1. Introduction
1.1 The Benefits of Using GPUs
在相近的价格和功耗范围内,GPU 可以提供远高于 CPU 的指令吞吐率和内存带宽。因此很多应用可以藉此优势在 GPU 上更快地运行。还有一些计算设备,如 FPGA 也非常 energy efficient,但在可编程的灵活性上远不如 GPU。
GPU 与 CPU 之间的差异根源自设计目标的不同——CPU 旨在尽可能快地执行一系列操作(即 thread),并且可以并行执行几十个这样的线程;GPU 旨在并行执行数千个这样的线程(通过摊销较慢地单线程性能来实现更高的吞吐量)。
GPU 专门用于高度并行的计算,因此设计上更注重数据处理而不是数据缓存和流量控制,下图展示了 CPU 与 GPU 芯片资源的示例分布:
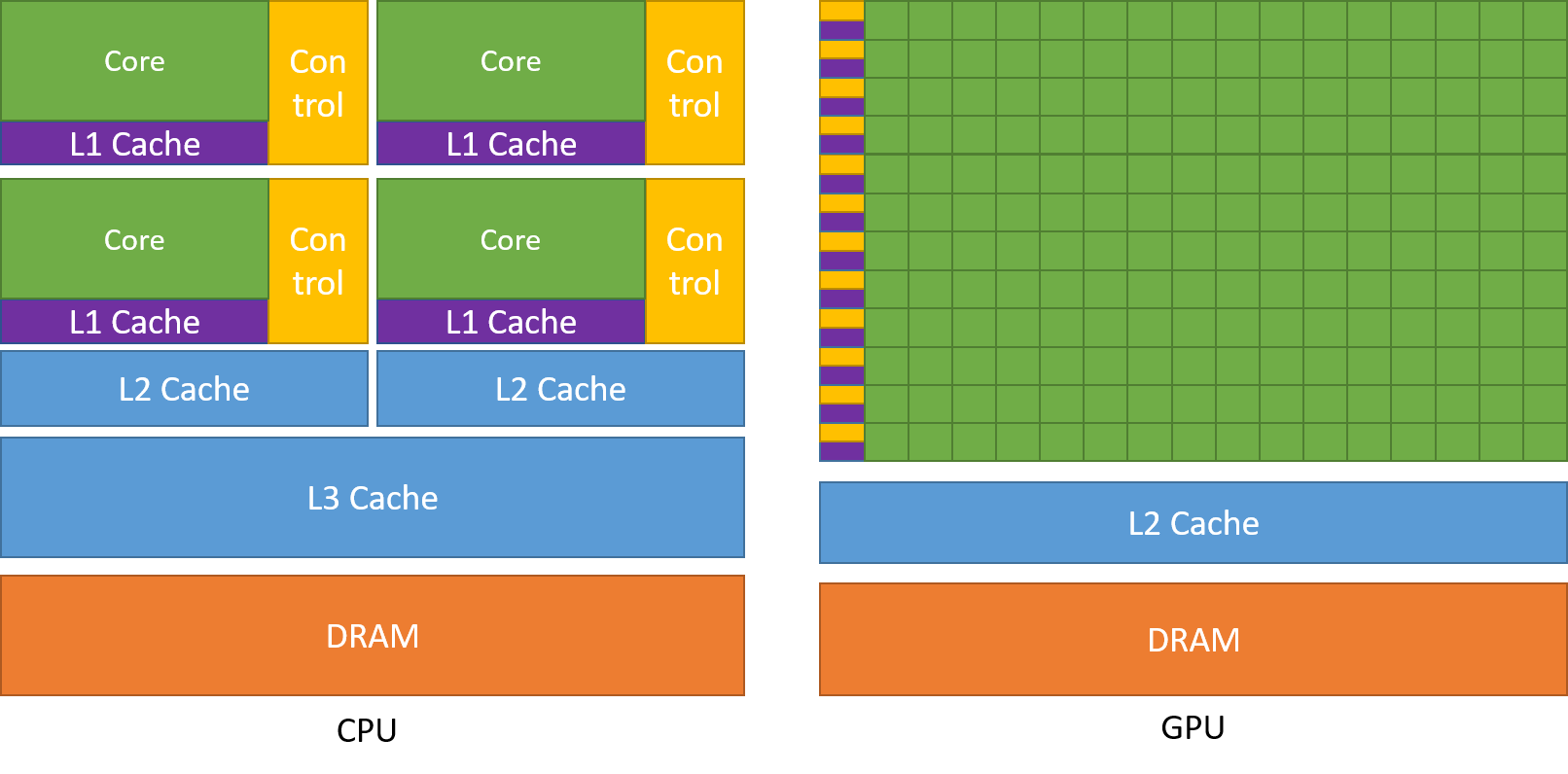
GPU 将更多的晶体管用于数据处理,例如浮点运算,这种选择有利于高度的并行计算;还可以通过计算来隐藏内存访问延迟,而不是依赖于大型数据缓存和复杂的流程控制来避免长时间的内存访问延迟,因为 cache 和 flow control 代价高昂。
一般来说,一个应用程序包含并行部分和顺序部分,因此系统设计时采用 GPU 和 CPU 的混合配置以最大化整体性能。具有高度并行性的应用程序可以利用 GPU 的特性实现比在 CPU 上更高的性能。
1.2 CUDA: A General-Purpose Parallel Computing Platform and Programming Model
CUDA 是一个利用 NVIDIA GPU 中的并行计算引擎,以比 CPU 更高效的方式解决许多复杂计算问题的通用并行计算平台和编程模型。
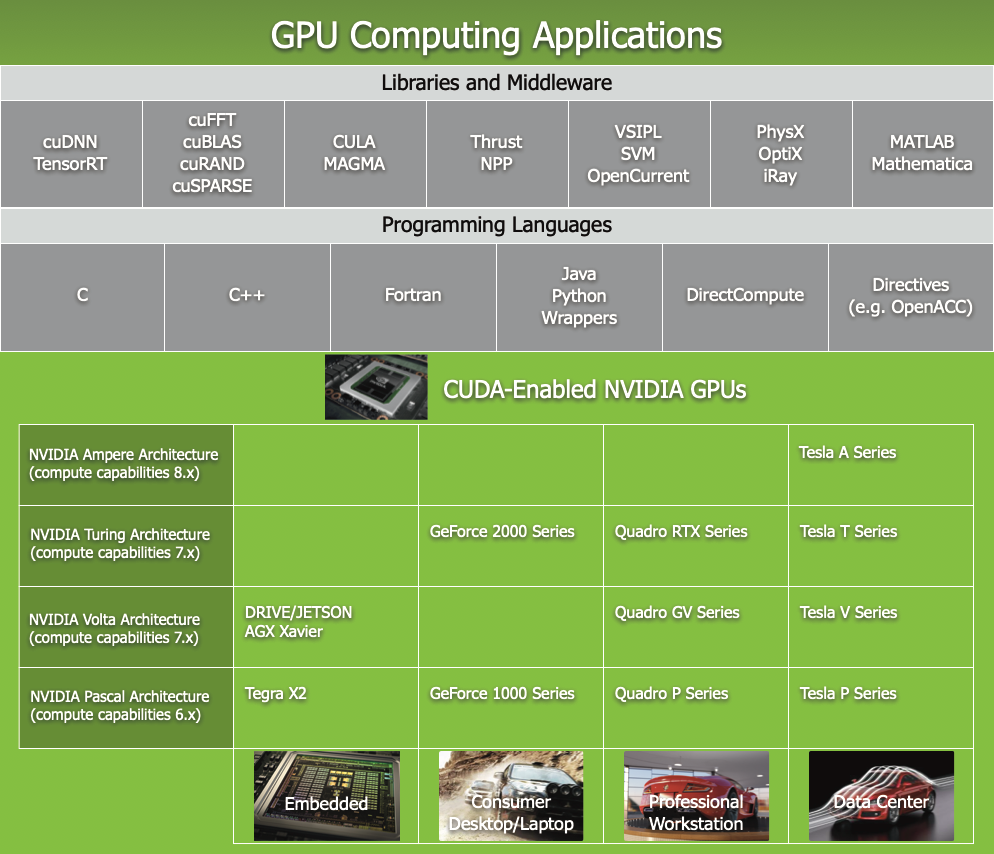
CUDA 附带一个软件环境,允许开发者使用 C++ 作为高级编程语言。如图 2 所示,还支持其他语言、应用程序编程接口或基于指令的方法,例如 FORTRAN、DirectCompute、OpenACC。
1.3 A Scalable Programming Model
多核(multicore) CPU 和众核(manycore) GPU 的出现意味着现代主流处理器芯片是并行系统。因此开发者的挑战在于,开发能够透明地扩展其并行性以利用不断增长的处理器核心数量的应用软件,就像 3D 图形应用能够透明地扩展其并行性以广泛地 963936适应具有不同核心数量的众核 GPU 一样。CUDA 并行编程模型为此而生,对于熟悉标准编程语言(如 C lang)地程序员来说,学习 CUDA 的曲线很低。
