本节导读
本节首先简单介绍了一下 I/O 设备的发展,可以看到设备越来越复杂,越来越多样化;然后进一步介绍了主要的 I/O 传输方式,这在后续的驱动程序中都会用上;最后介绍了历史上出现的几种 I/O 设备抽象,从而可以理解设备驱动程序的编程基础所在。
I/O 设备概述
I/O 设备从早期相对比较简单的串口、键盘和磁盘等,逐步发展壮大,已经形成种类繁多,不同领域的各种类型的设备大家庭。而各种设备之间功能不一,性能差异巨大,难以统一地进行管理,这使得对应 I/O 设备的设备驱动程序成为了操作系统中最繁杂的部分。
站在不同的角度会对 I/O 设备有不同的理解。在硬件工程师看来,I/O 设备就是一堆芯片、电源和其他电路的组合;而软件程序员则主要关注 I/O 设备为软件提供的接口(interface),即硬件能够接收的命令、能够完成的功能以及能产生的各种响应或错误等。操作系统重点关注的是如何对 I/O 设备进行管理,而不是其内部的硬件工作原理。
然而,对许多 I/O 设备进行编程还是不可避免地涉及到其内部的硬件细节。如果对 I/O 设备的发展过程进行深入分析,是可以找到 I/O 设备的共性特点,从而可以更好地通过操作系统来管理 I/O 设备。
I/O 设备的发展
计算机的发展历史可体现为计算机硬件中各个部件的复杂度和集成度的变化发展过程。而在 I/O 设备变化过程中,除了外设硬件的多样性越来越广和集成度越来越高以外,与 CPU 进行交互的能力也越来越强。在计算机发展过程中,I/O 设备先后出现了很多,也消亡了不少。
现在 I/O 设备的种类繁多,我们可以从数据传输的特点来给 I/O 设备进行分类。早期的 UNIX 把 I/O 设备分为两类:块设备(block device)和字符设备(character device)。
- 块设备(比如磁盘)把信息存储在固定大小的块中,每个块有独立的地址。块的大小一般在 0.5KB 至 32KB 不等。块设备的 I/O 传输以一个或多个完整的(连续的)块为单位。
- 另一类 I/O 设备是字符设备,字符设备(如串口,键盘等)以单个字符为单位发送或接收一个字符流。字符设备不需要寻址,只需访问 I/O 设备提供的相关接口即可获得 / 发出字符信息流。
后来随着网络的普及,又出现了一类设备:网络设备。
- 网络面向报文而不是面向字符流或数据块,还具有数据丢失等可靠性问题,因此将网络设备映射为常见的文件比较困难。
- 为此 UNIX 的早期继承者 BSD(Berkeley Software Distribution)提出了 socket 接口和对应操作,形成了事实上的 TCP/IP 网络 API 标准。
再后来随着个人电脑的普及,计算机已经进入寻常百姓家中,计算机的功能和控制范围进一步放大,各种类型的 I/O 设备层出不穷。GPU、声卡、显卡等外设已经很难归类到上述的三种分类中,所以它们也就形成了各自独立的设备类型。各种设备出现时间有早晚,功能特点各异,这也使得现有的操作系统在设备驱动的设计和实现上面比较繁杂。当前典型的桌面计算机的 I/O 总体架构如下图所示:
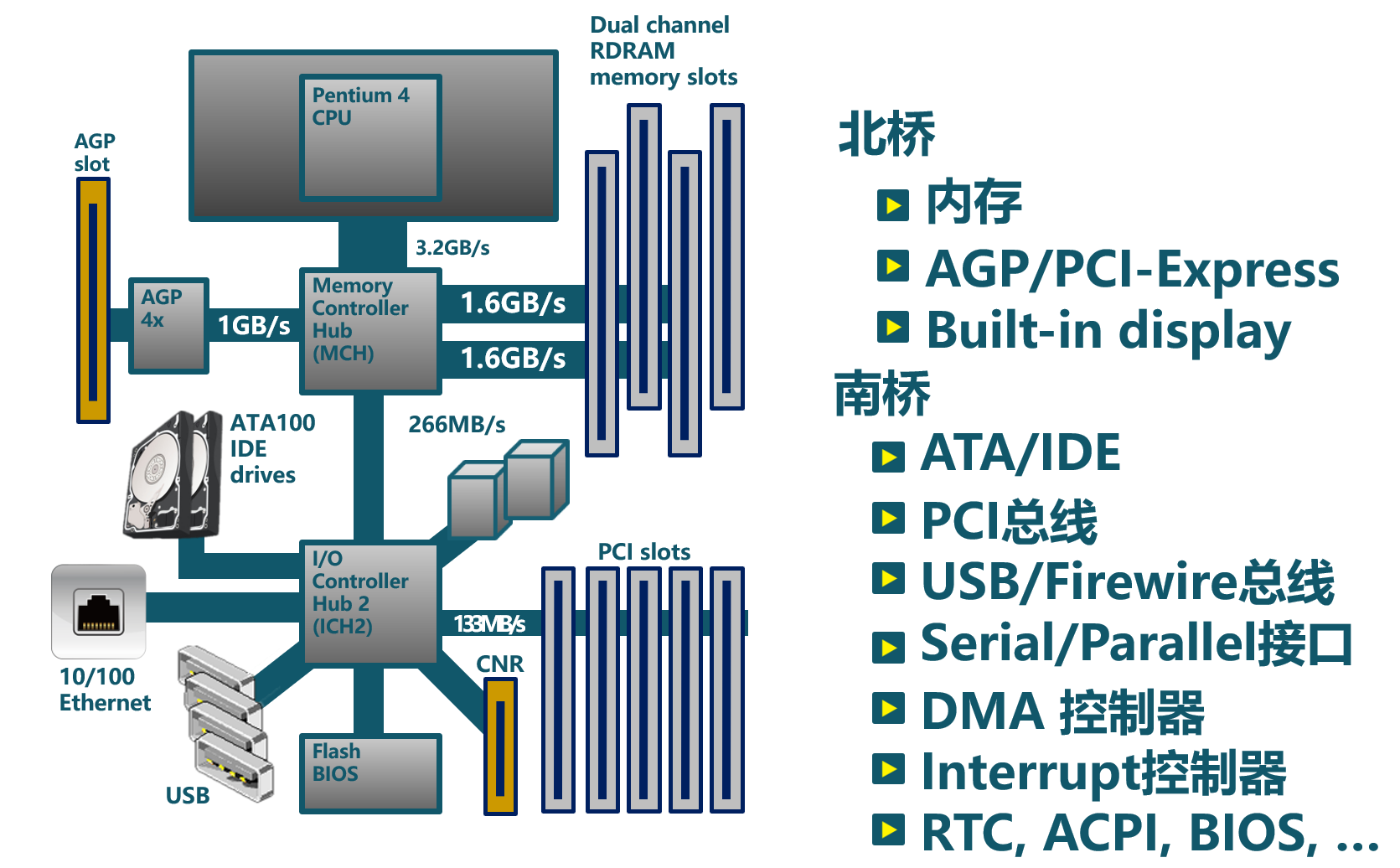
从 CPU 与外设的交互方式的发展过程来看,CPU 可管理的设备数量越来越多,CPU 与设备之间的数据传递性能(延迟和吞吐量)也越来越强。总体上看,CPU 连接的外设有如下的发展过程:
简单设备
计算机发展早期,CPU 连接的设备不多,设备性能较低,所以 CPU 可通过 I/O 接口(如嵌入式系统中的通用输入输出 GPIO 接口)直接控制 I/O 设备(如简单的发光二极管等),这在简单的单片机和微处理器控制设备中经常见到。其特点是 CPU 发出 I/O 命令或数据,可立刻驱动 I/O 设备并产生相应的效果。
[! note] GPIO GPIO(General-Purpose Input/Output)是一种输入 / 输出接口,可以在微控制器或嵌入式系统上使用。它由一组可编程的引脚组成,可以作为输入或输出使用。GPIO 引脚可以控制或感测电平,并且可以用于连接各种类型的传感器和输出设备,如 LED、按钮、马达和各种类型的传感器。
GPIO 引脚可以配置为输入或输出,并且可以通过软件控制其电平。
- 在输入模式下,GPIO 引脚可以监测外部电平变化,如按钮按下或传感器发出的信号。
- 在输出模式下,GPIO 引脚可以控制外部设备的状态,如 LED 亮或灭或电机转动。
