Introduction
DeepEP 是一个专门为 MoE 和专家并行(EP)定制的通信库。它为 all-to-all 连接的 GPU 内核提供高吞吐量和低延迟(即所谓的 MoE 调度和组合)。该库还支持低精度操作,包括 FP8。
为了与 DeepSeek-V3 论文中提出的 组限制门控算法(group-limited gating algorithm)保持一致,DeepEP 提供了一组针对非对称域带宽转发(asymmetric-domain bandwidth forwarding)进行优化的内核,例如将数据从 NVLink 域转发到 RDMA 域。这些内核提供了高吞吐量,使它们适合于训练和推理预填充任务。此外,它们支持 SM(Streaming Multiprocessor)编号控制。
对于延迟敏感的推理解码,DeepEP 包含了一组具有纯 RDMA 的低延迟内核,以最小化延迟。该库还引入了一种 hook-based 的 通信-计算 重叠 方法,该方法不占用任何 SM 资源。
Network Configurations
DeepEP 通过 InfiniBand 网络进行了全面测试。然而,它在理论上也与 RDMA over Converged Ethernet(RoCE)兼容。
Traffic Isolation
InfiniBand 通过虚通道(Virtual Lanes)支持流量隔离。
为了防止不同类型的流量之间的干扰,建议按如下方式跨不同的虚拟通道隔离工作负载:
- 使用普通内核的工作负载
- 使用低延迟内核的工作负载
- 其他工作负载
对于 DeepEP,可以通过设置
NVSHMEM_IB_SL环境变量来控制虚拟通道的指定。
Adaptive Routing
自适应路由是 InfiniBand 交换机提供的高级路由功能,可以在多条路径上均匀分布流量。目前,低延迟内核支持自适应路由,而普通内核不支持——为正常的节点间内核启用自适应路由可能会导致死锁或数据损坏问题。
对于低延迟内核,启用自适应路由可以完全消除路由冲突导致的网络拥塞,但它也会引入额外的延迟。我们建议使用以下配置以获得最佳性能:
- 在网络负载繁重的环境中启用自适应路由
- 在网络负载较轻的环境中使用静态路由
Congestion Control
拥塞控制被禁用,因为我们在生产环境中没有观察到明显的拥塞。
Interfaces and Examples
Example Usage in Training or Inferernce Prefilling
模型训练或推理时预填充阶段(不包含反向传递部分)会用到普通内核,示例代码如下:
import torch
import torch.distributed as dist
from typing import List, Tuple, Optional, Union
from deep_ep import Buffer, EventOverlap
# Communication buffer (will allocate at runtime)
_buffer: Optional[Buffer] = None
# Set the number of SMs to use
# NOTES: this is a static variable
Buffer.set_num_sms(24)
# You may call this function at the framework initialization
def get_buffer(group: dist.ProcessGroup, hidden_bytes: int) -> Buffer:
global _buffer
# NOTES: you may also replace `get_*_config` with your auto-tuned results via all the tests
num_nvl_bytes, num_rdma_bytes = 0, 0
for config in (Buffer.get_dispatch_config(group.size()), Buffer.get_combine_config(group.size())):
num_nvl_bytes = max(config.get_nvl_buffer_size_hint(hidden_bytes, group.size()), num_nvl_bytes)
num_rdma_bytes = max(config.get_rdma_buffer_size_hint(hidden_bytes, group.size()), num_rdma_bytes)
# Allocate a buffer if not existed or not enough buffer size
# NOTES: the adaptive routing configuration of the network **must be off**
if _buffer is None or _buffer.group != group or _buffer.num_nvl_bytes < num_nvl_bytes or _buffer.num_rdma_bytes < num_rdma_bytes:
_buffer = Buffer(group, num_nvl_bytes, num_rdma_bytes)
return _buffer
def get_hidden_bytes(x: torch.Tensor) -> int:
t = x[0] if isinstance(x, tuple) else x
return t.size(1) * max(t.element_size(), 2)
def dispatch_forward(x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],
topk_idx: torch.Tensor, topk_weights: torch.Tensor,
num_experts: int, previous_event: Optional[EventOverlap] = None) -> \
Tuple[Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], torch.Tensor, torch.Tensor, List, Tuple, EventOverlap]:
# NOTES: an optional `previous_event` means a CUDA event captured that you want to make it as a dependency
# of the dispatch kernel, it may be useful with communication-computation overlap. For more information, please
# refer to the docs of `Buffer.dispatch`
global _buffer
# Calculate layout before actual dispatch
num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, previous_event = \
_buffer.get_dispatch_layout(topk_idx, num_experts,
previous_event=previous_event, async_finish=True,
allocate_on_comm_stream=previous_event is not None)
# Do MoE dispatch
# NOTES: the CPU will wait for GPU's signal to arrive, so this is not compatible with CUDA graph
# For more advanced usages, please refer to the docs of the `dispatch` function
recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event = \
_buffer.dispatch(x, topk_idx=topk_idx, topk_weights=topk_weights,
num_tokens_per_rank=num_tokens_per_rank, num_tokens_per_rdma_rank=num_tokens_per_rdma_rank,
is_token_in_rank=is_token_in_rank, num_tokens_per_expert=num_tokens_per_expert,
previous_event=previous_event, async_finish=True,
allocate_on_comm_stream=True)
# For event management, please refer to the docs of the `EventOverlap` class
return recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event
def dispatch_backward(grad_recv_x: torch.Tensor, grad_recv_topk_weights: torch.Tensor, handle: Tuple) -> \
Tuple[torch.Tensor, torch.Tensor, EventOverlap]:
global _buffer
# The backward process of MoE dispatch is actually a combine
# For more advanced usages, please refer to the docs of the `combine` function
combined_grad_x, combined_grad_recv_topk_weights, event = \
