读完论文你应该收获什么?
Problem
What problem is the paper solving?
Why is this problem important?
Context
What was the previous state of the art?
How does the paper advance the state of the art?
Design
How is the system designed?
What are the key insights from the design?
Results
How is the design evaluated, what are the key results?
What related problems are still open?
Questions
- What questions do you have?
Introduction
Current Distributed Routing. 传统数据中心网络(DCN)依赖 BGP 协议作为分布式路由方案。然而,随着数据中心规模的扩大,其固有缺陷日益显著:
- 收敛速度慢:由于交换机独立响应网络变化,缺乏集中协调,导致路由更新过程中通信冗余和计算重复,造成链路连通性长时间中断(即使物理网络仍连通)。
- 管理复杂性高:在大规模网络中(如数千台交换机),BGP 配置和维护难度极高,难以实现全局路由的精细化控制。
Centralized Routing and Remaining Problems. 集中式路由(如 Google 的 Firepath)通过全局链路状态(LS)管理和集中控制解决了分布式路由的部分问题,显著提升了收敛速度和管理效率。然而,其仍面临两大挑战:
- 路由计算效率不足:
- 如果使用集中式控制器直接计算整个网络的路由,将会非常缓慢且不具备可扩展性,因此 Firepath 中的集中式控制器仅收集和存储整个网络的链路状态数据库 LSDB,链路状态的变化会分发给交换机。
- 每个交换机使用 SPF 算法分布式地计算最短路,这仍然非常耗时—— 个节点、 条边、 条等成本最短路径的拓扑中,典型的 kSPF 算法的时间复杂度为 ,具体实验表明,10K 规模拓扑下单次 LS 更新需超过 3 秒(这也是 Jupiter Rising 表 4 中 ToR-S2 链路会有 4s 中断的原因)。
- 控制平面容错能力有限:依赖多控制器(主+备用)同步链路状态数据库(LSDB)以保证一致性,每个控制器都会维护一份整个网络的拓扑图。但同步过程引入额外开销(如日志复制),且控制平面网络故障可能导致 LS 更新丢失或延迟(这样就不得不引入重传超时或控制器选举耗时)。
Contribution. 提出 Primus,一种高效、鲁棒的集中式 DCN 路由协议,其核心创新如下:
- 基于表查找的轻量化路由计算:
- 预装基础拓扑与规则:利用 DCN 拓扑的规律性,将路由更新分类为一些固定的模式,简化为预定义规则下的表查询操作(而非动态计算)。 具体来说,每个交换机只需将当前链路状态与预装的基础拓扑进行比较,并根据预定义的规则启用或禁用其预装的基础路由表中的路由条目。
- 智能索引技术:通过预判链路状态变化对路由的影响模式,实现路由表的快速更新(复杂度为 ),同时设计新的数据结构使得每个交换机的内存占用 <10MB,计算耗时与内存占用得到了显著降低。。
- 低开销的容错机制:
- 无状态控制器:采用类似 Jupiter 的多热备无状态(hot-standby backup, stateless)控制器,通过冗余 LS 消息传递(不同故障域)确保更新可靠性,避免同步开销。具体来说,负责报告的交换机在逻辑上将 LS 变化传递到整个网络(尽管在物理上仍然通过主控节点),从而主控节点无需记住整个网络的链路状态(这就是所谓的 stateless)。因此,处理主控节点故障既简单又低成本,因为任何备份主控节点都可以处理LS变化,且无需等待多个主控节点之间的同步。
