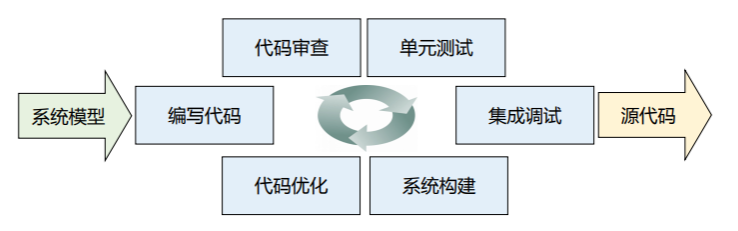
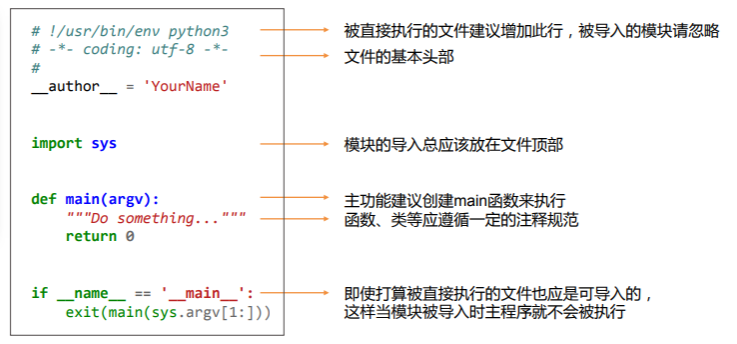
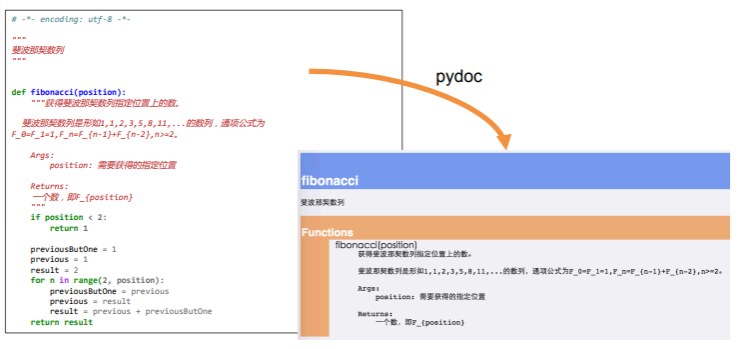
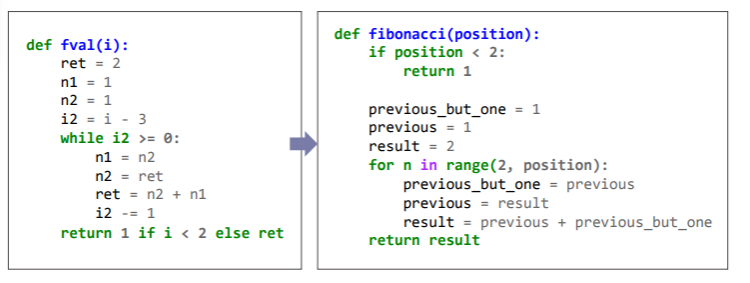
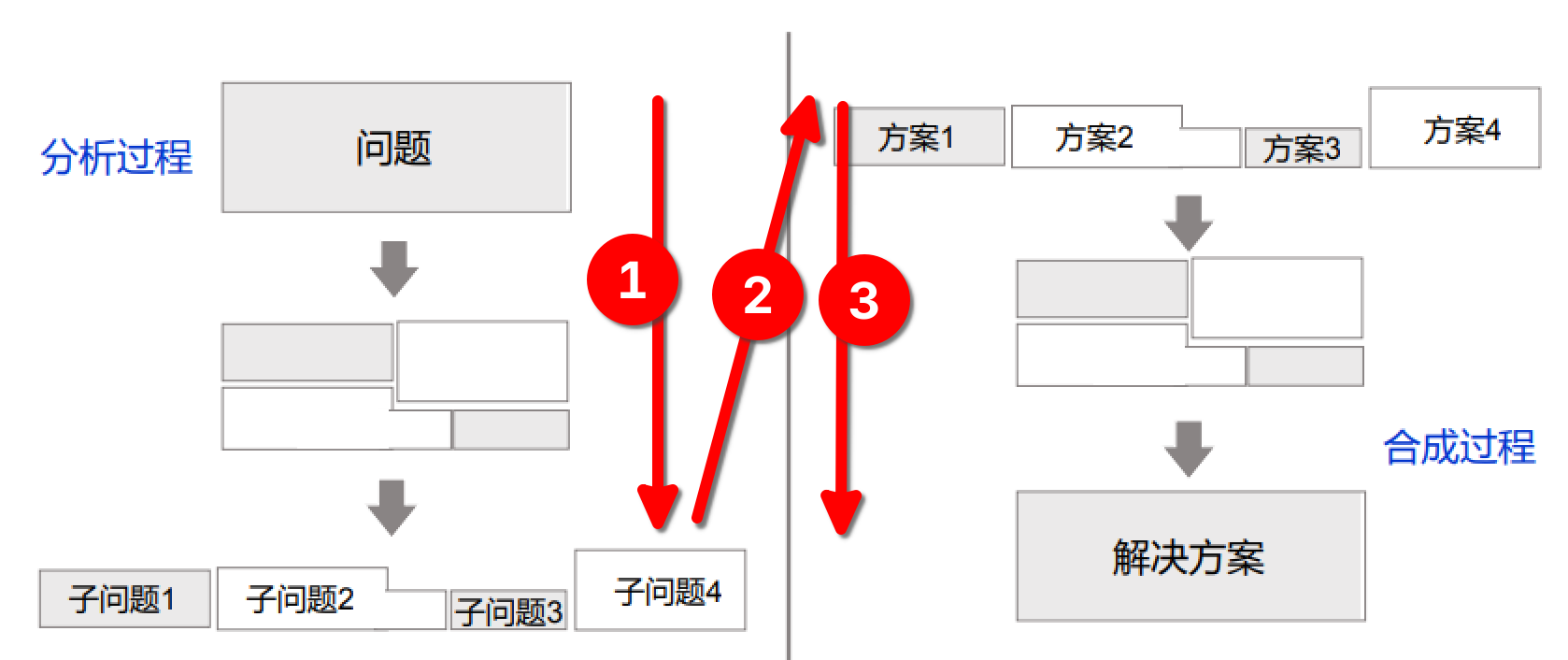
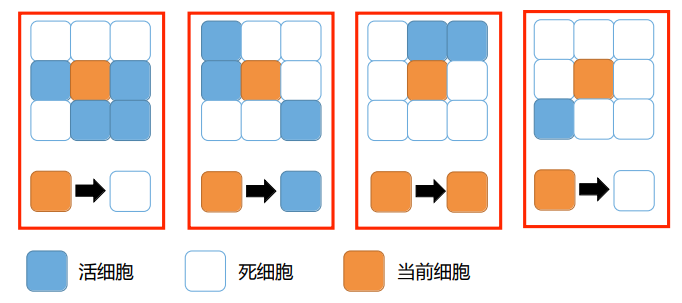
if __name__ == '__main__ 语句的作用:检查文件是否是直接执行。因为 pydoc 、单元测试等场景中,都要求每一个文件都是可导入的,而且考虑到代码的最大可重用性,即使部分文件是打算直接执行的,但未来也有被其它文件作为模块导入的可能。加上对 name 的判断后,主程序只有在被直接执行时才会执行,其他情况下则作为模块导入。
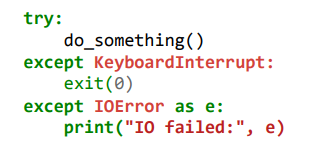
However, you may put the result of a test on the same line as the test only if the entire statement fits on one line. In particular, you can never do so with try/except since the try and except can’t both fit on the same line, and you can only do so with an if if there is no else.
