本论文是对 DeepSeek V3 模型架构和 Infra 的深入分析。
Introduction
Core View: Effective software-hardware co-design can enable cost-efficient training and inference of large models.
Background
大型语言模型的快速扩展(如 GPT4o、LLaMA-3、DeepSeek-V3 等)揭示了当前硬件架构的瓶颈,包括内存容量、计算效率和互联带宽的限制。尽管行业巨头(如 Google、Meta)通过超大规模 GPU/TPU 集群训练模型,但其高昂成本限制了中小团队的发展。
DeepSeek-V3 通过软硬件协同设计,仅用 2048 块 NVIDIA H800 GPU 实现了高效训练与推理,验证了硬件感知模型设计的可行性。其核心创新包括:
- Multi-head Latent Attention (MLA):压缩注意力机制中的 Key-Value 缓存,显著降低内存占用;
- Mixture of Experts (MoE):稀疏激活参数,减少计算资源需求;
- FP8 混合精度训练:利用低精度计算降低硬件成本;
- Multi-Plane 网络拓扑:优化集群级网络开销。
Objectives
本文旨在从硬件与模型设计的双重视角,分析二者协同对高效扩展 LLM 的作用,而非重复技术细节。具体目标包括:
- 硬件驱动的模型设计:研究 FP8 低精度计算、网络拓扑特性如何影响 DeepSeek-V3 的架构选择;
- 硬件与模型的相互依赖:探讨硬件能力如何推动模型创新,以及 LLM 需求如何驱动下一代硬件发展;
- 未来硬件方向:基于 DeepSeek-V3 的实践经验,提出硬件与模型协同设计的指导原则。
Structure of this Paper
论文后续结构如下:
- Section 2:阐述 DeepSeek-V3 的设计原则,包括 MLA、MoE 优化、多令牌预测模块(MTP);
- Section 3:分析低精度计算与通信的协同设计;
- Section 4:讨论 Scale-Up 互联优化、并行策略与硬件特性关联;
- Section 5:聚焦 Scale-Out 网络优化,包括多平面网络与低延迟互联;
- Section 6:总结关键见解,提出未来硬件与模型协同设计的方向。
Design Principles for DeepSeek Models
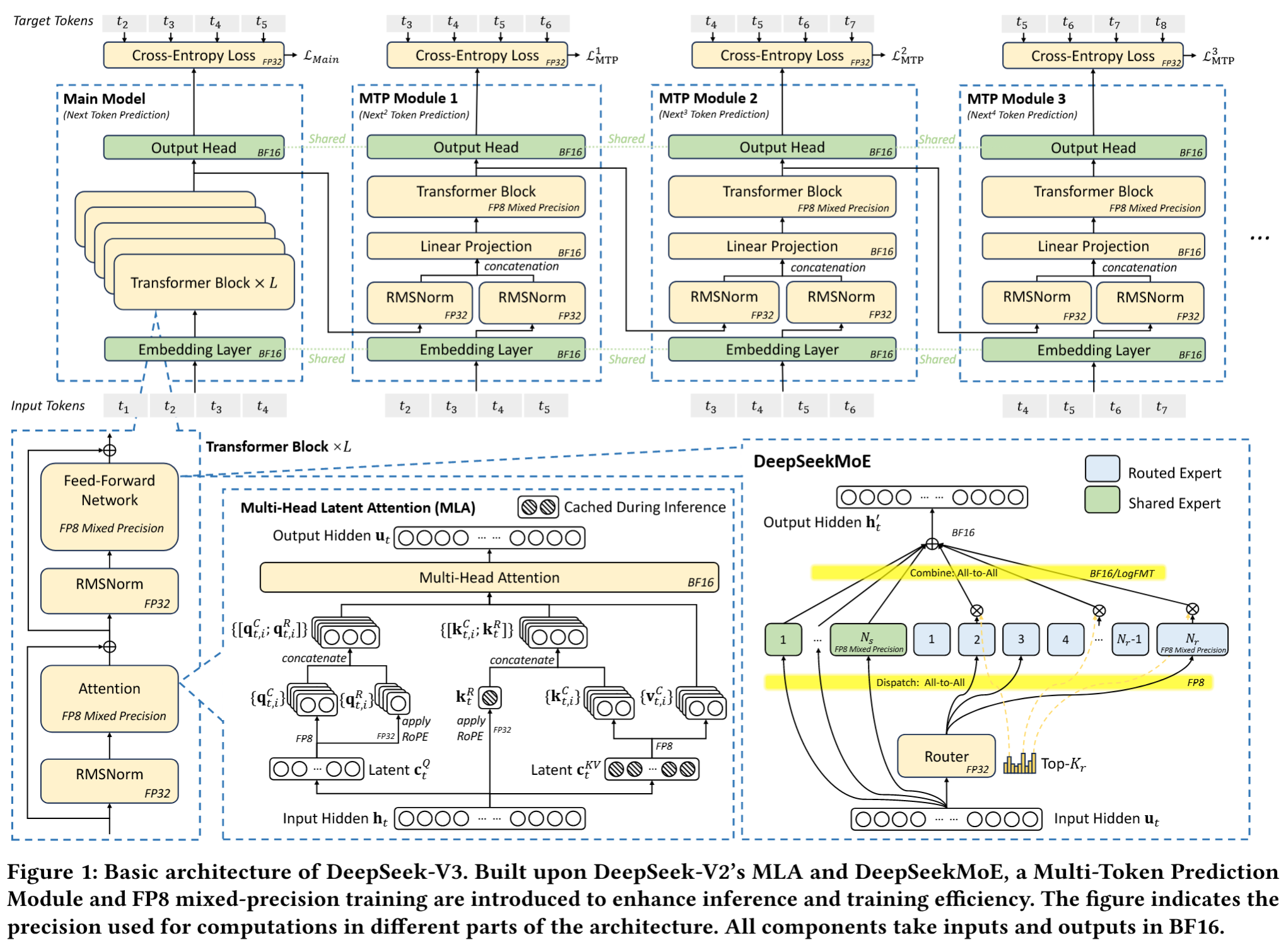
回顾 DeepSeek V3 Technical Report 中提出的技术,其主要目标是为了解决三个问题:
- 内存效率
- 成本效益
- MoE 稀疏激活
- MPFT 网络拓扑
- 基于硬件感知的并行策略、节点限制路由
- 基于IBGDA的DeepEP通信库
- 推理速度
- MTP 多词元预测模块
- DualPipe
- Prefilling and decode disaggregation
- Test-Time Scaling
Memory Efficiency
核心挑战:LLM内存需求年增长超1000%,而高速内存(如HBM)容量年增长不足50%。
虽然通过多节点并行可以解决一定的内存限制,但是更关键的还是从源头优化内存使用:
- 低精度模型(FP8):
- 将权重从BF16转为FP8,内存占用减少50%,缓解内存墙问题。具体技术在 第三章 。
- MLA 技术减少 KV Cache:
- KV cache 及其不足:
- LLM 推理中,用户请求常涉及多轮对话,为高效处理此类请求,系统会将历史对话的上下文缓存于 Key-Value vector1 中,避免反复计算。在每次推理步骤中,模型仅计算当前词元的键向量与值向量,并通过将其与历史缓存的键值对组合进行注意力计算。这种增量式计算将每个词元的生成复杂度降低至 ,使得处理长序列或多轮输入时更为高效。
- 然而,这引入了内存受限的瓶颈,因为计算从GEMM转向了GEMV(通用矩阵-向量乘法),后者的计算-内存比显著降低。现代硬件可提供数百TFLOPS的算力,使得GEMV迅速受限于内存带宽,导致内存访问成为主要瓶颈。
- MLA2 的思路:通过投影矩阵压缩所有注意力头的KV缓存为潜在向量,推理时仅需缓存潜在向量,从而显著降低了内存消耗。
- 效果:
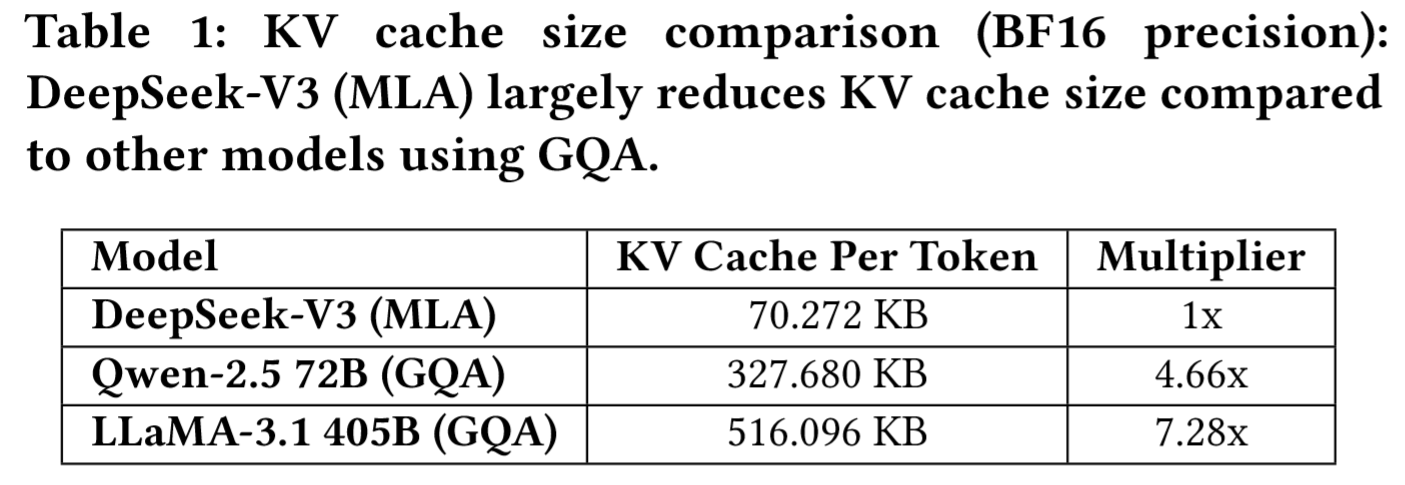 KV缓存大小降至70 KB/token(对比Qwen-2.5 72B的327 KB和LLaMA-3.1 405B的516 KB),这表明 MLA 比 GQA 在降低 KVCache 占用方面的显著优势。
KV缓存大小降至70 KB/token(对比Qwen-2.5 72B的327 KB和LLaMA-3.1 405B的516 KB),这表明 MLA 比 GQA 在降低 KVCache 占用方面的显著优势。
- 效果:
- KV cache 及其不足:
- 其他优化方法:
- 共享KV(GQA/MQA):与每个注意力头维护独立键值对不同,多个注意力头共享同一组键值对,代表性方法就是 Grouped-Query Attention/Multi-Query Attention。
- 窗口化KV:对于长序列,缓存中仅保留滑动窗口内的KV,牺牲长上下文能力换取内存节省(如Longformer)。
- 量化压缩:低比特位宽存储KV(如4-bit),进一步降低内存,代表工作是 KVQuant、GEAR 等。
- 未来方向:探索线性时间注意力(如Mamba-2 和 Lightning Attention)和稀疏注意力(如 DeepSeek 的 NSA),突破Transformer的平方复杂度限制。
GEMV 为什么比 GEMM 在计算-内存比显著降低?
