本节导读
在上一节实现的二叠纪 “锯齿螈” 操作系统还是比较原始,一个应用会独占 CPU 直到它出错或主动退出。操作系统还是以程序的一次执行过程(从开始到结束)作为处理器切换程序的时间段。为了提高效率,我们需要引入新的操作系统概念 任务 、 任务切换 、任务上下文 。为此,我们需要实现从 “螈” 到“恐龙”的进化,实现 “始初龙” 操作系统。
如果把应用程序执行的整个过程进行进一步分析,可以看到,当程序访问 I/O 外设或睡眠时,其实是不需要占用处理器的,于是我们可以把应用程序在不同时间段的执行过程分为两类,占用处理器执行有效任务的计算阶段和不必占用处理器的等待阶段。这些阶段就形成了一个我们熟悉的 “暂停 - 继续…” 组合的控制流或执行历史。从应用程序开始执行到结束的整个控制流就是应用程序的整个执行过程。
本节的重点是操作系统的核心机制—— 任务切换 ,在内核中这种机制是在 __switch 函数中实现的。 任务切换支持的场景是:一个应用在运行途中便会主动或被动交出 CPU 的使用权,此时它只能暂停执行,等到内核重新给它分配处理器资源之后才能恢复并继续执行。有了任务切换的能力,“螈”级的操作系统才能跳出水坑,进入陆地,才有能力进化到 “恐龙” 级的操作系统。
任务的概念形成
如果操作系统能够在某个应用程序处于等待阶段的时候,把处理器转给另外一个处于计算阶段的应用程序,那么只要转换的开销不大,那么处理器的执行效率就会大大提高。当然,这需要应用程序在运行途中能主动交出 CPU 的使用权,此时它处于等待阶段,等到操作系统让它再次执行后,那它就可以继续执行了。
到这里,我们就
- 把应用程序的一次执行过程(也是一段控制流)称为一个 任务 ,
- 把应用执行过程中的一个时间片段上的执行片段或空闲片段称为 “ 计算任务片 ” 或 “ 空闲任务片 ” 。
- 当应用程序的所有任务片都完成后,应用程序的一次任务也就完成了。
- 从一个程序的任务切换到另外一个程序的任务称为 任务切换 。
- 为了确保切换后的任务能够正确继续执行,操作系统需要支持让任务的执行 “暂停” 和“继续”。
我们又看到了熟悉的 “暂停 - 继续” 组合。一旦一条控制流需要支持“暂停 - 继续”,就需要提供一种控制流切换的机制,而且需要保证程序执行的控制流被切换出去之前和切换回来之后,能够继续正确执行。这需要让程序执行的状态(也称上下文),即在执行过程中同步变化的资源(如寄存器、栈等)保持不变,或者变化在它的预期之内。
不是所有的资源都需要被保存,事实上只有那些对于程序接下来的正确执行仍然有用,且在它被切换出去的时候有被覆盖风险的那些资源才有被保存的价值。这些需要保存与恢复的资源被称为 任务上下文 (Task Context) 。
抽象与具体
注意:同学会在具体的操作系统设计实现过程中接触到一些抽象的概念,其实这些概念都是具体代码的结构和代码动态执行过程的文字表述而已。
不同类型的上下文与切换
在控制流切换过程中,我们需要结合硬件机制和软件实现来保存和恢复任务上下文。任务的一次切换涉及到被换出和即将被换入的两条控制流(分属两个应用的不同任务),通常它们都需要共同遵循某些约定来合作完成这一过程。在前两章,我们已经看到了两种上下文保存 / 恢复的实例。让我们再来回顾一下它们:
-
第一章 “应用程序与基本执行环境” 中,我们介绍了 函数调用与栈 。当时提到过,为了支持嵌套函数调用,不仅需要硬件平台提供特殊的跳转指令,还需要保存和恢复 函数调用上下文 。