CUDA 的核心是三个关键抽象——层次化结构的线程组(hierarchy of thread groups)、共用内存(shared memory)和屏障同步(barrier synchronization),这些抽象作为一组最小语言扩展提供给程序员。这些抽象通过在粗粒度的数据并行和任务并行中嵌套地提供细粒度的数据并行和线程并行。它们指导程序员将问题划分为粗粒度子问题,这些子问题可以通过线程块独立并行解决,再将每个子问题进一步细分为更小的部分,这些更小部分可以通过块内所有线程的协作并行解决。
这种问题的分解通过线程在解决每个子问题时的协作,保留了语言的表达能力,同时实现了自动的可扩展性。因此在实践中,每个线程块可以按任何顺序并发或顺序地调度到 GPU 内任何可用的多处理器上,因此编译的 CUDA 程序可以在如图 3 所示的任何数量的多处理器上执行,只需运行时系统知道物理的多处理器的数量即可。显然,随着多线程程序被划分为相互独立执行的线程块,多处理器数量更多的 GPU 执行程序更快。
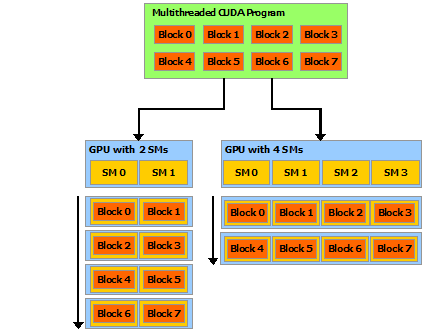
这种可扩展的编程模型允许通过简单地调整多处理器和内存分区的数量,使 GPU 架构跨越广泛的市场范围:从高性能的 GeForce GPU 爱好者和专业级的 Quadro 和 Tesla 计算产品,到各种经济实惠的主流 GeForce GPU。
2. Programming Model
2.1 Kernels
CUDA C++扩展了 C++,使得程序员可以定义称为内核1的 C++ 函数,当调用时,这些 kernel 由 N 个不同的 CUDA 线程并行执行 N 次,而不是像常规 C++ 函数那样只执行一次。
kernel 的定义需要使用 __global__ 说明符来声明,并使用一种新的称为执行配置(execution configuration)的语法—— <<<...>>> ——指定在对应内核调用(kernel call)中执行该 kernel 的 CUDA 线程数。执行 kernel 的每个线程都有一个唯一的线程 ID,可以通过内置变量在 kernel 中访问。下面是示例:
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}这段代码的意思是:使用内置变量 threadIdx 将大小为 N 的两个向量 A 和 B 相加,并将结果存储到向量 C 中。这里,执行 VecAdd() 的 N 个线程中,都执行一次加法。
2.2 Thread Hierarchy
方便起见,以三分量向量 threadIdx 为例做解释:可以使用一维、二维或三维线程索引来识别,形成一维、二维、三维的线程块。这就提供了跨域(如向量 vector、矩阵 matrix 或卷 volume)中元素调用计算的自然方法。
线程的索引和线程ID以一种直接的方式相互关联:对于一维块,它们是相同的;对于大小为 (Dx,Dy) 的二维块,索引为 (x,y) 的线程的线程ID为 (x+y Dx) ;对于尺寸为 (Dx,Dy,Dz) 的三维块,索引为 (x,y,z) 的线程的线程ID为 (x+y Dx+z Dx Dy) 。