_buffer.combine(grad_recv_x, handle, topk_weights=grad_recv_topk_weights, async_finish=True)
# For event management, please refer to the docs of the `EventOverlap` class
return combined_grad_x, combined_grad_recv_topk_weights, event
def combine_forward(x: torch.Tensor, handle: Tuple, previous_event: Optional[EventOverlap] = None) -> \
Tuple[torch.Tensor, EventOverlap]:
global _buffer
# Do MoE combine
# For more advanced usages, please refer to the docs of the `combine` function
combined_x, _, event = _buffer.combine(x, handle, async_finish=True, previous_event=previous_event,
allocate_on_comm_stream=previous_event is not None)
# For event management, please refer to the docs of the `EventOverlap` class
return combined_x, event
def combine_backward(grad_combined_x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],
handle: Tuple, previous_event: Optional[EventOverlap] = None) -> \
Tuple[Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], EventOverlap]:
global _buffer
# The backward process of MoE combine is actually a dispatch
# For more advanced usages, please refer to the docs of the `combine` function
grad_x, _, _, _, _, event = _buffer.dispatch(grad_combined_x, handle=handle, async_finish=True,
previous_event=previous_event,
allocate_on_comm_stream=previous_event is not None)
# For event management, please refer to the docs of the `EventOverlap` class
return grad_x, event更进一步,在 dispatch 函数中,可能不知道具体有多少个 token 会在当前 rank 中接收,因此会涉及到隐式的 CPU 等待 GPU 接收计数的信号,如下图所示:
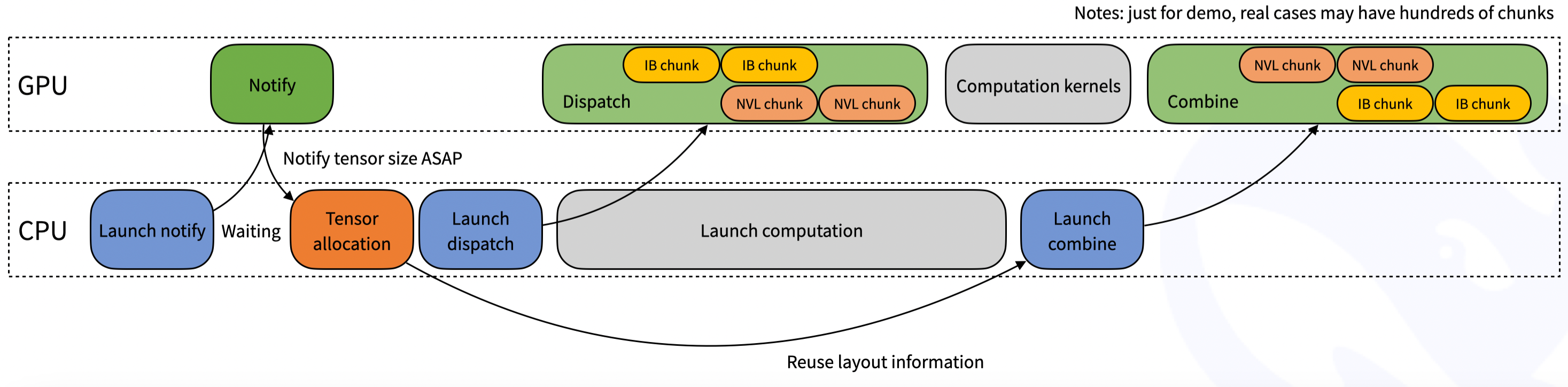
Example Usage in Inference Decoding
在推理解码阶段会使用到低延时内核,示例代码如下:
import torch
import torch.distributed as dist
from typing import Tuple, Optional
from deep_ep import Buffer
# Communication buffer (will allocate at runtime)
# NOTES: there is no SM control API for the low-latency kernels
_buffer: Optional[Buffer] = None
# You may call this function at the framework initialization
def get_buffer(group: dist.ProcessGroup, num_max_dispatch_tokens_per_rank: int, hidden: int, num_experts: int) -> Buffer:
# NOTES: the low-latency mode will consume much more space than the normal mode
# So we recommend that `num_max_dispatch_tokens_per_rank` (the actual batch size in the decoding engine) should be less than 256
global _buffer