- GEMV和GEMM的定义
GEMV(General Matrix - Vector Multiply)是矩阵 - 向量乘法。假设有一个矩阵A,其维度是,向量x的维度是,那么计算结果是一个的向量y,计算公式为。例如,矩阵A是,向量x是,那么计算结果向量y为。
GEMM(General Matrix - Matrix Multiply)是矩阵 - 矩阵乘法。如果矩阵A的维度是,矩阵B的维度是,那么结果矩阵C的维度是,计算公式为。例如,矩阵A是,矩阵B是,那么结果矩阵C为。
- 计算 - 内存比的概念
- 计算 - 内存比(computational-to-memory ratio)是指计算操作的数量与内存访问操作数量的比值。对于矩阵运算,计算操作主要是加法和乘法,而内存访问操作包括读取矩阵或向量的元素以及存储结果。
- GEMV和GEMM的计算 - 内存比对比
- GEMV的计算 - 内存比
- 在GEMV运算中,对于每个矩阵A的行元素和向量x的元素,都需要进行一次乘法和一次加法操作。假设矩阵A的大小是,向量x的大小是,那么总的计算量(乘法和加法)大约是(因为每个元素乘法和加法各一次)。而内存访问方面,需要读取矩阵A的所有元素(次读取)和向量x的所有元素(n次读取),以及写入结果向量y的元素(m次写入)。所以总的内存访问次数大约是。计算 - 内存比可以近似为,当矩阵A的行数m和列数n都很大时,这个比值会趋近于2,但总体上计算 - 内存比相对较低,因为每次计算操作后,结果向量y的存储和矩阵A、向量x的读取操作使得内存访问频繁。
- GEMM的计算 - 内存比
- 对于GEMM运算,矩阵A的大小是,矩阵B的大小是,结果矩阵C的大小是。计算量(乘法和加法)大约是。内存访问方面,需要读取矩阵A的所有元素(次读取)、矩阵B的所有元素(次读取),以及写入结果矩阵C的元素(次写入)。总的内存访问次数大约是。计算 - 内存比可以近似为,当矩阵的维度m、k、n都较大时,这个比值通常会比GEMV的计算 - 内存比高。因为GEMM中计算操作的数量相对内存访问操作数量增加得更快,例如在大规模矩阵乘法中,计算操作可以充分利用矩阵元素之间的关系,而内存访问主要是读取和存储矩阵元素,相对较少。
- 结论理解
- 说GEMV比GEMM在计算 - 内存比显著降低,是因为在GEMV运算中,每次计算操作后,内存访问(读取矩阵A的行元素、向量x的元素以及写入结果向量y的元素)的开销相对计算操作来说比较显著。而GEMM运算中,计算操作(大量的乘法和加法)可以更高效地利用矩阵元素之间的关系,使得计算操作数量相对于内存访问操作数量的增加速度更快,从而计算 - 内存比相对较高。
Cost-Effectiveness of MoE Models
核心思想:通过稀疏激活参数降低训练和推理成本,同时保持模型规模。
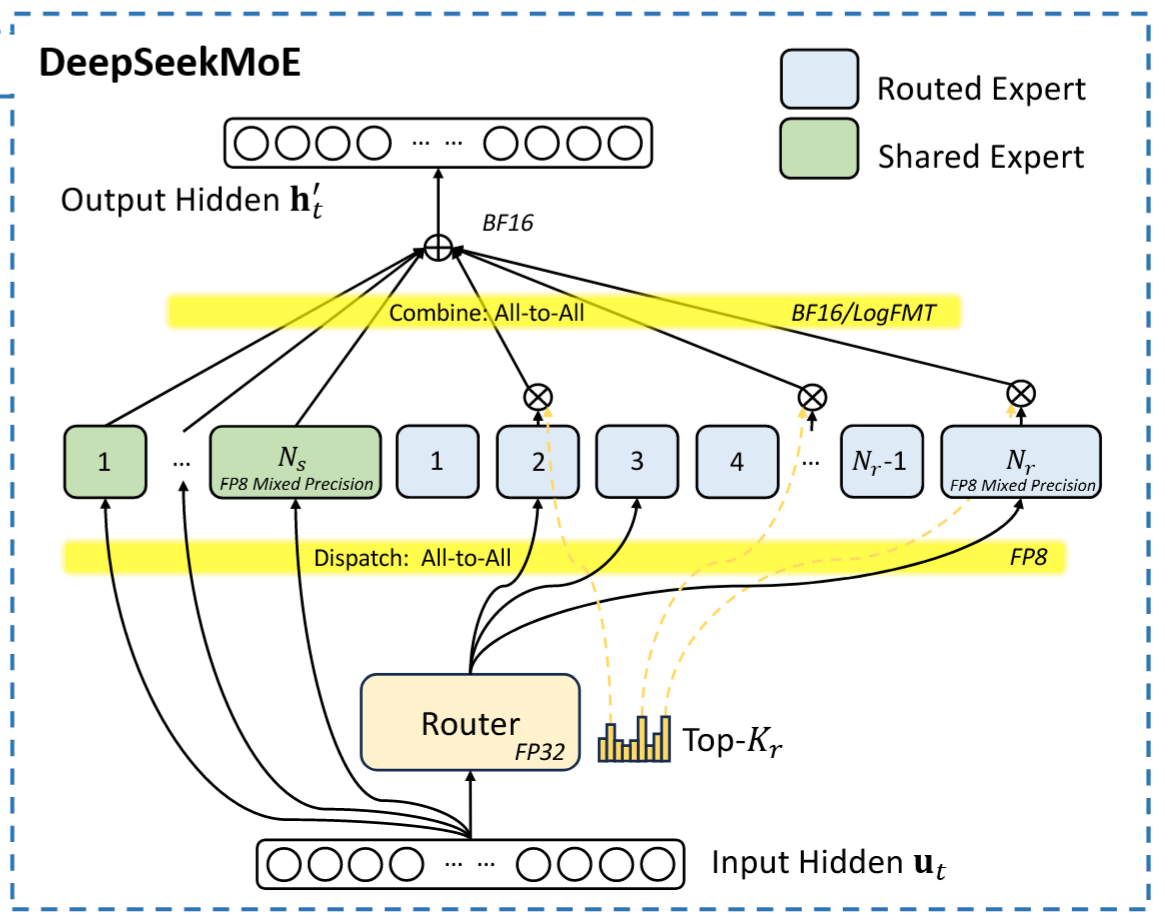
MoE 模型的优势在于:
- 训练时计算成本优化:通过选择性激活部分专家参数,MoE模型可在保持适度计算需求的同时,使总参数量实现数量级增长。
- DeepSeek MoE:V2 的总参数量为 236B,每 token 激活 21B 参数、计算成本 155GFLOPS/token;V3 的总参数量671B,但每token仅激活37B参数,计算成本250 GFLOPS/token,显著低于稠密模型(如LLaMA3.1-405B 需要激活全部参数、2448 GFLOPS 的计算成本)。
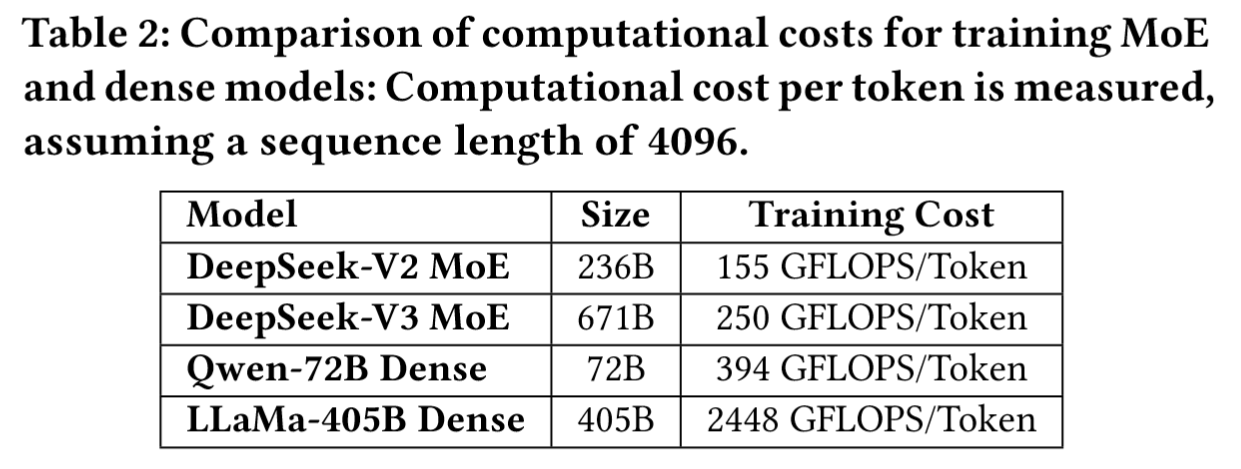
- 个人、本地场景下的推理与部署优势:通过最小化内存与计算开销,MoE模型无需昂贵基础设施即可实现高质量推理性能。
- 单次请求场景:MoE模型(如DeepSeek-V2)在消费级AI SoC芯片上实现20+ TPS,而同等能力的密集模型(如70B参数)仅个位数TPS。
- 低成本服务器支持:通过KTransformers推理引擎,DeepSeek-V3可在1万美元消费级服务器上运行,推理速度达20 TPS。
Increasing Inference Speed
提升推理速度的核心目标:最小化单次请求延迟TPOT(Time Per Output Token)和最大化系统吞吐量,提升用户体验与推理效率。
优化手段:
- 计算与通信重叠:➡ 最大化吞吐量
- dual micro-batch overlap架构3:通过刻意重叠通信延迟与计算时间,将 MLA与 MoE的计算解耦为两个独立阶段:当一个微批次执行部分 MLA 或 MoE 计算时,另一个微批次同步执行对应的调度通信;反之当第二个微批次处于计算阶段时,第一个微批次则执行聚合通信步骤。这种流水线设计实现了All2All 通信与持续计算的无缝重叠,确保 GPU 时刻保持满载状态。
- disaggregating prefill and decode架构:在生产环境中,将大批次的预填充请求和对延迟敏感的解码请求分配给不同规模的专家并行组进行处理,该策略使得在实际服务条件下的系统吞吐量最大化。
- 推理速度理论极限:
- LLM服务的解码输出速度,通常以TPOT作为衡量指标,TPOT不仅是影响用户体验的关键参数,更直接决定了OpenAI o1/o3、DeepSeek-R1等依赖推理长度提升智能的推理模型的响应性能。
- 对于MoE模型而言,实现高速推理的核心在于高效地将专家参数部署至计算设备,为达到理论最快推理速度,理想情况下每个设备应仅负责单个专家的计算(必要时可由多设备协同计算单个专家)。然而EP策略需要将 token 路由至对应设备,这涉及跨节点的 All2All 通信。因此,MoE模型的推理速度上限实际由互联带宽决定。
