equal ()
可以用和比较字符串类似的方式来比较序列。如果两个序列的长度相同,并且对应元素都相等,equal () 算法会返回 true。
有 4 个版本的 equal () 算法,其中两个用 == 运算符来比较元素,另外两个用我们提供的作为参数的函数对象来比较元素,所有指定序列的迭代器都必须至少是输入迭代器。
- 用 == 运算符来比较两个序列的第一个版本期望 3 个输入迭代器参数,前两个参数是第一个序列的开始和结束迭代器,第三个参数是第二个序列的开始迭代器。如果第二个序列中包含的元素少于第一个序列,结果是未定义的。
- 用 == 运算符的第二个版本期望 4 个参数:第一个序列的开始和结束迭代器,第二个序列的开始和结束迭代器,如果两个序列的长度不同,那么结果总是为 false。本节会演示这两个版本,但推荐使用接受 4 个参数的版本,因为它不会产生未定义的行为。
下面是一个演示如何应用它们的示例:
// Using the equal() algorithm
#include <iostream> // For standard streams
#include <vector> // For vector container
#include <algorithm> // For equal() algorithm
#include <iterator> // For stream iterators
#include <string> // For string class
using std::string;
int main()
{
// Initialize two vectors with strings
std::vector<string> words1 {"one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
std::vector<string> words2 {"two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"};
// Create iterators to the beginning and end of the two vectors
auto iter1 = std::begin(words1);
auto end_iter1 = std::end(words1);
auto iter2 = std::begin(words2);
auto end_iter2 = std::end(words2);
// Output the contents of the two vectors
std::cout << "Container - words1:";
std::copy(iter1, end_iter1, std::ostream_iterator<string>{std::cout, " "});
std::cout << "\nContainer - words2:";
std::copy(iter2, end_iter2, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
// 1. Compare from words1[1] to end with words2:
std::cout << "1. Compare from words1[1] to end with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2) << std::endl;
// 2. Compare from words2[0] to second-to-last with words1:
std::cout << "2. Compare from words2[0] to second-to-last with words1:";
std::cout << std::boolalpha << std::equal(iter2, end_iter2 - 1, iter1) << std::endl;
// 3. Compare from words1[1] to words1[5] with words2:
std::cout << "3. Compare from words1[1] to words1[5] with words2:";
std::cout << std::boolalpha << std::equal(iter1 + 1, iter1 + 6, iter2) << std::endl;
// 4. Compare first 6 from words1 with first 6 in words2:
std::cout << "4. Compare first 6 from words1 with first 6 in words2:";
std::cout << std::boolalpha << std::equal(iter1, iter1 + 6, iter2, iter2 + 6) << std::endl;
// 5. Compare all words1 with words2:
std::cout << "5. Compare all words1 with words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2) << std::endl;
// 6. Compare all of words1 with all of words2:
std::cout << "6. Compare all of words1 with all of words2:";
std::cout << std::boolalpha << std::equal(iter1, end_iter1, iter2, end_iter2) << std::endl;
// 7. Compare from words1[1] to end with words2 from first to second-to-last:
std::cout << "7. Compare from words1[1] to end with words2 from first to second-to-last:";
std::cout << std::boolalpha << std::equal(iter1 + 1, end_iter1, iter2, end_iter2 - 1) << std::endl;
}
输出结果为:
Container - words 1: one two three four five six seven eight nine
Container - words 2: two three four five six seven eight nine ten
1. Compare from words 1[1] to end with words 2: true
2. Compare from words 2[0] to second-to-last with words 1: false
3. Compare from words 1[1] to wordsl[5] with words 2: true
4. Compare first 6 from words 1 with first 6 in words 2: false
5. Compare all wordsl with words 2: false
6. Compare all of words 1 with all of words 2: false
7. Compare from words 1[1] to end with words 2 from first to second_to_last: true
在这个示例中,对来自于 words 1 和 words 2 容器的元素的不同序列进行了比较。equal () 调用产生这些输出的原因如下:
- 第 1 条语句的输出为 true,因为 words 1 的第二个元素到最后一个元素都从 words 2 的第一个元素开始匹配。第二个序列的元素个数比第一个序列的元素个数多 1,但 第一个序列的元素个数决定了比较多少个对应的元素。
- 第 2 条语句的输出为 false,因为有直接的不匹配;words 2 和 words 1 的第一个元素不同。
- 第 3 条语句的输出为 true,因为 word 1 中从第二个元素开始的 5 个元素和 words 2 的前五个元素相等。
- 在第 4 条语句中,words 2 的元素序列是由开始和结束迭代器指定的。序列长度相同,但它们的第一个元素不同,所以结果为 false。
- 在第 5 条语句中,两个序列的第一个元素直接就不匹配,所以结果为 false。
- 第 6 条语句的输出为 false,因为序列是不同的。这条语句不同于前面的 equal () 调用,因为指定了第二个序列的结束迭代器。
- 第 7 条语句会从 words 1 的第二个元素开始,与 word 2 从第一个元素开始比较相同个数的元素,所以输出为 true。
当用 equal () 从开始迭代器开始比较两个序列时,第二个序列用来和第一个序列比较的元素个数由第一个序列的长度决定。就算第二个序列比第一个序列的元素多,equal () 仍然会返回 true。如果为两个序列提供了开始和结束迭代器,为了使结果为 true,序列必须是相同的长度。
尽管可以用 equal () 来比较两个同种类型的容器的全部内容,但最好还是使用容器的成员函数 operator==() 来做这些事。示例中的第 6 条输出语句可以这样写:
std::cout << std::boolalpha << (words1 == words2) << " "; // false
这两个版本的 equal () 接受一个谓词作为额外的参数。这个谓词定义了元素之间的等价 比较。下面是一个说明它们用法的代码段:
std::vector<string> r1 { "three", "two", "ten"};
std::vector<string> r2 {"twelve", "ten", "twenty" };