num_rdma_bytes = Buffer.get_low_latency_rdma_size_hint(num_max_dispatch_tokens_per_rank, hidden, group.size(), num_experts)
# Allocate a buffer if not existed or not enough buffer size
if _buffer is None or _buffer.group != group or not _buffer.low_latency_mode or _buffer.num_rdma_bytes < num_rdma_bytes:
# NOTES: for best performance, the QP number **must** be equal to the number of the local experts
assert num_experts % group.size() == 0
_buffer = Buffer(group, 0, num_rdma_bytes, low_latency_mode=True, num_qps_per_rank=num_experts // group.size())
return _buffer
def low_latency_dispatch(hidden_states: torch.Tensor, topk_idx: torch.Tensor, num_max_dispatch_tokens_per_rank: int, num_experts: int):
global _buffer
# Do MoE dispatch, compatible with CUDA graph (but you may restore some buffer status once you replay)
recv_hidden_states, recv_expert_count, handle, event, hook = \
_buffer.low_latency_dispatch(hidden_states, topk_idx, num_max_dispatch_tokens_per_rank, num_experts,
async_finish=False, return_recv_hook=True)
# NOTES: the actual tensor will not be received only if you call `hook()`,
# it is useful for double-batch overlapping, but **without any SM occupation**
# If you don't want to overlap, please set `return_recv_hook=False`
# Later, you can use our GEMM library to do the computation with this specific format
return recv_hidden_states, recv_expert_count, handle, event, hook
def low_latency_combine(hidden_states: torch.Tensor,
topk_idx: torch.Tensor, topk_weights: torch.Tensor, handle: Tuple):
global _buffer
# Do MoE combine, compatible with CUDA graph (but you may restore some buffer status once you replay)
combined_hidden_states, event_overlap, hook = \
_buffer.low_latency_combine(hidden_states, topk_idx, topk_weights, handle,
async_finish=False, return_recv_hook=True)
# NOTES: the same behavior as described in the dispatch kernel
return combined_hidden_states, event_overlap, hook对于两个 micro-batch 重叠,可以参考下图。通过接收挂钩接口,RDMA 网络流量在后台生成,而不会从计算部分消耗任何 GPU SM。但请注意,重叠部分可能会发生变化,即 attention/dispatch/MoE/combine 的 4 个部分可能没有完全相同的执行时间。使用者需要根据工作负载调整流水线阶段的设置。
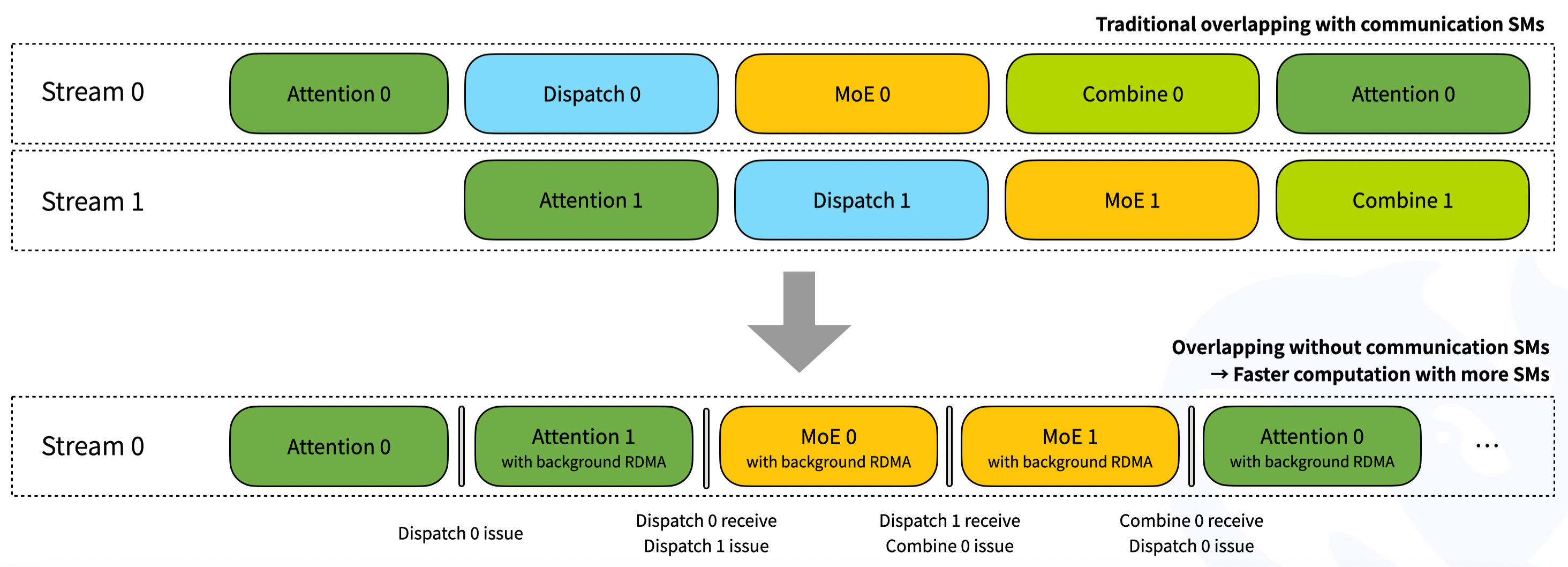