将大小为 NxN 的两个矩阵 A 和 B 相加,并将结果存储到矩阵 C 中,代码如下:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}每个线程块中的线程数有限,这是因为一个块中的所有线程都应该驻留(reside)在同一个流式多处理器核心(streaming multiprocessor core)上,并且必须共享该核心的有限内存资源。在当前代次的 GPU 上,一个线程块最多可包含 1024 个线程。
一个 kernel 可以由多个形状相同的线程块执行,因此线程总数等于每个块中线程数乘块数。如下图所示,线程块被组织成一维、二维或三维的网格,网格中线程块的数量通常由正在处理的数据的大小决定,这通常超过系统中的处理器数量。

在 <<<...>>> 语法中指定的每个块中的线程数和每个网格中的块数可以是 int 或 dim3 类型。二维块或网格可以如上例 <<<numBlocks, threadsPerBlock>>> 一样进行指定。网格中的每个块都可以通过一个一维、二维或三维的唯一索引来标识,该索引可以通过内置的 blockIdx 变量在内核中访问。线程块的维度可以在内核中通过内置的 blockDim 变量访问。因此,扩展 MatAdd() 为处理多个块的代码如下:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}在这个示例代码中,线程块大小(指其中的线程数)可以是任意的,只要不超过 1024 即可,不过这里是 16x16(即 256 个线程,这也是常见的配置),网格由一定数量的线程块组成,这里仍然是每个线程上运行一个矩阵运算。代码为了简单起见,假设每个维度中每个网格的线程数可以被该维度中每个块的线程数整除,尽管其他情况中并非如此。
线程块需要独立执行,并且必须能够以任何顺序并行或串行地执行,因此要求线程块以任何顺序、在任何数量的 GPU 内核(core)上进行调度,如 图 3 所示,从而程序员编写的 CUDA 代码能够随内核数量而扩展。
{kind=link}
块内的线程可以通过共用内存(shared memory)来共享数据,并且同步其执行来协调内存的访问,从而进行协作。更确切地说,可以通过调用 __syncthreads() 内置函数在 kernel 中指定同步点—— 这里的 __syncthreads() 充当一个屏障,块中的所有线程都必须等待,然后才能允许线程继续执行。 3.2.4 Shared Memory 一节给出了一个使用共用内存的示例。除了 __syncthreads() 之外 ,Cooperative Groups API 还提供了一组丰富的线程同步原语。
