Learning with Different Output Space
Binary Classification
对于一个问题的判断只有两个结果——是或否,则称为二元分类问题:
- 例如前文提到的是否批准信用卡申请的问题:
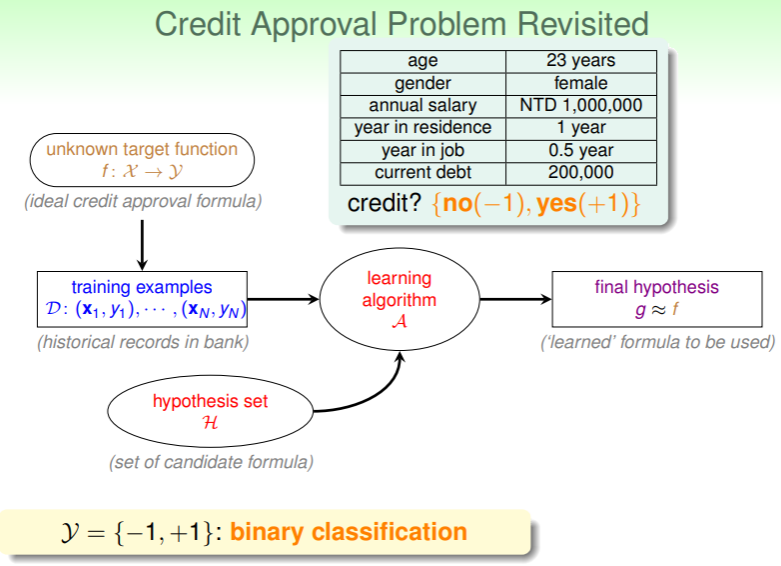
- 类似的问题还有判断恶意软件与否,判断垃圾邮件与否,判断回答是否正确…
二元分类问题是机器学习的一个核心、基础的话题。
Multicalss Classification
对一个问题的判断有 K 种,是对二元分类问题的扩展,称为多元分类问题:
- 例如根据硬币的重量对其币值进行判断:
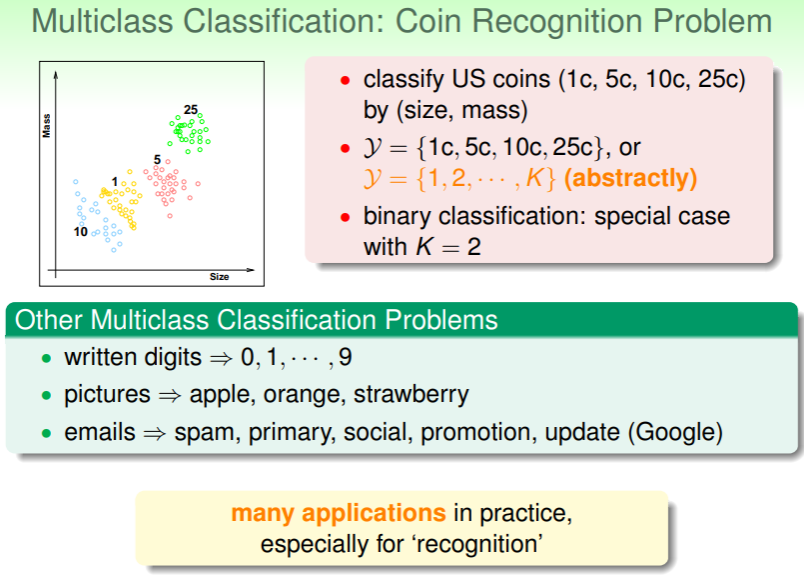
- 更多的多分类问题:判断手写数字究竟是什么?判断图片中究竟是什么水果?判断邮件究竟是哪一类?