Notice
- 为了获得极高的性能,DS 团队发现并使用文档外的行为 PTX(Parallel Thread Execution)指令:
ld.global.nc.L1::no_allocate.L2::256B。此指令将导致未定义的行为:使用非相干的只读 PTX 修饰符.nc访问易失的 GPU 内存。但正确性已通过测试来保证。L1::no_allocate在 Hopper 架构上性能将更好。如果发现内核不能在某些其他平台上工作,可以将 DISABLE_AGGRESSIVE_PTX_INSTRS=1 添加到 setup. py 并禁用该选项,或者提交问题。 - 为了在集群上获得更好的性能,我们建议运行所有测试并使用最佳的自动调整配置。默认配置在 DeepSeek 的内部集群上进行了优化。
Investigation
kernels/ 文件树介绍
总体结构:
intranode.cu: 处理单个节点内的专家并行通信,利用 NVLink 实现高速数据传输。runtime.cu: 提供一些辅助函数,例如类型转换、内存操作等,供其他内核调用。internode.cu: 处理跨节点间的专家并行通信,利用 RDMA 实现数据传输。internode_ll.cu: 提供低延迟跨节点通信的内核,同样基于 RDMA。api.cuh,configs.cuh,exception.cuh: 头文件,定义了内核 API、配置结构和异常处理机制。
优化目标和实现策略:
- 高吞吐量 (High Throughput) : 尽可能提高单位时间内的数据传输量。
- 低延迟 (Low Latency) : 尽可能缩短数据传输的完成时间。
- 低精度支持 (FP8 Support) : 支持 FP8 数据类型,以减少内存占用和计算量。
- 通信与计算重叠 (Communication-Computation Overlap) : 隐藏通信延迟,提高整体效率。
- 灵活的 SM 控制 (SM Number Control) : 允许用户控制内核使用的 SM 数量,以适应不同的硬件配置和工作负载。
MoE 的 EP 存在哪些问题
- 通信开销:每个 Expert 可能分布在不同设备上,所以需要跨设备进行通信,特别是 all-to-all 通信模式下,通信开销会引入巨大负担;
- 负载均衡问题:在 Token 路由到不同专家时,如果分配不当,就会导致某些 Expert 过热,而某些遇冷,在训练阶段还会导致过热专家“过拟合”问题;
- 动态路由自身限制:MoE 模型中,token 在选择专家时,超过专家的容量就会 drop 掉多余的 token,从而导致训练效果变差。
涉及的并行策略
-
Intra-node 高吞吐量通信:
- 使用 NVLink 进行节点内全对全通信,适用于高带宽需求的场景。
- 通过
Buffer类的dispatch和combine方法实现。
-
Internode 高吞吐量通信:
- 使用 RDMA(Remote Direct Memory Access)进行节点间全对全通信。
- 支持高吞吐量场景,适用于大规模分布式训练。
-
低延迟通信:
- 使用 RDMA 的 IBGDA(InfiniBand Global Device Access)功能,支持低延迟的 all-to-all 通信。
- 适用于推理解码任务,强调快速响应。
-
混合通信:
- 在同一节点内的通信使用 NVLink,跨节点通信使用 RDMA。
- 通过
Buffer类的internode_dispatch和internode_combine方法实现。
涉及的集合通信
-
All-to-All 通信:
- Intranode:通过 NVLink 实现节点内的 all-to-all 通信,使用
ipc_handles共享内存,通过dist.all_gather_object快速同步。 - Internode:通过 RDMA 实现节点间的 all-to-all 通信,在
notify_dispatch内核中,通过nvshmem_int_put_nbi跨节点广播元数据,减少同步开销。 - 代码中通过
Buffer类的dispatch和combine方法实现。
- Intranode:通过 NVLink 实现节点内的 all-to-all 通信,使用
-
点对点通信:
- 在低延迟模式下,通过 RDMA 的 IBGDA 功能实现点对点通信。
- 代码中通过
Buffer类的low_latency_dispatch和low_latency_combine方法实现。
-
同步机制:
- 使用 CUDA 事件(
torch.cuda.Event)和EventOverlap类来管理通信和计算的重叠。 - 通过
Buffer类的capture方法捕获 CUDA 事件。
- 使用 CUDA 事件(
-
动态负载均衡:
- 在
get_dispatch_layout内核中,统计各专家和Rank的令牌分布(num_tokens_per_expert和num_tokens_per_rank),动态调整数据分区。
- 在
Technical Details
如何支持低精度操作?
