5-1 二叉树中节点深度、高度与全树高度关系
- ==试证明,对于二叉树 T 中任一节点 ,总有 depth (v) + height (v) ⇐ height (T);== 对于子树 v 中的任一节点 x,我们将 x 在该子树中的深度记作 depthv (x)。 若将树根节点记作 r,则根据定义有:
于是,
另一方面,
对比 (1)、(2)两式,二者都是取 depth (x)的最大值,但前者所覆盖的范围(子树 v)是后者 所覆盖范围(全树)的子集,因此前者必然不大于后者。
- 取等号的充要条件是什么? 唯有在全树最深节点属于子树 v 时,1) 中不等式方可取等号;反之亦然。 实际上,此时对应的充要条件是:全树最深(叶)节点(之一)是节点 v 的后代,或者等价地, 节点 v 是全树(某一)最深(叶)节点的祖先。
5.2 二叉树深度、节点数与高度关系
- ==试证明: ;== 采用数学归纳法,对树高 h 做归纳。在 h = 0 时,该不等式对单节点的二叉树显然成立。故假定对于高度小于 h 的二叉树,该不等式均成立,以下考查高度为 h 的二叉树。
该树在最底层拥有恰好 个(叶)节点。如图 x5.1 所示,若将它们统一删除,则只可能在原次底层(现最底层)增加叶节点,其余更高层的叶节点不增不减。准确地说,若原次底层新增叶节点共计 m 个,则必有 ;或者反过来等价地,
 经如此统一删除底层(叶)节点之后,所得二叉树的高度为 h - 1,故由归纳假设应当满足:
经如此统一删除底层(叶)节点之后,所得二叉树的高度为 h - 1,故由归纳假设应当满足:
相应地,对于原树而言应有:
- 取等号的充要条件是什么?
由以上证明过程可见,题中不等式若欲取等号,则在(沿数学归纳反向)每一步递推中,以上不等式
*都应取等号,而其充要条件是 。
换而言之,二叉树每次增加一层,最底层的新叶节点都应该是成对引入的。递推地应用这一规则即不难看出,在如此生成的二叉树中,所有节点的度数必为偶数——亦即所谓的真二叉树(proper binary tree)。
5-4 改进 updateHeightAbove 算法
- 试证明:逆行向上依次更新 x 的各祖先高度时,一旦发现某一祖先的高度没有变化,则算法可以提前终止; 在高度更新过程中,将首个高度不变的节点记作 C。 考查任一更高的祖先节点 A。若从 A 通往其最深后代的通路不经过 C,则 A 的高度自然不变。
否则,该通路自上而下经过 C 之后,必然会继续通往 C 的最深后代。这种情况下,既然 C 的高度保 持不变,则该后代的深度必然也不变——尽管这种后代节点可能不止一个。
-
如何改进? 在自底而上逐层更新的过程中,一旦当前祖先节点的高度未变,即可立即终止。
-
算法的渐进复杂度降低了吗? 在最坏情况下我们仍需一直更新到树根节点,因此就渐进意义而言算法的复杂度并未降低。 当然,如此改进之后毕竟可以自适应地减少不必要的更新计算,因此这种改进依然是值得的。
5-5 removeAt ()的时间复杂度和空间复杂度
指向原始笔记的链接//子树删除 template <typename T> //删除二叉树中位置x处的节点及其后代,返回被删除节点的数值 Rank BinTree<T>::remove( BinNodePosi<T> x ) { // assert: x为二叉树中的合法位置 FromParentTo( *x ) = NULL; //切断来自父节点的指针 updateHeightAbove( x->parent ); //更新祖先高度 Rank n = removeAt( x ); _size -= n; return n; //删除子树x,更新规模,返回删除节点总数 } template <typename T> //删除二叉树中位置x处的节点及其后代,返回被删除节点的数值 static Rank removeAt( BinNodePosi<T> x ) { // assert: x为二叉树中的合法位置 if ( !x ) return 0; //递归基:空树 Rank n = 1 + removeAt( x->lc ) + removeAt( x->rc ); //递归释放左、右子树 release( x->data ); release( x ); return n; //释放被摘除节点,并返回删除节点总数 } // release()负责释放复杂结构,与算法无直接关系,具体实现详见代码包
对于待删除子树中的每一节点,该算法都有一个对应的递归实例;反之,算法运行期间出现过的每一递归实例,也唯一对应于某一节点。再注意到,每个递归实例均只需常数时间,故知整体的运行时间应线性正比于待删除子树的规模。
在算法运行过程中的任何时刻,递归调用栈中各帧所对应的节点,自底而上两两构成“父亲 - 孩子”关系 —— 比如特别地,最底部的一帧对应于(子树的)根节点。而当递归调用栈达到最高时,栈顶一帧必然对应于(子树中的)最深节点。由此可见,该算法的空间复杂度应线性正比于待删除子树的高度。
5-6 PFC 编码一定解码成功吗?