- 冗余通信:为了在故障发生时保持快速反应,Primus在传递LS消息时增加了一些冗余。这些冗余的LS消息通常位于不同的故障域中(例如,由不同的备份主控节点和控制平面网络设备处理),只要至少一个LS消息副本被成功处理,路由就可以正确执行。因此,Primus即使在控制平面网络故障和主控节点故障的情况下,也能保持快速的路由收敛(对于拥有10K+交换机的网络,收敛时间为几十毫秒)
- 间接通道恢复:主控链路故障时,通过数据平面快速建立间接通信通道,保障控制平面的持续可用性。
Related Work
Other centralized routing control
其他工作的总结:
- 部分研究(如 NSDI’10 Hedera 动态流调度,SIGCOMM’15 Fastpass 集中式零队列数据中心,EuroSys’14 WCMP)通过集中式控制器优化网络流量调度,但仍依赖底层的分布式路由协议(如 BGP)维护路径。
- SIGCOMM’09 PortLand(可扩展的容错式二层 DCN)使用集中控制器收集/分发链路状态,尝试构建基于 MAC 地址的集中式 L2 路由,但这与 L3 IP 路由架构不兼容,且未解决快速计算与容错问题。
- SIGCOMM’09 VL2 DCN、NSDI’14 多租户 DC 中的网络虚拟化、 SIGCOMM’08 NOX 网络操作系统、Open/R 这些工作专注于网络虚拟化或底层系统抽象,但未设计完整路由协议。
不足:上述工作仅解决特定局部问题,未形成完整的集中式路由协议,无法应对大规模 DCN 的路由计算效率与控制平面容错挑战。
Improved distributed routing protocol
其他工作的总结:
- BGP 优化(如 INFOCOM’02 通过一致性改进 BGP 收敛、INFOCOM’11 指出时间多样性导致 BGP 收敛速度指数级恶化、INFOCOM’03 通过 ghost flushing 改进 BGP 收敛等)通过状态同步、路由策略调整等提升性能,但无法根治分布式协议的固有缺陷(如收敛延迟仍然在秒级)。
- RIFT 协议利用 DCN 胖树拓扑的先验知识限制广播范围,但仍依赖分布式决策、链路状态广播与计算、定时器等待等方法,导致收敛速度与可控性不足。
不足:改进方案未突破分布式架构的瓶颈,收敛速度与全局管理效率仍无法满足大规模 DCN 需求。
Data-plane connectivity recovery before routing convergence
其他工作的总结:
- 快速重路由(FRR)技术(如 RFC 5286 IP 快速重路由、RFC 7490 远程无环替代加速重路由、RFC 7811 使用最大冗余树计算快速重路由)关注在 Internet 场景中通过预置备份路径加速恢复,但无法满足 DCN 密集拓扑的无环路要求(控制平面收敛才能计算出下一跳)。
- DCN 专用方案(如 CoNEXT’13 AspenTree、NSDI’13 F10、TON’17 等)通过大量拓扑改造或非最短路径回弹实现快速恢复,但可能引入临时环路,实用性受限。
不足:此类技术与控制平面路由收敛互补而非替代,且部分方案需牺牲路径最优性或拓扑灵活性。
Centralized routing in WAN
其他工作的总结:
- 广域网(WAN)集中式路由系统(如 SIGCOMM’13 使用软件驱动 WAN 实现高利用性、SIGCOMM’18 B4 and after 等)专注于跨数据中心的流量工程与带宽优化。
不足:WAN 与 DCN 的网络规模、拓扑规律性、故障模式差异显著,其设计无法直接适用于 DCN 内部路由场景。
