Introduction
AI datacenters need to meet the following requirements
R1: Large Scale. LLM 训练需数万至数十万 NPU/GPU,如 LLAMA-3 需 16K GPU 训练 54 天,业界已部署 100K GPU 系统(xAI 的 Grok3),且 DCN 需支持持续扩展。
R2: High Bandwidth. AI 计算节点互联带宽需求超 3.2 Tbps/节点(10 倍于传统 CPU 集群),sota AI 训练系统的聚合带宽 10-100 倍于传统 CPU-based 的 IaaS 系统。
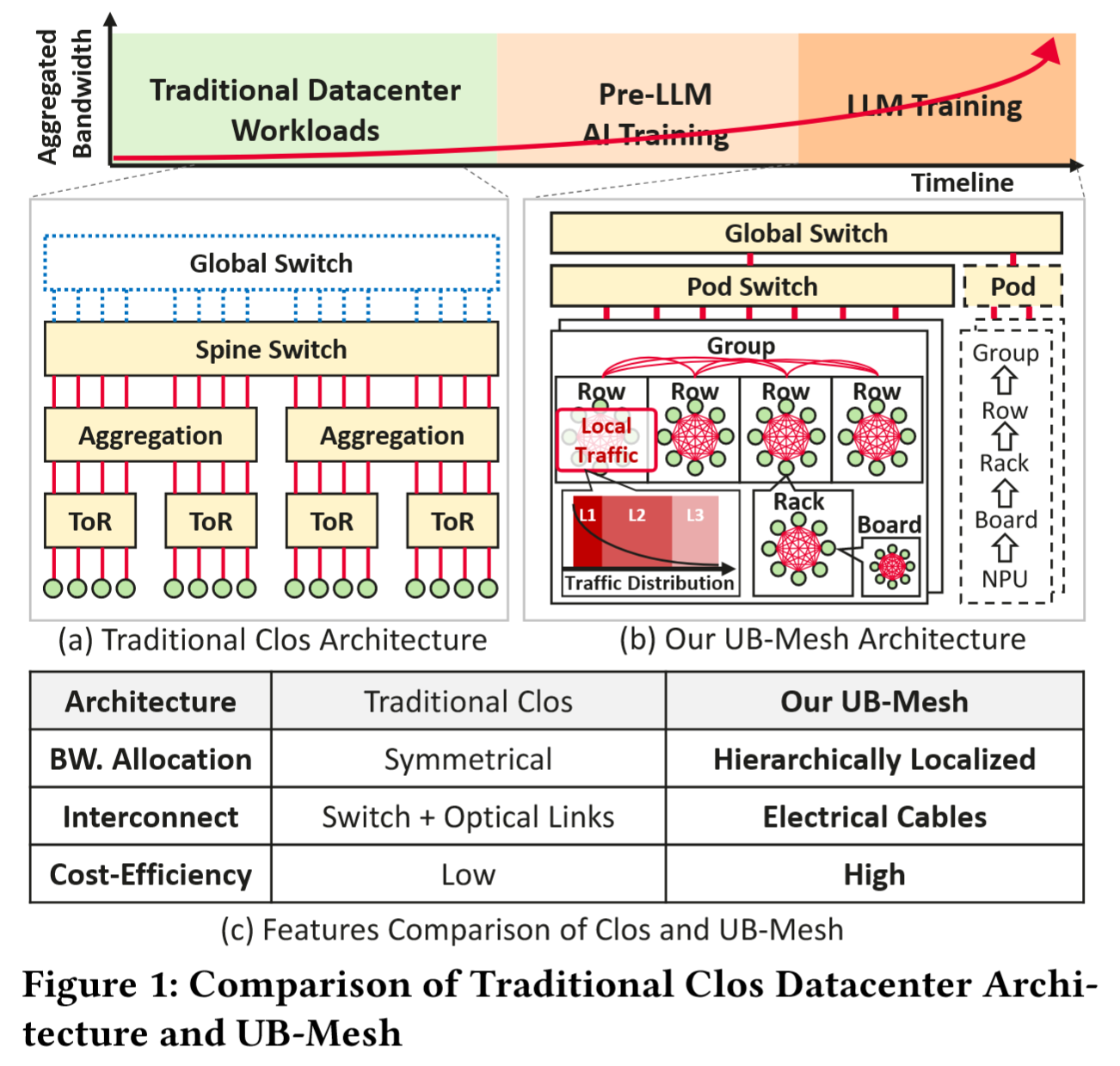 R3: Cost Effective. 传统 Clos 架构实现高带宽需 10-100 倍成本增长(与聚合互联带宽的增长规模相似),需优化网络架构降低 CapEx(硬件成本)与 OpEx(运维能耗)。
R3: Cost Effective. 传统 Clos 架构实现高带宽需 10-100 倍成本增长(与聚合互联带宽的增长规模相似),需优化网络架构降低 CapEx(硬件成本)与 OpEx(运维能耗)。
R4: High Availability. 100K 节点、1M 光模块的 LLM 训练集群 MTBF(平均故障间隔)低至 30 分钟(即使单个链路的 MTBF 为 5 年,整个集群的 MTBF 也会迅速下降到 30min),因此需硬件可靠性提升与容错机制(处理互联链路、计算资源、控制系统、存储中的故障)。
Three principles to design AI datacenters
要实现上述 4 个需求,需要对数据中心架构的设计进行范式级转变(paradigm shift),这里讨论 3 个设计原则。
P1: Traffic-Pattern Driven Network Topology. 传统数据中心负载产生的是统一、随机的数据流量,而 LLM 训练流量具有强局部性(如张量并行占 50%+流量,且多发生在 8 至 64 个相邻 NPU 组成的集群内部;数据并行仅 2%,却通常需要远距离传输),因此需分层、局部化网络架构更适配此类流量模式。
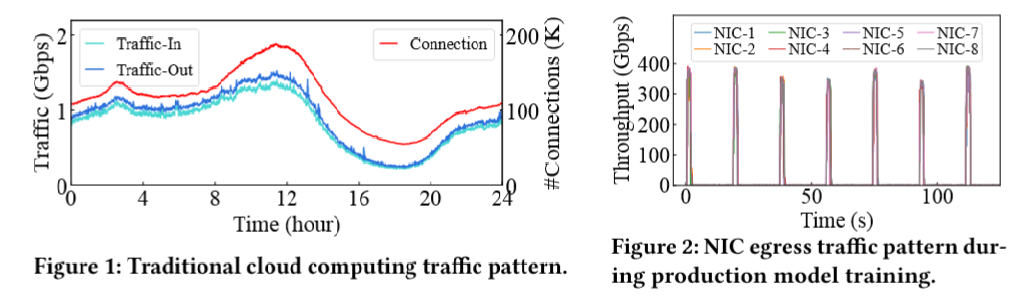 1
1
P2: Topology-Aware Computation&Communication. 若训练任务未在计算资源间实现最优分配,或网络系统未得到充分优化,AI 集群可能因流量拥塞或带宽利用率不足而性能降低。为此,并行策略、路由算法、负载均衡需与拓扑对齐。
P3: Self-Healing System for Fault-Tolerance. 链路/NPU 故障时自动切换路径或启用备份,保障系统完整性、训练连续性。
Innovative architecture: UB-Mesh
-
nD-FullMesh 拓扑:如 Fig1-(b) 所示,UB-Mesh 采用 nD-FullMesh 网络拓扑
- 层次化局部连接:1D(板内)、2D(机架内)、3D+(跨机架/楼层)递归全连接,减少通信传输的跳数、优化每跳的距离;更注重直连而不是间接连接和长范围交换,从而降低对交换机和光模块依赖(满足 R1、R3)。
- 分层带宽分配:短距离(电连接)高带宽、长距离(光连接)低带宽,适配 LLM 流量模式(满足 R2、R3,遵循 P1)。
-
硬件与系统优化:
- 统一总线(UB):集成 NPU、CPU、LRS/HRS 等模块,所有模块间的互联通过统一总线,从而支持灵活 IO 资源分配与通过 p2p 通信实现高效硬件池化,消除协议转换开销。
- 64+1 高可用设计:每机架配置 1 个备份 NPU,故障时无缝切换;链路故障时,路由系统通过直接通知(direct-notification)快速恢复(满足 R4,遵循 P3)。
- 全路径路由(APR):结合源路由、结构化寻址与线性表查找、无死锁流量控制来实现自适应路由,最小化转发开销和避免死锁,另外采用拓扑感知的快速故障恢复来加强可靠性,通过拓扑感知的集合通信和并行优化来最大化训练时带宽利用率( 支持非最短路径,满足 P2)。
- nD-FullMesh 拓扑:通过一套硬件组件(NPU、CPU、LRS、HRS、NICs 等)作为基础块,使得 UB-Mesh 能够平滑扩展至 8K 个 NPU,构建高带宽域的数据中心。
Background
”Communication Wall” in LLM Training
LLM 训练是迄今为止规模最大、计算与通信最密集的并行计算任务,模型参数和训练数据的持续扩展导致所需 NPU/GPU 数量激增(如 LLAMA-3 需 16K GPU 训练 54 天,Grok3 需 100K GPU)。
训练迭代中频繁的前向传播、反向传播、梯度同步操作需 NPU 间大量数据交换,数据移动成为系统主要瓶颈(“通信墙”)。分布式并行策略(如数据并行、模型并行)进一步加剧通信需求,集群规模扩大时通信延迟显著影响训练效率。
Locality of Data Traffic in LLM Training
不同并行策略产生差异化的通信模式与数据量:
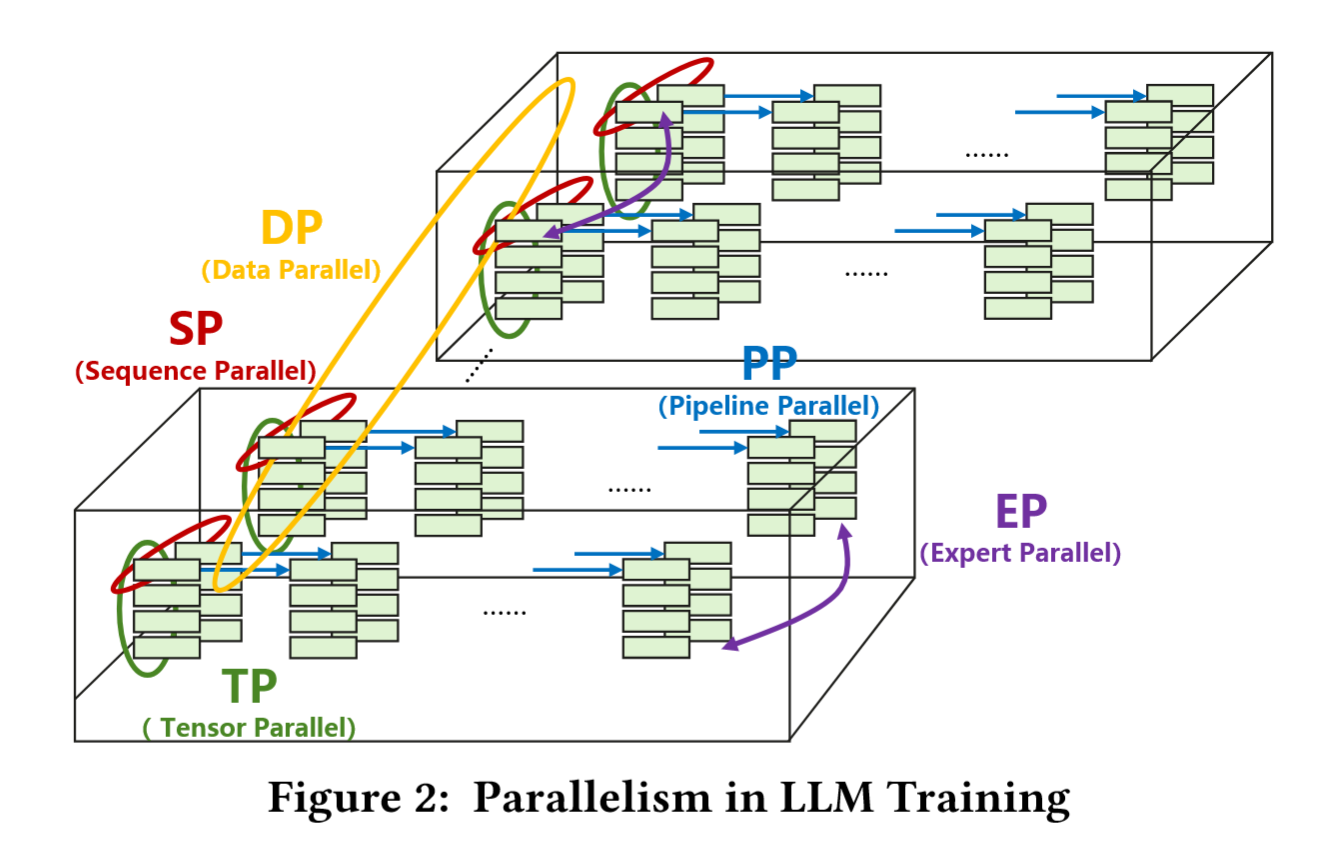
- Tensor Parallelism:TP 将模型层按行或列方向分割,并将子层置于多个并行计算的 NPU 上。其核心是通过
