,真实对象往往具有以下特点:
- 真实对象具有不可确定的行为(产生不可预测的结果)
- 真实对象很难被创建(如具体的 Web 容器)
- 真实对象的某些行为很难触发(如网络错误)
- 真实情况令程序的运行速度很慢
- 真实对象有用户界面
- 测试需要询问真实对象它是如何被调用的
- 真实对象实际上并不存在
例如以下这个案例:
- 支付宝接龙红包通过猜金额的小游戏方式,实现朋友之间的互动并领取春节红包。这种情况应如何测试?

- 这就要用到 Mock 对象,即针对接口进行编程,被测试的代码通过接口来引用对象,再使用 Mock 对象模拟所引用的对象及其行为,因此被测试模块并不知道它所引用的究竟是真实对象还是 Mock 对象:
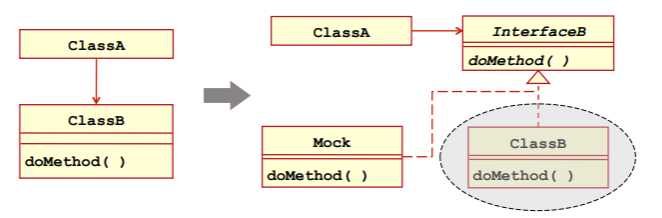
黑盒测试方法
测试用例
设计良好的测试用例是单元测试质量可以信任的关键。那么,完整的测试用例应该包含哪些内容?
- 测试用例值:完成被测软件的某个执行所需的输入值
- 期望结果:当且仅当程序满足其期望行为,执行测试时产生的结果
- 前缀值:将软件置于合适的状态来接受测试用例值的任何必要的输入
- 后缀值:测试用例值被发送以后,需要被发送到软件的任何输入
可选内容
除了上述四项保证测试用例真实可用的内容外,还有两个补充的可选内容,它们可以让测试过程更加完善:
- 验证值:查看测试用例值结果所要用到的值
- 结束命令:终止程序或返回到稳定状态所要用到的值
以拨打电话为例说明一个完整的测试用例:

- 测试用例值:电话号码
- 期望结果:接通(或未接通)
- 前缀值:电话开启并进入拨号界面
- 后缀值:按下“呼叫”或“取消”按钮
因此,我们可以总结出以下几项测试用例设计的要求:
- 具有代表性和典型性
- 寻求系统设计和功能设计的弱点
- 既有正确输入也有错误或异常输入
- 考虑用户实际的诸多使用场景
黑盒测试具体方法
我们已经提到,黑盒测试不需要考虑内部逻辑结构是否正确,只需要知道给定正确的输入,能否得到正确的输出。黑盒测试技术有以下方法:
- 等价类划分
- 边界值分析
- 因果图决策表
- 场景法
- 组合设计法
- 状态转换测试
在单元测试中,我们具体学习前两种方法。
等价类划分
等价类划分是将输入域划分成尽可能少的若干子域,在划分中要求每个子域两两互不相交,每个子域称为一个等价类:
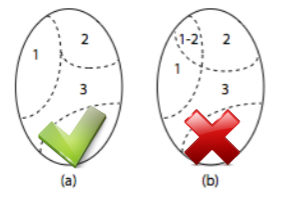
- 要注意,同一输入域的等价类划分可能不唯一,而不论如何划分,我们只需从每一个等价类中选取一个输入作为测试用例即可;
对于等价类,也有不同的分类:
- 有效等价类是对规格说明有意义、合理的输入数据构成的集合,能够检验程序是否实现了规格说明中预先规定的功能和性能
- 无效等价类是对规格说明无意义、不合理的输入数据构成的集合,以检查程序是否具有一定的容错性

根据不同变量的输入条件,我们可以得到不同的有效等价类和无效等价类:
- 对于规定了取值范围的数值变量,可以确定一个有效等价类和两个无效等价类:
- 对于规定了输入规则的字符串变量,可以确定一个有效等价类和若干不同角度违反规则的无效等价类;
- 对于规定了可选内容的枚举变量,可以确定 个有效等价类和一个无效等价类:
- 对于规定了类型和长度的数组变量,其长度和元素类型都可以作为等价类划分的依据:
- 对于复合数据类型,我们要考虑输入数据的所有属性的合法、非法取值:




通过对等价类的合理组合,我们才能生成合理、可信、可用的测试用例:
- 测试用例生成:测试对象通常有多个输入参数,如何对这些参数等价类进行组合测试,来保证等价类的覆盖率,是测试用例设计首先需要考虑的问题。
- 所有有效等价类的代表值都集成到测试用例中,即覆盖有效等价类的所有组合。任何一个组合都将设计成一个有效的测试用例,也称正面测试用例。
- 无效等价类的代表值只能和其他有效等价类的代表值(随意)进行组合。因此,每个无效等价类将产生一个额外的无效测试用例,也称负面测试用例。
案例:三角形类型判断
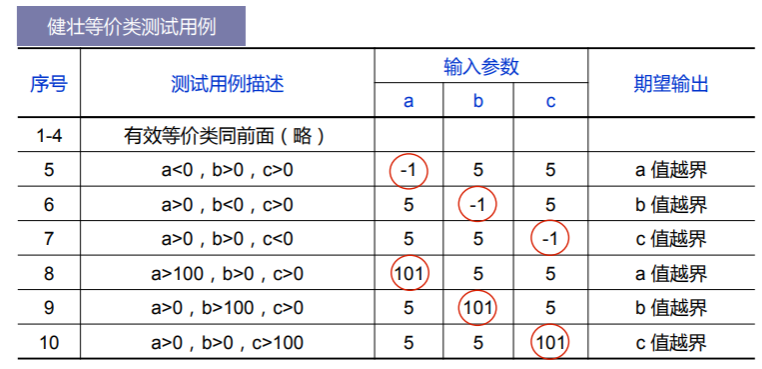
我们以一个判断三角形类型的案例讨论:输入三个整数 a、b、c,分别作为三角形的三条边,现通过一个程序判断这三条边构成的三角形类型,包括等边三角形、等腰三角形、一般三角形(特殊的还包括 直角三角形)以及构不成三角形。 现在要求输入的三个整数 a、b、c 必须满足以下条件:
- 条件 1:1≤a≤100
- 条件 2:1≤b≤100
- 条件 3:1≤c≤100
- 条件 4:a<b+c
- 条件 5:b<a+c
- 条件 6:c<a+b
请使用等价类划分方法,设计该程序的测试用例。
首先,我们提出一些常见的等价类划分方法:
- 按输入取值划分:{0,>0,<0} 或 {0,1,>1,<0}
- 按输出的几何特性划分:{等腰且非等边三角形,等边三角形,一般三角形,非三角形}
显然,第二种划分方法更适合本题,因此我们可以如下设置测试样例:
为了程序的健壮性,我们应当结合无效等价类生成额外的测试:
边界值分析
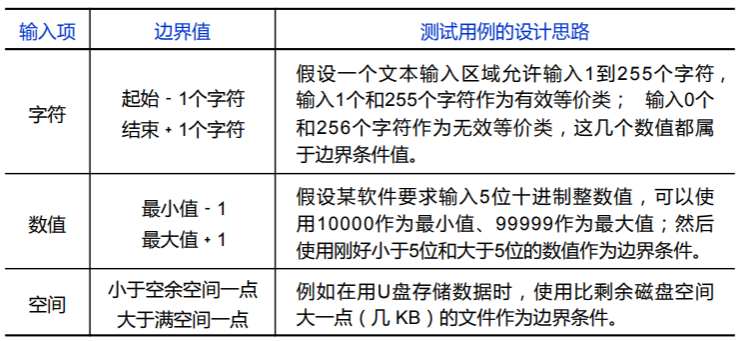
边界值分析是对输入或输出的边界值进行测试的一种方法,它通常作为等价类划分法的补充,这种情况下的测试用例来自等价类的边界。
- 先确定边界:通常输入或输出等价类的边界就是应该着重测试的边界情况
- 选取正好等于、刚刚大于或刚刚小于边界的值作为测试数据,而不是选取等价类中的典型值或任意值
- 这是因为实践表明,大多数故障往往发生在输入定义域或输出值域的边界上,而不是内部;
- 因此,针对各种边界情况设计测试用例,通常会取得很好的测试效果。
- 对不同输入项,应当设计不同的边界值检查,比如下列这些可行的边界值设计思路:
不过,边界值通常有最大边界和最小边界两者,该如何选取呢?