Regression
通过已有数据对未来进行合理的预测,称为回归分析(Regression):例如对于某一疾病,已知大量的其他病人的痊愈时间,那么可以对当前病人的痊愈时间作出合理的估计:
- 统计学中,曾学习过线性回归,即是回归分析的一种:
- 输出应当是一个预先不能确定的数:

Structured Learning
所谓结构化学习,是一种复杂的多分类问题,以自然语言处理领域为例,其中一个问题是对句子中的词性作以划分:
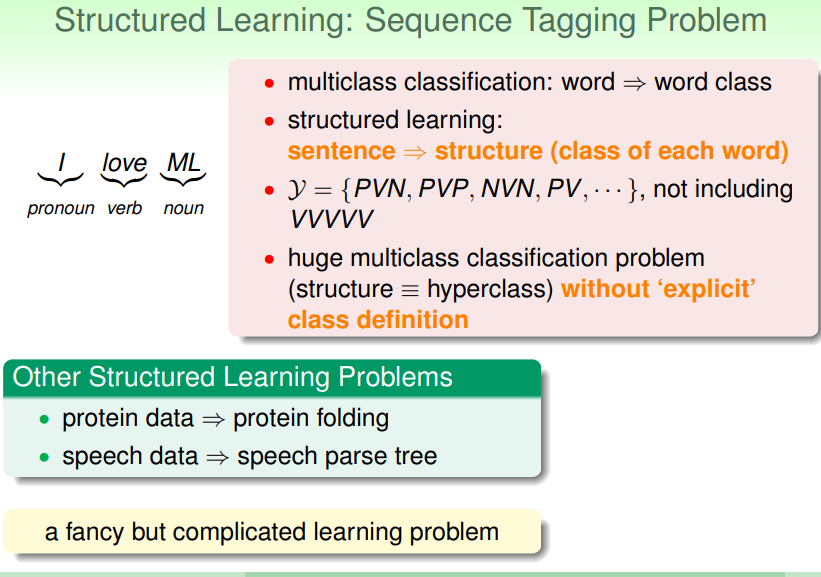
- 和多分类问题简单地给出词性不同,结构化学习需要根据语境给出合理的词性判断,而不同的句子中同一单词的词性是可能不同的,因此问题更复杂——没有确定的分类标准;
- 更多的结构化学习示例:由蛋白质数据推测蛋白质折叠的空间结构…
Learning with Different Data Label
Supervised
监督式学习:在数据集 中不仅给出每个样本的 data ,同时给出其 label :
- 例如根据硬币重量判断币值的问题,其中若每个样本数据都是
(重量,币值)的二元组,则是监督式学习: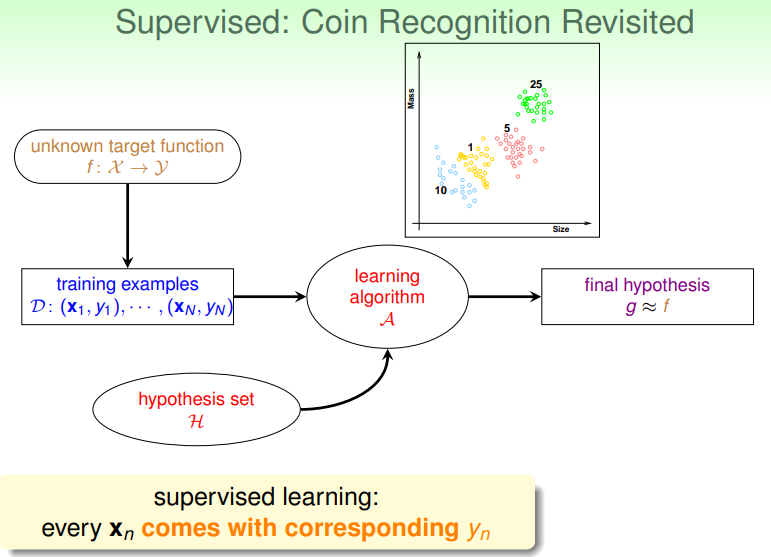
- 显然,监督式学习对数据的预处理要求较高,相应的准确度也更高。
Unsupervised
无监督式学习:预先数据集 中不给出 label ,而是让模型根据数据自行判断