std::cout << std::boolalpha<< std::equal (std::begin (r1) , std::end (r1) , std::begin (r2),[](const string& s1, const string& s2) { return s1[0] = s2[0]; })<< std::endl; // true
std::cout << std::boolalpha<<std::equal(std::begin(r1), std::end(r1), std::begin(r2), std::end(r2),[](const string& s1, const string& s2) { return s1[0] == s2[0]; }) << std::endl; // true
在 equal () 的第一次使用中,第二个序列是由开始迭代器指定的。谓词是一个在字符串 参数的第一个字符相等时返回 true 的 lambda 表达式。最后一条语句表明,equal () 算法可以使用两个全范围的序列,并使用相同的谓词。
不应该用 equal () 来比较来自于无序 map 或 set 容器中的元素序列。在无序容器中,一组给定元素的顺序可能和保存在另一个无序容器中的一组相等元素不同,因为不同容器的元素很可能会被分配到不同的格子中。
mismatch ()
equal () 算法可以告诉我们两个序列是否匹配。mismatch () 算法也可以告诉我们两个序列是否匹配,而且如果不匹配,它还能告诉我们不匹配的位置。
mismatch () 的 4 个版本和 equal () 一样有相同的参数——第二个序列有或没有结束迭代器,有或没有定义比较的额外的函数对象参数。
mismatch () 返回的 pair 对象包含两个迭代器。它的 first 成员是一个来自前两个参数所指定序列的迭代器,second 是来自于第二个序列的迭代器。当序列不匹配时,pair 包含的迭代器指向第一对不匹配的元素;因此这个 pair 对象为 pair<iter1+n,iter2 + n>,这两个序列中索引为 n 的元素是第一个不匹配的元素。
当序列匹配时,pair 的成员取决于使用的 mismatch () 的版本和具体情况。iter 1 和 end_iter 1 表示定义第一个序列的迭代器,iter 2 和 end_iter 2 表示第二个序列的开始和结束迭代器。返回的匹配序列的 pair 的内容如下:
对于 mismatch (iter 1,end_iter 1,iter 2):
- 返回 pair<end_iter1,(iter2 + (end_ter1 - iter1))>,pair 的成员 second 等于 iter 2 加上第一个序列的长度。如果第二个序列比第一个序列短,结果是未定义的。
对于 mismatch (iterl, end_iter 1, iter 2, end_iter 2):
- 当第一个序列比第二个序列长时,返回 pair<end_iter1, (iter2 + (end_iter1 - iter1))>,所以成员 second 为 iter 2 加上第一个序列的长度。
- 当第二个序列比第一个序列长时,返回 pair<(iter1 + (end_iter2 - iter2)),end_iter2>, 所以成员 first 等于 iter 1 加上第二个序列的长度。
- 当序列的长度相等时,返回 pair<end_iter1, end_iter2>。
不管是否添加一个用于比较的函数对象作为参数,上面的情况都同样适用。
下面是一个使用带有默认相等比较的 mismatch () 的示例:
// Using the mismatch() algorithm
#include <iostream> // For standard streams
#include <vector> // For vector container
#include <algorithm> // For equal() algorithm
#include <string> // For string class
#include <iterator> // For stream iterators
using std::string;
using word_iter = std::vector<string>::iterator;
int main()
{
std::vector<string> words1 {"one", "two", "three", "four", "five", "six", "seven", "eight", "nine"};
std::vector<string> words2 {"two", "three", "four", "five", "six", "eleven", "eight", "nine", "ten"};
auto iter1 = std::begin(words1);
auto end_iter1 = std::end(words1);
auto iter2 = std::begin(words2);
auto end_iter2 = std::end(words2);
// Lambda expression to output mismatch() result
auto print_match = [](const std::pair<word_iter, word_iter>& pr, const word_iter& end_iter)
{
if(pr.first != end_iter)
std::cout << "\nFirst pair of words that differ are "<< *pr.first << " and " << *pr.second << std::endl;
else
std::cout << "\nRanges are identical." << std::endl;
};
std::cout << "Container - words1: ";
std::copy(iter1, end_iter1, std::ostream_iterator<string>{std::cout, " "});
std::cout << "\nContainer - words2: ";
std::copy(iter2, end_iter2, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::cout << "\nCompare from words1[1] to end with words2:";
print_match(std::mismatch(iter1 + 1, end_iter1, iter2), end_iter1);
std::cout << "\nCompare from words2[0] to second-to-last with words1:";
print_match(std::mismatch(iter2, end_iter2 - 1, iter1), end_iter2 - 1);
std::cout << "\nCompare from words1[1] to words1[5] with words2:";
print_match(std::mismatch(iter1 + 1, iter1 + 6, iter2), iter1 + 6);
std::cout << "\nCompare first 6 from words1 with first 6 in words2:";
print_match(std::mismatch(iter1, iter1 + 6, iter2, iter2 + 6), iter1 + 6);
std::cout << "\nCompare all words1 with words2:";
print_match(std::mismatch(iter1, end_iter1, iter2), end_iter1);
std::cout << "\nCompare all of words2 with all of words1:";
print_match(std::mismatch(iter2, end_iter2, iter1, end_iter1), end_iter2);
std::cout << "\nCompare from words1[1] to end with words2[0] to second-to-last:";
print_match(std::mismatch(iter1 + 1, end_iter1, iter2, end_iter2 - 1), end_iter1);
}
注意 words 2 中的内容和前面示例中的有些不同。每一次应用 mismatch () 的结果都是由定义为 print_match 的 lambda 表达式生成的。它的参数是一个 pair 对象和一个 vector<string> 容器的迭代器。使用 using 指令生成 word_iter 别名可以使 lambda 表达式的定义更简单。
在 main () 的代码中使用了不同版本的 mismatch (),它们都没有包含比较函数对象的参数。如果第二个序列只用开始迭代器指定,为了和第一个序列匹配,它只需要有和第一个序列相等长度的元素,但也可以更长。如果第二个序列是完全指定的,会由最短的序列来确定比较多少个元素。
输出如下:
Container - words 1: one two three four five six seven eight nine
Container - words 2: two three four five six eleven eight nine ten
Compare from words 1[1] to end with words 2:
First pair of words that differ are seven and eleven
Compare from words 2[0] to second-to-last with words 1:
First pair of words that differ are two and one
Compare from words 1[1] to words 1[5] with words 2:
Ranges are identical.