按照教材 5.2.2 节介绍的 PFC 解码算法,
PFC 解码
反过来,依据 PFC 编码树可便捷地完成编码串的解码:
- PFC 编码中的编码树为例,设对编码串”101001100”解码。从前向后扫描该串,同时在树中相应移动。
- 起始时从树根出发,视各比特位的取值相应地向左或右深入下一层,直到抵达叶节点。比如,在扫描过第 1 位 “1”后将抵达叶节点’M’。此时,可以输出其对应的字符’M’,然后重新回到树根,并继续扫描编码串的剩余部分。
- 再经过接下来的 3 位”010”后将抵达叶节点’A’,同样地输出字符’A’ 并回到树根。
- 如此迭代,即可无歧义地解析出原文中的所有字符。
实际上,这一解码过程甚至可以在二进制编码串的接收过程中实时进行,而不必等到所有比特位都到达之后才开始,因此这类算法属于在线算法。
指向原始笔记的链接
整个解码过程就是在 PFC 编码树上的“漫游”过程:最初从根节点出发;此后,根据编码串的当前编码位相应地向左(比特 0)或向(比特 1)右深入;一旦抵达叶节点,则输出其对应的字符,并随即复位至根节点。
根据定义及约束条件,PFC 编码树必是真二叉树(proper binary tree)。也就是说,该算法运行过程中所抵达的每一内部节点,必同时拥有左、右分支。因此无法解码的情况只能是,在尚未抵达叶节点之前,输入的二进制编码串已经耗尽。
5-9 树的三种遍历的渐进时间复杂度
==试证明递归式遍历的时间复杂度为:==
这些算法都属于二分递归(binary recursion),但无论如何,每当递归深入一层,都等效于将当前问题(遍历规模为 n 的二叉树)分解为两个子问题(分别遍历规模为 a 和 n - a - 1 的两棵子树)。
因此,递归过程总是可以描述为题中的递推关系。在考虑到边界条件(递归基仅需常数时间),即可导出这些算法的运行时间均为 O (n)的结论。
5-15 迭代式遍历算法的栈的最小容量
最坏情况下(二叉树深度为 Ω(n) 时)辅助栈必须足以容纳 Ω(n) 个节点,这也是这些算法空间规模的安全下限。
5-16 分析 travIn_I3 的时间复杂度
指向原始笔记的链接template <typename T> BinNodePosi<T> BinNode<T>::succ() { //定位节点v的直接后继 BinNodePosi<T> s = this; //记录后继的临时变量 if ( rc ) { //若有右孩子,则直接后继必在右子树中,具体地就是 s = rc; //右子树中 while ( HasLChild( *s ) ) s = s->lc; //最靠左(最小)的节点 } else { //否则,直接后继应是“将当前节点包含于其左子树中的最低祖先”,具体地就是 while ( IsRChild( *s ) ) s = s->parent; //逆向地沿右向分支,不断朝左上方移动 s = s->parent; //最后再朝右上方移动一步,即抵达直接后继(如果存在) } return s; }// 两种情况下运行时间分别为当前节点的高度和深度,总和不超过O(h)
指向原始笔记的链接//travIn_I3 template <typename T, typename VST> //元素类型、操作器 void travIn_I3( BinNodePosi<T> x, VST& visit ) { //二叉树中序遍历算法(迭代版#3,无需辅助栈) bool backtrack = false; //前一步是否刚从左子树回溯――省去栈,仅O(1)辅助空间 while ( true ) if ( !backtrack && HasLChild( *x ) ) //若有左子树且不是刚刚回溯,则 x = x->lc; //深入遍历左子树 else { //否则――无左子树或刚刚回溯(相当于无左子树) visit( x->data ); //访问该节点 if ( HasRChild( *x ) ) { //若其右子树非空,则 x = x->rc; //深入右子树继续遍历 backtrack = false; //并关闭回溯标志 } else { //若右子树空,则 if ( !( x = x->succ() ) ) break; //回溯(含抵达末节点时的退出返回) backtrack = true; //并设置回溯标志 } } }
中序遍历迭代式第三版需要反复地调用 succ()接口以定位直接后继,这个计算成本会影响渐进复杂度 O (n)吗?