- 估算推理速度的理论极限:假设某系统中每个设备存储单个专家参数并同时处理约32个 token,该 token 数量实现了计算内存比与通信延迟的最佳平衡,同时确保专家并行期间各设备处理等量批次,从而便于精确计算通信耗时。
- 对于采用CX7 400Gbps InfiniBand(IB)网卡互连的系统,EP中两次 all-to-all 通信所需时间计算为: ,此处,
dispatch采用FP8(1Byte),而combine采用BF16(2Bytes),每个 token的隐藏层大小约为7K。系数9表示每个令牌需传输至8个路由专家和1个共享专家。 - 上文提到,实现最大吞吐量需采用双微批次重叠策略,在接下来该策略的理论最优案例分析中,假设计算开销最小化,性能上限完全由通信延迟决定(然而在实际推理任务中,请求上下文通常更长,且MLA计算往往主导执行时间,故本分析代表双微批次重叠下的理想化场景)。基于此假设,单层总时间可表述为:,而61层的DeepSeek-V3总推理时间为:,因此该系统的理论上限为:,也即67TPS。实际运行中,通信开销、延迟、带宽利用率不足及计算效率低下等因素会降低这一数值。
- 作为对比,若采用GB200 NVL72等高带宽互连方案(72块GPU间单向传输带宽达900GB/s),每个EP步骤的通信时间将降至: ,假设计算时间与通信时间相等,则总推理时间将大幅缩短,理论上可实现超过0.82毫秒的TPOT(即1200TPS)。
- 对于采用CX7 400Gbps InfiniBand(IB)网卡互连的系统,EP中两次 all-to-all 通信所需时间计算为: ,此处,
- 这表明,高带宽纵向扩展网络对加速大规模模型推理具有变革潜力。
- 多词元预测:
- 传统自回归模型在推理时每个解码步骤仅生成单个 token,导致序列化瓶颈。MTP 通过使模型能够以较低成本生成额外候选令牌并进行并行验证,有效缓解了这一问题。
 如图所示,每个MTP模块仅使用单层轻量级网络(远小于完整模型规模)预测额外token,从而实现多候选token的并行验证。
如图所示,每个MTP模块仅使用单层轻量级网络(远小于完整模型规模)预测额外token,从而实现多候选token的并行验证。- 尽管该方法对吞吐量略有影响,但能显著改善端到端生成延迟。实际应用数据表明,MTP模块对第二个后续token的预测接受率达80%至90%,相较无MTP模块的场景,生成吞吐量(TPS)提升1.8倍。
- 此外,通过单步预测多token,MTP还增大了推理时的批处理规模,这对提升EP计算密集性和硬件利用率至关重要。
- 推理模型的高推理速度与测试时动态扩展(Test-Time Scaling):
- 以OpenAI的o1/o3系列为代表的测试时动态扩展技术,通过推理过程中动态调整计算资源,在数学推理、编程和通用推理领域实现了重大突破。后续模型——包括DeepSeek-R1、Claude-3.7 Sonnet、Gemini 2.5 Pro、Seed1.5-Thinking和Qwen3——均采用类似策略,在这些任务上取得了显著提升。
- 对于此类推理模型,高token输出速度至关重要。在强化学习工作流(如PPO、DPO和GRPO)中,由于需要快速生成大量样本,推理吞吐量成为关键瓶颈。同样,过长的推理序列会增加用户等待时间,降低模型的实际可用性。因此,通过硬件与软件的协同创新优化推理速度,对提升推理模型效率具有不可替代的作用。
Technical Validation Methodology
分层验证确保技术可行性,避免全量模型的高成本消融测试:
- 先小规模验证,随后进行最小化的大规模调优,最后整合至一次完整的训练过程中。
- 例如,先在16B/230B的DeepSeek-V2模型上测试FP8训练,精度损失较FP16控制在0.25%以内(通过高精度累加和细粒度量化),之后再整合到DeepSeek-V3中。
Low-Precision Driven Design
FP8 Mix-Precision Training
核心目标:利用FP8低精度计算减少训练内存与计算成本,同时保持模型精度。
诸如GPTQ和AWQ等量化技术已被广泛用于将位宽降至8位、4位甚至更低,显著降低了内存需求。然而这些技术主要应用于推理阶段以节省内存,而非训练阶段。NVIDIA的Transformer Engine虽早已支持FP8混合精度训练,但在DeepSeek-V3之前,尚未有开源大模型采用FP8进行训练。FP8框架技术细节详见 DeepSeek V3 Technical Report,其中对激活值实施细粒度分块量化(1x128的tile-wise量化),对模型权重执行128x128的blockwise量化。
- FP8训练的限制:
- FP8累加精度不足:FP8在Tensor Core中采用受限累加精度,这对大型模型训练的稳定性产生影响,尤其在NVIDIA Hopper GPU上表现显著。当基于最大指数通过右移对齐32个尾数乘积后,Tensor Core仅保留其最高13位小数部分用于加法运算,超出此范围的位数将被截断。加法结果会累积至FP22寄存器(1位符号位、8位指数位及13位尾数位)。
- 细粒度量化的问题:细粒度量化(如分片量化和块级量化)在将部分结果从Tensor Core传输至CUDA Core进行缩放因子乘法时,会引入显著的去量化开销。这导致频繁的数据迁移,不仅降低了计算效率,还使得硬件利用率复杂化。
- 未来硬件设计的建议:
- 支持FP32累加精度:硬件应提高累加寄存器精度至适当值(如FP32),或支持可配置的累加精度,从而根据不同模型在训练与推理中的需求,实现性能与精度的权衡。