Compare first 6 from words 1 with first 6 in words 2:
First pair of words that differ are one and two
Compare all words 1 with words 2:
First pair of words that differ are one and two
Compare all of words 2 with all of words 1:
First pair of words that differ are two and one
Compare from words 1[1] to end with words 2[0] to second-to-last:
First pair of words that differ are seven and eleven
输出显示了每个 mismatch () 的运用结果。 在我们提供自己的函数对象时,就可以完全灵活地定义相等比较。例如:
std::vector<string> range 1 {"one", "three", "five", "ten"};
std::vector<string> range 2 {"nine", "five", "eighteen”,"seven"};
auto pr = std:: mismatch ( std:: begin (range 1), std:: end (range 1), std: rbegin (range 2), std:: end (range 2),[](const string& s 1, const string& s 2) { return s 1.back () = s 2.back (); });
if (pr. first == std:: end (range 1) || pr. second == std:: end (range 2))
std:: cout << "The ranges are identical." << std:: endl;
else
std:: cout << *pr. first << " is not equal to " << *pr. second <<std:: endl;
当两个字符串的最后一个字符相等时,这个比较会返回 true,所以这段代码的输出为:
five is not equal to eighteen
当然,这是正确的,而且根据比较函数,“one”等于 “nine”,“three” 等于“five”。
lexicographical_compare ()
两个字符串的字母排序是通过从第一个字符开始比较对应字符得到的。第一对不同的对应字符决定了哪个字符串排在首位。字符串的顺序就是不同字符的顺序。如果字符串的长度相同,而且所有的字符都相等,那么这些字符串就相等。如果字符串的长度不同,短字符串的字符序列和长字符串的初始序列是相同的,那么短字符串小于长字符串。因此 “age” 在 “beauty” 之前,“a lull” 在 “a storm” 之前。显然,“the chicken” 而不是 “the egg” 会排在首位。
对于任何类型的对象序列来说,字典序都是字母排序思想的泛化。从两个序列的第一个元素开始依次比较对应的元素,前两个对象的不同会决定序列的顺序。显然,序列中的对象必须是可比较的。
lexicographical_compare () 算法可以比较由开始和结束迭代器定义的两个序列。它的前两个参数定义了第一个序列,第 3 和第 4 个参数分别是第二个序列的开始和结束迭代器。默认用 < 运算符来比较元素,但在需要时,也可以提供一个实现小于比较的函数对象作为可选的第 5 个参数。如果第一个序列的字典序小于第二个,这个算法会返回 true,否则返回 false。所以,返回 false 表明第一个序列大于或等于第二个序列。
序列是逐个元素比较的。第一对不同的对应元素决定了序列的顺序。如果序列的长度不同,而且短序列和长序列的初始元素序列匹配,那么短序列小于长序列。长度相同而且对应元素都相等的两个序列是相等的。空序列总是小于非空序列。
下面是一个使用 lexicographical_compare () 的示例:
std::vector<string> phrase1 {"the", "tigers", "of", "wrath"};
std::vector<string> phrase2 {"the", "horses", "of", "instruction"};
auto less = std::lexicographical_compare (std::begin (phrase1), std: :end (phrase1),
std::begin(phrase2), std::end(phrase2)); std::copy(std::begin(phrase1), std::end(phrase1), std::ostream_iterator<string>{std::cout, " "});
std::cout << (less ? "are":"are not") << " less than ";
std::copy(std::begin(phrase2), std::end(phrase2), std::ostream_iterator <string>{std::cout, " "});
std::cout << std::endl;
因为这些序列的第二个元素不同,而且 “tigers” 大于“horses”,这段代码会生成如下 输出:
the tigers of wrath are not less than the horses of instruction
可以在 lexicographical_compare () 调用中添加一个参数,得到相反的结果:
auto less = std::lexicographical_compare (std::begin (phrase1), std::end (phrase1),std::begin(phrase2), std::end(phrase2), [](const string& s1, const string& s2) { return s1.length() < s2.length(); });
这个算法会使用作为第 3 个参数的 lambda 表达式来比较元素。这里会比较序列中字符串的长度,因为 phrase 1 中第 4 个元素的长度小于 phrase 2 中对应的元素,所以 phrase 1 小于 phrase 2。
next_permutation ()
permutation — n. 置换,排列 (方式)
排列就是一次对对象序列或值序列的重新排列。例如,“ABC” 中字符可能的排列是:
"ABC", "ACB", "BAC", "BCA", "CAB", "CBA"
三个不同的字符有 6 种排列,这个数字是从 3*2*1 得到的。一般来说,n 个不同的字 符有 n! 种排列,n! 是 nx (n_1) x (n-2)… x 2 x 1。很容易明白为什么要这样算。有 n 个对象 时,在序列的第一个位置就有 n 种可能的选择。对于第一个对象的每一种选择,序列的第 二个位置还剩下 n-1 种选择,因此前两个有 n x ((n-1) 种可能选择。在选择了前两个之后, 第三个位置还剩下 n-2 种选择,因此前三个有 nx (n-1) x (n-2) 种可能选择,以此类推。序列的末尾是 Hobson 选择,因为只剩下 1 种选择。
对于包含相同元素的序列来说,只要一个序列中的元素顺序不同,就是一种排列。next_permutation () 会生成一个序列的重排列,它是所有可能的字典序中的下一个排列,默认使用 < 运算符来做这些事情。它的参数为定义序列的迭代器和一个返回布尔值的函数,这个函数在下一个排列大于上一个排列时返回 true,如果上一个排列是序列中最大的,它返回 false,所以会生成字典序最小的排列。
下面展示了如何生成一个包含 4 个整数的 vector 的排列:
std::vector<int> range {1,2,3,4};
do {
std::copy (std::begin(range), std::end(range), std::ostream_iterator<int>{std::cout, " "});
std::cout << std::endl;
}while(std::next_permutation(std::begin(range), std::end(range)));
当 next_permutation () 返回 false 时,循环结束,表明到达最小排列。这样恰好可以生成 序列的全部排列,这只是因为序列的初始排列为 1、2、3、4,这是排列集合中的第一个排列。
有一种方法可以得到序列的全排列,就是使用 next_permutation () 得到的最小排列:
std::vector<string> words { "one", "two", "three", "four", "five", "six", "seven", "eight"};
while(std::next_permutation(std::begin(words), std::end(words)));
do
{