- 注意在上述定义中,函数调用包含在普通控制流(与异常控制流相对)之内,且始终用一个固定的栈来保存执行的历史记录,因此函数调用并不涉及控制流的特权级切换。
- 但是我们依然可以将其看成调用者和被调用者两个执行过程的 “切换”,二者的协作体现在它们都遵循调用规范,分别保存一部分通用寄存器,这样的好处是编译器能够有足够的信息来尽可能减少需要保存的寄存器的数目。虽然当时用了很大的篇幅来说明,但其实整个过程都是编译器负责完成的,我们只需设置好栈就行了。
-
第二章 “批处理系统” 中第一次涉及到了某种异常(Trap)控制流,即两条控制流的特权级切换,需要保存和恢复 系统调用(Trap)上下文 。
- 当时,为了让内核能够 完全掌控 应用的执行,且不会被应用破坏整个系统,我们必须利用硬件提供的特权级机制,让应用和内核运行在不同的特权级。
- 应用运行在 U 特权级,它所被允许的操作进一步受限,处处被内核监督管理;而内核运行在 S 特权级,有能力处理应用执行过程中提出的请求或遇到的状况。
应用程序与操作系统打交道的核心在于硬件提供的 Trap 机制,也就是在 U 特权级运行的应用控制流和在 S 特权级运行的 Trap 控制流(操作系统的陷入处理部分)之间的切换。
- Trap 控制流是在 Trap 触发的一瞬间生成的,它和原应用控制流有着很密切的联系,因为它几乎唯一的目标就是处理 Trap 并恢复到原应用控制流。
- 而且,由于 Trap 机制对于应用来说几乎是透明的,所以基本上都是 Trap 控制流在 “负重前行”。Trap 控制流需要把 Trap 上下文(即几乎所有的通用寄存器)保存在自己的内核栈上,因为在 Trap 处理过程中所有的通用寄存器都可能被用到。可以回看 Trap 上下文保存与恢复 小节。
任务切换的设计与实现
本节所讲的任务切换是第二章提及的 Trap 控制流切换之外的另一种异常控制流,都是描述两条控制流之间的切换,如果将它和 Trap 切换进行比较,会有如下异同:
-
与 Trap 切换不同,它不涉及特权级切换;
-
与 Trap 切换不同,它的一部分是由编译器帮忙完成的;
-
与 Trap 切换相同,它对应用是透明的。
事实上,任务切换是来自两个不同应用在内核中的 Trap 控制流之间的切换。当一个应用 Trap 到 S 模式的操作系统内核中进行进一步处理(即进入了操作系统的 Trap 控制流)的时候,其 Trap 控制流可以调用一个特殊的 __switch 函数。这个函数表面上就是一个普通的函数调用:在 __switch 返回之后,将继续从调用该函数的位置继续向下执行。但是其间却隐藏着复杂的控制流切换过程。
- 具体来说,调用
__switch之后直到它返回前的这段时间,原 Trap 控制流 A 会先被暂停并被切换出去, CPU 转而运行另一个应用在内核中的 Trap 控制流 B 。 - 然后在某个合适的时机,原 Trap 控制流 A 才会从某一条 Trap 控制流 C (很有可能不是它之前切换到的 B ,既然有一次切换,自然可以出现多次切换)切换回来继续执行并最终返回。
不过,从实现的角度讲, ==__switch 函数和一个普通的函数之间的核心差别仅仅是它会 换栈== 。
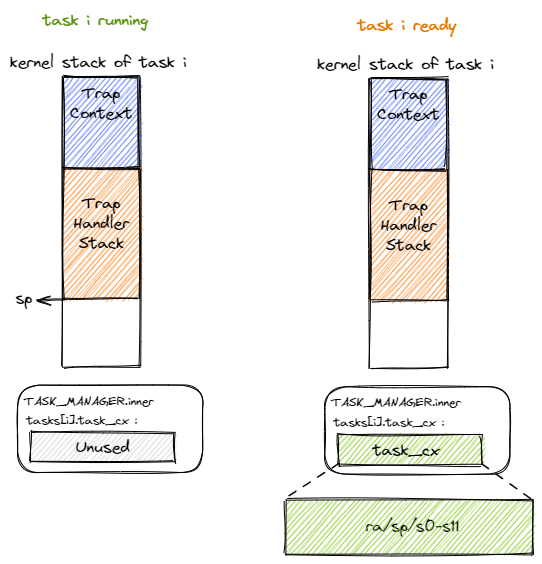