为了高效协作,共用内存是每个处理器核心附近的低延迟内存(很像L1缓存),而 __syncthreads() 是轻量级的。
2.2.1 Thread Block Clusters
随着 NVIDIA Compute Capability 9.0 的推出,CUDA 编程模型引入了一个可选的层次结构级别,称为由线程块组成的线程块簇(Thread Block Cluster)。与块中线程在流式多处理器上保证共同调度的方式类似,簇中的线程块也保证在 GPU 中的 GPU 处理簇(GPU Processing Cluster)上共同调度。
与线程块类似,簇也被组织成一维、二维或三维的线程块簇网格,如图 5 所示。簇中的线程块数量可以由用户定义,CUDA 支持簇中最多 8 个线程块作为可移植簇大小(portable cluster size)。请注意,在 GPU 硬件或 MIG 配置上,如果太小而无法支持 8 个多处理器,则最大簇的大小将相应减小。这些较小的配置,或者支持簇大小超过 8 的较大配置,其区别在于特定的体系结构(architecture-specific),可以使用 cudaOccupancyMaxPotentialClusterSize API进行查询。在使用簇支持的 kernel 中,出于兼容性目的,gridDim 变量仍然表示线程块数量的大小,而簇中一个块的秩(rank)可以使用 Cluster Group API 找到。
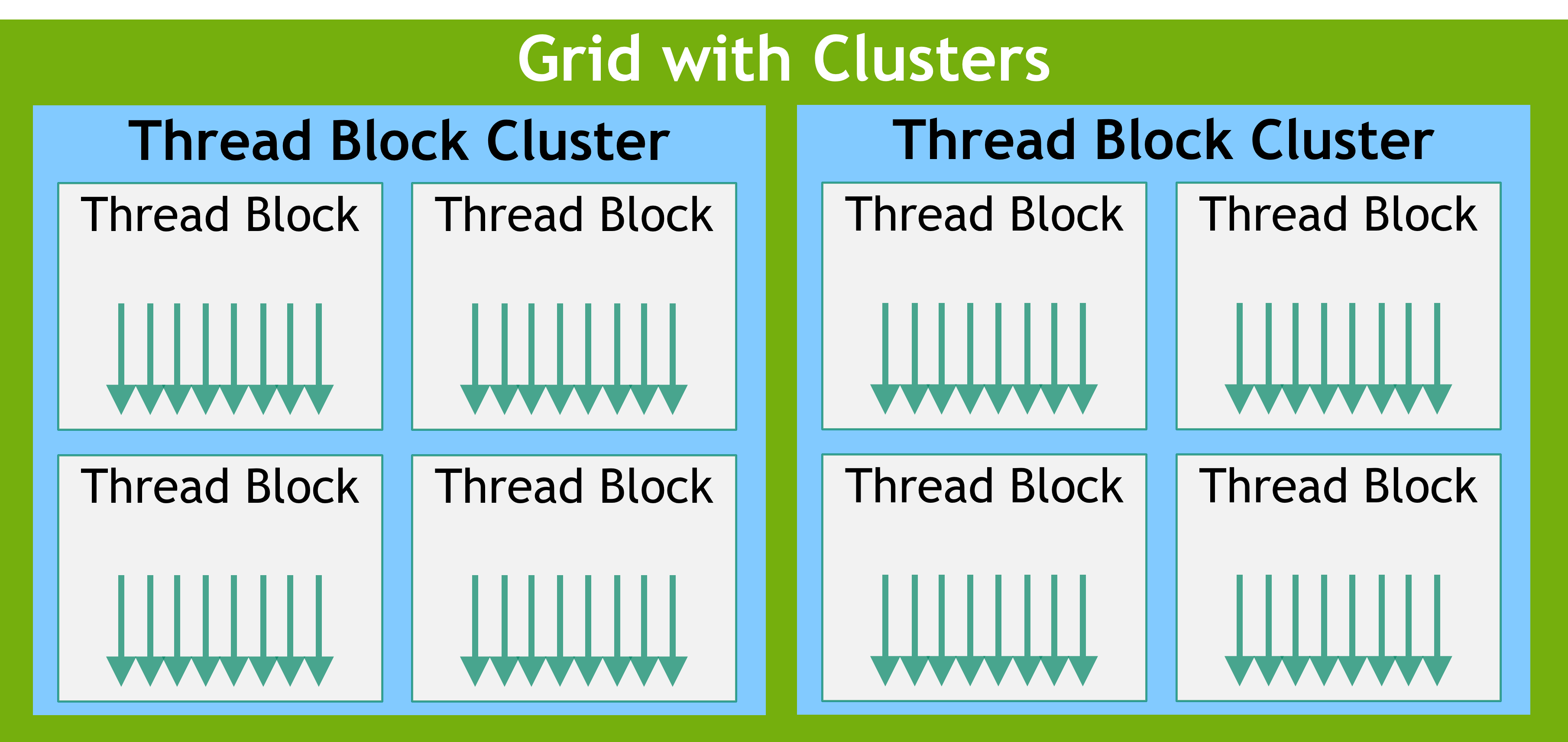
线程块簇可以在 kernel 中启用——要么使用 __cluster_dims__(X,Y,Z) 这个编译时(compile-time) kernel 属性,要么使用 CUDA kernel 启动 API cudaLaunchKernelEx 。下面的示例显示了如何使用编译时 kernel 属性来启用簇。使用 kernel 属性的簇的大小在编译时是固定的(启动后无法修改),然后可以使用经典的 <<<...>>> 来启用 kernel。
// Kernel definition
// Compile time cluster size 2 in X-dimension and 1 in Y and Z dimension
__global__ void __cluster_dims__(2, 1, 1) cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
// Kernel invocation with compile time cluster size
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension must be a multiple of cluster size.