- 原生细粒度量化支持:硬件需原生支持细粒度量化,使Tensor Core能够接收缩放因子并实现分组缩放的矩阵乘法。如此,所有partial sum accumulation及去量化过程可直接在Tensor Core内部完成直至生成最终结果,避免频繁数据搬移以降低去量化开销。该方案的典型工业实现是NVIDIA Blackwell对微缩放数据格式的支持,这印证了原生量化技术在大规模应用中的实践价值。
LogFMT: Communication Compression
核心思路:通过压缩EP通信数据,降低带宽需求。
- FP8量化token:
- 在当前DeepSeek-V3架构中执行EP时,通过细粒度FP8量化分发token,相比BF16可减少50%通信量,显著降低通信耗时。
- LogFMT格式:
- 除传统浮点格式外,还尝试了名为对数浮点格式(LogFMT-nBit)的新型数据类型,其中为总位数,首位为符号位,通过将激活值从线性空间映射至对数空间,其分布更趋均匀。
- 具体实现:对于大小的数据块,先取绝对值并计算各元素对数,确定最小值和最大值。最小值编码为,最大值编码为,步长。零值特例采用表示,其余值则四舍五入为最接近的步长整数倍。解码过程仅需结合符号位与公式即可完成。通过本地计算最小值和步长,该数据类型支持为不同区块动态调整表示范围,相较于静态浮点格式,既能覆盖更大区间又可提供更高精度。
- 此外,为实现对激活值的无偏量化,必须在原始线性空间而非对数空间执行舍入操作。同时将最小值约束为大于,这意味着最大表示范围与5位指数浮点格式E5相当。
- 在约7B参数的稠密语言模型上验证LogFMT-nBit,通过量化残差分支输出来模拟MoE模型中的
combine阶段。当(与FP8位数相同)时,LogFMT-8Bit展现出优于E4M3和E5M2的训练精度。将增至10位后,其表现与BF16combine阶段相当。
- 硬件限制与改进建议:
- 现有问题:
- 编解码开销与兼容性限制:最初采用LogFMT格式的目的是将其应用于传输过程中的激活值或临近激活函数的区域,然而后续计算需将其重新转换为BF16或FP8以适应Hopper GPU张量核心的数据类型。由于GPU在日志/指数运算时带宽不足,且编码/解码过程会产生过高的寄存器压力,若将编解码操作与all-to-all通信融合执行,其开销将非常显著(延迟增加50%∼100%)。
- 未来硬件建议:为FP8或自定义精度格式量身定制的压缩与解压缩单元提供原生支持,降低通信带宽需求(其减少的通信开销在混合专家模型训练等带宽密集型任务中尤为重要)。
- 现有问题:
Interconnection Driven Design
Current Hardware Architecture
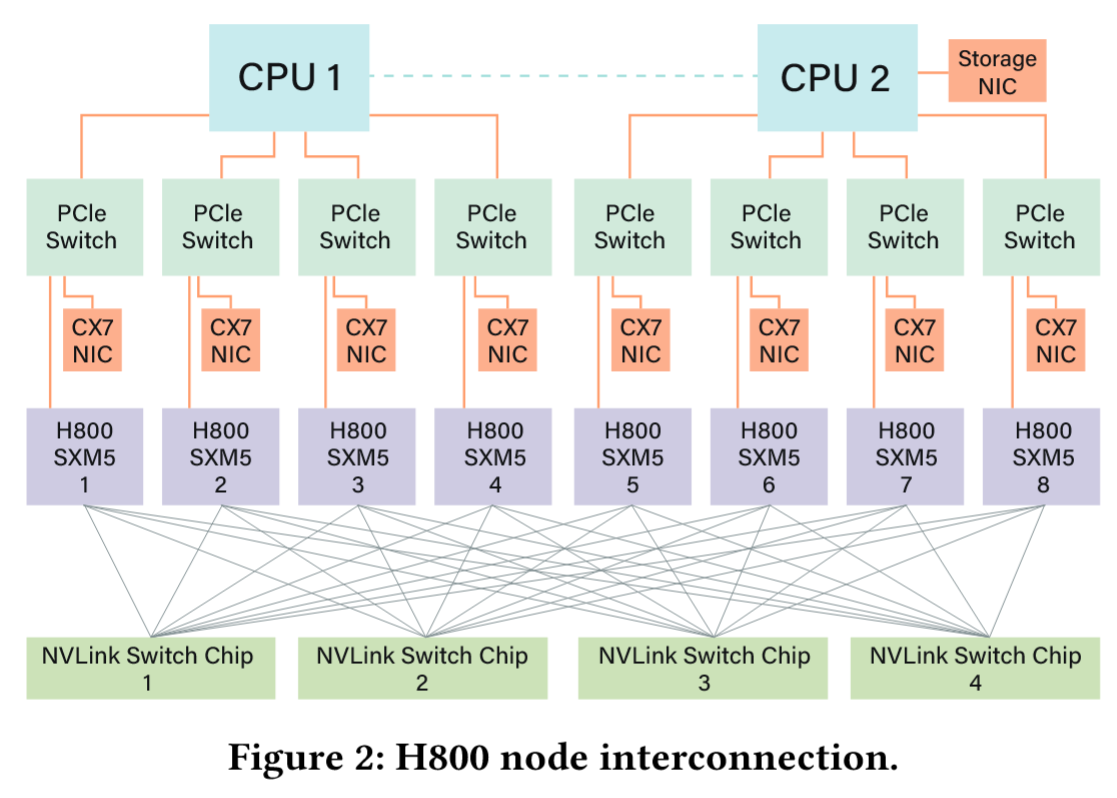 当前采用的 NVIDIA H800 GPU SXM 架构基于与 H100 GPU 相同的 Hopper 架构,但为符合美团的监管要求降低了 FP64 计算性能与 NVLink 带宽。具体而言,H800 SXM 节点的 NVLink 带宽从 900 GB/s 缩减至 400 GB/s。这种节点内 Scale-up 带宽的大幅削减对高性能工作负载构成挑战。为此,每个节点配置了八块 400G Infiniband CX7 网卡,通过增强 Scale-Out 能力来弥补带宽不足。
当前采用的 NVIDIA H800 GPU SXM 架构基于与 H100 GPU 相同的 Hopper 架构,但为符合美团的监管要求降低了 FP64 计算性能与 NVLink 带宽。具体而言,H800 SXM 节点的 NVLink 带宽从 900 GB/s 缩减至 400 GB/s。这种节点内 Scale-up 带宽的大幅削减对高性能工作负载构成挑战。为此,每个节点配置了八块 400G Infiniband CX7 网卡,通过增强 Scale-Out 能力来弥补带宽不足。
针对这些硬件限制,DeepSeek-V3 模型采用了多项与硬件特性及约束相匹配的设计考量:
Hardware-Aware Parallelism
为适配 H800 架构的限制,采用以下并行策略优化 DeepSeek-V3 的性能:
- 避免TP:
- 训练阶段因 NVLink 带宽限制导致的低效问题而避免使用 TP,但在推理阶段仍可选择性启用以降低延迟并提升 TPOT 性能、降低延迟。
- 增强PP:
- 采用 DualPipe 技术实现注意力计算、MoE 计算与 MoE 通信的重叠执行,有效减少流水线气泡并均衡 GPU 间内存使用,从而提升整体吞吐量。具体实现详见 DeepSeek V3 Technical Report。
- 加速EP:
- 利用8个400Gbps IB网卡实现高带宽(40GB/s)高效All-to-All通信,并且利用DeepEP优化EP性能。
Model Co-Design: Node-Limited Routing
核心思想:为平衡并充分利用更高的节点内带宽,模型架构与硬件需要协同设计,尤其体现在 TopK 专家选择策略中。
H800 架构中节点内Scale-up与节点间Scale-out通信的带宽差异约为4:1——具体而言,NVLink 提供 200GB/s 带宽(实际可达约 160GB/s),而每张 400Gbps IB 网卡仅能提供 50GB/s 带宽(考虑小消息尺寸和延迟影响,实际有效带宽按 40GB/s 计算)。
