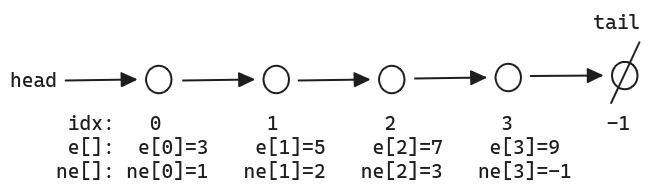
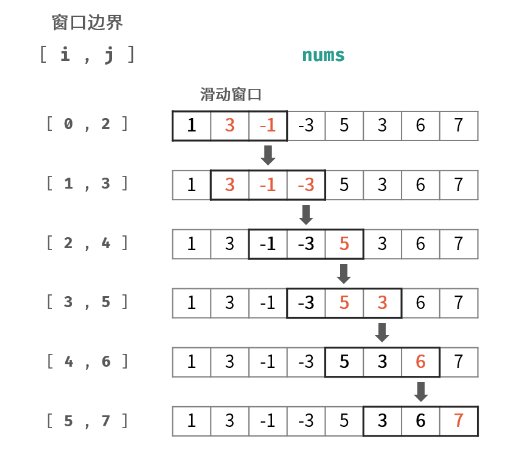
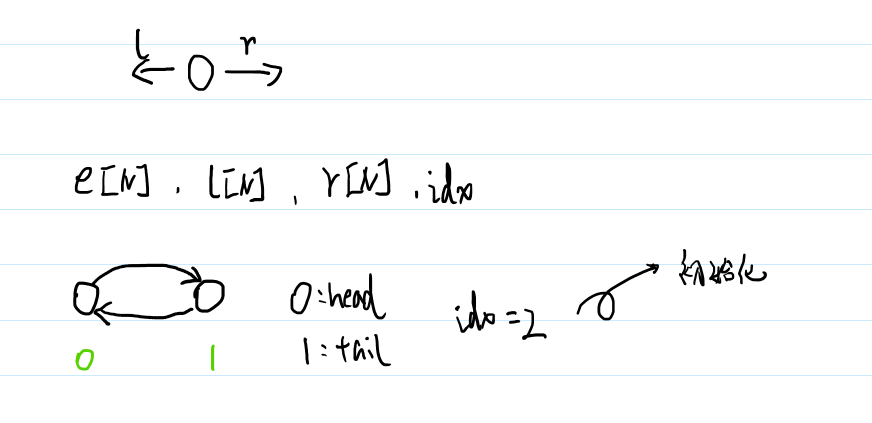// s[]是长文本,p[]是模式串,n是s的长度,m是p的长度// 求模式串的Next数组:for (int i = 2, j = 0; i <= m; i ++ ){ while (j && p[i] != p[j + 1]) j = ne[j]; if (p[i] == p[j + 1]) j ++ ; ne[i] = j;}// 匹配for (int i = 1, j = 0; i <= n; i ++ ){ while (j && s[i] != p[j + 1]) j = ne[j]; if (s[i] == p[j + 1]) j ++ ; if (j == m) { j = ne[j]; // 匹配成功后的逻辑 }}
#include <iostream>using namespace std;const int N = 1000010;char p[N], s[N]; // 用 p 来匹配 s// “next” 数组,若第 i 位存储值为 k// 说明 p[0...i] 内最长相等前后缀的前缀的最后一位下标为 k// 即 p[0...k] == p[i-k...i]int ne[N];int n, m; // n 是模板串长度 m 是模式串长度int main() { cin >> n >> p >> m >> s; // p[0...0] 的区间内一定没有相等前后缀 ne[0] = -1; // 构造模板串的 next 数组 for (int i = 1, j = -1; i < n; i++) { while (j != -1 && p[i] != p[j + 1]) { // 若前后缀匹配不成功 // 反复令 j 回退,直至到 -1 或是 s[i] == s[j + 1] j = ne[j]; } if (p[i] == p[j + 1]) { j++; // 匹配成功时,最长相等前后缀变长,最长相等前后缀前缀的最后一位变大 } ne[i] = j; // 令 ne[i] = j,以方便计算 next[i + 1] } // kmp start ! for (int i = 0, j = -1; i < m; i++) { while (j != -1 && s[i] != p[j + 1]) { j = ne[j]; } if (s[i] == p[j + 1]) { j++; // 匹配成功时,模板串指向下一位 } if (j == n - 1) // 模板串匹配完成,第一个匹配字符下标为 0,故到 n - 1 { // 匹配成功时,文本串结束位置减去模式串长度即为起始位置 cout << i - j << ' '; // 模板串在模式串中出现的位置可能是重叠的 // 需要让 j 回退到一定位置,再让 i 加 1 继续进行比较 // 回退到 ne[j] 可以保证 j 最大,即已经成功匹配的部分最长 j = ne[j]; } } return 0;}
int match ( char* P, char* T ) { //KMP算法 int* next = buildNext ( P ); //构造next表 int n = ( int ) strlen ( T ), i = 0; //文本串指针 int m = ( int ) strlen ( P ), j = 0; //模式串指针 while ( j < m && i < n ) { //自左向右逐个比对字符 if ( 0 > j || T[i] == P[j] ) //若匹配,或P已移出最左侧(两个判断的次序不可交换) { i ++; j ++; } //则转到下一字符 else //否则 j = next[j]; //模式串右移(注意:文本串不用回退) delete [] next; //释放next表 return i - j; }}int* buildNext ( char* P ) { //构造模式串P的next表 size_t m = strlen ( P ), j = 0; //“主”串指针 int* next = new int[m]; int t = next[0] = -1; //next表,首项必为-1 while ( j < m - 1 ) if ( 0 > t || P[t] == P[j] ) { //匹配 ++t; ++j; next[j] = t; //则递增赋值:此处可改进... } else //否则 t = next[t]; //继续尝试下一值得尝试的位置 return next;}// 返回数组int *buildNext(char *P) { size_t m = strlen(P), j = 0; int *N = new int[m]; int t = N[0] = -1; while (j < m - 1) { if (0 > t || P[j] == P[t]) { j++; t++; N[j] = (P[j] != P[t] ? t : N[t]); } else { t = N[t]; } } return N;}vector<int> match(char *P, char *S) { int *next = buildNext(P); int n = strlen(S), i = 0; int m = strlen(P), j = 0; vector<int> positions; while (i < n) { if (j < 0 || S[i] == P[j]) { i++; j++; } else { j = next[j]; } if (j == m) { positions.push_back(i - j); // 存储找到匹配的起始位置 j = next[j-1]; // 继续查找下一个可能的匹配 } } delete[] next; // 修正:释放next表应在函数末尾 return positions;}
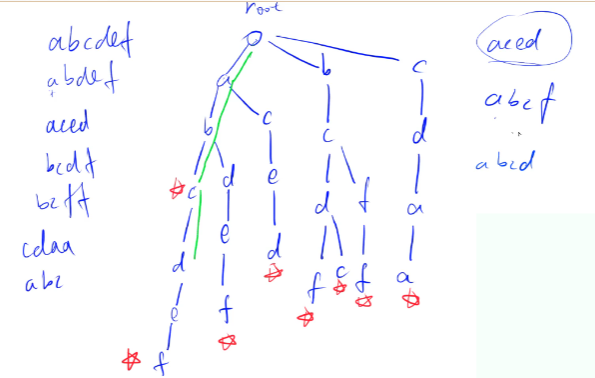
Trie 树
高效地存储和查找字符串集合的数据结构:
存储:从 root 开始,逐个存储字符串,每层存放一个字符,在字符串结束时做结束标记;
查找:从 root 开始,从上到下检验节点是否与给定字符串的对应字符匹配;
int son[N][26], cnt[N], idx;// 0号点既是根节点,又是空节点// son[][]存储树中每个节点的子节点// cnt[]存储以每个节点结尾的单词数量// 插入一个字符串void insert(char *str){ int p = 0; for (int i = 0; str[i]; i ++ ) { int u = str[i] - 'a'; if (!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } cnt[p] ++ ;}// 查询字符串出现的次数int query(char *str){ int p = 0; for (int i = 0; str[i]; i ++ ) { int u = str[i] - 'a'; if (!son[p][u]) return 0; p = son[p][u]; } return cnt[p];}
#include <algorithm>#include <iostream>using namespace std;typedef long long LL;const int N = 100010, M = 32 * N;int son[M][2], idx;LL input[N];void insert(int x) { int p = 0; // Trie root for (int i = 30; i >= 0; i--) { int u = x >> i & 1; // 取x的第i位的二进制数 if (!son[p][u]) son[p][u] = ++idx; // 插入过程中没有发现孩子节点,则设之 p = son[p][u]; // 指针指向下一层 }}int search(int x) { int p = 0, res = 0; for (int i = 30; i >= 0; i--) { int u = x >> i & 1; // 从最高位开始查找 if (son[p][!u]) { // 如果当前层有对应的不相同的数,p指针就指向不同数的地址; p = son[p][!u]; res = res * 2 + 1; } else { p = son[p][u]; res = res * 2 + 0; } } return res;}int main() { cin.tie(0); int n; cin >> n; idx = 0; for (int i = 0; i < n; i++) { cin >> input[i]; insert(input[i]); } int res = 0; for (int i = 0; i < n; i++) { res = max(res, search(input[i])); /// search(a[i])查找的是a[i]值的最大与或值 } cout << res << endl; return 0;}
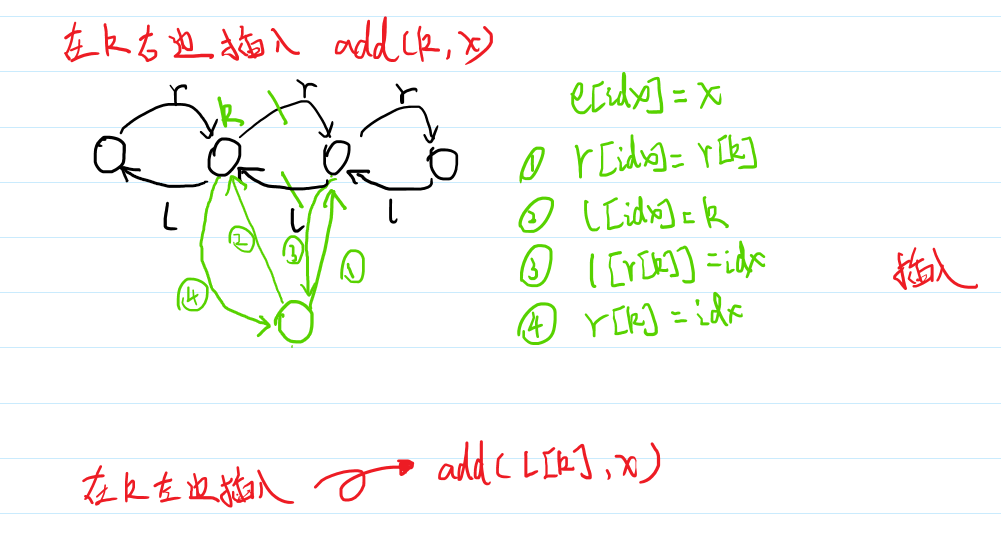
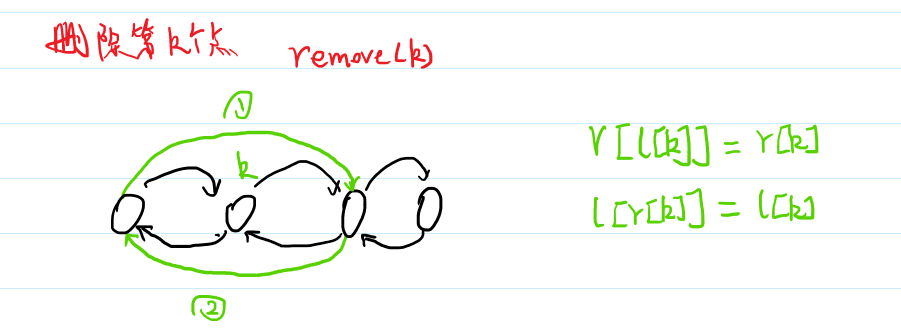
并查集