该算法的时间复杂度依然还是 O (n)。
为得出这一结论,只需证明: 无论二叉树规模与结构如何,对 succ ()接口所有调用所需时间总和不超过 O (n)
反观代码 travIn_I3 不难看出,实际上在这一场合下对 succ ()算法的调用,其中的 if 判断语句必然取自 else 分支。因此,算法所消耗的时间应线性正比于其中 while 循环的步数,亦即其中对 parent 引用的访问次数。考查该次数,并将规模为 n 的二叉树所需的最大次数记作 P (n)。可以证明,必有 P (n) ⇐ n。
为此,我们对二叉树的高度做数学归纳。
- 作为归纳基,不难验证:对于高度为-1(规模 n = 0)的空树而言,根本无需访问 parent 引用,即 P (0) = 0;
- 对于高度为 0(规模 n = 1)的二叉树而言,只需访问(根节点数值为 NULL 的)parent 引用一次,故有 P (1) = 1。
- 因此,以下假设 P (n) ⇐ n 对于高度小于 h 的所有二叉树均成立,并考查高度为 h 的二叉树 T。如下图所示,
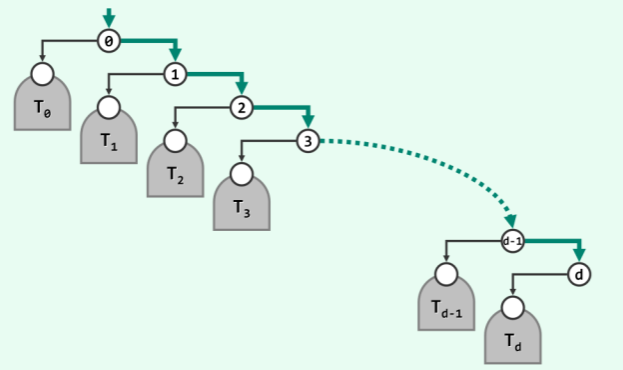
- 若 T 的最右侧通路长度为 d(d ⇐ h),必然可以将 T 分解为 d + 1 棵子树: { }
- 当然,其中的某些子树可能是空树。另外,尽管各子树的高度未必相同,但必然都小于 h。
- 因此根据归纳假设,其各自内部的遍历过程中对 parent 引用的访问次数,应线性正比于其各自的规模。
- 特别地,其中最后一个节点(若子树非空)对应的 succ ()调用中,最后一个访问的是从子树根节点,联接到全树最右侧通路的 parent 指针(图中以细线条示意)。请注意,尽管相对于孤立的子树而言,这个 parent 引用不再是 NULL,但并不影响访问次数的统计。
- 因此,在所有子树内部的遍历过程中对 parent 引用的访问,累计不会超过:
- 就全树而言,除此之外尚未统计的,只有在最右侧通路末节点处对succ()的调用。该次调用过程中对parent引用的访问,也就是在图中以粗线条示意者(实际方向应颠倒,向上),不难看出其总数为d + 1。与各子树合并统计,总次数不超过: (n - d - 1) + (d + 1) = n
5-17 改进 travIn_I3 以不借助辅助栈和标志位
指向原始笔记的链接//travIn_I4 template <typename T, typename VST> //元素类型、操作器 void travIn_I4( BinNodePosi<T> x, VST& visit ) { //二叉树中序遍历(迭代版#4,无需栈或标志位) while ( true ) if ( HasLChild( *x ) ) //若有左子树,则 x = x->lc; //深入遍历左子树 else { //否则 visit ( x->data ); //访问当前节点,并 while ( !HasRChild( *x ) ) //不断地在无右分支处 if ( ! ( x = x->succ() ) ) return; //回溯至直接后继(在没有后继的末节点处,直接退出) else visit ( x->data ); //访问新的当前节点 x = x->rc; //(直至有右分支处)转向非空的右子树 } }
5-18 层次遍历辅助队列容量问题
设二叉树共 n 个节点,
- ==试证明只要辅助队列 Q 的容量不小于 ,就不致于中途出现溢出问题==;
可以证明:在该算法执行过程中的每一步迭代之后,若当前已经有 n 个节点入过队,则仍在队中的至多有 个 —— 当然,相应地,至少已有 个已经出队。 实际上,对该算法稍加观察即不难发现:每次迭代都恰有一个节点出队;若该节点的度数为 d(0 ⇐ d ⇐ 2),则随即会有 d 个节点入队。通过对已出队节点的数目做数学归纳,即不难证明以上事实。
- 规模为 n 的所有二叉树中,哪些树会需要如此大容量的辅助队列?