AllReduce操作合并分布式的部分计算结果。- 占 50%+总流量,通过
AllReduce在 8-64 个相邻 NPU 间同步。
- 占 50%+总流量,通过
- Sequence Parallelism:(部分文献中亦称 Context Parallelism)通常用于将序列分割至多个 NPU 上以实现并行处理。该技术依托 RingAttention 算法,可通过
AllGather操作聚合不同 NPU 上的部分计算结果。- 占 44%流量,通过
AllGather在局部 NPU 间聚合结果。
- 占 44%流量,通过
- Expert Parallelism:对于采用 MoE 技术的 LLM,稠密的 MLP 层被替换为 MoE 层,其中每层包含若干“专家”。专家在运算过程中被稀疏激活。EP 将专家分布在不同 NPU 上,输入 token 通过
All2All通信动态路由至目标专家。 - Pipeline Parallelism:与 TP 逐层拆分模型不同,PP 是将各层分配到多个设备上,以前后向流水线方式执行。PP 采用低开销的
P2P通信跨层传输激活值,但需依赖高效调度算法以减少流水线气泡。 - Data Parallelism:DP 在多个 NPU 间复制模型及优化器状态。每个副本并行处理输入 batch 的一部分数据。训练过程中需通过
AllReduce操作同步梯度。- 仅占 1.34%流量,需跨全局节点同步梯度。
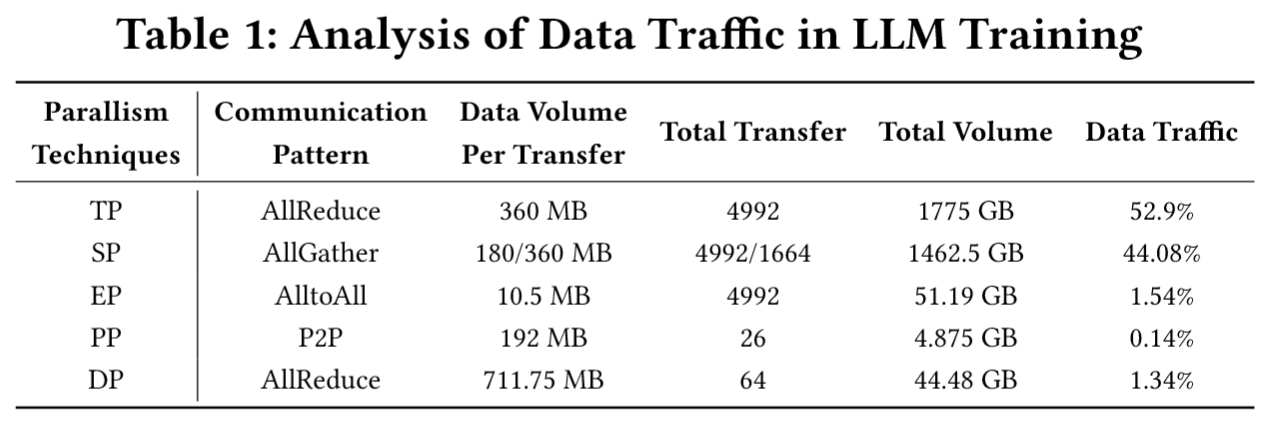 Table1 是基于 2T 参数的 MoE 模型测量而得,可以看到通信密集性是具有分层性质和强局部性的:TP 与 SP 占 97%流量,具有强局部性(短距离通信);DP、EP、PP 等跨节点通信占比低但需长距离传输。设计启示:网络架构需分层分配带宽,优先满足局部高带宽需求(如 TP/SP),而非全局对称带宽。
Table1 是基于 2T 参数的 MoE 模型测量而得,可以看到通信密集性是具有分层性质和强局部性的:TP 与 SP 占 97%流量,具有强局部性(短距离通信);DP、EP、PP 等跨节点通信占比低但需长距离传输。设计启示:网络架构需分层分配带宽,优先满足局部高带宽需求(如 TP/SP),而非全局对称带宽。
Other DCN Architectures
- Clos 架构:
- 特点:通过多层交换机对称连接节点,高性能地支持灵活流量模式。
- 问题:高带宽需求下需大量高端交换机与光模块,成本过高(网络设施占系统 CapEx 的 67%)。
- 3D Torus:
- 特点:相邻 NPU 之间直接连接,降低交换机依赖。
- 问题:NPU 间带宽低,难以支持复杂通信模式(如 MoE 模型的
All2All操作)。- 拓扑示例:
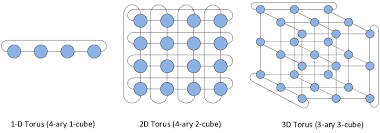
- 拓扑示例:
- Dragon-Fly:
- 特点:组内全直连,组间分组互联,通过间接路由降低成本。在传统 DCN 和 HPC 环境中精简了维度复杂性。
- 问题:仍需全带宽地 NPU-交换机 连接,成本仍高,且对
P2P/AllReduce的 LLM 训练流量场景中性能差。 - 拓扑示例:
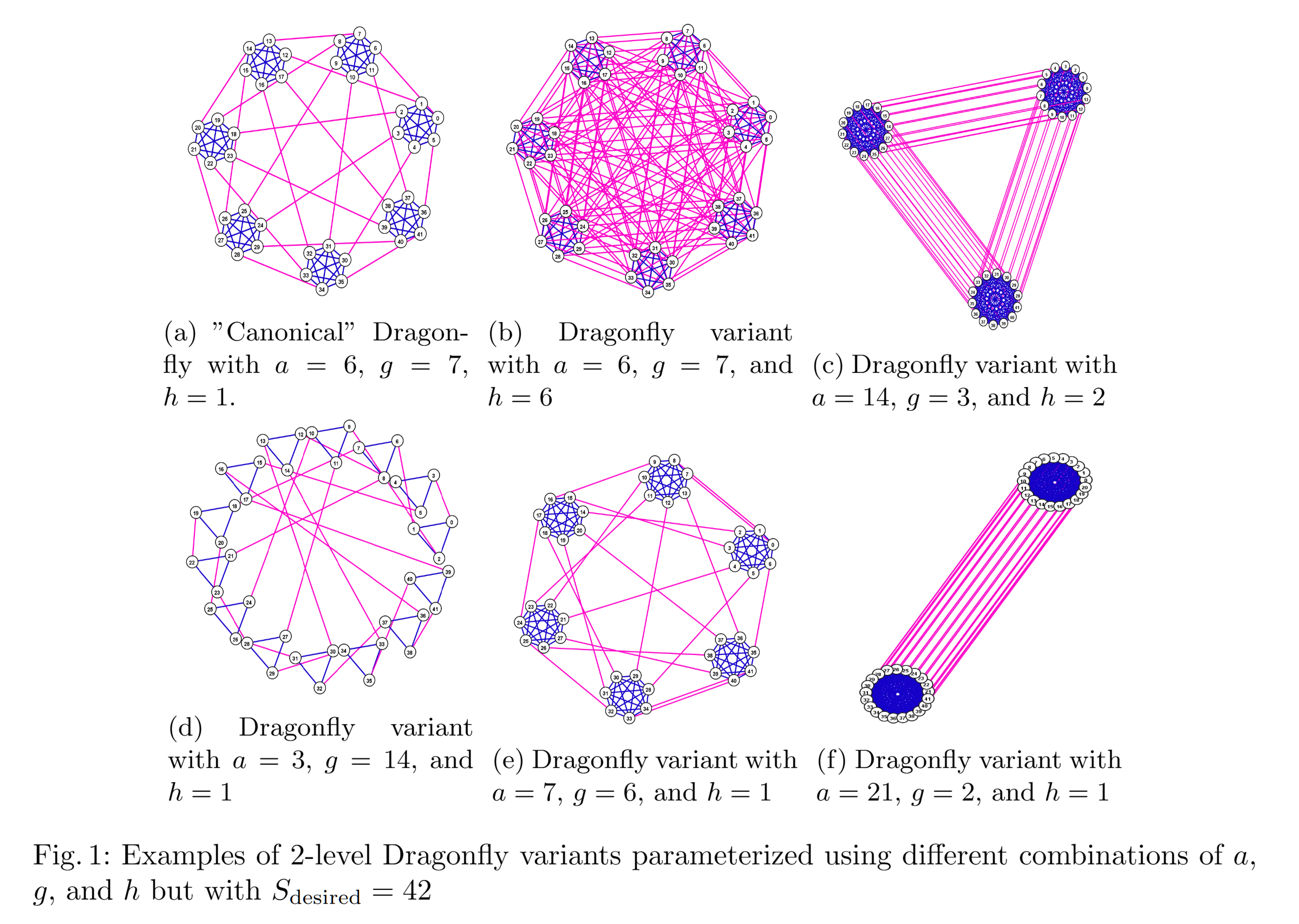
- Fugaku Tofu(6D Torus):
- 特点:高维环形拓扑,适配 HPC 应用。
- 问题:类似 3D Torus,NPU 间带宽不足且对 LLM 的复杂流量模式支持差。
UB-Mesh Architecture
The nD-FullMesh Topology
拓扑核心:递归式层次化全连接⭐——该拓扑结构始于相邻节点构建的一维全连接网络,其中每个节点均与同层所有其他节点直连。通过扩展这一概念,从 1D(板内 NPU 直连)、2D(机架内相邻 1D 全连接)、3D(跨机架)到 nD,逐层扩展全连接网络,优先使用电直连(短距离)而非光模块(长距离)。
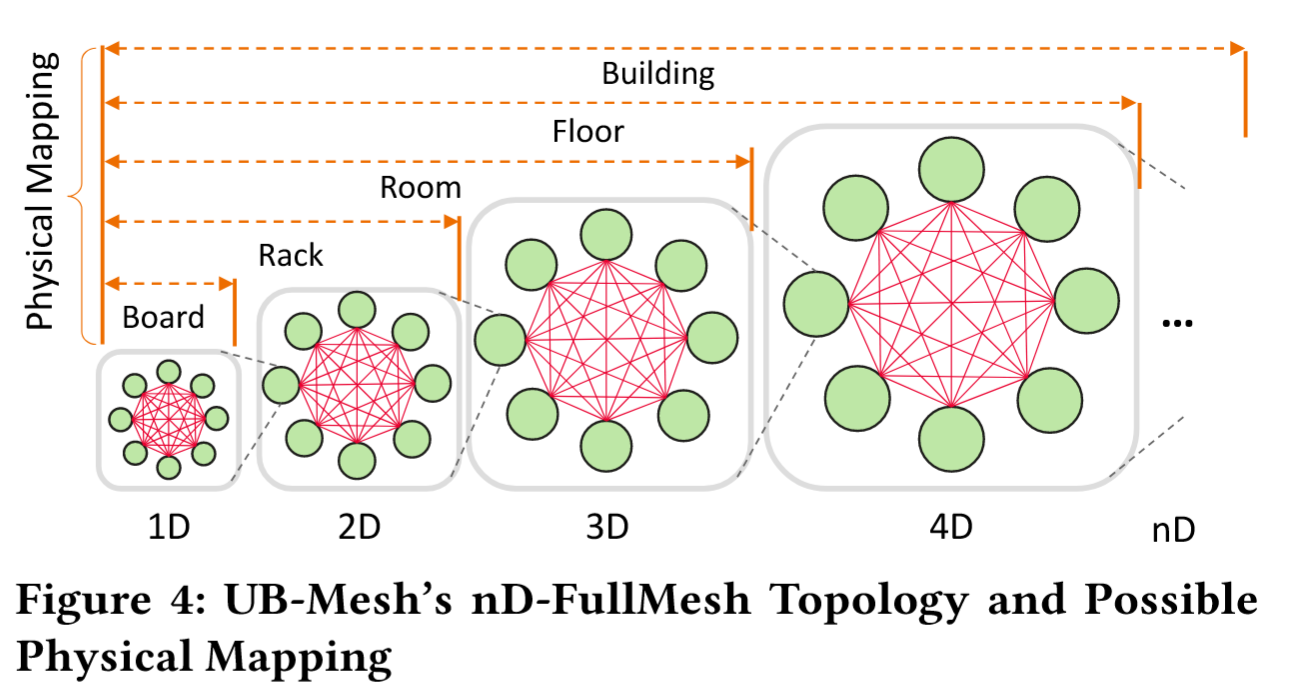
优势所在:
- 契合 LLM 训练特点:nD-FullMesh 在每个网络维度形成紧耦合的直连域,提供 tier-over-tier 的超订带宽,充分契合 LLM 训练固有的数据局部性和 dense-to-sparse 混合流量模式。可灵活调整各维度单节点带宽分配,以满足未来 LLM 训练的特定需求——
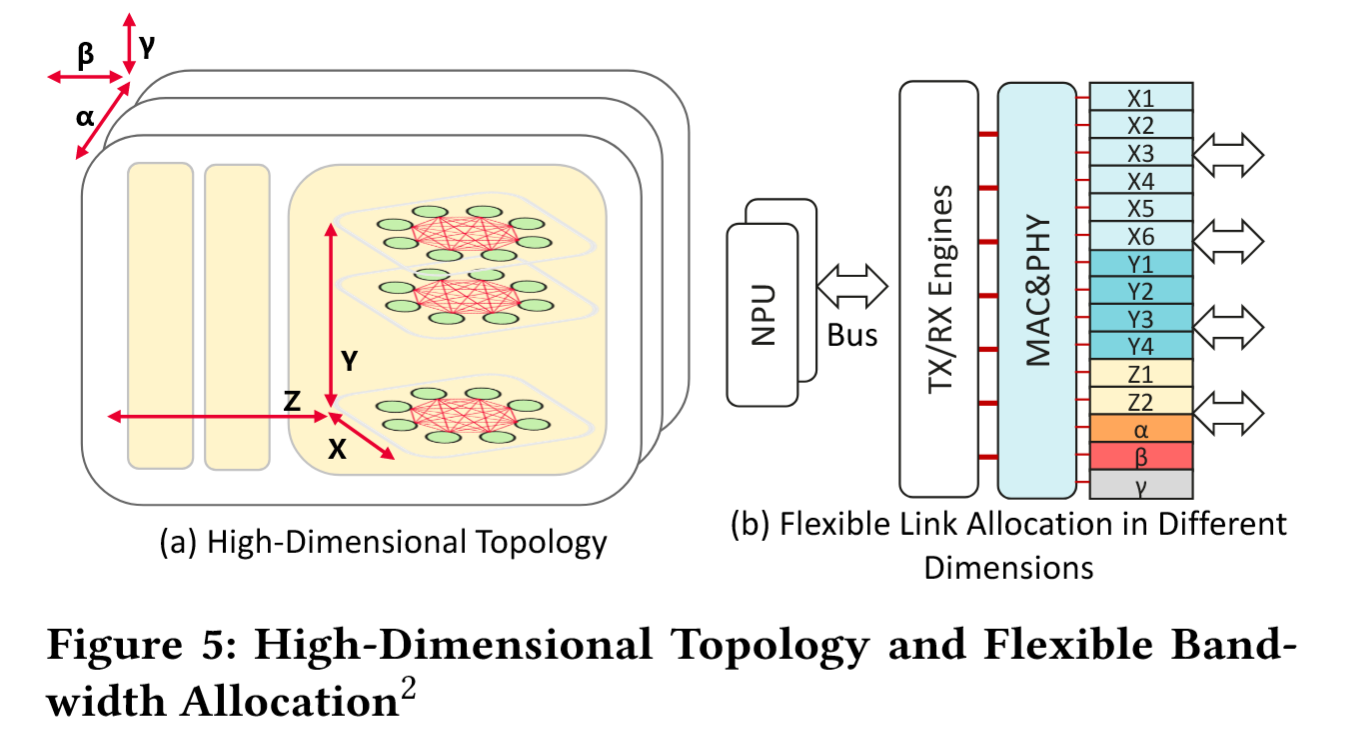 上图 6D-FullMesh 拓扑中,可以通过为 NPU IO 模块配置不同数量的互联链路,从而实现带宽灵活分配。局部高带宽满足 TP/SP 的密集通信需求,长距离低带宽满足 DP/EP 的稀疏流量。
上图 6D-FullMesh 拓扑中,可以通过为 NPU IO 模块配置不同数量的互联链路,从而实现带宽灵活分配。局部高带宽满足 TP/SP 的密集通信需求,长距离低带宽满足 DP/EP 的稀疏流量。 - 显著缩短传输距离:结合书局放置与集合通信优化,大多数传输(TP/SP)可在 0~2 跳内完成,大幅降低数据移动开销。
- 显著降低 CapEx:减少对高带宽交换机和长距离光互连模块的依赖,最大化利用短距直连。如表 2,短距离(XY 维度)使用低成本被动电缆(占 86.7%),长距离(Z、αβγ维度)按需分配带宽(光模块仅占 4.8%),显著降低 CapEx 的同时还提高了系统可靠性——电缆与连接器比交换机和光模块更可靠!与传统对称拓扑(Clos)相比,成本降低 2.04 倍。