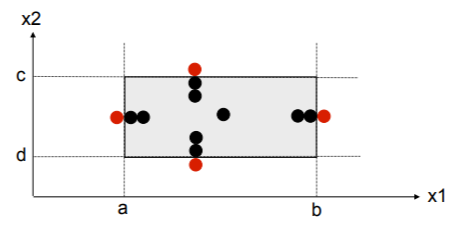
- 边界值分析法是基于可靠性理论中称为“单故障”的假设,即有两个或两个以上故障同时出现而导致失效的情况很少,因此对于程序中每次保留一个变量,让其余的变量取正常值,被保留的变量依次取 min、min+ 、nom、max- 和 max,然后对所有变量都这样做一次检查;
- 例如对于
x1,x2这两个变量,就可以进行这样的检查: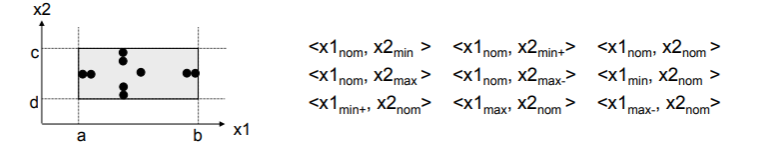
案例:判断三角形类型(补充)
因此,对于之前探讨的三角形类型判断问题,我们可以如下设置边界值来进行检查:
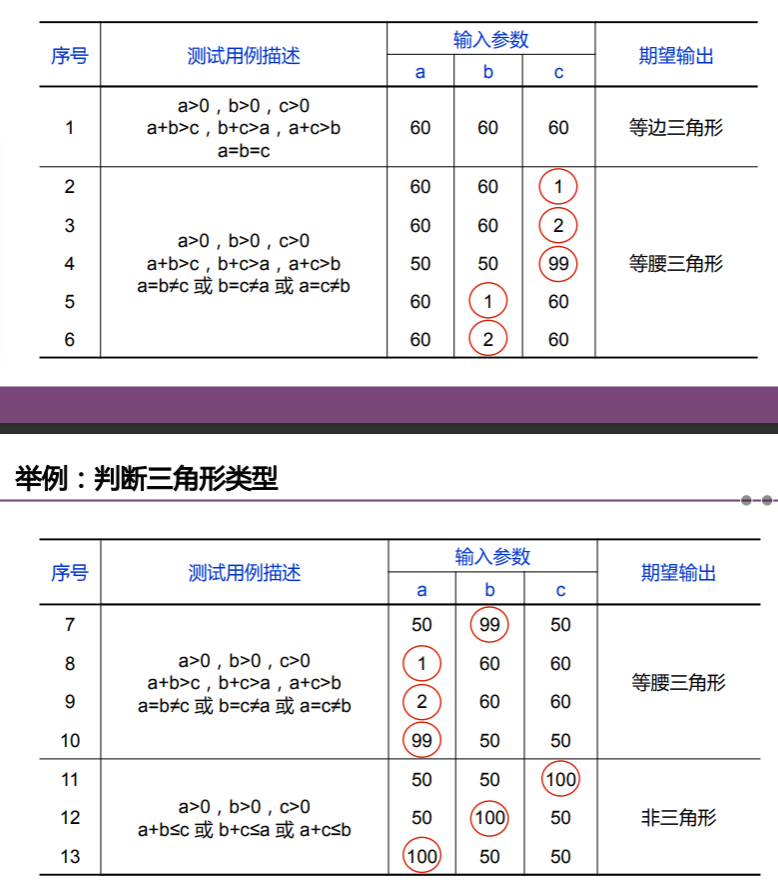
健壮性测试
健壮性测试是作为边界值分析的一个简单的扩充,它除了对变量的5个边界值分析取值外,还要增加一个略大于最大值(max+)以及略小于最小值(min-)的取值,检查超过极限值时系统的情况:
白盒测试方法
基本概念
测试覆盖标准
我们前面提到 测试覆盖率 用于评估测试完整性,现在我们从四个方面来探讨测试覆盖标准的相关概念:
- 测试需求:测试需求是软件制品的一个特定元素,测试用例必须满足或覆盖这个特定元素
- 覆盖标准:一个覆盖标准是一条规则,或者是将测试需求施加在一个测试集上的一组规则
- 测试覆盖:给定一个覆盖标准 C 和相关的测试需求集合 TR,欲使一个测试集合 T 满足 C,当且仅当对于测试需求集合 TR 中的每一条测试需求 tr,在 T 中至少存在一个测试 t 可以满足 tr
- 覆盖程度:给定一个测试需求集合 TR 和一个测试集合 T,覆盖程度就是 T 满足的测试需求数占 TR 总数的比例
以一个超市中糖豆分类的实际问题理解这四个概念:
- 现在糖豆有 6 种口味和 4 种颜色:柠檬味(黄色)、开心果味(绿色)、梨子味(白色)、哈密瓜味(橙色)、橘子味(橙色)、杏味(黄色)
