这篇文章主要总结与路由相关的设计,对我的工作做一些启发。
路由设计的核心挑战与过去工作的不足
-
传统Clos网络的局限性:
- 静态拓扑与增量扩展问题:Clos 网络需要预先部署所有骨干交换机(spine),导致新加入的高速聚合块(aggregation block)因骨干交换机的旧链路速率而降级(如100Gbps块连接到40Gbps骨干时,带宽被限制为20Gbps)。
- 流量模式不匹配:Clos 假设均匀流量分布,但实际生产流量存在显著的异构性(如不同块之间的流量需求差异大、突发性高),导致链路利用率不均衡。
- 运维复杂度:升级骨干交换机需要全网停机或大规模重布线,成本高且风险大。
-
现有动态路由方案的不足:
- Valiant Load Balancing (VLB):通过均匀分配流量到所有路径(直连和中转),但导致2:1的过载比(oversubscription ratio),在高负载场景下性能不足。
- 缺乏对异构网络的支持:传统方案未有效解决多代硬件(如40G/100G/200G)共存时的链路速率不匹配问题。
本文中路由相关的技术贡献
1. 控制平面设计(Control Plane Design)
- Orion 架构:
- 架构分层:Jupiter 采用分层 SDN 控制平面(Orion),分为域内路由(Routing Engine) 和 域间路由(Inter-Block Router-Central):
- 域内路由:每个聚合块作为一个独立 Orion 域,通过 RE 管理内部路由,负责块内连通性和外部可达性。
- 域间路由:通过 IBR-C 管理块间逻辑链路,将 DCNI 层(Optical Circuit Switch)划分为 4 个独立的控制域(颜色),每个域管理 25%的 OCS 跨块链路,限制故障影响范围。
- 容错机制:OCS 控制平面采用“失效静态”(fail-static)设计,控制平面断开时保持最后配置,避免数据平面完全失效。OCS 电源域与控制域对齐,单电源故障最多影响 25%容量。
