笔记内容来自: MPI Tutorial
MPI history
Message Passing Model
消息传递模型是一种并行编程范式,指程序通过在进程间显式传递消息(消息可以理解成带有一些信息和数据的一个数据结构)来进行通信和同步。在实践中,并发程序用这个模型去实现特别容易。举例来说,主进程(manager process)可以通过对从进程(worker process)发送一个描述工作的消息来把这个工作分配给它。另一个例子就是一个并发的排序程序可以在当前进程中对当前进程可见的(我们称作本地的,local)数据进行排序,然后把排好序的数据发送的邻居进程上面来进行合并的操作。几乎所有的并行程序可以使用消息传递模型来描述。这一模型独立于具体平台,能有效解耦计算和通信。
但不同软件库实现的消息传递模型存在差异。1992年,MPI标准在Supercomputing大会上定义,1994年MPI-1标准完成,随后MPI被广泛应用。
MPI desigh
- 通讯器(communicator)定义了一组可相互通信的进程,每个进程被分配一个唯一序号——秩(rank),进程间通过显性地指定秩进行通信。
- 通信基于发送和接收操作:发送方指定目标进程的秩和(唯一的)消息标签(tag),接收方可选择接收特定标签或任意消息,然后依次处理接收到的数据;此类一对一的交互称为点对点通信。
- 当进程需要与所有其他进程通信时(如广播),MPI 提供集体性通信接口以提高效率;点对点和集体性通信的结合能构建复杂的并发程序。
Getting started
Install MPICH
MPI Hello World
// An intro MPI hello world program that uses MPI_Init, MPI_Comm_size,
// MPI_Comm_rank, MPI_Finalize, and MPI_Get_processor_name.
//
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// Initialize the MPI environment. The two arguments to MPI Init are not
// currently used by MPI implementations, but are there in case future
// implementations might need the arguments.
MPI_Init(NULL, NULL);
// Get the number of processes
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the rank of the process
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Get the name of the processor
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Print off a hello world message
printf("Hello world from processor %s, rank %d out of %d processors\n",
processor_name, world_rank, world_size);
// Finalize the MPI environment. No more MPI calls can be made after this
MPI_Finalize();
}-
引入头文件:
必须首先包含#include <mpi.h>。 -
初始化 MPI 环境:
调用MPI_Init(int* argc, char*** argv)。此函数:- 创建所有 MPI 全局变量和内部变量。
- 创建通信器(如
MPI_COMM_WORLD),包含所有可用进程(进程通过 MPI Runtime 指定),为每个进程分配唯一的 秩 (rank)。 - 当前程序中
argc和argv参数暂时没有填充,保留位置供未来实现使用。
-
获取通信器信息(常用函数):
MPI_Comm_size(MPI_Comm communicator, int* size):- 返回指定通信器(此处是
MPI_COMM_WORLD)中的 进程总数。
- 返回指定通信器(此处是
MPI_Comm_rank(MPI_Comm communicator, int* rank):- 返回当前进程在指定通信器中的 秩 (同一个通信器中的进程的秩从 0 开始递增)。
- rank 用于标识进程,指定通信时接收方进程。
-
获取处理器名称(可选):
MPI_Get_processor_name(char* name, int* name_length):
获取运行当前进程的处理器名称。 -
清理 MPI 环境:
调用MPI_Finalize()。- 清理 MPI 环境。
- 此后不能再调用任何 MPI 函数。
MPICH compile
EXECS=mpi-helloworld # make时要注意名称是否对应
MPICC?=mpicc
all: ${EXECS}
mpi-helloworld: mpi-helloworld.c
${MPICC} -o mpi-helloworld mpi-helloworld.c
clean:
rm -f ${EXECS}在编译和运行 MPI 程序时,关键步骤如下:
-
设置编译环境:
- 如果 MPICH2 安装在本地而非全局路径,需手动设置
MPICC环境变量,指向mpicc二进制程序(本质为 GCC 封装,更方便 MPI 程序的编译、链接)。 - 执行命令:
export MPICC=/home/kendall/bin/mpicc后运行make,Makefile 调用mpicc编译程序(如mpi_hello_world.c生成可执行文件)。
- 如果 MPICH2 安装在本地而非全局路径,需手动设置
-
运行前配置:
- 单机运行:无需额外配置,直接执行。
- 集群运行:需创建 host 文件(非系统 hosts),列出所有节点名称(如
cetus1, cetus2),并确保节点间通过 SSH 无密码通信。 - 使用脚本运行前需设置环境变量:
export MPI_HOSTS=host_file指向 host 文件路径。- 如果 MPI 未全局安装,设置
export MPIRUN=/home/kendall/bin/mpirun。
-
运行程序:
- 使用提供的 Python 脚本
run.py,可编译并运行所有教程程序。 - 示例命令:
cd tutorials ./run.py mpi_hello_world- 脚本会使用
mpicc先编译程序,再调用mpirun -n 4 -f host_file ./mpi_hello_world,其中-n指定进程数(本例为 4)。- 输出显示各节点进程的 rank,顺序随机(无同步操作)。
- 脚本会使用
- 如果是单机运行,可以直接使用 makefile 编译、运行(
mpirun -np 4 ./mpi-helloworld),结果如下:
- 使用提供的 Python 脚本
Hello world from processor SenjL-PC, rank 0 out of 4 processors
Hello world from processor SenjL-PC, rank 1 out of 4 processors
Hello world from processor SenjL-PC, rank 2 out of 4 processors
Hello world from processor SenjL-PC, rank 3 out of 4 processors
- 优化多核节点间的进程分布:
- 在 host 文件中指定每节点核数(如
cetus1:2),MPI 按核生成进程(例:4 个进程仅需两个节点各 2 核)。 - 修改后运行,确保进程高效分布。
- 在 host 文件中指定每节点核数(如
注意事项:避免过度指定进程数以防系统过载;脚本自动处理编译和参数传入。
Blocking point-to-point communication
MPI send and receive
MPI 发送接收机制:
- 当进程 A 需向进程 B 发送消息时,其首先将数据打包至缓冲区(类似于信封),后通过网络路由至 B(根据 rank 确定)。
- B 必须主动确认接收到的消息,A 收到消息传递成功的信息后才继续工作(阻塞式)。
- 消息可附加标签(tag)进行区分,未匹配标签的消息会暂存在缓冲区。
函数原型如下:
MPI_Send(
void* data, # 数据缓冲区
int count, # 数据数量
MPI_Datatype datatype, # 数据类型
int destination, # 接收方进程的rank
int tag, # 消息的标签
MPI_Comm communicator) # 指定使用的通信器
MPI_Recv(
void* data,
int count,
MPI_Datatype datatype,
int source, # 发送方进程的rank
int tag,
MPI_Comm communicator,
MPI_Status* status) # 接收到的消息的状态
基础 MPI 数据类型:
| MPI datatype | C equivalent |
|---|---|
| MPI_SHORT | short int |
| MPI_INT | int |
| MPI_LONG | long int |
| MPI_LONG_LONG | long long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_UNSIGNED_LONG_LONG | unsigned long long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | char |
示例程序:
- 发送接收程序(send_recv. c):进程 0 发送整数-1 给进程 1,进程 1 接收并打印。验证消息传递基础功能。
// MPI_Send, MPI_Recv example. Communicates the number -1 from process 0
// to process 1.