在算法过程中的任一时刻,辅助队列的规模均不致小于仍应在队列中节点的数目。考查这些节点在目前已入过队的节点中所占的比重。由以上观察结果,可以进一步推知:为使这一比重保持为尽可能大的 ,此前所有出队节点的度数都必须取作最大的 2;且中途一旦某个节点只 有 1 度甚至 0 度,则不可能恢复到这一比重。 由此可见,若果真需要如此大容量的辅助队列,则在最后一个节点入队之前,所有出队节点都必须是 2 度的。由此可见,其对应的充要条件是,该树是一棵包含奇数个节点的完全二叉树,或者是这样一棵树中摘除了某一棵子树。
- ==层次遍历过程中,若 Q 中节点数确实会达到 ,则最多达到几次?==
按照层次遍历的次序,若将树中各节点依次记作:
则其中 为内部节点,共计 个; 为叶节点,共计 个。 根据以上分析,若 n 为奇数,则必然是一棵真完全二叉树,此时的最大规模 仅在 处于队首时出现一次。若 n 为偶数,则只有最后一个内部节点 的度数为 1,此时的最大规模 在 和 处于队首时各出现一次。
若 n 为奇数,则仅一次;否则,恰好两次
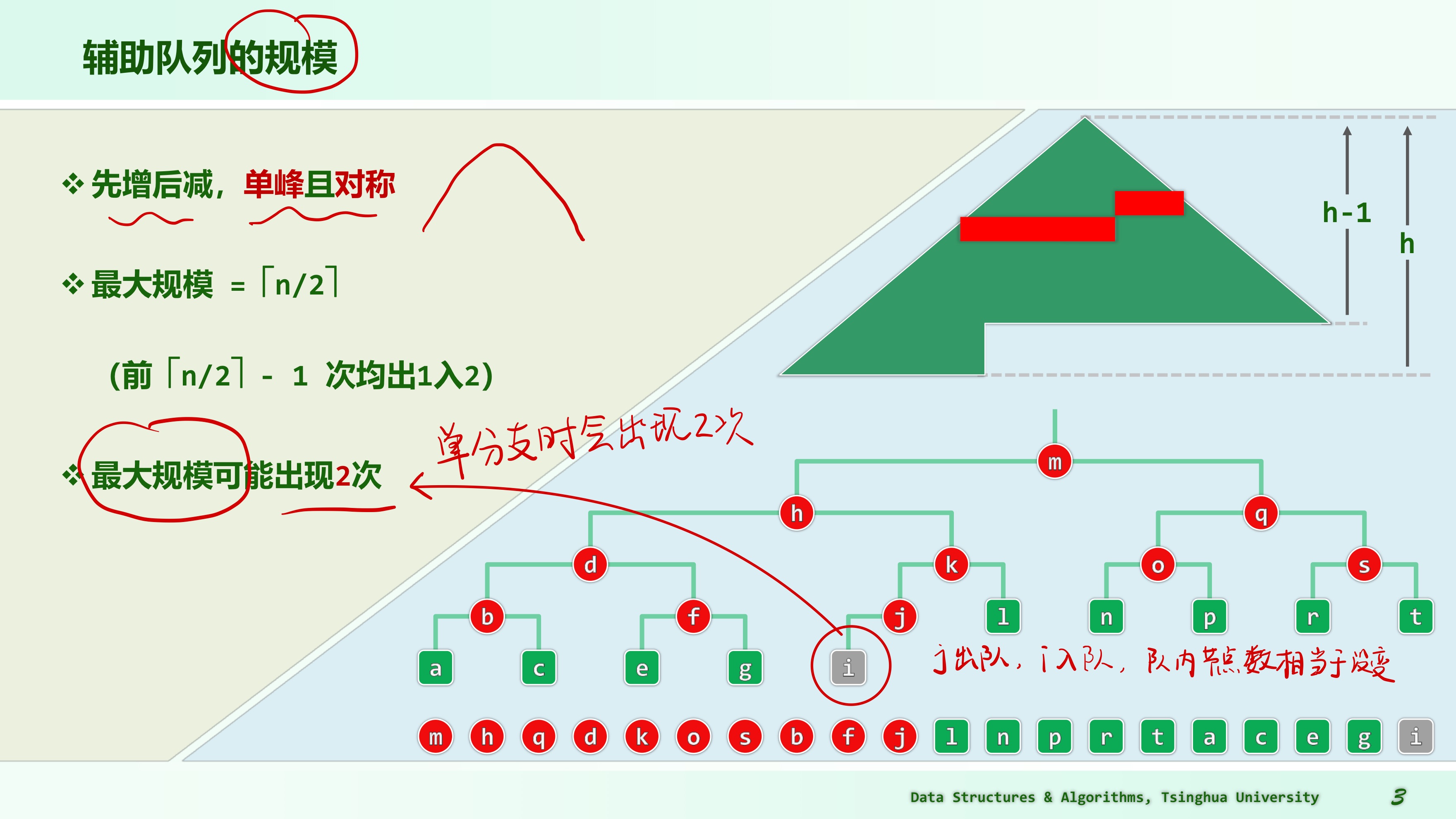
5-19 证明完全二叉树层次遍历过程中辅助队列规模单峰对称
-
试证明:在整个遍历过程中,辅助队列的规模变化是单峰对称的,即 { 0, 1, 2, ..., (n + 1)/2, ..., 2, 1, 0 } (n 为奇数时)或 { 0, 1, 2, ..., n/2, n/2, ..., 2, 1, 0 } (n 为偶数时) 根据上题的分析结论,显然成立。
-
非完全二叉树的层次遍历过程,是否也可能具有这种性质?为什么?
从由奇数个节点构成的完全二叉树中删除底层的倒数第二个节点,所得的二叉树也具有上述(单峰且对称)的性质。
5-20 如何判断任一对节点间存在“祖先-后代”关系?
描述:在完全二叉树的层次遍历过程中,按入队次序从 0 起将各节点 X 编号为 r (X)
- 试证明对任一节点 X 及左右孩子 (若存在),则必然有
.png) 由上图中的实例,直接易见。
由上图中的实例,直接易见。
-
==试证明:任一编号 都唯一对应于某个节点== 由上图中的实例,直接易见。
-
如何利用上述性质提高对树的存储和处理效率? 将所有节点存入向量结构,各节点 X 的秩 rank(X)即为其编号 r(X)。
-
根据上述编号规则,如何判断任何一对节点之间是否存在“祖先-后代”关系? 令 s(X) = r(X) + 1,S(X)为 s(X)的二进制展开,于是有:
- 节点 A 是 D 的祖先,当且仅当 S (A)是 S (D)的前缀。其中特别地,
- 节点 A 是 D 的父亲,当且仅当 S (A)是 S (D)的前缀且|S (A)| + 1 = |S(D)|
以上图中的节点1、8和18为例,即可验证上述结论: s( 1) = r( 1) + 1 = 2 = 10 s( 8) = r( 8) + 1 = 9 = 1001 s(18) = r(18) + 1 = 19 = 10011
5-23 O (n)时间内互换二叉树所有节点的左右孩子
在递归版先序、中序或后序遍历算法的基础上,在每个递归实例中,交换当前节点的左、右孩子(子树)。
5-24 O (n)时间内判断是否树中所有节点的数值均不小于其真祖先的数值总和
仍以教材所给的递归版先序、中序或后序遍历算法,作为基础框架。