Primus Design
Architecture
设计思路: Primus 沿用 Jupiter-Rising 的集中式控制器架构(主控收集/分发链路状态),但核心创新在于将路由计算简化为预定义规则下的表查询操作。每个交换机预装基础拓扑和路由表,仅需根据链路状态变化启用/禁用预存 的路由条目,而非动态计算。
技术改进:
- 预装基础拓扑与路由表:利用 DCN 拓扑的规律性,提前计算所有可能的最短路径并固化到交换机。
- 控制平面与管理解耦:主控仅负责链路状态分发,路由更新由交换机本地完成,降低主控计算压力。
有效性原因:
- DCN 拓扑的高度规律性使得路径模式可预测,预存路径覆盖所有可能变化,避免动态 SPF 计算的复杂度。
- 去中心化计算将主控从高负载中解放,提升系统扩展性。
技术细节:

这里所谓受影响与拓扑的关系可以这样理解:上行链路会影响其下方子树中的所有交换机,例如,在图 1 中,链路 2.1→3.1 可能影响交换机 2.1 和 1.1-1.100 的路由。同样,下行链路会影响与其连接的上层交换机(通过一跳或两跳)以及这些交换机下方的子树,例如,在图 1 中,链路 2.1→1.1 可能影响交换机 2.1、3.1-3.4、每个 Pod 中最左侧的 Agg 交换机以及除 1.1 之外的所有 ToR 交换机。
每个交换机都预先配置了主节点的静态地址,并通过控制平面网络与主节点建立了一个长期存在的双向可靠传输连接(例如 TCP),用于传递链路状态消息(称为主通道)。 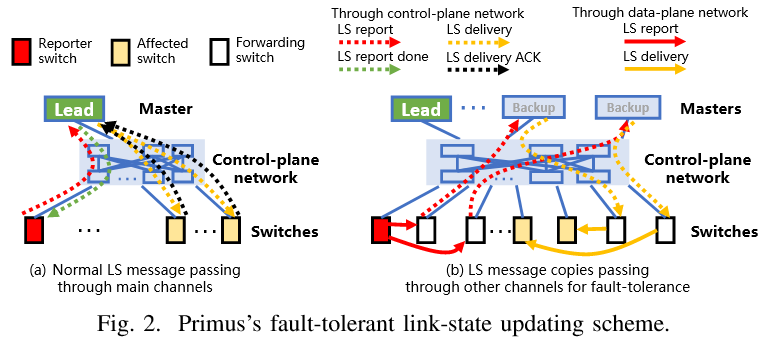 如图 2 (a) 所示,当检测到本地链路状态变化时,报告交换机会通过主通道向主节点报告(红色虚线箭头)。每个链路状态变化在每条链路上都有一个唯一递增的 ID。每当接收到新的链路状态时,主节点会通过主通道将链路状态传递给所有可能受影响的交换机(黄色虚线箭头)。受影响交换机在成功接收链路状态并更新其路由后,会通过主通道向主节点发送确认(黑色虚线箭头)。当主节点成功将链路状态传递给所有受影响的交换机并收到它们的确认后,会通过主通道向报告交换机发送响应(绿色虚线箭头)。如果未收到主节点的响应,报告交换机会在超时后继续重传链路状态,直到成功或主节点发生变化(在主节点重新选举的情况下)。
如图 2 (a) 所示,当检测到本地链路状态变化时,报告交换机会通过主通道向主节点报告(红色虚线箭头)。每个链路状态变化在每条链路上都有一个唯一递增的 ID。每当接收到新的链路状态时,主节点会通过主通道将链路状态传递给所有可能受影响的交换机(黄色虚线箭头)。受影响交换机在成功接收链路状态并更新其路由后,会通过主通道向主节点发送确认(黑色虚线箭头)。当主节点成功将链路状态传递给所有受影响的交换机并收到它们的确认后,会通过主通道向报告交换机发送响应(绿色虚线箭头)。如果未收到主节点的响应,报告交换机会在超时后继续重传链路状态,直到成功或主节点发生变化(在主节点重新选举的情况下)。
LS change的递增ID溢出问题评估
在Primus中,每个链路的LS更新分配唯一递增的ID以跟踪更新顺序。若ID溢出(如32位整数上限),可能的解决策略包括:
- 循环复用与周期标识:
- ID达到最大值后循环归零,但需结合时间戳或周期计数器区分新旧ID。例如,使用高位数位表示周期,低位数位为递增ID(如64位复合ID:高32位为周期号,低32位为序列号)。
- 扩展ID空间:
- 采用64位或128位整数作为ID,使溢出时间远超实际网络生命周期(如64位ID需约5亿年才能耗尽)。
- 状态重置协商:
- 主控定期与交换机同步ID状态,若检测到即将溢出,触发全局ID重置协议,确保所有节点同步至新起点。
- 分布式ID生成机制:采用类似雪花算法(Snowflake) 的分布式ID生成方案,结合时间戳、节点ID和序列号生成全局唯一ID。例如:
- 时间戳(41位):精确到毫秒,可使用约69年。
- 节点ID(10位):标识 Reporter Switch 或控制器,支持1024个节点。
- 序列号(12位):每节点每毫秒生成4096个ID。这种设计避免了单点依赖,且时间戳部分天然递增,溢出周期极长(远超系统生命周期)。
阅读代码后,这个问题有了更深的理解:
当前eventID的溢出风险:
eventID是int类型,在大多数系统上是32位有符号整数,最大值为2,147,483,647(约21亿),在Primus系统中,eventID是单调递增的,如果系统运行时间足够长,确实存在溢出风险当前使用场景分析:
- 从代码来看,eventID主要用于:
- 标识单个链路的状态变化
- 用于调试和日志记录
- 确保消息处理的顺序性
- 在
MasterGenerateLinkStatusChange()中,eventID是随机生成的- 在
GenerateLinkStatusChange()中,eventID是简单的递增是否需要修改:
- 如果系统运行时间较短(几年内),且eventID增长较慢,可能不需要修改
- 如果系统需要长期稳定运行(10年以上),或者eventID增长较快,则需要考虑修改
可能的解决方案:
- 方案1:使用64位整数(long long)
- 简单直接,将int改为long long
- 可以支持更大的数值范围
- 但仍然是顺序递增,可能不够健壮
- 方案2:使用雪花算法(Snowflake)
- 优点:
- 分布式ID生成
- 包含时间戳信息
- 支持高并发
- 缺点:
- 实现复杂度较高
- 需要额外的时钟同步机制
- 可能需要修改现有代码逻辑
- 方案3:UUID
- 优点:
- 全局唯一
- 无需担心溢出
- 缺点:
- 占用空间较大(128位)
- 无法保持顺序性
- 可能影响现有日志分析工具
推荐方案: 对于Primus系统,建议采用方案1:使用64位整数,原因如下:
- 实现简单,只需修改数据类型
- 保持现有逻辑不变
- 64位整数可以支持极大的数值范围(约922亿亿)
- 对于链路状态变化这种场景,64位整数已经足够
- 如果未来需要更复杂的ID生成机制,可以在此基础上扩展
具体修改建议:
// 修改link结构体 struct link { ident identA; ident identB; sockaddr_in addrA; sockaddr_in addrB; long long eventId; // 改为64位整数 bool linkStatus; };
- 注意事项:
- 修改后需要检查所有使用eventID的地方
- 确保日志系统能够正确处理64位整数
- 如果与其他系统交互,需要考虑数据类型的兼容性
Routing Caculation
拓扑背景: 假设数据中心网络(DCN)采用最流行的三层胖树拓扑结构(与 Jupiter-Rising 一致)。该拓扑结构包含三层交换机,分别为核心层(Core)、汇聚层(Aggregation, Agg)和机架顶层(Top-of-Rack, ToR)交换机。k 个 ToR 交换机和 s 个 Agg 交换机组成一个 pod,每个 ToR 交换机与每个 Agg 交换机相连。我们将 pod 的数量记为 p。每个 pod 中的 Agg 交换机连接到 n 个不同的 Core 交换机,每个 Core 交换机则连接到所有 pod。Core、Agg 和 ToR 交换机的总数分别为 、 和 。图 1 展示了一个示例拓扑,其中 k = 100、s = 4、p = 100 和 n = 4,该拓扑被用于腾讯的生产 DCN 中。对于更多层的胖树,Primus 也依旧有效。
技术改进:
- 智能索引:根据 DCN 链路类型(4 类)预判路径影响范围,避免全表遍历。