当 Trap 控制流准备调用 __switch 函数使任务从运行状态进入暂停状态的时候,让我们考察一下它内核栈上的情况。
- 如上图左侧所示,
- 在准备调用
__switch函数之前,内核栈上从栈底到栈顶分别是保存了应用执行状态的 Trap 上下文以及内核在对 Trap 处理的过程中留下的调用栈信息。 - 由于之后还要恢复回来执行,我们必须保存 CPU 当前的某些寄存器,我们称它们为 任务上下文 (Task Context)。我们会在稍后介绍里面需要包含哪些寄存器。
- 至于上下文保存的位置,下一节在我们会介绍任务管理器
TaskManager,在里面能找到一个数组tasks,其中的每一项都是一个任务控制块即TaskControlBlock,它负责保存一个任务的状态,而==任务上下文TaskContext被保存在任务控制块中==。 - 在内核运行时我们会初始化
TaskManager的全局实例TASK_MANAGER,==因此所有任务上下文实际保存在在TASK_MANAGER中,从内存布局来看则是放在内核的全局数据.data段中==。
- 在准备调用
- 当我们将任务上下文保存完毕之后则转化为下图右侧的状态。当要从其他任务切换回来继续执行这个任务的时候,CPU 会读取同样的位置并从中恢复任务上下文。
对于当前正在执行的任务的 Trap 控制流,我们
- 用一个名为
current_task_cx_ptr的变量来保存放置当前任务上下文的地址; - 而用
next_task_cx_ptr的变量来保存放置下一个要执行任务的上下文的地址。
利用 C 语言的引用来描述的话就是:
TaskContext *current_task_cx_ptr = &tasks[current].task_cx;
TaskContext *next_task_cx_ptr = &tasks[next].task_cx;
接下来我们同样从栈上内容的角度来看 __switch 的整体流程:
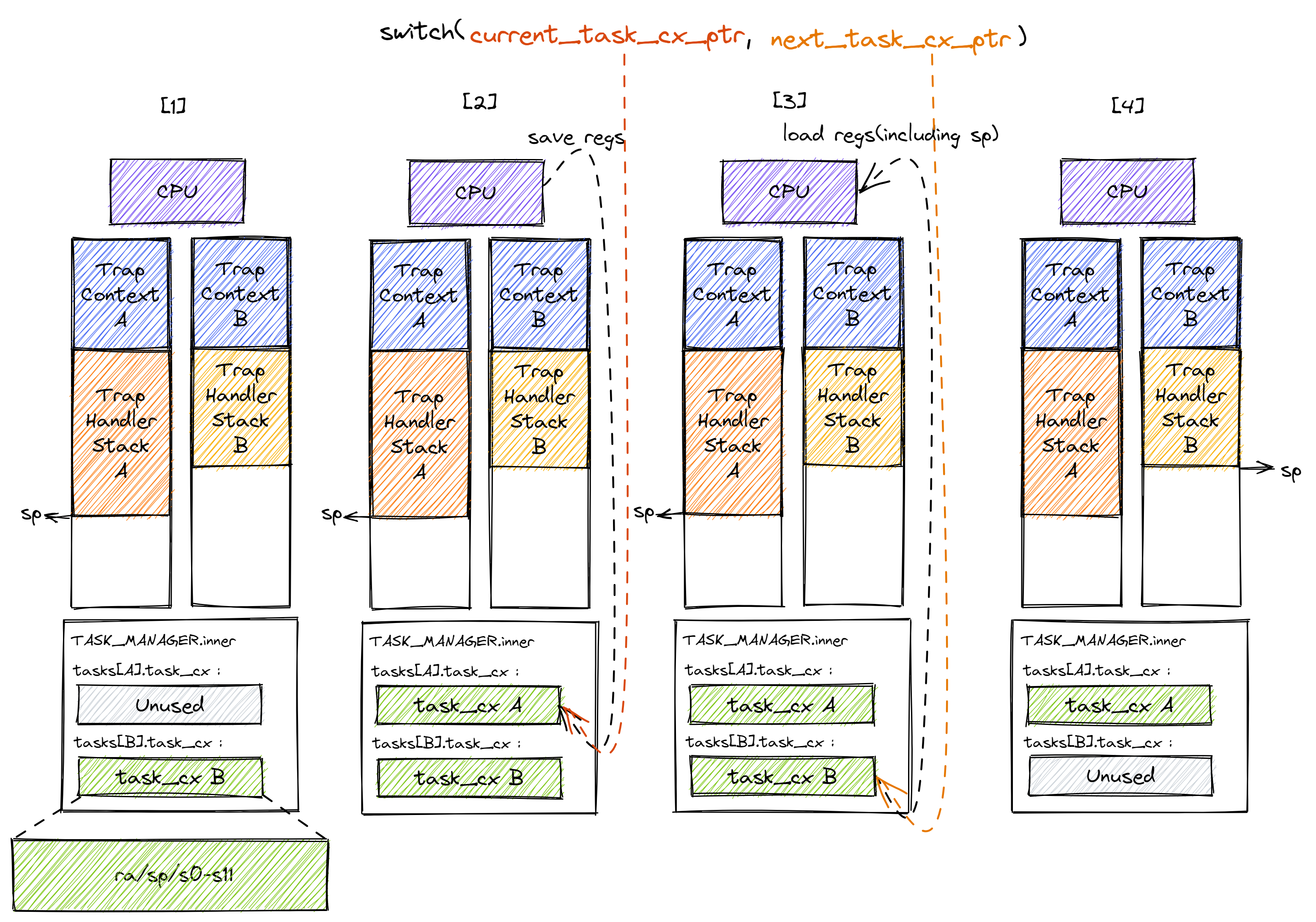
Trap 控制流在调用 __switch 之前就需要明确知道即将切换到哪一条目前正处于暂停状态的 Trap 控制流,因此 __switch 有两个参数,第一个参数代表它自己,第二个参数则代表即将切换到的那条 Trap 控制流。这里我们用上面提到过的 current_task_cx_ptr 和 next_task_cx_ptr 作为代表。
在上图中我们假设某次 __switch 调用要从 Trap 控制流 A 切换到 B,一共可以分为四个阶段,在每个阶段中我们都给出了 A 和 B 内核栈上的内容:
-
阶段 [1]:在 Trap 控制流 A 调用
__switch之前,A 的内核栈上只有 Trap 上下文和 Trap 处理函数的调用栈信息,而 B 是之前被切换出去的; -
阶段 [2]:A 在 A 任务上下文空间在里面保存 CPU 当前的寄存器快照;
-
阶段 [3]:这一步极为关键,==读取
next_task_cx_ptr指向的 B 任务上下文,根据 B 任务上下文保存的内容来恢复ra寄存器、s0~s11寄存器以及sp寄存器==。只有这一步做完后,__switch才能做到一个函数跨两条控制流执行,即 通过换栈也就实现了控制流的切换 。 -
阶段 [4]:上一步寄存器恢复完成后,==可以看到通过恢复