cluster_kernel<<<numBlocks, threadsPerBlock>>>(input, output);
}簇的大小在运行时也可以设置,并且可以使用 CUDA kernel 启动 API cudaLaunchKernelEx 来启用 kernel。下面的代码展示了如何使用可扩展的 API 启用簇:
// Kernel definition
// No compile time attribute attached to the kernel
__global__ void cluster_kernel(float *input, float* output)
{
}
int main()
{
float *input, *output;
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
// Kernel invocation with runtime cluster size
{
cudaLaunchConfig_t config = {0};
// The grid dimension is not affected by cluster launch, and is still enumerated
// using number of blocks.
// The grid dimension should be a multiple of cluster size.
config.gridDim = numBlocks;
config.blockDim = threadsPerBlock;
cudaLaunchAttribute attribute[1];
attribute[0].id = cudaLaunchAttributeClusterDimension;
attribute[0].val.clusterDim.x = 2; // Cluster size in X-dimension
attribute[0].val.clusterDim.y = 1;
attribute[0].val.clusterDim.z = 1;
config.attrs = attribute;
config.numAttrs = 1;
cudaLaunchKernelEx(&config, cluster_kernel, input, output);
}
}在具有 compute capability 9.0 的 GPU 中,簇中的所有线程块都保证在单个 GPU 处理簇上共同调度,并且允许簇中的线程块使用 Cluster Group API cluster.sync() 执行硬件支持的同步。Cluster Group 还提供成员函数,分别使用 num_threads() 和 num_blocks() API 以线程数或块数来查询簇组的大小。簇组中线程或块的秩可以分别使用 dim_threads() 和 dim_blocks() 进行查询。
属于簇的线程块可以访问分布式共享内存。簇中的线程块能够读取、写入分布式共享内存中的任何地址,并对其执行原子操作。[Distributed Shared Memory] 给出了在分布式共享内存中执行直方图的示例。
2.3 Memory Hierarchy
CUDA 线程在执行过程中可以从多个内存空间访问数据,如图 6 所示。
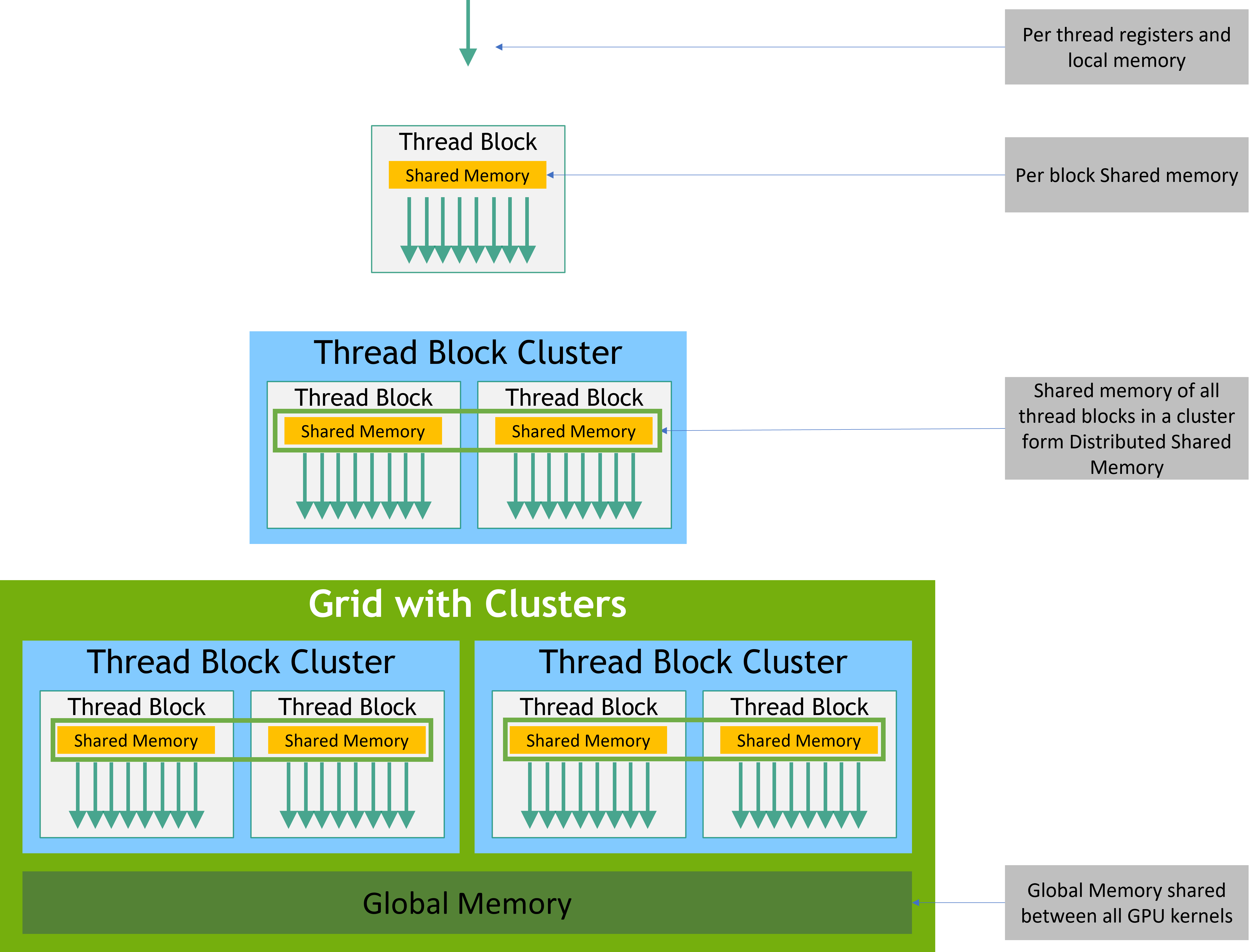
每个线程都有私有的本地内存,每个线程块都有共享内存,共用内存对该线程块的所有线程都是可见的,并且与该线程块具有相同的生命周期。线程块簇中的线程块可以在彼此的共享内存上执行读、写和原子操作。所有线程都可以访问相同的全局内存。
还有两个额外的只读内存空间可供所有线程访问:常量(constant)内存空间和纹理(texture)内存空间。全局、常量和纹理内存空间针对不同的内存使用进行了优化(请参阅[Device Memory Accesses])。纹理内存还为某些特定的数据格式提供了不同的寻址模式以及数据过滤(请参见[Texture and Surface Memory])。全局、常量和纹理内存空间在同一应用程序的 kernel 启动过程中是持久的。
2.4 Heterogeneous Programming
如图 7 所示,CUDA 编程模型假设 CUDA 线程执行在物理上独立的 设备 上,该设备作为运行 C++ 程序的 主机 的协处理器运行。例如,当 kernel 在GPU上执行,而 C++ 程序的其余部分在CPU上执行时,就会出现这种情况——异构。图 7 中的串行代码在主机上执行,而并行代码在设备上执行。
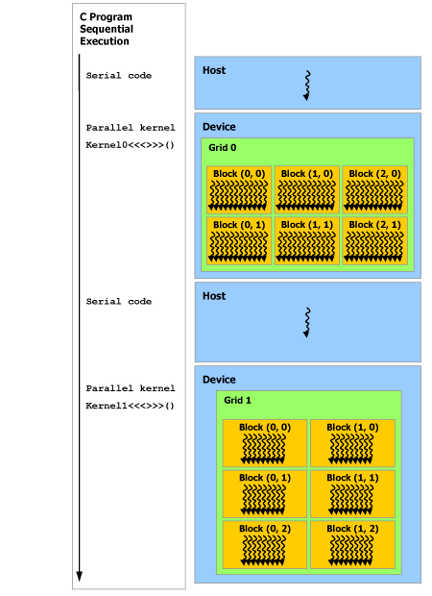