- 支持复杂集合通信操作:full-mesh 对
All2All等复杂集合通信操作的支持更优,详见 第五章 的讨论。
Building Blocks of UB-Mesh
核心组件:
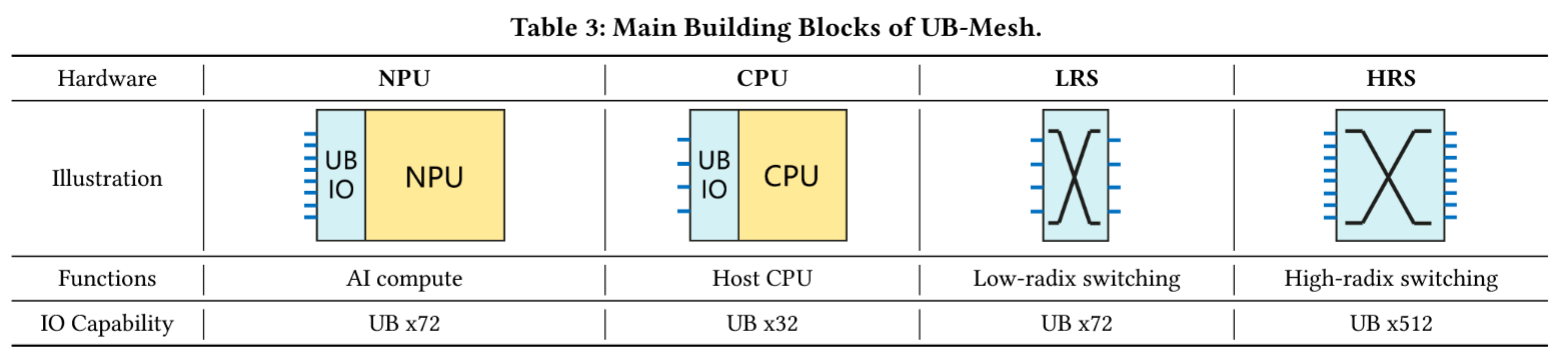
- NPU:集成两个 UB IO 控制器,提供 x72 带宽的 UB 通道,兼具计算与路由功能。
- CPU:负责执行主机程序,集成一个 UB IO 控制器,提供 x32 的 UB 通道。
- LRS(低基数交换机):
- 交换能力仍然很重要:图 5 中 Z 维度和αβγ维度的 NPU IO 进行聚合能够实现更高效的机架间互联;此外,通过交换功能,CPU 与 NPU 的比例及其绑定关系可灵活调整,以实现高效的 NPU 与内存资源池化。
- LRS 是轻量化的交换机(UB x72 IO),用于机架间 IO 带宽聚合与 CPU-NPU 连接,成本低。通常仅适用于特定规模(UB-Mesh-Pod,尽管功能上与 HRS 没什么区别,强行扩展使用也勉强可行)
- HRS(高基数交换机):支持跨 Pod 互联(UB x512 IO),用于扩展至 SuperPod。
- 统一总线(UB):
- 统一总线互联方案是区别于传统 GPU-based 的 LLM 训练系统的关键:
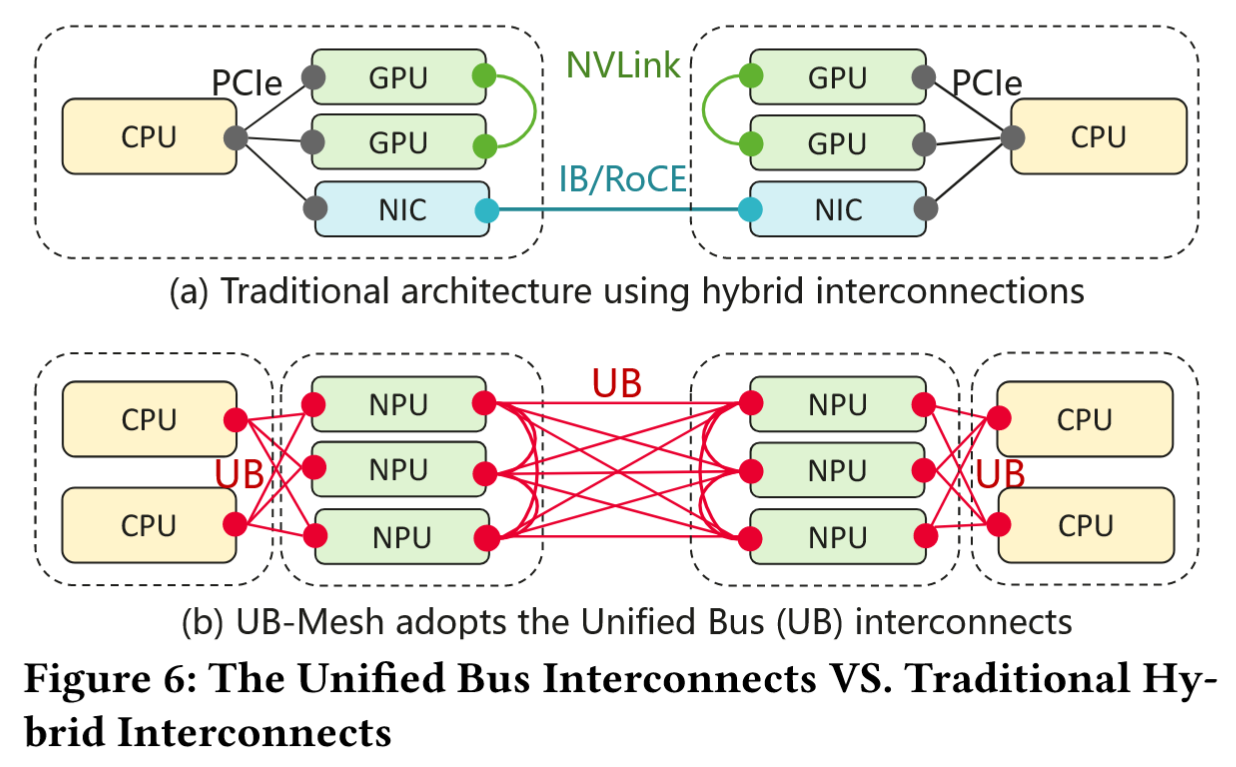 混合互连方案通过 PCIe 实现 CPU-GPU 和 CPU-NIC 互连,通过 NVLink 实现服务器内 GPU 互连、InfiniBand/RoCE 实现服务器间互连。
混合互连方案通过 PCIe 实现 CPU-GPU 和 CPU-NIC 互连,通过 NVLink 实现服务器内 GPU 互连、InfiniBand/RoCE 实现服务器间互连。 - UB 同时支持同步(Load/Store/Atomic)与异步(Read/Write/Message)操作,消除 PCIe/NVLink/IB 等多协议转换开销。
- 灵活的 IO 资源分配:UB 互连与具体应用场景解耦,可灵活分配芯片内不同类型 IO 资源(如 Fig 5 所示)。由于采用统一 UB 链路,NPU 间带宽与 CPU-NPU 带宽均可按需动态调整。
- 硬件资源池化:UB 的点对点通信能力实现了 DDR DRAM、CPU、NPU 和 NIC 等硬件资源的高效池化。例如 Fig 6-(b) 中,CPU 与 NPU 通过 UB 互连形成资源池以提升利用率。
- 系统优化效益:UB 架构避免了协议转换开销,显著降低系统损耗,同时简化了驱动程序、通信库及框架等组件的设计与优化。
- 统一总线互联方案是区别于传统 GPU-based 的 LLM 训练系统的关键:
Architecture Overview
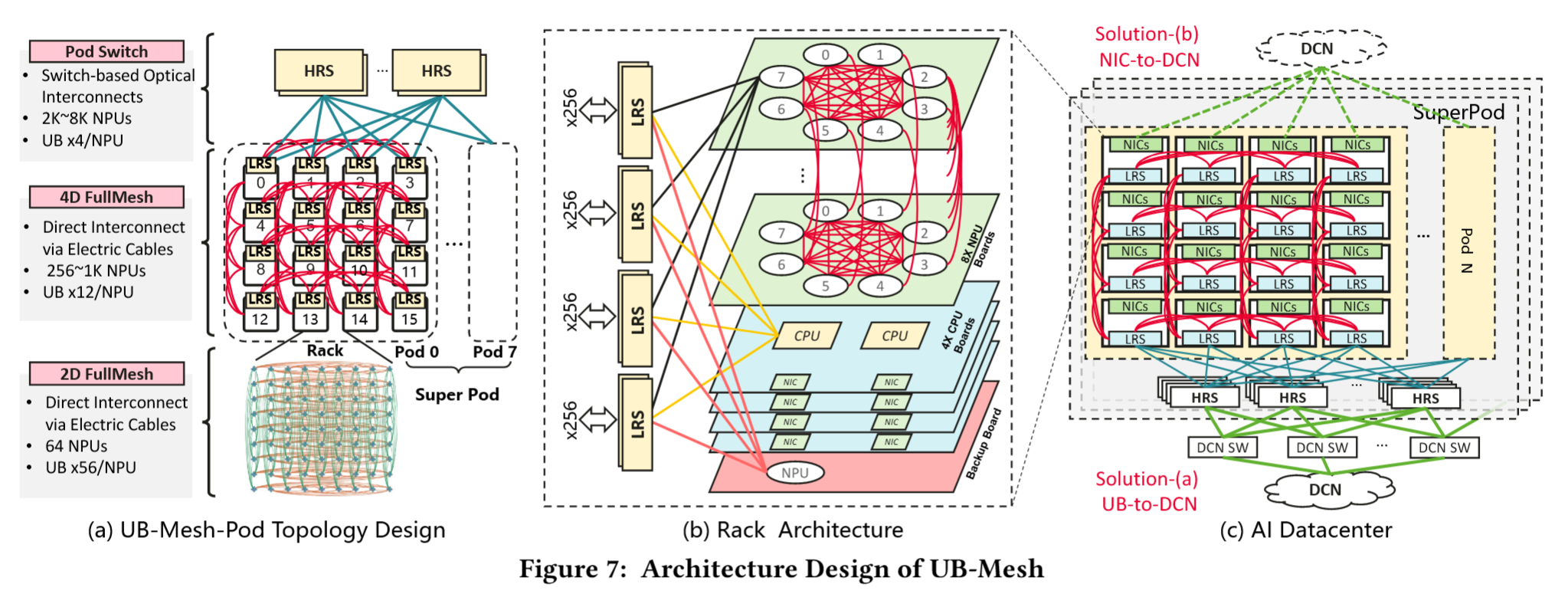
具体实现:
- Implementing 2D-FullMesh in Racks. 如 Fig 7-(b) 所示,每个机架内都配置了 2D-FullMesh 拓扑
- 机架的核心是 8 个 NPU 板(板间直连形成 XY 全连接),每个板上有 8 个 NPU,这 64 个互联的 NPU 构成了 2D-FullMesh 的网络,保障 NPU2NPU 的高带宽。UB IO 控制器也有路由功能,因此 NPU 也提供间接路由功能。
- 与传统 CPU 和 NPU 在同一主板上不同,这里 CPU 是独立存在的,通过交换机与 NPU 连接,从而实现灵活的 CPU/NPU 配比以及 CPU/NPU/DDR 资源的池化。
- 机架配备多块背板交换机,用于管理机架内与机架间的连接。这些交换机采用低基数设计(称为 LRS),在确保设备间无阻塞通信的同时降低成本。这些背板交换机集合输出四组 UB 256 个 IO 接口。
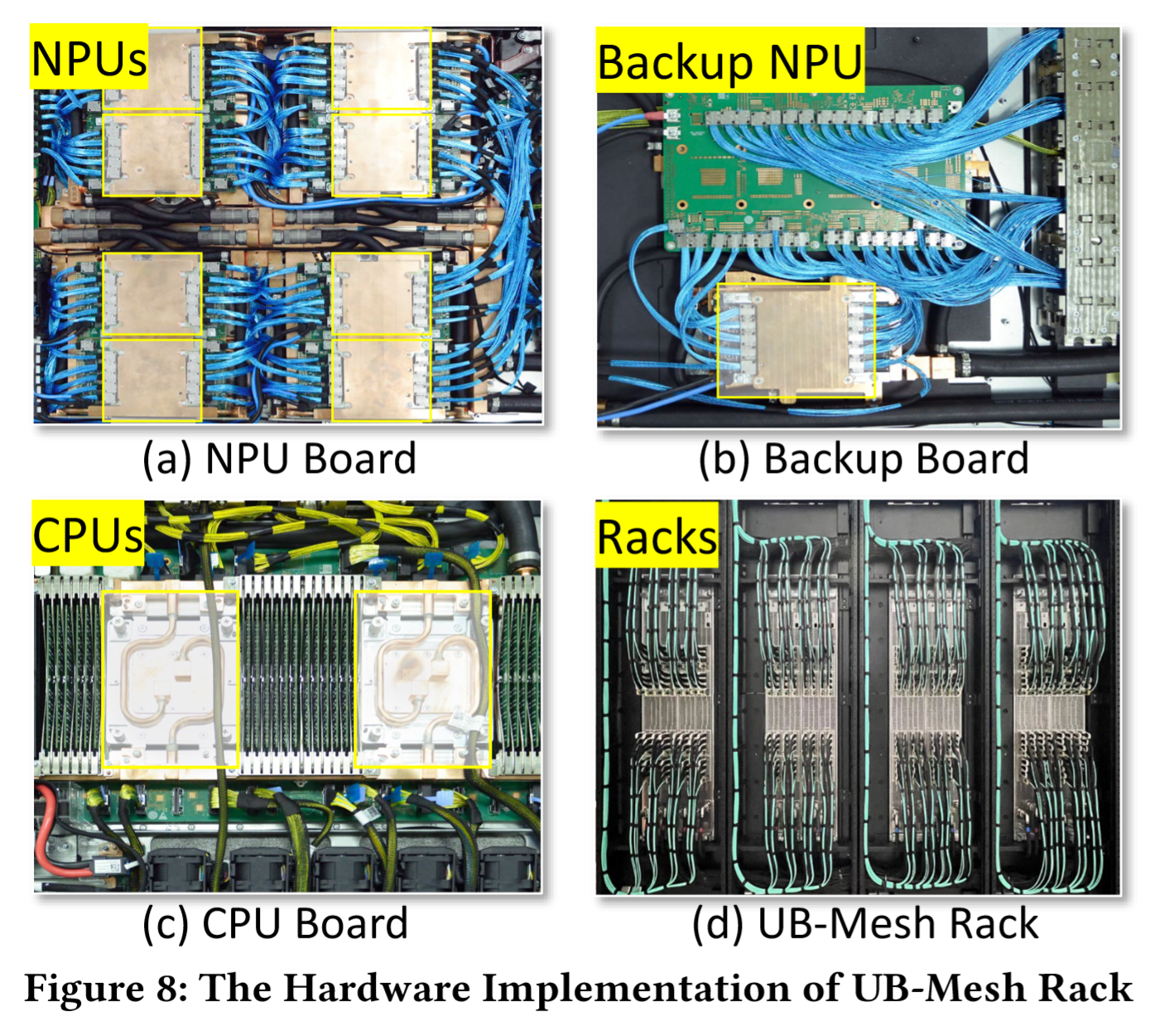
- 64+1 高可用设计:如 Fig 7-(b) 和 Fig 8-(b) 所示,每机架内配置 1 个备份 NPU,备份 NPU 通过 LRS 与 64 个常规 NPU 相连,故障时通过 LRS 切换路径,牺牲单跳延迟(增加 1 跳)但避免训练中断。
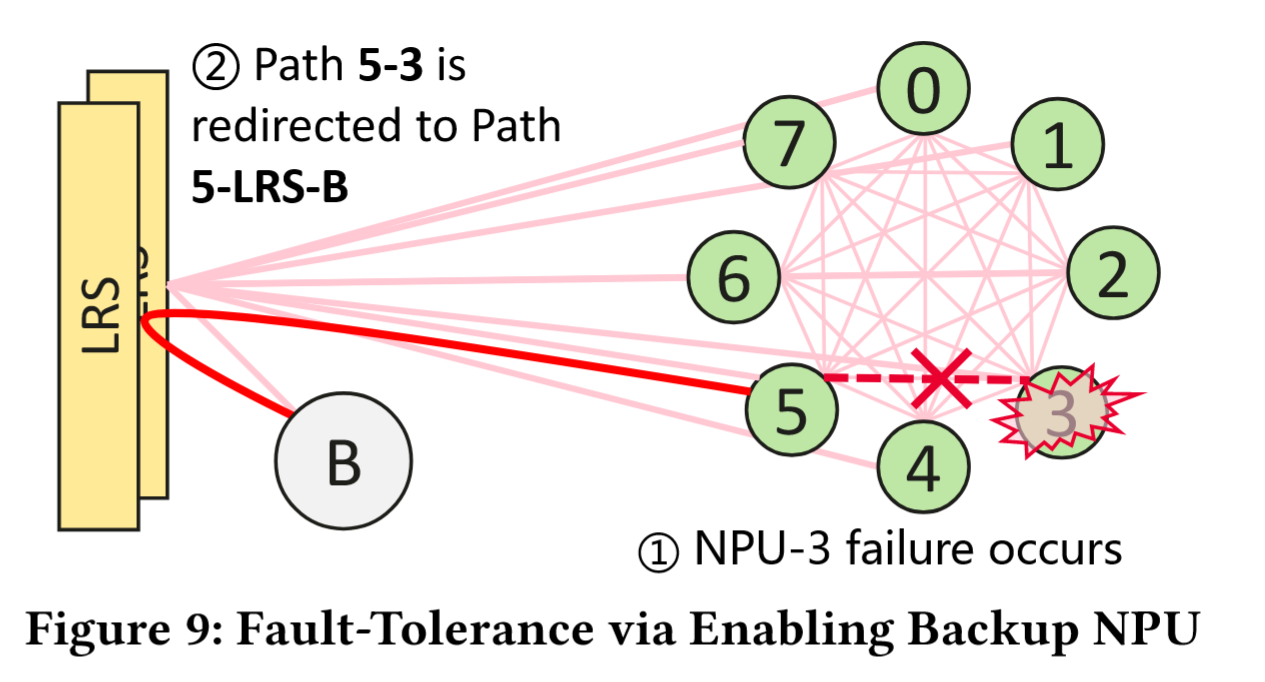 如此图,当 NPU-3 发生故障时,管理系统激活备用 NPU(图中节点 B)替代 NPU-3,与 NPU-3 相关的原始直连链路将被重定向,例如路径 5-3 被重定向为路径 5-LRS-B。尽管该策略将原始直连改为单跳路由,略微增加传输延迟,但远优于直接屏蔽 NPU-3 并在剩余七个 NPU 上运行任务。在 LLM 训练场景中,由于机架内带宽是主要考量因素,增加的延迟对整体训练性能影响可忽略不计。
如此图,当 NPU-3 发生故障时,管理系统激活备用 NPU(图中节点 B)替代 NPU-3,与 NPU-3 相关的原始直连链路将被重定向,例如路径 5-3 被重定向为路径 5-LRS-B。尽管该策略将原始直连改为单跳路由,略微增加传输延迟,但远优于直接屏蔽 NPU-3 并在剩余七个 NPU 上运行任务。在 LLM 训练场景中,由于机架内带宽是主要考量因素,增加的延迟对整体训练性能影响可忽略不计。
