Noise and Probabilistic Target
之前我们简要讲述了应对数据中 noise 的策略—— Pocket Algorithm 。现在我们考虑在 noise 的影响下 VC bound 是否还成立?
什么样的例子是有噪音的?什么样又是无噪音的呢?不妨以之前抓橙色小球的例子:
- 无噪音情形(deterministic):以小球为变量 ,“无噪音”即对任意 ,都有确定的颜色,
- 此时推导 VC bound 时是判断 是否成立;
- 有噪音情形(probabilistic):“有噪音”即对 ,其颜色是以某种概率存在的,而非确定的(噪音即实际的颜色与 算出的颜色不一致),
- 此时推导 VC bound 时判断 是否成立;
Target Distribution
因此对于有噪音的情况,我们仍可以通过计算抓取出的样本中橙色小球的数量,估计原罐子中橙色小球的分布情况:
- :VC bound 在 的情况下仍成立。
- 意思是,小球 independent and identically distributed 地服从 分布、小球的实际颜色也 i.i.d 地服从 分布;也可以写成联合分布:
我们称 为目标分布,它表征对一个样本 做最理想的预测(mini-target)的行为:
- 目标分布可以看作 ideal mini-target + noise ,例如 ,则 ideal mini-target ,并且噪音等级(flipping noise level)为 0.3
target function v.s. target distribution
target function 可以看作是 target distribution 的特例,即
- ,
- 。
因此,在有噪音的情形下,ML 的目标是在输入的数据中预测理想的 mini-target ,即从 预测 :
- 现在,完整的 learning 流程是这样:
练习:再一次理解 pocket 和 PLA

- 第三个描述之所以是错的,是因为我们这里只提到了线性这一种感知器,但不要误解,非线性感知器也可能在线性可分的输入上依旧可用,
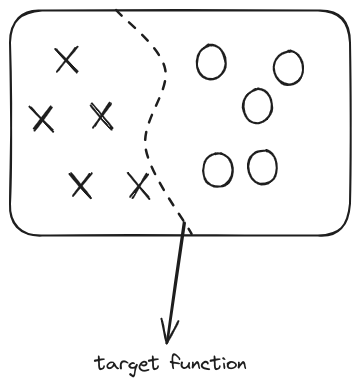
Error Measure
ML 的最终目标是找到可用的最佳估计 以接近 ,过去我们通过测量训练样本外犯错概率的期望 来进行错误评估,
- 我们将错误评估统称为
- 错误评估通常有以下特点:
- 训练样本之外(out of sample):averaged over unknown
- 在特定点上判断(pointwise):evaluate on one
