4-1 列表实现栈
#include "../List/List.h" //以列表为基类,派生出栈模板类
template <typename T> class Stack: public List<T> { //将列表的首/末端作为栈底/顶
public: //size()、empty()以及其它开放接口,均可直接沿用
void push ( T const& e ) { insertAsLast ( e ); } //入栈:等效于将新元素作为列表的末元素插入
T pop() { return remove ( last() ); } //出栈:等效于删除列表的末元素
T& top() { return last()->data; } //取顶:直接返回列表的末元素
};
这里直接将列表结构视作栈结构,并借助List类已有的操作接口,实现Stack类所需的操作接口。具体地,列表的头部对应于栈底,尾部对应于栈顶。于是,栈顶元素总是与列表的末节点相对应;为将某个元素压入栈中,只需将其作为末节点加至列表尾部;反之,为弹出栈顶元素,只需删除末节点,并返回其中存放的元素。
请注意,这里还同时默认地继承了List类的其它开放接口,但它们的语义与Vector类所提供的同名操作接口可能不尽相同。比如查找操作,List::find()通过返回值(位置)为NULL来表示查找失败,而Vector()则是通过返回值(秩)小于零来表示查找失败。因此在同时还使用了这些接口的算法中,需要相应地就此调整代码实现。
比如,在基于栈结构实现的八皇后算法 placeQueens()中,(局部)解存放于栈 solu 中,一旦经过 solu.find(q)操作确认没有冲突,即加入一个皇后。教材中所实现版本中的栈结构派生自 Vector 类,故可通过检查 find()所返回的秩是否非负来判定查找是否成功。若改由 List 类派生出栈结构,则需相应地调整此句。
另外,将列表节点与栈元素之间的对应次序颠倒过来,从原理上讲也是可行的。但是,同样出于以上考虑,我们还是更加倾向于采用以上的对应次序。如此,栈中元素的逻辑次序与它们在向量或列表中的逻辑次序一致,从而使得栈的标准接口之外的接口具有更好的兼容性。
以 hanoi()算法为例,为了显示盘子移动的过程,必须反复地遍历栈中的元素(盘子)。若采用与前文相反的次序,则针对栈基于 Vector 和 List 的两种实现,需要分别更改显示部分的代码;反之,则可以共享同一份代码。
4-2 向量实现队列
class MyCircularQueue {
private:
int front;
int rear;
int capacity;
vector<int> elements;
public:
MyCircularQueue(int k) {
this->capacity = k + 1;
this->elements = vector<int>(capacity);
rear = front = 0;
}
bool enQueue(int value) {
if (isFull()) {
return false;
}
elements[rear] = value;
rear = (rear + 1) % capacity;
return true;
}
bool deQueue() {
if (isEmpty()) {
return false;
}
front = (front + 1) % capacity;
return true;
}
int Front() {
if (isEmpty()) {
return -1;
}
return elements[front];
}
int Rear() {
if (isEmpty()) {
return -1;
}
return elements[(rear - 1 + capacity) % capacity];
}
bool isEmpty() {
return rear == front;
}
bool isFull() {
return ((rear + 1) % capacity) == front;
}
};
- 来自 leetcode 构造循环队列的一道题:设计循环队列-leetcode官方题解
- 向量实现队列思路类似,只是考虑扩容问题,并且仍然建议使用循环队列的模式
- 一个可行的思路是以向量低位作队头,向量高位作队尾,插入时元素追加到队尾,删除时直接移出队头元素,因此插入删除的时间复杂度是 O (1)
- 当队尾添加元素超出当前向量规模,则循环填充到向量低位(如果已有出队);若没有元素出队,则需要向量扩容,并且仍然是倍增扩容策略