sp寄存器换到了任务 B 的内核栈上,进而实现了控制流的切换==。这就是为什么__switch能做到一个函数跨两条控制流执行。此后,当 CPU 执行ret汇编伪指令完成__switch函数返回后,任务 B 可以从调用__switch的位置继续向下执行。
从结果来看,我们看到 A 控制流 和 B 控制流的状态发生了互换, A 在保存任务上下文之后进入暂停状态,而 B 则恢复了上下文并在 CPU 上继续执行。
下面我们给出 __switch 的实现:
# os/src/task/switch.S
.altmacro
.macro SAVE_SN n
sd s\n, (\n+2)*8(a0)
.endm
.macro LOAD_SN n
ld s\n, (\n+2)*8(a1)
.endm
.section .text
.globl __switch
__switch:
# 阶段 [1]
# __switch(
# current_task_cx_ptr: *mut TaskContext,
# next_task_cx_ptr: *const TaskContext
# )
# 阶段 [2]
# save kernel stack of current task
sd sp, 8(a0)
# save ra & s0~s11 of current execution
sd ra, 0(a0)
.set n, 0
.rept 12
SAVE_SN %n
.set n, n + 1
.endr
# 阶段 [3]
# restore ra & s0~s11 of next execution
ld ra, 0(a1)
.set n, 0
.rept 12
LOAD_SN %n
.set n, n + 1
.endr
# restore kernel stack of next task
ld sp, 8(a1)
# 阶段 [4]
ret
我们手写汇编代码来实现 __switch 。
- 在阶段 [1] 可以看到它的函数原型中的两个参数分别是当前 A 任务上下文指针
current_task_cx_ptr和即将被切换到的 B 任务上下文指针next_task_cx_ptr,从 RISC-V 调用规范 可以知道它们分别通过寄存器a0/a1传入。 - 阶段 [2] 体现在第 19~27 行,即将当前 CPU 状态(包括
ra寄存器、s0~s11寄存器以及sp寄存器)保存到 A 任务上下文。 - 阶段 [3] 体现在第 29~37 行,即根据 B 任务上下文保存的内容来恢复上述 CPU 状态。从中我们也能够看出
TaskContext里面究竟包含哪些寄存器:
// os/src/task/context.rs
pub struct TaskContext {
ra: usize,
sp: usize,
s: [usize; 12],
}
保存 ra 很重要,==它记录了 __switch 函数返回之后应该跳转到哪里继续执行,从而在任务切换完成并 ret 之后能到正确的位置 (记录了返回地址)==。对于一般的函数而言,Rust/C 编译器会在函数的起始位置自动生成代码来保存 s0~s11 这些被调用者保存的寄存器。但== __switch 是一个用汇编代码写的特殊函数,它不会被 Rust/C 编译器处理,所以我们需要在 __switch 中手动编写保存 s0~s11 的汇编代码==。