假设一个 8 节点(共 64 块 GPU)、256 个路由专家(每 GPU 承载 4 专家)的部署场景。在 DeepSeek-V3 中,每个 token 会被路由至 1 个共享专家和 8 个路由专家。若其 8 个目标专家分布在全部 8 个节点上,则 IB 通信时间为 ( 表示单个 token 通过 IB 传输的耗时)。但通过利用更高带宽的 NVLink,路由至同一节点的 token 可先经 IB 传输一次,再通过 NVLink 转发至节点内其他 GPU。这种 NVLink 转发机制能消除重复的 IB 流量。当某 token 的目标专家分布在 个节点时,去重后的 IB 通信成本将降至 ()。
鉴于 IB 流量仅取决于 值,DeepSeek-V3 在 TopK 专家选择策略中引入了节点受限路由机制:将 256 个路由专家划分为 8 组(每组 32 专家),每组部署于单一节点,并通过算法确保每个 token 最多被路由至 4 个节点,减少跨节点IB流量。该方法有效缓解了 IB 通信瓶颈,提升了训练过程中的有效通信带宽。
Scale-Up and Scale-Out Convergence
实际应用中,GPU 流式多处理器
当前问题:
- kernel 复杂度:虽然上一节的 Node-Limited Routing 策略降低了通信带宽需求,但由于节点内NVLink与节点间IB互连带宽的差异,该策略增加了通信流水线 CUDA kernel 实现的复杂性。
- SM资源占用:GPU SM 的线程需同时处理网络消息(如填充 QP 和 WQE)及通过 NVLink 进行数据转发,这会消耗一定计算资源——例如在训练过程中,H800 GPU 上多达 20 个 SM 被分配用于通信相关操作,导致可用于实际计算的资源减少。为最大化在线推理吞吐量,需要完全通过网卡 RDMA 操作执行端点间 EP all-to-all 通信,避免 SM 资源争用并提升计算效率。这凸显了 RDMA 异步通信模型在重叠计算与通信方面的优势。
以下是 SM 在 EP 通信过程中当前执行的关键任务,特别是针对 combine 阶段的 reduce 操作与数据类型转换,将这些任务卸载至专用通信硬件可释放 SM 的计算内核资源,从而显著提升整体效率:
- 数据转发:在 InfiniBand 与 NVLink 域之间聚合同一节点内多块 GPU 的 IB 流量。
- 数据传输:在 RDMA 缓冲区(已注册的 GPU 内存区域)与输入/输出缓冲区之间移动数据。
- 归约操作:执行 EP all-to-all
combine通信所需的归约运算。 - 内存布局管理:处理跨 IB 与 NVLink 域的块数据传输所需的细粒度内存布局。
- 数据类型转换:在all-to-all通信前后执行数据类型转换。
硬件改进建议:将节点间(scale-out)通信与节点内(scale-up)通信整合至统一框架
- 统一网络适配器:
- 设计支持Scale-Up与Scale-Out统一编址的NIC或I/O Die,同时这些适配器支持基础交换功能,能够将Scale-out网络的数据包转发至Scale-up网络内的特定GPU。可以通过LID或基于策略路由的IP地址实现。
- 一些新兴的协议如Ultra Ethernet Consortium(UEC)、Ultra Accelerated Networking(UAN)支持在单个物理链路上同时传输NVLink和IB流量,从而实现Scale-Up与Scale-Out的统一编址;华为提出的Unified Bus及 UB-Mesh 技术则从统一所有接口的视角出发予以实现。
- 专用通信协处理器:
- 在I/O Die集成专用的协处理器或可编程组件来处理网络流量,实现 NVLink 和 IB 域间的无缝流量转发,并且从SM中卸载数据转发、归约操作和类型转换任务,释放计算资源。同时还能包含硬件加速的内存拷贝功能,以实现高效的缓冲区管理。达到降低软件复杂度并最大化带宽利用率的目的。
- 例如,DeepSeek-V3采用的节点受限路由策略,可通过硬件支持的动态流量去重功能进一步优化。
- 灵活转发、广播、规约机制:
- 硬件应在Scale-Up与Scale-Out网络中均能支持灵活的转发、广播操作(用于EP分发)及归约操作(用于EP合并),这与DeepSeek团队当前基于GPU SM的实现方式相呼应。此举不仅能提升有效带宽,还可降低网络专用操作的计算复杂度。
- 硬件同步原语:
- 提供细粒度的硬件同步指令以处理内存一致性问题或硬件层面的乱序数据包到达问题,消除对软件层面同步机制(如RDMA完成事件)的需求——此类机制会引入额外延迟并增加编程复杂性。
- 例如,采用acquire/release机制的内存语义通信方案。
Bandwidth Contention and Latency
当前瓶颈:
- PCIe带宽争用:当前硬件缺乏在NVLink和PCIe上动态分配不同类型流量带宽的灵活性。例如在推理过程中,将KVcache数据从CPU内存传输至GPU可能消耗数十GB/s的带宽,导致PCIe通道饱和,若GPU此时还需通过IB网络进行EP通信,KVcache传输与EP通信之间的资源争用将降低整体性能并引发延迟激增。
- IB延迟敏感:EP的All-to-All通信对微秒级延迟敏感,需低延迟网络支持。
硬件改进建议:
- 动态流量优先级:
- 硬件支持按流量类型(EP、TP、KVcache)动态分配NVLink/PCIe带宽优先级。对于PCIe而言,向用户级编程暴露流量类别(TC)即可满足需求。
- I/O Die集成:
- 将NIC直接集成至I/O Die并与计算核心通过同封装互联,而非PCIe通道连接,以避免PCIe瓶颈、提升吞吐并降低延迟。
- CPU-GPU在Scale-Up网络中直连:
- 采用NVLink或类似的专用高带宽互联技术替代PCIe连接CPU与GPU,该方法可显著提升训练和推理过程中GPU-CPU内存间参数卸载或KVcache传输等场景的性能。
