Introduction
大规模ML训练的挑战:核心矛盾是,ML 模型规模与复杂性激增(如 LLM),要求超算系统扩展节点规模以支持并行化训练(DP、TP、PP),系统高可用性 成为关键瓶颈。
-
并行化与资源可用性矛盾
- 静态资源分配的脆弱性:传统ML训练依赖编译时静态分片策略和集体调度(gang scheduling),要求所有计算资源同时健康,这在超大规模系统中难以保障(单点故障就会导致整个任务中断)。
- 硬件可靠性压力:现代大模型(如LLM)需要数千节点协同工作,导致系统MTBF(平均无故障时间)降至小时甚至分钟级别。
- 资源碎片化、征用与动态分配:共享集群环境中多用户竞争资源,静态互连架构难以动态调整资源分配,加剧碎片化问题。
-
现有系统的局限性
- TPUv3 等静态架构的缺陷:TPUv3 采用固定互连拓扑(如 32x32 环面),资源需物理连续且同时可用,导致可用性随规模急剧下降(如1024节点时可用性显著降低)。
TPUv4的硬件与软件组件:
-
硬件创新
- Cube单元:64个TPU芯片组成4x4x4 3D网格,64个Cube构成一个Pod(总计4096 TPU)。
- 专有片间互连(ICI):定制三维环面(Torus)网络,支持高带宽设备间直接通信网络,支持RDMA。
- 光路交换(OCS):用于动态交叉连接(xconnect)来自不同多维数据集的 ICI,通过动态光路切换(Optical Circuit Switching)以动态配置跨Cube的互连拓扑,支持灵活重构。
-
软件协同设计
- Borg调度系统:集群的全局资源调度与任务管理。
- Pod Manager:响应 Borg 的调度决策,协调OCS配置与健康监控,按需组合Cube形成用户指定拓扑。
libtpunet:为 TPUv4 用户作业配置ICI 网络拓扑和路由策略,支持容错与拓扑发现。healthd:Pod 中每一台主机都运行的守护进程,实时监控硬件健康,触发故障恢复。
本文贡献:
-
可配置系统架构:提出基于 OCS 的动态互连方案,通过SDN实现拓扑灵活重构,绕过故障节点/链路,显著提升系统可用性。
-
自动化软件栈设计:集成 Borg 调度、Pod Manager与
libtpunet,实现资源动态分配、拓扑配置与故障恢复的端到端自动化,最小化对运行中作业的影响。 -
容错路由优化:设计 accelerator-side 多跳 RDMA 路由算法,支持常规环面与扭曲环面拓扑上的弹性集体操作,绕过链路或交换机故障。
-
生产环境验证:通过 cube-粒度 的隔离故障(单个立方体故障仅影响局部资源),结合光路冗余与路由优化,TPUv4 在谷歌生产集群中实现99.98%可用性,支持数千任务每日动态重构,验证了软硬件协同设计的有效性。
The Reconfigurable ML Supercomputer System Architecture
TPUv4 的核心设计目标是解决大规模 ML 训练中可扩展性、可用性、弹性与成本的平衡问题,其核心是一个可重构的 ICI 结构拓扑,用于连接不同的 TPUv4 芯片,并为每个 pod 提供一组可编程的动态互联架构(OCS)的支持,通过SDN灵活组合物理分散的 Cube 单元,形成用户指定的拓扑(如 3D 环面或扭曲环面)。
相较于前代 TPUv3 的静态架构,TPUv4 的 OCS 重构能力显著提升了系统可用性(如 1024 节点时可用性从 TPUv3 的快速下降改善了 94%,在大概 50 cube 或 3200 TPUv4 时才会下降),同时通过容错路由进一步优化至 99.98%。