//
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Find out rank, size
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// We are assuming at least 2 processes for this task
if (world_size < 2) {
fprintf(stderr, "World size must be greater than 1 for %s\n", argv[0]);
MPI_Abort(MPI_COMM_WORLD, 1);
}
int number;
if (world_rank == 0) {
// If we are rank 0, set the number to -1 and send it to process 1
number = -1;
MPI_Send(
/* data = */ &number,
/* count = */ 1,
/* datatype = */ MPI_INT,
/* destination = */ 1,
/* tag = */ 0,
/* communicator = */ MPI_COMM_WORLD);
} else if (world_rank == 1) {
MPI_Recv(
/* data = */ &number,
/* count = */ 1,
/* datatype = */ MPI_INT,
/* source = */ 0,
/* tag = */ 0,
/* communicator = */ MPI_COMM_WORLD,
/* status = */ MPI_STATUS_IGNORE);
printf("Process 1 received number %d from process 0\n", number);
}
MPI_Finalize();
}
- 乒乓程序(ping_pong. c):两进程交替发送计数器值(起始 0),每轮发送方递增计数器并发送,接收方打印值(循环 10 次)。
// Ping pong example with MPI_Send and MPI_Recv. Two processes ping pong a
// number back and forth, incrementing it until it reaches a given value.
//
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
const int PING_PONG_LIMIT = 10;
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Find out rank, size
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// We are assuming 2 processes for this task
if (world_size != 2) {
fprintf(stderr, "World size must be two for %s\n", argv[0]);
MPI_Abort(MPI_COMM_WORLD, 1);
}
int ping_pong_count = 0;
int partner_rank = (world_rank + 1) % 2;
while (ping_pong_count < PING_PONG_LIMIT) {
if (world_rank == ping_pong_count % 2) {
// Increment the ping pong count before you send it
ping_pong_count++;
MPI_Send(&ping_pong_count, 1, MPI_INT, partner_rank, 0, MPI_COMM_WORLD);
printf("%d sent and incremented ping_pong_count %d to %d\n",
world_rank, ping_pong_count, partner_rank);
} else {
MPI_Recv(&ping_pong_count, 1, MPI_INT, partner_rank, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("%d received ping_pong_count %d from %d\n",
world_rank, ping_pong_count, partner_rank);
}
}
MPI_Finalize();
}
- 环形程序(ring. c):多进程以环状传递数据。进程 0 初始化值 -1 发送给进程 1,后续进程依次接收前驱进程发来的数据并发送给后继进程,最终值传回进程 0。程序会在进程 0 收到最后一个进程发来的值后结束,避免死锁。
// Example using MPI_Send and MPI_Recv to pass a message around in a ring.
//
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Find out rank, size
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int token;
// Receive from the lower process and send to the higher process. Take care
// of the special case when you are the first process to prevent deadlock.
if (world_rank != 0) {
MPI_Recv(&token, 1, MPI_INT, world_rank - 1, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("Process %d received token %d from process %d\n", world_rank, token,
world_rank - 1);
} else {
// Set the token's value if you are process 0
token = -1;
}
MPI_Send(&token, 1, MPI_INT, (world_rank + 1) % world_size, 0,
MPI_COMM_WORLD);
// Now process 0 can receive from the last process. This makes sure that at
// least one MPI_Send is initialized before all MPI_Recvs (again, to prevent
// deadlock)
if (world_rank == 0) {
MPI_Recv(&token, 1, MPI_INT, world_size - 1, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("Process %d received token %d from process %d\n", world_rank, token,
world_size - 1);
}
MPI_Finalize();
}
具体来说,进程0保证了在想要接受数据之前发送了 token。所有其他的进程只是简单的调用 MPI_Recv (从他们的邻居进程接收数据),然后调用 MPI_Send (发送数据到他们的邻居进程)把数据从环上传递下去。 MPI_Send 和 MPI_Recv 会阻塞直到数据传递完成。设置进程数为 6 时,结果如下:
Process 1 received token -1 from process 0
Process 2 received token -1 from process 1
Process 3 received token -1 from process 2
Process 4 received token -1 from process 3
Process 5 received token -1 from process 4
Process 0 received token -1 from process 5
Dynamic receive
发送消息前并不一定知道消息具体的长度,因此留了一个坑,即 MPI_Recv 函数的最后一个参数 MPI_Status(可使用 MPI_STATUS_IGNORE 忽略),它将会在其中填充有关接收操作的其他信息:
- 发送者秩 (Source):存储在
MPI_Status结构体的MPI_SOURCE属性中。 - 消息标签 (Tag):存储在
MPI_Status结构体的MPI_TAG中。 - 消息长度 (Length):不直接存储在结构中。需使用
MPI_Get_count函数获取。
MPI_Get_count(
MPI_Status* status, # MPI_Status 的地址
MPI_Datatype datatype, # 消息的类型
int* count); # 消息长度填写的地址MPI_Status 获取这些信息的必要性:
- 当
MPI_Recv使用MPI_ANY_SOURCE(任意发送者)或MPI_ANY_TAG(任意标签)时,MPI_Status是唯一途径以确定实际的发送者秩和消息标签。 MPI_Recv不保证接收到参数(count)指定数量的全部元素,它只接收实际发送来的元素量(过多发送会导致错误)。MPI_Get_count用于确定实际接收量。
使用 MPI_Probe 在实际接收前探查消息大小:
MPI_Probe函数原型类似于MPI_Recv:
MPI_Probe(
int source,
int tag,
MPI_Comm comm,
MPI_Status* status);- 它阻塞等待匹配
source和tag的消息到达,但不实际接收数据。消息到达后,它填充status结构(包含消息大小等信息)。 - 作用:允许在接收前探查消息大小(使用
MPI_Get_count(&status, datatype, &count))。基于探查到的count动态分配精确大小的缓冲区,再用MPI_Recv接收消息。 - 优势:避免为
MPI_Recv准备一个超大缓冲区来处理可能的动态消息,提高效率(尤其对于变量大小的消息交换,如管理器/工作器模式)。
两种缓冲区分配方式的对比:
- 使用静态大缓冲区 (如
check_status.c)
// Example of checking the MPI_Status object from an MPI_Recv call
//
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
if (world_size != 2) {
fprintf(stderr, "Must use two processes for this example\n");
MPI_Abort(MPI_COMM_WORLD, 1);
}
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
const int MAX_NUMBERS = 100;
int numbers[MAX_NUMBERS];
int number_amount;
if (world_rank == 0) {
// Pick a random amount of integers to send to process one
srand(time(NULL));
number_amount = (rand() / (float)RAND_MAX) * MAX_NUMBERS;
// Send the amount of integers to process one
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD);
printf("0 sent %d numbers to 1\n", number_amount);
} else if (world_rank == 1) {
MPI_Status status;
// Receive at most MAX_NUMBERS from process zero
MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
// After receiving the message, check the status to determine how many
// numbers were actually received
MPI_Get_count(&status, MPI_INT, &number_amount);
// Print off the amount of numbers, and also print additional information
// in the status object
printf("1 received %d numbers from 0. Message source = %d, tag = %d\n",
number_amount, status.MPI_SOURCE, status.MPI_TAG);
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
程序将随机数量的数字发送给接收端,然后接收端找出发送了多少个数字。
1 received 56 numbers from 0. Message source = 0, tag = 0
可以看到,进程 0 将最多 MAX_NUMBERS 个整数以随机数量发送到进程 1。 进程 1 然后调用 MPI_Recv 以获取最多 MAX_NUMBERS 个整数(可以看到本次执行只获取了 56 个数字)。
另外需要注意,MPI_Get_count 的返回值是相对于传递的数据类型而言的。 如果用户使用 MPI_CHAR 作为数据类型,则返回的数量将是原来的四倍(整数是四个字节,而 char 是一个字节)。
- 使用
MPI_Probe动态分配 (如probe.c)
// Example of using MPI_Probe to dynamically allocated received messages
//
#include <mpi.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(int argc, char** argv) {
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
if (world_size != 2) {
fprintf(stderr, "Must use two processes for this example\n");
MPI_Abort(MPI_COMM_WORLD, 1);
}
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int number_amount;
if (world_rank == 0) {
const int MAX_NUMBERS = 100;
int numbers[MAX_NUMBERS];
// Pick a random amont of integers to send to process one
srand(time(NULL));
number_amount = (rand() / (float)RAND_MAX) * MAX_NUMBERS;
// Send the amount of integers to process one
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD);
printf("0 sent %d numbers to 1\n", number_amount);
} else if (world_rank == 1) {
MPI_Status status;
// Probe for an incoming message from process zero
MPI_Probe(0, 0, MPI_COMM_WORLD, &status);
// When probe returns, the status object has the size and other
// attributes of the incoming message. Get the size of the message.