Large Scale Network Driven Design
Network Co-Design: Multi-Plane Fat-Tree
-
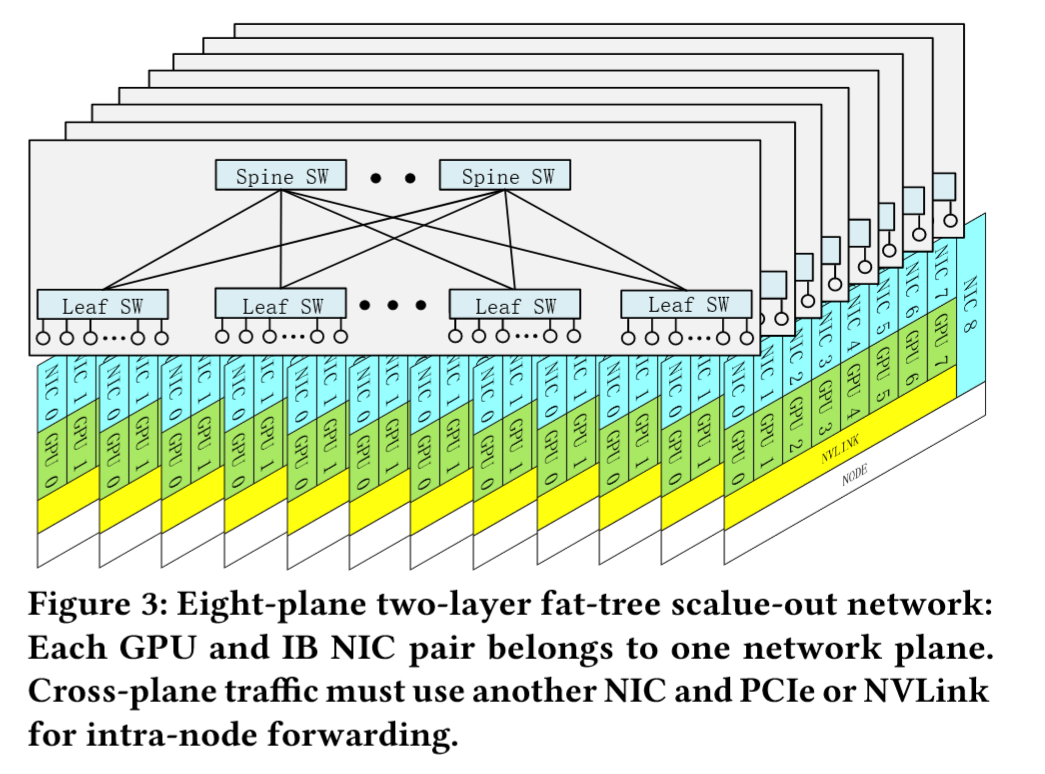
多平面两层Fat-Tree(MPFT)架构:DeepSeek-V3的训练过程中部署了如图所示的多平面胖树(MPFT)Scale-Out 网络架构
- 设计:每个计算节点配备八块 GPU 与八张 IB 网卡,每个GPU-NIC对分配至独立网络平面(共8平面),结合 400Gbps 的RoCE 网卡接入独立的存储网络平面以访问 3FS 分布式文件系统。
- 扩展性:Scale-Out 网络采用 64 端口 400G 的 IB 交换机搭建,理论上支持16,384 GPU的超大规模集群(实际部署受政策限制为2,000+ GPU)。
-
多平面网络的特点:
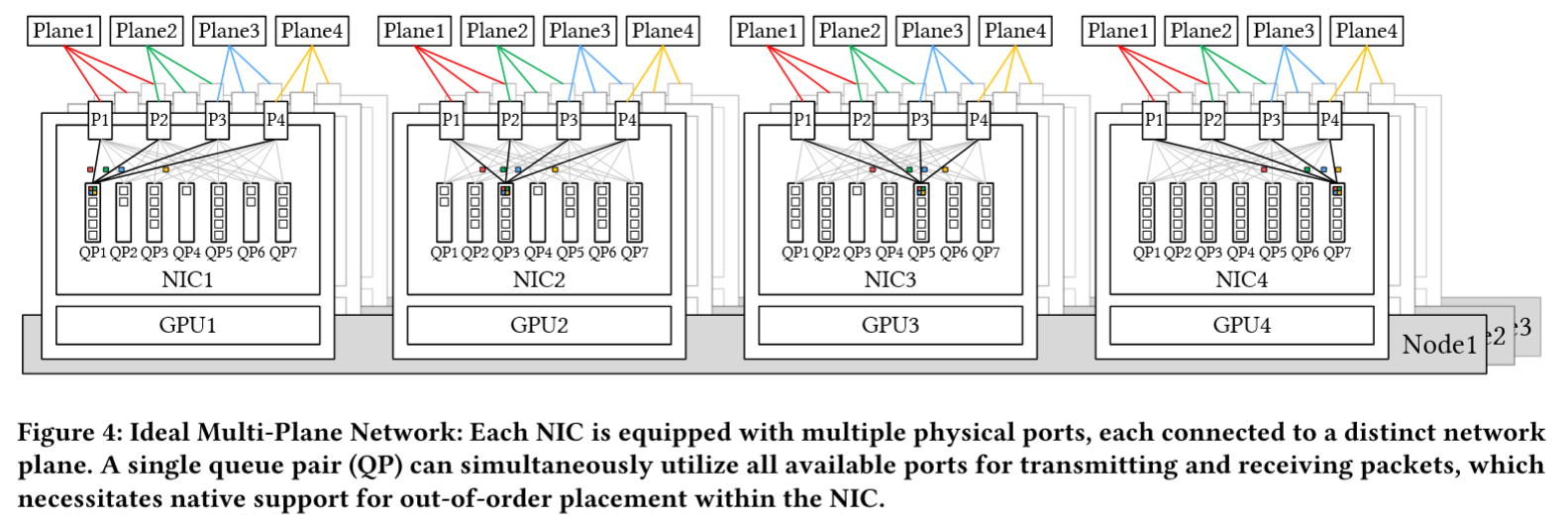 当前受限于IB ConnectX-7的技术约束,已部署的MPFT网络尚未完全实现理想架构。
当前受限于IB ConnectX-7的技术约束,已部署的MPFT网络尚未完全实现理想架构。- 流量隔离:理想状态下应如 Fig 4 所示,每张网卡具备多个物理端口,各端口分别连接不同网络平面,同时通过端口绑定技术向用户呈现为单一逻辑接口,每个平面独立运行,确保一个平面的拥塞不会影响其他平面。这种隔离机制提升了整体网络的稳定性,并防止性能的级联下降。
- 对支持乱序数据包和多平面功能的网卡的需求:从用户视角看,单个队列对(QP)可无缝跨所有可用端口收发消息,类似 packet spraying 机制,因此源自同一QP的数据包可能经由不同网络路径传输,导致接收端出现乱序,这就要求网卡原生支持乱序排列功能以确保消息一致性及正确的顺序语义。例如InfiniBand ConnectX-8已原生支持四平面架构。未来网卡若能完整支持先进的多平面功能,将推动双层胖树网络有效扩展至更大规模AI集群4。
- 兼容性/扩展性良好:MPFT 是Multi-Rail Fat-Tree的特例,因此NVIDIA和NCCL为多轨道网络开发的现有优化方案可直接应用于多平面网络部署场景。
- 成本优势:
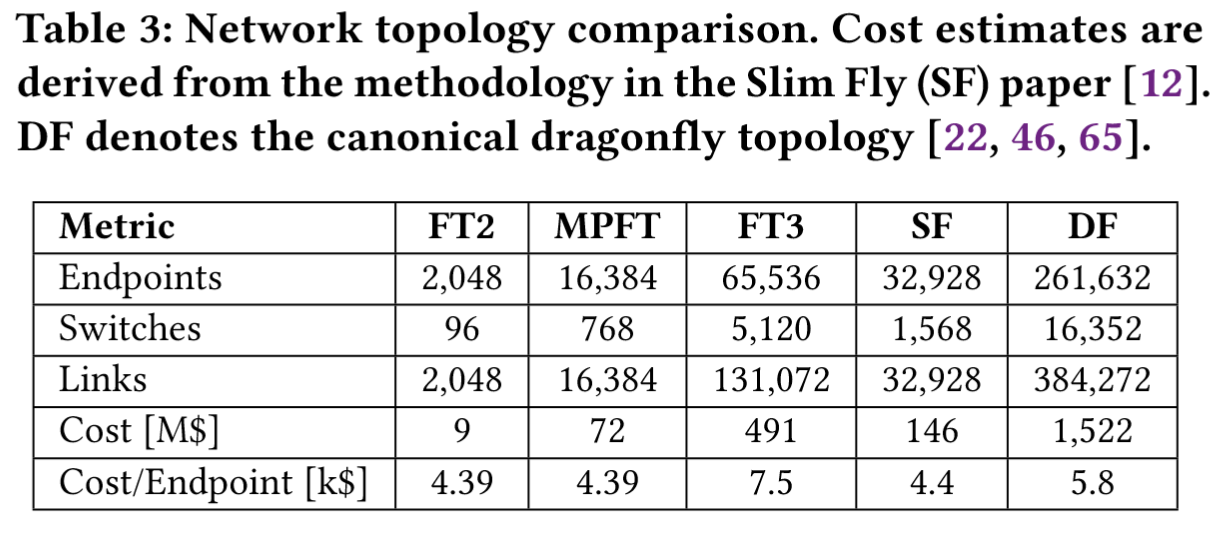 双层胖树(FT2)结构可以支持超过 1w 个断电,相比传统FT3 的每端点成本降低41%(),接近Slim Fly拓扑()。
双层胖树(FT2)结构可以支持超过 1w 个断电,相比传统FT3 的每端点成本降低41%(),接近Slim Fly拓扑()。 - 延迟更低、负载均衡性能更好:双层胖树延迟更低,且哈希聚集/冲突问题更小(这个可以在 Alibaba HPN 这篇文章中找到解答),因此特别适用于对延迟敏感的应用场景,例如MoE模型的训练与推理。
- 鲁棒性:多端口网卡提供多个上行链路,因此单端口故障不会中断连接,并能实现快速透明的故障恢复。
-
性能对比分析:MP 2Layer FT vs. Single-Plane Multi-Rail FT
- All2All 与 EP 通信场景:
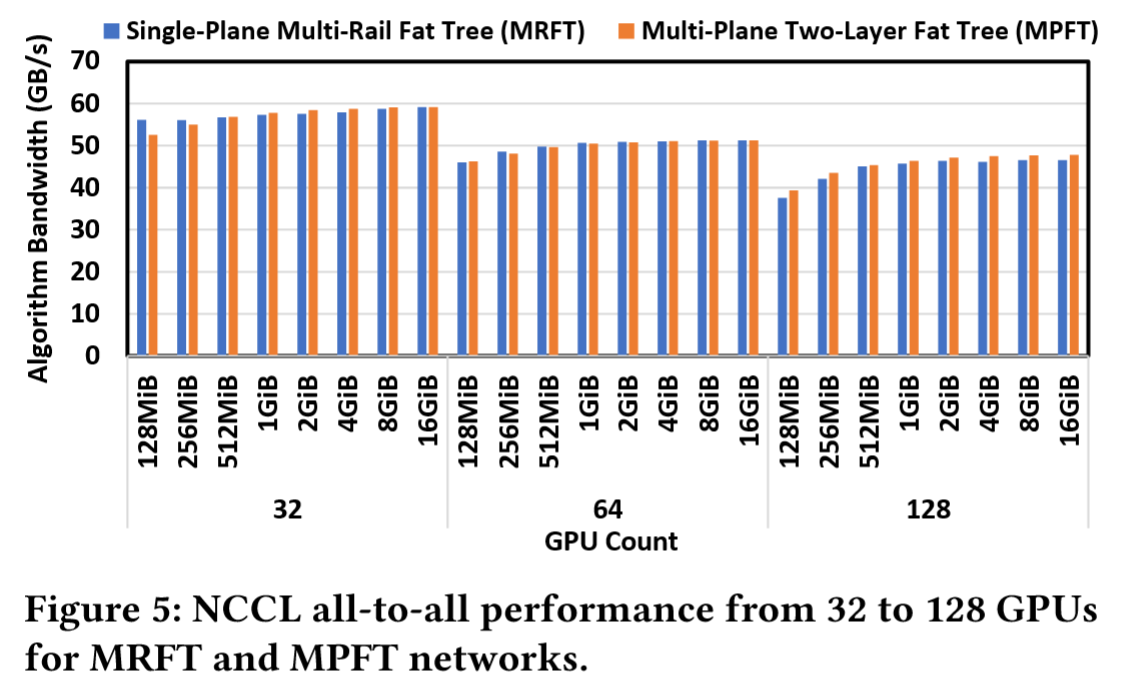 如图5所示,MPFT的All-to-All性能与MRFT高度相似。这种性能一致性可归因于NCCL的PXN机制,该机制通过NVLink在多轨道拓扑中优化流量转发。多平面拓扑同样受益于此机制。
如图5所示,MPFT的All-to-All性能与MRFT高度相似。这种性能一致性可归因于NCCL的PXN机制,该机制通过NVLink在多轨道拓扑中优化流量转发。多平面拓扑同样受益于此机制。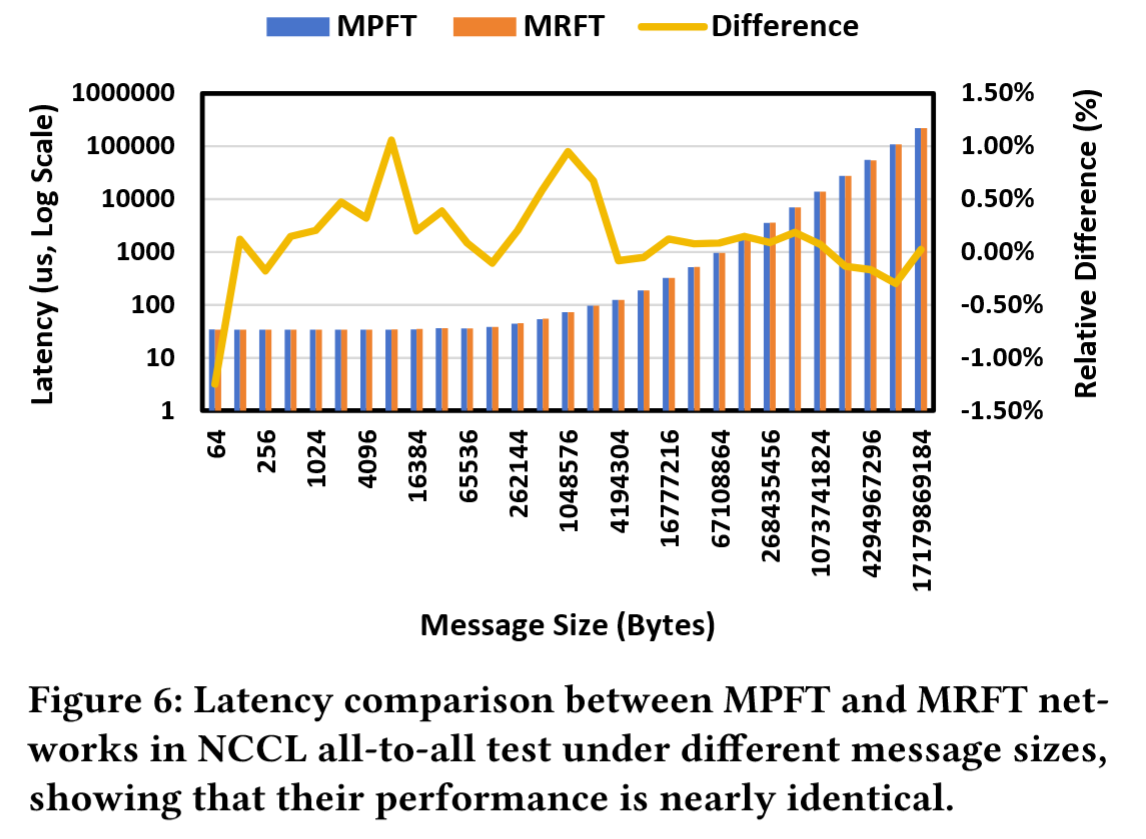 图6展示了16块GPU上All-to-All通信测试结果,MPFT与MRFT拓扑的延迟差异可忽略不计。
图6展示了16块GPU上All-to-All通信测试结果,MPFT与MRFT拓扑的延迟差异可忽略不计。- 为评估MPFT在实际训练场景中的All-to-All通信性能,测试了训练过程中常用的EP通信模式。
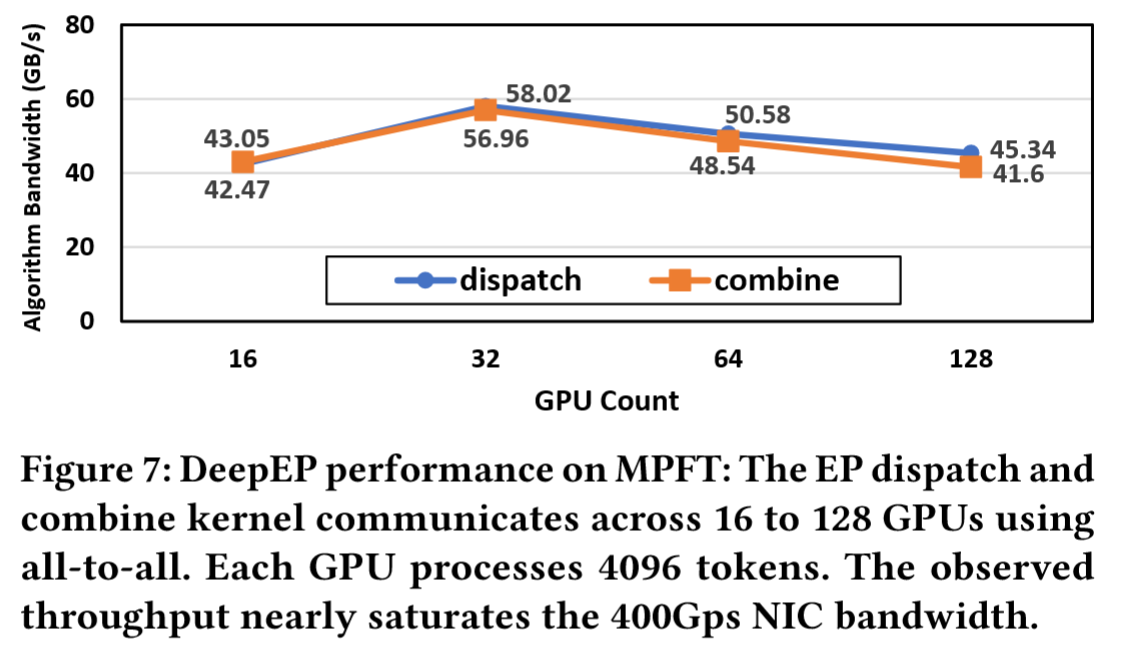 图7表明,在多平面网络中每块GPU均可实现超过40GB/s的高带宽,为训练任务提供了可靠的性能保障。
图7表明,在多平面网络中每块GPU均可实现超过40GB/s的高带宽,为训练任务提供了可靠的性能保障。
- DeepSeek V3 训练时的吞吐:
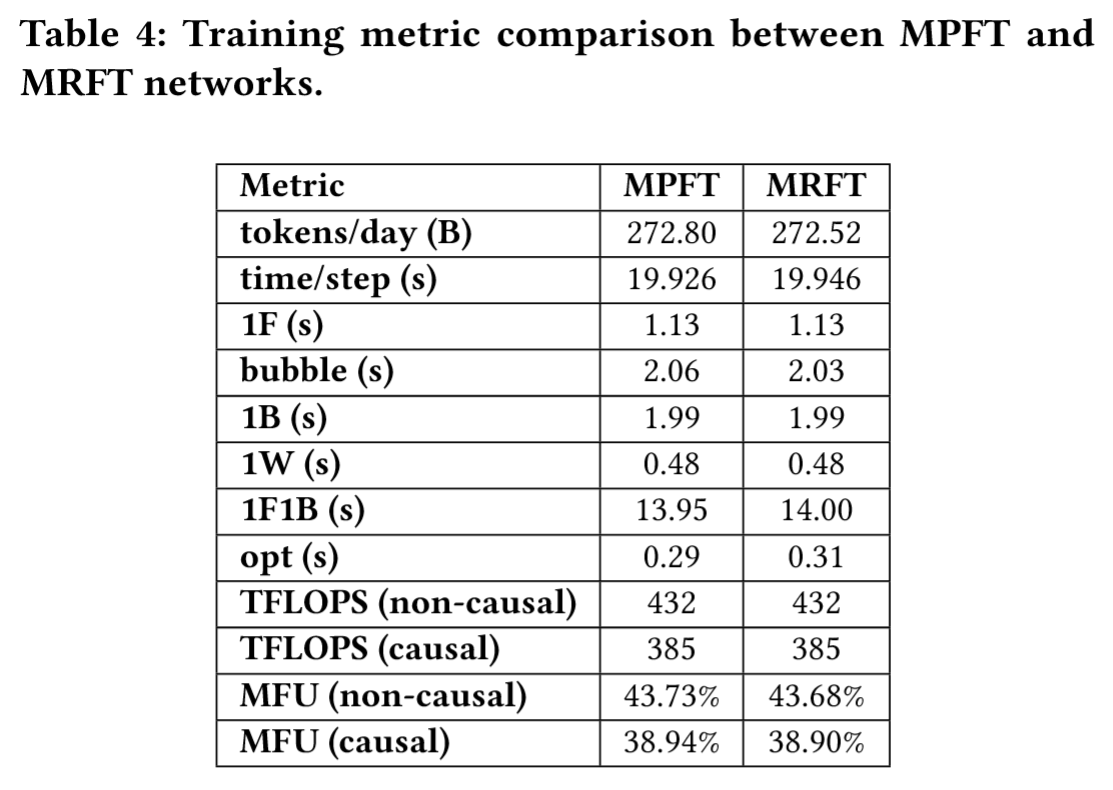 表4中对比了DeepSeek-V3模型在MPFT与MRFT模式下的训练指标。MFU(模型浮点运算利用率)基于BF16峰值性能计算得出:因果MFU仅考虑注意力矩阵下三角部分的浮点运算(与FlashAttention一致),非因果MFU则计入整个注意力矩阵的运算量(与Megatron方案一致)。1F、1B和1W分别表示前向时间、输入反向传播时间和权重反向传播时间。当在2048块GPU上训练V3模型时,MPFT与MRFT的性能表现近乎一致,观测差异均处于正常波动与测量误差范围内。
表4中对比了DeepSeek-V3模型在MPFT与MRFT模式下的训练指标。MFU(模型浮点运算利用率)基于BF16峰值性能计算得出:因果MFU仅考虑注意力矩阵下三角部分的浮点运算(与FlashAttention一致),非因果MFU则计入整个注意力矩阵的运算量(与Megatron方案一致)。1F、1B和1W分别表示前向时间、输入反向传播时间和权重反向传播时间。当在2048块GPU上训练V3模型时,MPFT与MRFT的性能表现近乎一致,观测差异均处于正常波动与测量误差范围内。
