并查集被很多 OIer 认为是最简洁而优雅的数据结构之一,主要用于解决一些元素分组的问题。它管理一系列不相交的集合,并支持两种操作:
- 合并(Union):把两个不相交的集合合并为一个集合。
- 查询(Find):查询两个元素是否在同一个集合中。
当然,这样的定义未免太过学术化,看完后恐怕不太能理解它具体有什么用。所以我们先来看看并查集最直接的一个应用场景:亲戚问题。
[! example] (洛谷 P1551)亲戚 题目背景
若某个家族人员过于庞大,要判断两个是否是亲戚,确实还很不容易,现在给出某个亲戚关系图,求任意给出的两个人是否具有亲戚关系。
题目描述
规定:x 和 y 是亲戚,y 和 z 是亲戚,那么 x 和 z 也是亲戚。如果 x, y 是亲戚,那么 x 的亲戚都是 y 的亲戚,y 的亲戚也都是 x 的亲戚。
输入格式
第一行:三个整数 n, m, p,(n⇐5000, m⇐5000, p⇐5000),分别表示有 n 个人,m 个亲戚关系,询问 p 对亲戚关系。
以下 m 行:每行两个数 Mi,Mj,1⇐Mi,Mj⇐N,表示 Mi 和 Mj 具有亲戚关系。
接下来 p 行:每行两个数 Pi,Pj,询问 Pi 和 Pj 是否具有亲戚关系。
输出格式
P 行,每行一个’Yes’或’No’。表示第 i 个询问的答案为 “具有” 或“不具有”亲戚关系。
这其实是一个很有现实意义的问题。我们可以建立模型,把所有人划分到若干个不相交的集合中,每个集合里的人彼此是亲戚。为了判断两个人是否为亲戚,只需看它们是否属于同一个集合即可。因此,这里就可以考虑用并查集进行维护了。
并查集的引入
并查集的重要思想在于,用集合中的一个元素代表集合。我曾看过一个有趣的比喻,把集合比喻成帮派,而代表元素则是帮主。接下来我们利用这个比喻,看看并查集是如何运作的。
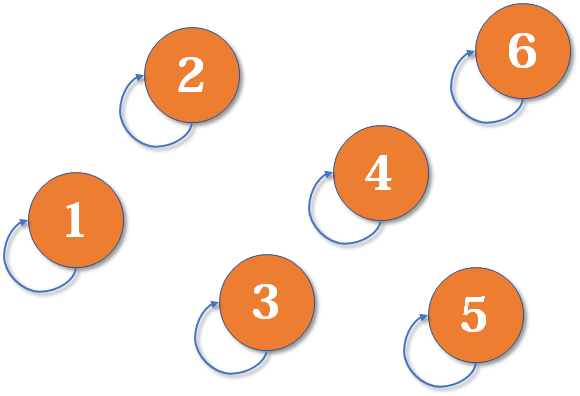
最开始,所有大侠各自为战。他们各自的帮主自然就是自己。(对于只有一个元素的集合,代表元素自然是唯一的那个元素)
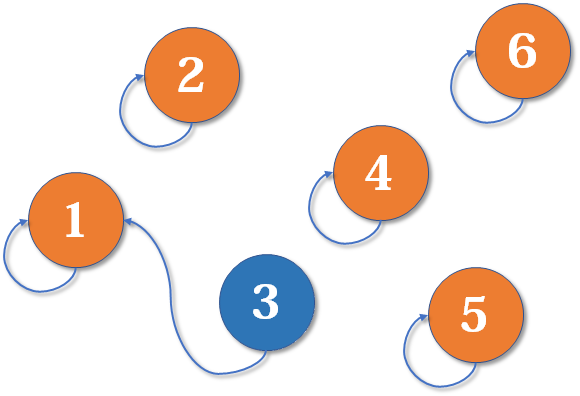
现在 1 号和 3 号比武,假设 1 号赢了(这里具体谁赢暂时不重要),那么 3 号就认 1 号作帮主(合并 1 号和 3 号所在的集合,1 号为代表元素)_。
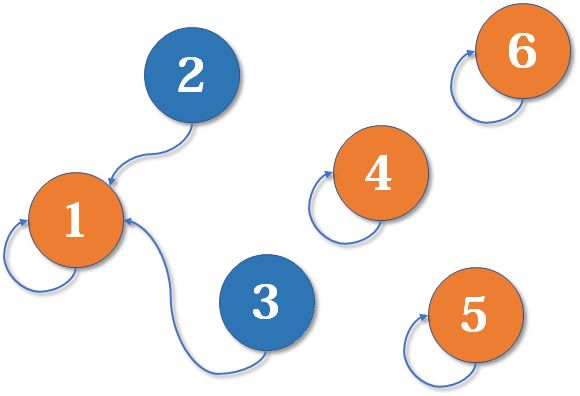