MPI_Get_count(&status, MPI_INT, &number_amount);
// Allocate a buffer just big enough to hold the incoming numbers
int* number_buf = (int*)malloc(sizeof(int) * number_amount);
// Now receive the message with the allocated buffer
MPI_Recv(number_buf, number_amount, MPI_INT, 0, 0, MPI_COMM_WORLD,
MPI_STATUS_IGNORE);
printf("1 dynamically received %d numbers from 0.\n",
number_amount);
free(number_buf);
}
MPI_Finalize();
}
运行结果如下:
0 sent 72 numbers to 1
1 dynamically received 72 numbers from 0.
结论:MPI_Probe 结合 MPI_Status 和 MPI_Get_count 可实现动态消息长度的探查与精确缓冲分配,是处理变长消息的高效方法。
Point-to-point communication application
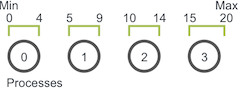
随机游走问题定义如下: 给定 Min,Max 和随机游走器 W,让游走器 W 向右任意移动 S 次,如果该过程越过边界,它就会绕回。 W 一次只能左右移动一个单位。并行化的随机游走可以模拟各种并行程序的行为。

并行化设计:
- 域分解:将一维域均分给所有进程(示例:域 0-20,4 进程 ⇒ 进程0:0-4, 进程1:5-9, 进程2:10-14, 进程3:15-20)。
- 初始化:每个进程在本地子域起点创建
N个行走者,随机生成其剩余步数。 - 行走规则:
- 行走者在本地子域内逐步移动。
- 当触及子域边界时,通过
MPI_Send将其发送给相邻进程。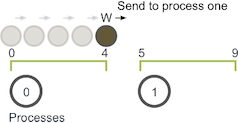
- 接收进程用
MPI_Probe + MPI_Recv动态获取数据,继续行走。
- 程序思路的构建:
- 明确每个进程在域中的部分。
- 每个进程初始化 N 个 walker,所有这些 walker 都从其局部域的第一个值开始。
- 每个 walker 都有两个相关的整数值:当前位置和剩余步数。
- Walkers 开始遍历该域,并传递到其他进程,直到完成所有移动。
- 当所有 walker 完成时,该进程终止。
关键代码组件:
- 结构体:
Walker{ location, num_steps_left_in_walk },初始化时采用子域边界,并将 walker 添加到 incoming_walker 这个 vector 中:
void initialize_walkers(int num_walkers_per_proc, int max_walk_size,
int subdomain_start,
vector<Walker>* incoming_walkers) {
Walker walker;
for (int i = 0; i < num_walkers_per_proc; i++) {
// Initialize walkers at the start of the subdomain
walker.location = subdomain_start;
walker.num_steps_left_in_walk =
(rand() / (float)RAND_MAX) * max_walk_size;
incoming_walkers->push_back(walker);
}
}- 域分解函数:
decompose_domain()计算各进程子域的起止
void decompose_domain(int domain_size, int world_rank,
int world_size, int* subdomain_start,
int* subdomain_size) {
if (world_size > domain_size) {
// Don't worry about this special case. Assume the domain size
// is greater than the world size.
MPI_Abort(MPI_COMM_WORLD, 1);
}
*subdomain_start = domain_size / world_size * world_rank;
*subdomain_size = domain_size / world_size;
if (world_rank == world_size - 1) {
// Give remainer to last process
*subdomain_size += domain_size % world_size;
}
}- 行走函数:
walk()移动 walker,跨域时加入待发送队列outgoing_walkers:
void walk(Walker* walker, int subdomain_start, int subdomain_size,
int domain_size, vector<Walker>* outgoing_walkers) {
while (walker->num_steps_left_in_walk > 0) {
if (walker->location == subdomain_start + subdomain_size) {
// Take care of the case when the walker is at the end
// of the domain by wrapping it around to the beginning
if (walker->location == domain_size) {
walker->location = 0;
}
outgoing_walkers->push_back(*walker);
break;
} else {
walker->num_steps_left_in_walk--;
walker->location++;
}
}
}- 通信函数:
send_outgoing_walkers():向下游进程发送越界的 walker
void send_outgoing_walkers(vector<Walker>* outgoing_walkers, int world_rank, int world_size) { // Send the data as an array of MPI_BYTEs to the next process. // The last process sends to process zero. MPI_Send((void*)outgoing_walkers->data(), outgoing_walkers->size() * sizeof(Walker), MPI_BYTE, (world_rank + 1) % world_size, 0, MPI_COMM_WORLD); // Clear the outgoing walkers list outgoing_walkers->clear();
}
- `receive_incoming_walkers()`:用 `MPI_Probe` 探测消息大小后接收 c
void receive_incoming_walkers(vector
死锁解决:
- 问题:原始循环(先发送后接收)可能导致进程间等待死锁。
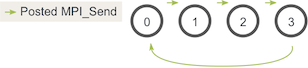 1
1 - 方案:对消息进行排序,以使发送将具有匹配的接收,反之亦然:
- 偶进程:先发送 → 后接收
- 奇进程:先接收 → 后发送
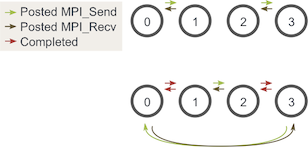
- 对于奇数个进程,这样的思路依然有效——至少有一个
MPI_Send和MPI_Recv相匹配: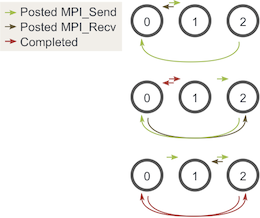
终止条件:
- Naive idea:让进程 0 跟踪所有已完成的 walker,然后告诉其他所有进程何时终止。 但是,这样的解决方案非常麻烦,因为每个进程都必须向进程 0 报告所有完成的 walker,然后还要处理不同类型的传入消息。
- Better solution:由于知道任意一个 walker 可以行进的最大距离和每对发送和接收对它可以行进的最小总大小(子域大小),因此可以计算出终止之前每个进程应该执行的发送和接收量——计算最大通信轮次:
max_walk_size / (domain_size/world_size) + 1。所有进程执行固定轮次后停止。
int main(int argc, char** argv) {
int domain_size;
int max_walk_size;
int num_walkers_per_proc;
if (argc < 4) {
cerr << "Usage: random_walk domain_size max_walk_size "
<< "num_walkers_per_proc" << endl;
exit(1);
}
domain_size = atoi(argv[1]);
max_walk_size = atoi(argv[2]);
num_walkers_per_proc = atoi(argv[3]);
MPI_Init(NULL, NULL);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
srand(time(NULL) * world_rank);
int subdomain_start, subdomain_size;
vector<Walker> incoming_walkers, outgoing_walkers;
// Find your part of the domain
decompose_domain(domain_size, world_rank, world_size,
&subdomain_start, &subdomain_size);
// Initialize walkers in your subdomain
initialize_walkers(num_walkers_per_proc, max_walk_size, subdomain_start,
&incoming_walkers);
cout << "Process " << world_rank << " initiated " << num_walkers_per_proc
<< " walkers in subdomain " << subdomain_start << " - "
<< subdomain_start + subdomain_size - 1 << endl;
// Determine the maximum amount of sends and receives needed to
// complete all walkers
int maximum_sends_recvs = max_walk_size / (domain_size / world_size) + 1;
for (int m = 0; m < maximum_sends_recvs; m++) {
// Process all incoming walkers
for (int i = 0; i < incoming_walkers.size(); i++) {
walk(&incoming_walkers[i], subdomain_start, subdomain_size,
domain_size, &outgoing_walkers);
}
cout << "Process " << world_rank << " sending " << outgoing_walkers.size()
<< " outgoing walkers to process " << (world_rank + 1) % world_size
<< endl;
if (world_rank % 2 == 0) {
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
} else {
// Receive all the new incoming walkers
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
// Send all outgoing walkers to the next process.