CUDA 编程模型还假设主机和设备在 DRAM 中保持各自独立的存储空间,分别称为 主机内存 和 设备内存 。因此,程序通过调用 CUDA 运行时(在 [Programming Interface] 中描述)来管理 kernel 可见的全局、常量和纹理内存空间。这包括设备内存的分配和释放,以及主机和设备内存之间的数据传输。
统一内存(Unified Memory)提供 托管内存(managed memory)以桥接主机和设备内存空间。托管内存可以从系统中的所有 CPU 和 GPU 访问,作为具有公共地址空间的单个连贯的内存映像。此功能实现了设备内存的超额订阅(oversubscription),并通过消除在主机和设备上显式镜像数据的需要,大大简化了移植应用程序(porting application)的任务。有关统一内存的介绍,请参阅[Unified Memory Programming]。
2.5 Asynchronous SIMT Programming Moel
在 CUDA 编程模型中,线程是进行计算或内存操作的最低抽象级别。从基于 NVIDIA Ampere GPU 架构的设备开始,CUDA 编程模型通过异步编程模型提供加速操作内存的手段。异步编程模型定义了 CUDA 线程的异步操作行为。
异步编程模型定义了 CUDA 线程之间同步的 [异步屏障] 的行为。该模型还解释并定义了如何在 GPU 中计算时使用 cuda::memcpy_async 从全局内存异步地移动数据。
2.5.1 Asynchronous Operations
异步操作的定义是:由 CUDA 线程发起并异步执行的操作,就像由另一个线程执行一样。在格式良好的程序中,一个或多个 CUDA 线程与异步操作同步。发起异步操作的 CUDA 线程不需要在同步的线程中。
这样的异步线程(并不真实存在,指的是上文中的“就像另一个线程执行”)总是与发起异步操作的 CUDA 线程相关联。异步操作使用同步对象(synchronization object)来同步操作的完成。这样的同步对象可以由用户显式管理(例如 cuda::memcpy_async ),也可以在库内隐式管理(如 cooperative_groups::memcpy_async )。同步对象可以是 cuda::barrier 或 cuda::pipeline 。这些对象在使用 cuda::pipeline 的[Asynchronous Barrier]和[Asynchronous Data Copies using cuda:: pipeline] 中有详细解释。这些同步对象可以在不同的线程作用域内使用,作用域定义了可以使用同步对象与异步操作同步的线程集,如下表所示,定义了 CUDA C++ 中可用的线程作用域以及可以与每个作用域同步的线程。
| Thread Scope 线程范围 | Description 描述 |
|---|---|
cuda::thread_scope::thread_scope_thread | 只有发起异步操作的CUDA线程会同步。 |
cuda::thread_scope::thread_scope_block | 与发起线程同步的同一线程块内的所有或任何CUDA线程。 |
cuda::thread_scope::thread_scope_device | 与发起线程同步的同一GPU设备中的所有或任何CUDA线程。 |
cuda::thread_scope::thread_scope_system | 与发起线程位于同一系统中的所有或任何CUDA或CPU线程同步。 |
这些线程作用域在 CUDA Standard C++ 库中作为标准 C++ 的扩展实现。
2.6 Compute Capability
设备的计算能力由版本号表示,有时也称为“SM 版本”。此版本号标识 GPU 硬件支持的功能,并由应用程序在运行时使用,以确定当前 GPU 上可用的硬件功能和指令。
计算能力包括主要修订号 X 和次要修订号 Y,用 X.Y 表示。
- 具有相同主要修订号的设备具有相同的核心架构。基于 NVIDIA Hopper GPU 架构的设备的主要修订号为 9,基于 NVIDIA Ampere GPU 架构的产品为 8,基于 Volta 架构的设备为 7,基于 Pascal 架构的设备 6,基于 Maxwell 架构的设备 5,基于 Kepler 架构的设备 3。
- 次要修订号对应于对核心架构的增量改进,可能包括新功能。Turing 是计算能力为 7.5 的设备的架构,是基于 Volta 架构的增量更新。
CUDA-Enabled GPUs 列出了所有支持CUDA的设备及其计算能力。 Compute Capabilities 给出了每种计算能力的技术规格。