4-3 栈混洗与禁形
设 B 为 A={1,2,3,…, n}的任一排列。 对 B 中任取秩为 1⇐i<j<k⇐n,
a. 试证明 B 是合法栈混洗时当且仅当不包含{k,i,j}模式
先证明“仅当”。为此可以采用反证法。 首先请注意,对于输入序列中的任意三个元素,其在输出序列中是否存在一个可行的相对排列次序,与其它元素无关。因此不妨只关注这三个元素{ i, j, k }。 接下来可注意到,无论如何,元素i和j必然先于k(弹出栈A并随即)压入中转栈S。若输出序列{ k, i, j }存在,则意味着在此三个元素中,k必然首先从栈S中弹出。而在k即将弹出之前的瞬间,i和j必然已经转入栈S;而且根据“后进先出”的规律,三者在栈S中(自顶向下)的次序必然是{ k, j, i }。这就意味着,若要k率先从栈S中弹出,则三者压入输出栈B的次序必然是{ k, j, i },而不可能是{ k, i, j }。 既然以上规律与其余元素无关,{ k, i, j }即可视作判定整体输出序列不可行的一个特征,我们不妨称之为“禁形”(forbidden pattern)。
再证明“当”。实际上只要按照下列算法,则对于不含任何禁形的输出序列,都可给出其对应的混洗过程:
stackPermutation( B[1, n] ) { //B[]为待甄别的输出序列,其中不含任何禁形
Stack S; //辅助中转栈
int i = 1; //模拟输入栈A(的栈顶元素)
for k = 1 to n { //通过迭代,依次输出每一项B[k]
while ( S.empty() || B[k] != S.top() ) //只要B[k]仍未出现在S栈顶
S.push( i++ ); //就反复地从栈A中取出顶元素,并随即压入栈S
//assert: 只要B[]的确不含任何禁形,则以上迭代就不可能导致栈A溢出
//assert: 以上迭代退出时,S栈必然非空,且S的栈顶元素就是B[k]
S.pop(); //因此,至此只需弹出S的栈顶元素,即为我们所希望输出的B[k]
}
}
该算法尽管包含两重循环,但其中实质的 push()和 pop()操作均不超过 O(n)次,故其总体时间复杂度应线性正比于输入序列的长度。
上述算法只需略作修改,即可在 O (n)内实现对栈混洗的甄别:对于{ 1, 2, 3, …, n }的任一排列,判定其是否为栈混洗。
b.判断不包含{j+1, i, j}时 B 是栈混洗
可以证明此类序列 B 必为 A 的一个栈混洗,故亦可将: { j + 1, i, j } 视作新的一类禁形。为此,不妨将: { k, i, j } { j + 1, i, j } 分别称作“915”式禁形、“615”式禁形。 显然,此类禁形是 a) 中禁形的特例,故只需证明“当”:只要 B 中含有“915”式禁形,则必然也含有“615”式禁形——当然,两类禁形中的 i 和 j 未必一致。
以下做数学归纳。假定对于任何的k - i < d,以上命题均成立,考查k - i = d的情况。 不妨设i < j < k - 1,于是元素k - 1在B中相对于i的位置无非两种可能:
- k - 1 居于 i 的左侧(前方)
- 此时,{ k - 1, i, j }即为“915”式禁形,由归纳假设,必然亦含有“615”式禁形。
- k - 1 居于 i 的右侧(后方)
- 此时,{ k, i, k - 1 }即构成一个“615”式禁形。
c.判断 1<j<k⇐n 时不包含{k, j-1, j}未必是合法栈混洗
此类序列 B 未必是 A 的一个栈混洗,故不能将“945”式特征:
{ k, j - 1, j }
称作禁形。作为反例,不妨考查序列:B[] = { 2, 4, 1, 3 }
不难验证,其中不含任何的“945”式模式({ 3, 1, 2 }、{ 4, 1, 2 }、{ 4, 2, 3 })。
但反过来,若对序列 B[] 应用算法,却将导致错误,这说明该序列并非 A 的栈混洗。
当然,作为对 b) 中结论的又一次验证,不难看出该序列的确包含“615”式禁形:{ 4, 1, 3 }
4-4 证明栈混洗总数为 catalan(n)
易知栈混洗中每个元素在 S 中的 push 和 pop,对应于括号匹配的一次匹配,故每个栈混洗都对应于 n 对括号的一个合法表达式。
根据以上结论,只需统计 n 对括号所能组成的合法表达式数目 T(n)。由 n 对括号组成的任一合法表达式 Sn,都可唯一地分解和表示为如下形式:
其中, 和 均为合法表达式,且分别由 k 和 n-k-1对括号组成。
鉴于 k 的取值范围为 [0, n),故有如下边界条件和递推式:
T(0) = T(1) = 1
这是典型的Catalan数式递推关系,解之即得题中结论。
4-7 中缀表达式中判断操作符的优先级关系 priority ()实现
Operator optr2rank ( char op ) { //由运算符转译出编号
switch ( op ) {
case '+' : return ADD; //加
case '-' : return SUB; //减
case '*' : return MUL; //乘
case '/' : return DIV; //除
case '^' : return POW; //乘方
case '!' : return FAC; //阶乘
case '(' : return L_P; //左括号
case ')' : return R_P; //右括号
case '\0': return EOE; //起始符与终止符
default : exit ( -1 ); //未知运算符
}
}
char priority ( char op1, char op2 ) //比较两个运算符之间的优先级,运用优先级表
{ return pri[optr2rank ( op1 ) ][optr2rank ( op2 ) ]; }
4-8 实现中缀表达式转后缀表达式
只需要将 evaluate()运算中将操作数和运算符适时接至 RPN 末尾即可。追加函数 append () 可以如下实现:
void append ( char*& rpn, float opnd ) { //将操作数接至RPN末尾
int n = strlen ( rpn ); //RPN弼前长度(以'\0'结尾,长度n + 1)
char buf[64];
if ( opnd != ( float ) ( int ) opnd ) sprintf ( buf, "%.2f \0", opnd ); //浮点格式,戒
else sprintf ( buf, "%d \0", ( int ) opnd ); //整数格式
rpn = ( char* ) realloc ( rpn, sizeof ( char ) * ( n + strlen ( buf ) + 1 ) ); //扩展空间
strcat ( rpn, buf ); //RPN加长
}
void append ( char*& rpn, char optr ) { //将运算符接至RPN末尾
int n = strlen ( rpn ); //RPN弼前长度(以'\0'结尾,长度n + 1)
rpn = ( char* ) realloc ( rpn, sizeof ( char ) * ( n + 3 ) ); //扩展空间
sprintf ( rpn + n, "%c ", optr ); rpn[n + 2] = '\0'; //接入指定癿运算符
}
这里,在接入每一个新的操作数或操作符之前,都要调用 realloc()函数以动态地扩充 RPN 表达式的容量,因此会在一定程度上影响时间效率。
4-11 中缀表达式运算中根据括号数求栈规模
描述:中缀表达式计算中,操作符栈共有 502 个括号,此时栈规模至多多大?(含栈底 '\0')
解答:由该算法的原理不难看出,在其执行过程中的任何时刻,操作符栈中所存每一操作符相对于其直接后继(若存在)的优先级都要(严格地)更高。
当然,这一性质只对相邻操作符成立,故并不意味着其中所有的操作符都按优先级构成一个单调序列。在该算法中,(左)括号扮演了重要的角色——无论它是栈顶操作符,或者是表达式中的当前操作符,都会(因对应的 pri[][] 表项为’<‘而)执行压栈操作。就效果而言,如此等价于将递增的优先级复位,从而可以开始新的一轮递增。
对照 优先级表 不难验证,其它操作符均无这一特性。
因此,在(左)括号数固定的条件下,为使操作符栈中容纳更多的操作符,必须使每个(左)括号的上述特性得以充分发挥。具体地,在每个(左)括号入栈之前,应使每个优先级别的操作符都出现一次(当然,也至多各出现一次)。这里,'+' 和 '-' 同处一级,'*' 和 '/' 同处一级,'^' 自成一级,'!' 也自成一级。
需特别注意的是,根据优先级表,任何时刻操作符'!'在操作符栈中只可能存有一个,而且必定是栈顶。对于合法的表达式,此后出现的下一操作符不可能是’(‘。而无论接下来出现的是何种操作符(即便是’!’本身),该操作符都会随即出栈并执行对应的计算。
综合以上分析,为使操作符栈的规模最大,其中所存的操作符应大致排列如下图所示。不难看出,此时操作符栈的规模为: (502 + 1) x 4 + 1 = 2013:

4-12 evaluate ()对异常输入求值
evaluate() 代码实现。
异常输入:” (12)3+!4*+5”
步骤与结果
-exception.png)
不会因异常而终止
尽管上述表达式明显不合语法,但 evaluate()算法却依然能够顺利求值, 并正常退出。实际上此类实例纯属巧合,更多时候该算法在处理非法表达式时都会异常退出。
反观上例也可看出,巧合的原因在于,在该“表达式”的求值过程中,每当需要执行某一运 算时,在操作数栈中至少存有足够多操作数可供弹出并参与运算。
改进
就最低的标准而言,改进后的算法应该能够判定表达式是否合法。为此,除了需要检查括号的匹配,以及在每次试图执行运算时核对操作数栈的规模足够大,还需要确认每个操作符与其所对应操作数之间的相对位置关系符合中缀表达式(infix)的语法。最后一项检查的准则并不复杂:在每个操作符即将入栈时,操作数栈的规模应比操作符栈的规模恰好大一。
4-17 迷宫寻径
-
试举例说明,即使 nxn 迷宫内没有任何障碍格点,且起始与目标格点紧邻,也可能需要在搜索过所有 (n-2)^2 个可用格点后才能找出一条长度为 (n-2)^2 的通路。
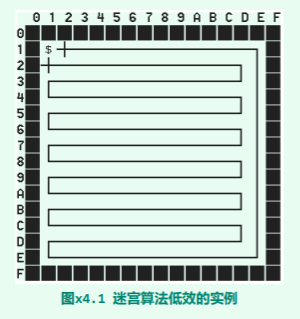 根据该算法的控制流程,在每个格点都是固定地按照东、南、西、北的次序,逐个地试探相邻的格点。因此,尽管在此例中目标终点就紧邻于起始点的西侧,也只有在按照如图所示的路线,遍历过所有的(n - 2)2个格点之后,才能抵达终点。
根据该算法的控制流程,在每个格点都是固定地按照东、南、西、北的次序,逐个地试探相邻的格点。因此,尽管在此例中目标终点就紧邻于起始点的西侧,也只有在按照如图所示的路线,遍历过所有的(n - 2)2个格点之后,才能抵达终点。 -
尝试改进,使访问格点尽可能少、路径尽可能短。 一种简便而行之有效的策略是,每次都是按随机次序试探相邻格点。
4-18 费马-拉格朗日分解
描述:任何一个自然数都可以表示为 4 个整数的平方和,这种表示形式称作费马-拉格朗日分解,比如:30 = 1^2 + 2^2 + 3^2 + 4^2。试采用试探回溯策略,实现以下算法:
- 对任一自然数 n,找出一个费马-拉格朗日分解;
- 对任一自然数 n,找出所有费马-拉格朗日分解(同一组数的不同排列规作等同);
- 对于不超过 n 的每一自然数,给出其费马-拉格朗日分解的总数。
实现:
#include <iostream>
#include <vector>
// 定义全局变量,存储分解结果
std::vector<std::vector<int>> decompositions;
// 计算 n 的费马-拉格朗日分解
bool fermatLagrangeDecomposition(int n, std::vector<int> currentDecomposition) {
if (n == 0) {
// 如果 n 等于 0,表示找到了一种分解方式
decompositions.push_back(currentDecomposition);
return true;
}
for (int i = 1; i * i <= n; ++i) {
if (currentDecomposition.size() == 4) {
// 如果当前分解中已经有 4 个数,则终止分解
return false;
}
currentDecomposition.push_back(i * i);
if (fermatLagrangeDecomposition(n - i * i, currentDecomposition)) {
// 递归寻找下一个分解
currentDecomposition.pop_back();
} else {
// 如果无法找到下一个分解,则回溯
currentDecomposition.pop_back();
}
}
return false;
}
int main() {
int n;
std::cout << "请输入一个自然数 n: ";
std::cin >> n;
// 寻找 n 的费马-拉格朗日分解
std::vector<int> currentDecomposition;
fermatLagrangeDecomposition(n, currentDecomposition);
// 输出所有分解
std::cout << n << " 的费马-拉格朗日分解为:" << std::endl;