- 引入一个辅助栈,用以记录从根节点到当前节点的(唯一)通路,当然,沿途节点亦即当前节点的所有祖先。另设一个累加器,动态记录辅助栈中所有节点数据项的总和。
- 为此,递归每深入一层,即将当前节点压入辅助栈中,同时累计其数据项;反之,递归每返回一层,即弹出辅助栈的顶部节点,并从累加器中扣除其数据项。
- 对于每个当前节点,都将其数据项与累加器做一比较。一旦确认前者小于后者,即可立刻报告“NO”并退出。若直到辅助栈重新变空,都未发生上述情况,即最终可报告“YES”并退出。
template <typename T>
struct BinNode {
T data;
BinNode* lc;
BinNode* rc;
};
template <typename T>
bool isSumGreater(BinNode<T>* x, T ancestorSum) {
if (!x) {
return true; // 空节点满足条件
}
// 检查当前节点的值是否小于其祖先节点的总和
if (x->data < ancestorSum) {
return false; // 不满足条件,返回false
}
// 递归遍历左子树和右子树
bool leftResult = isSumGreater(x->lc, ancestorSum + x->data);
bool rightResult = isSumGreater(x->rc, ancestorSum + x->data);
// 返回左子树和右子树的结果的逻辑与
return leftResult && rightResult;
}
template <typename T, typename VST>
void traverse(BinNode<T>* x, VST& visit) {
if (!x) return;
visit(x->data);
traverse(x->lc, visit);
traverse(x->rc, visit);
}
int main() {
// 构建一个示例树
BinNode<int>* root = new BinNode<int>{10};
BinNode<int>* child1 = new BinNode<int>{5};
BinNode<int>* child2 = new BinNode<int>{15};
BinNode<int>* child3 = new BinNode<int>{20};
root->lc = child1;
root->rc = child2;
child2->rc = child3;
// 调用isSumGreater函数判断是否满足条件
bool result = isSumGreater(root, 0);
if (result) {
std::cout << "YES, all nodes satisfy the condition." << std::endl;
} else {
std::cout << "NO, not all nodes satisfy the condition." << std::endl;
}
// 释放内存(假设没有其他指向这些节点的引用)
delete root;
delete child1;
delete child2;
delete child3;
return 0;
}
改进为迭代版
#include <iostream>
#include <stack>
#include <vector>
struct TreeNode {