- Scaling to 4D-FullMesh in UB-Mesh-Pod. 如 Fig 7-(a)&(c) 所示,
- 在机架行中的 4 个相邻机架组成紧耦合的 1D-full-mesh,机架间通过 LRS 端口互联;在每个机架列中,同样互联,构成 16 个机架组成的 2D-full-mesh 拓扑,形成 ZW 维度全连接,总规模 1024 NPU/Pod,总的来看也就是 4D-FullMesh 拓扑。每条链路均采用 128 个 UB IO 接口,
- 在二维平面上每方向 4 个相邻机柜全互联,是基于有源电缆传输距离限制的最优方案。
- UB-Mesh-SuperPod and Beyond. 在 1K NPU 的 UB-Mesh-Pod 基础上,UB-Mesh-SuperPod 可容纳多个 Pod。
- 鉴于当前云场景中中小规模 LLM 训练工作负载可能无法完全占用整个 SuperPod,Pod 级互联中仍采用对称 Clos 拓扑结构,而非延续全连接架构。该设计使云管理员能根据用户需求灵活划分 SuperPod,并确保每个划分域内的全带宽传输。——(工程上的 trade-off)
- 如图 7-(c) 所示,采用高基数 Pod 交换机(HRS)连接 SuperPod 内的每个 Pod,最高可扩展至 8K 个 NPU。
- 最终,SuperPod 内的机架通过 UB 交换机(方案 a)或 CPU 板载网卡(方案 b)接入 DCN。DCN 域通常支持大规模 DP 训练,其交换机采用 Clos 拓扑组织,可扩展至 100K 或更多 NPU 规模。
估算单个 NPU 故障对整个系统性能的影响
1. 计算能力降级
- 板级(8 NPU):
- 单个 NPU 故障导致计算能力损失为 1/8 = 12.5%(假设任务均匀分布)。
- 机架级(64 NPU):
- 若启用64+1 备份设计,备份 NPU 激活后计算能力无损失(降级 0%)。
- 若未启用备份,损失为 1/64 ≈ 1.56%。
- Pod 级(1024 NPU):
- 备份机制下,单个 NPU 故障对全局计算能力影响为 0%;未启用时损失 1/1024 ≈ 0.0977%。
2. 带宽降级
- 板内(1D-FullMesh):
- 单个 NPU 故障导致其直连的 7 条链路中断,其余 NPU 间通信需通过其他路径(如绕行相邻 NPU)。
- 带宽影响:局部路径跳数可能从 1 跳增至 2 跳,带宽利用率下降(但全连接拓扑提供冗余路径,整体带宽损失有限,估算为 <5%)。
- 机架内(2D-FullMesh):
- 备份 NPU 通过 LRS 连接,原直连路径(如 NPU-A → 故障 NPU → NPU-B)改为 NPU-A → LRS → 备份 NPU → NPU-B,增加 1 跳。
- 带宽影响:单跳延迟增加对 LLM 训练影响可忽略(文中称性能损失 <1%)。
- Pod 级(4D-FullMesh):
- 跨机架通信通过 HRS 或 LRS 聚合,单个 NPU 故障对全局带宽影响极低(依赖备份路径,估算影响 <0.1%)。
3. 实际场景综合影响
- 启用 64+1 备份机制时:
- 计算能力降级:0%(备份 NPU 补偿)。
- 带宽降级:局部路径跳数增加导致延迟微升,但对训练吞吐量影响 <1%(文中实验显示性能损失在 7%以内,备份场景下更小)。
- 未启用备份或多故障时:
- 计算能力降级:按比例线性增加(如 2 个 NPU 故障时,损失翻倍)。
- 带宽降级:路径拥塞风险上升,可能显著影响性能(如 10%+)。
结论
UB-Mesh 通过64+1 备份设计与层次化冗余路径,将单个 NPU 故障的影响降至最低:
- 计算能力:备份机制下无损失。
- 带宽:局部跳数增加导致微小延迟,但对 LLM 训练整体性能影响可忽略(文中实验验证性能损失<7%,实际备份场景更低)。
- 设计有效性:该机制显著优于传统架构(如 Clos)依赖软件重启的恢复方案,后者可能导致分钟级中断与更高性能降级。
Enabling The Architecture
UB-Mesh 是一种全新的、特殊的网络拓扑,它需要全新设计的路由系统与容错系统,它们需要满足如下需求:
- 支持混合拓扑:4D-FullMesh+Clos。
- 高效转发:NPU 同时用作计算和路由,因此不能因为路由而占用太多资源,因此需要高效的路由表查找和转发操作。
- 支持非最短路径:nD-FullMesh 拓扑中,任意两个终端都有若干可能的路,并且 64+1 的备份设计也要求非最短路的使用。
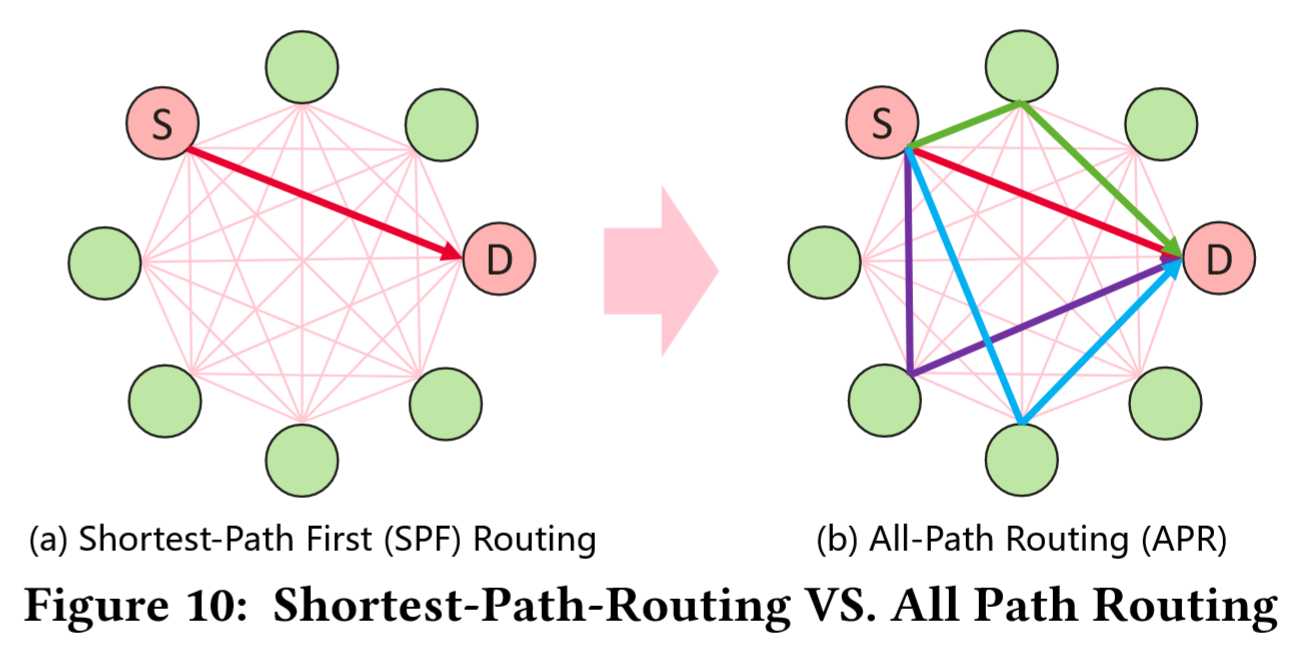
- 传统基于 SPF 的最短路路由不能最大化利用带宽资源且易受链路故障的影响;APR 需要对链路故障和拥塞做到快速响应——动态路径切换。
- 快速故障恢复:路由系统必须能够保障高可靠和可用性。
- 无死锁:死锁会造成资源浪费甚至是功能上的错误。
| 需求 | APR 路由 | 基于直接通告的快速故障恢复 |
|---|---|---|
| 混合拓扑支持 | 结构化寻址 + 源路由跨层路径指定 | 依赖关系预计算适配混合拓扑 |
| 高效转发 | 线性表查找 + 源路由预解析 | 直接通知减少控制平面负载 |
| 非最短路径支持 | 多路径位图选择 + Borrow 策略 | 快速路径切换启用备份路径 |
| 快速故障恢复 | APR 动态路径切换 | 直接通知 + 备份路径即时激活 |