- 如果判断币值的问题中,不给出样本点的 label ,则如下右图:
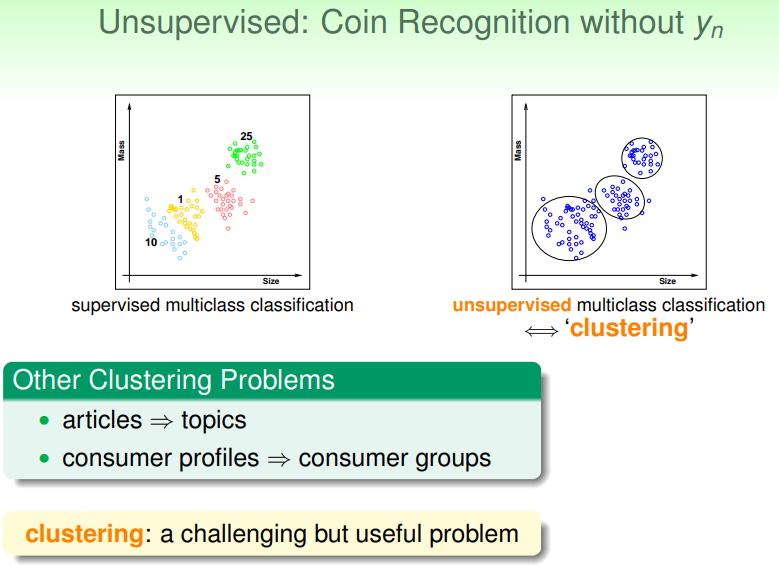
- 模型不知道样本究竟属于哪个 label,只能根据相近程度进行划分——因此又称聚类(clustering)
- 其它的聚类问题:从一大堆文章中根据话题进行分类,从用户购买历史的肖像中对用户进行分类…
- 聚类问题有一个特点——没有一个预先确定的目标能够指引模型该如何分类数据,因此只能让建模者根据经验等方法,进行粗略地估计阈值,从而划分;
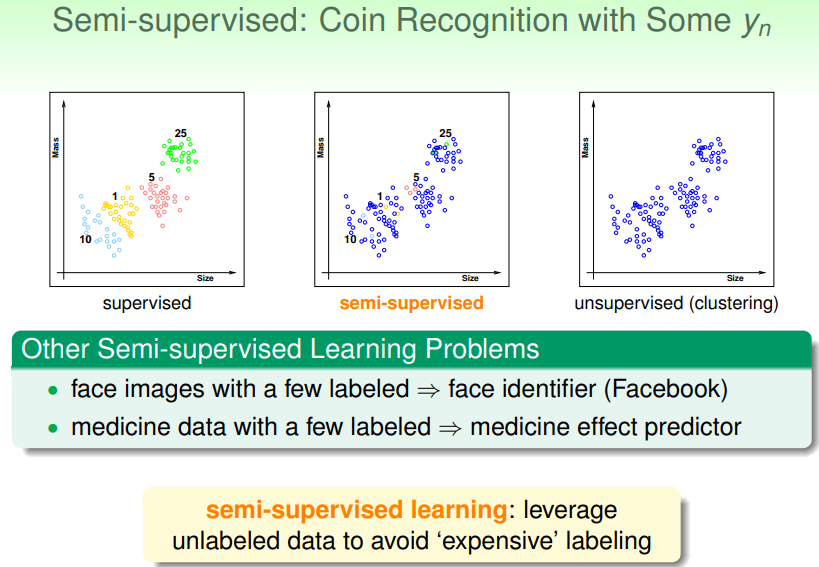
Semi-supervised
半监督式学习:对部分样本给出 label ,而大多数样本都不给出,让模型根据给出 label 的样本自行学习,从而提高对其他样本的判断准确性:
Reinforcement Learning
思路对比
巴甫洛夫的狗:强化条件反射的思路。
强化学习:通过设置完成目标与否后的奖励或惩罚,让模型更倾向于学习建模者所需的目标:
- 就像驯狗一样:


- 更多的强化学习案例:广告投放系统中用户对不同广告的反应…
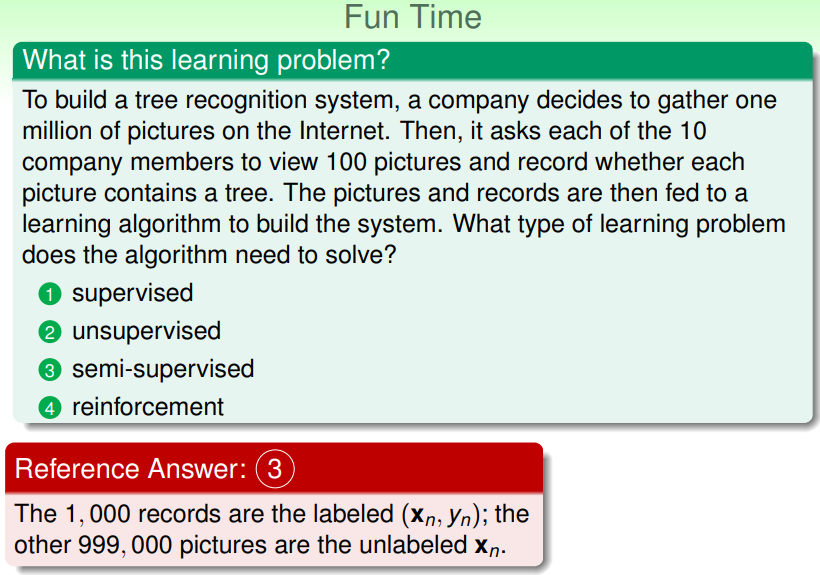
练习:选择合适的监督方法
Learning with Different Protocol
Batch Learning