GPIO 可用于实现软件定义的功能,这意味着可以在设备驱动程序中来控制 GPIO 引脚的状态。
基于总线的多设备
随着计算机技术的发展,CPU 连接的设备越来越多,需要在 CPU 与 I/O 设备之间增加一层 I/O 控制器(如串口控制器等)。
- CPU 可通过对 I/O 控制器进行编程来控制各种设备。其特点是 CPU 给 I/O 控制器发出 I/O 命令或读写数据,由 I/O 控制器来直接控制 I/O 设备和传达 I/O 设备的信息给 CPU。
- CPU 还需通过访问 I/O 控制器相关寄存器获取 I/O 设备的当前状态。其特点是 CPU 需要轮询检查设备情况,对于低速设备(如串口等)而言,高速 CPU 和低速设备之间是一种串行执行的过程,导致 CPU 利用率低。
随着设备的增多,I/O 控制器也逐渐通用化(如各种总线接口等),把不同设备连接在一起,并能把设备间共性的部分进行集中管理。
同时,为了简化 CPU 与各种设备的连接,出现了 总线(bus) 。总线定义了连接在一起的设备需要共同遵守连接方式和 I/O 时序等,不同总线(如 SPI 总线、I2C 总线、USB 总线、PCI 总线等)的连接方式和 I/O 时序是不同的。
总线
计算机中的总线是一种用于在计算机中连接不同设备的电气传输路径。它可以用于在计算机的主板和外部设备之间传输数据。SPI (Serial Peripheral Interface)、I2C (Inter-Integrated Circuit)、USB (Universal Serial Bus) 和 PCI (Peripheral Component Interconnect) 总线都是用于在电脑和外部设备之间传输数据技术,但它们之间有一些显著的区别。在操作系统的眼里,总线也是一种设备,需要设备驱动程序对其进行管理控制。
连接方式:
- SPI 总线使用四根线来连接设备。它通常使用四条线路,一个用于传输数据(MOSI),一个用于接收数据(MISO),一个用于时钟(SCK),另一个用于选择设备(SS)。
- I2C 总线使用两根线来连接设备。它通常使用两个线路,一个用于传输数据(SDA),另一个用于时钟(SCL)。
- USB 总线是一种通用外部总线,具有即插即用和热插拔的功能,处理器通过 USB 控制器与连接在 USB 上的设备交互。
- PCI 总线使用一条板载总线来连接计算机中处理器(CPU)和周边设备。这个总线通常是一条板载在主板上的总线,它使用一组插座和插头来连接设备。
速度快慢:
- I2C 总线的传输速度较慢,通常在几 KB/s~ 几百 KB/s。
- SPI 总线的传输速度较快,通常在几 MB/s。
- USB 总线设备的传输速度更快,通常在几 MB/s~ 几十 GB/s。
- PCI 总线的传输速度最快,可达到几 GB/s~ 几十 GB/s。
应用领域:
- SPI 总线和 I2C 总线通常用于嵌入式系统中,连接传感器、显示器和存储设备等外设。
- USB 总线和 PCI 总线通常用于桌面和服务器计算机中,连接打印机、键盘、鼠标、硬盘、网卡等外设。
支持中断的设备
随着处理器技术的高速发展,CPU 与外设的性能差距在加大,为了不让 CPU 把时间浪费在等待外设上,即为了解决 CPU 利用率低的问题,I/O 控制器扩展了中断机制(如 Intel 推出的 8259 可编程中断控制器)。CPU 发出 I/O 命令后,无需轮询忙等,可以干其他事情。但外设完成 I/O 操作后,会通过 I/O 控制器产生外部中断,让 CPU 来响应这个外部中断。由于 CPU 无需一直等待外设执行 I/O 操作,这样就能让 CPU 和外设并行执行,提高整个系统的执行效率。
[! note] 中断并非总是比 PIO 好 尽管中断可以做到计算与 I/O 的重叠,但这仅在快速 CPU 和慢速设备之间的数据交换速率差异大的情况下上有意义。
否则,如果设备的处理速度也很快(比如高速网卡的速率可以达到 1000Gbps),那么额外的中断处理和中断上下文切换、进程上下文切换等的代价反而会超过其提高 CPU 利用率的收益。
如果一个或多个设备在短时间内产生大量的外设中断,可能会使得系统过载,并且让操作系统应付不过来,从而引发活锁 1 。
在上述比较特殊的情况下,采用轮询的方式反而更有效,可以在操作系统自身的调度上提供更多的控制,甚至绕过操作系统直接让应用管理和控制外设。
高吞吐量设备
