Motivation of Dual SVM
上节课提到,我们要实现非线性的 SVM ,就必须要借助特征转换这个工具:
不过在涉及到特征转换时,要求解这个 QP 问题就会比较麻烦:

- 这里 就是特征转换的空间维数,QP 的解法就与 个变量和样本规模 的限制有关,当 非常大时,计算效率很低;
因此我们的目标是移除 SVM 在空间维数 上的依赖:
- 我们提出等价的 SVM ,称为 Dual SVM(对偶支持向量机),其只与样本规模 N 有关:

Regularization and Dual SVM
那么如何实现这种等价互换呢?回想之前使用 正则化 对高维空间的限制:

- 在这里,左右两式可以通过求梯度 建立联系,从而得知 与 实际上是等价的,在正则化中我们将 视作 的一个替代;
那么在 Dual SVM 中,我们也将 视作未知的既定限制,作为变量来求解,并且 SVM 中限制条件数与输入样本的规模相同(限制条件为 ,即对所有输入样本的判断都正确),因此作为变量求出的 数量将会有 个。故,原本有条件限制的 SVM 问题:
就可以利用拉格朗日乘子 设立拉格朗日函数,求解极值:
这里 objective 部分就是要求解的极小值的部分,constaint 部分就是限制条件 (这里与大陆课本的拉格朗日函数不同, 实际上充作了课本中的那个作为限制条件的系数的 ,这里的差异不过是为了前后 符号的含义统一,无需疑虑)
现在,我们可以将 SVM 问题看作是求解拉格朗日函数的问题:
这里要分析,
- 如果拉格朗日函数中限制条件 为正,说明这样的 违反了限制,要使得拉格朗日函数最大,就会一直增长到无穷大;
- 而若限制条件为负,则说明可行,因此拉格朗日函数最大也不超过 ;
最终,我们将 SVM 中的限制纳入了对拉格朗日函数求最值的问题中。
练习:写出拉格朗日函数的形式

Lagrange Dual SVM
我们继续思考上述的拉格朗日函数,由于其要取 ,因此在 前提下,任意特定 都满足:
因此,选择所有 中最佳的 ,也可以满足上面的关系,即:
右侧式子称为该拉格朗日问题的对偶问题。不过此时左右两式关系是 ,称为 weak duality ;如果能够证明为 关系,那就可以解右式从而得到左式的解,这称为 strong duality 。经过 QP 问题的研究,如果目标问题满足:函数为凸、原问题有解、线性条件限制,那么 就成立,幸运的是,在这里刚好满足这三个条件(constraint qualification)。
Solution for Langrange Dual Problem
因此,我们可以展开右侧对偶式进行求解:
该式内部的拉格朗日函数的最小值即是在“谷底”,我们可以通过求解梯度来获得:
既然最佳解最后必然满足这个条件,那么我们在求解最小值前就先将这个条件附加上,那么就可以得到:
,另一方面,在“谷底”对 也会满足:
写成向量形式,就是:
同理,我们可以最终化简问题为:
因此,这最后就变成只有 的一个最大化问题。
上述的过程中用到的限制条件称为 KKT Optimality Conditions :

- 这些条件是:原问题可解、可以实现对偶、对偶后的内部可以求得最优解、原问题的内部也可以求得最优解;
- 从此,找到最优的 就可以求解原问题。
练习:理解 KKT 条件