- 架构分层:Jupiter 采用分层 SDN 控制平面(Orion),分为域内路由(Routing Engine) 和 域间路由(Inter-Block Router-Central):
- Optical Engine Controller:
- OCS 编程:通过OpenFlow接口动态配置光交叉连接(如
match{IN_PORT 1} → OUT_PORT 2),实现逻辑拓扑的毫秒级调整。 - 容错机制:OCS 断电时依赖路由系统重新均衡流量,避免单点故障。
- OCS 编程:通过OpenFlow接口动态配置光交叉连接(如
2. 非最短路径路由(Non-Shortest Path Routing)
- 设计动机:
- 直接连接拓扑在极端流量下可能过载(最坏情况下过载比为 ),需通过1 跳中转路径(如 A→B→C)扩展容量。
- 应用场景:
1. 块间需求超过直接路径容量。
2. 流量方向不对称(如
A→B流量>B→A流量,需构建对称链路容量)。 3. 流量不确定性(突发性)要求路径多样性(从而通过多路径分摊风险)。 4. 异构网络中利用高速块作为“解复用器”(如200G块中转100G块的流量),保留高速块上的高速端口,虽然总带宽有一定程度降低,但是带宽冗余的块可以用于传输。 - 路径限制:仅允许单跳中转,限制路径长度以避免延迟增加。通过VRF 隔离源流量与中转流量,确保无环路。
3. 流量感知路由(Traffic-Aware Routing)
- 流量矩阵预测与优化:
- 数据收集:每 30 秒通过流计数器或采样获取细粒度流量矩阵(TM),
- 预测模型:基于过去 1 小时的峰值流量构建预测矩阵,每小时更新以适应变化,
- 优化目标:最小化最大链路利用率(MLU,其是吞吐量以及对流量模式变化弹性的一种合理代理指标,高 MLU 表明许多链路面临过载的风险),同时降低路径平均拉伸率(stretch,拉伸率越长,代表块间流量通过的路径越长,非直接连接的路径越长就会消耗越多的容量以及导致更多的 RTT 时延)。
- 鲁棒性机制:
- 引入Variable Hedging(变量对冲),通过