- 内存优化:紧凑数据结构(如链路表仅需类型标记+首路径索引)降低内存占用(<10MB/交换机)。
有效性原因: - 模式化路径管理:DCN 链路的固定影响模式(如上行链路影响子树)使索引规则高度简化。
- 路径合并与位运算:合并相同下一跳路径,通过位操作快速判断路由可用性,减少计算开销。
设计细节:
通过路径表(Path Table) 和 链路表(Link Table) 两种数据结构实现快速查表更新:
- 路径表:存储所有到目的地的等价最短路径及与该路径相关的所有链路。
- 路径表中不合并路径(如,相同的下一跳路径),还记录每条路径中故障链路的数量(记为 FL),交换机可以通过检查 FL 是否等于零来在 O (1) 时间内检测路径是否可用于路由。
- 一旦从主节点接收到链路状态更新,交换机首先找到包含该链路的路径条目(稍后讨论如何找到它们),然后根据链路故障或链路恢复,将这些路径条目的 FL 增加或减少 1。
- 对于图 1 所示的拓扑,路径表中有约 160K 条路径,这些路径在每台交换机中占用约 7.7MB。需要注意的是,该表是 Primus 路由计算算法使用的内部数据结构,交换机数据平面中的实际路由/转发表可以更小,因为具有相同第一跳和相同目的地的路径可以合并为一条路由。
- 每台交换机可以分布式地合并其路由,并通过检测该路由中是否至少有一条路径正常工作(即 FL=0)来检查合并后的路由是否有效。使此合并和检查过程非常快速也很简单,例如,对所有路径的 FL 进行按位与操作。
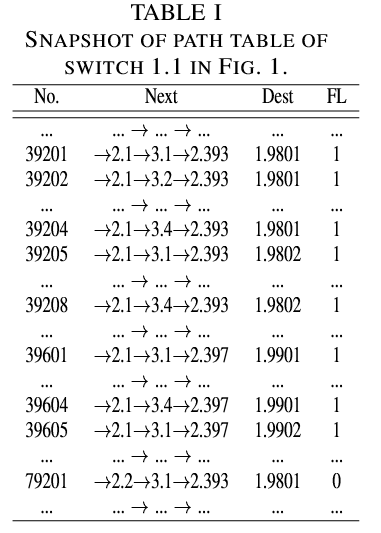 表 I 显示了交换机 1.1 的路径表快照,假设从交换机 1.1 到 2.1 的链路发生故障(受影响的条目的 FL 增加了 1)。
表 I 显示了交换机 1.1 的路径表快照,假设从交换机 1.1 到 2.1 的链路发生故障(受影响的条目的 FL 增加了 1)。
- 链路表:记录基础拓扑中所有链路的当前状态。支持 O(1) 时间定位受影响路径。
- 链路状态变化时才在路径表中进行暴力搜索以找出哪些条目会受到已经为时已晚。因此,预先计算每条链路的所有受影响路径,并在每个链路表条目中维护一个数据结构,以智能地索引路径表中受该链路影响的所有路径条目,时间复杂度为 O (1)。
- 用于维护此类索引的直观数据结构是位图,其中每个位表示某条路径是否包含该链路。然而,由于路径表中总共有 k × s × n 个条目,这种简单的位图会消耗过多内存。例如,在图 1 中,这样的位图需要 160Kb 内存来索引所有路径条目,而 40K 条链路中的每条都需要一个这样的位图,总共需要约 6.6Gb 内存。随着规模的扩大,这种内存消耗将变得不可接受1。
- 幸运的是,在 DCN 中,链路状态变化对路由路径的影响仅有几种固定的模式,具体来说,从交换机的角度来看,胖树拓扑中的链路可以分为四种类型:类型 1:对于从 ToR(架顶交换机)到 Agg(汇聚交换机)的上行链路,它将影响总共 n×k×p 条路径条目,即从该 Agg 出发到所有 k×p 个目的地的 n 条路径。类型 2:对于从 Agg 到 Core(核心交换机)的上行链路,它将影响总共 k×(p−1) 条路径条目,即通过该链路到所有其他 pod 中 k×(p−1) 个目的地的单条路径。类型 3:对于从 Core 到 Agg 的下行链路,它将影响总共 k 条路径条目,即通过该链路到该 pod 中所有 k 个目的地的单条路径。类型 4:对于从 Agg 到 ToR 的下行链路,它将影响总共 n 条路径条目,即通过该 Agg 到 ToR 的单一目的地的 n 条路径。因此,可以使用一种紧凑的数据结构,只需指示链路类型以及受该链路影响的第一个路径,并根据上述模式快速索引所有受影响的路径条目。这种数据结构仅需要 2 位(用于类型)加上 位(用于第一个受影响条目的索引)。