-
FP8 和 BF16 数据类型:
- 在低延迟模式下,支持 FP8 和 BF16 数据类型。例如,在
low_latency_dispatch和low_latency_combine方法中,输入和输出张量支持torch.bfloat16和torch.float8_e4m3fn,这些张量来自 FP8 量化。
- 在低延迟模式下,支持 FP8 和 BF16 数据类型。例如,在
-
量化和反量化:
- 在低延迟模式下,数据在传输前会被量化为低精度格式(如 FP8),以减少通信开销。在接收端,数据会被反量化回高精度格式(如 BF16)。
low_latency_dispatch的输出recv_x是float8_e4m3fn类型,配合packed_recv_x_scales(torch.float)存储动态缩放因子,实现混合精度通信。数据在传输前被量化为FP8,接收端通过反量化恢复为BF16。内核自动处理 BF16 到 FP8 的转换,无需显式调用量化函数,减少计算开销。
DeepEP 内核针对非对称带宽转发的处理
DeepEP 通信库通过以下方式优化非对称带宽转发:
-
IBGDA(InfiniBand Global Device Access):
- 在低延迟模式下,启用 IBGDA 功能,允许 GPU 直接访问远程 GPU 的内存,避免数据包在 NVLink 和 RDMA 之间的转发。
- 利用
NVSHMEM的 GPU 直接 RDMA 特性,绕过 CPU,实现 GPU 内存到远程 GPU 内存的直接传输。通过设置环境变量NVSHMEM_IB_ENABLE_IBGDA=1和NVSHMEM_IBGDA_NIC_HANDLER=gpu实现。 - 零拷贝与流水线:在
dispatch 内核中,使用 使用nvshmemx_int8_put_nbi_wa 非阻塞写入,结合循环展开(环展开(#pragma unroll)实现数据流水线,最大化带宽利用率。
-
禁用自适应路由(AR):
- 在低延迟模式下,禁用自适应路由(AR),以避免数据包在 NVLink 和 RDMA 之间的转发。
- 通过设置环境变量
NVSHMEM_DISABLE_P2P=1实现。
-
QP(Queue Pair)深度优化:
- 设置较大的 QP 深度(如
NVSHMEM_QP_DEPTH=1024),以确保 QP 槽位足够,避免等待 WQ(Work Queue)槽位检查。 - 内存对齐:通过
expert_alignment参数对齐本地专家的 token 数,减少内存碎片和访存开销。
- 设置较大的 QP 深度(如
-
双缓冲策略:
num_nvl_bytes(NVLink缓冲区)和num_rdma_bytes(RDMA缓冲区)分离,确保高带宽设备间通信(NVLink)和跨节点通信(RDMA)互不干扰。
不同种类 Kernel 的分工
-
Normal Kernel:
- 适用场景:训练和推理预填充任务。
- 批量处理:通过
get_dispatch_config选择大块参数(如Config(24, 8, 288, 32, 128)),优化SM占用率,适合密集计算。 - NVLink优化:在
intranode_dispatch中,通过ipc_handles共享内存,减少跨节点通信,最大化NVLink吞吐。 - 特点:
- 支持较大的数据量和复杂的通信模式。
- 适用于需要高吞吐量的场景。
- 使用 NVLink 和 RDMA 进行通信,支持自适应路由(AR)。
- 代码中通过
Buffer类的dispatch和combine方法实现。
-
Low-Latency Kernel:
- 适用场景:推理解码任务。
- 细粒度通信:在
low_latency_dispatch中,每个令牌独立分配RDMA缓冲区,支持单令牌级通信,减少等待时间。 - IBGDA直连:跳过NVLink,直接通过RDMA传输,避免节点内转发延迟(见
nvshmem_barrier_with_same_gpu_idx)。 - 特点:
- 强调低延迟和快速响应。
- 使用 RDMA 的 IBGDA 功能,禁用自适应路由(AR)。
- 适用于需要快速处理少量数据的场景。
- 代码中通过
Buffer类的low_latency_dispatch和low_latency_combine方法实现。
| 特性 | Normal Kernel | Low-latency Kernel |
|---|---|---|
| 适用场景 | 训练、推理预填充(大批次) | 推理解码(小批次、低延迟) |
| 同步机制 | 需要显式事件同步(EventOverlap) | 隐式异步,通过hook触发接收 |
| SM占用 | 使用SM进行数据整理(如前缀和计算) | 完全卸载到RDMA硬件,不占用SM |
| 带宽利用率 | 高吞吐(NVLink全带宽) | 低延迟(RDMA最小化往返时间) |