- 我们应该选择什么覆盖标准来选择糖豆进行测试?显然,味道能够覆盖所有糖豆的类型,因此能够完全区分;而颜色则会有重复,不能完全覆盖,因此不是好的覆盖标准;
- 综合起来,我们应当考虑这些因素来选择覆盖标准:
- 处理测试需求的难易程度
- 生成测试的难易程度
- 用测试发现缺陷的能力
控制流图
我们已经知道,白盒测试需要知晓程序内部的逻辑结构及相关信息,从而“因材施教”地设计测试用例,实现对所有逻辑路径的测试。那么,如何形象地表达出逻辑路径,就是选择合适的测试用例前最关键的操作。
控制流图(Control Flow Graph)就是对程序的抽象表示:
- 矩形代表了连续的顺序计算,也称基本块
- 节点是语句或语句的一部分,边表示语句的控制流
以下面这段代码为例,我们尝试勾画控制流图:
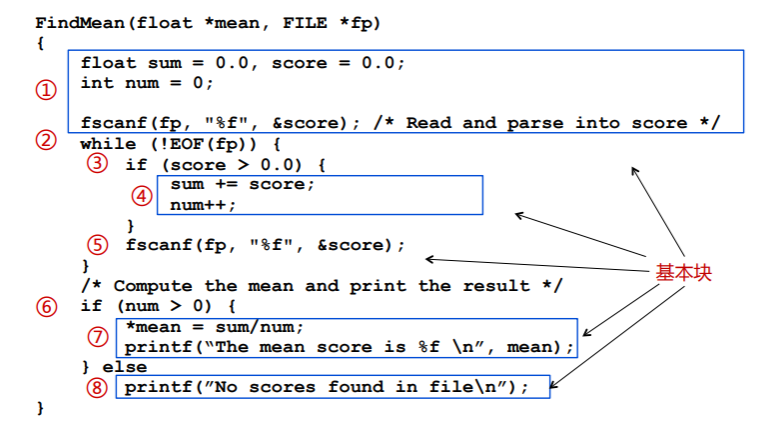
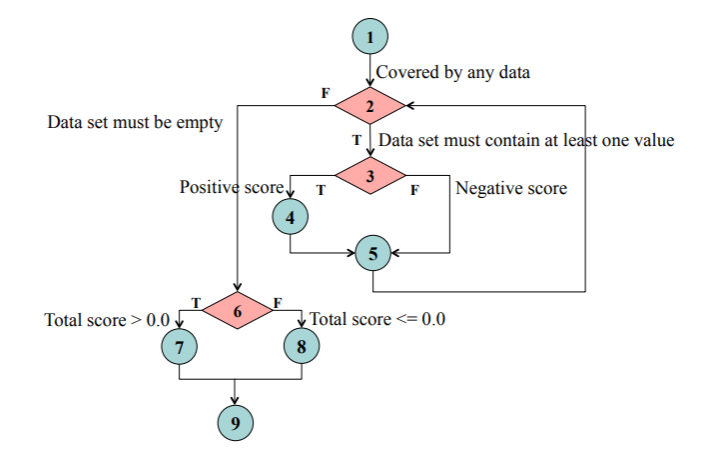
- 这段代码中,第 1、4、5、7、8 五个部分是控制流图中的基本块,其余部分是控制流,因此可以如下绘制出控制流图:
基于控制流的测试
得到程序的控制流图后,我们就可以清晰直观地找到测试路径,从而对症下药地设计测试用例,进而开始测试,整体流程如下:
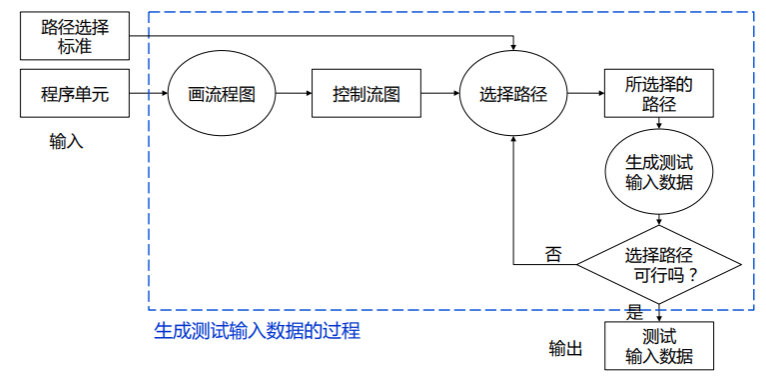
代码覆盖标准
代码覆盖率描述的是代码被测试的比例和程度,通过代码覆盖率可以得知哪些 代码没有被覆盖,从而进一步补足测试用例。代码覆盖率的判断有以下几种形式:
- 语句覆盖
- 判定覆盖
- 条件覆盖
- 判定条件覆盖
- 条件组合覆盖
- 路径覆盖
以下面这段代码及其控制流图,我们逐个解析各种覆盖的含义:
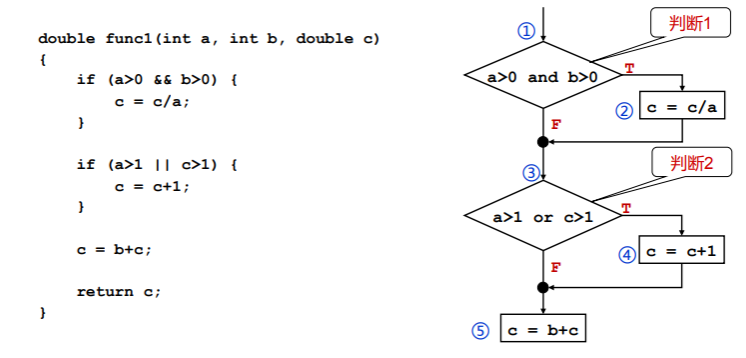
语句覆盖
即,程序中的每个可执行语句至少被执行一次。