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
}
cout << "Process " << world_rank << " received " << incoming_walkers.size()
<< " incoming walkers" << endl;
}
cout << "Process " << world_rank << " done" << endl;
MPI_Finalize();
return 0;
}实际应用:
此模型可扩展至科学计算(如并行粒子追踪):并行粒子跟踪是用于可视化流场的主要方法之一。 将粒子插入流场,然后使用数值积分技术(例如 Runge-Kutta)沿流线跟踪。 然后可以呈现跟踪的路径以用于可视化目的。 一个示例渲染是左上方的龙卷风图像。
执行有效的并行粒子跟踪可能非常困难。 这样做的主要原因是,只有在积分的每个增量步骤之后才能确定粒子行进的方向。 因此,线程很难协调和平衡所有通信和计算。 为了更好地理解这一点,让我们看一下粒子跟踪的典型并行化。
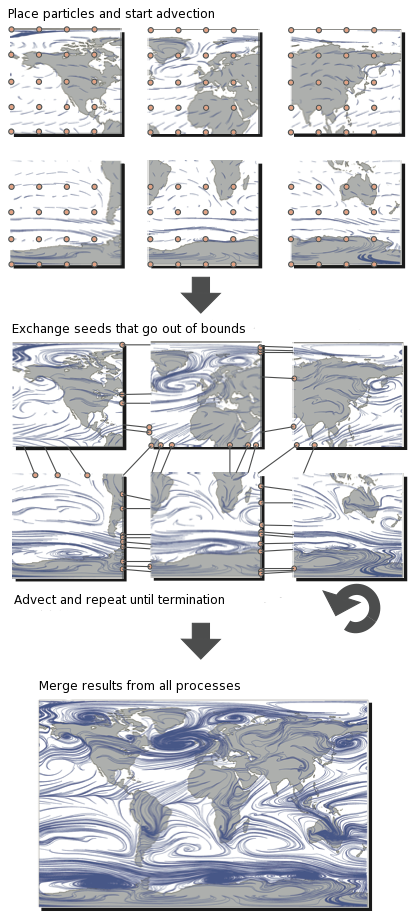 在此插图中,可以看到该域分为六个过程。 然后将粒子(有时称为 种子)放置在子域中(类似于将 walkers 放置在子域中的方式),然后开始跟踪它们。 当粒子超出范围时,必须与具有适当子域的进程进行交换。 重复此过程,直到粒子离开整个域或达到最大迹线长度为止。
在此插图中,可以看到该域分为六个过程。 然后将粒子(有时称为 种子)放置在子域中(类似于将 walkers 放置在子域中的方式),然后开始跟踪它们。 当粒子超出范围时,必须与具有适当子域的进程进行交换。 重复此过程,直到粒子离开整个域或达到最大迹线长度为止。
Basic collective communication
MPI broadcast
-
集合通信基础:
- 区别于点对点通信,集合通信要求同一通信域(communicator)内的所有进程必须参与——if you can’t successfully complete an
MPI_Barrier, then you also can’t successfully complete any collective call.。 - 所有集合通信操作都隐含着同步点(synchronization point):所有进程必须到达相应的调用点才能继续执行后续代码。MPI 中提供
MPI_Barrier(MPI_Comm communicator)用于显式同步,工作原理是阻止任何进程直至所有进程都调用它(常通过 令牌环 等机制实现)。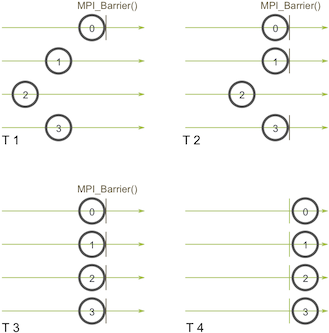
- 区别于点对点通信,集合通信要求同一通信域(communicator)内的所有进程必须参与——if you can’t successfully complete an
-
广播操作(MPI_Bcast):
- 功能:由一个根进程(root process)将相同数据发送给通信域内的所有其他进程。常见用途包括分发用户输入或配置参数。
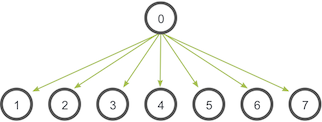
- 函数原型:
MPI_Bcast( void* data, int count, MPI_Datatype datatype, int root, MPI_Comm communicator) - 调用一致性:根进程和接收进程都调用同一个
MPI_Bcast函数。根进程调用时发送数据,接收进程调用时填充接收缓冲区。
- 功能:由一个根进程(root process)将相同数据发送给通信域内的所有其他进程。常见用途包括分发用户输入或配置参数。
-
**手动实现与
MPI_Bcast**:- 简单实现的低效:仅用根进程向每个其他进程逐一发送,无法充分利用网络带宽(仅用根进程的网络连接发送所有数据)。
void my_bcast(void* data, int count, MPI_Datatype datatype, int root, MPI_Comm communicator) { int world_rank; MPI_Comm_rank(communicator, &world_rank); int world_size; MPI_Comm_size(communicator, &world_size); if (world_rank == root) { // If we are the root process, send our data to everyone int i; for (i = 0; i < world_size; i++) { if (i != world_rank) { MPI_Send(data, count, datatype, i, 0, communicator); } } } else { // If we are a receiver process, receive the data from the root MPI_Recv(data, count, datatype, root, 0, communicator, MPI_STATUS_IGNORE); } }- 树形广播算法:
MPI_Bcast的实现采用更高效的树形算法(如二叉权树),允许多个进程并行转发数据,大大提升网络利用率(每下一层级并行连接数翻倍)。这使得通信时间在进程数增多时仅呈对数增长 (O(log n),换言之,能够利用的网络连接每个阶段都会比前一阶段翻番),而非线性增长 (O(n))。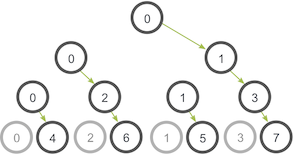
#include "mpiimpl.h"
/* Algorithm: Tree-based bcast
* For short messages, we use a kary/knomial tree-based algorithm.