for (const std::vector<int>& decomposition : decompositions) {
for (int i = 0; i < decomposition.size(); ++i) {
std::cout << decomposition[i];
if (i < 3) {
std::cout << " + ";
}
}
std::cout << std::endl;
}
// 输出费马-拉格朗日分解的总数
std::cout << n << " 的费马-拉格朗日分解总数为:" << decompositions.size() << std::endl;
return 0;
}
![[将整数分解为 09(每个数字只出现一次) 之间的算术运算|4-19 将整数分解为 09(每个数字只出现一次) 之间的算术运算]]
4-23 使用队列接口实现二路归并
无论 Vector::merge() 还是 List::merge(),所用到的操作无非两类:从两个输入序列的前端删除元素,将元素插入至输出序列的后端
因此,可使用队列的接口来实现该算法:
可以将 Vector 或 List 结构的首、末两端,与 Queue 结构的首、末两端相对应,并约定队列中的各元素从队首至队末,按单调非降次序排列。于是,对待归并序列(队列)的操作,仅限于调用 front()接口(取各序列的首元素并比较大小)和 dequeue()接口(摘出首元素中的小者);而对合成序列(队列)的操作,仅限于调用 enqueue()接口(将摘出的元素归入序列)。
实际上,使用栈的ADT接口,也可简洁地描述和实现归并排序算法。当然,每次归并之后,还需随即对合成的序列(栈)做一次倒置操作reverse()
4-24 孪生栈
描述:基于向量模板类 Vector 实现栈结构时,为了进一步提高空间的利用率,可以考虑在一个向量内同时维护两个栈。它们分别以向量的首、末元素为栈底,并相向生长。为此,对外的入栈和出栈操作接口都需要增加一个标志位,用一个比特来区分实施操作癿的栈。具体地,入栈接口形式为 push(0, e)和 push(1, e),出栈接口形式为 pop(0)和 pop(1)。
实现:
#include <vector>
class TwinStack {
private:
std::vector<int> data;
int size1 = 0;
int size2 = 0;
// 扩容函数
void expand() {
std::vector<int> new_data(data.size() * 2);
for(int i = 0; i < size1; i++) {
new_data[i] = data[i];
}
for(int i = 0; i < size2; i++) {
new_data[new_data.size()-size2+i] = data[data.size()-size2+i];
}
data = new_data;
}
public:
TwinStack() {
data.resize(1);
}
// 在栈1顶部插入元素
void push1(int val) {
if (size1 + size2 == data.size()) {
expand();
}
data.insert(data.begin() + size1, val);
size1++;
}
// 在栈2顶部插入元素
void push2(int val) {
if (size1 + size2 == data.size()) {
expand();
}
data.insert(data.end() - size2 - 1, val);
size2++;
}
// 删除栈1顶部元素
int pop1() {
if (size1 == 0) return -1; // 栈为空
int top = data[size1-1];
data.erase(data.begin() + size1-1);
size1--;
return top;
}
// 删除栈2顶部元素
int pop2() {
if (size2 == 0) return -1;
int top = data[data.size()-size2];
data.erase(data.end()-size2-1);
size2--;
return top;
}
};
这个实现利用一个vector来存储两个栈的数据,一个栈从头部开始向后增长,另一个栈从尾部向前增长,并记录每个栈的大小。通过插入和删除元素来实现入栈和出栈操作。这样可以充分利用vector的空间,实现双栈的需求。