外设技术的发展也在加速,某些高性能外设(SSD,网卡等)的性能在逐步提高,如果每次中断产生的 I/O 数据传输量少,那么 I/O 设备(如硬盘 / SSD 等)要在短期内传输大量数据就会频繁中断 CPU,导致中断处理的总体开销很大,系统效率会降低。
通过 DMA(Direct Memory Access,直接内存访问)控制器(如 Intel 推出 8237DMA 控制器等),可以让外设在 CPU 没有访问内存的时间段中,以数据块的方式进行外设和内存之间的数据传输,且不需要 CPU 的干预。这样 I/O 设备的传输效率就大大提高了。CPU 只需在开始传送前发出 DMA 指令,并在外设结束 DMA 操作后响应其发出的中断信息即可。
I/O 传输方式
在上述的 I/O 设备发展过程可以看到, CPU 主要有三种方式可以与外设进行数据传输:
- Programmed I/O (简称 PIO)、
- Interrupt、
- Direct Memory Access (简称 DMA),如下图所示:
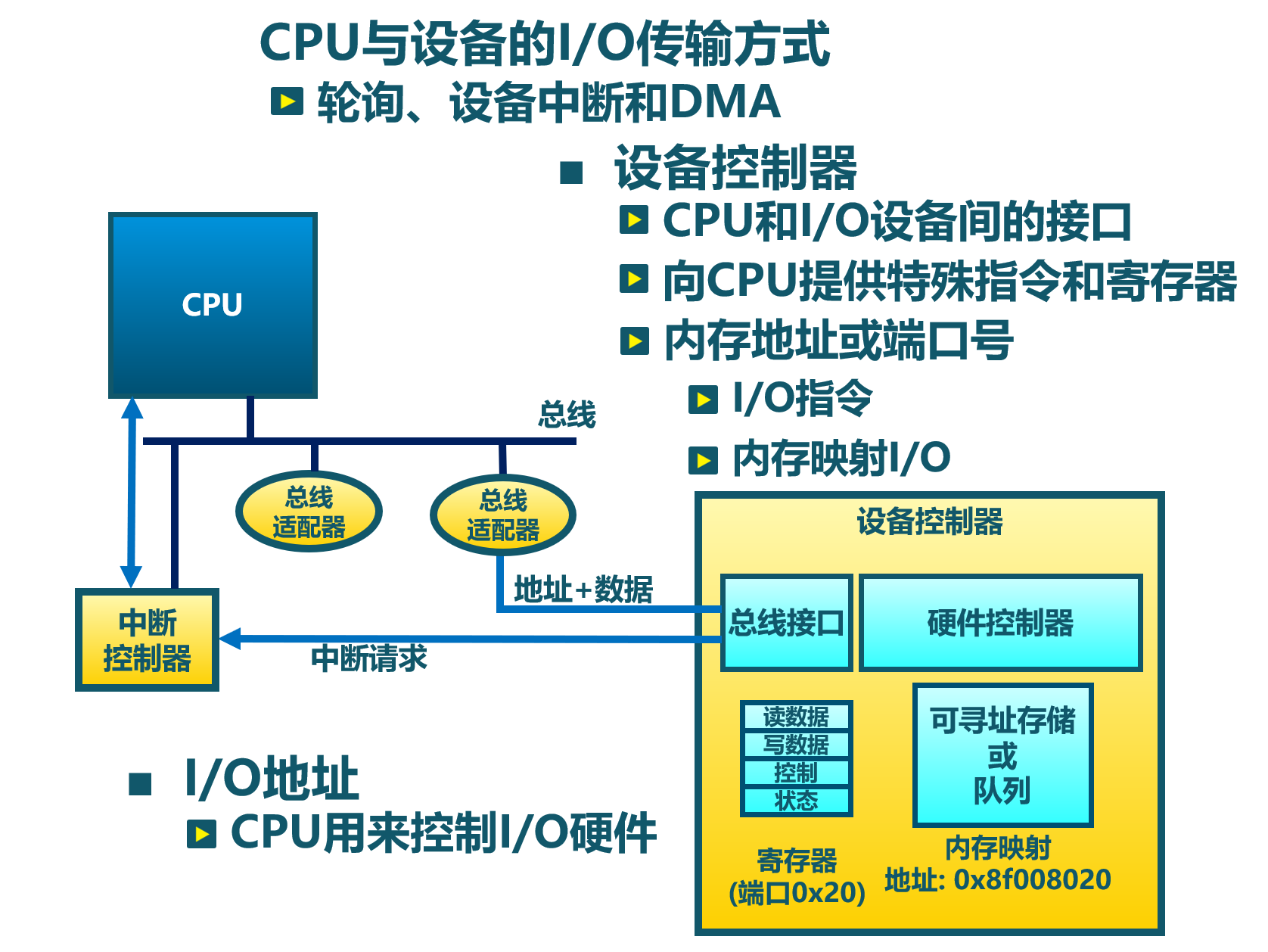
Programmed I/O
PIO 指 CPU 通过发出 I/O 指令的方式来进行数据传输。PIO 方式可以进一步细分为:
- 基于 Memory-mapped 的 PIO(简称 MMIO)
- MMIO 是将 I/O 设备物理地址映射到内存地址空间,这样 CPU 就可以通过普通访存指令将数据送到 I/O 设备在主存上的位置,从而完成数据传输。
- Port-mapped 的 PIO(简称 PMIO),
- 对于采用 PMIO 方式的 I/O 设备,它们具有自己独立的地址空间,与内存地址空间分离。
- CPU 若要访问 I/O 设备,则需要使用特殊的 I/O 指令,如 x86 处理器中的
IN、OUT指令,这样 CPU 直接使用 I/O 指令,就可以通过 PMIO 方式访问设备。
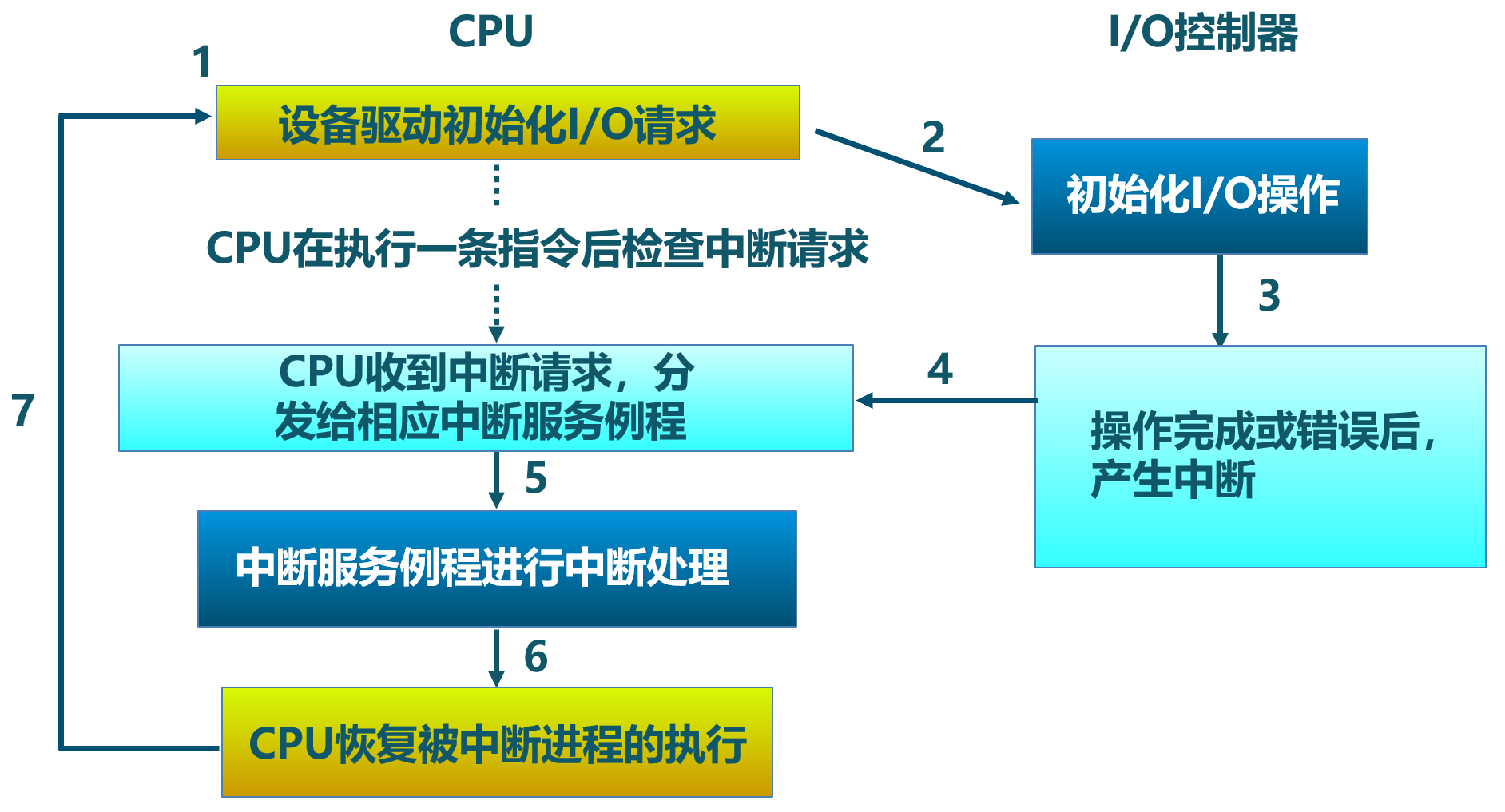
Interrupt-based I/O
如果采用 PIO 方式让 CPU 来获取外设的执行结果,那么这样的 I/O 软件中有一个 CPU 读外设相关寄存器的循环,直到 CPU 收到可继续执行 I/O 操作的外设信息后,CPU 才能进一步做其它事情。当外设 (如串口) 的处理速度远低于 CPU 的时候,将使 CPU 处于忙等的低效状态中。
中断机制的出现,极大地缓解了 CPU 的负担。
- CPU 可通过 PIO 方式来通知外设,只要 I/O 设备有了 CPU 需要的数据,便会发出中断请求信号。
- CPU 发完通知后,就可以继续执行与 I/O 设备无关的其它事情。
- 中断控制器会检查 I/O 设备是否准备好进行传输数据,并发出中断请求信号给 CPU。
- 当 CPU 检测到中断信号,CPU 会打断当前执行,并处理 I/O 传输。
下图显示了设备中断的 I/O 处理流程:
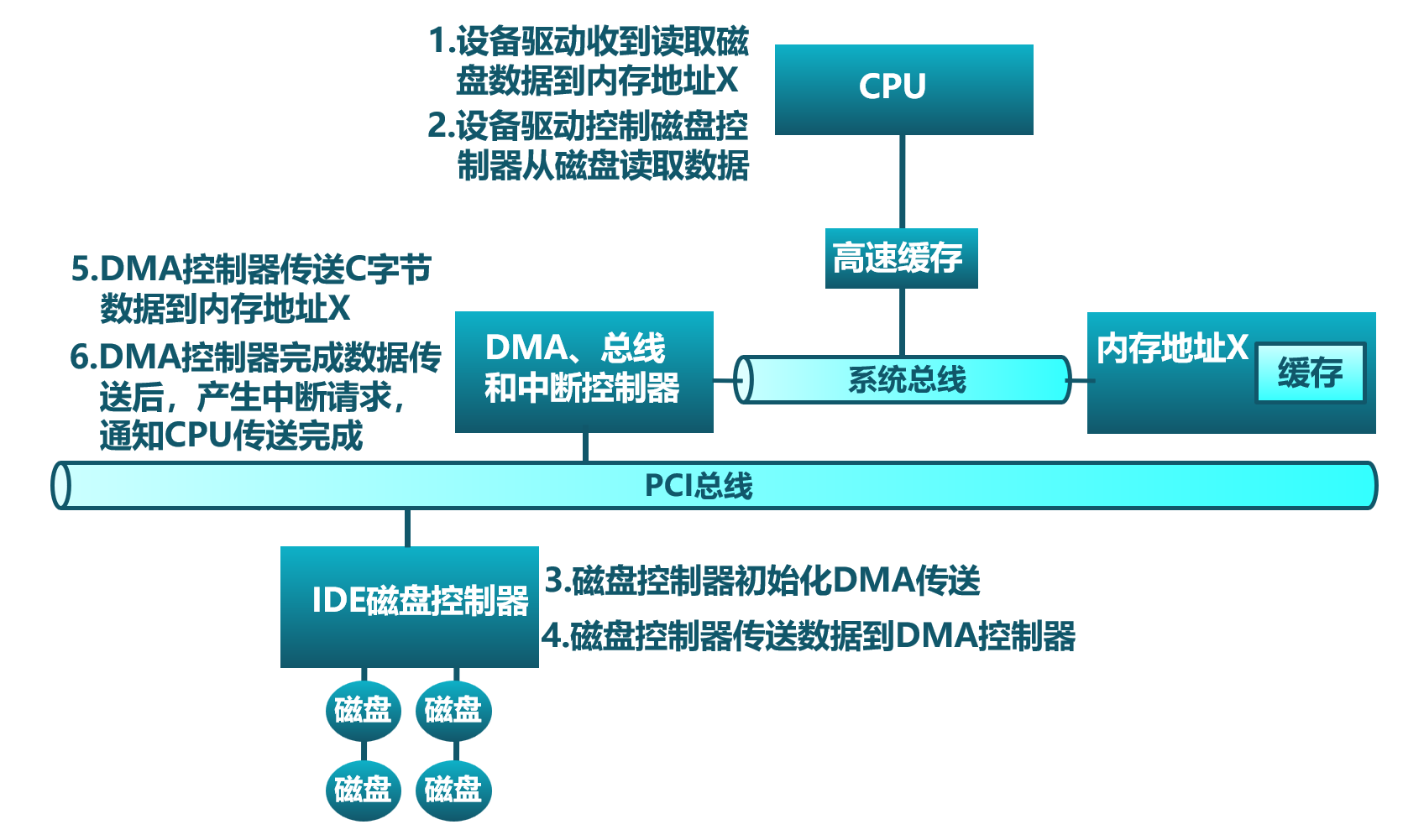
Direct Memory Access
如果外设每传一个字节都要产生一次中断,那系统执行效率还是很低。DMA(Direct Memory Access)是一种用于在计算机系统中进行快速数据传输的技术。它允许设备直接将数据传输到内存中,而不必通过 CPU 来直接处理。这样使得 CPU 从 I/O 任务中解脱出来,从而提高了系统的整体性能。
DMA 操作通常由 DMA 控制器来完成。
- 当 CPU 需要从内存中读取或写入设备数据时,它会提前向 DMA 控制器发出准备请求,
- 然后 DMA 控制器会在后续阶段直接将数据传输到目标位置。
- 当 DMA 控制器将数据传输完成后,会发送一个中断告知 CPU 传送结束。
下图显示了磁盘数据的 DMA 传输的图示例子:
在后面的小节中,我们会进一步介绍基于 I/O 控制器的轮询,中断等方式的设备驱动的设计与实现。
[! note] DMA 技术工作流程
- 当 CPU 想与外设交换一块数据时,它会向 DMA 控制器发出一条命令。命令的基本内容包括:读或写 I/O 设备的操作标记,I/O 设备的地址,DMA 内存的起始地址和传输长度。
- 然后 CPU 继续其它工作。DMA 控制器收到命令后,会直接从内存中或向内存传送整块数据,这个传输过程不再需要通过 CPU 进行操作。