| 无死锁 | TFC 流控 + 双 VL 划分 | 快速收敛避免临时拥塞 |
现有的路由技术并不能完全满足 UB-Mesh 的特殊需求:

All-Path Routing
为了实现上述路由系统的需求,APR 采用了以下技术:
- Source Routing. 数据包在原始头部的基础上新增 8 字节的 SR 报头,其中包含转发指令。
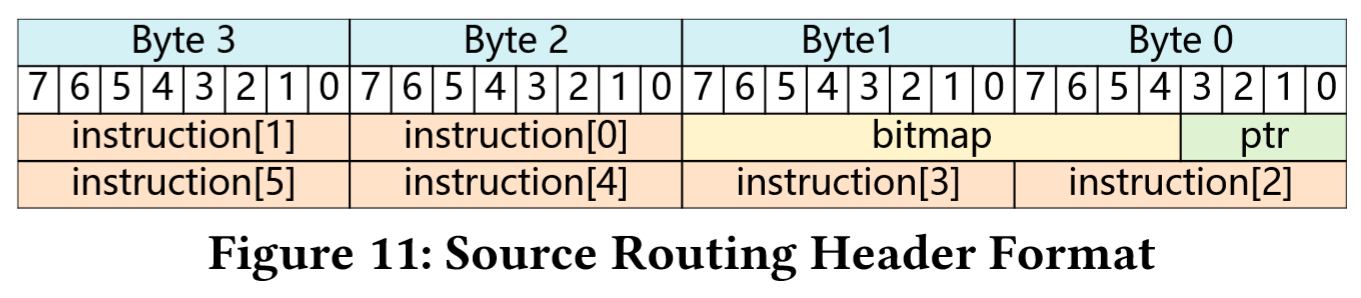
- 各路由器通过 4 位指针(
ptr)指示 12 位bitmap的位偏移量,bitmap中第 个 bit 的值决定第 跳的转发方式(bit=1表示该跳采用 SR 转发,0表示传统转发)。若启用 SR 转发,bitmap字段还将用于定位 6 个指令字段之一,以确定数据包转发路径。 - 原论文中的解释有些模糊,在我仔细思考之后,这里的机制应该是3:
- 6 个指令域中包含的是转发的完整指令,每个字段存储具体的转发路径,在报头构成时就已经确定下来(为了加快转发速度),之所以是 6 个,应该是考虑到即使出现链路故障启用备份 NPU 时,转发到目的 NPU 的跳数期望就是 6;必要时指令域应当也会更新,因为
bitmap中能够指示的跳数显然不止 6 个。 - 因此
bitmap中应该有 3 个 bit 保留不用,专门用于指示当前跳应该使用哪一个指令(大概率是高位的 3 个 bit);那么就剩下 9 个 bit 指示如何转发,这 9 个 bit 的偏移量需要 个 bit 的ptr域来表示;至于ptr域,在每完成一跳之后,需要递增 1。
- 6 个指令域中包含的是转发的完整指令,每个字段存储具体的转发路径,在报头构成时就已经确定下来(为了加快转发速度),之所以是 6 个,应该是考虑到即使出现链路故障启用备份 NPU 时,转发到目的 NPU 的跳数期望就是 6;必要时指令域应当也会更新,因为
- 因此,SR 机制的优势是:本身信息是高度压缩地添加在原报头,因此开销极低;可以灵活且快速地(预先)指定转发方式和转发路径,能够适应混合拓扑,且转发时直接解析下一跳,避免动态路由决策延迟;
- Structured Addressing&Linear Table Lookup. 基于网络元素(Pod,rack,board 等)的物理位置将寻址空间划分为多个段(segment),因此同一个段内的 NPU 共享相同的前缀,从而仅需存储短的段地址,令 NPU 通过相对于段地址的线性偏移量进行寻址。
- 优势:地址分段后,路由表仅存储短前缀,使得查询复杂度从 降至 4 ;显著降低路由表的空间占用,且降低路由表生成和分发的时间开销;时空复杂度的降低,使得路由表对链路状态的变化能够快速响应,例如在链路故障及恢复时,仅更新局部段的路由表,而非全局
- Topology-Aware Deadlock-free Flow Control. nD-FullMesh 拓扑包含复杂的环形结构,且 APR 支持多跳路由,因此有限的虚拟通道(Virtual Lane)资源下实现无死锁流量控制非常困难,故提出基于拓扑感知的无死锁流控算法(TFC),TFC 能够在仅需 2 个 VL 资源的情况下实现全路径无死锁路由。
- TFC 通过通道依赖图(Channel Dependency Graph)建模死锁状态,将 nD-FullMesh 拓扑划分为若干无环子图,确保数据流动无循环依赖。具体来说,每个子图内将拓扑转向规则与 VL 约束统一为单一规则集——运用 N 维跨维度环破除原则将规则集分解为单 VL 无环子集,再通过同维度环破除原则计算幂集元素的排列与笛卡尔积,从而生成全路径组合与 VL 映射关系,确保无死锁运行。
- 为什么是 2 个 VL 资源?通过 VL 划分流量类型(如请求与响应),打破资源竞争导致的死锁。
仔细理解 TFC 算法 1
1. 通道依赖图(CDG)的建模
- 定义:CDG 是一个有向图,其中节点表示网络中的通信通道资源(如 VL),有向边表示资源依赖关系(如数据包从通道A转发到通道B时,B依赖于A的资源释放)。例如,若路径 A 使用通道 X 后需要通道 Y,则 CDG 中存在边 。
- 死锁条件:CDG 中存在环(如 ),则可能因循环等待资源导致死锁。
2. 拓扑分解与环路消除
- N 维跨维度环路破除:根据 UB-Mesh 的高维网格结构,将整个拓扑划分为多个低维子图,每个子图对应一个维度组合(如 XY 平面、ZW 平面)。具体来说可能有以下原则:
- 在跨维度的通道依赖中,强制依赖方向遵循维度优先级(如X>Y>Z>W)。例如,数据包在X维度传输完成后才能进入Y维度,避免跨维度循环依赖。
- 利用模运算(如 )将维度分组,确保每组内的依赖关系独立。
- 利用图论中的树分解(Tree Decomposition) 或 强连通分量(SCC)分解,将高维依赖关系分解为低维子问题。
- 同维度环路破除:在单个子图(如 2D 网格)内,进一步分解依赖关系。具体来说可能有这些手段:每个维度内按链路方向分组(如 X+方向与 X-方向),在同一维度的子图内,强制所有通道依赖方向一致;对每个子图内单独应用拓扑排序,消除局部环路。
- 路径组合枚举与 VL 分配:对幂集元素计算其排列(permutation)和笛卡尔积(Cartesian product),从而生成生成全路径组合,结合 VL 分配,从而生成所有可能的无环映射。