* Cost = lgp.alpha + n.lgp.beta
*/
int MPIR_Bcast_intra_tree(void *buffer,
MPI_Aint count,
MPI_Datatype datatype,
int root, MPIR_Comm * comm_ptr, int tree_type,
int branching_factor, int is_nb, MPIR_Errflag_t errflag)
{
int rank, comm_size, src, dst, *p, j, k, lrank = -1, is_contig;
int parent = -1, num_children = 0, num_req = 0, is_root = 0;
int mpi_errno = MPI_SUCCESS;
MPI_Aint nbytes = 0, type_size, actual_packed_unpacked_bytes, recvd_size;
MPI_Aint saved_count = count;
MPI_Status status;
void *send_buf = NULL;
MPIR_Request **reqs = NULL;
MPI_Status *statuses = NULL;
MPI_Datatype dtype;
MPIR_Treealgo_tree_t my_tree;
MPIR_CHKLMEM_DECL();
MPIR_COMM_RANK_SIZE(comm_ptr, rank, comm_size);
/* If there is only one process, return */
if (comm_size == 1)
goto fn_exit;
if (HANDLE_GET_KIND(datatype) == HANDLE_KIND_BUILTIN)
is_contig = 1;
else {
MPIR_Datatype_is_contig(datatype, &is_contig);
}
MPIR_Datatype_get_size_macro(datatype, type_size);
nbytes = type_size * count;
if (nbytes == 0)
goto fn_exit; /* nothing to do */
send_buf = buffer;
dtype = datatype;
if (!is_contig) {
MPIR_CHKLMEM_MALLOC(send_buf, nbytes);
/* TODO: Pipeline the packing and communication */
if (rank == root) {
mpi_errno = MPIR_Typerep_pack(buffer, count, datatype, 0, send_buf, nbytes,
&actual_packed_unpacked_bytes, MPIR_TYPEREP_FLAG_NONE);
MPIR_ERR_CHECK(mpi_errno);
}
count = count * type_size;
dtype = MPIR_BYTE_INTERNAL;
}
if (tree_type == MPIR_TREE_TYPE_KARY) {
if (rank == root)
is_root = 1;
lrank = (rank + (comm_size - root)) % comm_size;
parent = (lrank == 0) ? -1 : (((lrank - 1) / branching_factor) + root) % comm_size;
num_children = branching_factor;
} else {
/*construct the knomial tree */
my_tree.children = NULL;
if (tree_type == MPIR_TREE_TYPE_TOPOLOGY_AWARE ||
tree_type == MPIR_TREE_TYPE_TOPOLOGY_AWARE_K) {
mpi_errno =
MPIR_Treealgo_tree_create_topo_aware(comm_ptr, tree_type, branching_factor, root,
MPIR_CVAR_BCAST_TOPO_REORDER_ENABLE, &my_tree);
} else if (tree_type == MPIR_TREE_TYPE_TOPOLOGY_WAVE) {
int overhead = MPIR_CVAR_BCAST_TOPO_OVERHEAD;
int lat_diff_groups = MPIR_CVAR_BCAST_TOPO_DIFF_GROUPS;
int lat_diff_switches = MPIR_CVAR_BCAST_TOPO_DIFF_SWITCHES;
int lat_same_switches = MPIR_CVAR_BCAST_TOPO_SAME_SWITCHES;
if (comm_ptr->csel_comm) {
MPIR_Csel_coll_sig_s coll_sig = {
.coll_type = MPIR_CSEL_COLL_TYPE__BCAST,
.comm_ptr = comm_ptr,
.u.bcast.buffer = buffer,
.u.bcast.count = count,
.u.bcast.datatype = datatype,
.u.bcast.root = root,
};
MPII_Csel_container_s *cnt = MPIR_Csel_search(comm_ptr->csel_comm, coll_sig);
MPIR_Assert(cnt);
if (cnt->id == MPII_CSEL_CONTAINER_TYPE__ALGORITHM__MPIR_Bcast_intra_tree) {
overhead = cnt->u.bcast.intra_tree.topo_overhead;
lat_diff_groups = cnt->u.bcast.intra_tree.topo_diff_groups;
lat_diff_switches = cnt->u.bcast.intra_tree.topo_diff_switches;
lat_same_switches = cnt->u.bcast.intra_tree.topo_same_switches;
}
}
mpi_errno =
MPIR_Treealgo_tree_create_topo_wave(comm_ptr, branching_factor, root,
MPIR_CVAR_BCAST_TOPO_REORDER_ENABLE,
overhead, lat_diff_groups, lat_diff_switches,
lat_same_switches, &my_tree);
} else {
mpi_errno =
MPIR_Treealgo_tree_create(rank, comm_size, tree_type, branching_factor, root,
&my_tree);
}
MPIR_ERR_CHECK(mpi_errno);
num_children = my_tree.num_children;
parent = my_tree.parent;
}
if (is_nb) {
MPIR_CHKLMEM_MALLOC(reqs, sizeof(MPIR_Request *) * num_children);
MPIR_CHKLMEM_MALLOC(statuses, sizeof(MPI_Status) * num_children);
}
if ((parent != -1 && tree_type != MPIR_TREE_TYPE_KARY)
|| (!is_root && tree_type == MPIR_TREE_TYPE_KARY)) {
src = parent;
mpi_errno = MPIC_Recv(send_buf, count, dtype, src, MPIR_BCAST_TAG, comm_ptr, &status);
MPIR_ERR_CHECK(mpi_errno);
/* check that we received as much as we expected */
MPIR_Get_count_impl(&status, MPIR_BYTE_INTERNAL, &recvd_size);
MPIR_ERR_CHKANDJUMP2(recvd_size != nbytes, mpi_errno, MPI_ERR_OTHER,
"**collective_size_mismatch",
"**collective_size_mismatch %d %d", (int) recvd_size, (int) nbytes);
}
if (tree_type == MPIR_TREE_TYPE_KARY) {
for (k = 1; k <= branching_factor; k++) { /* Send to children */
dst = lrank * branching_factor + k;
if (dst >= comm_size)
break;
dst = (dst + root) % comm_size;
if (!is_nb) {
mpi_errno =
MPIC_Send(send_buf, count, dtype, dst, MPIR_BCAST_TAG, comm_ptr, errflag);
} else {
mpi_errno = MPIC_Isend(send_buf, count, dtype, dst,