Spread参数约束流量在路径上的分布比例(意即控制流量分配的保守程度),平衡预测准确性与流量不确定性。例如,高Spread类似 VLB 的均匀分配(鲁棒性强但效率低),低Spread接近 MCF最优解(效率高但对预测误差敏感)。 - 动态调整:根据历史流量模式为每个数据中心选择最优
Spread(如高稳定性业务用小Spread,突发性业务用大Spread。
- 引入Variable Hedging(变量对冲),通过
- 实际效果:仿真显示,结合 Hedging 的 TE 可将 MLU 降低 15%,同时减少突发流量导致的拥塞(图 13)
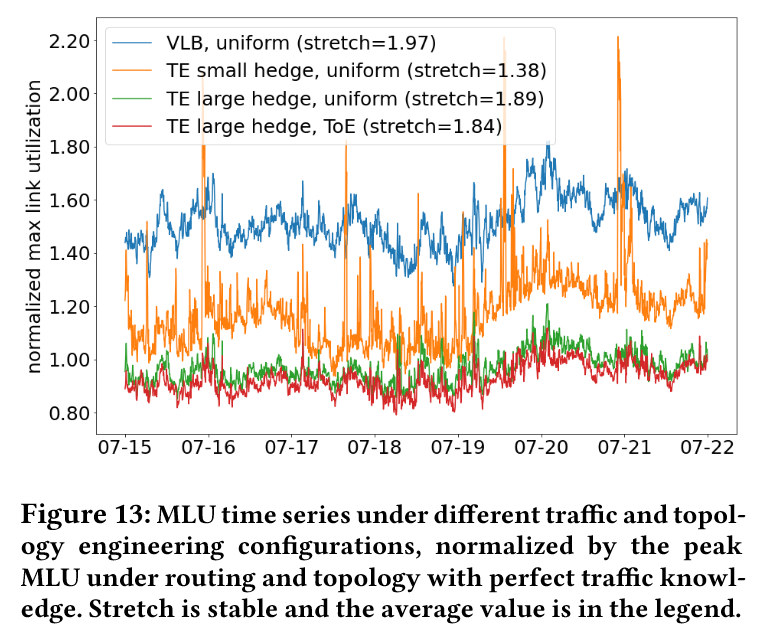
4. 拓扑工程(Topology Engineering)
- 异构网络的优化:
- 流量感知拓扑利用低负载的高速块作为“解复用器”,将高速链路转换为多条低速链路,提升低速块容量,或者在高速块间分配更多链路(图 9),减少异构速度块的链路降速影响,
 图 9 表明,流量无关的均匀拓扑无法为来自区块 A 的流量需求提供足够的聚合带宽,而流量感知拓扑则能应对该负载。
图 9 表明,流量无关的均匀拓扑无法为来自区块 A 的流量需求提供足够的聚合带宽,而流量感知拓扑则能应对该负载。 - 联合优化拓扑与路由,同时调整逻辑链路数量(拓扑)与路径权重(路由),最大化吞吐量、最小化 stretch、容忍 tail burst,同时尽量减小与均匀拓扑的差异——这使得网络从运维角度来看不会显得突兀,既保持了类似均匀拓扑的特性,又实现了更高的吞吐量或更低的路径扩展。
- 流量感知拓扑利用低负载的高速块作为“解复用器”,将高速链路转换为多条低速链路,提升低速块容量,或者在高速块间分配更多链路(图 9),减少异构速度块的链路降速影响,
- 实现方法:
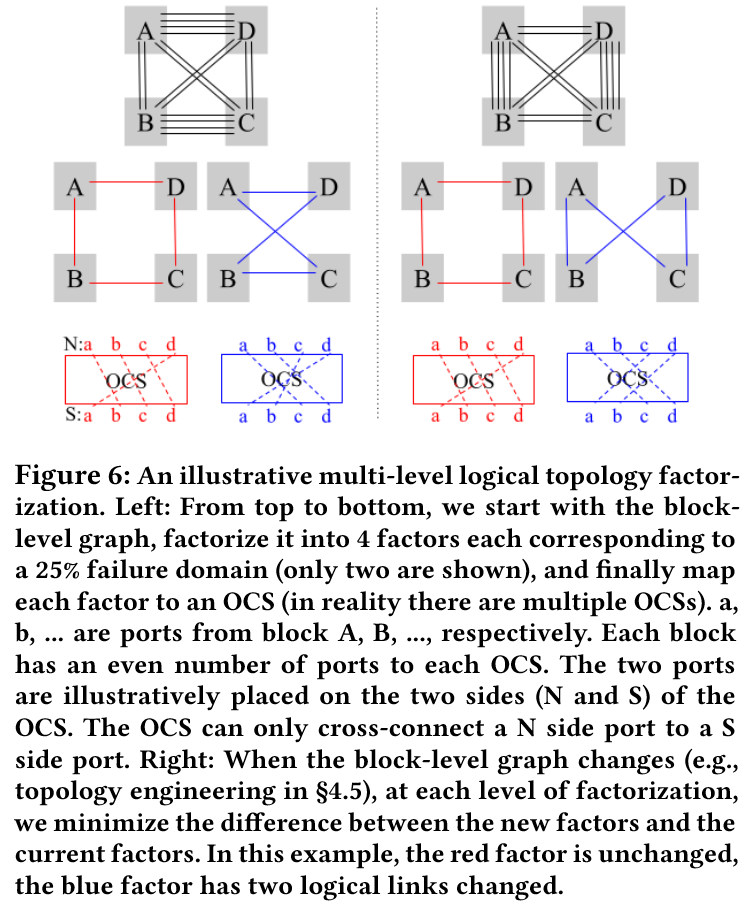
- 块级拓扑分解为端口级 OCS 连接,通过整数规划最小化拓扑差异(图 6)
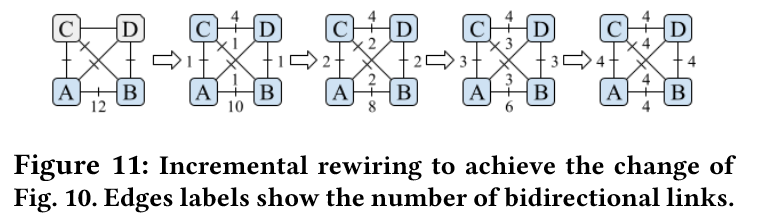