std::copy(std::begin(words), std::end(words), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
} while(std::next_permutation(std::begin(words), std::end(words)));
words 中的初始序列不是最小的排列序列,循环会继续进行,直到 words 包含最小排列。do-while 循环会输出全部的排列。如果想执行这段代码,需要记住它会生成 8! 种排列,从而输出 40320 行,因此首先可能会减少 words 中元素的个数。
当排列中的每个元素都小于或等于它后面的元素时,它就是元素序列的最小排列,所以可以用 min_element () 来返回一个指向序列中最小元素的迭代器,然后用 iter_swap () 算法交换两个迭代器指向的元素,从而生成最小的排列,例如:
std::vector<string> words { "one", "two", "three", "four", "five","six",
"seven", "eight"};
for (auto iter = std::begin(words); iter != std::end(words)-1 ;++iter)
std::iter_swap(iter, std::min_element(iter, std::end(words)));
for 循环从序列的第一个迭代器开始遍历,直到倒数第二个迭代器。for 循环体中的语句会交换 iter 指向的元素和 min_element () 返回的迭代器所指向的元素。这样最终会生成一个最小排列,然后可以用它作为 next_permutation () 的起始点来生成全排列。
在开始生成全排列之前,可以先生成一个原始容器的副本,然后在循环中改变它,从而避免到达最小排列的全部开销。
std::vector<string> words {"one","two", "three", "four", "five", "six", "seven", "eight"};
auto words_copy = words; // Copy the original
do {
std::copy(std::begin(words), std::end(words), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;
std::next_permutation(std::begin(words), std::end(words));
}while(words != words_copy); // Continue until back to the original
循环现在会继续生成新的排列,直到到达原始排列。下面是一个找出单词中字母的全部排列的示例:
// Finding rearrangements of the letters in a word
#include <iostream> // For standard streams
#include <iterator> // For iterators and begin() and end()
#include <string> // For string class
#include <vector> // For vector container
#include <algorithm> // For next_permutation()
using std::string;
int main()
{
std::vector<string> words;
string word;
while(true)
{
std::cout << "\nEnter a word, or Ctrl+z to end: ";
if((std::cin >> word).eof()) break;
string word_copy {word};
do
{
words.push_back(word);
std::next_permutation(std::begin(word), std::end(word));
} while(word != word_copy);
size_t count{}, max{8};
for(const auto& wrd : words)
std::cout << wrd << ((++count % max == 0) ? '\n' : ' ');
std::cout << std::endl;
words.clear(); // Remove previous permutations
}
}
这段代码会从标准输入流读取一个单词到 word 中,然后在 word_copy 中生成一个副本,将 word 中字符的全排列保存到 words 容器中。这个程序会继续处理单词直到按下 Ctrl+Z 组合键。用 word 的副本来判断是否已经保存了全排列。然后所有的排列会被写入输出流,8 个一行。像之前说的那样,随着被排列元素个数的增加,排列的个数增加也很快,所以这里不要尝试使用太长的单词。
可以为 next_permutation () 提供一个函数对象作为第三个参数,从而用这个函数对象定义的比较函数来代替默认的比较函数。下面展示如何使用这个版本的函数,通过比较最后 一个字母的方式来生成 words 序列的排列:
std::vector<string> words { "one", "two", "four", "eight"};
do {
std::copy(std:rbegin(words), std::end(words), std::ostream_iterator<string> {std::cout, " "});
std::cout << std::endl;
} while(std::next_permutation(std::begin(words), std::end(words),[](const string& s1, const strings s2) {return s1.back() < s2.back(); }));
通过传入一个 lambda 表达式作为 next_permutation () 的最后一个参数,这段代码会生成 words 中元素的全部 24 种排列。
prev_permutation ()
next_permutation() 是按照字典升序的方式生成的排列。当我们想以降序的方式生成排列时,可以使用 prev_permutation()。
prev_permutation 和 next_permutation() 一样有两个版本,默认使用 < 来比较元素。因为排列是以降序的方式生成的,所以算法大多数时候会返回 true。当生成最大排列时,返回 false。例如:
std::vector<double> data {44.5, 22.0, 15.6, 1.5};
do {
std::copy(std::begin(data), std::end(data), std::ostream_iterator<double> {std::cout, " "});
std::cout << std::endl;
} while(std::prev_permutation(std::begin(data), std::end(data)));
这段代码会输出 data 中 4 个 double 值的全部 24 种排列,因为初始序列是最大排列,所以 prev_permutation() 会在输入最小排列时,才返回 false。
is_permutation ()
is_permutation () 算法可以用来检查一个序列是不是另一个序列的排列,如果是,会返回 true。下面是在这个算法中使用 lambda 表达式的示例:
std::vector<double> data1{44.5, 22.0, 15.6, 1.5};
std::vector<double> data2{22.5, 44.5, 1.5, 15.6};
std::vector<double> data3{1.5, 44.5, 15.6, 22.0};
auto test = [] (const auto& d1, const auto& d2)
{
std::copy(std::begin(d1), std::end(d1), std::ostream_iterator<double> {std::cout," "});
std::cout << (is_permutation (std::begin (d1), std::end(d1), std::begin {d2), std::end(d2))?"is":"is not")>>" a permutation of ";
std::copy(std::begin(d2), std::end(d2), std::ostream_iterator<double>{std::cout, " "});
std::cout << std::endl;
};
test(data1, data2);
test(data1, data3);
test(data3, data2);
lambda 表达式 test 的类型参数是用 auto 指定的,编译器会推断出它的实际类型为 const std::vector<double>&。使用 auto 来指定类型参数的 lambda 表达式叫作泛型 lambda。lambda 表达式 test 用 is_permutation () 来评估参数是否是另一种排列。