# coding=utf-8# Simple Caeser Codeimport stringshift = 3choice = input("Would you like to encode or decode?")word = input("Please enter (E)ncode or (D)ecode:")letters = string.ascii_letters + string.punctuation + string.digitsencoded = ""if choice == "E": for letter in word: if letter == " ": encoded = encoded + " " else: x = letters.index(letter) + shift encoded = encoded + letters[x]if choice == "D": for letter in word: if letter == " ": encoded = encoded + " " else: x = letters.index(letter) - shift encoded = encoded + letters[x]print(encoded)
分析结果及报告如下:
❯ pylint --reports=y simplecaeser.py************* Module simplecaesersimplecaeser.py:1:0: C0114: Missing module docstring (missing-module-docstring)simplecaeser.py:5:0: C0103: Constant name "shift" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:8:0: C0103: Constant name "letters" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:9:0: C0103: Constant name "encoded" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:13:12: C0103: Constant name "encoded" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:15:12: C0103: Constant name "x" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:16:12: C0103: Constant name "encoded" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:20:12: C0103: Constant name "encoded" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:22:12: C0103: Constant name "x" doesn't conform to UPPER_CASE naming style (invalid-name)simplecaeser.py:23:12: C0103: Constant name "encoded" doesn't conform to UPPER_CASE naming style (invalid-name)Report======19 statements analysed.Statistics by type------------------+---------+-------+-----------+-----------+------------+---------+|type |number |old number |difference |%documented |%badname |+=========+=======+===========+===========+============+=========+|module |1 |1 |= |0.00 |0.00 |+---------+-------+-----------+-----------+------------+---------+|class |0 |NC |NC |0 |0 |+---------+-------+-----------+-----------+------------+---------+|method |0 |NC |NC |0 |0 |+---------+-------+-----------+-----------+------------+---------+|function |0 |NC |NC |0 |0 |+---------+-------+-----------+-----------+------------+---------+27 lines have been analyzedRaw metrics-----------+----------+-------+------+---------+-----------+|type |number |% |previous |difference |+==========+=======+======+=========+===========+|code |22 |81.48 |NC |NC |+----------+-------+------+---------+-----------+|docstring |0 |0.00 |NC |NC |+----------+-------+------+---------+-----------+|comment |2 |7.41 |NC |NC |+----------+-------+------+---------+-----------+|empty |3 |11.11 |NC |NC |+----------+-------+------+---------+-----------+Duplication-----------+-------------------------+------+---------+-----------+| |now |previous |difference |+=========================+======+=========+===========+|nb duplicated lines |0 |0 |0 |+-------------------------+------+---------+-----------+|percent duplicated lines |0.000 |0.000 |= |+-------------------------+------+---------+-----------+Messages by category--------------------+-----------+-------+---------+-----------+|type |number |previous |difference |+===========+=======+=========+===========+|convention |10 |10 |10 |+-----------+-------+---------+-----------+|refactor |0 |0 |0 |+-----------+-------+---------+-----------+|warning |0 |0 |0 |+-----------+-------+---------+-----------+|error |0 |0 |0 |+-----------+-------+---------+-----------+Messages--------+-------------------------+------------+|message id |occurrences |+=========================+============+|invalid-name |9 |+-------------------------+------------+|missing-module-docstring |1 |+-------------------------+------------+------------------------------------------------------------------Your code has been rated at 4.74/10 (previous run: 4.74/10, +0.00)
对其中内容我们详细讲解:
首先是 pylint 对错误列表进行分析:
图片中错误列表的每一行从左到右的内容分别是错误类型、出现位置、说明信息:
我们的输出部分与图片中不太一样,这是因为版本比较新的缘故,其中给出了错误代号,比如 invalid-name 的错误代号是 C0103 ,具体代号对应什么错误,可以参考相关 wiki :PyLint Messages
这里 C 类型的报错是指其与 pylintrc 文件中制定的编码标准约定不相符;R 类型报错是指该段代码写得极其糟糕,需要重构;W 类型报错是指其触发了 Python 特定的问题;E 类型报错是指代码中可能存在的语法等错误;
接下来我们细看 pylint 的报告:
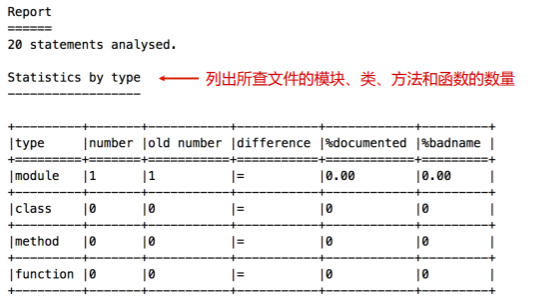
首先会报告 pylint 所检查文件的模块、类、方法和函数的数量:
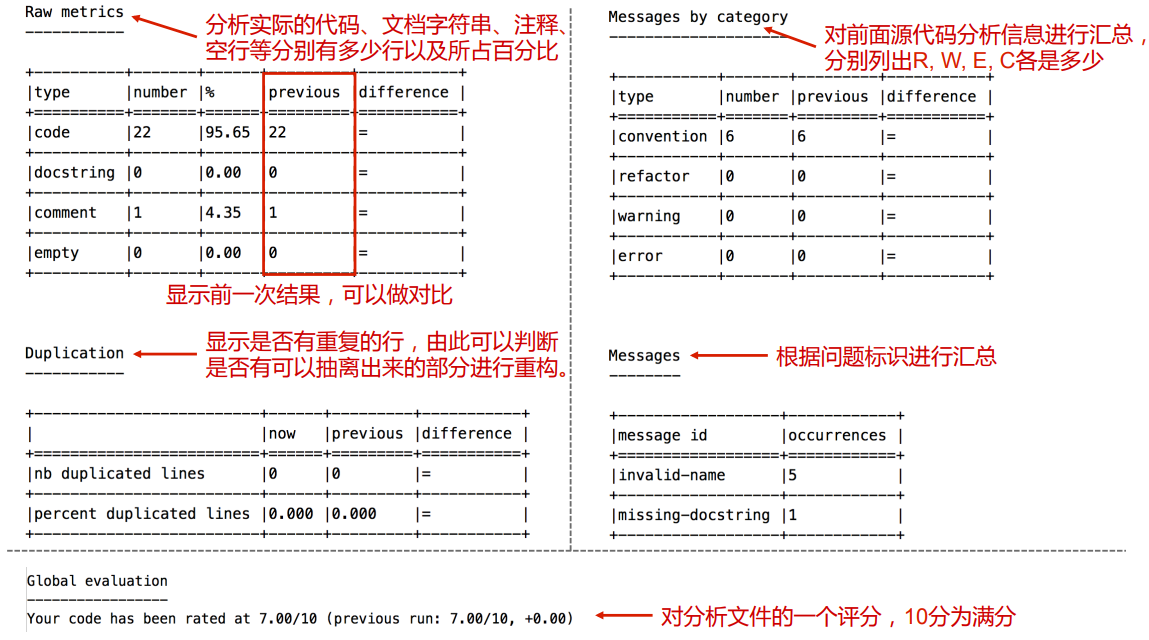
接着会报告文件中代码、注释等部分占比,是否有重复行,汇总之前列出的错误数量,最终给出对文件的评分:
一切基于 pylintrc
pylint 进行检查的一切根据都是来自 pylintrc 这个配置文件,这也是它 high customized 特性的来源,因此建议使用普遍认可的 pylintrc 文件,比如 Google 给出的:pylintrc
实验输入为一个含有标点符号的英文文献。其中,将所有连续的英文字母视作一个单词,仅以句号“.”、问号“?”、感叹号“!”结尾的才视作一个完整的句子。例如:“fdafa”、“a”、“b”均是一个单词,而“I‘m a boy.”是一个句子,它含有“I”、“m”、“a”、“boy”四个单词;但“I am a boy,”则不是一个完整的句子,因为其以逗号“,”结尾。若最后一句话没有结束符号,则视为不完整的句子,不计入结果。