- 无环 VL 映射的生成:1. 单 VL 子集分解:将 CDG 分解为多个子集,每个子集仅使用一个 VL;2. 无环验证:对每个子集应用拓扑排序,确保无环路;3. 组合优化:通过动态规划选择最小 VL 数量(如仅需 2 个 VL)。最终实现,为每个路径分配一个 VL,使得所有路径的依赖关系在 CDG 中无环。
Fast Fault Recovery via Direct Notification
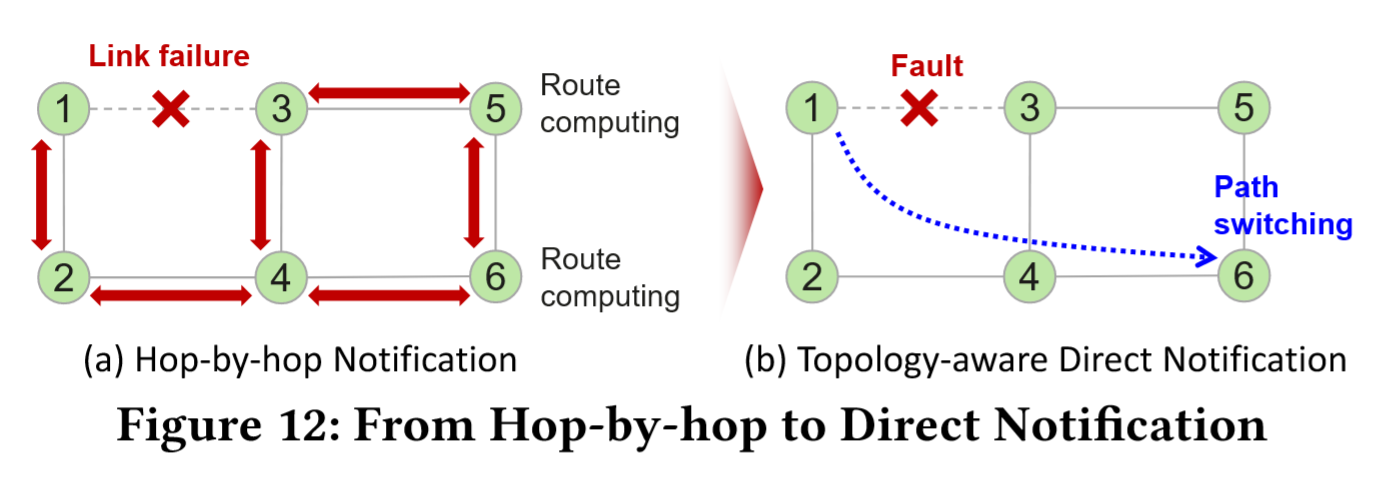 Hop-by-hop vs. Directt Notification:
Hop-by-hop vs. Directt Notification:
- 链路故障时,传统路由系统通常采用逐跳通知机制,如 Fig 12-(a) 所示,当链路 1-3 发生故障时,该信息会通过节点 1 和 3 逐跳传播,从而产生较长时延。
- 在 UB-Mesh 网络中,由于每个节点都拥有确定的通信目标集合,因此可以在链路故障时直接通知相关节点来加速路由收敛,如 Fig 12-(b) 所示,当链路 1-3 发生故障时,该信息会根据预先计算的路由关系直接发送至节点 6。这种基于拓扑感知的直接通知机制可大幅降低控制平面开销。
Maximizing The Performance
训练任务是否有效分配到计算资源上,或者受限于集合通信的性能,UB-Mesh 上运行工作负载仍可能利用率较低。为确保 LLM 训练期间系统性能达到最优,华为引入了若干拓扑感知的优化策略。
Topology-Aware Collective Communication
为了充分利用 UB-Mesh 的层次化直连带宽和 APR 路由能力,华为提出了基于拓扑感知的集合通信算法,以 AllReduce 和 All2All 为例:
- All-Reduce:用于梯度同步(如 TP/DP),占 LLM 训练流量的 50%+。
- All-to-All:用于 MoE 模型的专家动态分配(EP),或长序列的注意力计算(SP)。
优化思路:路径映射与带宽借用
- Multi-Ring 算法:
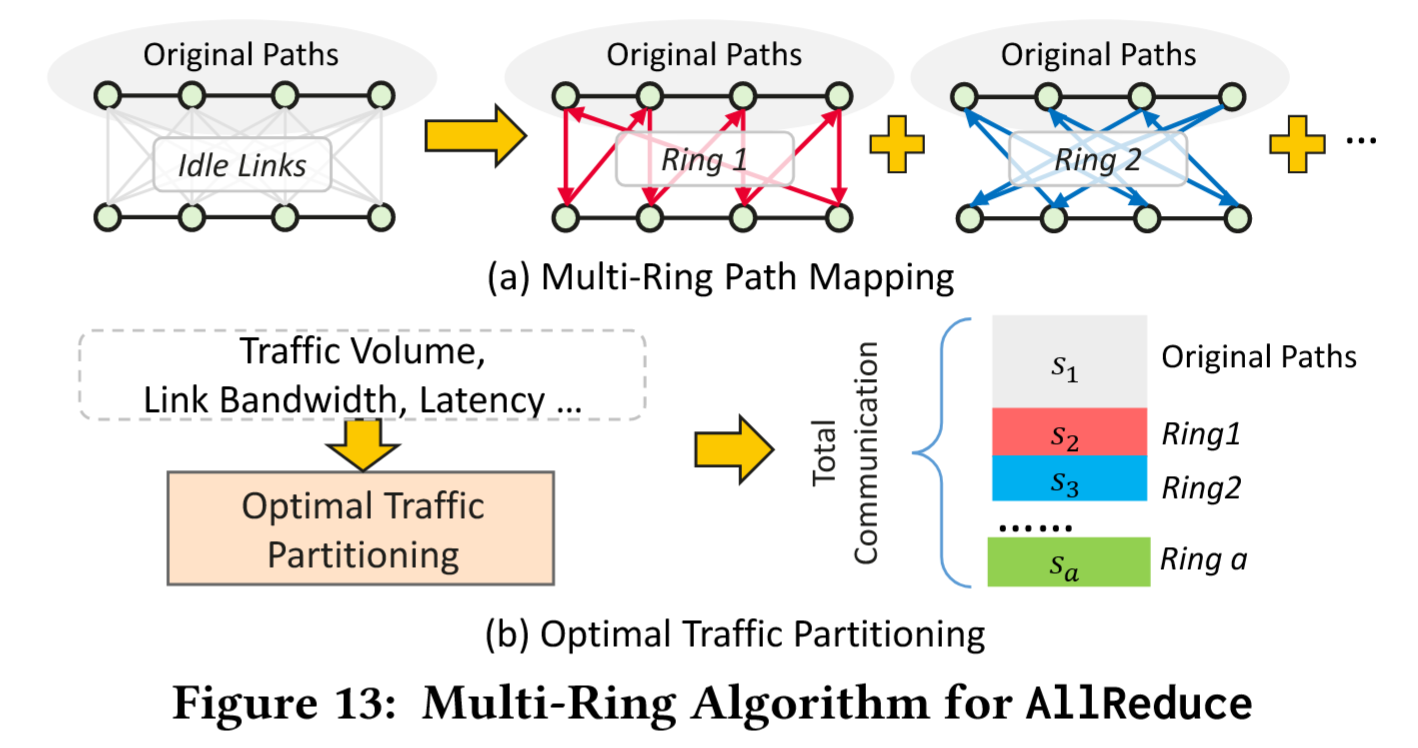
- 将
AllReduce分解到多个环形路径,利用 UB-Mesh 的 nD-FullMesh 拓扑,通过 APR 动态选择空闲链路。步骤:1. 统一拓扑抽象:综合考虑节点数、连接方式、链路带宽、延迟等参数对网络拓扑进行统一建模;2. 生成互不重叠的环形路径(确保路径独占性以避免流量冲突);3. 根据 APR 的 borrow 策略,借用空闲链路扩展带宽。 - 如 Fig 13-(a) 所示,原始路径代表默认映射方案,而未被纳入这些路径的闲置链路则通过 APR 的机制进行带宽扩展。最终如 Fig 13-(b) 所示,通过多路径流量分区优化来缓解瓶颈,并借助 APR 的带宽借用(Borrow)机制实现效益最大化。
- 将
All2All通信有两种经典情形: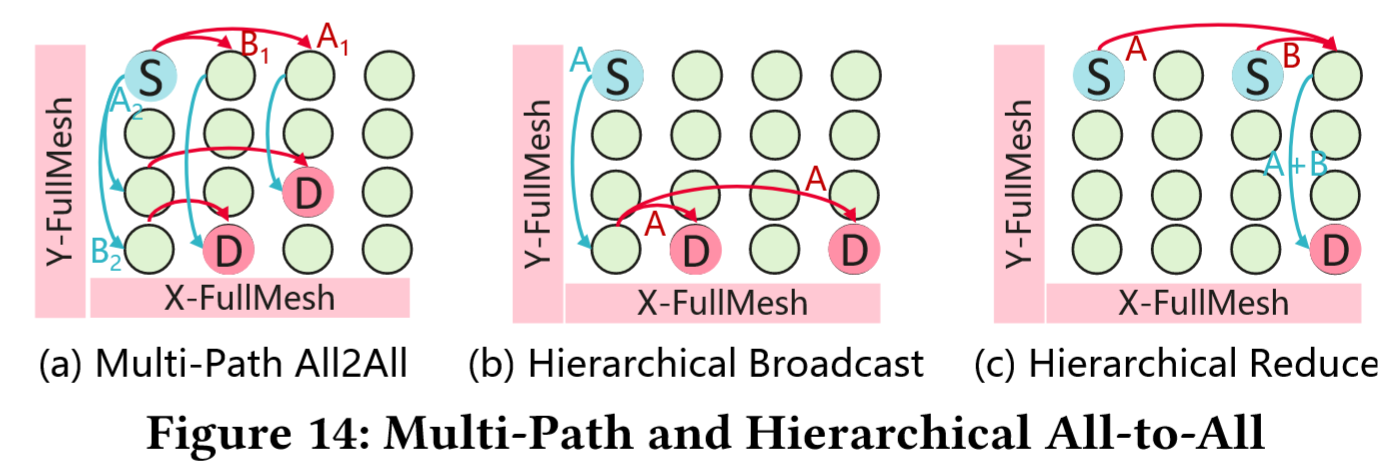
- 1)General
All2All:如 Fig 14-(a) 所示,UB-Mesh 中的源节点向不同目的节点发送不同的数据,此时采用 Multi-Path All2All 优化——每个元素(vector 或 tensor)分成两部分,同时通过 X-FullMesh 和 Y-FullMesh 互联进行传输5,在最多一跳转发内到达目的节点。这种策略能够保证 UB-Mesh 中 nD-FullMesh 的高带宽利用率。 - 2)Broadcast+Reduce:对于涉及 token 分发和专家数据收集的
All2All操作,其语义等价于多个broadcast和reduce操作的重叠,如 Fig 14-(b&c) 所示,则可以采用分层广播/规约策略,将全局操作分解为局部子操作,从而节省带宽消耗,充分利用 UB-Mesh 的分层拓扑。
Topology-Aware Collective Parallelization
为充分利用 UB-Mesh 高带宽的本地互联,华为采用拓扑感知的并行机制来优化 LLM 训练中的模型与数据分割,方法如下: 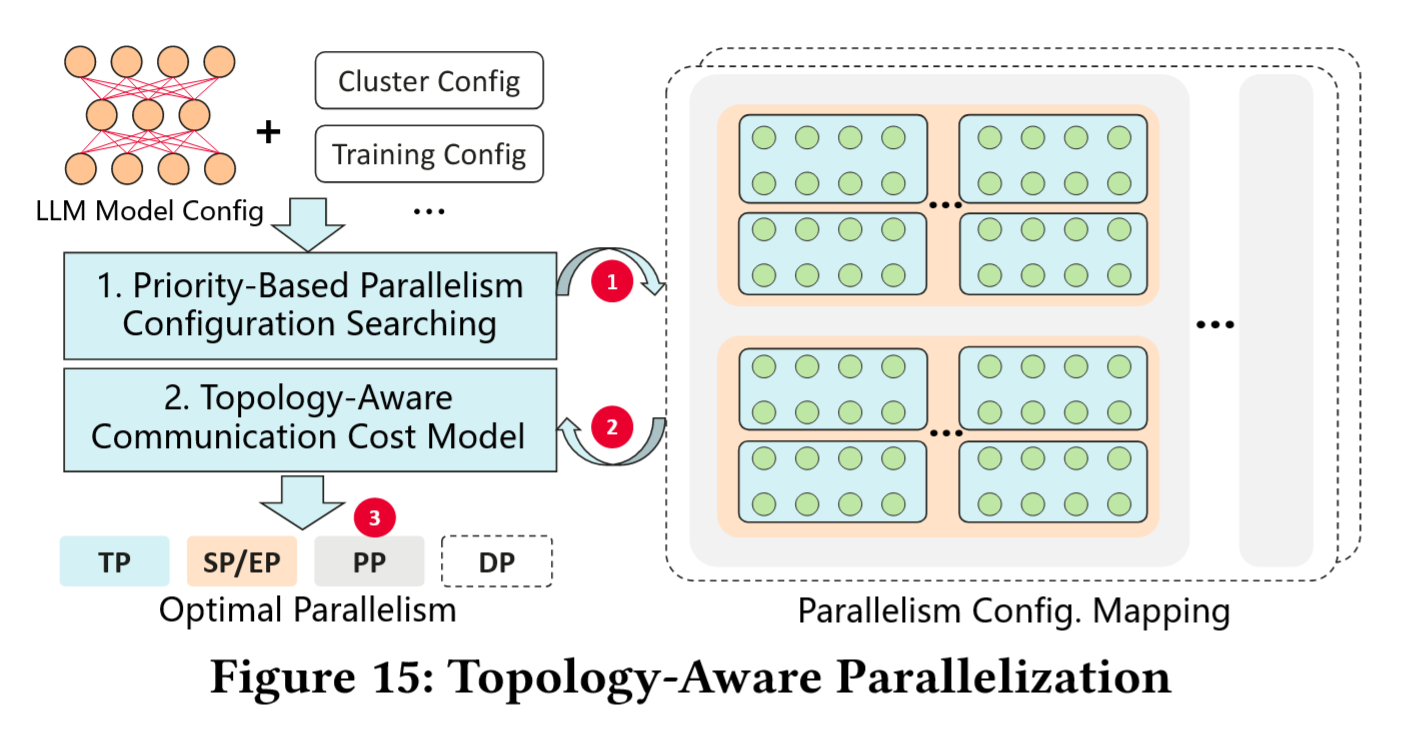
- 生成可行的并行配置并将其映射到 UB-Mesh 架构
- 通过拓扑感知通信成本模型(Topology-Aware Communication Cost Model)评估通信开销
- 迭代最小化通信开销以获得最优配置
这个机制有两个重要要求:
- 构建合适的搜索空间以平衡效率与性能;
- 确保成本模型尽可能精确。 对于要求 (1),采用基于优先级的启发式方法剪枝搜索空间:
- 涉及高通信量的 TP 与 SP 优先分配至高带宽域(如机架内的 2D-FullMesh),
- EP 需强制满足
SP*DP mod EP=0,从而确保专家均匀分布, - 而用于梯度更新的 PP 和 DP 优先级最低,分配到跨机架或 Pod 级链路。 针对要求 (2),通过内部仿真平台模拟APR 路由、链路拥塞、VL 竞争等行为,校准理论模型与实测性能的偏差。
Evaluation
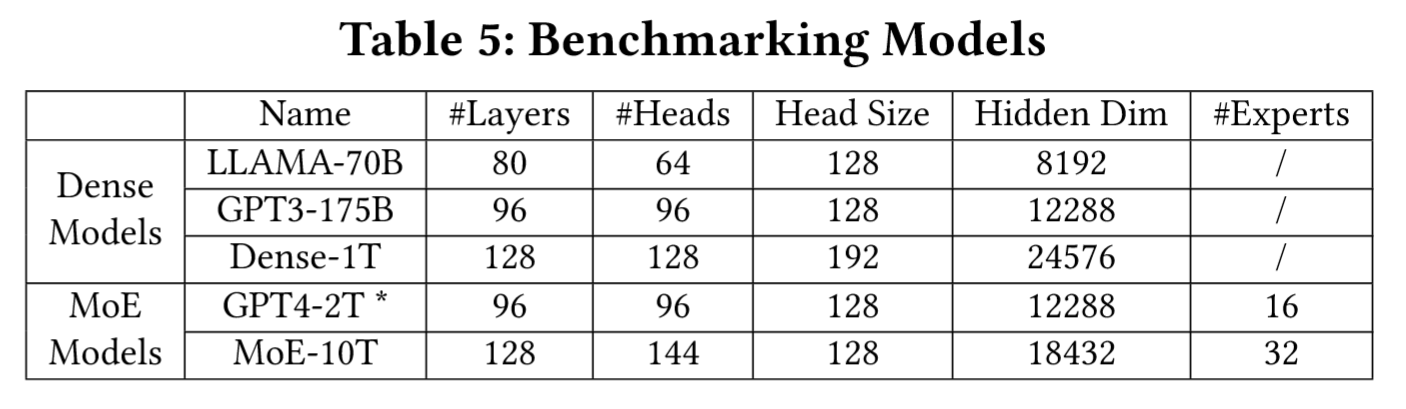 测试模型:
测试模型:
- 密集模型:LLAMA-70B(80 层)、GPT3-175B(96 层)、Dense-1T(128 层)。
- 稀疏模型:GPT4-2T(社区参数版本,MoE,16 专家)、MoE-10T(32 专家)。 评估指标:
- 训练吞吐量(Token/sec)、线性度(Scaling Efficiency)、成本效益(TCO)、网络可用性(MTBF)。
- 仿真平台:基于真实硬件 PoC(Proof of Concept)校准的集群级仿真,覆盖 8K NPU(UB-Mesh-SuperPod)场景。
Intra-Rack Architecture Exploration
机架内网络架构对比: 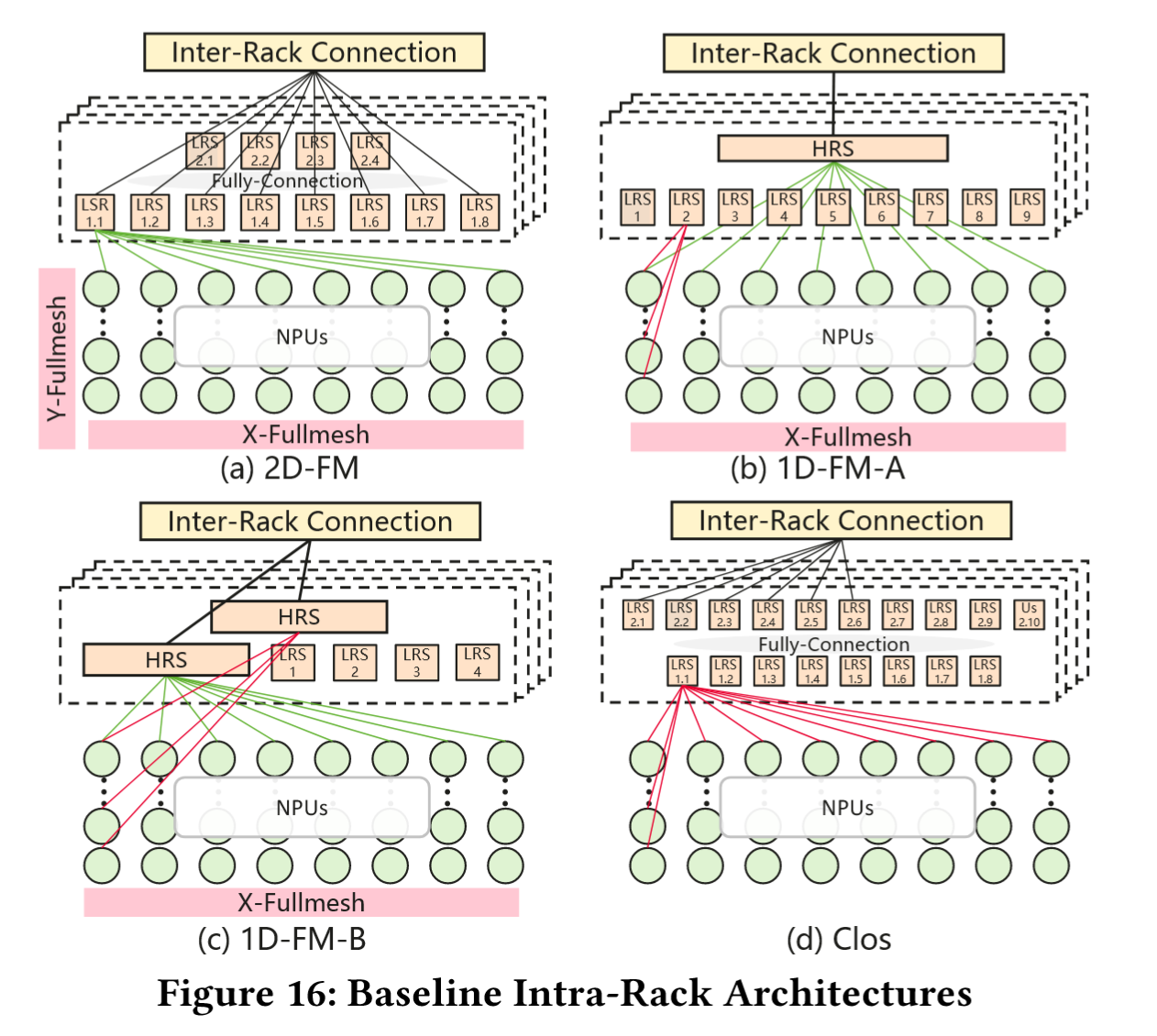 6
6
- 2D-FM(UB-Mesh):64 NPU/机架,通过电缆直连实现 2D 全连接(X 向、Y 向全互联),采用 48 LRS 实现机架间带宽的聚合与 CPU-NPU 的互联。
- 1D-FM-A:保留 1D 的 X 向全互联,即板内全连接,跨板通过 36 LRS 实现互联。每个 NPU 配备一个 x16 带宽的 UB IO 端口连接到 LRS,另有一个 x16 带宽的 UB UI 端口连接到 4 个 HRS 用于机架间通信。
- 1D-FM-B:进一步以 HRS 替代 LRS,每个背板部署四个 LRS 用于 NPU-to-CPU 通信,跨板 NPU 通信通过四个背板中的八台 HRS 实现,这些 HRS 同时连接机架间网络,为每个 NPU 提供 x32 UB IO 用于机架间通信。
- Clos:将 64 个 NPU 的所有端口连接至 72 个 LRS(NPU 之间不直连),构成对称 Clos 拓扑。此架构提供了最高灵活性,但也需要大量交换资源。
性能对比:机架间架构固定为 2D-FM,8K=64×128 规模的 SuperPod,评估序列长度为 8K 到 10M,对比训练时吞吐的性能差异 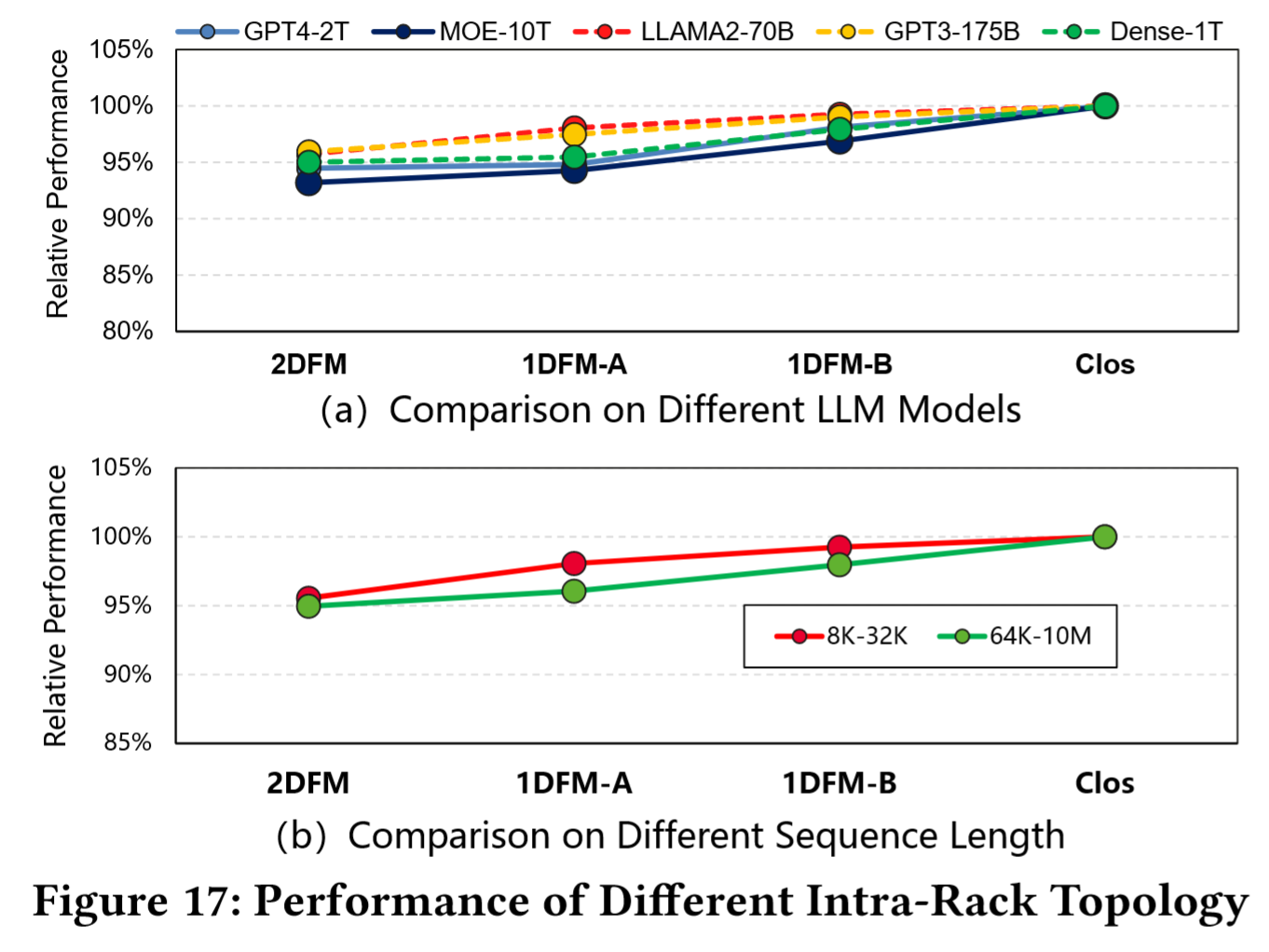
| 模型 | 2D-FM(vs Clos) | 1D-FM-A(vs Clos) | 1D-FM-B(vs Clos) |
|---|---|---|---|
| LLAMA-70B | 93.2% | 95.5% | 96.8% |
| GPT3-175B | 94.5% | 96.1% | 97.3% |
| GPT4-2T | 95.9% | 97.8% | 98.4% |
具体数据:
- Fig 17-(a) 表明:2D-FM 性能损失仅 5-7%,但硬件成本降低 65%(LRS 数量减少 50%+);1D-FM-A 性能略优于 2D-FM(~2%);1D-FM-B 性能接近 Clos(97%+),但成本仍高于 2D-FM(HRS 使用增加),性能相对于 2D-FM 有一定提升(~3%)。
- Fig 17-(b) 表明:不同序列长度下(在 8K 至 32K 序列长度范围),2D-FM 架构达到 95.5%的性能,略低于 1D-FM-A(98.1%)和 1D-FM-B(99.2%);在 64K 至 10M 序列长度区间,2D-FM 架构保持 95.0%的相对性能。
结论:可见相较于 Clos 架构,2D-FM 能以显著降低的硬件成本提供相近的训练性能(性能差距在 7%以内)。
Inter-Rack Architecture Exploration
对比架构:机架内 2D-FullMesh 之上的连接 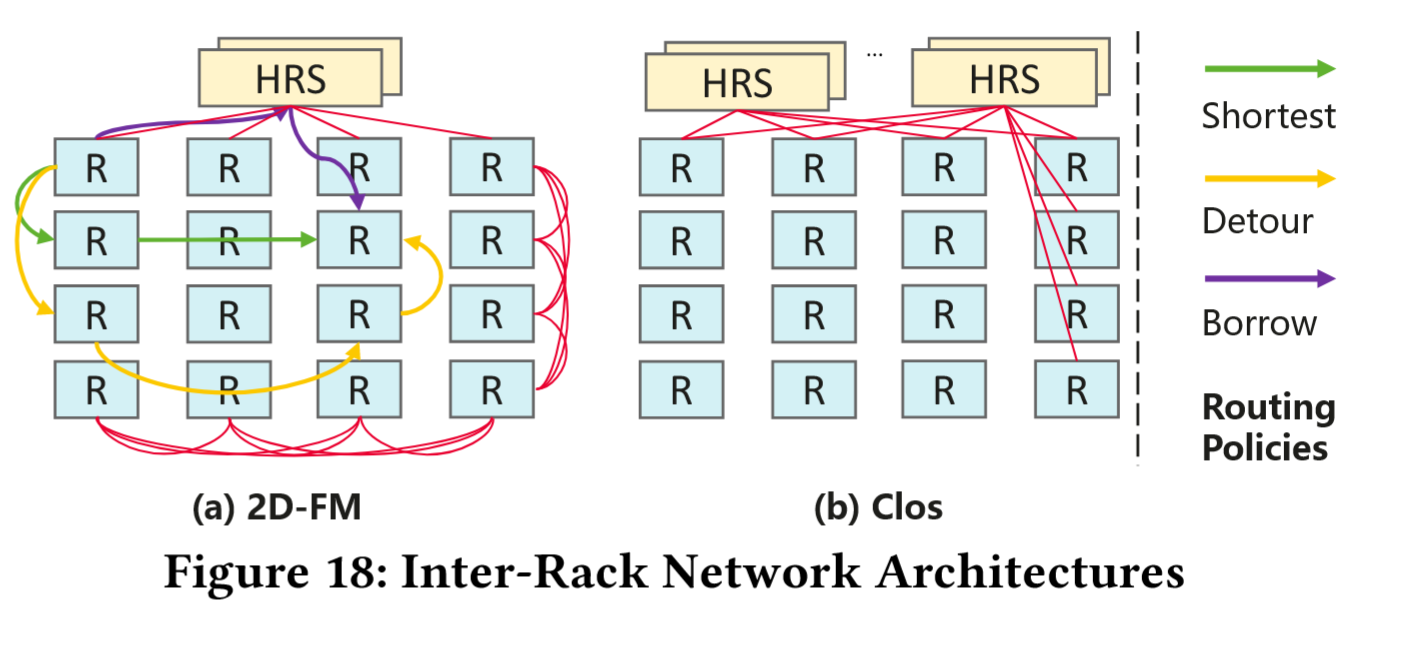
- 2D-FM(UB-Mesh):Pod 内的 16 个机架在水平和竖直方向都直接互联形成 2D 全连接,并且所有机架还通过 HRS 实现跨 Pod 互联。
- 在 UB-Mesh-Pod 中支持三种路由策略:Shortest,P2P 通信时仅选择 2D mesh 中的最短路;Detour,启用 APR 非最短路机制,为了最大化利用带宽而绕行使用空闲路径;Borrow,机架借用 Pod 间 HRS 链路带宽。(Detour 的主要目的是避免局部链路拥塞, Borrow 则是为了增加临时带宽提高对 burst flow 的容忍)
- Clos:16 机架全连接 HRS 而互相不直连,通过消耗更多的 HRS 获得极高的 all-to-all 对称带宽和灵活性。
性能对比: 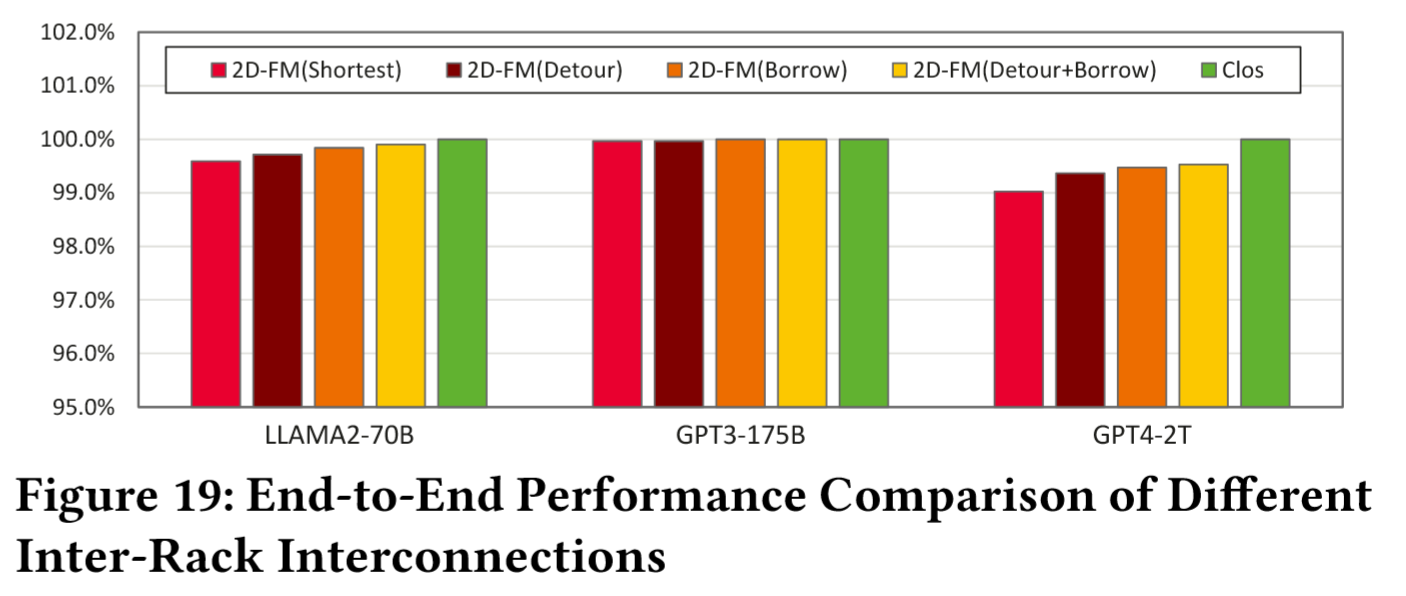
 具体数据与分析:
具体数据与分析:
- 对于端到端的训练时吞吐性能差异,Detour+Borrow 策略几乎达到 Clos 性能(差距<0.5%),最短路策略也可以做到 99.27%的性能,但成本降低 70%(HRS 减少 82%)。(GPT3-175B 对机架间架构的差异不敏感)
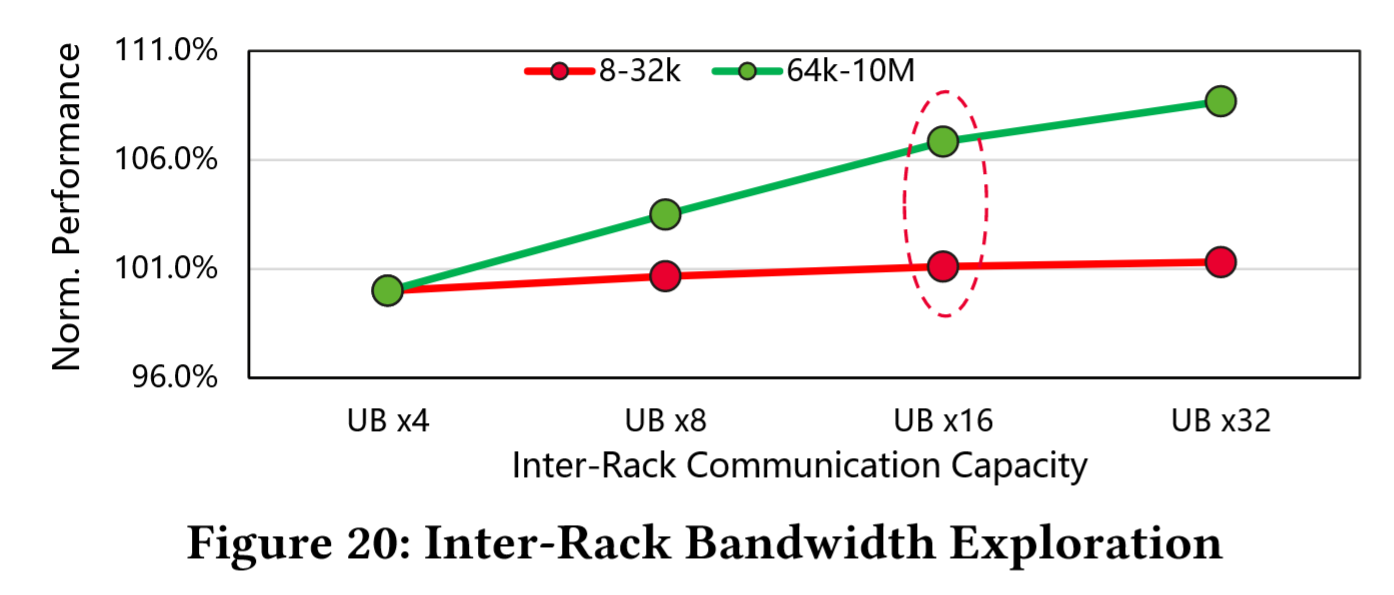
- Fig 20 比较了 8K SuperPod 在不同机架间带宽条件(每个 NPU 对应 x4、x8、x16 和 x32 UB IO)的吞吐性能:
- 在 8K 至 32K 序列长度范围内,最佳机架间带宽为 UB x16;而在 64K 至 10M 序列长度范围内,最佳机架间带宽则为 UB x32。
- 将机架间带宽从 UB x8 提升至 UB x16 时,8K-32K 序列长度区间的性能增益仅为 0.44%;而将带宽从 UB x16 提升至 UB x32 时,64K-10M 序列长度区间的性能增益更为显著,达到 1.85%。