不用保存其它寄存器是因为:其它寄存器中,属于调用者保存的寄存器是由编译器在高级语言编写的调用函数中自动生成的代码来完成保存的;还有一些寄存器属于临时寄存器,不需要保存和恢复。
我们会将这段汇编代码中的全局符号 __switch 解释为一个 Rust 函数:
// os/src/task/switch.rs
global_asm!(include_str!("switch.S"));
use super::TaskContext;
extern "C" {
pub fn __switch(
current_task_cx_ptr: *mut TaskContext,
next_task_cx_ptr: *const TaskContext
);
}
我们会调用该函数来完成切换功能而不是直接跳转到符号 __switch 的地址。因此在调用前后 Rust 编译器会自动帮助我们插入保存 / 恢复调用者保存寄存器的汇编代码。
仔细观察的话可以发现 ==TaskContext 很像一个普通函数栈帧中的内容。正如之前所说, __switch 的实现除了换栈之外几乎就是一个普通函数,也能在这里得到体现。尽管如此,二者的内涵却有着很大的不同==。
同学可以自行对照注释看看图示中的后面几个阶段各是如何实现的。另外,当内核仅运行单个应用的时候,无论该任务主动 / 被动交出 CPU 资源最终都会交还给自己,这将导致传给 __switch 的两个参数相同,也就是某个 Trap 控制流自己切换到自己的情形,请同学对照图示思考目前的实现能否对它进行正确处理。
评论区有价值的讨论
加深理解 ret 指令
Q:有个不太理解的地方,TaskContext 保存了 s 寄存器,而这些寄存器都保存在 TrapContext 里,__switch 的时候恢复了 TaskContext,之后又跳到 __restore 恢复了 TrapContext,所以 TaskContext 保存的 s 寄存器实际没有起到作用吧?
A:TrapContext 中保存的寄存器记录了应用陷入 S 特权级之前的 CPU 状态,而 TaskContext 则可以看成一个应用在 S 特权级进行 Trap 处理的过程中调用__switch 之前的 CPU 状态。当恢复 TaskContext 之后会继续进行 Trap 处理,而__restore 恢复 TrapContext 之后则是会回到用户态执行应用。 另外,保存 TrapContext 之后进行 Trap 处理的时候,s0-s11寄存器可能会被覆盖,后面进行任务切换时这些寄存器会被保存到 TaskContext 中,也就是说这两个 Context 中的 s0-s11也很可能是不同的。
未进行内存回收
Q:有一点疑惑的地方:每次处理 trap 的时候从 call trap_handler 一直到__switch 函数执行,这中间的调用链是有一些压栈操作的,但是当一个 task exit 之后,就再也不会__switch 回来了,那么这个 task 对应的调用链里的栈空间就是无法再使用了是么?
A:你的理解是正确的。第二章为了简单起见,每个 task 的栈空间仅会被使用一次,对应的 task 退出之后就会永久闲置。等到第五章引入了进程之后,可以看到在进程退出之后,它的栈空间所在的物理内存会被回收并可以供其他进程使用。
为什么使用多个内核栈?