 表 II 展示了图 1 中交换机 1.1 的链路表快照。最后一列是受影响路径条目的索引。如果按照表 I 所示的顺序(即按第一跳、目的地、第二跳的顺序)组织路径表中的条目,类型
表 II 展示了图 1 中交换机 1.1 的链路表快照。最后一列是受影响路径条目的索引。如果按照表 I 所示的顺序(即按第一跳、目的地、第二跳的顺序)组织路径表中的条目,类型 1:1表示链路 1.1→2.1 影响从条目 1 开始的连续 40000(4×100×100)个条目;类型2:401表示链路 2.1→3.1 总共影响 9900(100×99)个条目,其中包括从条目 401 开始的每 4 个条目中的第一个。
深入分析新的
类型+链表式数据结构数据结构设计:
每个链路表项包含以下字段:
- Type(2 bits):标识链路类型(Type 1-4)。
- Start Index(log₂(N) bits):记录该链路影响的路径表(Path Table)中第一个条目的索引。
- Count(可选,log₂(M) bits):记录连续受影响的路径条目数量(可根据类型推导,可能省略)。
示例:
- Type 1(ToR→Agg 上行链路):
- 影响所有通过该 Agg 的路径(如
n × k × p条)。- 起始索引指向路径表中该 Agg 对应的第一条路径,后续条目按固定步长连续分布(如每 4 条路径对应一个 Agg 的上行链路)。
- Type 3(Core→Agg 下行链路):
- 影响该 Core 连接的 Pod 内所有 ToR 的路径(如
k条)。- 起始索引指向该 Core 在路径表中的第一条相关路径。
- 压缩原理:
- 规律性拓扑的路径分布:胖树(Fat-Tree)等数据中心拓扑的路径具有对称性和规律性。例如,Type 1 链路影响的路径是连续的,只需记录首路径索引和数量;Type 2 链路影响的路径每隔固定步长出现(如每 4 条路径中的第 1 条),通过首索引+步长公式计算。 。
- 数学推导代替存储:根据链路类型和拓扑参数(如
k, s, p, n),通过公式计算受影响路径的范围,而非存储具体条目。例如:Type 2 链路(Agg→Core)影响k × (p-1)条路径,起始索引为base + (core_id × k × p)。内存优化效果:
- 传统位图需
O(N)空间(N 为路径总数),而压缩结构仅需O(1)空间(每链路固定字段)。- 如论文示例,10K 交换机的拓扑中,链路表仅占用 1.3MB,远低于位图的 6.6GB。
Handling Control-Plane Failure
设计思路:通过冗余通信与无状态控制器实现快速容错:
- 冗余 LS 消息:每个 LS 更新通过主通道(TCP)和冗余通道(UDP)多路径发送,确保至少一条路径成功。
- 无状态热备控制器:主控与备控无需同步全局状态,故障时备控可立即接管,避免 LSDB 同步延迟。
- 间接通道恢复:主控链路故障时,通过数据平面建立间接通信通道,维持控制平面连通性。
技术改进:
- 低开销冗余:冗余消息使用轻量 UDP,仅需处理首个到达的 LS 副本,避免 ACK 与重传开销。
- 慢同步与快恢复分离:后台共识协议(如 Raft)用于主控选举,不影响实时路由更新。
有效性原因:
- 冗余覆盖多故障域:不同传输路径和控制器降低单点故障风险,符合 DCN 控制平面的高容错需求。
- 无状态设计:主控不维护全局状态,故障切换无需等待同步,恢复时间从秒级降至毫秒级。
实现细节: Architecture 中描述的可靠 LS 报告方案确保网络对最新的 LS 变化具有最终一致性视图,而无需依赖主节点或网络其他部分维护的状态。因此,可以使用控制平面冗余(备用主节点和冗余 LS 消息)来容忍故障。
可靠 LS 报告方案与控制平面冗余的关联
可靠LS报告方案的核心:
- Reporter Switch 负责端到端确认:每个LS变更由Reporter Switch发起,通过多路径冗余传递(UDP副本),并等待所有受影响交换机的ACK。若主控制器故障,备份控制器可独立处理冗余消息。
- 主控制器无状态化:主控制器仅转发LS消息,不存储全局LSDB,状态由Reporter Switch维护。备份控制器无需实时同步LSDB,仅需在故障时通过共识协议(如Raft)缓慢同步。
- 主通道(TCP):确保LS更新可靠传递,通过ACK机制和重传保证交付。
- 冗余通道(UDP):通过多路径、多控制器发送冗余LS副本,覆盖不同故障域。
与控制平面冗余的协作机制:
- 无状态备控快速接管:
- 备控不维护全局LSDB,收到冗余LS后直接转发,无需等待状态同步。
- 主控故障时,任意备控可立即处理新LS更新,避免选举延迟。
- 备份控制器在正常时处于“热备”状态,无需同步LSDB,仅在主控制器故障时接管。由于LS消息已通过冗余传递,备份控制器可直接处理未完成的LS变更。
- 冗余覆盖多故障域:
- LS副本通过不同物理路径(数据平面)和控制器传递,即使部分控制平面链路或控制器故障,仍有副本可达目标交换机。
- 最终一致性保证:
- 交换机仅处理首个到达的LS副本(基于唯一ID),忽略重复消息,确保最终所有节点状态一致。
- 主控通过ACK确认全网更新完成,与冗余通道解耦,避免冗余消息的ACK开销。
可靠LS报告通过冗余消息和Reporter Switch确保LS变更最终一致,不依赖控制器状态。控制平面冗余(多控制器、多路径)在此基础上提供高可用性,两者结合实现“无状态快速容错”。
设计有效性原因:
- 解耦状态与传输:控制平面冗余不依赖全局状态同步,故障恢复速度从秒级(如Raft选举)降至毫秒级(直接处理冗余消息)。
- 物理冗余与逻辑简化的平衡:通过轻量冗余(如3份UDP副本)覆盖常见故障场景,避免全网络泛洪的开销。
具体而言,Primus 采用了以下容错方案:
- Slight redundancy for speed. Primus使用多个热备份主控,每个交换机预配置了主控的静态地址,并通过主通道和UDP冗余通道报告和传递链路状态变化,从而即使在复杂的控制平面或主控故障下,只要至少有一个主通道或其他通道工作,Primus仍能保持快速的路由响应,具体设计如下:
- 对于交换机而言,每当检测到数据平面中的本地LS变化时,除了通过其主通道报告该LS外,还会通过其他可达交换机使用常规数据平面网络(图2(b)中的实线红色箭头)将LS的多个副本发送到备份主节点。这些交换机会立即通过其自身的控制平面链路(图2(b)中的虚线红色箭头)将这些副本转发给备份主节点。类似地,备份主节点会将此类副本发送到其他交换机(这些交换机会进一步转发),以将LS更新传递到目标交换机(图2(b)中的黄色箭头)。上述LS副本通过随机选择(且不同)的转发交换机和备份主节点,使用低开销的不可靠传输(例如UDP)进行传输,并且从不进行ACK或重传。这就在主节点和交换机之间形成了多个其他通道。
- 目标交换机将处理所有副本(包括原始副本)中第一个到达的LS消息,并忽略其他消息(基于消息ID)。需要注意的是,交换机在首次处理该LS时(无论来自主通道还是其他通道),始终会通过主通道向主节点发送ACK,因此主节点可以快速通知报告交换机整个网络已完成路由更新。
- Slow detection and synchronization with low-overhead. Primus通过慢速检测和低开销同步来处理主通道故障和主控故障,确保网络路由的快速收敛。