现在 2 号想和 3 号比武(合并 3 号和 2 号所在的集合),但 3 号表示,别跟我打,让我帮主来收拾你(合并代表元素)。不妨设这次又是 1 号赢了,那么 2 号也认 1 号做帮主。
现在我们假设 4、5、6 号也进行了一番帮派合并,江湖局势变成下面这样:
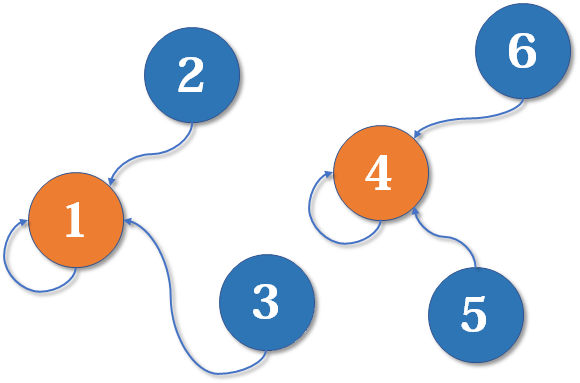
现在假设 2 号想与 6 号比,跟刚刚说的一样,喊帮主 1 号和 4 号出来打一架(帮主真辛苦啊)。1 号胜利后,4 号认 1 号为帮主,当然他的手下也都是跟着投降了。
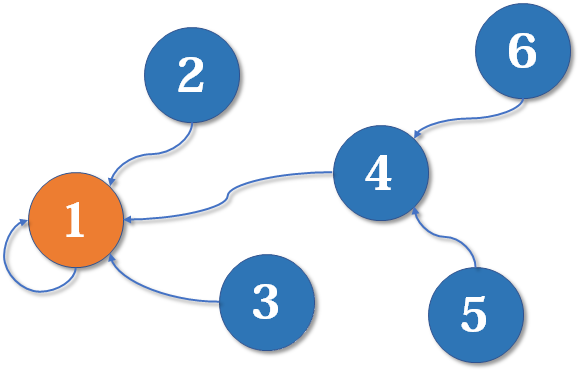
好了,比喻结束了。如果你有一点图论基础,相信你已经觉察到,这是一个树状的结构,要寻找集合的代表元素,只需要一层一层往上访问父节点(图中箭头所指的圆),直达树的根节点(图中橙色的圆)即可。根节点的父节点是它自己。我们可以直接把它画成一棵树:
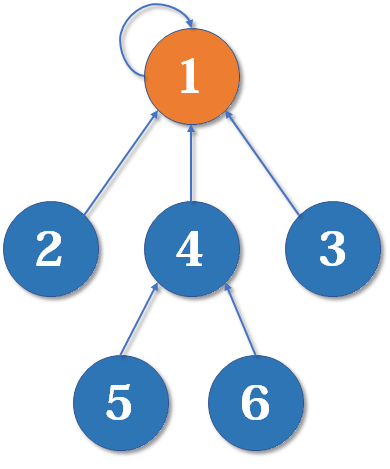
用这种方法,我们可以写出最简单版本的并查集代码。
初始化
int fa[MAXN];
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
fa[i] = i;
}
假如有编号为 1, 2, 3, …, n 的 n 个元素,我们用一个数组 fa[] 来存储每个元素的父节点(因为每个元素有且只有一个父节点,所以这是可行的)。一开始,我们先将它们的父节点设为自己。
查询
int find(int x)
{
if(fa[x] == x)
return x;
else
return find(fa[x]);
}
我们用递归的写法实现对代表元素的查询:一层一层访问父节点,直至根节点(根节点的标志就是父节点是本身)。要判断两个元素是否属于同一个集合,只需要看它们的根节点是否相同即可。
合并
inline void merge(int i, int j)
{
fa[find(i)] = find(j);
}
合并操作也是很简单的,先找到两个集合的代表元素,然后将前者的父节点设为后者即可。当然也可以将后者的父节点设为前者,这里暂时不重要。本文末尾会给出一个更合理的比较方法。
删除
[! warning]+ 并查集无法以较低复杂度实现集合的分离。
要删除一个叶子节点,我们可以将其父亲设为自己。为了保证要删除的元素都是叶子,我们可以预先为每个节点制作副本,并将其副本作为父亲。