MPIR_BCAST_TAG, comm_ptr, &reqs[num_req++], errflag);
}
MPIR_ERR_CHECK(mpi_errno);
}
} else {
for (j = 0; j < num_children; j++) {
p = (int *) utarray_eltptr(my_tree.children, j);
dst = *p;
if (!is_nb) {
mpi_errno =
MPIC_Send(send_buf, count, dtype, dst, MPIR_BCAST_TAG, comm_ptr, errflag);
} else {
mpi_errno = MPIC_Isend(send_buf, count, dtype, dst,
MPIR_BCAST_TAG, comm_ptr, &reqs[num_req++], errflag);
}
MPIR_ERR_CHECK(mpi_errno);
}
}
if (is_nb) {
mpi_errno = MPIC_Waitall(num_req, reqs, statuses);
MPIR_ERR_CHECK(mpi_errno);
}
if (tree_type != MPIR_TREE_TYPE_KARY)
MPIR_Treealgo_tree_free(&my_tree);
if (!is_contig) {
if (rank != root) {
mpi_errno = MPIR_Typerep_unpack(send_buf, nbytes, buffer, saved_count, datatype, 0,
&actual_packed_unpacked_bytes, MPIR_TYPEREP_FLAG_NONE);
MPIR_ERR_CHECK(mpi_errno);
}
}
fn_exit:
MPIR_CHKLMEM_FREEALL();
return mpi_errno;
fn_fail:
goto fn_exit;
}
-
性能对比(
my_bcastvsMPI_Bcast):- 实验数据表明(
compare_bcast程序对比):- 2 个进程时性能相同:树形算法无额外优势。
- 4 个及以上进程时:树形广播算法开始显现优势。
- 16 个进程时:
MPI_Bcast(约 0.1268 秒) 显著快于低效的my_bcast(约 0.5109 秒)。差距随进程数增加而增大。
- 实验数据表明(
-
关键注意事项:
- 死锁风险:任何集体调用(包括
MPI_Bcast)都需要确保通信域内所有进程都成功调用了该函数。如果某个进程未能调用,程序将发生死锁(所有进程在隐式同步点等待)。
- 死锁风险:任何集体调用(包括
MPI scatter, gather, allgather
MPI_Scatter 功能
- 类似广播(MPI_Bcast),但以数组分块形式分发数据。
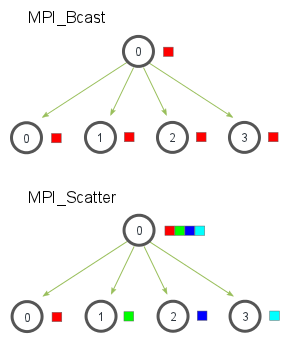
- 根进程将数组按进程秩顺序分发:第 0 个元素发往进程 0,第 1 个元素发往进程 1,依此类推。
- 函数原型:
MPI_Scatter( void* send_data, // 根进程的待分发数组 int send_count, // 每个进程接收的元素数量 MPI_Datatype send_datatype, // 元素数据类型 void* recv_data, // 接收缓冲区(各进程) int recv_count, // 接收元素数量(通常同send_count) MPI_Datatype recv_datatype, // 接收数据类型 int root, // 根进程秩 MPI_Comm communicator) - 关键点:
send_count通常为数组长度/进程数。若不能整除需额外处理。
MPI_Gather 功能
- Scatter 的逆操作:从多进程收集数据到根进程。
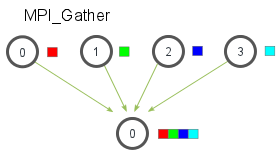
- 数据按进程秩排序收集(如进程 0 的数据排在接收数组最前)。
- 函数原型(与 Scatter 参数一致):
MPI_Gather( void* send_data, // 各进程待发送数据 int send_count, // 发送元素数量 MPI_Datatype send_datatype, void* recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator) - 注意:仅根进程需有效接收缓冲区(非根进程可设
recv_data=NULL),且recv_count指每个进程贡献的元素量(非总量)。
MPI_Allgather 功能
- 多对多通信:所有进程获得完整收集数据(相当于 Gather + Broadcast)
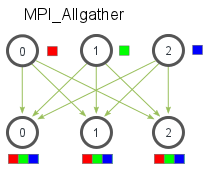
- 函数原型(较之前两个函数缺少了根进程的 rank 这个参数):
MPI_Allgather( void* send_data, // 各进程待发送数据 int send_count, // 发送元素数量 MPI_Datatype send_datatype, void* recv_data, // 接收完整数据的缓冲区(所有进程) int recv_count, // 从每个进程接收的元素量 MPI_Datatype recv_datatype, MPI_Comm communicator)
应用示例:并行计算数组内所有数字的平均值
- **根进程:生成随机数组。
- Scatter 阶段:用
MPI_Scatter将数组均分给所有进程。 - 局部计算:各进程计算子数组平均值。
- 收集阶段:
- 用
MPI_Gather:仅根进程收集子平均值后计算总平均。 - 用
MPI_Allgather:所有进程获知总平均值(见代码all_avg.c)。
- 用
关键代码片段
// 1. 根进程创建数组
if (world_rank == 0) {
rand_nums = create_rand_nums(elements_per_proc * world_size);
}
// 2. 各进程申请子数组缓冲区
float *sub_rand_nums = malloc(sizeof(float) * elements_per_proc);
// 3. Scatter分发数据
MPI_Scatter(rand_nums, elements_per_proc, MPI_FLOAT,
sub_rand_nums, elements_per_proc, MPI_FLOAT,
0, MPI_COMM_WORLD);
// 4. 各进程计算子数组平均值
float sub_avg = compute_avg(sub_rand_nums, elements_per_proc);
// 5. Gather收集子平均值(仅根进程需缓冲区)
float *sub_avgs = NULL;
if (world_rank == 0) {
sub_avgs = malloc(sizeof(float) * world_size);
}
MPI_Gather(&sub_avg, 1, MPI_FLOAT,
sub_avgs, 1, MPI_FLOAT,
0, MPI_COMM_WORLD);
// 5.1 AllGather收集所有子平均值到所有进程上(计算总平均数时就不用再判断是否是root进程)
float *sub_avgs = (float *)malloc(sizeof(float) * world_size);
MPI_Allgather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT,
MPI_COMM_WORLD);
// 6. 根进程计算总平均
if (world_rank == 0) {
float avg = compute_avg(sub_avgs, world_size);
}Parallel rank using MPI_Scatter/Gather/Allgather
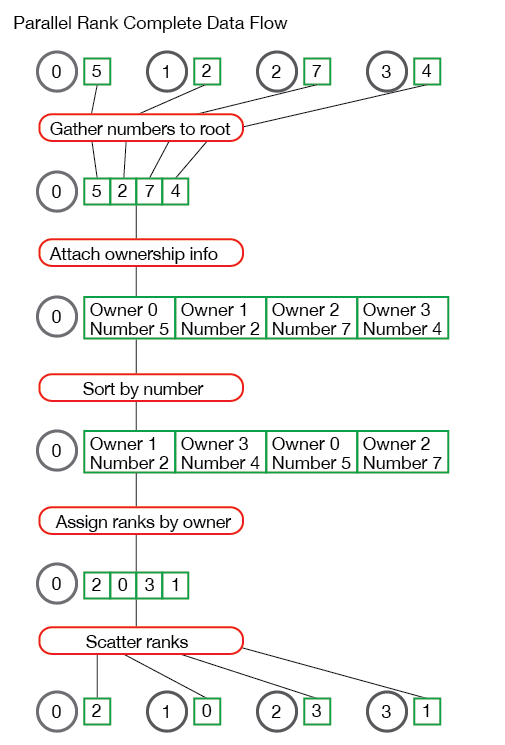
目标:实现并行排名函数 TMPI_Rank
在多个进程中,每个进程持有一个本地数值(整数或浮点数),需计算该数值在整个进程组全局数据集中的排名(即从小到大的顺序位置)。
TMPI_Rank(
void *send_data, # 缓冲区
void *recv_data, # 接收排名
MPI_Datatype datatype,
MPI_Comm comm)核心步骤
- 收集数据到根进程(MPI_Gather)
- 所有进程将本地数据发送至根进程(如进程 0)。
- 根进程动态分配内存存储全局数据集。
// Gathers numbers for TMPI_Rank to process zero. Allocates enough space given the MPI datatype and
// returns a void * buffer to process 0. It returns NULL to all other processes.
void *gather_numbers_to_root(void *number, MPI_Datatype datatype, MPI_Comm comm) {
int comm_rank, comm_size;
MPI_Comm_rank(comm, &comm_rank);
MPI_Comm_size(comm, &comm_size);
// Allocate an array on the root process of a size depending on the MPI datatype being used.