本章为了简要说明任务的切换,使用了多个内核栈,没有考虑任务共享内核栈的问题。有人设计了共享同一个内核栈的示例:main.rs
// src/main.rs
#![no_std]
#![no_main]
#![feature(naked_functions, asm_sym, asm_const)]
#![feature(default_alloc_error_handler)]
#![deny(warnings)]
mod mm;
mod process;
#[macro_use]
extern crate console;
#[macro_use]
extern crate alloc;
use crate::{
impls::{Sv39Manager, SyscallContext},
process::Process,
};
use alloc::vec::Vec;
use console::log;
use impls::Console;
use kernel_context::foreign::ForeignPortal;
use kernel_vm::{
page_table::{MmuMeta, Sv39, VAddr, VmFlags, PPN, VPN},
AddressSpace,
};
use riscv::register::*;
use sbi_rt::*;
use syscall::Caller;
use xmas_elf::ElfFile;
// 应用程序内联进来。
core::arch::global_asm!(include_str!(env!("APP_ASM")));
/// Supervisor 汇编入口。
///
/// 设置栈并跳转到 Rust。
#[naked]
#[no_mangle]
#[link_section = ".text.entry"]
unsafe extern "C" fn _start() -> ! {
const STACK_SIZE: usize = 6 * 4096;
#[link_section = ".bss.uninit"]
static mut STACK: [u8; STACK_SIZE] = [0u8; STACK_SIZE];
core::arch::asm!(
"la sp, {stack} + {stack_size}",
"j {main}",
stack_size = const STACK_SIZE,
stack = sym STACK,
main = sym rust_main,
options(noreturn),
)
}
static mut PROCESSES: Vec<Process> = Vec::new();
extern "C" fn rust_main() -> ! {
let layout = linker::KernelLayout::locate();
// bss 段清零
unsafe { layout.zero_bss() };
// 初始化 `console`
console::init_console(&Console);
console::set_log_level(option_env!("LOG"));
console::test_log();
// 初始化 syscall
syscall::init_io(&SyscallContext);
syscall::init_process(&SyscallContext);
syscall::init_scheduling(&SyscallContext);
syscall::init_clock(&SyscallContext);
// 初始化内核堆
mm::init();
mm::test();
// 建立内核地址空间
let mut ks = kernel_space(layout);
// 加载应用程序
for (i, elf) in linker::AppMeta::locate().iter().enumerate() {
let base = elf.as_ptr() as usize;
log::info!("detect app[{i}]: {base:#x}..{:#x}", base + elf.len());
if let Some(process) = Process::new(ElfFile::new(elf).unwrap()) {
unsafe { PROCESSES.push (process) };
}
}
// 异界传送门
// 可以直接放在栈上
let mut portal = ForeignPortal:: new ();
// 传送门映射到所有地址空间
map_portal (&mut ks, &portal);
unsafe {
PROCESSES
.iter_mut ()
.for_each (|proc| map_portal (&mut proc. address_space, &portal))
};
const PROTAL_TRANSIT: usize = VPN::<Sv39>:: MAX.base (). val ();
while !unsafe { PROCESSES. is_empty () } {
let ctx = unsafe { &mut PROCESSES[0]. context };
unsafe { ctx.execute (&mut portal, PROTAL_TRANSIT) };
match scause:: read (). cause () {
scause::Trap:: Exception (scause::Exception::UserEnvCall) => {
use syscall::{SyscallId as Id, SyscallResult as Ret};
let ctx = &mut ctx. context;
let id: Id = ctx.a (7). into ();
let args = [ctx.a (0), ctx.a (1), ctx.a (2), ctx.a (3), ctx.a (4), ctx.a (5)];
match syscall:: handle (Caller { entity: 0, flow: 0 }, id, args) {
Ret:: Done (ret) => match id {
Id:: EXIT => unsafe {
PROCESSES.remove (0);
},
_ => {
*ctx. a_mut (0) = ret as _;
ctx. move_next ();
}
},
Ret:: Unsupported (_) => {
log::info! ("id = {id:?}");
unsafe { PROCESSES.remove (0) };
}
}
}
e => {
log::error! ("unsupported trap: {e:?}");
unsafe { PROCESSES.remove (0) };
}
}
}
system_reset (Shutdown, NoReason);
unreachable! ()
}
/// Rust 异常处理函数,以异常方式关机。
#[panic_handler]
fn panic (info: &core::panic::PanicInfo) -> ! {
println! ("{info}");
system_reset (Shutdown, SystemFailure);
loop {}
}
fn kernel_space (layout: linker::KernelLayout) -> AddressSpace<Sv39, Sv39Manager> {
// 打印段位置
let text = VAddr::<Sv39>:: new (layout. text);
let rodata = VAddr::<Sv39>:: new (layout. rodata);
let data = VAddr::<Sv39>:: new (layout. data);
let end = VAddr::<Sv39>:: new (layout. end);
log::info! ("__text ----> {: #10x }", text.val ());
log::info! ("__rodata --> {: #10x }", rodata.val ());
log::info! ("__data ----> {: #10x }", data.val ());
log::info! ("__end -----> {: #10x }", end.val ());
println! ();
// 内核地址空间
let mut space = AddressSpace::<Sv39, Sv39Manager>:: new ();
space. map_extern (
text.floor ()..rodata.ceil (),
PPN:: new (text.floor (). val ()),
VmFlags:: build_from_str ("X_RV"),
);
space. map_extern (
rodata.floor ()..data.ceil (),