struct dsu {
vector<size_t> pa, size;
explicit dsu(size_t size_) : pa(size_ * 2), size(size_ * 2, 1) {
iota(pa.begin(), pa.begin() + size_, size_);
iota(pa.begin() + size_, pa.end(), size_);
}
void erase(size_t x) {
--size[find(x)];
pa[x] = x;
}
};
移动
与删除类似,通过以副本作为父亲,保证要移动的元素都是叶子。
void dsu::move(size_t x, size_t y) {
auto fx = find(x), fy = find(y);
if (fx == fy) return;
pa[x] = fy;
--size[fx], ++size[fy];
}
路径压缩
直接查询是低效的
最简单的并查集效率是比较低的。例如,来看下面这个场景:
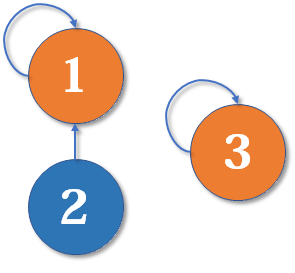
现在我们要 merge (2,3),于是从 2 找到 1,fa[1] =3,于是变成了这样:

然后我们又找来一个元素 4,并需要执行 merge (2,4):
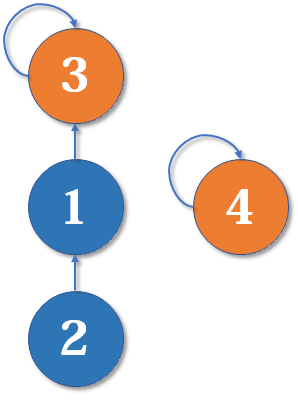
从 2 找到 1,再找到 3,然后 fa[3] = 4,于是变成了这样:

大家应该有感觉了,这样可能会形成一条长长的链,随着链越来越长,我们想要从底部找到根节点会变得越来越难 (每一次都要从低向上搜索一遍)。
路径压缩的思路
怎么解决呢?我们可以使用路径压缩的方法。既然我们只关心一个元素对应的根节点,那我们希望每个元素到根节点的路径尽可能短,最好只需要一步,像这样:

其实这说来也很好实现。只要我们在查询的过程中,把沿途的每个节点的父节点都设为根节点即可。下一次再查询时,我们就可以省很多事。这用递归的写法很容易实现:
合并(路径压缩)
int find(int x)
{
if(x == fa[x])
return x;
else{
fa[x] = find(fa[x]); //父节点设为根节点
return fa[x]; //返回父节点
}
}以上代码常常简写为一行:
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