上图中可执行语句有3️三条,分别是 c=c/a 、 c=c+1 、c=b+c ,因此我们可以设计测试样例 a=2,b=1,c=6 ,这个样例就会使得每个可执行语句都被执行一次。
不过这个测试用例虽然覆盖了全部的可执行语句,但无法检查判断逻辑是否存在问题,如第一个条件判断中的 && 被错误地写成 || ,但是却能然能够执行第一个可执行语句。
因此,语句覆盖的可信程度并不高。实际上,语句覆盖是最弱的逻辑覆盖准则。
判定(分支)覆盖
程序中每个判断的取真和取假分支至少经历一次,即判断真假值均被满足。
上图中测试样例 a=2,b=1,c=6 可以让每个分支语句都取真(进行分支),那么我们可以再设计一个测试样例 a=-2,b=-1,c=-3 ,使得每个分支语句都取假(不进行分支)。
然而这样覆盖也有问题:由于大部分判定语句是由多个逻辑条件组合而成,若仅判断其整个最终结果,而忽略每个条件的取值情况,必然会遗漏部分测试路径。(比如 a>4 || a>3 || a>2 这个条件,结果是二元的,但判断语句却由三部分组成)
判定覆盖具有比语句覆盖更强的测试能力,但仍是弱的逻辑覆盖。
条件覆盖
每个判断中每个条件的可能取值至少满足一次。
上面控制流图中我们可以设计测试样例 a=2,b=-1,c=-2 和 a=-1,b=2,c=3 。它们分别能够覆盖 a>0,b<=0,a>1,c<=1 和 a<=0,b>0,a<=1,c>1 这两个条件,即对 a>0 、b>0 、a>1 、c>1 这四个条件都进行了正反两个方向的判断。
不过这样的覆盖方案却不一定包含判定覆盖,上面的测试用例就没有覆盖判断 1 的 T 分支和判断 2 的 F 分支。这是因为条件覆盖只能保证每个条件至少有一次为真,而没有考虑整个判定结果。
判定条件覆盖
判断中所有条件的可能取值至少执行一次,且所有判断的可能结果至少执行一次。