- All2All 与 EP 通信场景:
Low Latency Networks
核心挑战:模型推理中,大规模EP的All-to-All通信对微秒级延迟敏感(如 2.3.2节中的讨论,在 50GB/s 带宽的网络中数据传输的延迟接近 120μs),因此需优化网络协议与硬件。
- InfiniBand vs RoCE:
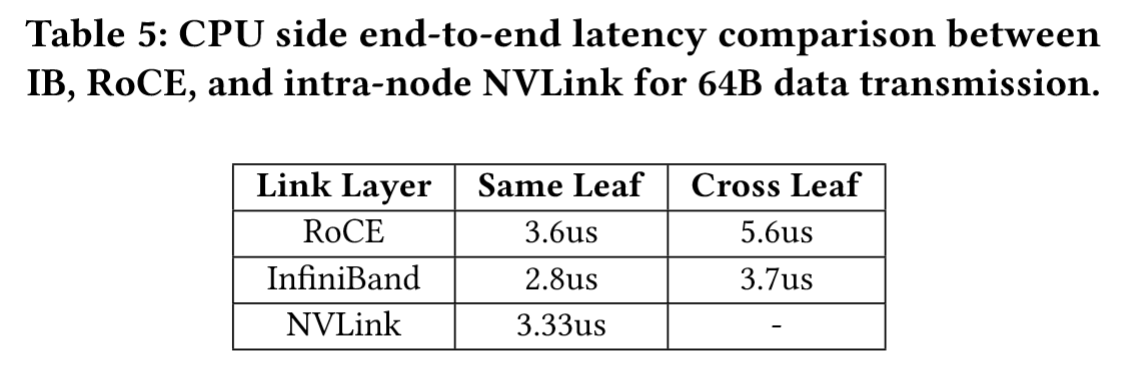
- IB优势:无论相同叶节点还是跨叶节点,延迟都比 RoCE更低,更适合EP通信。
- IB 劣势:
- 更贵:需要专门的硬件支持,例如InfiniBand ConnectX-8网卡,比RoCE贵得多。
- 扩展性差:IB交换机是64端口,RoCE则是128端口,严重限制了大规模部署。
- RoCE改进建议:
- 专用低延迟RoCE交换机:剥离冗余以太网功能,专门针对RDMA工作负载进行优化,参考Slingshot架构实现IB级延迟。还有博通公司新推出的包含AI转发头和低延迟以太网交换机的技术——为LLM定制的高性能以太网是可行的。
- 优化路由策略:
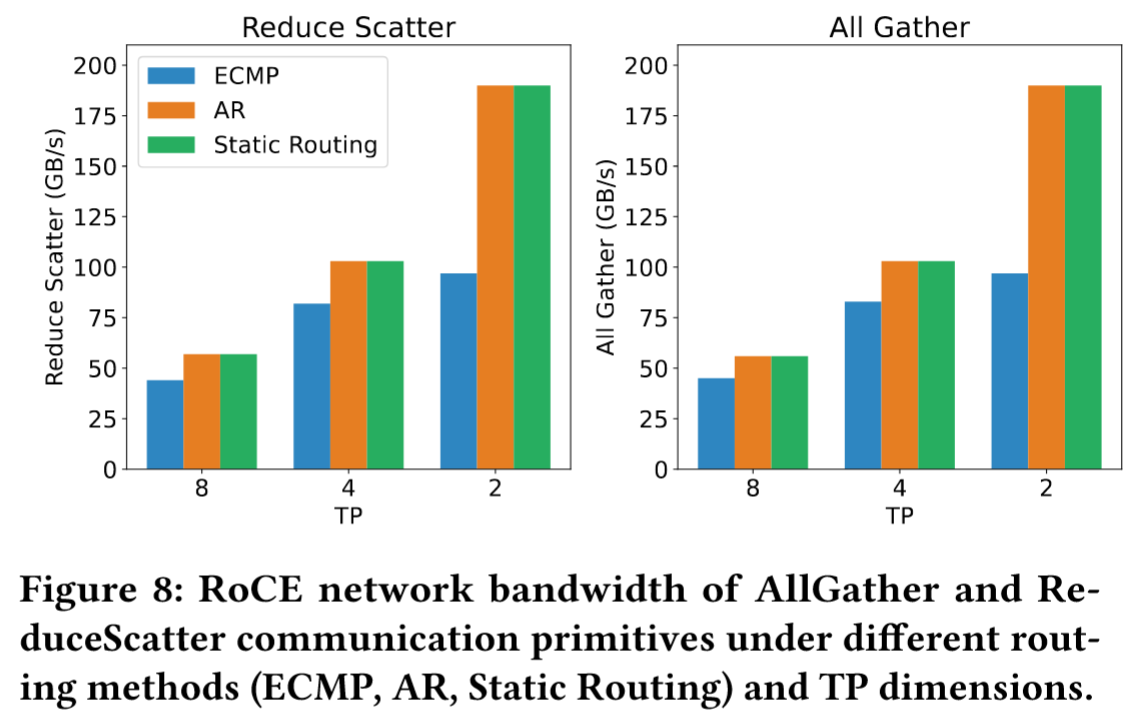 如图8所示,RoCE中默认的ECMP路由策略难以在互连链路上高效分配流量,导致NCCL集合通信测试中出现严重的拥塞性能下降。DP等LLM训练流量往往缺乏随机性,致使多股流汇聚到同一互连链路。相比之下,自适应路由(AR)通过动态将数据包分散到多条路径,可显著提升网络性能。虽然基于手动配置路由表的静态路由能避免特定目标地址的链路冲突,但缺乏灵活性。对于大规模全连接通信场景,自适应路由具备更优的性能与扩展性。动态路径选择缓解热点,提升All-to-All带宽。
如图8所示,RoCE中默认的ECMP路由策略难以在互连链路上高效分配流量,导致NCCL集合通信测试中出现严重的拥塞性能下降。DP等LLM训练流量往往缺乏随机性,致使多股流汇聚到同一互连链路。相比之下,自适应路由(AR)通过动态将数据包分散到多条路径,可显著提升网络性能。虽然基于手动配置路由表的静态路由能避免特定目标地址的链路冲突,但缺乏灵活性。对于大规模全连接通信场景,自适应路由具备更优的性能与扩展性。动态路径选择缓解热点,提升All-to-All带宽。 - 优化流量隔离和拥塞控制机制:当前RoCE交换机仅支持有限数量的优先级队列,这对于涉及EP allto-all和DP all-reduce等并发通信模式的复杂AI工作负载而言远远不足。在此类混合工作负载中,all-to-all流量可能因突发性多对一传输导致汇聚拥塞(incast congestion),进而影响整体网络性能。
- 为消除汇聚流对其他流量的干扰,一种解决方案是采用虚拟输出队列(VOQ),为每个QP分配专用虚拟队列以实现流量隔离。
- 另一种方案是部署更高效的拥塞控制机制,例如基于RTT的拥塞控制(RTTCC)或用户可编程拥塞控制(PCC),通过网卡与交换机的协同优化,在动态流量环境下维持低延迟与高吞吐。隔离流量类型(如EP All-to-All与DP All-Reduce),避免突发流量干扰。
- InfiniBand GPUDirect Async (IBGDA):
- 原理:传统上的GPU网络通信需要创建CPU代理线程——当GPU完成数据准备后,必须通知CPU代理,由后者填充工作请求(WR)的控制信息,并通过门铃机制通知NIC发起数据传输。这一过程会引入额外的通信开销。IBGDA则通过允许GPU直接填充WR内容并写入RDMA门铃MMIO地址来解决该问题。通过将整个控制平面交由GPU管理,IBGDA消除了GPU与CPU通信带来的显著延迟开销。此外,在发送大量小数据包时,控制平面处理器极易成为瓶颈。由于GPU具有多并行线程特性,发送方可利用这些线程分散工作负载,从而规避此类瓶颈。
- 效果:在DeepSeek团队提出的DeepEP采用IBGDA实现了显著的性能提升(接近线速400Gbps),降低小包通信的GPU-CPU交互开销。
Discussion and Insights for Future Hardware Architecture Design
Robustness Challenges
限制瓶颈:
- 互联故障:IB/NVLink间歇性断开导致通信中断(尤其在EP等高通信负载场景危害甚大),最终导致显著的性能下降或训练任务失败。
- 单硬件故障:节点崩溃、GPU故障或ECC(纠错码)内存错误可能危及长时间运行的训练任务,通常导致代价高昂的重启,此类故障的影响在大规模部署中尤为显著。
- 静默数据损坏:诸如multi-bit内存翻转或计算误差等未被ECC机制检测到的错误,对模型质量构成重大风险。这些错误在长时间运行的任务中尤为隐蔽,它们可能未被发现并持续传播,进而破坏下游计算。当前的缓解策略依赖于应用层启发式方法,但这还不足以确保系统整体的鲁棒性。
解决方案与建议:
- 基于校验和的验证技术或硬件加速的冗余检查等方法,可为大规模部署提供更高可靠性。
- 硬件供应商应向终端用户提供全面的诊断工具包,使其能够严格验证系统完整性并主动识别潜在的静默数据损坏。此类工具包作为标准硬件组件的内置部分,可增强透明度并支持在设备全生命周期内持续验证,从而全面提升系统可信度。
CPU Bottlenecks and Interconnects
CPU 在协调计算、管理 I/O 及维持系统吞吐量方面仍不可或缺。然而当前架构面临若干关键瓶颈:
- PCIe 瓶颈 :
- 前文已述,PCIe接口成为CPU与GPU间数据传输的带宽瓶颈,尤其在大规模参数、梯度或KVcache传输时。