特定 GPU 的计算能力版本不应与 CUDA 版本(例如 CUDA 7.5、CUDA 8、CUDA 9)混淆,CUDA 版本是 CUDA 软件平台的版本。CUDA 平台被应用程序开发人员用来创建在多代 GPU 架构上运行的应用程序,包括尚未发明的未来 GPU 架构。虽然 CUDA 平台的新版本通常通过支持新 GPU 架构的计算能力版本来添加对该架构的原生支持,但 CUDA 平台新版本通常还包括独立于硬件生成的软件功能。例如,Tesla 和 Fermi 架构分别从CUDA 7.0和CUDA 9.0开始不再受支持。
3. Programming Interface
CUDA C++为熟悉 C++编程语言的用户提供了一条可以轻松编写程序供设备执行的简单路径——CUDA C++由 C++语言的一组最小扩展和一个运行库组成。 编程模型 一节中引入了核心的语言扩展。它们允许程序员将 kernel 定义为 C++函数,并在每次调用函数时使用一些新的语法来指定网格和块的维度。所有扩展的完整描述可以在 C++ Language Extensions 中找到。任何包含这些扩展名的源文件都必须按照 使用NVCC编译一节 中所述的 nvcc 进行编译。
CUDA Runtime 引入了运行时的概念,它提供在主机上执行的 C 和 C++函数,用于分配和释放设备内存、在主机内存和设备内存之间传输数据、管理具有多个设备的系统等。runtime 的完整描述可以在 CUDA 参考手册中找到。
runtime 构建在较低级别的 C API(CUDA 驱动程序 API)之上,该驱动程序也可由应用程序访问。驱动程序 API 通过公开较低级别的概念提供了额外的控制级别,如 CUDA context(设备的主机进程的模拟)和 CUDA module(设备的动态加载库的模拟)。大多数应用程序不使用驱动程序 API,因为它们不需要这种额外的控制级别,并且当使用 runtime 时,上下文和模块管理是隐式的,从而产生更简洁的代码。由于 runtime 可与驱动程序 API 互操作,大多数需要某些驱动程序 API 功能的应用程序可以默认使用 runtime API,只在需要时使用驱动程序 API。驱动程序 API 在 Driver API 中介绍,并在参考手册中进行了全面描述。
3.1 Compilation with NVCC
kernel 可以使用 CUDA 指令集架构编写,称为 PTX(Parallel Thread eXecution),PTX 参考手册中对此进行了描述。然而,使用 C++等高级编程语言通常更有效。在这两种情况下,kernel 都必须通过 nvcc 编译成二进制代码才能在设备上执行。
nvcc 是一个编译器驱动程序,它简化了编译 C++或 PTX 代码的过程:它提供了简单而熟悉的命令行选项,并通过调用实现不同编译阶段的工具集合来执行它们。本节概述了 nvcc 工作流和命令选项。完整的描述可以在 nvcc 用户手册中找到。
3.1.1 Compilation Workflow
Offline Compilation. 用 nvcc 编译的源文件可以包括主机代码(即在主机上执行的代码)和设备代码(即在设备上执行的码)的混合。nvcc 的基本工作流程包括将设备代码与主机代码分离,然后:
- 将设备代码编译成汇编形式(PTX 代码)和 二进制形式(cubin object),
- 以及通过用必要的 CUDA runtime 函数调用以替换
<<<...>>>语法(在 Execution Configuration 中有更详细的描述)来修改主机代码,以从 PTX 代码和 cubin 对象加载和启动每个编译的 kernel 。(修改后的主机代码要么作为 C++代码输出,留待使用其他工具再次编译;要么作为目标代码直接输出,方法是在最后一个编译阶段让nvcc调用主机编译器。)
然后,应用程序可以: 3. 链接到完成编译的主机代码(这是最常见的情况), 4. 或者忽略修改后的主机代码(如果有),使用 CUDA 驱动程序 API 加载并执行 PTX 代码或 cubin 对象。
Just-in-Time Compilation. 应用程序在 runtime 加载的任何 PTX 代码都会被设备驱动程序进一步编译为二进制代码,这称为实时编译。实时编译增加了应用程序的加载时间,但允许应用程序从每个新设备驱动程序带来的任何新的编译器改进中受益。这也是应用程序运行在编译时不存在的设备上的唯一方法,详见 Application Compatibility 。 当设备驱动程序为某个应用程序实时编译一些 PTX 代码时,它会自动缓存生成的二进制代码生成副本,以避免在应用程序的后续调用中重复编译。当设备驱动程序升级时,缓存(称为计算缓存)会自动失效,这样应用程序就可以从设备驱动程序中内置的新实时编译器的改进中受益。 环境变量可以像 CUDA Environment Variables 描述的那样控制实时编译。