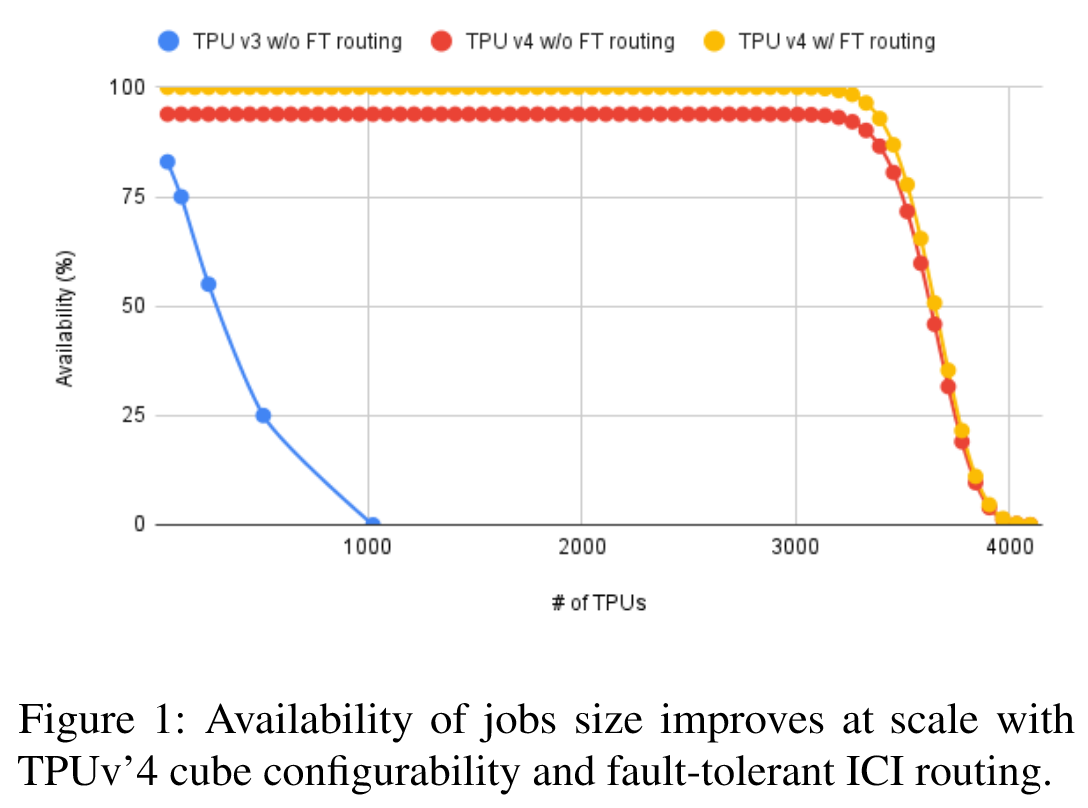
- 静态拓扑为什么不行?这是因为在静态pod中,一组连续节点中的所有资源必须同时处于正常状态才能分配给用户,随着系统的扩展,分配给用户的可能性会降低。
- 在未达到极限容量前的可用性下降的原因?超过这一点的可用性降低是因为不同多维数据集之间偶尔会发生机器和ICI链路故障。
2.1 静态 Pod 架构的教训
-
TPUv2/v3 的局限性
- 固定拓扑与资源碎片化:TPUv3 采用 32x32 环面等静态互连,要求资源物理连续且同时可用,导致大规模作业可用性急剧下降(如 1024 节点时需单节点 99.9% 可用性)。
- 多 Pod 扩展的瓶颈:TPUv3 尝试通过多 Pod 互联(如 4 Pod 组成 128x32 环面)提升规模,但受限于固定拓扑的扩展能力,无法动态绕过故障或碎片化资源。
- 部署与维护成本高:静态架构需硬件完全就绪后才可用,且维护事件(如硬件升级)需整体停机,导致资源利用率低。
-
核心问题
- 组合爆炸效应:作业规模扩大时,所有节点需同时健康的概率呈指数级下降。
- 资源分配僵化:无法动态整合非连续资源,加剧碎片化问题。
2.2 TPUv4 的 OCS 可重配置架构
-
硬件设计
- Cube 单元:64 个 TPU 芯片组成 4x4x4 3D 网格,每个 Pod 包含 64 个 Cube(总计 4096 TPU)。
- OCS 动态互连:通过 MEMS 光开关(切换时间毫秒级)连接 Cube 的 ICI 链路,支持非连续 Cube 组合为任意 3D 环面或扭曲环面拓扑。
- 分层连接模式:每个 Cube 的 6 个面暴露 16 条 ICI 链路,通过 48 个 OCS 按维度(X/Y/Z)分组建模,支持灵活跨 Cube 通信。
-
关键改进
- 资源灵活分配:Borg 调度无需物理连续性,通过 OCS 动态拼接可用 Cube,降低碎片化。
- 故障隔离:硬件故障仅影响单个 Cube(16 节点),隔离范围(blast radius)小。
- 成本优势:OCS 与光链路的资本与运营成本(<5% 总成本)显著低于传统包交换(如 Infiniband)。
-
挑战
- OCS 故障影响:单个 OCS 故障会中断其管理的所有链路,需依赖容错路由绕过(§4)。
2.3 可编程 ICI 协议栈
-
分层协议设计
- 物理层:光链路初始化与健康监控(由
healthd实现),支持链路级自动修复(如 SERDES 重训练)。 - 可靠数据层:提供有序、可靠传输(自动重传与流控),由
libtpunet管理会话启停与缓冲区优化。 - 路由层:静态转发表(由
libtpunet编程)实现全局负载均衡,支持多跳 RDMA 与容错路径。 - 事务层:编译器生成 RDMA 指令,硬件直接执行内存到 ICI 的数据传输。
- 物理层:光链路初始化与健康监控(由
-
软件协同优势
- 灵活路由策略:支持常规环面(DOR 路由)与扭曲环面(ILP 优化路径),适应不同拓扑需求。
- 在线维护能力:通过链路级隔离(drain)实现故障链路的在线修复,无需中断整体作业。
-
局限性
- 静态转发表限制:路由策略在作业启动时固定,无法动态响应运行时故障(需依赖作业重启或重调度)。
总结:TPUv4 通过 OCS 动态重构与分层 ICI 协议,解决了静态架构的资源碎片化与可用性瓶颈,同时以低成本实现高灵活性与容错能力,为超大规模 ML 训练提供了可扩展的硬件-软件协同解决方案。