成批学习:模型从全知的角度获取全部数据的全部信息:
- 还是之前的硬币例子,如果模型能够获取数据的全部信息,那么就可以对这批数据在一段时间内集中处理:
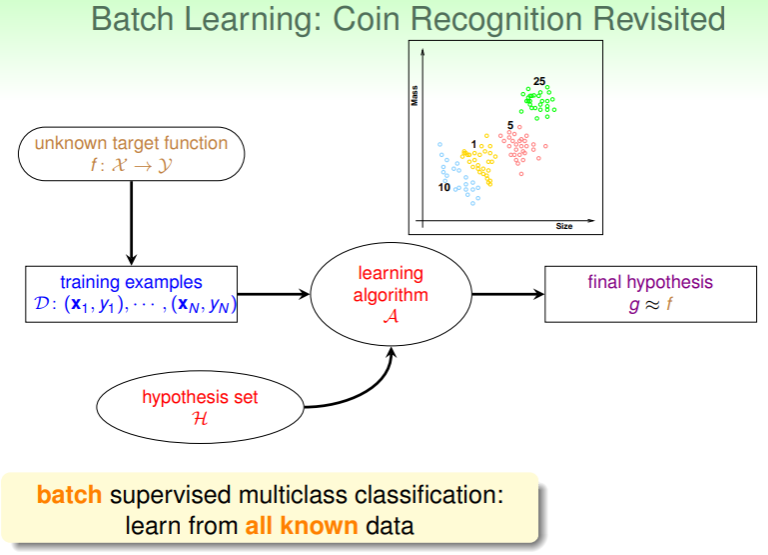
- 更多 batch learning 案例:从一大堆已知邮件是否为垃圾的数据中学习得到垃圾邮件过滤器……
- batch learning 就像是填鸭式学习,模型从已知的一批数据中学到知识;
Online Learning
在线学习:模型以一种时间先后的序列逐步地掌握数据集的特征,可以理解为多批数据依次处理、学习:
- 模型收到一封邮件,然后对其进行预测,然后由建模者告知其预测是否正确,然后模型根据正确与否进行调整,如此来逐步提高模型的准确性;
- 回顾之前的模型:
- PLA 是每轮选出一个错误的预测进行修正,因此思路类似,可以很方便地切换为 online learning —— 将每轮在已知数据中的纠错改为每轮对收到的新数据纠错;
- 强化学习通常是在线学习,因为强化学习需要逐步地对判断正确与否进行赏罚,这显然就是 online learning 的特征;
- online learning 就像是老师教书,逐步地告知一个命题的正确与否,让学生(模型)增长见识——hypothesis “improves” through receiving data instances sequentially.