作为使用 nvcc 编译 CUDA C++设备代码的替代方法,NVRTC 可用于在 runtime 将 CUDA C++设备代码编译为 PTX。NVRTC 是 CUDA C++的运行时编译库;更多信息可以在 NVRTC 用户指南中找到。
3.1.2 Binary Compatibility
3.1.3 PTX Compatibility
3.1.4 Application Compatibility
3.1.5 C++ Compatibility
3.1.6 64-Bit Compatibility
3.2 CUDA Runtime
3.2.4 Shared Memory
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.width + col)
typedef struct {
int width;
int height;
float* elements;
} Matrix;
// Thread block size
#define BLOCK_SIZE 16
// Forward declaration of the matrix multiplication kernel
__global__ void MatMulKernel(const Matrix, const Matrix, Matrix);
// Matrix multiplication - Host code
// Matrix dimensions are assumed to be multiples of BLOCK_SIZE
void MatMul(const Matrix A, const Matrix B, Matrix C)
{
// Load A and B to device memory
Matrix d_A;
d_A.width = A.width; d_A.height = A.height;
size_t size = A.width * A.height * sizeof(float);
cudaMalloc(&d_A.elements, size);
cudaMemcpy(d_A.elements, A.elements, size,
cudaMemcpyHostToDevice);
Matrix d_B;
d_B.width = B.width; d_B.height = B.height;
size = B.width * B.height * sizeof(float);
cudaMalloc(&d_B.elements, size);
cudaMemcpy(d_B.elements, B.elements, size,
cudaMemcpyHostToDevice);
// Allocate C in device memory
Matrix d_C;
d_C.width = C.width; d_C.height = C.height;
size = C.width * C.height * sizeof(float);
cudaMalloc(&d_C.elements, size);
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
// Read C from device memory
cudaMemcpy(C.elements, d_C.elements, size,
cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A.elements);
cudaFree(d_B.elements);
cudaFree(d_C.elements);
}
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Each thread computes one element of C
// by accumulating results into Cvalue
float Cvalue = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int e = 0; e < A.width; ++e)
Cvalue += A.elements[row * A.width + e]
* B.elements[e * B.width + col];
C.elements[row * C.width + col] = Cvalue;
}Footnotes
-
为了避免中英互译时的混淆,后文再次提及 CUDA 的内核函数时,使用 kernel 一词,不再翻译。 ↩