- 支持增量重构,每步保持至少 83%容量在线(图 11),确保生产 SLO
- 块级拓扑分解为端口级 OCS 连接,通过整数规划最小化拓扑差异(图 6)
- 评估结果:
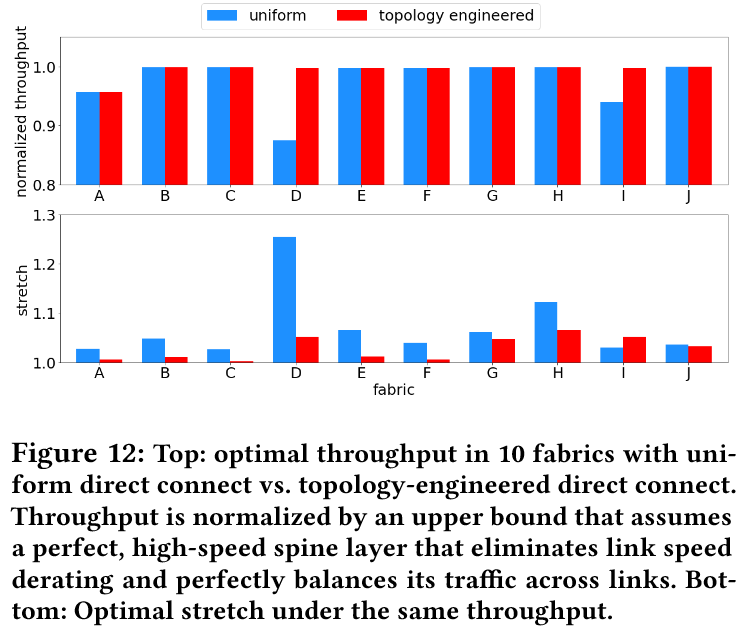
- 流量感知拓扑在异构网络中可将吞吐量提升至理论上限,平均路径长度(stretch)从 1.64 降至 1.04(图 12)
- 均匀拓扑与流量感知拓扑的对比:均匀拓扑 :链路数量与块速率乘积成比例(如200G块间链路数是100G块的4倍)。流量感知拓扑 :根据实际流量需求动态调整链路分配(如为高流量块对分配更多直连链路)。
- 流量感知拓扑在异构网络中可将吞吐量提升至理论上限,平均路径长度(stretch)从 1.64 降至 1.04(图 12)
5. 评估与生产验证
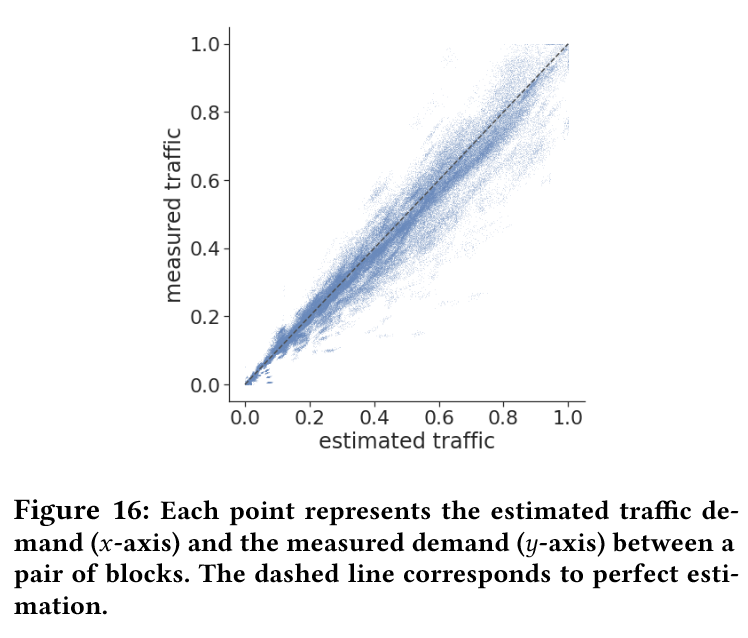
- 流量特性:实际流量符合重力模型(块间流量与块的总需求乘积成正比),RMSE 误差仅 0.05(图 16)。流量峰值集中在少数块,其余块带宽空闲(NPOL<10%),支持中转路径。
- 性能对比:
- 吞吐量与链路利用率:
- 直接连接拓扑(结合 TE 和 ToE)在 10 个生产集群中实现 99th percentile MLU 降低 15%,接近理论最优值(均匀流量下达到 Clos 的吞吐量),
- 异构网络中,流量感知拓扑通过消除低速链路导致的降级,将网络吞吐量提升至 Clos 的 1.3 倍。
- 吞吐量与链路利用率:
- 路径效率:
- Clos 的 stretch=2.0,降至 1.4(60%流量通过直连路径(stretch=1.0),40%通过单跳中转(stretch=2.0),平均stretch为1.4),端到端延迟降低 16%(小流 FCT 减少 24%)
- ToE 进一步优化 stretch 至 1.04(表 1)
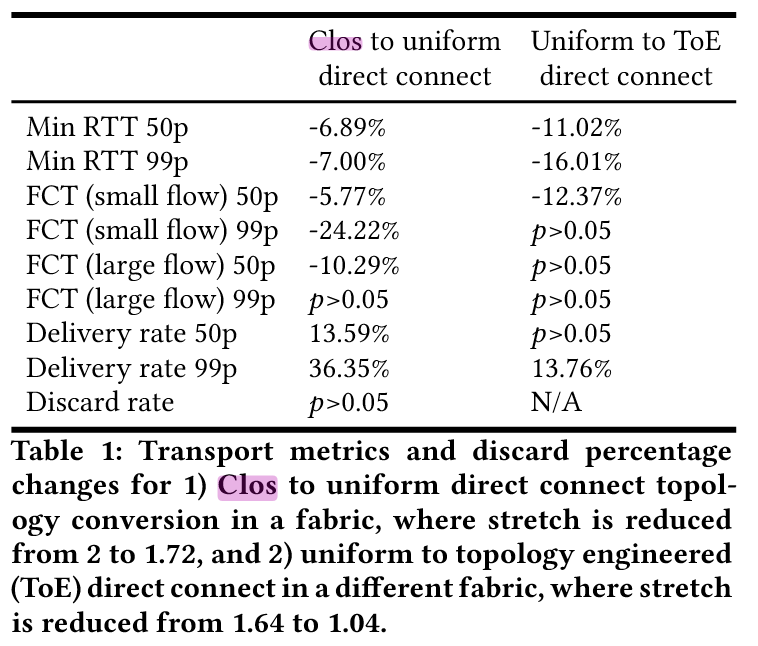
- 延迟与丢包:转换至直接连接后,RTT 降低 6-14%,小流 FCT 减少 29%(表 1)。