- 传送结束后,DMA 控制器会通过 I/O 控制器给 CPU 发送一个表示 DMA 操作结束的中断。
- CPU 在收到中断后,知道这次 I/O 操作完成,可进行后续相关事务的处理。
在后续讲解的 virtio-blk, virtio-gpu 等模拟设备中,就是通过 DMA 来传输数据的。
I/O 设备抽象
I/O 接口的交互协议
对于一个外设而言,它包含了两部分重要组成部分。
- 第一部分是对外向系统其他部分展现的设备 I/O 接口(hardware I/O interface),这样操作系统才能通过接口来管理控制外设。所有设备都有自己的特定接口以及典型交互的协议。
- 第二部分是对内的内部结构,包含了设备相关物理实现。
由于外在接口的多样性,使得操作系统难以统一管理外设。
如果我们不考虑具体的设备,而是站在一个高度抽象的角度来让软件管理设备,那么我们就不用太关注设备的内部结构,而重点考虑设备的接口如何进行简化。其实一个简化的抽象设备接口需要包括三部分:状态、命令、数据。
- 软件可以读取并查看设备的当前状态,从而根据设备当前状态决定下一步的 I/O 访问请求;
- 而软件是通过一系列的命令来要求设备完成某个具体的 I/O 访问请求;
- 在完成一个 I/O 访问请求中,会涉及到将数据传给设备或从设备接收数据。
CPU 与设备间的 I/O 接口的交互协议如下所示:
while STATUS == BUSY {}; // 等待设备执行完毕
DATA = data; // 把数据传给设备
COMMAND = command; // 发命令给设备
while STATUS == BUSY {}; // 等待设备执行完毕
引入中断机制后,这个简化的抽象设备接口需要包括四部分:状态、命令、数据、中断。CPU 与设备间的 I/O 接口的交互协议如下所示:
DATA = data; // 把数据传给设备
COMMAND = command; // 发命令给设备
do_otherwork(); // 做其它事情
... // I/O设备完成I/O操作,并产生中断
... // CPU执行被打断以响应中断
trap_handler(); // 执行中断处理例程中的相关I/O中断处理
restore_do_otherwork();// 恢复CPU之前被打断的执行
... // 可继续进行I/O操作
中断机制允许 CPU 的高速计算与外设的慢速 I/O 操作可以重叠(overlap),CPU 不用花费时间等待外设执行的完成,这样就形成 CPU 与外设的并行执行,这是提高 CPU 利用率和系统效率的关键。
站在软件的角度来看,为提高一大块数据传输效率引入的 DMA 机制并没有改变抽象设备接口的四个部分。仅仅是上面协议伪码中的 data 变成了 data block 。这样传输单个数据产生的中断频度会大大降低,从而进一步提高 CPU 利用率和系统效率。
这里描述了站在软件角度上的抽象设备接口的交互协议。如果站在操作系统的角度,还需把这种设备抽象稍微再具体一点,从而能够在操作系统中实现对设备的管理。
基于文件的 I/O 设备抽象
在二十世纪七十到八十年代,计算机专家为此进行了诸多的探索,希望能给 I/O 设备提供一个统一的抽象。首先是把本来专门针对存储型 I/O 设备的文件进行扩展,认为所有的 I/O 设备都是文件,这就是传统 UNIX 中常见的设备文件。所有的 I/O 设备按照文件的方式进行处理。你可以在 Linux 下执行如下命令,看到各种各样的设备文件:
$ ls /dev
i2c-0 gpiochip0 nvme0 tty0 rtc0 ...
这些设备按照文件的访问接口(即 open/close/read/write )来进行处理。==但由于各种设备的功能繁多,仅仅靠 read/write 这样的方式很难有效地与设备交互==。于是 UNIX 的后续设计者提出了一个非常特别的系统调用 ioctl ,即 input/output control 的含义。
- 它是一个专用于设备输入输出操作的系统调用, 该调用传入一个跟设备有关的请求码,系统调用的功能完全取决于设备驱动程序对请求码的解读和处理。
- 比如,CD-ROM 驱动程序可以弹出光驱,于是操作系统就可以设定一个 ioctl 的请求码来对应这种操作。当应用程序发出带有 CD-ROM 设备文件描述符和 弹出光驱 请求码这两个参数的
ioctl系统调用请求后,操作系统中的 CD-ROM 驱动程序会识别出这个请求码,并进行弹出光驱的 I/O 操作。