注意赋值运算符 = 的优先级没有三元运算符 ?: 高,这里要加括号。
路径压缩优化后,并查集的时间复杂度已经比较低了,绝大多数不相交集合的合并查询问题都能够解决。然而,对于某些时间卡得很紧的题目,我们还可以进一步优化。
按秩合并(启发式合并)
有些人可能有一个误解,以为路径压缩优化后,并查集始终都是一个菊花图(只有两层的树的俗称)。但其实,由于路径压缩只在查询时进行,也只压缩一条路径,所以并查集最终的结构仍然可能是比较复杂的。例如,现在我们有一棵较复杂的树需要与一个单元素的集合合并:
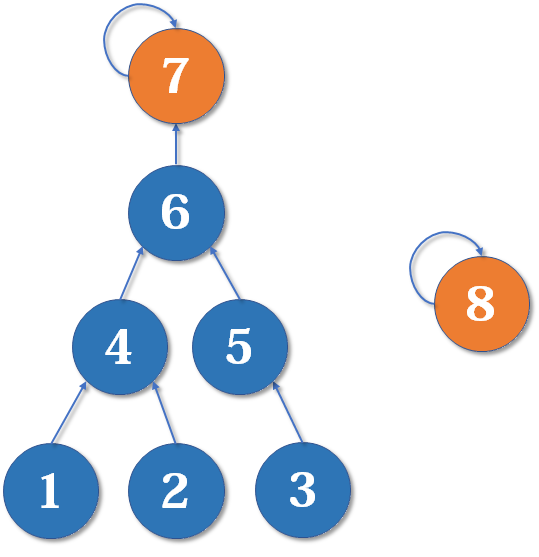
假如这时我们要 merge (7,8),如果我们可以选择的话,是把 7 的父节点设为 8 好,还是把 8 的父节点设为 7 好呢?
当然是后者。==因为如果把 7 的父节点设为 8,会使树的深度(树中最长链的长度)加深,原来的树中每个元素到根节点的距离都变长了,之后我们寻找根节点的路径也就会相应变长==。虽然我们有路径压缩,但路径压缩也是会消耗时间的。而把 8 的父节点设为 7,则不会有这个问题,因为它没有影响到不相关的节点。
[! note]+ 关于路径压缩和启发式合并的复杂度讨论 由于需要并查集支持的只有集合的合并、查询操作,当我们需要将两个集合合二为一时,无论将哪一个集合连接到另一个集合的下面,都能得到正确的结果。但不同的连接方法存在时间复杂度的差异。具体来说,如果我们将一棵点数与深度都较小的集合树连接到一棵更大的集合树下,显然相比于另一种连接方案,接下来执行查找操作的用时更小(也会带来更优的最坏时间复杂度)。
当然,我们不总能遇到恰好如上所述的集合——点数与深度都更小。鉴于点数与深度这两个特征都很容易维护,我们常常从中择一,作为估价函数。而无论选择哪一个,时间复杂度都为 ,具体的证明可参见 References 中引用的论文1。
在算法竞赛的实际代码中,即便不使用启发式合并,代码也往往能够在规定时间内完成任务。在 Tarjan 的论文2中,证明了不使用启发式合并、只使用路径压缩的最坏时间复杂度是 。在姚期智的论文 3 中,证明了不使用启发式合并、只使用路径压缩,在平均情况下,时间复杂度依然是 )。
如果只使用启发式合并,而不使用路径压缩,时间复杂度为 。由于路径压缩单次合并可能造成大量修改,有时路径压缩并不适合使用。例如,在可持久化并查集、线段树分治 + 并查集中,一般使用只启发式合并的并查集。