int datatype_size;
MPI_Type_size(datatype, &datatype_size);
void *gathered_numbers;
if (comm_rank == 0) {
gathered_numbers = malloc(datatype_size * comm_size); # 根进程必须在此函数中收集 `comm_size` 个数字,因此它会分配如此长度的数组。
}
// Gather all of the numbers on the root process
MPI_Gather(number, 1, datatype, gathered_numbers, 1, datatype, 0, comm);
return gathered_numbers;
} - 排序并关联进程号
- 根进程创建结构体数组
CommRankNumber,保存各个进程将数字发送到根进程的次序;通过qsort对全局数据排序(根据MPI_FLOAT或MPI_INT选择比较函数):
- 根进程创建结构体数组
typedef struct {
int comm_rank; // 发送数据的进程编号
union { float f; int i; } number; // 数值(支持 int/float)
} CommRankNumber; -
计算排名
- 排序后,按原始进程号顺序生成
ranks[]数组:ranks[i] = 进程 i 的数据在全局的排名
// This function sorts the gathered numbers on the root process and returns an array of // ordered by the process's rank in its communicator. Note - this function is only // executed on the root process. int *get_ranks(void *gathered_numbers, int gathered_number_count, MPI_Datatype datatype) { int datatype_size; MPI_Type_size(datatype, &datatype_size); // Convert the gathered number array to an array of CommRankNumbers. This allows us to // sort the numbers and also keep the information of the processes that own the numbers // intact. CommRankNumber *comm_rank_numbers = malloc(gathered_number_count * sizeof(CommRankNumber)); int i; for (i = 0; i < gathered_number_count; i++) { comm_rank_numbers[i].comm_rank = i; memcpy(&(comm_rank_numbers[i].number), gathered_numbers + (i * datatype_size), datatype_size); } // Sort the comm rank numbers based on the datatype if (datatype == MPI_FLOAT) { qsort(comm_rank_numbers, gathered_number_count, sizeof(CommRankNumber), &compare_float_comm_rank_number); } else { qsort(comm_rank_numbers, gathered_number_count, sizeof(CommRankNumber), &compare_int_comm_rank_number); } // Now that the comm_rank_numbers are sorted, create an array of rank values for each process. The ith // element of this array contains the rank value for the number sent by process i. int *ranks = (int *)malloc(sizeof(int) * gathered_number_count); for (i = 0; i < gathered_number_count; i++) { ranks[comm_rank_numbers[i].comm_rank] = i; } // Clean up and return the rank array free(comm_rank_numbers); return ranks; } - 排序后,按原始进程号顺序生成
-
分发排名结果(MPI_Scatter)
- 根进程将排名值散播回各进程:
MPI_Scatter(ranks, 1, MPI_INT, recv_data, 1, MPI_INT, 0, comm);
- 根进程将排名值散播回各进程:
整个过程如下:
MPI reduce and allreduce
MPI_Reduce
功能
将分布式数据通过特定操作(如求和、求最大值等,这个过程称为规约,即一组数字规约为较小规模的另一组数字)聚合到根进程。
函数原型
MPI_Reduce(
void* send_data, // 待归约的本地数据
void* recv_data, // 根进程接收规约结果的缓冲区
int count, // 数据元素数量
MPI_Datatype datatype, // 数据类型(如MPI_FLOAT)
MPI_Op op, // 归约操作(如MPI_SUM)
int root, // 根进程编号
MPI_Comm communicator // 通信域
)常用操作符
MPI_MAX/MPI_MIN:返回最大/最小值MPI_SUM:求和MPI_PROD:求积MPI_LAND/MPI_LOR:逻辑与(或)MPI_BAND/MPI_BOR:按位与(或)MPI_MAXLOC/MPI_MINLOC:返回最大值(最小值)及其所在进程号
执行流程
- 每个进程对本地数据执行局部计算(如求部分和)。
- 根进程收集所有结果并应用操作(如累加局部和)。
- 最终结果仅存于根进程。
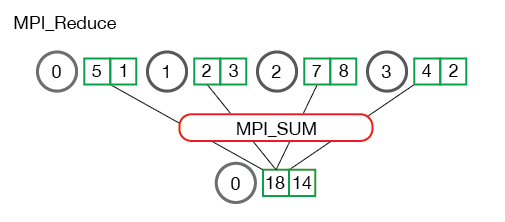 注意:结果求和基于每个元素进行。 换句话说,不是将所有数组中的所有元素累加到一个元素中,而是将每个数组中的第 i 个元素累加到进程 0 结果数组中的第 i 个元素中。
注意:结果求和基于每个元素进行。 换句话说,不是将所有数组中的所有元素累加到一个元素中,而是将每个数组中的第 i 个元素累加到进程 0 结果数组中的第 i 个元素中。
示例:计算全局平均值
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Print the random numbers on each process
printf("Local sum for process %d - %f, avg = %f\n",
world_rank, local_sum, local_sum / num_elements_per_proc);
// Reduce all of the local sums into the global sum
float global_sum;
MPI_Reduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// Print the result
if (world_rank == 0) {
printf("Total sum = %f, avg = %f\n", global_sum,
global_sum / (world_size * num_elements_per_proc));
}MPI_Allreduce
功能
执行归约操作,但将结果广播到所有进程(相当于 MPI_Reduce + MPI_Bcast)。
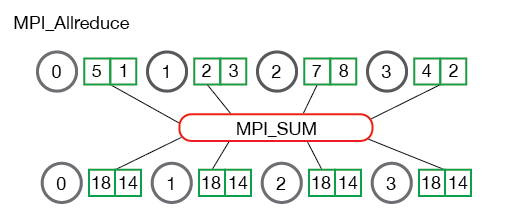
函数原型
MPI_Allreduce(
void* send_data,
void* recv_data, // 所有进程都会接收到结果
int count,
MPI_Datatype datatype,
MPI_Op op,
MPI_Comm communicator
)应用场景
需在所有进程中获取归约结果(如计算标准差需所有进程知道均值)。
示例:计算标准差
// Sum the numbers locally
float local_sum = 0;
int i;
for (i = 0; i < num_elements_per_proc; i++) {
local_sum += rand_nums[i];
}
// Reduce all of the local sums into the global sum in order to
// calculate the mean
float global_sum;
MPI_Allreduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM,
MPI_COMM_WORLD);
float mean = global_sum / (num_elements_per_proc * world_size);
// Compute the local sum of the squared differences from the mean
float local_sq_diff = 0;
for (i = 0; i < num_elements_per_proc; i++) {
local_sq_diff += (rand_nums[i] - mean) * (rand_nums[i] - mean);
}
// Reduce the global sum of the squared differences to the root process
// and print off the answer
float global_sq_diff;
MPI_Reduce(&local_sq_diff, &global_sq_diff, 1, MPI_FLOAT, MPI_SUM, 0,
MPI_COMM_WORLD);
// The standard deviation is the square root of the mean of the squared
// differences.
if (world_rank == 0) {
float stddev = sqrt(global_sq_diff /
(num_elements_per_proc * world_size));
printf("Mean - %f, Standard deviation = %f\n", mean, stddev);
}Groups and communicators
Self-defined communicators
为什么需要自定义通信器?