思路就是将具体实现的细节交给驱动程序。
ioctl 这名字第一次出现在 Unix 第七版中,他在很多类 unix 系统(比如 Linux、Mac OSX 等)都有提供,不过不同系统的请求码对应的设备有所不同。Microsoft Windows 在 Win32 API 里提供了相似的函数,叫做 DeviceIoControl。
表面上看,基于设备文件的设备管理得到了大部分通用操作系统的支持,且这种 ioctl 系统调用很灵活,但它的问题是太灵活了,请求码的定义无规律可循,文件的接口太面向用户应用,并没有挖掘出操作系统在进行 I/O 设备处理过程中的共性特征。所以文件这个抽象还不足覆盖到操作系统对设备进行管理的整个执行过程中。
基于流的 I/O 设备抽象
在二十世纪八十到九十年代的 UNIX 操作系统的发展过程中,出现了网络等更加复杂的设备,也随之出现了 流 stream 这样的面向 I/O 设备管理的抽象。Dennis M. Ritchie 在 1984 年写了一个技术报告 “A Stream Input-Output System”,详细介绍了基于流的 I/O 设备的抽象设计。现在看起来,是希望把 UNIX 中的管道(pipe)机制拓展到内核的设备驱动中。
流是用户进程和设备或伪设备之间的全双工连接。
- 它由几个线性连接的处理模块(module)组成,类似于一个 shell 程序中的管道(pipe),用于数据双向流动。
- 流中的模块通过向邻居模块传递消息来进行通信。
- 除了一些用于流量控制的常规变量,模块不需要访问其邻居模块的其他数据。
- 此外,一个模块只为每个邻居提供一个入口点,即一个接受消息的例程。
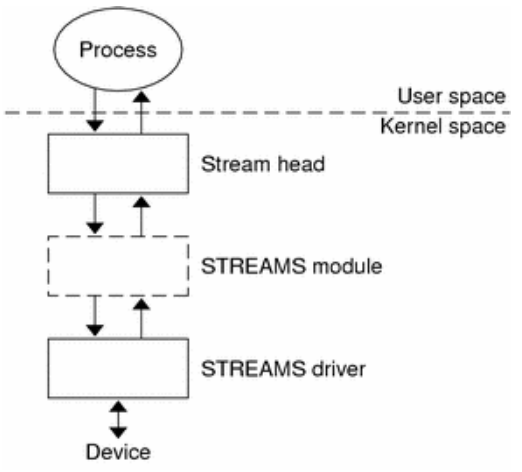
- 在最接近进程的流的末端是一组例程,它们为操作系统的其余部分提供接口。用户进程的写操作请求和输入 / 输出控制请求被转换成发送到流的消息,而读请求将从流中获取数据并将其传递给用户进程。
- 流的另一端是设备驱动程序模块。对字符或网络传输而言,从用户进程以流的方式传递数据将被发送到设备;设备检测到的字符、网络包和状态转换被合成为消息,并被发送到流向用户进程的流中。整个过程会经过多个中间模块,这些模块会以各种方式处理或过滤消息。
在具体实现上,当设备打开时,流中的两个末端管理的内核模块自动连接;中间模块是根据用户程序的请求动态附加的。为了能够方便动态地插入不同的流处理模块,这些中间模块的读写接口被设定为相同语义。
每个流处理模块由一对队列(queue)组成,每个方向一个队列。队列不仅包括数据队列本身,还包括两个例程和一些状态信息。
- 一个是 put 例程,它由邻居模块调用以将消息放入数据队列中。
- 另一个是服务(service)例程,被安排在有工作要做的时候执行。
- 状态信息包括指向下游下一个队列的指针、各种标志以及指向队列实例化所需的附加状态信息的指针。
虽然基于流的 I/O 设备抽象看起来很不错,但并没有在其它操作系统中推广开来。其中的一个原因是 UNIX 在当时还是一个曲高和寡的高端软件系统,运行在高端的工作站和服务器上,支持的外设有限。而 Windows 这样的操作系统与 Intel 的 x86 形成了 wintel 联盟,在个人计算机市场被广泛使用,并带动了而多媒体,GUI 等相关外设的广泛发展,Windows 操作系统并没有采用流的 I/O 设备抽象,而是针对每类设备定义了一套 Device Driver API 接口,提交给外设厂商,让外设厂商写好相关的驱动程序,并加入到 Windows 操作系统中。这种相对实用的做法再加上微软的号召力让各种外设得到了 Windows 操作系统的支持,但也埋下了标准不统一,容易包含 bug 的隐患。
基于 virtio 的 I/O 设备抽象
到了二十一世纪,对于操作系统如何有效管理 I/O 设备的相关探索还在继续,但环境已经有所变化。随着互联网和云计算的兴起,在数据中心的物理服务器上通过虚拟机技术(Virtual Machine Monitor, Hypervisor 等),运行多个虚拟机(Virtual Machine),并在虚拟机中运行 guest 操作系统的模式成为一种主流。但当时存在多种虚拟机技术,如 Xen、VMware、KVM 等,要支持虚拟化 x86、Power 等不同的处理器和各种具体的外设,并都要求让以 Linux 为代表的 guest OS 能在其上高效的运行。这对于虚拟机和操作系统来说,实在是太繁琐和困难了。