Active Learning
主动学习:机器主动地“提出问题”、等待回答:
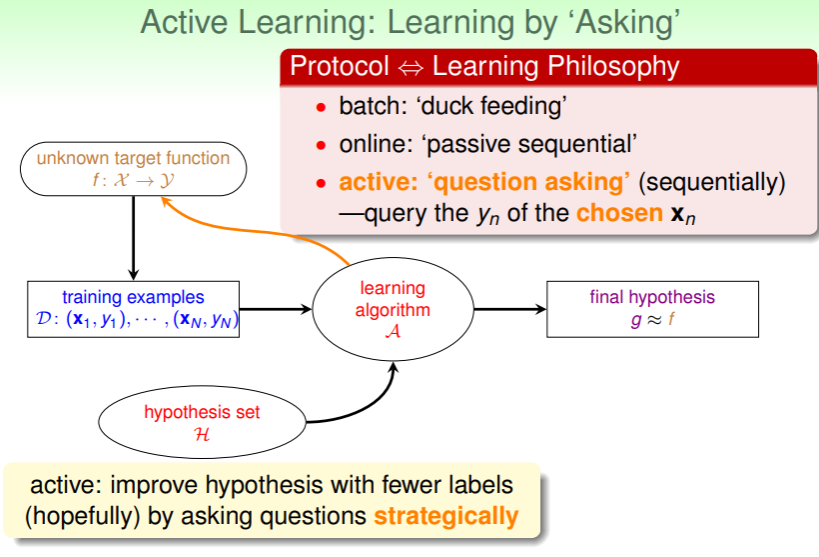
- 无论 batch learning 还是 online learning,模型都是被动地接受数据的特征,而 active learning 则是机器主动地阐述对数据的困惑,等待建模者的回答;
- active learning 就像学生向老师提问,等待老师回答一样,因此这种方式使得很少的 label 便能大幅提高模型的准确性——适用于打标签的代价很昂贵的场合;
练习:选择合适的学习方式
Learning with Different Input Space
Concrete Features
特征具体的输入:输入数据样本的每个维度的含义都是固定、已知的:
- 是否签发信用卡的问题中,客户数据的每个维度含义都是确定的,如年龄、性别、年薪等:
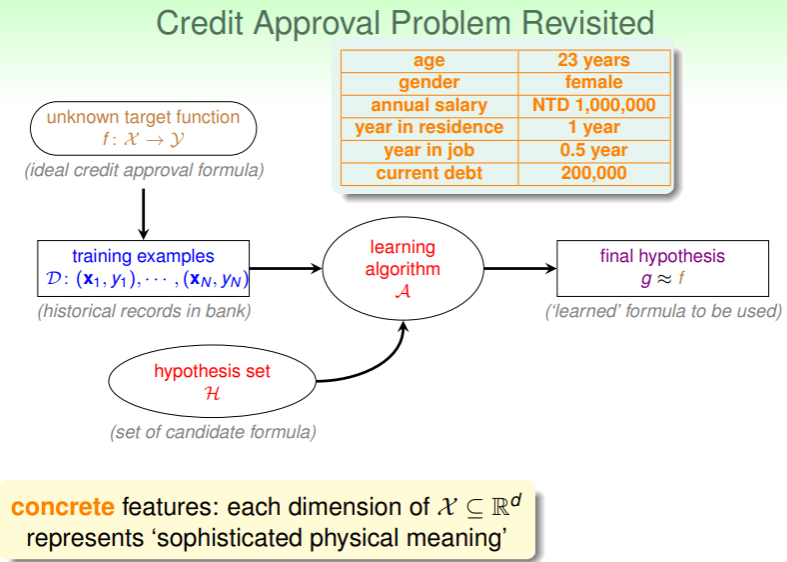
- 更多的案例:硬币的重量与币值判断问题中每个硬币数据都是由二维向量
(重量, 币值)构成的…… - 特征具体的数据对模型来说是目标明确、易于学习的;
Raw Features
未经处理的输入:输入数据的特征是未经“打标签”这样的预处理的:
- 手写数字识别问题中,输入数据是一张张图片,如果已经做好了数据预处理——即每个样本都是由
(对称程度, 密度)这样的二维向量构成,那就是 concrete features ; - 但若未经处理,那模型就不得不从图片(假设是 的灰度图)中自行提取特征,进行聚类分析:

- 更多的 raw features 案例:图像识别、语音识别等,都是难以对数据逐个提前打好标签的;
- 这类 raw features 的输入需要人工或机器进行预处理转化为 concrete features 才能利用、学习,因此耗时更长、困难度骤增;
Abstract Features
特征抽象的输入:输入数据可能仅有几个维度的特征,但这些特征都无法体现数据的区别:
- 例如给出某次评分中某个裁判的 ID、评分项目的 ID、上次评分的结果,然后预测下次评分的结果:

- 仅凭 ID 当然无法确定评分的结果,因此仍然需要特征提取——这就是另一门学问,特征工程(Feature Engineering)