在简单应用中,使用默认通信器 MPI_COMM_WORLD(包含所有进程)是可行的。但随着应用规模扩大,常需仅与特定子集进程通信(例如网格计算中按行处理数据)。自定义通信器可高效管理子组通信,避免全局通信开销。
通信器概述
- 功能:通信器定义一组可相互通信的进程,提供独立通信域(避免不同组间操作冲突)。
- 核心函数:
MPI_Comm_split是最常用的通信器创建函数,通过“拆分”原通信器生成子组:MPI_Comm_split( MPI_Comm comm, // 原通信器(如 MPI_COMM_WORLD) int color, // 决定进程归属的子组(相同 color 属同一通信器) int key, // 决定新通信器中的进程排名(值小者 rank 低) MPI_Comm* newcomm // 返回新通信器 );- 特殊值:若
color = MPI_UNDEFINED,进程不属于任何新通信器。 - 排序规则:
key值最小者在新通信器中为 rank 0,次小者为 rank 1,以此类推(若 key 相同,则按原通信器 rank 排序)。
- 特殊值:若
示例:按行拆分 4x4 进程网格
目标:将 16 个进程(逻辑排列为 4x4 网格)按行拆分为 4 个通信器,每行一个子组。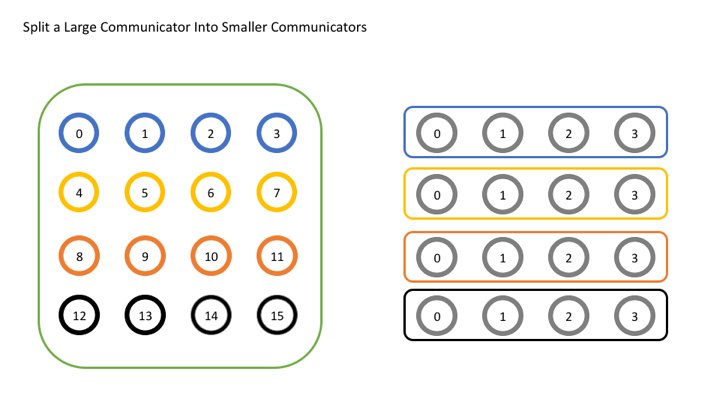
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// 按行分配 color:0~3 为第0行,4~7 为第1行,以此类推
int color = world_rank / 4;
MPI_Comm row_comm;
MPI_Comm_split(MPI_COMM_WORLD, color, world_rank, &row_comm);
int row_rank, row_size;
MPI_Comm_rank(row_comm, &row_rank);
MPI_Comm_size(row_comm, &row_size);
printf("全局 Rank/Size: %d/%d \t 行内 Rank/Size: %d/%d\n",
world_rank, world_size, row_rank, row_size);
MPI_Comm_free(&row_comm); // 释放通信器资源!- 使用原始秩(
world_rank)作为拆分操作的key。 由于我们希望新通讯器中的所有进程与原始通讯器中的所有进程处于相同的顺序,因此在这里使用原始等级值最有意义,因为它已经正确地排序了。
输出示例:
全局 Rank/Size: 0/16 行内 Rank/Size: 0/4
全局 Rank/Size: 4/16 行内 Rank/Size: 0/4 // 第1行的首个进程
全局 Rank/Size: 15/16 行内 Rank/Size: 3/4 // 第4行的末位进程
注意:MPI 进程输出返回顺序不确定,不能依赖
printf顺序判断逻辑正确性。
其他通信器创建方法
-
MPI_Comm_dup复制通信器- 用途:创建原通信器的副本,避免用户代码与第三方库(如数学库)共用
MPI_COMM_WORLD导致冲突。
MPI_Comm_dup(MPI_COMM_WORLD, &new_comm); // 建议应用和库均复制通信器 - 用途:创建原通信器的副本,避免用户代码与第三方库(如数学库)共用
-
MPI_Comm_create_group按组创建- 与
MPI_Comm_create区别:MPI_Comm_create需原通信器所有进程参与集体调用。MPI_Comm_create_group仅需新组内进程参与,适合超大规模应用(如百万进程)。
MPI_Comm_create( MPI_Comm comm, MPI_Group group, MPI_Comm* newcomm) MPI_Comm_create_group( MPI_Comm comm, // 原通信器 MPI_Group group, // 目标组(定义新通信器成员) int tag, // 通信标签 MPI_Comm* newcomm // 返回新通信器 ); - 与
Group operate
组 vs 通信器
- 通信器:包含 通信上下文(唯一ID)和 进程组,支持进程间通信。
- 组:仅定义进程集合,不包含上下文,不能直接用于通信。可通过
MPI_Comm_group从通信器获取组:- 可以获取组的秩和大小(分别为
MPI_Group_rank和MPI_Group_size)。 - 组特有的功能是可以使用组在本地构建新的组——远程操作涉及与其他秩的通信,而本地操作则没有。创建新的通讯器是一项远程操作,因为所有进程都需要决定相同的上下文和组,而在本地创建组是因为它不用于通信,因此每个进程不需要具有相同的上下文。
- 可以随意操作一个组,而无需执行任何通信。
MPI_Group world_group; MPI_Comm_group(MPI_COMM_WORLD, &world_group); // 获取 MPI_COMM_WORLD 的组 - 可以获取组的秩和大小(分别为
集合操作
- 并集(Union):合并两组,包含所有唯一成员。
MPI_Group_union(group1, group2, &new_group); - 交集(Intersection):取两组共有成员。
MPI_Group_intersection(group1, group2, &new_group);
实用函数:MPI_Group_incl
显式选择特定 rank 的进程创建新组:
int ranks[4] = {0, 2, 4, 6}; // 选择原组中 rank 0,2,4,6
MPI_Group_incl(
orig_group,
4, // 进程数
ranks, // 目标 rank 数组
&new_group // 返回新组
);完整示例:创建质数秩进程通信器 目标:创建仅包含秩为质数(1,2,3,5,7,11,13)进程的通信器。
// Get the rank and size in the original communicator
int world_rank, world_size;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the group of processes in MPI_COMM_WORLD
MPI_Group world_group;
MPI_Comm_group(MPI_COMM_WORLD, &world_group);
int n = 7;
const int ranks[7] = {1, 2, 3, 5, 7, 11, 13};
// Construct a group containing all of the prime ranks in world_group
MPI_Group prime_group;
MPI_Group_incl(world_group, 7, ranks, &prime_group);
// Create a new communicator based on the group
MPI_Comm prime_comm;
MPI_Comm_create_group(MPI_COMM_WORLD, prime_group, 0, &prime_comm);
int prime_rank = -1, prime_size = -1;
// If this rank isn't in the new communicator, it will be MPI_COMM_NULL
// Using MPI_COMM_NULL for MPI_Comm_rank or MPI_Comm_size is erroneous
if (MPI_COMM_NULL != prime_comm) {
MPI_Comm_rank(prime_comm, &prime_rank);
MPI_Comm_size(prime_comm, &prime_size);
}
printf("WORLD RANK/SIZE: %d/%d --- PRIME RANK/SIZE: %d/%d\n",
world_rank, world_size, prime_rank, prime_size);
MPI_Group_free(&world_group);
MPI_Group_free(&prime_group);Footnotes
-
尽管
MPI_Send是一个阻塞调用,但 MPI 规范指出 MPI_Send 会阻塞直到发送缓冲区可以被回收。这意味着MPI_Send会在网络可以缓冲消息时返回。如果发送最终无法被网络缓冲,它们将阻塞直到匹配的接收被发布。在我们的案例中,有足够的小发送和频繁的匹配接收,因此无需担心死锁,然而,绝不能假设网络缓冲区足够大。 ↩