优势:
将两个集合合并
询问两个元素是否在一个集合当中
/*************Init****************/int fa[MAXN]; // 存每个节点的父亲inline void init(int n){ // 初始化,每个节点初始时的父亲都是自身(自环) for (int i = 1; i <= n; ++i) fa[i] = i;}/*************Find****************/int find(int x) //递归地查找最顶层的父亲{ if(fa[x] == x) return x; else return find(fa[x]);}/*************Merge****************/inline void merge(int i, int j){ fa[find(i)] = find(j); // 将i与j合并到同一个集合}/*************Erase****************/struct dsu { vector<size_t> pa, size; explicit dsu(size_t size_) : pa(size_ * 2), size(size_ * 2, 1) { iota(pa.begin(), pa.begin() + size_, size_); iota(pa.begin() + size_, pa.end(), size_); } void erase(size_t x) { --size[find(x)]; pa[x] = x; }};/*************Move****************/void dsu::move(size_t x, size_t y) { auto fx = find(x), fy = find(y); if (fx == fy) return; pa[x] = fy; --size[fx], ++size[fy];}/*************Compress****************/int find(int x) // 路径压缩查找{ if(x == fa[x]) return x; else{ fa[x] = find(fa[x]); //父节点设为根节点 return fa[x]; //返回父节点 }}/************Rank-based Merge************/inline void init(int n) // 按秩合并{ for (int i = 1; i <= n; ++i) { fa[i] = i; rank[i] = 1; }}inline void merge(int i, int j){ int x = find(i), y = find(j); //先找到两个根节点 if (rank[x] <= rank[y]) fa[x] = y; else fa[y] = x; if (rank[x] == rank[y] && x != y) rank[y]++; //如果深度相同且根节点不同,则新的根节点的深度+1}
// 模拟堆#include <iostream>using namespace std;const int N = 100010;int h[N]; // h[N]存储堆中的值, h[1]是堆顶,x的左儿子是2x, 右儿子是2x + 1int ph[N]; // ph[k]存储第k个插入的点在堆中的位置int hp[N]; // hp[k]存储堆中下标是k的点是第几个插入的int hsize = 0; // 堆的规模void heap_swap(int a, int b) { // 交换两个点,及其映射关系 swap(ph[hp[a]], ph[hp[b]]); swap(hp[a], hp[b]); swap(h[a], h[b]);}void down(int u) { // 下滤 int t = u; if (u * 2 <= hsize && h[u * 2] < h[t]) t = u * 2; // 从指定节点开始,比较节点与其子节点的值, if (u * 2 + 1 <= hsize && h[u * 2 + 1] < h[t]) t = u * 2 + 1; if (u != t) { // 将其与两个子节点中较小的一个交换,直到节点值小于其子节点或已经是叶子节点 heap_swap(u, t); down(t); }}void up(int u) { // 上滤 while (u / 2 && h[u] < h[u / 2]) { heap_swap(u, u / 2); u >>= 1; }}int main() { int n, m = 0; cin >> n; while (n--) { string opt; int k, x; cin >> opt; if (opt == "I") { // 插入x cin >> x; h[++hsize] = x; m++; ph[m] = hsize; // 更新ph数组 hp[hsize] = m; // 更新hp数组 up(hsize); } else if (opt == "PM") { cout << h[1] << endl; } else if (opt == "DM") { heap_swap(1, hsize); hsize--; down(1); } else if (opt == "D") { cin >> k; int tmp = ph[k]; heap_swap(tmp, hsize); hsize--; down(tmp); up(tmp); } else { cin >> k >> x; int tmp = ph[k]; h[tmp] = x; down(tmp); up(tmp); } } return 0;}
Priority_Queue
#include <iostream>#include <queue>#include <vector>using namespace std;// 定义一个小顶堆(改成less就是大顶堆)priority_queue<int, vector<int>, greater<int>> minHeap;int main() { int n, m; cin >> n >> m; // 读取所有元素并添加到小顶堆中 for (int i = 0; i < n; i++) { int x; cin >> x; minHeap.push(x); } // 输出前m个最小的元素 for (int i = 0; i < m; i++) { // 由于是小顶堆,所以堆顶是最小的元素 cout << minHeap.top() << " "; minHeap.pop(); // 移除堆顶元素,下一个最小的元素将移动到堆顶 } return 0;}
哈希表
哈希操作
// 拉链法int h[N], e[N], ne[N], idx;// 向哈希表中插入一个数void insert(int x){ int k = (x % N + N) % N; // 让余数变为正数,k就是哈希值,C++中对负数取模比较诡异 e[idx] = x; // 链表的插入操作 ne[idx] = h[k]; h[k] = idx ++ ;}// 在哈希表中查询某个数是否存在bool find(int x){ int k = (x % N + N) % N; for (int i = h[k]; i != -1; i = ne[i]) if (e[i] == x) return true; return false;}//开放寻址法//经验上说,这里数组长度要开到题目的数据范围的2~3倍int h[N];// 如果x在哈希表中,返回x的下标;如果x不在哈希表中,返回x应该插入的位置int find(int x){ int t = (x % N + N) % N; while (h[t] != null && h[t] != x) //这里null设置一个不在数据范围内的任意数即可,作为位置为空的标记 { t ++ ; if (t == N) t = 0; } return t;}
注意初始化 h[N] 数组
在 main 函数开始处,应当首先对 h[N] 数组进行初始化,否则会导致 insert 和 find 函数行为异常:在独立链表法实现的哈希表中,h[]数组用于存储各个链表的头节点索引,因此在使用之前需要将其初始化为某个不可能的索引值,通常是-1,表示空链表。如果不进行这一步,h[]数组的初始值将是未定义的,这可能导致你的find函数遍历未初始化的链表,从而极大地增加计算时间,特别是当h[k]偶然被初始化为一个非常大的值时。
如何进行初始化?
在 C++中建议使用 fill(h, h + N, -1); 语句进行初始化。在C++中,fill函数是一个标准库函数,用于给容器或数组中的所有元素赋相同的值。其原型定义在头文件<algorithm>中,形式如下:
void fill (ForwardIterator first, ForwardIterator last, const T& value);
first 和 last 是迭代器,分别指向要填充范围的起始位置和终点位置(不包括 last)。
value 是要赋给指定范围内所有元素的值。
fill函数与memset的优势
C 中有一个臭名昭著的初始化函数 memset ,为什么不用它?主要考虑以下几点:
类型安全:fill是类型安全的,可以用于任何数据类型的容器或数组,而memset仅适用于字符数组或需要按字节操作的场景。memset在处理非POD(Plain Old Data)类型时可能会导致未定义行为。