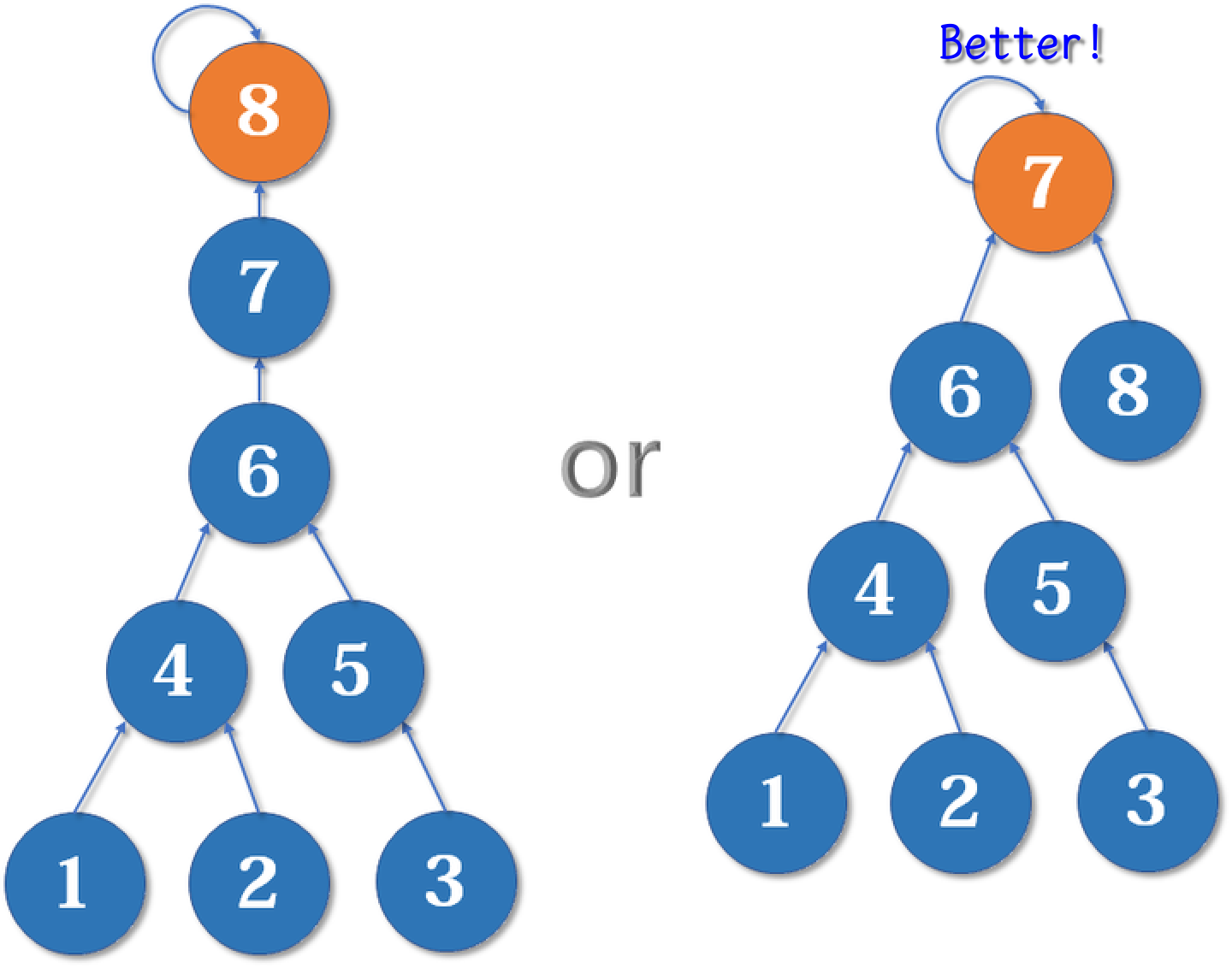
这启发我们:我们应该把简单的树往复杂的树上合并,而不是相反。因为这样合并后,到根节点距离变长的节点个数比较少。
我们用一个数组 rank[] 记录每个根节点对应的树的深度(如果不是根节点,其 rank 相当于以它作为根节点的子树的深度)。一开始,把所有元素的 rank(秩)设为 1。合并时比较两个根节点,把 rank 较小者往较大者上合并。
路径压缩和按秩合并如果一起使用,时间复杂度接近 ,但是很可能会破坏 rank 的准确性。
初始化(按秩合并)
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
合并(按秩合并)
inline void merge(int i, int j)
{
int x = find(i), y = find(j); //先找到两个根节点
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++; //如果深度相同且根节点不同,则新的根节点的深度+1
}
为什么深度相同,新的根节点深度要 + 1?如下图,我们有两个深度均为 2 的树,现在要 merge (2,5):
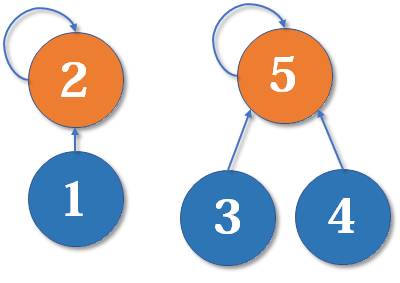
这里把 2 的父节点设为 5,或者把 5 的父节点设为 2,其实没有太大区别。我们选择前者,于是变成这样:
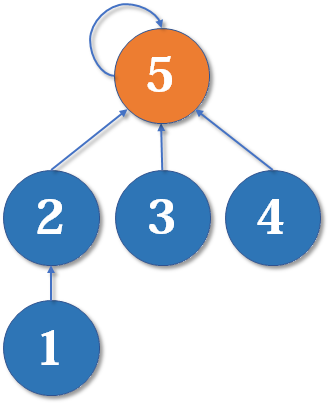
显然树的深度增加了 1。另一种合并方式同样会让树的深度 + 1。
复杂度
时间复杂度
同时使用路径压缩和启发式合并之后,并查集的每个操作平均时间仅为 ,其中 为阿克曼函数的反函数,其增长极其缓慢,也就是说其单次操作的平均运行时间可以认为是一个很小的常数。
Ackermann 函数 A(m, n) 的定义是这样的:
而反 Ackermann 函数 的定义是阿克曼函数的反函数,即为最大的整数 使得 。
时间复杂度的证明 在这个页面中。
空间复杂度
显然为 。
并查集的应用
亲戚问题
我们先给出亲戚问题的 AC 代码:
#include <cstdio>
#define MAXN 5005
int fa[MAXN], rank[MAXN];
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