IBM 资深工程师 Rusty Russell 在开发 Lguest (Linux 内核中的的一个 hypervisor(一种高效的虚拟计算机的系统软件)) 时,深感写模拟计算机中的高效虚拟 I/O 设备的困难,且编写 I/O 设备的驱动程序繁杂且很难形成一种统一的表示。于是他经过仔细琢磨,提出了一组通用 I/O 设备的抽象 – virtio 规范。
- 虚拟机(VMM 或 Hypervisor)提供 virtio 设备的实现,virtio 设备有着统一的 virtio 接口,guest 操作系统只要能够实现这些通用的接口,就可以管理和控制各种 virtio 设备。
- 而虚拟机与 guest 操作系统的 virtio 设备驱动程序间的通道是基于共享内存的异步访问方式来实现的,效率很高。虚拟机会进一步把相关的 virtio 设备的 I/O 操作转换成物理机上的物理外设的 I/O 操作。这就完成了整个 I/O 处理过程。
由于 virtio 设备的设计,使得虚拟机不用模拟真实的外设,从而可以设计一种统一和高效的 I/O 操作规范来让 guest 操作系统处理各种 I/O 操作。这种 I/O 操作规范其实就形成了基于 virtio 的 I/O 设备抽象,并逐渐形成了事实上的虚拟 I/O 设备的标准。
外部设备为 CPU 提供存储、网络等多种服务,是计算机系统中除运算功能之外最为重要的功能载体。CPU 与外设之间通过某种协议传递命令和执行结果;virtio 协议最初是为虚拟机外设而设计的 IO 协议,但是随着应用范围逐步扩展到物理机外设,virtio 协议正朝着更适合物理机使用的方向而演进。
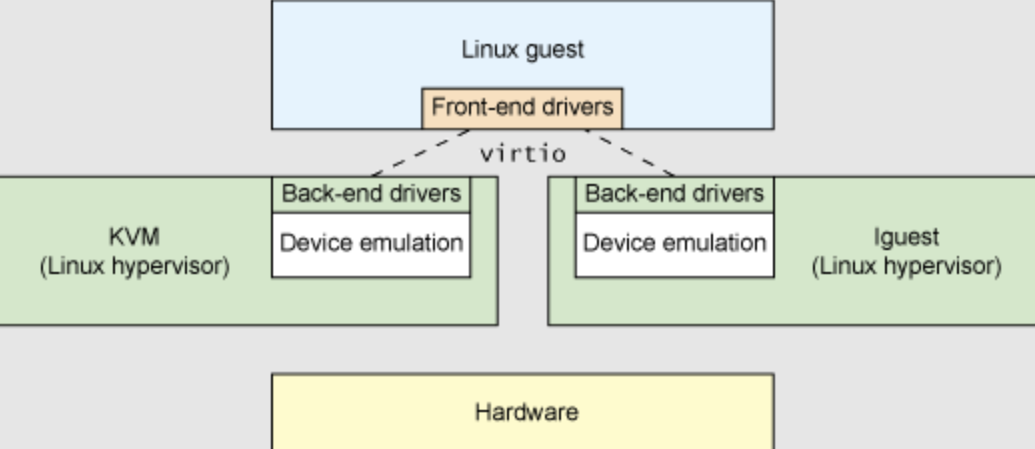
由于 virtio 具有相对的通用性和代表性,本章将进一步分析 virtio 规范,以及针对多种 virtio 设备的设备驱动程序,从而对设备驱动程序和操作系统其他部分的关系有一个更全面的了解。
[! note] virtio 历史 Rusty Russell 工程师在 2008 年在 “ACM SIGOPS Operating Systems Review” 期刊上发表了一篇论文“virtio: towards a de-facto standard for virtual I/O devices”,提出了给虚拟环境(Virtual Machine)中的操作系统提供一套统一的设备抽象,这样操作系统针对每类设备只需写一种驱动程序就可以了,这极大降低了系统虚拟机(Virtual Machine Monitor)和 Hypervisor,以及运行在它们提供的虚拟环境中的操作系统的开发成本,且可以显著提高 I/O 的执行效率。
目前 virtio 已经有相应的规范,最新的 virtio spec 版本是 v1.1。
I/O 执行模型
从用户进程的角度看,用户进程是通过 I/O 相关的系统调用(简称 I/O 系统调用)来进行 I/O 操作的。在 UNIX 环境中,I/O 系统调用有多种不同类型的执行模型。根据 Richard Stevens 的经典书籍 “UNIX Network Programming Volume 1: The Sockets Networking” 的 6.2 节 “I/O Models ” 的介绍,大致可以分为五种 I/O 执行模型 (I/O Execution Model,简称 IO Model, IO 模型):
-
blocking IO
-
nonblocking IO
-
IO multiplexing
-
signal driven IO
-
asynchronous IO
当一个用户进程发出一个 read I/O 系统调用时,主要经历两个阶段:
-
等待数据准备好 (Waiting for the data to be ready)
-
把数据从内核拷贝到用户进程中 (Copying the data from the kernel to the process)
上述五种 IO 模型在这两个阶段有不同的处理方式。需要注意,阻塞与非阻塞关注的是进程的执行状态:
-
阻塞:进程执行系统调用后会被阻塞
-
非阻塞:进程执行系统调用后不会被阻塞
同步和异步关注的是消息通信机制:
-
