Quadratic Hypotheses
之前我们学习了线性模型,但是对于一些问题,任何线性模型产生的 都大得难以接受,我们不得不考虑非线性模型:
- 以圆形模型为例:
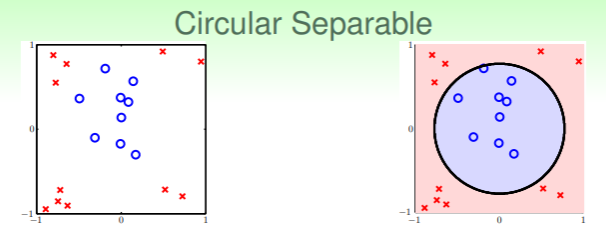 这个数据集是圆形可分的,其分类函数为
这个数据集是圆形可分的,其分类函数为
Circular Separable to Linear Separable
如果对这个圆形模型再像之前的探讨一样做一遍 circular-PLA、circular-Regression… 未免太过笨拙,我们考虑化非线性为线性,从而直接套用之前的线性分类器:
- 考虑圆形分类函数的各项含义,我们可以分离出权重和各维变量: ,将平方项用一次项代替,我们就又得到了线性模型;
- 这实现了从 圆形可分 到 线性可分 的转换,在 ML 中称这样的转换为特征转换( feature transform, denoted as ):
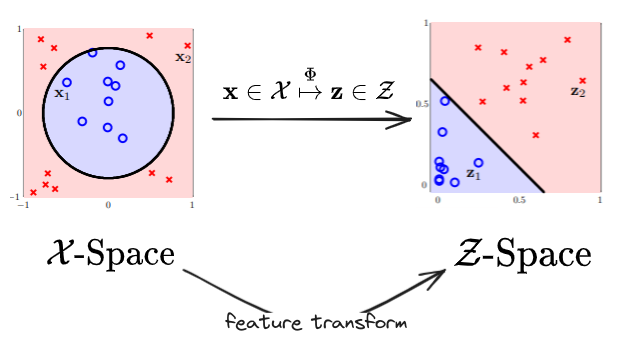
Linear Separable to Circular Separable
从二维的圆形可分转换到线性可分是可行的,那么反过来,还能从线性可分转换成圆形可分吗?
- 写成数学语言,就是对线性特征向量 经过特征转换得到 ,是否有假设函数能实现: ?
- 结合解析几何,我们对不同的权重向量 ,实际上可以得出以下的线性到非线性的转换:

- 不过显然,我们这里实现的转换其实是在 空间中的直线对 空间中特定二次曲线的转换,而不是任意的转换都能实现;这是由于维度限制的;
如果想实现任意直线到二次曲线的转换,我们需要扩充转换函数的维度: ,经过这样转换后的假设集才能包含全部的二维空间的曲线: 。
试看下面这个例子,对于一个偏心椭圆 ,其可以通过 实现,其中 。
站在二次曲线的角度,我们可以将线性直线看作是其中的特例,即二次项的系数全部为 0 。
练习:熟悉曲线到直线的转换
![]()
Nonlinear Transform
现在,一切真相大白:
- 只要我们能够实现特征转换,那么在线性模型上的假设就可以应用到非线性模型,并且这样的转换实质上只是符号的转换,而不会带来精度的影响:
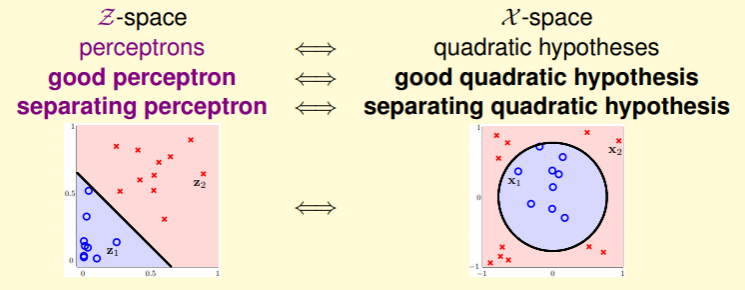
Nonlinear Perceptron to Linear Perceptron
只要将数据也经过同样的转换,那么在 空间中的好的线性感知器在经过特征转换后,就是在 空间中同样优秀的非线性感知器,具体步骤如下:
- 将原始非线性数据 通过特征转换 转换为线性数据 ;
- 在 空间中使用合适的线性模型 (如:PLA、pocket、Linear Regression、Logistic Regression)获取一个足够好的感知器 ;
- 返回的最佳估计为 ;
![]() 现在,我们完成了思路的梳理,余下最关键的就是特征转换如何找到了。
现在,我们完成了思路的梳理,余下最关键的就是特征转换如何找到了。
在探讨特征转换之前,考虑之前谈论过的一个例子,第三节我们讨论过将 手写数字的像素图转换为二维图 的例子:
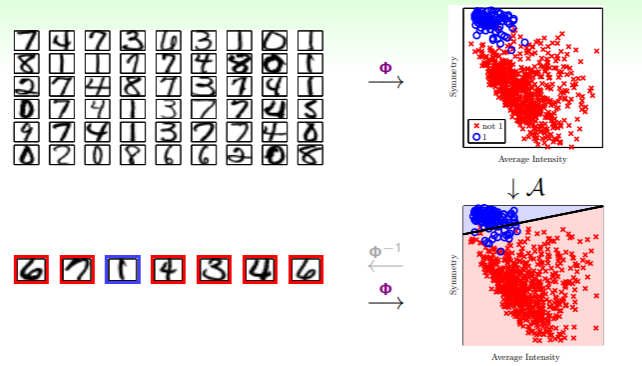
- 这里我们将 的 256 维的数字像素图,进行特征转换(提取)后,得到可以二元分类的两个特征——密度、对称性;
练习:特征转换的维度变化
![]()
Price of Nonlinear Transform
根据上面的论证,我们可以推知,要实现从 d 维空间降维到 Q 维空间,我们需要的特征转换函数为:
这是一个 Q 次多项式的转换,其中的维数是 个,其数量就是小于 Q 次方的所有组合的数量: ,这意味着在从非线性的 空间转换到线性的 空间时, 耗费的时间和 耗费的空间都是 。
另一方面,从 VC Dimension 的角度来看, 所代表的自由度(VC Dimension 的维数)也大概是 ,不过还好,由于 空间中任何超过 维的输入都不会被 shatter,因此 ,并且 空间中也不会 shatter 超过 维的输入( 空间这个当结论记住,比较难证,林老师也没有详说)
总之,Q 越大,代表着实现转换时的时间复杂度和空间复杂度越大,相应的 也会越大。
Overfitting Risk
如何权衡 Q 呢?试看这个分类:

- 相对于一次曲线的分类,四次曲线的分类虽然 ,但是显然我们认为它把噪声也额外地进行了分类,这是不合理的,称为 overkill 或 overfit
综合起来,我们这里有两个问题:
- 我们在何种程度上确保 足够接近 呢?
- 我们在何种程度上确保 足够小呢?
这两个问题不可兼得,是 ML 中一个关键的 trade-off(权衡),满足一者必然要适当的放宽另一者。
Danger of Visual Choices
另外一个问题是,选择降维到的 Q 如何抉择?考虑降维到二维空间:

- 先前我们讨论过完全实现降维需要特征转换是 6 维的,但是视觉上我们似乎用 3 维的圆也可以实现分类?进一步,我们也许可以提出 2 维、1 维的特征转换也能够实现这样的目标?不过这样的操作很危险,因为这是我们人工地对部分数据进行了 Human Learning ,我们用自己的学识、偏见做出了不一定合理的降维,这在更大范围的数据上并不一定可行,甚至可能导致结果和预期偏离甚远。
- Human Learning 不能代替 Machine Learning ,Human Learning 的操作在局部上是比 ML 更“聪明、敏捷”的,因此如果过分的依赖 Human Learning ,就会对 ML 模型的性能估计得过于乐观;
- 事实上,三维以上的空间就很难 visualize ,因此 visualize 这种手段是不可靠、不可行的。
练习:降维的代价
![]()
- 我们之前在 VC Dimension 中讨论过,要支撑 1300 多个维度的学习,我们至少需要 13000 个样本数据,这对数据集的大小要求颇高。
Structured Hypothesis Sets
重新站在特征转换的角度思考 和 的关系。
Nested Hypotheses Set
实现特征转换的函数可以写成如下嵌套的形式:
从假设集的角度来看,随着维度的增加,呈现集合包含的关系,即低维空间的变换是高维空间变化的特例:
- nested :
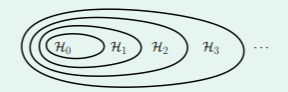
VC Dimension and Feature Transform
考虑假设的 VC Dimension 与 的关系,则有:
- 首先,高维空间可以 shatter 的点一定比低维空间可以 shatter 的点更多: ,
- 相应的,在考虑找到每个 最小的 时,即 ,就会有 ,这是因为高维空间的可选范围更广了,因此找到更低的 的假设 g 的概率也会下降;
- 因此这就从另一个角度解释这幅图:
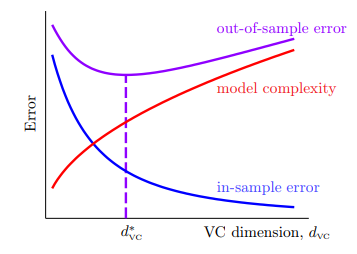
因此使用高维的特征转换尽管能够做到 ,但从全局来看并不意味着完美,因为一方面实现转换时的复杂度太高,另一方面 却并不能像 一样低。要明确, 只是一个中间产物,如果过于计较眼前的“得”,有可能导致全局的“失”。
安全的学习路线应当是从低维的假设集开始: ,如果 已经足够好,那自然皆大欢喜,否则逐步地增加转换的维度——从线性模型开始做起,逐步扩展到高维模型。
练习:理解 VC Dimension 与特征转换
![]()