- 为缓解此问题,未来系统应采用NVLink或Infinity Fabric等直连CPU-GPU互连方案,或将CPU与GPU集成至纵向扩展域,从而消除节点内瓶颈。
- 内存带宽瓶颈:
- 除PCIe限制外,维持如此高的数据传输速率还需极高的内存带宽——例如饱和160通道PCIe 5.0需单节点超640GB/s带宽,这意味着约1TB/s的单节点内存带宽需求,这对传统DRAM架构构成重大挑战。
- 单核 CPU 性能瓶颈:
- 内核启动和网络处理等延迟敏感型任务需要高单核CPU性能,通常要求基础频率超过4GHz。此外,现代AI负载要求每块GPU配备足量CPU核心以避免控制端瓶颈。对于基于小芯片的架构,还需额外核心支持缓存感知型工作负载分区与隔离。
Toward Intelligent Networks for AI
为满足时延敏感型工作负载的需求,未来互连技术必须同时兼顾低时延与智能网络两大核心特性:
- 共封装光学器件:采用硅光技术可实现更高带宽的可扩展性及能效提升,这两者对大规模分布式系统至关重要。
- 无损网络:基于信用的流量控制(CBFC)机制虽能确保无损传输,但简陋地触发流控会导致严重的队头(head-of-line)阻塞。因此必须部署先进的终端驱动拥塞控制算法,主动调节注入速率以避免病态拥塞。
- 自适应路由:如 第 5.2.2 节 强调,未来网络应标准化动态路由方案(如packet spraying和拥塞感知的路径选择),实时监测网络状态并智能调度流量。这类自适应策略对缓解集体通信(如all-to-all和reduce-scatter操作)中的热点与瓶颈尤为有效。
- 高效容错协议:通过自愈协议、冗余端口和快速故障转移技术可显著提升抗故障能力。例如链路层重试机制与选择性重传协议对保障大规模网络可靠性、降低停机时间、实现间歇性故障下的无缝运行不可或缺。
- 动态资源管理:为高效处理混合工作负载,未来硬件需支持动态带宽分配与流量优先级划分。例如在统一集群中将推理任务与训练流量隔离,确保时延敏感型应用的响应性。
Discussion on Memory-Semantic Communication and Ordering Issue
内存顺序与乱序包问题:
- 采用加载/存储内存语义的节点间通信兼具高效性与编程友好性,但现有实现方案受限于内存排序问题——例如,数据写入后,发送方必须显式插入内存屏障(fence)才能更新通知接收方的标志位,以此确保数据一致性。这种严格排序会引入额外的RTT时延,并可能阻塞发起线程,阻碍存储指令的流水线执行并降低吞吐量。
- 类似的乱序同步问题也存在于消息语义的RDMA中:在InfiniBand或NVIDIA BlueField-3上执行常规RDMA写入后,若采用packet spraying技术进行RDMA原子加操作,就会产生额外RTT延迟。
解决建议:通过硬件支持为内存语义通信提供内置的顺序保证。
- 这种一致性应在编程层面(如通过acquire/release语义)和接收端硬件层面同步实施,从而实现无开销的有序交付。
- 现有多种可行方案:
- 接收方可缓冲原子消息并采用数据包序号实现顺序处理,但acquire/release机制在优雅性与效率上更胜一筹。
- 区域acquire/release(RAR)机制,其核心在于接收端硬件通过位图追踪RNR内存区域状态,并将acquire/release操作限定在RAR地址范围内。该机制以极小的位图开销实现硬件强制的高效排序,既消除了发送端显式栅栏指令,又将排序任务委派给硬件(理想情况下由网卡或I/O芯片执行)。值得注意的是,RAR机制不仅适用于内存语义操作,还能优化消息语义RDMA原语,从而拓展其实际应用价值。
In-Network Computation and Compression
EP包含两个关键的全员通信阶段——分发(dispatch)与聚合(combine):
dispatch阶段类似于小规模多播操作,需将单条消息转发至多个目标设备。支持自动数据包复制及多目的地转发的硬件级协议可显著降低通信开销并提升效率。combine阶段作为小规模规约操作,可受益于网络内聚合技术。但由于EP聚合阶段规约范围小且工作负载不均衡,实现灵活的网络内聚合具有挑战性。
如 第3.2节 所述,LogFMT支持低精度token传输且对模型性能影响极小,将LogFMT原生集成至网络硬件中,可通过提高熵密度和降低带宽占用进一步优化通信。硬件加速的压缩与解压可实现LogFMT在分布式系统中的无缝集成,从而提升整体吞吐量。
Memory-Centric Innovations
内存带宽的局限性:模型规模的指数级增长已超越高带宽内存(HBM)技术的进步速度,这种差距形成了内存瓶颈,在Transformer等注意力密集型架构中尤为突出。
建议:
- DRAM堆叠加速器:利用先进的三维堆叠技术,可将DRAM芯片垂直集成于逻辑芯片之上,从而实现极高的内存带宽、超低延迟及实用内存容量(尽管受堆叠层数限制)。该架构范式对混合专家(MoE)模型的超高速推理极具优势——此类场景中内存吞吐是关键瓶颈。SeDRAM等架构展现了此方法的潜力,为内存受限型工作负载提供了突破性性能。
- 晶圆级系统(SoW):通过晶圆级集成技术,可最大化计算密度与内存带宽,满足超大规模模型的需求。
Footnotes
-
向量存储技术请看论文:SPFresh: Incremental In-Place Update for Billion-Scale Vector Search [SOSP’23] ↩
-
MLA 的数学细节请看:Understand MLA ↩
-
DeepSeek 的 DeepEP 和 DualPipe ↩
-
Alibaba HPN 架构的数据中心。 ↩