同步:用户进程与操作系统(设备驱动)之间的操作是经过双方协调的,步调一致的
-
异步:用户进程与操作系统(设备驱动)之间并不需要协调,都可以随意进行各自的操作
阻塞 IO(blocking IO)
基于阻塞 IO 模型的文件读系统调用 – read 的执行过程如下图所示:
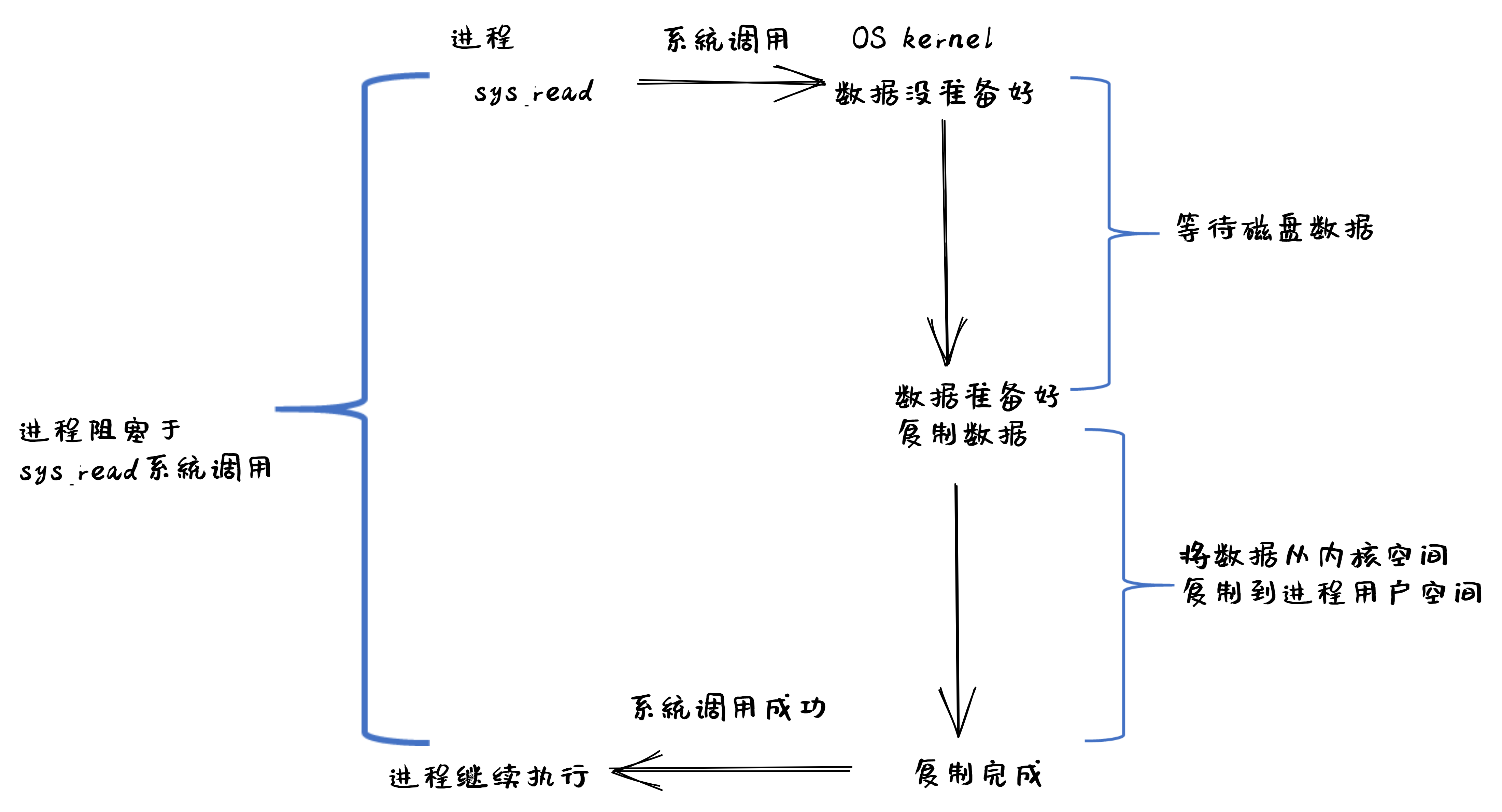
从上图可以看出执行过程包含如下步骤:
-
用户进程发出
read系统调用; -
内核发现所需数据没在 I/O 缓冲区中,需要向磁盘驱动程序发出 I/O 操作,并让用户进程处于阻塞状态;
-
磁盘驱动程序把数据从磁盘传到 I/O 缓冲区后,通知内核(一般通过中断机制),内核会把数据从 I/O 缓冲区拷贝到用户进程的 buffer 中,并唤醒用户进程(即用户进程处于就绪态);
-
内核从内核态返回到用户态的进程,此时
read系统调用完成。
所以阻塞 IO(blocking IO)的特点就是用户进程在 I/O 执行的两个阶段(等待数据和拷贝数据两个阶段)都是阻塞的。
当然,如果正好用户进程所需数据位于内存中,那么内核会把数据从 I/O 缓冲区拷贝到用户进程的 buffer 中,并从内核态返回到用户态的进程, read 系统调用完成。这个由于 I/O 缓冲带了的优化结果不会让用户进程处于阻塞状态。
非阻塞 IO(non-blocking IO)
基于非阻塞 IO 模型的文件读系统调用 – read 的执行过程如下图所示:
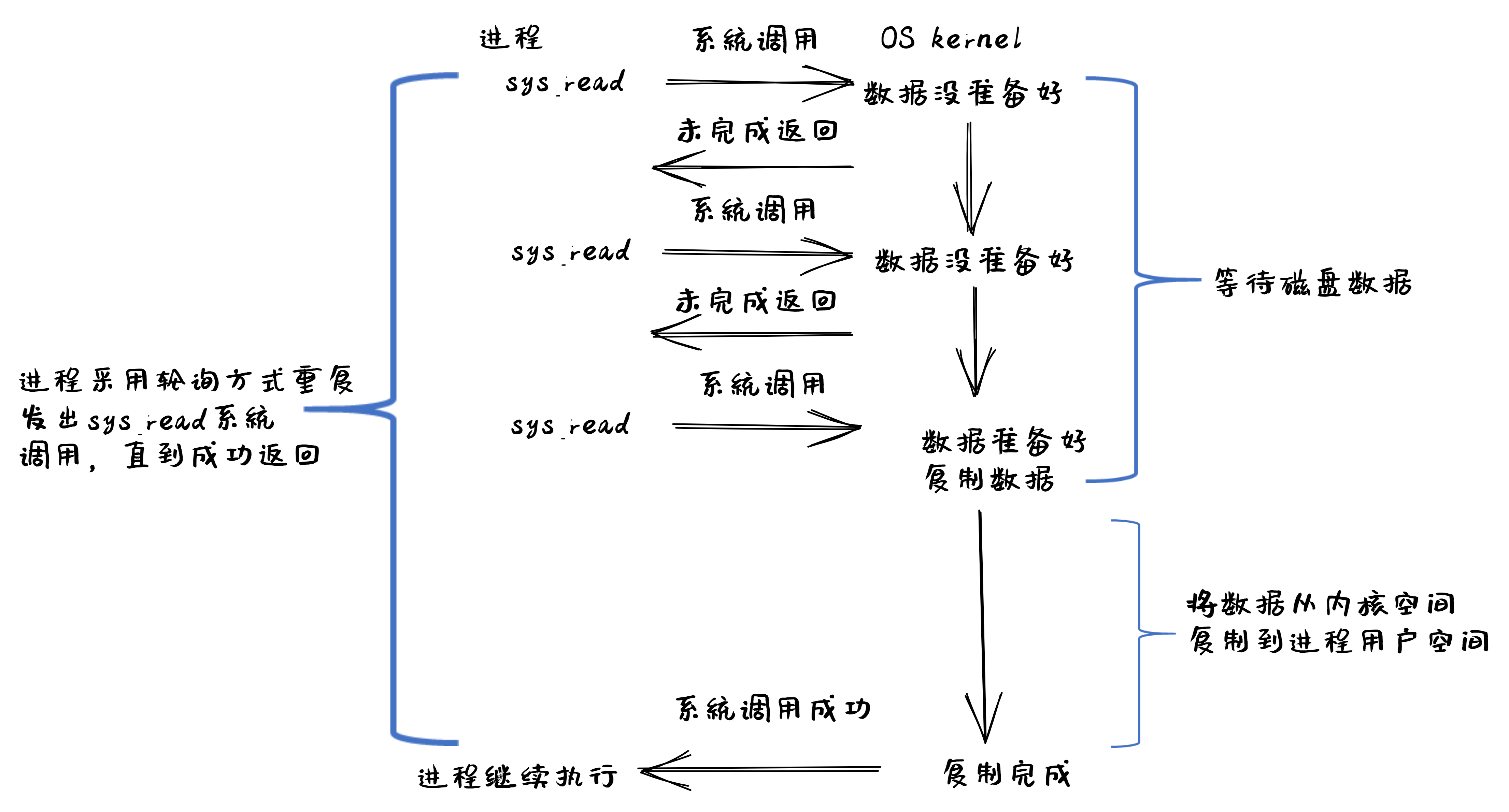
从上图可以看出执行过程包含如下步骤:
-
用户进程发出
read系统调用; -
内核发现所需数据没在 I/O 缓冲区中,需要向磁盘驱动程序发出 I/O 操作,并不会让用户进程处于阻塞状态,而是立刻返回一个 error;
-
用户进程判断结果是一个 error 时,它就知道数据还没有准备好,于是它可以等待一段时间再次发送 read 操作(这一步操作可以重复多次);
-
磁盘驱动程序把数据从磁盘传到 I/O 缓冲区后,通知内核(一般通过中断机制),内核在收到通知且再次收到了用户进程的 system call 后,会马上把数据从 I/O 缓冲区拷贝到用户进程的 buffer 中;
-
内核从内核态返回到用户态的进程,此时
read系统调用完成。
所以,在非阻塞式 IO 的特点是用户进程不会被内核阻塞,而是需要用户进程不断的主动询问内核所需数据准备好了没有。非阻塞系统调用相比于阻塞系统调用的的差异在于在被调用之后会立即返回。
使用系统调用 fcntl ( fd, F_SETFL, O_NONBLOCK ) 可以将对某文件描述符 fd 进行的读写访问设为非阻塞 IO 模型的读写访问。
多路复用 IO(IO multiplexing)
IO multiplexing 对应的 I/O 系统调用是 select 和 epoll 等,也称这种 IO 方式为事件驱动 IO (event driven IO)。
select和epoll的优势在于,采用单进程方式就可以同时处理多个文件或网络连接的 I/O 操作。- 其基本工作机制就是通过
select或epoll系统调用来不断地轮询用户进程关注的所有文件句柄或 socket,当某个文件句柄或 socket 有数据到达了,select或epoll系统调用就会返回到用户进程,用户进程再调用read系统调用,让内核将数据从内核的 I/O 缓冲区拷贝到用户进程的 buffer 中。
在多路复用 IO 模型中,==对于用户进程关注的每一个文件句柄或 socket,一般都设置成为 non-blocking,只是用户进程是被 select 或 epoll 系统调用阻塞住了==。
select/epoll 的优势:
- 并不会导致单个文件或 socket 的 I/O 访问性能更好,而是在有很多个文件或 socket 的 I/O 访问情况下,其总体效率会高。
基于多路复用 IO 模型的文件读的执行过程如下图所示:
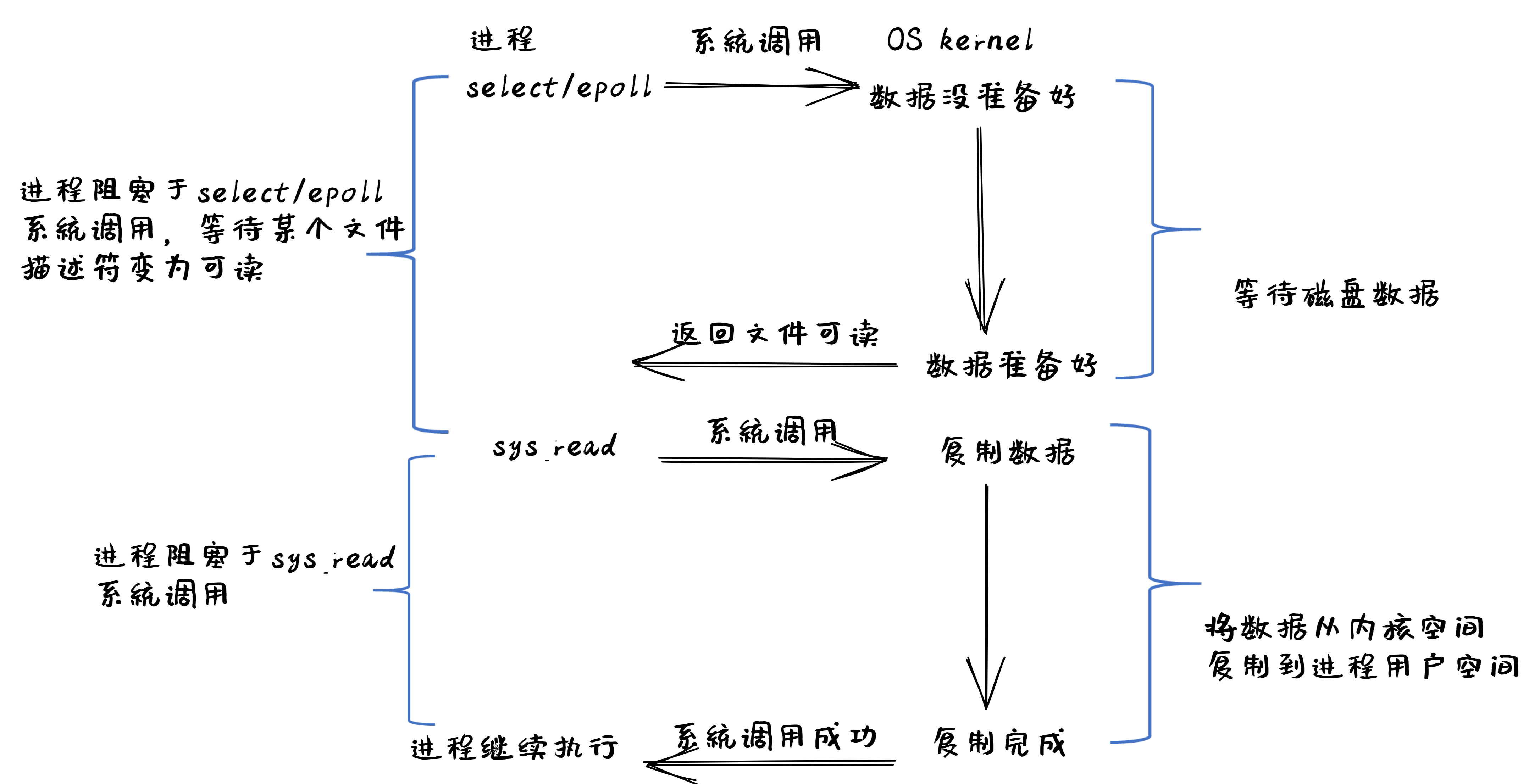
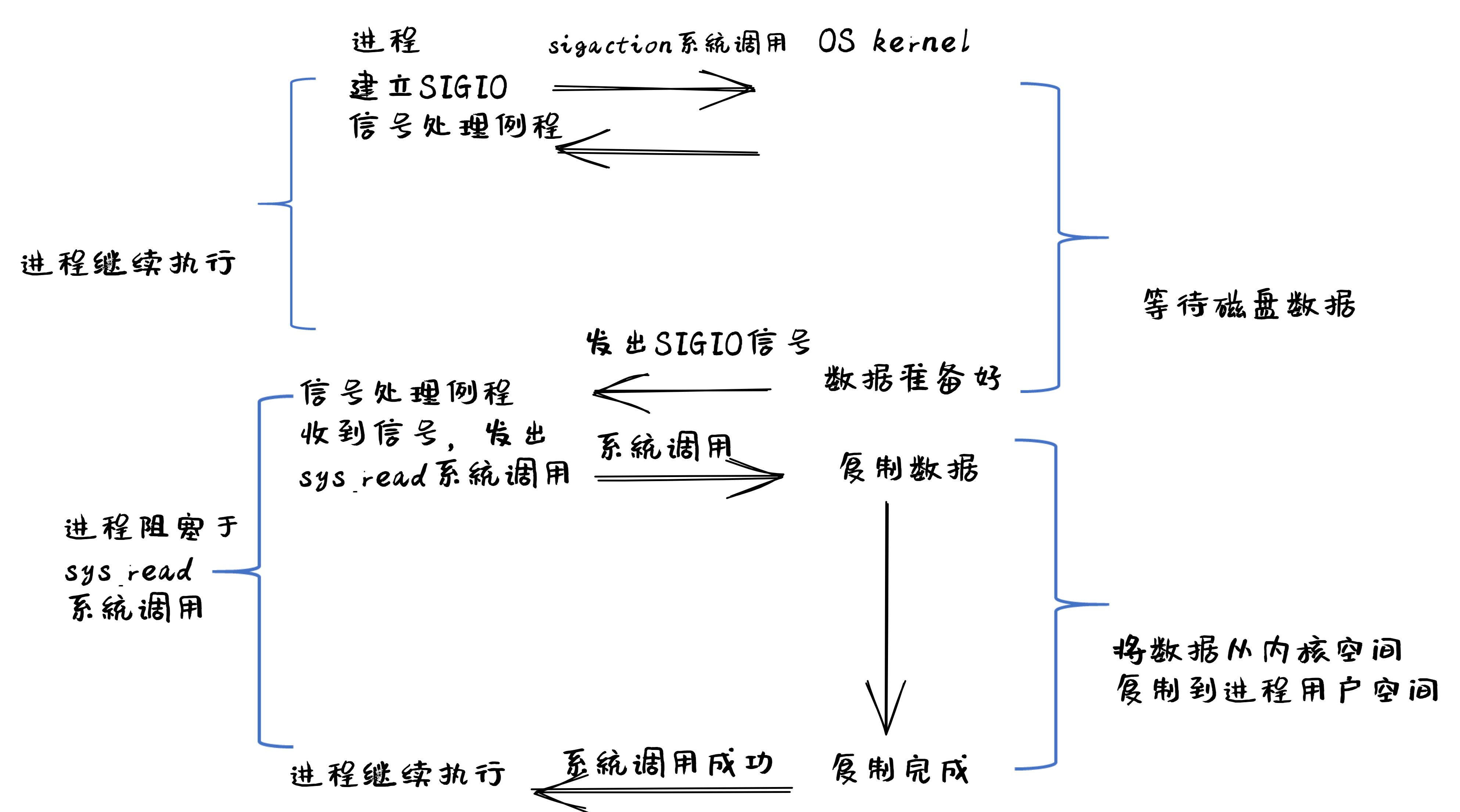
信号驱动 IO(signal driven I/O)
当进程发出一个 read 系统调用时,会向内核注册一个信号处理函数,然后系统调用返回。进程不会被阻塞,而是继续执行。当内核中的 I/O 数据就绪时,会发送一个信号给进程,进程便在信号处理函数中调用 I/O 读取数据。此模型的特点是,采用了回调机制,这样开发和调试应用的难度加大。