算法的参数是一对用来定义被比较范围的迭代器。返回的布尔值会用来选择输出两个字符串中的哪一个。输出如下:
44.5 22 15.6 1.5 is not a permutation of 22.5 44.5 1.5 15.6
44.5 22 15.6 1.5 is a permutation of 1.5 44.5 15.6 22
1.5 44.5 15.6 22 is not a permutation of 22.5 44.5 1.5 15.6
另一个版本的 is_permutation () 允许只用开始迭代器指定第二个序列。在这种情况下,第二个序列可以包含比第一个序列还要多的元素,但是只会被认为拥有第一个序列中的元素个数。
然而,并不推荐使用它,因为如果第二个序列包含的元素少于第一个序列,会产生未定义的错误。接下来会展示一些使用这个函数的代码。我们可以在 data 3 中添加一些元素,但它的初始序列仍然会是 data 1 的一个排列。例如:
std::vector<double> data 1 {44.5, 22.0, 15.6, 1.5};
std::vector<double> data 3 {1.5, 44.5, 15.6, 22.0, 88.0, 999.0}; std:: copy (std:: begin (data 1), std:: end (data 1), std:: ostream_iterator <double> {std:: cout, " "});
std:: cout << (is_permutation (std:: begin (data 1), std:: end (data 1), std :: begin (data 3))?"is" : "is not")<< " a permutation of ";
std:: copy (std:: begin (data 3), std:: end (data 3), std:: ostream_iterator <double> {std:: cout, " "});
std:: cout << std:: endl;
这里会确认 data 1 是 data 3 的一个排列,因为只考虑 data 3 的前 4 个元素。每一个版本的 is_permutation () 都可以添加一个额外的参数来指定所使用的比较。
unique ()
unique () 算法可以在序列中原地移除重复的元素,这就要求被处理的序列必须是正向迭代器所指定的。在移除重复元素后,它会返回一个正向迭代器作为新序列的结束迭代器。可以提供一个函数对象作为可选的第三个参数,这个参数会定义一个用来代替 == 比较元素的方法。例如:
std::vector<string> words {"one", "two", "two", "three", "two", "two", "two"};
auto end_iter = std::unique(std::begin(words), std::end(words));
std::copy(std::begin(words), end_iter, std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl;这样会通过覆盖来消除 words 中的连续元素。输出为:
one two three two
当然,没有元素会从输入序列中移除; 算法并没有方法去移除元素,因为它并不知道它们的具体上下文。整个序列仍然存在。但是,无法保证新末尾之后的元素的状态;如果在上面的代码中用 std::end (words) 代替 end_iter 来输出结果,得到的输出如下:
one two three two two two
相同个数的元素仍然存在,但新的结束迭代器指向的元素为空字符串;最后两个元素还和之前一样。在你的系统上,可能会有不同的结果。因为这个,在执行 unique () 后,最好按如下方式截断序列:
auto end_iter = std::unique(std::begin(words), std::end(words));
words.erase(end_iter, std::end(words));
std::copy (std::begin (words) , std::end (words) , std::ostream iterator<string> {std::cout, " "});
std::cout << std::endl;容器的成员函数 erase () 会移除新的结束迭代器之后的所有元素,因此 end (words) 会返回 end_iter。
当然,可以将 unique () 运用到字符串中的字符上:
string text {"There's no air in spaaaaaace!"};
text.erase(std::unique(std::begin(text), std::end(text),[](char ch1, char ch2) { return ch1 = ' '&& ch1 = ch2; }), std::end(text));
std::cout << text << std::endl; // Outputs: There's no air in spaaaaaace!这里使用 unique () 会移除字符串 text 中的连续重复的空格。这段代码会用 unique () 返回的迭代器作为 text 成员函数 erase () 的第一个参数,而且它会指向被移除的第一个字符。erase () 的第二个参数是 text 的结束迭代器,因此在没有重复元素的新字符串之后的所有字符都会被移除。
rotate ()
rotate () 算法会从左边选择序列的元素。它的工作机制如图所示:

为了理解如何旋转序列,可以将序列中的元素想象成手镯上的珠子。rotate () 操作会导致一个新元素成为开始迭代器所指向的第一个元素。在旋转之后,最后一个元素会在新的第一个元素之前。
rotate () 的第一个参数是这个序列的开始迭代器;第二个参数是指向新的第一个元素的迭代器,它必定在序列之内。第三个参数是这个序列的结束迭代器。图中的示例说明在容器 ns 上的旋转操作使值为 4 的元素成为新的第一个元素,最后一个元素的值为 3。元素的圆形序列会被维持,因此可以有效地旋转元素环,直到新的第一个元素成为序列的开始。这个算法会返回一个迭代器,它指向原始的第一个元素所在的新位置。
例如:
std::vector<string> words { "one", "two", "three", "four", "five","six", "seven", "eight"};
auto iter = std::rotate(std::begin(words), std::begin(words)+3, std::end(words));
std::copy(std::begin(words), std::end(words),std::ostream_iterator<string> {std::cout, " "});
std::cout << std::endl << "First element before rotation: " << *iter << std::endl;
这段代码对 words 中的所有元素进行了旋转。执行这段代码会生成如下内容:
four five six seven eight one two three
First element before rotation: one
输出说明 “four” 成为新的第一个元素,而且 rotate () 返回的迭代器指向之前的第一个元素 “one”。
当然,不需要对容器中的全部元素进行旋转。例如:
std::vector<string> words { "one", "two", "three", "four", "five","six", "seven", "eight", "nine", "ten"};
auto start = std::find(std:rbegin(words), std::end(words), "two");
auto end_iter = std::find(std::begin(words), std::end(words), "eight");
auto iter = std::rotate(start, std::find(std::begin(words), std::end (words), "five") , end_iter);
std::copy(std::begin(words), std::end(words), std::ostream_iterator<string>{std::cout, " "});
std::cout << std::endl << "First element before rotation: " << *iter << std::endl;
这里用 find () 算法分别获取了和 “two”、“eight” 匹配的元素的迭代器。它们定义了被旋转的序列,这个序列是容器元素的子集。这个序列会被旋转为使 “five” 成为第一个元素,输出说明它是按预期工作的:
one five six seven two three four eight nine ten
First element before rotation: two