| 数据流 | 需要完整前缀矩阵计算 | 预分配固定大小缓冲区,动态索引 |
Hook-based 的通信-计算重叠方法
-
实现位置:
- Python层:
buffer.py的low_latency_dispatch返回hook函数,用户可手动触发数据接收。 - 在
low_latency_dispatch和low_latency_combine方法中,返回一个hook函数,用于在需要时触发数据接收。设置return_recv_hook=True时,延迟实际数据接收,通信仅发起 RDMA 请求,不等待数据到达。 - CUDA层:在
internode.cu的low_latency_dispatch内核中,通过nvshmem_put_nbi非阻塞操作发起请求,后续由hook调用nvshmem_quiet等待完成。
- Python层:
-
为什么能够不占用任何 SM 资源:
- 硬件卸载:利用RDMA网卡的硬件卸载能力,数据传输由网卡直接完成,无需GPU参与。
- 异步通信:
hook函数仅在需要时显式触发数据接收,通信操作在后台异步进行,不占用 GPU 的 SM(Streaming Multiprocessor)资源。SM仅记录事件(如EventOverlap) - CPU 控制:
hook函数在 CPU 上运行,不涉及 GPU 的计算资源。 - 双缓冲机制:通过双缓冲机制,通信和计算可以在不同的缓冲区中并行进行,避免资源冲突。
- 预分配缓冲区 :低延迟模式使用固定大小缓冲区(
num_max_dispatch_tokens_per_rank),避免动态内存操作。 - 无前缀计算 :通过预定义布局(
packed_recv_layout_range)直接索引,省去SM密集的前缀和计算。 - 事件回调机制:
hook通过CUDA事件(如cudaEventRecord)通知计算流,无需SM主动轮询,释放计算资源。
未定义行为的极限优化
V3 论文中提到:
In addition, both dispatching and combining kernels overlap with the computation stream, so we also consider their impact on other SM computation kernels. Specifically, we employ customized PTX (Parallel Thread Execution) instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs.
在 DeepEP 的 utils.cuh 文件中,利用 UB 代码对 L2 缓存做出的优化:
#ifndef DISABLE_AGGRESSIVE_PTX_INSTRS
#define LD_NC_FUNC "ld.global.nc.L1::no_allocate.L2::256B" // 关键优化点
#else
#define LD_NC_FUNC "ld.volatile.global"
#endif
template <>
__device__ __forceinline__ int ld_nc_global(const int *ptr) {
int ret;
asm volatile(LD_NC_FUNC ".s32 %0, [%1];" : "=r"(ret) : "l"(ptr));
return ret;
}这段代码是自定义的内存加载指令优化,控制数据在 GPU 内存层级间的流动方式,减少 L2 cache 的使用。
ld.global.nc.L1::no_allocate.L2::256B 的含义:
ld.global表示从全局内存读取数据;nc表示非连贯读取;L1::no_allocate意思是不要把数据放在 L1 缓存L2::256B是使用 256 字节的 L2 cache
假设现在有一个 GPU 集群通信的场景,数据流向是:
GPU1---->GPU2---->GPU3,
数据需要经过 GPU2 进行转发。
未优化时的数据流:
- GPU1 发送数据到 GPU2:
数据 -> GPU2 L2 Cache -> GPU2 L1 Cache -> 读取处理 -> 写回L2 Cache- GPU2 转发到 GPU3:
L2 Cache中的数据 -> 读取 -> 发送到GPU3问题:
- 数据在 L2 缓存中占用空间
- 其他 SM 在做计算时,需要用 L2 缓存存储中间结果
- 导致缓存冲突,计算性能下降
使用了优化后:
L1::no_allocate完全不使用 L1 缓存nc(non-coherent)跳过缓存一致性检查L2::256B只在 L2 中短暂停留,使用优化的块大小
这个场景的前提是,要识别出只需要使用一次的通信数据。然后为这些数据相当于开通了一个快速通道,进行处理,所以能提高效率。