基于信号驱动 IO 模型的文件读的执行过程如下图所示:
异步 IO(Asynchronous I/O)
用户进程发起 async_read 异步系统调用之后,立刻就可以开始去做其它的事。而另一方面,==从内核的角度看,当它收到一个 async_read 异步系统调用之后,首先它会立刻返回,所以不会对用户进程产生任何阻塞情况==。然后,kernel 会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel 会通知用户进程,告诉它 read 操作完成了。
基于异步 IO 模型的文件读的执行过程如下图所示:
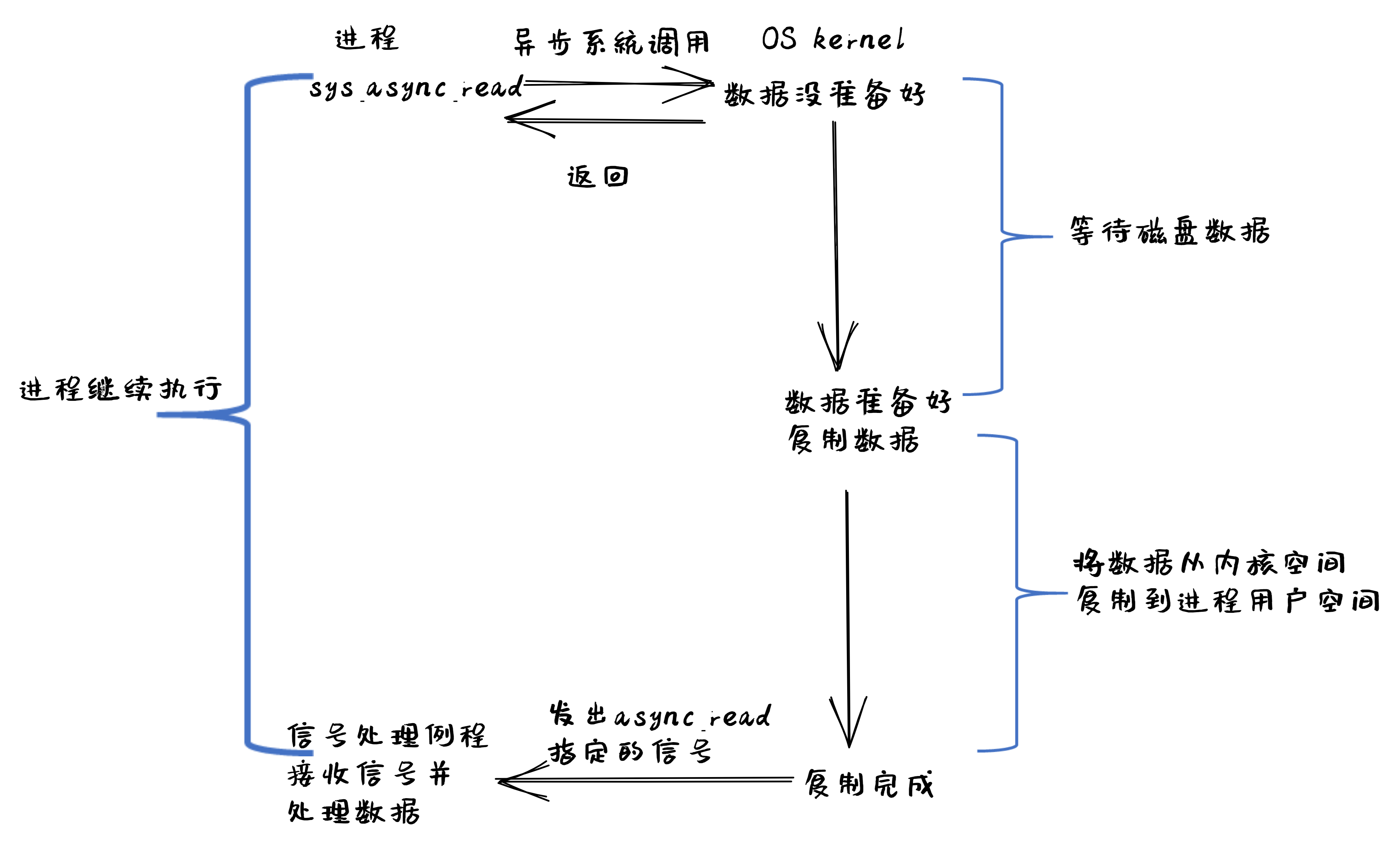
[! note] Linux 异步 IO 的历史 2003 年,Suparna Bhattacharya 提出了 Async I/O 在 Linux kernel 的设计方案,里面谈到了用 Full async state machine 模型来避免阻塞,把一系列的阻塞点用状态机来驱动,把用户态的 buffer 映射到内核来驱动,这个模型被应用到 Linux kernel 2.4 中。
在出现 io_uring 之前,虽然还出现了一系列的异步 IO 的探索(syslet、LCA、FSAIO、AIO-epoll 等),但性能一般,实现和使用复杂,应该说 Linux 没有提供完善的异步 IO (网络 IO、磁盘 IO) 机制。
io_uring 是由 Jens Axboe 提供的异步 I/O 接口,io_uring 围绕高效进行设计,采用一对共享内存 ringbuffer 用于应用和内核间通信,避免内存拷贝和系统调用。io_uring 的实现于 2019 年 5 月合并到了 Linux kernel 5.1 中,现在已经在多个项目中被使用。
五种 IO 执行模型对比
这里总结一下阻塞 IO、非阻塞 IO、同步 IO、异步 IO 的特点:
-
阻塞 IO:在用户进程发出 IO 系统调用后,进程会等待该 IO 操作完成,而使得进程的其他操作无法执行。
-
非阻塞 IO:在用户进程发出 IO 系统调用后,如果数据没准备好,该 IO 操作会立即返回,之后进程可以进行其他操作;如果数据准备好了,用户进程会通过系统调用完成数据拷贝并接着进行数据处理。
-
同步 IO:导致请求进程阻塞 / 等待,直到 I/O 操作完成。
-
异步 IO:不会导致请求进程阻塞。
从上述分析可以得知,
- 阻塞和非阻塞的区别在于内核数据还没准备好时,用户进程是否会阻塞(第一阶段是否阻塞);
- 同步与异步的区别在于当数据从内核 copy 到用户空间时,用户进程是否会阻塞 / 参与(第二阶段是否阻塞)。
所以前述的阻塞 IO(blocking IO),非阻塞 IO(non-blocking IO),多路复用 IO(IO multiplexing),信号驱动 IO 都属于同步 IO(synchronous IO)。这四种模型都有一个共同点:在第二阶段阻塞 / 参与,也就是在真正 IO 操作 read 的时候需要用户进程参与,因此以上四种模型均称为同步 IO 模型。
有人可能会说,执行非阻塞 IO 系统调用的用户进程并没有被阻塞。其实这里定义中所指的 IO 操作 是指实际的 IO 操作 。比如,非阻塞 IO 在执行 read 系统调用的时候,如果内核中的 IO 数据没有准备好,这时候不会 block 进程。但是当内核中的 IO 数据准备好且收到用户进程发出的 read 系统调用时(处于第二阶段), 内核中的 read 系统调用的实现会将数据从 kernel 拷贝到用户内存中,这个时候进程是可以被阻塞的。
而异步 IO 则不一样,当用户进程发起 IO 操作之后,就直接返回做其它事情去了,直到内核发送一个通知,告诉用户进程说 IO 完成。在这整个过程中,用户进程完全没有被阻塞。
Footnotes
-
Jeffrey Mogul and K. K. Ramakrishnan, Eliminating Receive Livelock in an Interrupt-driven Kernel, USENIX ATC 1996, San Diego, CA, January 1996 ↩