int value;
std::vector<TreeNode*> children;
};
bool isSumGreater(TreeNode* root) {
if (!root) {
return true; // 空树满足条件
}
std::stack<TreeNode*> ancestorStack;
int ancestorSum = 0;
// 使用深度优先搜索的迭代方式
std::stack<TreeNode*> nodeStack;
nodeStack.push(root);
while (!nodeStack.empty()) {
TreeNode* current = nodeStack.top();
nodeStack.pop();
// 将当前节点及其祖先节点入栈,并更新累加器
ancestorStack.push(current);
ancestorSum += current->value;
// 检查当前节点的子节点
for (TreeNode* child : current->children) {
nodeStack.push(child);
}
// 检查是否当前节点的值小于其祖先节点的总和
while (!ancestorStack.empty()) {
TreeNode* ancestor = ancestorStack.top();
if (current->value < ancestorSum - ancestor->value) {
return false; // 不满足条件,返回false
}
ancestorStack.pop();
}
}
return true; // 所有节点都满足条件,返回true
}
迭代版需要多少空间
对于第一个算法,使用了迭代的形式,空间复杂度取决于树的高度和辅助栈的最大大小。在最坏情况下,如果树是一个完全二叉树,辅助栈的大小将达到树的高度,即 O (log n)。因此,该算法的空间复杂度为 O (log n),其中 n 是树中节点的数量。
这是因为在迭代过程中,辅助栈用于存储从根节点到当前节点的通路,以及用于累加祖先节点的数值总和。当树的高度为 h 时,辅助栈的最大大小将是 h,而 h 通常是 log n(在平衡二叉树的情况下)。
总之,这个算法的空间复杂度是 O (log n)。
5-25 O (n)时间内将每个节点的数值替换为后代中最大数值
以教材所给的递归版后序遍历算法为基础框架,做必要的扩充。
首先,需要调整接口约定,使每个递归实例都有返回值——亦即,当前节点更新后的数据项。
- 作为递归基,空树可返回可能的最小值(比如对于整数,可取 INT_MIN)。
- 这样,按照后序遍历的次序,只要当前节点的左、右子树均已遍历(左、右孩子的数据项均已更新),即可从二者当中取其更大者,并相应地更新当前节点的数据项,最后再返回更新后的数据项。 同样地,以上扩充既不致增加递归实例的数量,亦不会增加各递归实例的渐进执行时间,故总体的时间复杂度依然为 O(n)。
#include <iostream>
#include <algorithm> // 使用std::max
template <typename T>
struct BinNode {
BinNode* parent;
BinNode* lc;
BinNode* rc;
T data;
// 其他成员函数和数据成员...
// 插入左孩子和右孩子等成员函数...