PPN:: new (rodata.floor (). val ()),
VmFlags:: build_from_str ("__RV"),
);
space. map_extern (
data.floor ()..end.ceil (),
PPN:: new (data.floor (). val ()),
VmFlags:: build_from_str ("_WRV"),
);
unsafe { satp:: set (satp::Mode:: Sv39, 0, space. root_ppn (). val ()) };
space
}
#[inline]
fn map_portal (space: &mut AddressSpace<Sv39, Sv39Manager>, portal: &ForeignPortal) {
const PORTAL: VPN<Sv39> = VPN:: MAX; // 虚地址最后一页给传送门
space. map_extern (
PORTAL.. PORTAL + 1,
PPN:: new (portal as *const _ as usize >> Sv39::PAGE_BITS),
VmFlags:: build_from_str ("XWRV"),
);
}
/// 各种接口库的实现。
mod impls {
use crate::{mm:: PAGE, PROCESSES};
use alloc::alloc:: handle_alloc_error;
use console:: log;
use core::{alloc:: Layout, num:: NonZeroUsize, ptr:: NonNull};
use kernel_vm::{
page_table::{MmuMeta, Pte, Sv39, VAddr, VmFlags, PPN, VPN},
PageManager,
};
use syscall::*;
#[repr (transparent)]
pub struct Sv39Manager (NonNull<Pte<Sv39>>);
impl Sv39Manager {
const OWNED: VmFlags<Sv39> = unsafe { VmFlags:: from_raw (1 << 8) };
}
impl PageManager<Sv39> for Sv39Manager {
#[inline]
fn new_root () -> Self {
const SIZE: usize = 1 << Sv39:: PAGE_BITS;
unsafe {
match PAGE.allocate (Sv39:: PAGE_BITS, NonZeroUsize:: new_unchecked (SIZE)) {
Ok ((ptr, _)) => Self (ptr),
Err (_) => handle_alloc_error (Layout:: from_size_align_unchecked (SIZE, SIZE)),
}
}
}
#[inline]
fn root_ppn (&self) -> PPN<Sv39> {
PPN:: new (self. 0. as_ptr () as usize >> Sv39::PAGE_BITS)
}
#[inline]
fn root_ptr (&self) -> NonNull<Pte<Sv39>> {
self. 0
}
#[inline]
fn p_to_v<T>(&self, ppn: PPN<Sv39>) -> NonNull<T> {
unsafe { NonNull:: new_unchecked (VPN::<Sv39>:: new (ppn.val ()). base (). as_mut_ptr ()) }
}
#[inline]
fn v_to_p<T>(&self, ptr: NonNull<T>) -> PPN<Sv39> {
PPN:: new (VAddr::<Sv39>:: new (ptr. as_ptr () as _). floor (). val ())
}
#[inline]
fn check_owned (&self, pte: Pte<Sv39>) -> bool {
pte.flags (). contains (Self::OWNED)
}
fn allocate (&mut self, len: usize, flags: &mut VmFlags<Sv39>) -> NonNull<u8> {
unsafe {
match PAGE.allocate (
Sv39:: PAGE_BITS,
NonZeroUsize:: new_unchecked (len << Sv39::PAGE_BITS),
) {
Ok ((ptr, size)) => {
assert_eq! (size, len << Sv39::PAGE_BITS);
*flags |= Self:: OWNED;
ptr
}
Err (_) => handle_alloc_error (Layout:: from_size_align_unchecked (
len << Sv39:: PAGE_BITS,
1 << Sv39:: PAGE_BITS,
)),
}
}
}
fn deallocate (&mut self, _pte: Pte<Sv39>, _len: usize) -> usize {
todo! ()
}
fn drop_root (&mut self) {
todo! ()
}
}
pub struct Console;
impl console:: Console for Console {
#[inline]
fn put_char (&self, c: u8) {
#[allow (deprecated)]
sbi_rt::legacy:: console_putchar (c as _);
}
}
pub struct SyscallContext;
impl IO for SyscallContext {
fn write (&self, caller: Caller, fd: usize, buf: usize, count: usize) -> isize {
match fd {
STDOUT | STDDEBUG => {
const READABLE: VmFlags<Sv39> = VmFlags:: build_from_str ("RV");
if let Some (ptr) = unsafe { PROCESSES. get_mut (caller. entity) }
.unwrap ()
.address_space
.translate (VAddr:: new (buf), READABLE)
{
print! ("{}", unsafe {
core::str:: from_utf8_unchecked (core::slice:: from_raw_parts (
ptr. as_ptr (),
count,
))
});
count as _
} else {
log::error! ("ptr not readable");
-1
}
}
_ => {
console::log::error! ("unsupported fd: {fd}");
-1
}
}
}
}
impl Process for SyscallContext {
#[inline]
fn exit (&self, _caller: Caller, _status: usize) -> isize {
0
}
}
impl Scheduling for SyscallContext {
#[inline]
fn sched_yield (&self, _caller: Caller) -> isize {
0
}
}
impl Clock for SyscallContext {
#[inline]
fn clock_gettime (&self, caller: Caller, clock_id: ClockId, tp: usize) -> isize {
const WRITABLE: VmFlags<Sv39> = VmFlags:: build_from_str ("W_V");
match clock_id {
ClockId:: CLOCK_MONOTONIC => {
if let Some (mut ptr) = unsafe { PROCESSES.get (caller. entity) }
.unwrap ()
.address_space
.translate (VAddr:: new (tp), WRITABLE)
{
let time = riscv::register::time:: read () * 10000 / 125;
*unsafe { ptr. as_mut () } = TimeSpec {
tv_sec: time / 1_000_000_000,
tv_nsec: time % 1_000_000_000,
};
0
} else {
log::error! ("ptr not readable");
-1
}
}
_ => -1,
}
}
}
}ra 寄存器是如何保存返回地址的?