Solving Dual SVM
Specific QP Solver is Better
将上文最终的对偶问题写成最小化的形式,我们就可以得到:
即,我们实现了本堂课开头的转换——将 SVM 问题转换为 个变量、 个限制的对偶问题。那么如何解这个问题呢?当然还是 QP 问题:
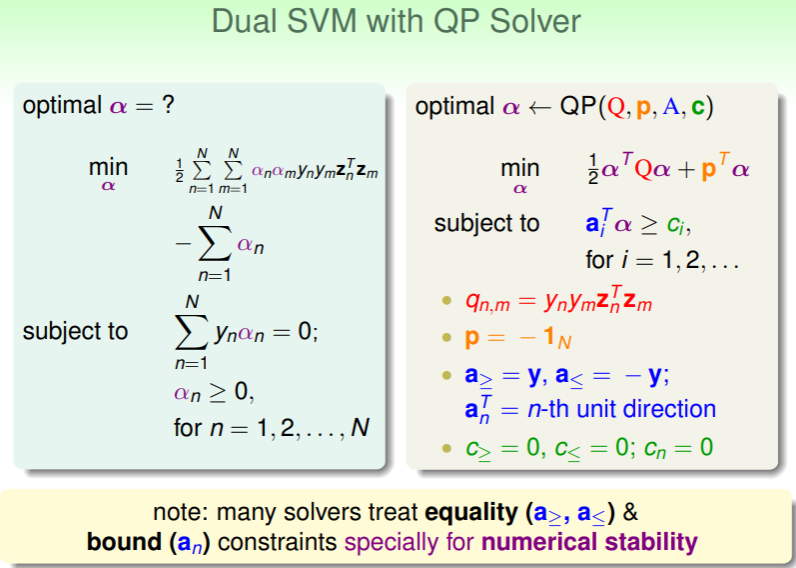
- 不过这个 QP 问题直接套用这种通用的 QP solver 的话,还需要进行一些考量:

- 在该对偶问题中当样本数 极大时,仅用于存放 这个稠密矩阵都将会占用过多的内存空间,因此有特定的针对 SVM 问题的 QP solver ,可以不必存储它;
回过头来从 KKT 条件中审视这个找最优的问题,我们可以得知:

- 要求得最佳的 ,就要求得最佳的 ,
- 而要求得最佳的 ,则在 条件下,可以推得 这样一系列的解, 代表着 SVM 可以活动的范围——就是 SVM boundary 的宽度;
练习:算出最佳的 b

Message behind Dual SVM
SV Candidate ?
还记得之前我们说 SVM 边界上的点其实是 候选者 (candidate)吗?现在从 Dual SVM 的角度,我们再来审视这个候选者的说法:

- 在 Dual SVM 中,我们会对样本添加一个 ,只有边界上点的 ,才有考虑的价值,此时它才从候选者中脱颖而出——成为真正的 Support Vector ;
- 因此,只有真正的支撑向量在计算 和 时才会贡献价值:
- 计算 时要考虑所有 SV : ,
- 计算 时只需要一个 SV 即可:;
SVM and PLA
通过对偶问题,我们可以求解得 ,从而求出 SVM 的最佳权重向量 ,这个式子似乎有些熟悉?回顾 PLA 中的权重向量求解公式:

- 我们可以得知,这两种模型的 都是原始资料的线性组合,并且这个结论对从 开始做对梯度下降或随机梯度下降的逻辑回归或线性回归也是成立的,这时 就称为由原始资料能够表示的最佳权重;
- 因此所谓 SVM ,就是可以仅有 SV 表示最佳权重 的模型;
Primal SVM Vs. Dual SVM
上节课我们讲述的 Primal SVM 和这节课讲的 Dual SVM 究竟有什么区别与联系呢?
- Primal SVM 适合在样本维数 较小时使用,它的物理含义就是通过特殊的放缩找到最佳的 ;
- Dual SVM 通过对偶问题,规约了样本维数,使 SVM 直接关联样本数,它的物理含义就是找到真正的 SV 和对应的 ,通过这些重建 SVM 边界;
- 二者最后都会得到最佳的 ,从而找到最合适的 hyperplane ,最终求得 ;

Hidden Dimension
还记得这节课的目标吗?我们想要消除样本维数 对 SVM 求解时的性能限制,Dual SVM 确实解决了一部分,但它真的消除了对 的依赖了吗?其实在计算 QP 问题的 矩阵里,这个内积的计算仍然是在 空间中的,因此还是对其有依赖的。
下节课我们将进一步避开在 中的计算,且听下回分解。
练习:计算 SV candidates