因此,很自然地我们就提出结合判定覆盖和条件覆盖,提出能够覆盖所有判断的所有分支、所有条件的所有方面:例如测试用例 a=2,b=1,c=6 能够覆盖 a>0,b>0,a>1,c>1 ,且判断均为 T ;而测试用例 a=-1,b=-2,c=-3 能够覆盖 a<=0,b<=0,a<=1,c<=1 ,且判断均为 F 。
不过这也并非尽善尽美,因为还没有考虑条件的组合情况。
条件组合覆盖
判断中每个条件的所有可能取值组合至少执行一次,并且每个判断本身的结果也至少执行一次。
因此上面例子中有 种条件组合:
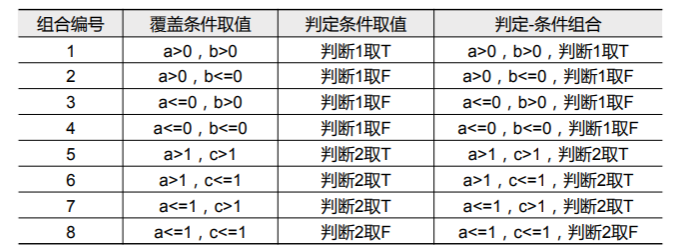
- 因此我们可以如下设计测试用例:
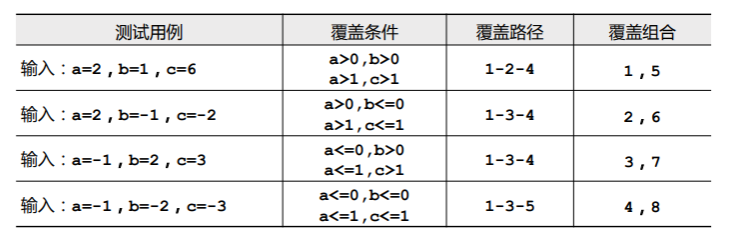
这样就万事大吉了吗?还没有,上面的测试用例中,虽然覆盖了所有组合,但是没有覆盖所有的路径,1-2-5 这条路径就没有覆盖。
路径覆盖
覆盖程序中的所有可能的执行路径。
因此我们直接从覆盖路径入手,设计测试用例:
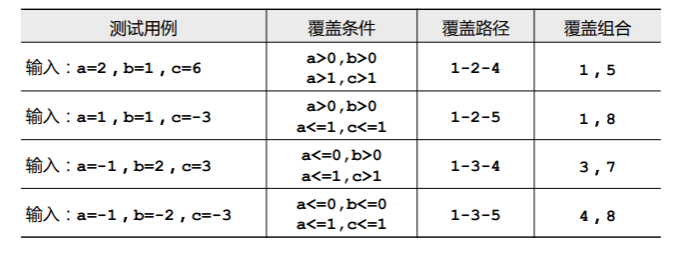
- 结合前面的条件组合覆盖的测试用例,我们可以得到覆盖了所有条件组合、路径的测试用例:
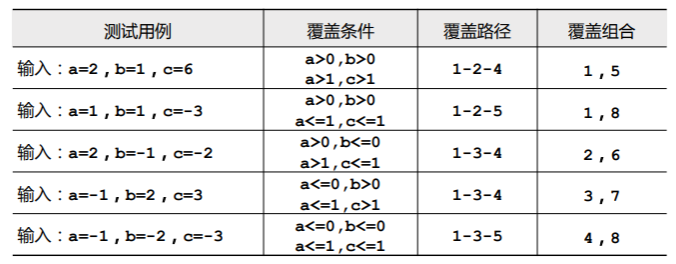
如何看待 测试覆盖率?
- 覆盖率数据只能代表测试过哪些代码,不能代表是否测试好这些代码
- 较低的测试覆盖率能说明所做的测试还不够,但反之不成立
- 路径覆盖 > 判定覆盖 > 语句覆盖
- 测试人员不能盲目追求代码覆盖率,而应该想办法设计更好的测试用例
- 测试覆盖率应达到多少需要考虑软件整体的覆盖率情况以及测试成本
基本路径测试
基本路径测试是在程序控制流图基础上,通过分析控制构造的环路复杂性,导出基本可执行路径集合,从而设计测试用例的方法:
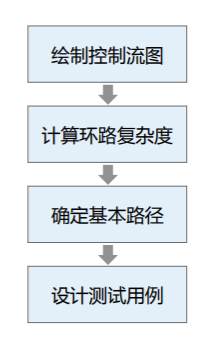
仍以上面的例子来探讨这个流程:
- 我们可以绘制出控制流图后,如何确定环路的复杂度呢?准确说,什么是环路复杂度呢?