inline void merge(int i, int j)
{
int x = find(i), y = find(j);
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++;
}
int main()
{
int n, m, p, x, y;
scanf("%d%d%d", &n, &m, &p);
init(n);
for (int i = 0; i < m; ++i)
{
scanf("%d%d", &x, &y);
merge(x, y);
}
for (int i = 0; i < p; ++i)
{
scanf("%d%d", &x, &y);
printf("%s\n", find(x) == find(y) ? "Yes" : "No");
}
return 0;
}奶酪孔洞
接下来我们来看一道 NOIP 提高组原题:
[! example] (NOIP 提高组 2017 年 D2T1 洛谷 P3958 奶酪) 题目描述
现有一块大奶酪,它的高度为 ,它的长度和宽度我们可以认为是无限大的,奶酪中间有许多半径相同的球形空洞。我们可以在这块奶酪中建立空间坐标系,在坐标系中, 奶酪的下表面为 ,奶酪的上表面为 。
现在,奶酪的下表面有一只小老鼠 Jerry,它知道奶酪中所有空洞的球心所在的坐标。如果两个空洞相切或是相交,则 Jerry 可以从其中一个空洞跑到另一个空洞,特别地,如果一个空洞与下表面相切或是相交,Jerry 则可以从奶酪下表面跑进空洞;如果一个空洞与上表面相切或是相交,Jerry 则可以从空洞跑到奶酪上表面。
位于奶酪下表面的 Jerry 想知道,在 不破坏奶酪 的情况下,能否利用已有的空洞跑到奶酪的上表面去?
空间内两点 、 的距离公式如下:
输入格式
每个输入文件包含多组数据。
第一行,包含一个正整数 ,代表该输入文件中所含的数据组数。
接下来是 组数据,每组数据的格式如下: 第一行包含三个正整数 和 ,两个数之间以一个空格分开,分别代表奶酪中空洞的数量,奶酪的高度和空洞的半径。
接下来的 行,每行包含三个整数 ,两个数之间以一个空格分开,表示空洞球心坐标为 。
输出格式
行,分别对应 组数据的答案,如果在第 组数据中,Jerry 能从下表面跑到上表面,则输出Yes,如果不能,则输出No(均不包含引号)。
大家看出这道题和并查集的关系了吗?