- 生产部署效果:
- Clos 转直接连接:
- 成本:CAPEX降低30%,功率减少41%(移除 spin 交换机层)。
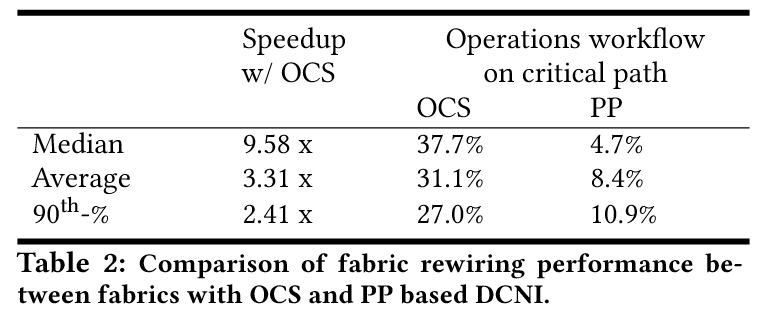
- 运维效率:OCS 重构速度比传统跳线盘(PP)快 3-9.6 倍,人工操作占比从 8.4%降至 31.1%(表 2)
- 异常场景恢复 :在VLB实验中,关闭TE导致丢包率上升89% ,99th percentile FCT增加29%,验证了TE的必要性。
- Clos 转直接连接:
6. 对比先前工作与创新点
- 对比 Clos 拓扑:
- 遗留问题:Clos 需预部署 Spine 层,限制新技术引入(链路降速),且路径固定(stretch=2.0)。
- 本文改进:通过动态拓扑(OCS)和联合 TE/ToE,实现等效吞吐量、更短路径、30%成本与 41%功耗节省。
- OCS硬件设计:
- MEMS-based OCS :支持136x136端口、双向通信,插入损耗<2dB,回波损耗←46dB。
- 光循环器(Circulator) :通过偏振分光与法拉第旋转实现单纤双向传输,节省50%光纤与OCS端口 。
- 流量矩阵特性 :
- 重力模型(Gravity Model) :块间流量与块总发送/接收量的乘积成正比,指导均匀拓扑设计。
- 负载异构性 :10%的块NPOL(归一化峰值负载)低于均值1个标准差,提供中转带宽冗余。
- 对比其他可重构网络:
- Helios、RotorNet 等方案缺乏细粒度流量感知,Jupiter 通过 SDN 集中控制实现动态优化。
- 支持异构速度块共存,利用流量工程缓解带宽不匹配问题。
7. 技术挑战与局限性
- 流量假设依赖:优化基于重力模型和流量可预测性,对突发或非均匀流量的适应性需进一步验证。
- 系统复杂性:动态拓扑与路由增加控制平面复杂度,需依赖高级调试工具(如状态回放)和自动化运维。
- 拓扑更新延迟:ToE 更新周期为小时级,未来需结合 ML 预测支持更频繁调整(如适应 AI 训练流量)。