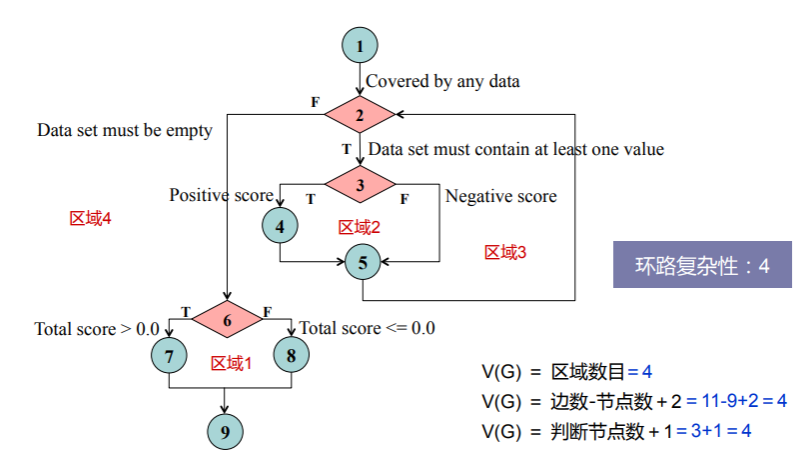
- 计算环路复杂度有三种方法,且计算结果是一致的;
- 从而,我们要设计能够通过所有路径的测试用例集,先找出所有路径:
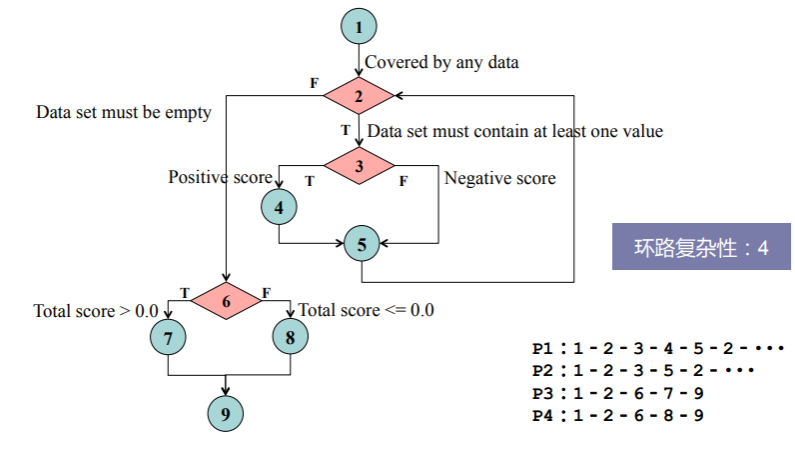
- 于是通过这四条路径的测试用例有:

循环测试
我们之前讨论的问题都是假定程序只有分支路径,现在我们需要对循环控制流进行探讨。
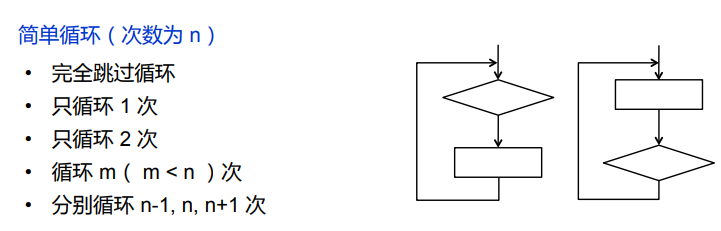
为了检查循环结构的有效性,我们先要明确有哪些类型的循环,针对不同的循环,有不同的测试方法:
- 简单循环
- 嵌套循环
- 串接循环
- 独立循环:分别采用简单循环的测试方法
- 依赖性循环:采用嵌套循环的测试方法。
- 非结构循环
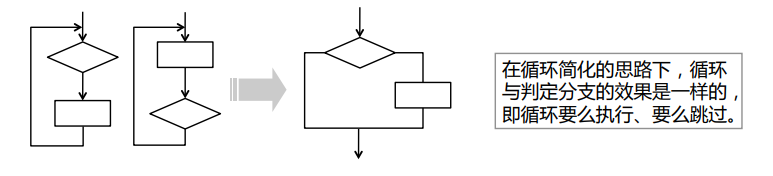
- 典型的如 Z 路径径覆盖下的循环测试
- 这是路径覆盖的一种变体,将程序中的循环结构简化为选择结构的一种路径覆盖
- 循环简化的目的是限制循环的次数,无论循环的形式和循环体实际执行的次数,简化后的循环测试只考虑执行循环体一次和零次(不执行)两种情况

单元测试工具
Unittest
Basic example
The
unittestmodule provides a rich set of tools for constructing and running tests. This section demonstrates that a small subset of the tools suffice to meet the needs of most users.Here is a short script to test three string methods:
import unittest class TestStringMethods(unittest.TestCase): def test_upper(self): self.assertEqual('foo'.upper(), 'FOO') def test_isupper(self): self.assertTrue('FOO'.isupper()) self.assertFalse('Foo'.isupper()) def test_split(self): s = 'hello world' self.assertEqual(s.split(), ['hello', 'world']) # check that s.split fails when the separator is not a string with self.assertRaises(TypeError): s.split(2) if __name__ == '__main__': unittest.main()A testcase is created by subclassing
unittest.TestCase. The three individual tests are defined with methods whose names start with the letterstest. This naming convention informs the test runner about which methods represent tests.The crux of each test is:
- a call to
assertEqual()to check for an expected result;assertTrue()orassertFalse()to verify a condition;- or
assertRaises()to verify that a specific exception gets raised.These methods are used instead of the
assertstatement so the test runner can accumulate all test results and produce a report.通过继承
unittest.TestCase类,我们可以定义自己的测试类,在类中的三个函数里,通过assertEqual()等方法,可以实现特定的检查。这些
assertXxx()方法是从assert方法中重构、精简来的更强大的断言方法,可以让 test runner 调用,统计测试结果和给出报告。The
setUp()andtearDown()methods allow you to define instructions that will be executed before and after each test method. They are covered in more detail in the section Organizing test code.