大家看看上面这张图,是不是看出一些门道了?我们把所有空洞划分为若干个集合,一旦两个空洞相交或相切,就把它们放到同一个集合中。
我们还可以划出 2 个特殊元素,分别表示底部和顶部,如果一个空洞与底部接触,则把它与表示底部的元素放在同一个集合中,顶部同理。最后,只需要看顶部和底部是不是在同一个集合中即可。这完全可以通过并查集实现。来看代码:
#include <cstdio>
#include <cstring>
#define MAXN 1005
typedef long long ll;
int fa[MAXN], rank[MAXN];
ll X[MAXN], Y[MAXN], Z[MAXN];
inline bool next_to(ll x1, ll y1, ll z1, ll x2, ll y2, ll z2, ll r)
{
return (x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2) + (z1 - z2) * (z1 - z2) <= 4 * r * r;
//判断两个空洞是否相交或相切
}
inline void init(int n)
{
for (int i = 1; i <= n; ++i)
{
fa[i] = i;
rank[i] = 1;
}
}
int find(int x)
{
return x == fa[x] ? x : (fa[x] = find(fa[x]));
}
inline void merge(int i, int j)
{
int x = find(i), y = find(j);
if (rank[x] <= rank[y])
fa[x] = y;
else
fa[y] = x;
if (rank[x] == rank[y] && x != y)
rank[y]++;
}
int main()
{
int T, n, h;
ll r;
scanf("%d", &T);
for (int I = 0; I < T; ++I)
{
memset(X, 0, sizeof(X));
memset(Y, 0, sizeof(Y));
memset(Z, 0, sizeof(Z));
scanf("%d%d%lld", &n, &h, &r);
init(n);
fa[1001] = 1001; //用1001代表底部
fa[1002] = 1002; //用1002代表顶部
for (int i = 1; i <= n; ++i)
scanf("%lld%lld%lld", X + i, Y + i, Z + i);
for (int i = 1; i <= n; ++i)
{
if (Z[i] <= r)
merge(i, 1001); //与底部接触的空洞与底部合并
if (Z[i] + r >= h)
merge(i, 1002); //与顶部接触的空洞与顶部合并
}
for (int i = 1; i <= n; ++i)
{
for (int j = i + 1; j <= n; ++j)
{
if (next_to(X[i], Y[i], Z[i], X[j], Y[j], Z[j], r))
merge(i, j); //遍历所有空洞,合并相交或相切的球