Q:我有个问题,任务从 taskA 通过 switch 函数切换栈后,此时 ra 寄存器的值应该是 switch 函数的下个地址,然后函数会返回到 taskB 的 trap_handler 继续执行。trap_handler 执行完毕后,此时应该会返回到__restore 函数执行,这里是如何返回到__restore 的我没想明白,ra 寄存器被编译器自动设置成了__restore 的地址?
A:我也有过这个问题,当时没学过汇编,所以对汇编文件 trap.S 理解不到位,后来根据文档有关汇编脚本文件的上下文猜测到:
__alltraps 和 __restore 都是定义在汇编文件 trap.S 中的,__alltraps 的最后一条指令是 call trap_handler,其下一条指令是符号 __restore: 指示的 ld t0, 32*8(sp),即__restore 第一条指令。而 call trap_handler 应该是“为内核支持函数调用”那节所说的用 jalr 实现的伪指令 call 实现函数调用,会保存当前指令的下一条指令地址 ld 的地址到 ra 寄存器并跳转到函数 trap_handler。trap_handler 执行完毕 ret 就返回到__restore 首指令 ld 了。
深入理解 ra 和 sepc 的作用
Q:有个问题,请问 ra 和 sepc 的作用是不是重复了?在 A-switch-B 返回后,restore 加载 B 的 trap context 后,请问 pc 究竟是跳转到 sepc 指定的地址还是跳转到 ra 指向的地址?
A:执行执行环境返回指令 sret 会将 sepc 写到 pc,执行函数调用返回指令 ret 会将 ra 写到 pc。
前面定义了pub fn __switch(~),因此在源代码中直接当做函数调用__switch(~),__switch最后会执行指令ret。而__restore的调用是通过call trap_handler执行完毕后接着执行下条指令实现的,__alltraps最后会执行sret。下一节会看到__switch会在系统调用中执行,因此先是__alltraps保存trap上下文,再执行__switch切换任务,以此保存被调用保存寄存器(其中一个目的G是:任务切换回来时从调用__switch()的地方回来接着往下执行,这是通过执行ret将ra写到pc实现的,ra存储着同特权级函数调用完成返回时要跳转到的位置),恢复下个任务的被调用者保存寄存器(其中恢复ra就是为实现目的G做的准备工作)和切换至下个任务(这样就暂停了当前任务,暂停在调用函数__switch的代码处)的暂停点(系统调用内核代码调用__switch的地方)继续执行(执行ret实现),系统调用代码__switch执行完了在执行剩余的系统调用代码完了会在__restore处接着执行恢复trap上下文代码,最后执行sret恢复trap上下文。
简言之ret是为了从系统调用时内核函数调用暂停点继续执行,sret是为了切换特权级,从用户态调用系统调用的函数暂停点接着执行,并使用系统调用返回的结果。
而当 CPU 完成 Trap 处理准备返回的时候,需要通过一条 S 特权级的特权指令
sret来完成,这一条指令具体完成以下功能:
- CPU 会将当前的特权级按照 sstatus 的 SPP 字段设置为 U 或者 S ;
- CPU 会跳转到 sepc 寄存器指向的那条指令,然后继续执行。