rotate_copy ()
rotate_copy () 算法会在新序列中生成一个序列的旋转副本,并保持原序列不变。rotate_copy () 的前 3 个参数和 copy () 是相同的;第 4 个参数是一个输出迭代器,它指向目的序列的第一个元素。这个算法会返回一个目的序列的输出迭代器,它指向最后一个被复制元素的下一个位置。
例如:
std::vector<string> words {"one", "two", "three", "four", "five","six", "seven", "eight", "nine","ten"};
auto start = std::find(std::begin(words), std::end(words), "two");
auto end_iter = std::find (std::begin(words) , std::end (words) ,"eight");
std::vector<string> words_copy;
std::rotate_copy(start, std::find(std::begin(words), std::end(words),"five") , end_iter, std::back_inserter (words_copy));
std::copy(std::begin(words_copy), std::end(words_copy),std::ostream_iterator<string> {std::cout, " "});
std::cout << std::endl;
这段代码会对 word 中从 “two” 到 “seven” 的元素生成一个旋转副本。通过使用 back_insert_iterator 将复制的元素追加到 words_copy 容器中,back_insert_iterator 会调用 words_copy 容器的成员函数 push_back () 来插入每个元素。这段代码产生的输出如下:
five six seven two three four
这里 rotate_copy () 返回的迭代器是 words_copy 中元素的结束迭代器。在这段代码中,并没有保存和使用它,但它却很有用。例如:
std::vector<string> words {"one”,"two", "three", "four", "five","six", "seven", "eight", "nine", "ten"};
auto start = std::find (std::begin(words) , std::end(words) ,"two");
auto end_iter = std::find(std::begin(words) , std::end(words),"eight"); std::vector<string> words_copy {20}; // vector with 20 default elements
auto end_copy_iter = std::rotate_copy(start,std::find(std::begin(words), std::end(words), "five"), end_iter, std::begin(words_copy));
std::copy (std::begin (words_copy),end_copy_iter, std::ostream_iterator<string>{std::cout," "});
std::cout << std::endl;
生成的 words_copy 容器默认有 20 个元素。rotate_copy () 算法现在会将现有元素的旋转序列保存到 words_copy 中。在输出时,这个算法返回的迭代器可以用来确定 words_copy 的尾部边界;如果没有它,就必须通过源序列的元素个数来计算出尾部边界。
move ()
move () 算法会将它的前两个输入迭代器参数指定的序列移到第三个参数定义的目的序列的开始位置,第三个参数必须是输出迭代器。这个算法返回的迭代器指向最后一个被移动到目的序列的元素的下一个位置。
这是一个移动操作,因此无法保证在进行这个操作之后,输入序列仍然保持不变;源元素仍然会存在,但它们的值可能不再相同了,因此在移动之后,就不应该再使用它们。如果源序列可以被替换或破坏,就可以选择使用 move () 算法。如果不想扰乱源序列,可以使用 copy () 算法。
下面是一个展示如何使用它的示例:
std::vector<int> srce {1, 2, 3, 4};
std::deque<int> dest {5, 6, 7, 8};
std::move(std::begin(srce), std::end(srce), std::back_inserter(dest));
这里会将 data 的最后 6 个元素移到容器的开头。它能够正常工作是因为目的地址在源序列之外。在移动之后,无法保证最后两个元素的值。这里它们虽然被移除了,但同样可以将它们重置为已知的值一一例如 0。
最后一行中的注释展示了输出结果。当然也可以用 rotate () 算法来代替 move () 移动元素,在这种情况下,我们肯定知道最后两个元素的值。
如果一个移动操作的目的地址位于源序列之内,move () 就无法正常工作,这意味着移动需要从序列的右边开始。原因是一些元素在移动之前会被重写,但 move_backward () 可以正常工作。它的前两个参数指定了被移动的序列,第三个参数是目的地址的结束迭代器。例如:
std::vector<int> data {1, 2, 3, 4, 5, 6, 7, 8};
std::move(std::begin(data) + 2, std::end(data), std::begin(data));
data.erase(std::end(data) - 2, std::end(data)); // Erase moved elements
std::copy(std::begin (data), std::end(data), std::ostream_iterator<int> {std::cout, " "});
std::cout << std::endl;
// 3, 4, 5, 6, 7, 8
这里使用 deque 容器只是为了换个容器使用。将前 6 个元素向右移动两个位置。在移动操作后,值无法得到保证的元素会被重置为 0。最后一行展示了这个操作的结果。
swap_ranges ()
可以用 swap_ranges() 算法来交换两个序列。这个算法需要 3 个正向迭代器作为参数。前两个参数分别是第一个序列的开始和结束迭代器,第三个参数是第二个序列的开始迭代器。显然,这两个序列的长度必须相同。这个算法会返回一个迭代器,它指向第二个序列的最后一个被交换元素的下一个位置。
例如:
using Name = std::pair<string, string>; // First and second name
std::vector<Name> people {Name{"Al", "Bedo" }, Name { "Ann", "Ounce"}, Name{"Jo","King"}};
std::list<Name> folks {Name{"Stan", "Down"}, Name{"Dan","Druff"},Name {"Bea", "Gone"}};
std::swap_ranges(std::begin(people), std::begin(people) + 2, ++std::begin(folks));
std::for_each(std::begin(people), std::end(people),[](const Name& name) {std: :cout << '"' << name.first << " " << name.second << "\" ";});
std::cout << std::endl; // "Dan Druff" "Bea Gone" "Jo King"
std::for_each (std::begin (folks) , std::end (folks) ,[] (const Name& name){std::cout << '"' << name.first << " " << name.second << "\" "; });
std::cout << std::endl;// "Stan Down" "Al Bedo" "Ann Ounce"
这里使用 vector 和 list 容器来保存 pair<string,string> 类型的元素,pair<string,string> 用来表示名称。swap_ranges() 算法被用来交换 people 的前两个元素和 folks 的后两个元素。
这里并没有为了将 pair 对象写入流而重载 operator<<() 函数,因此 copy() 无法用输出流迭代器来列出容器的内容。为了生成输出,选择使用 for_each() 算法将 lambda 表达式运用到容器的每个元素上。这个 lambda 表达式只会将传给它的 Name 元素的成员变量写入标准输出流。注释展示了执行这段代码后输出的结果。
定义在 utility 头文件中的 swap() 算法的重载函数的模板原型为:
template<typename T1, typename T2> void swap(std::pair<T1,T2> left, std::pair<T1,T2> right);
这段代码会对 pair<T1,T2> 对象进行交换,在前面的代码段中也可以用 swap_ranges() 来交换元素。
用来交换两个 T 类型对象的 swap() 模板也被定义在 utility 头文件中。除了 pair 对象的重载之外,utility 文件头中也有可以交换任何类型的容器对象的模板的重载。也就是说,可以交换两个 list<T> 容器或者两个 set<T> 容器但不能是一个 list<T> 和 vector<T>,也不能是一个 list<T1> 和一个 list<T2>。
另一个 swap() 模板的重载可以交换两个相同类型的数组。也有其他几个 swap() 的重载,它们可以用来交换其他类型的对象,包含元组和智能指针类型,正如本章前面所述。iter_swap() 算法有一些不同,它会交换两个正向迭代器所指向的元素。
fill ()/fill_n ()
fill () 和 fill_n () 算法提供了一种为元素序列填入给定值的简单方式,fill () 会填充整个序列; fill_n () 则以给定的迭代器为起始位置,为指定个数的元素设置值。下面展示了 fill () 的用法:
std::vector<string> data {12}; // Container has 12 elements
std::fill (std::begin (data), std::end (data), "none"); // Set all elements to "none"
fill 的前两个参数是定义序列的正向迭代器,第三个参数是赋给每个元素的值。
当然这个序列并不一定要代表容器的全部元素。例如:
std::deque<int> values (13); //Container has 13 elements
int n{2}; // Initial element value
const int step {7}; // Element value increment
const size_t count{3}; // Number of elements with given value
auto iter = std::begin(values);
while(true)
{
auto t0_end = std::distance(iter, std::end(values)); // Number of elements remaining
if (to_end < count) //In case no. of elements not a multiple of count
{
std:: fill (iter, iter + to_end, n); // Just fill remaining elements and end the loop
break;
}
else
{
std:: fill (iter, std:: end (values), n); // Fill next count elements
}
iter = std::next(iter, count); // Increment iter
n += step;
}
上面创建了具有 13 个元素的 value 容器。在这种情况下,必须用圆括号将值传给构造函数;使用花括号会生成一个有单个元素的容器,单个元素的值为 13。在循环中,fill () 算法会将 values 赋值给 count 个元素。以 iter 作为容器的开始迭代器,如果还有足够的元素剩下,每次遍历中,它会被加上 count,因此它会指向下个序列的第一个元素。执行这段代码会将 values 中的元素设置为:
2 2 2 9 9 9 16 16 16 23 23 23 30
fill_n () 的参数分别是指向被修改序列的第一个元素的正向迭代器、被修改元素的个数以及要被设置的值。distance () 和 next () 函数定义在 iterator 头文件中。前者必须使用输入迭代器,而后者需要使用正向迭代器。
generate ()/generate_n ()
你已经知道可以用 for_each () 算法将一个函数对象应用到序列中的每一个元素上。函数对象的参数是 for_each () 的前两个参数所指定序列中元素的引用,因此它可以直接修改被保存的值。generate () 算法和它有些不同,它的前两个参数是指定范围的正向迭代器,第三个参数是用来定义下面这种形式的函数的函数对象:
T fun (); // T is a type that can be assigned to an element in the range
无法在函数内访问序列元素的值。generate () 算法只会保存函数为序列中每个元素所返回的值,而且 generate () 没有任何返回值。
为了使这个算法更有用,可以将生成的不同的值赋给无参数函数中的不同元素。也可以用一个可以捕获一个或多个外部变量的函数对象作为 generate () 的第三个参数。例如:
string chars (30, ' ');// 30 space characters
char ch {'a'};
int incr {};
std::generate (std::begin (chars) , std::end (chars), [ch, &incr]
{
incr += 3;
return ch + (incr % 26);});
std::cout << chars << std: :endl;
// chars is: dgjmpsvybehknqtwzcfiloruxadgjm
变量 chars 被初始化为了个有 30 个空格的字符串。作为 generate () 的第三个参数的 lambda 表达式的返回值会被治存到 chars 的连续字符中。lambda 表达式以值的方式捕获 ch,以引用的方式捕获 incr,因此会在 lambda 的主体中对后者进行修改。lambda 表达式会返回 ch 加上 incr 后得到的字符,增加的值是 26 的模,因此返回的值总是在’a’ 到’z’ 之间,给定的起始值为’a’。这个操作的结果会在注释中展示出来。可以对 lambda 表达式做一些修改, 使它可以用于任何大写或小写字母,但只生成保存在 ch 中的这种类型的字母。
generate_n () 和 generate () 的工作方式是相似的。不同之处是,它的第一个参数仍然是序列的开始迭代器,第二个参数是由第三个参数设置的元素的个数。为了避免程序崩溃,这个序列必须至少有第二个参数定义的元素个数。例如:
string chars (30,' '); // 30 space characters
char ch {'a'}/ int incr {};
std::generate_n(std::begin(chars), chars.size()/2,[ch, &incr]
{
incr += 3;
return ch + (incr % 26);
});
这里,chars 中只有一半的元素会被算法设为新的值,剩下的一半仍然为空格。
transform ()
transform () 可以将函数应用到序列的元素上,并将这个函数返回的值保存到另一个序列中,它返回的迭代器指向输出序列所保存的最后一个元素的下一个位置。
这个算法有一个版本和 for_each () 相似,可以将一个一元函数应用到元素序列上来改变它们的值,但这里有很大的区别。for_each () 中使用的函数的返回类型必须为 void,而且可以通过这个函数的引用参数来修改输入序列中的值;而 transform () 的二元函数必须返回一个值,并且也能够将应用函数后得到的结果保存到另一个序列中。
不仅如此,输出序列中的元素类型可以和输入序列中的元素类型不同。对于 for_each (),函数总是会被应用序列的元素上,但对于 transform (),这一点无法保证。
第二个版本的 transform () 允许将二元函数应用到两个序列相应的元素上,但先来看一下如何将一元函数应用到序列上。在这个算法的这个版本中,它的前两个参数是定义输入序列的输入迭代器,第 3 个参数是目的位置的第一个元素的输出迭代器,第 4 个参数是一个二元函数。这个函数必须接受来自输入序列的一个元素为参数,并且必须返回一个可以保存在输出序列中的值。例如:
std::vector<double> deg_C {21.0, 30.5, 0.0, 3.2, 100.0};
std::vector<double> deg_F(deg_C.size());
std::transform(std::begin(deg_C), std::end(deg_C), std:rbegin(deg_F),[](double temp){ return 32.0 + 9.0*temp/5.0; });
//Result 69.8 86.9 32 37.76 212
这个 transform () 算法会将 deg_C 容器中的摄氏温度转换为华氏温度,并将这个结果保存到 deg_F 容器中。为了保存全部结果,生成的 deg_F 需要一定个数的元素。因此第三个参数是 deg_F 的开始迭代器。通过用 back_insert_iterator 作为 transform () 的第三个参数,可以将结果保存到空的容器中:
std::vector<double> deg_F; // Empty container
std::transform(std::begin(deg_C), std::end(deg_C),std::back_inserter(deg_F),[](double temp){ return 32.0 + 9.0* temp/5.0; });
// Result 69.8 86.9 32 37.76 212
用 back_insert_iterator 在 deg_F 中生成保存了操作结果的元素;结果是相同的。第三个参数可以是指向输入容器的元素的迭代器。例如:
std::vector<double> temps {21.0, 30.5, 0.0, 3.2, 100.0}; // In Centigrade
std::transform(std::begin (temps), std::end(temps), std::begin(temps),[](double temp){ return 32.0 + 9.0* temp / 5.0; });
// Result 69.8 86.9 32 37.76 212
这里将 temp 容器中的值从摄氏温度转换成了华氏温度。第三个参数是输入序列的开始迭代器,应用第 4 个参数指定的函数的结果会被存回它所运用的元素上。
下面的代码展示了目的序列和输入序列是不同类型的情况:
std::vector<string> words {"one", "two", "three", "four","five"};
std::vector<size_t> hash_values;
std::transform (std::begin(words), std::end(words),std::back_inserter(hash_values),std::hash<string>()); // string hashing function
std::copy(std::begin(hash_values), std::end(hash_values),std::ostream_iterator<size_t> {std::cout," "});
std::cout << std::endl;
输入序列包含 string 对象,并且应用到元素的函数是一个定义在 string 头文件中的标准的哈希函数对象。这个哈希函数会返回 size_t 类型的哈希值,并且会用定义在 iterator 头文件中的辅助函数 back_inserter () 返回的 back_insert_iterator 将这些值保存到 hash_values 容器中。在笔者的系统上,这段代码产生的输出如下:
3123124719 3190065193 2290484163 795473317 2931049365
你的系统可能会产生不同的输出。注意,因为目的序列是由 back_insert_iterator 对象指定的,这里 transform () 算法会返回一个 back_insert_iterator<vector<size_T>> 类型的迭代器,因此不能在 copy () 算法中用它作为输入序列的结束迭代器。为了充分利用 transform () 返回的迭代器,这段代码可以这样写:
std::vector<string> words {"one", "two", "three", "four", "five"}; std::vector<size_t> hash_values(words.size());
auto end_iter = std::transform(std::begin(words),std::end(words), std::begin(hash_values), std::hash<string>()); // string hashing function
std::copy(std::begin(hash_values) , end_iter, std::ostream iterator<size t>{std::cout," "});
std::cout << std::endl;
现在,transform () 返回的是 hash_values 容器中元素序列的结束迭代器。
可以在 transform () 所运用的函数中为元素序列调用一个算法。下面举例说明:
std::deque<string> names {"Stan Laurel", "Oliver Hardy", "Harold Lloyd"};
std::transform(std::begin(names), std::end(names), std::begin(names),[](string& s) { std::transform(std::begin(s), std::end(s), std::begin(s), ::toupper);return s;});
std::copy(std::begin(names), std::end(names), std::ostream iterator<string>{std::cout," "});
std::cout << std::endl;
transform () 算法会将 lambda 定义的函数应用到 names 容器中的元素上。这个 lambda 表达式会调用 transform (),将定义在 cctype 头文件中的 toupper () 函数应用到传给它的字符串的每个字符上。它会将 names 中的每个元素都转换为大写,因此输出为:
STAN LAUREL OLIVER HARDY HAROLD LLOYD
当然,也有其他更简单的方式可以得到相同的结果。
应用二元函数的这个版本的 transform () 含有 5 个参数:
- 前两个参数是第一个输入序列的输入迭代器。
- 第 3 个参数是第二个输入序列的开始迭代器,显然,这个序列必须至少包含和第一个输入序列同样多的元素。
- 第 4 个参数是一个序列的输出迭代器,它所指向的是用来保存应用函数后得到的结果的序列的开始迭代器。
- 第 5 个参数是一个函数对象,它定义了一个接受两个参数的函数,这个函数接受来自两个输入序列中的元素作为参数,返回一个可以保存在输出序列中的值。
让我们来思考一个关于几何计算的简单示例。一条折线是由点之间连续的线组成的。折线可以表示为一个 Point 对象的 vector,折线线段是加入连续点的线。如果最后一个点和前一个点相同,折线就是闭合的一个多边形。
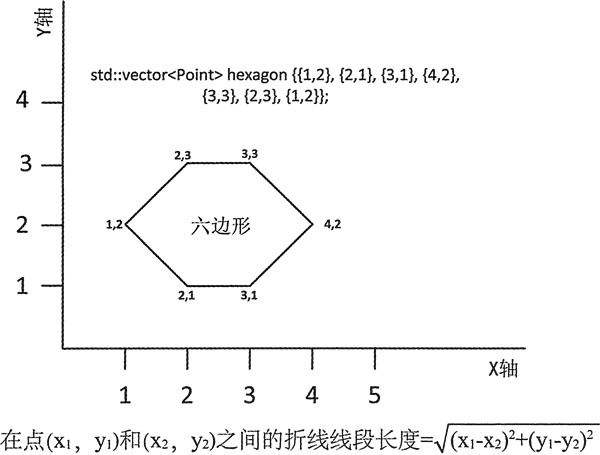
Point 被定义为一个类型别名,图 1 展示了一个示例:
using Point = std::pair<double, double>; // pair<x,y> defines a point
这里有 7 个点,因此图 1 中的六边形对象有 6 个折线段。因为第一个点和最后一个 点是相同的,这 6 条线段实际上组成了一个多边形——六边形。可以用 transform () 算法来 计算这些线段的长度:
std::vector<Point> hexagon {{1,2}, {2,1}, {3,1}, {4,2}, {3,3}, {2,3}, {1,2}};
std::vector<double> segments; // Stores lengths of segments
std::transform (std::begin (hexagon),std::end(hexagon) — 1, std::begin (hexagon) + 1, std::back_inserter(segments),[](const Points p1, const Points p2){return st d::sqrt((p1.first-p2.first)*(p1.first-p2.first) +(p1.second - p2.second)*(p1.second - p2.second)); });
transform () 的第一个输入序列包含六边形中从第一个到倒数第二个 Point 对象。第二个输入序列是从第二个 Point 对象开始的,因此这个二元函数调用的连续参数为点 1 和 2、点 2 和 3、点 3 和 4,依此类推,直到输入序列的最后两个点 6 和 7。图 1 展示了计算 (x 1, y 1) 和 (x 2, y 2) 两点之前距离的公式,作为 transform () 最后一个参数的 lambda 表达式实现的就是这个公式。线段的长度是由 lambda 表达式计算的,它们会被保存在 segments 容器中。我们可以用两种以上的算法来输出线段的长度和这个六边形的周长。例如:
std::cout << "Segment lengths: ";
std::copy(std::begin(segments), std::end(segments),std::ostream_iterator<double> {std::cout," "});
std::cout << std::endl;
std::cout << "Hexagon perimeter: "<< std::accumulate(std::begin(segments), std::end(segments), 0.0) << std::endl;
这里使用 copy () 算法来输出线段的长度。accumulate () 函数可以求出 segments 中元素值之和,从而得到周长。