}
}
printf("%s\n", find(1001) == find(1002) ? "Yes" : "No");
}
return 0;
}因为数据范围的原因,这里要开一个 long long。
并查集的应用还有很多,例如最小生成树的 Kruskal 算法等。这里就不细讲了。总而言之,凡是涉及到元素的分组管理问题,都可以考虑使用并查集进行维护。
MST 的 Kruskal 算法
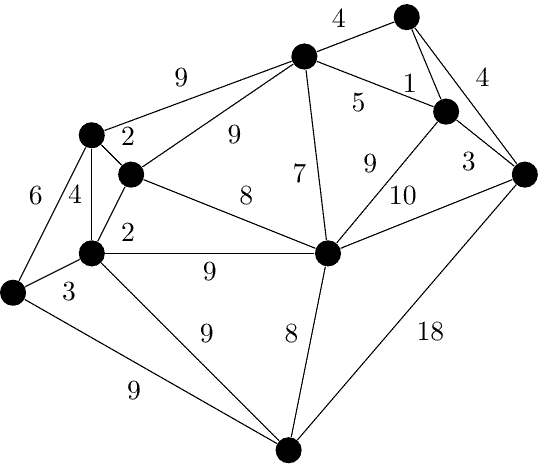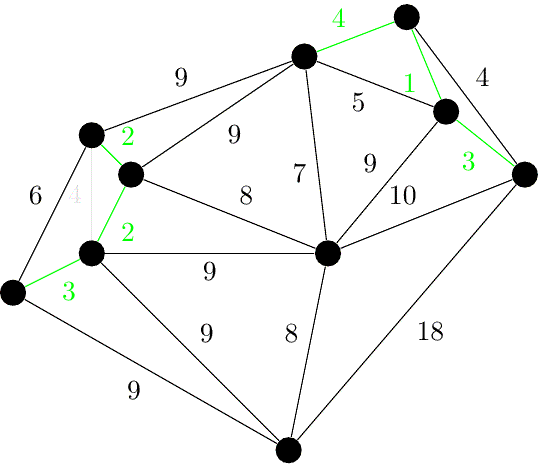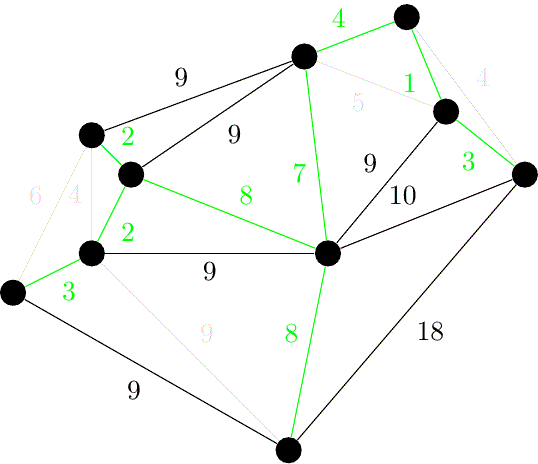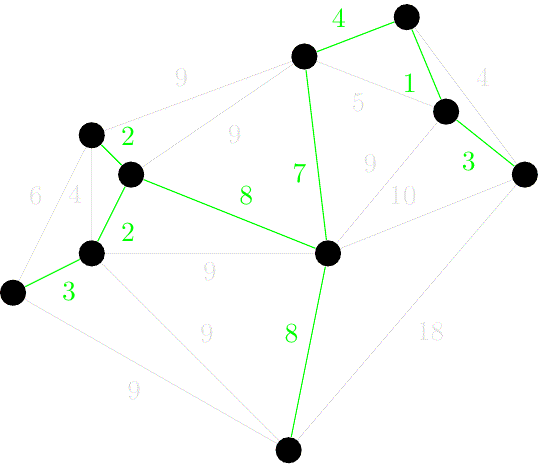
伪代码:
算法虽简单,但需要相应的数据结构来支持……具体来说,维护一个森林,查询两个结点是否在同一棵树中,连接两棵树。
抽象一点地说,维护一堆 集合,查询两个元素是否属于同一集合,合并两个集合。
其中,查询两点是否连通和连接两点可以使用并查集维护。
如果使用 的排序算法,并且使用 或 的并查集,就可以得到时间复杂度为 的 Kruskal 算法。
[! note]+ Kruskal 算法的证明 思路很简单,为了造出一棵最小生成树,我们从最小边权的边开始,按边权从小到大依次加入,如果某次加边产生了环,就扔掉这条边,直到加入了 n-1 条边,即形成了一棵树。
证明:使用归纳法,证明任何时候 K 算法选择的边集都被某棵 MST 所包含。
- 基础:对于算法刚开始时,显然成立(最小生成树存在)。
- 归纳:
- 假设某时刻成立,当前边集为 F,令 T 为这棵 MST,考虑下一条加入的边 e。
- 如果 e 属于 T,那么成立。
- 否则,T+e 一定存在一个环,考虑这个环上不属于 F 的另一条边 f(一定只有一条)。
- 首先,f 的权值一定不会比 e 小,不然 f 会在 e 之前被选取。
- 然后,f 的权值一定不会比 e 大,不然 T+e-f 就是一棵比 T 还优的生成树了。
- 所以,T+e-f 包含了 F,并且也是一棵最小生成树,归纳成立。
Footnotes
-
- Gabow, H. N., & Tarjan, R. E. (1985). A Linear-Time Algorithm for a Special Case of Disjoint Set Union. JOURNAL OF COMPUTER AND SYSTEM SCIENCES, 30, 209-221. PDF
-
Tarjan, R. E., & Van Leeuwen, J. (1984). Worst-case analysis of set union algorithms. Journal of the ACM (JACM), 31(2), 245-281.ResearchGate PDF ↩
-
Yao, A. C. (1985). On the expected performance of path compression algorithms.SIAM Journal on Computing, 14(1), 129-133. ↩