- 评估预测与实际的差异:prediction ≠ target ?
Pointwise Error Measures
我们可以用平均犯错概率表达错误评估:
- 我们之前使用的 就是这个意思,这里 err 代表着对特定点上的错误评估;
错误评估有两类:
- 0/1 error:指的是 ,即判断与实际是否吻合?这通常用在分类问题上;
- squared error:指的是 ,即预测与实际的差距有多远?这通常用于回归问题上;
那么错误评估是如何指引 learning 的呢?
- noise 相关的目标分布 和错误评估 联合定义了理想的 mini-target :
 对于 0/1 error,其中 最大者就是 ideal mini-target;而对于 squared error,其中对 及对应概率的加权平均是 ideal mini-target;
对于 0/1 error,其中 最大者就是 ideal mini-target;而对于 squared error,其中对 及对应概率的加权平均是 ideal mini-target;
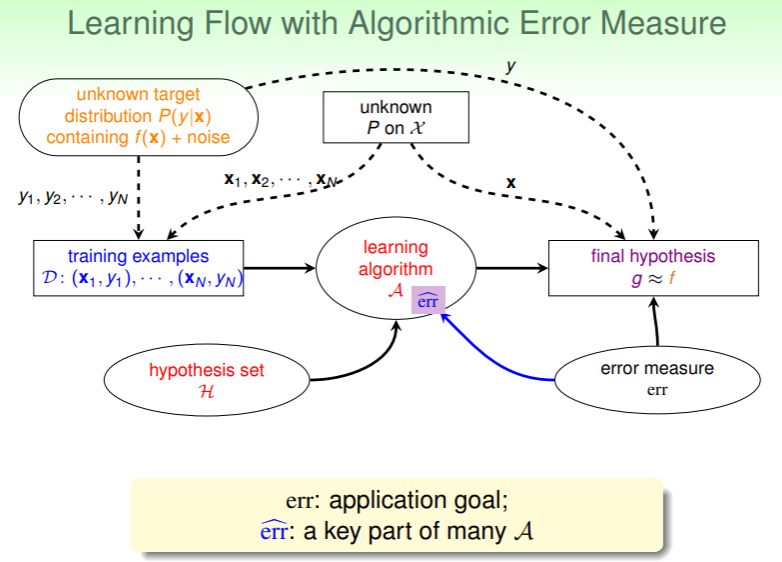
加入错误评估后的 ML 流程图如下:
- 这里最后一句话指的是,VC 理论及思想对大多数问题的假设集 和错误评估 都成立,只需要适当的延伸即可。这里涉及的数学推导比较繁琐,暂时只需要记住这个结论即可。
练习:找到 ideal mini-target

Algorithmic Error Measure
Different Errors and Cost
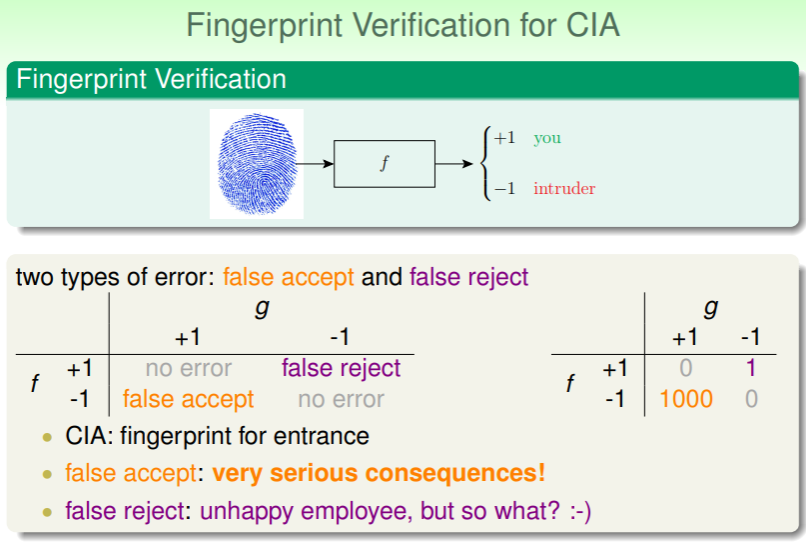
考虑一个指纹识别的问题:
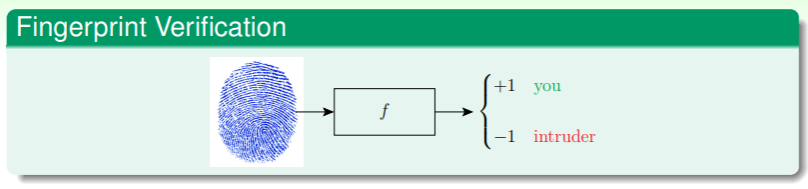
- 这个问题会发生两种错误:
- 当估计的 g 给出的结果为 -1 (即用户的指纹验证不通过),但实际上正确的 f 给出的结果为 +1 (即用户的指纹验证应当给予通过):去真——错误地排除了正确答案,称为 false reject;
- 当估计的 g 给出的结果为 +1 (即用户的指纹验证通过),但实际上正确的 f 给出的结果为 -1 (即用户的指纹验证应当不予通过):纳伪——错误地接收了错误答案,称为 false accept;
- 这两种错误在不同情形下的代价也是不一样的:
- 在超市中客户付款时,VIP 会员可以通过指纹验证获取折扣:
- 此时去真的犯错会极大地影响会员用户的使用体验,给超市带来较大损失;
- 而纳伪的犯错只不过是超市方面让利了一些折扣,并且还获取了入侵者的指纹信息,因此代价不算大;