setUp()和tearDown()方法用于每个测试方法前后设置要执行的特定指令。具体可以查看后文。The final block shows a simple way to run the tests.
unittest.main()provides a command-line interface to the test script. When run from the command line, the above script produces an output that looks like this:
unittest.main()方法提供了命令行式的接口,用以运行测试,输出类似下面:... ---------------------------------------------------------------------- Ran 3 tests in 0.000s OKPassing the
-voption to your test script will instructunittest.main()to enable a higher level of verbosity, and produce the following output:test_isupper (__main__.TestStringMethods.test_isupper) ... ok test_split (__main__.TestStringMethods.test_split) ... ok test_upper (__main__.TestStringMethods.test_upper) ... ok ---------------------------------------------------------------------- Ran 3 tests in 0.001s OKThe above examples show the most commonly used
unittestfeatures which are sufficient to meet many everyday testing needs. The remainder of the documentation explores the full feature set from first principles.指向原始笔记的链接Changed in version 3.11: The behavior of returning a value from a test method (other than the default
Nonevalue), is now deprecated.
Mock
unittest.mock — mock object library — Python 3.12.2 documentation
Converage
Coverage.py — Coverage.py 7.4.1 documentation
Practice
判断
- 用同一等价类中的任意输入对软件进行测试,软件都输出相同的结果。
✅
编程作业
生命游戏单元测试
生命游戏是英国数学家约翰·何顿·康威在1970年发明的细胞自动机,它包括一个二维矩形世界,这个世界中的每个方格居住着一个活着的或死亡的细胞。一个细胞在下一个时刻生死取决于相邻八个方格中活着的或死了的细胞的数量。如果相邻方格活着的细胞数量过多,这个细胞会因为资源匮乏而在下一个时刻死去;相反,如果周围活细胞过少,这个细胞会因太孤单而死去。
游戏在一个类似于围棋棋盘一样的,可以无限延伸的二维方格网中进行(在程序实现中,我们采取令左右边界相接、上下边界相接的方法模拟无限棋盘的情况)。例如,设想每个方格中都可放置一个生命细胞,生命细胞只有两种状态:“生”或“死”。图中,用黑色的方格表示该细胞为“死”, 其它颜色表示该细胞为“生” 。游戏开始时, 每个细胞可以随机地(或给定地)被设定为“生”或“死”之一的某个状态, 然后,再根据如下生存定律计算下一代每个细胞的状态:
-
每个细胞的状态由该细胞及周围8个细胞上一次的状态所决定;
-
如果一个细胞周围有3个细胞为生,则该细胞为生,即该细胞若原先为死则转为生,若原先为生则保持不变;
-
如果一个细胞周围有2个细胞为生,则该细胞的生死状态保持不变;
-
在其它情况下,该细胞为死,即该细胞若原先为生则转为死,若原先为死则保持不变。
这里提供四个 python 文件(见附件),分别是 main.py、life_game.py、game_timer.py、game_map.py,它可以正确地实现生命游戏的功能(棋盘的左右、上下是相连的),通过 python main.py 即可启动。本次作业要求针对 game_map.py 中的接口编写测试用例,测试文件需要命名为 test_game_map.py。
代码链接:code.zip