};
// 后序遍历修改每个节点的值
template <typename T>
T updateMaxDescendant(BinNode<T>* x) {
if (!x) {
return std::numeric_limits<T>::min(); // 空节点返回最小值
}
// 递归后序遍历左子树和右子树,并获取左右子树的最大值
T leftMax = updateMaxDescendant(x->lc);
T rightMax = updateMaxDescendant(x->rc);
// 更新当前节点的数据项为左右子树的最大值和当前节点的值的较大者
x->data = std::max(x->data, std::max(leftMax, rightMax));
return x->data; // 返回当前节点的数据项
}
int main() {
// 构建一个示例树
BinNode<int>* root = new BinNode<int>{10};
BinNode<int>* child1 = new BinNode<int>{5};
BinNode<int>* child2 = new BinNode<int>{15};
BinNode<int>* child3 = new BinNode<int>{20};
root->lc = child1;
root->rc = child2;
child2->rc = child3;
// 调用updateMaxDescendant函数修改每个节点的值
updateMaxDescendant(root);
// 打印修改后的树
std::cout << "Modified Tree:" << std::endl;
// 编写打印树的代码或遍历树的其他方式...
// 释放内存(假设没有其他指向这些节点的引用)
delete root;
delete child1;
delete child2;
delete child3;
return 0;
}
改进为迭代版
#include <iostream>
#include <stack>
#include <algorithm> // 使用std::max
template <typename T>
struct BinNode {
BinNode* parent;
BinNode* lc;
BinNode* rc;
T data;
// 其他成员函数和数据成员...
// 插入左孩子和右孩子等成员函数...
};
// 后序遍历修改每个节点的值
template <typename T>
void updateMaxDescendantIterative(BinNode<T>* root) {
if (!root) {
return;
}
std::stack<BinNode<T>*> nodeStack;
BinNode<T>* current = root;
BinNode<T>* lastVisited = nullptr;
while (current || !nodeStack.empty()) {
if (current) {
nodeStack.push(current);
current = current->lc;
} else {
BinNode<T>* topNode = nodeStack.top();
if (topNode->rc && topNode->rc != lastVisited) {
current = topNode->rc;
} else {
// 访问节点并更新其值为后代中的最大值
T leftMax = (topNode->lc) ? topNode->lc->data : std::numeric_limits<T>::min();
T rightMax = (topNode->rc) ? topNode->rc->data : std::numeric_limits<T>::min();
topNode->data = std::max(topNode->data, std::max(leftMax, rightMax));
lastVisited = topNode;
nodeStack.pop();
}
}
}
}
int main() {
// 构建一个示例树
BinNode<int>* root = new BinNode<int>{10};
BinNode<int>* child1 = new BinNode<int>{5};
BinNode<int>* child2 = new BinNode<int>{15};
BinNode<int>* child3 = new BinNode<int>{20};
root->lc = child1;
root->rc = child2;
child2->rc = child3;
// 调用updateMaxDescendantIterative函数修改每个节点的值
updateMaxDescendantIterative(root);
// 打印修改后的树
std::cout << "Modified Tree:" << std::endl;
// 编写打印树的代码或遍历树的其他方式...
// 释放内存(假设没有其他指向这些节点的引用)
delete root;
delete child1;
delete child2;
delete child3;
return 0;
}
迭代版需要多少空间?
对于迭代版的实现,需要使用一个栈来辅助遍历树的节点,其空间复杂度取决于树的高度和树中节点的数量。在最坏情况下,如果树是一个完全二叉树,栈的最大大小将达到树的高度,即 O (log n),其中 n 是树中节点的数量。
除了栈之外,还需要一些额外的辅助空间来存储变量和临时值,但这些额外空间的大小与树的规模无关,通常可以忽略不计。
因此,迭代版的实现需要的辅助空间为 O (log n),其中 n 是树中节点的数量,这是由树的高度决定的。
5-26 O (n)时间内为每个节点设置适当的数值
要求:1.树根为 0 ;2.对于数值为 k 的节点,其左孩子数值为 2k + 1,右孩子数值为 2k + 2
不难看出,对于完全二叉树,题中的要求实际上等效于,按照层次遍历的次序,为树中的各节点顺序编号。而一般的二叉树作为其子树,各节点的编号也与完全二叉树完全吻合。因此可以教材所给的层次遍历算法为基础框架,并做必要的扩充。
具体地,在根节点首先入队之前,将其数据项置为0。此后的每一步迭代中,若出队节点的编号为 k,则入队的左、右孩子节点(若存在)的数值,可分别取作2k + 1、2k + 2。
#include <iostream>
#include <queue>
template <typename T>
struct BinNode {
BinNode* lc;
BinNode* rc;
T data;
// 构造函数...