- 但是机密办公室里,通过指纹验证才能进入、获取机密文件:
- 此时去真的犯错代价并不高,只是短暂的需要技术人员介入修复罢了;
- 但纳伪的犯错代价极高,有很大可能导致机密文件泄露;
- 在超市中客户付款时,VIP 会员可以通过指纹验证获取折扣:
Two Types of Error Measures
上面的例子表明,错误评估 是与具体的应用或用户相关的,即 application/user dependent 。然而我们有时想要得到确切的错误评估并不是一件容易的事,就像机密文件的指纹验证问题里,两种犯错的代价虽然可以知道前者低后者高,但具体用数字表示多低多高并不容易。因此常见的有两种用估计的错误评估 代替 :
- 有实际意义的(plausible):如 0/1 策略,选择其中错误最少者(pocket 策略),不过这是个 NP-hard 问题,难以优化;或 squared 策略,选择其中符合最小高斯分布者(即正态分布)
- 大致估计的:closed-form solution,convex objective function
练习:错误估计的 形式

- 注意此处要考虑犯错的代价;
Weighted Classification
我们可以为同一个问题的不同情形分配不同的权重,尤其是对分类问题,由此可以得到一个代价矩阵:
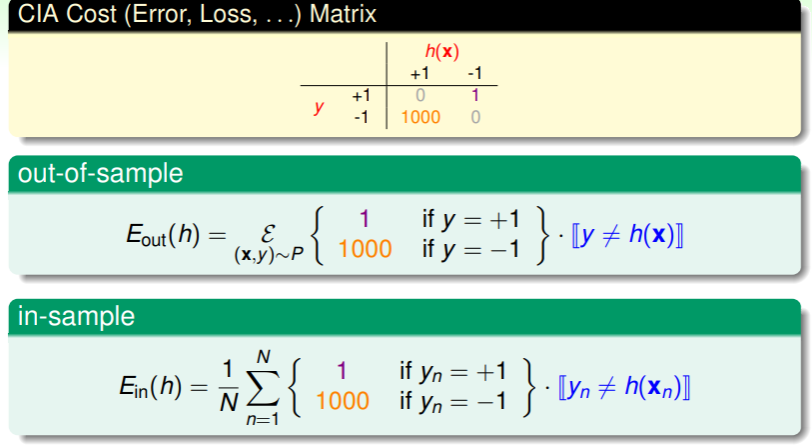
我们将这种问题称为带权重的分类:different weight for different ,因此我们的目标就是在 Weighted Classification 中找到最小的 ,直觉上想,我们可以采用 PLA 或 pocket 两种策略:
- 不过 PLA 有一个弊端是不能处理噪音或其它非线性可分问题;
- pocket 策略会每轮迭代并始终保持之前运行中的最小 ,pocket 策略能够满足二元分类 上的要求,我们可以修改它以满足在带权分类 中的要求吗?
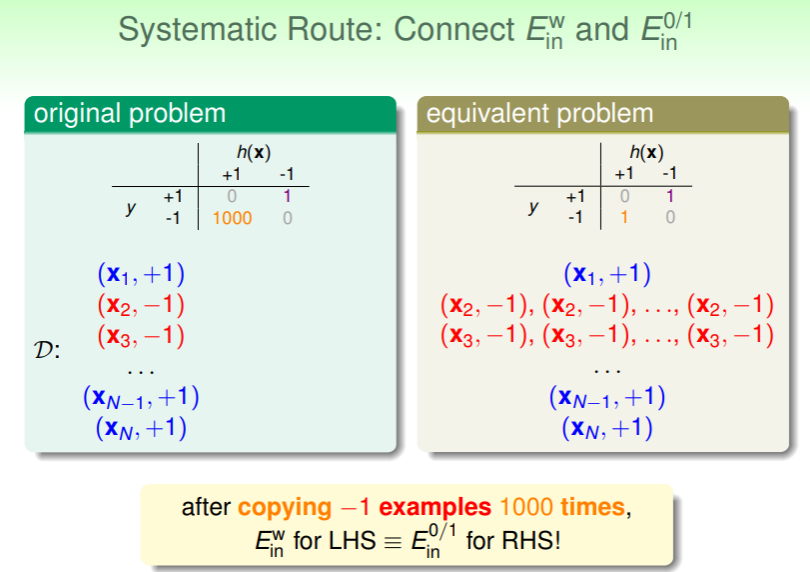 对于权重 1000 的问题,我们可以转化为权重为 1 的情况重复 1000 遍,这样就实现了从 转化到 ;
对于权重 1000 的问题,我们可以转化为权重为 1 的情况重复 1000 遍,这样就实现了从 转化到 ;- 这样的思路称为 systematic route ,在计算机科学中也称为 reduction ,即规约化,化特殊为一般;
练习:计算带权重的

- 这里的假设 是总是给出+1,即允许访问,这显然是一种非常 lazy 的处理方式,但是加权后我们可以看到 ,似乎还可以?
- 当然不是,这是因为数据太过不平衡,权重的设置也不恰当;