- 当序列长度处于 64K 至 10M 范围时,部分 TP(张量并行)和 SP(序列并行)流量必然经过机架间链路。更高的机架间带宽能显著降低 TP 与 SP 的通信耗时,从而在这些场景中产生更明显的性能提升。该数据印证了根据不同模型场景的序列长度需求匹配机架间带宽的重要性,尤其对于降低大规模模型中 TP/SP 通信延迟具有关键意义。
UB-Mesh 默认分配每个 NPU x16 UB IO 用于机架间通信,以实现成本与性能的平衡。还可调整机架内/间带宽比例,以满足特定 LLM 训练工作负载的需求。
Cost-Efficiency Comparison
系统成本通常以 TCO(=OpEx+CapEx)衡量,考虑到训练性能,则成本效率计算公式为:
成本构成: 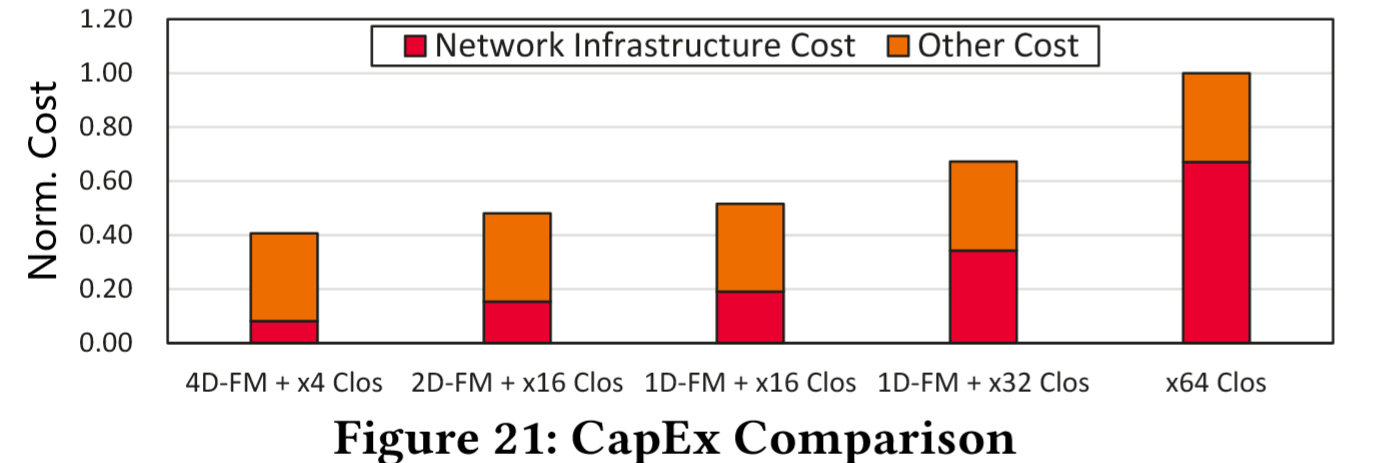
相较于 2D-FM+x16 Clos(表示每 NPU 配备 UB x16 IO)、1D-FM+x16 Clos 以及 x64T Clos 架构,UBMesh 的 4D-FM+Clos 架构分别实现了 1.18 倍、1.26 倍、1.65 倍和 2.46 倍的 CapEx 降低。
运营支出(OpEx)的降低主要来自系统生命周期内的电费与维护成本,得益于交换机与光模块用量的显著减少,UB-Mesh 较 Clos 架构实现约 35%的运营支出节约。
根据云事业部对 AI 系统的测算,运营支出约占总体拥有成本(TCO)的 30%。最终依据公式 1 计算,UB-Mesh 实现了 2.04 倍的成本效益提升。
节省来源:UB-Mesh 通过节省高性能交换机和长距光缆/光模块,成功将系统内网络基础设施成本占比从 67%压缩至 20%
- 交换机:减少 98% HRS 和 50% LRS。
- 光模块:减少 93%长距光连接,以电直连替代。
- 电缆:被动电缆占比 86.7%(成本低于主动电缆/光缆)。
Linearity Evaluation
线性度指的是 AI 集群能够提供的性能与 NPU 数量的线性程度:
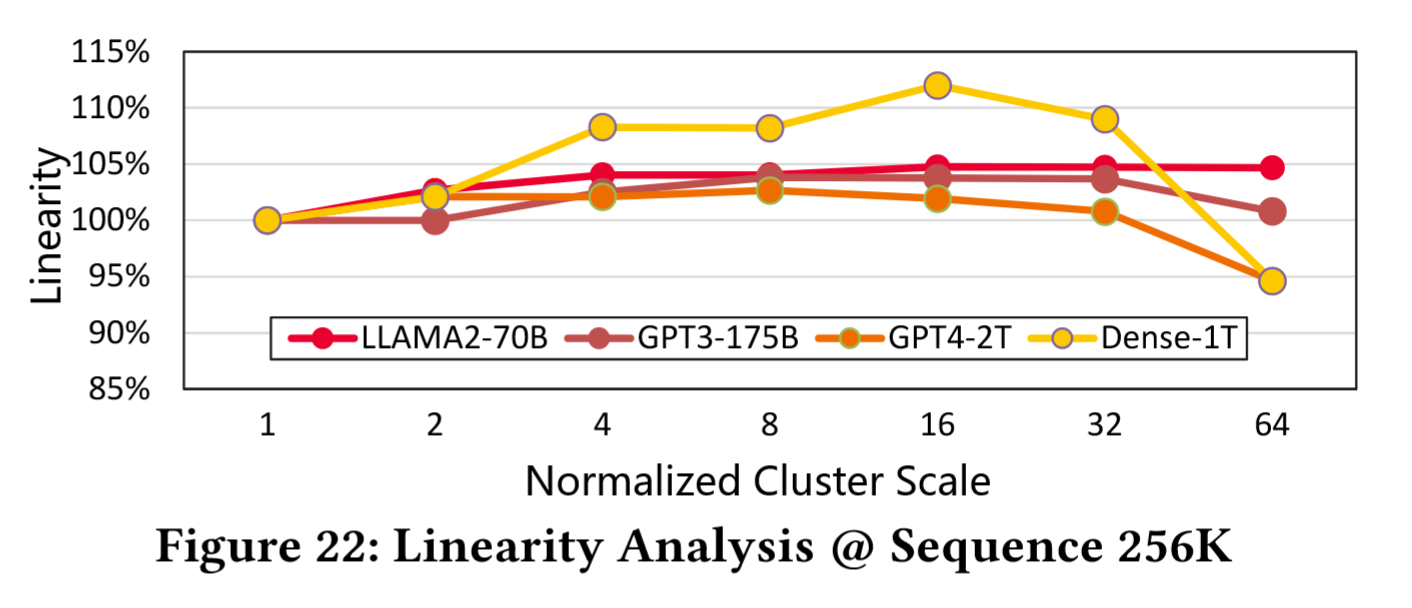 测试方法:测量每 NPU 在不同集群规模下吞吐量的保持率。基准规模(图中的 1x)因模型任务而异——LLAMA2-70B 采用 128 个 NPU,GPT3-175B 的基准规模为 512 个 NPU,Dense-1T 与 GPT4-2T 则使用 1K 个 NPU。
测试方法:测量每 NPU 在不同集群规模下吞吐量的保持率。基准规模(图中的 1x)因模型任务而异——LLAMA2-70B 采用 128 个 NPU,GPT3-175B 的基准规模为 512 个 NPU,Dense-1T 与 GPT4-2T 则使用 1K 个 NPU。
关键结论:
- 在 1×至 32×规模范围内,UB-Mesh 在所有任务上的线性度均超过 100%,这是因为规模扩大提供了更多高带宽域(前文提到的拓扑感知并行优化的策略,将高通信量操作(TP/SP)限制在局部域,减少全局通信干扰),同时高带宽域可以充分探索更优并行策略以提升 MFU(Model Flops Utilization)。
- 当规模扩展至 64×(涉及 64K 个 NPU)时,GPT4-2T 和 Dense-1T 模型的线性度有所下降,但仍保持在 95%以上,仍显著优于 Clos(传统方案在 32K 时线性度<85%)。
Network Reliability Analysis
基于时间的系统可用性度量为:
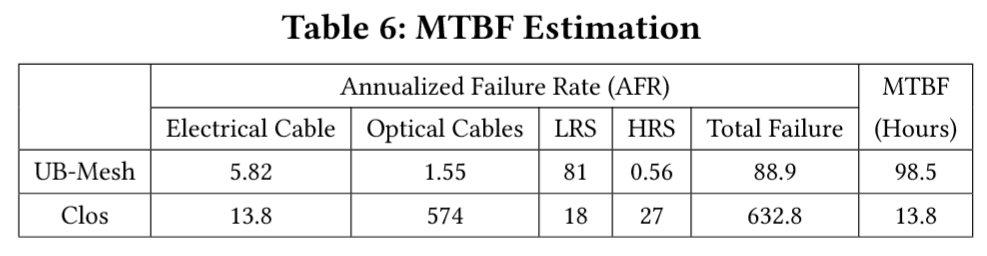
如 Table 6 估算所示,优先采用直连电力线缆(E-Cables)而非光纤与交换机的方案,可大幅降低网络模块的年化故障率(AFR)。据此可计算两种架构的 MTBF:基线 Clos 架构在 8K-NPU 集群中为 13.8 小时,而 UB-Mesh 达到 98.5 小时,实现 7.14 倍提升。根据公式 3 计算(基于现有统计数据假设平均修复时间 MTTR 为 75 分钟),UB-Mesh 的可用性最终达到 98.8%,显著优于 Clos 架构的 91.6%(提升 7.2%)。
为进一步提高可用性,华为还精心开发了内部网络监控工具,可在 10 分钟内快速识别定位网络故障,并在 3 分钟内触发任务迁移,从而大幅降低 MTTR。经评估,通过此项 MTTR 优化,UB-Mesh 的可用性可进一步提升至 99.78%。
总结:相比基线 Clos 架构,UB-Mesh 以轻微性能损失(7%以内)为代价,实现 2.04 倍成本效益提升。通过大幅减少交换机与光模块使用,UB-Mesh 将网络可用性提高 7.2%。在多项 LLM 训练任务中,UB-Mesh 还实现了 95%以上的线性度。
| 性能优势 | UB-Mesh 独到设计 |
|---|---|
| 低延迟高带宽 | nD-FullMesh 直连(1-2 跳) vs Clos 多跳交换;电直连占比 86.7%,减少光模块延迟。 |
| 成本效益 | 减少 98% HRS 和 93%光模块;UB 总线集成降低协议转换与硬件冗余。 |
| 高线性度 | 拓扑感知并行化(局部域优先) + APR 多路径负载均衡,避免拥塞导致的扩展效率下降。 |
| 快速故障恢复 | 64+1 备份 NPU + 直接通知机制,MTTR 从 75 分钟(Clos)降至 3 分钟,可用性提升 7.2%。 |
| 无死锁通信 | TFC 算法通过 VL 划分与拓扑分解,确保 APR 多路径下的无死锁运行,支持高吞吐量。 |