};
// 为每个节点设置适当的数值
template <typename T>
void setNodeValues(BinNode<T>* root) {
if (!root) {
return;
}
std::queue<BinNode<T>*> nodeQueue;
root->data = 0; // 根节点的数值为0
nodeQueue.push(root);
while (!nodeQueue.empty()) {
BinNode<T>* current = nodeQueue.front();
nodeQueue.pop();
if (current->lc) {
current->lc->data = current->data * 2 + 1;
nodeQueue.push(current->lc);
}
if (current->rc) {
current->rc->data = current->data * 2 + 2;
nodeQueue.push(current->rc);
}
}
}
int main() {
// 构建一个示例二叉树
BinNode<int>* root = new BinNode<int>{nullptr, nullptr, 0};
BinNode<int>* leftChild = new BinNode<int>{nullptr, nullptr, 0};
BinNode<int>* rightChild = new BinNode<int>{nullptr, nullptr, 0};
root->lc = leftChild;
root->rc = rightChild;
// 调用setNodeValues函数设置每个节点的数值
setNodeValues(root);
// 打印每个节点的数值
std::cout << "Node Values:" << std::endl;
// 编写打印节点值的代码或遍历树的其他方式...
// 释放内存(假设没有其他指向这些节点的引用)
delete root;
delete leftChild;
delete rightChild;
return 0;
}
5-30 键树 Trie
设字符集为Σ(|Σ|=r),任一字符串集 S 都可用如图的 Trie 树表示:
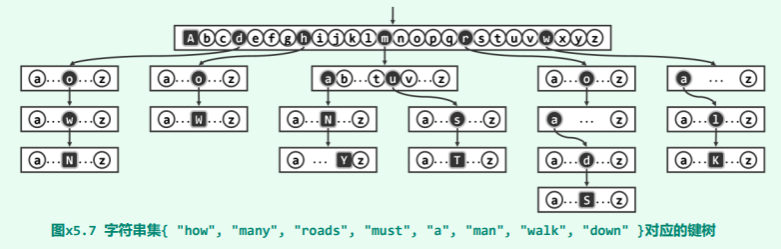 Trie:键树是有根有序树,其中的每个节点均包含 r 个分支。深度为 d 的节点分别对应于长度为 d 的字符串,且祖先所对应字符串必为后代所对应字符串的前缀。键树只保留与 S 中字符串(及其 前缀)相对应的节点(黑色),其余的分支均标记为 NULL(白色)。 注意,因为不能保证字符串相互不为前缀(如”man”不”many”),故对应于完整字符串的节点(黑色方形、大写字母)未必都是叶子。
Trie:键树是有根有序树,其中的每个节点均包含 r 个分支。深度为 d 的节点分别对应于长度为 d 的字符串,且祖先所对应字符串必为后代所对应字符串的前缀。键树只保留与 S 中字符串(及其 前缀)相对应的节点(黑色),其余的分支均标记为 NULL(白色)。 注意,因为不能保证字符串相互不为前缀(如”man”不”many”),故对应于完整字符串的节点(黑色方形、大写字母)未必都是叶子。
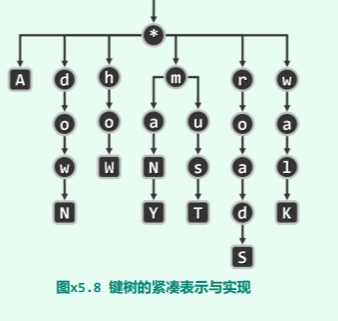
==试按照如下图所示的构思,实现对应 Trie 模板类。同时要求提供一个接口 find(w), 在 O(|w|) = O(h)的时间内判断 S 是否包含字符串 w,其中|w|为该字符串的长度,h 为树高。== (提示:每个节点都实现为包含 r 个指针的一个向量,各指针依次对应于 Σ 中的字符:S 包含对应的字符串(前缀),当且仅当对应的指针非空。此外,每个非空指针都还需配有一个 bool 类型的标志位,以指示其是否对应于 S 中的某个完整的字符串。于是,键树的整体逻辑结构可以抽象为下图所示形式。其中,黑色方形元素的标志位为 true,其余均为 false。)
具体实现看这篇:
- OIwiki:50-Trie-Tree
- Wikipedia:A2-Trie-Tree
- dsa-c-yan-impl:93-键树