- 通过周期性的hello消息检测主通道状态。借助前述的容错方案,这种hello消息可以非常缓慢(例如分钟级的TCP保活),而不会使控制平面故障时的路由反应过分延迟。一旦检测到主通道失效,将建立间接通道作为新的主通道来传递控制平面消息。对于交换机而言,如果它检测到其主通道失效,它会根据其本地路由表通知数据平面中可能可达的其他交换机,并选择第一个响应的交换机,通过它建立一条间接的可靠数据平面通信通道到主节点,作为新的主通道。类似地,当主节点检测到某个目标交换机的主通道失效时,也会建立间接主通道。
- 在所有主节点(包括主、备)之间运行共识协议(例如Raft)。需要注意的是,共识协议不会影响正常的链路状态处理,而仅在后台运行以检测主节点故障并重新选举主节点。一旦原主节点失效后选举出新主节点,它将通知所有交换机。为了集中管理和控制,在主节点故障时维护全局网络状态,共识协议还会在后台缓慢交换主节点和备份节点之间的最新全局链路状态(仅为尽力而为,并非路由正确性的必要条件)。需要注意的是,共识协议与链路状态变化时的正常路由反应解耦,因此可以以非常低的频率运行,从而开销极低。
Other Design Details
-
控制路由震荡(Controlling Routing Flaps):
- 改进:
- 首次链路状态变化立即上报,确保快速响应;此外每个交换机为本地链路维护一个计时器,该计时器不用于每个链路的首次状态变化,而是仅对后续连续状态变化更新到主控节点进行抑制(如抑制短时间内重复上报同一链路状态变化)。
- 定时器可以通过在链路表为每个本地链路添加时间戳来实现,指示上次状态变化的时间,故而开销很小。
- 有效性:
- 对连续状态变化的抑制,能够避免因链路震荡导致的路由表频繁更新(传统BGP可能因MRAI定时器导致延迟累积)。
- 改进:
-
路由初始化与重启(Routing Initialization/Reboot):
- 改进:
- 交换机预配置基础拓扑、自身位置(如Pod ID)及所有主控制器的静态地址,基于预配置生成基础路径和链路表。当交换机初始化或从崩溃中重启时,会与所有主节点简历主通道并报告基础信息、确定当前的主节点(主节点也可以通过交换机报告的位置发现拓扑布线错误)。
- 初始化时,交换机通过主控制器获取本地链路的最高LS事件的ID,检查本地所有链路状态后,使用最高 LS 事件 ID++的方式报告所有当前状态,确保全局对最新链路状态的一致。
- 主控制器初始化或从崩溃中重启时,通过共识协议(如Raft)确定(或重新选举)主节点,并开始监听/处理交换机的 LS 消息。
- 有效性:
- 快速恢复路由状态,无需依赖分布式协议的全网同步(如BGP的邻居重建需数秒)。
- 预配置机制避免了传统协议初始化时的“冷启动”问题。
- 改进:
-
多链路失效与交换机失效(Multi-Link Failures and Switch Failures):
- 改进:
- 多链路失效视为独立事件处理,逐个触发LS更新。
- 交换机失效通过主控制器检测(所有主控制器均无法通过冗余路径访问该交换机),并通知全网将其视为所有链路断开。
- 有效性:
- 避免分布式协议中因多故障引发的“状态不一致”问题(如BGP的路径撤销延迟)。
- 集中式决策确保全网对故障的统一视图。
- 改进:
-
与外部路由器的交互(Interacting with External Routes):
- 改进:
- 仍采用 BGP 与外部 Internet 路由器交互,由边界交换机(如Core层)运行BGP实例,但仅在外部端口启用。
- 内部路由由Primus处理,外部学习到的 BGP 路由通过Primus的LS机制分发到内部交换机。
- 有效性:
- 结合BGP的外部路由能力与Primus的内部快速收敛,避免传统方案(如纯BGP)的内外部耦合复杂性。
- 边界交换机通过Primus的路径表将外部流量导向内部最优路径。
- 改进:
-
控制平面内的路由(Routing in Control-Plane):
- 机制:
- 控制平面网络规模较小,冗余方案能够低成本地、可靠地快速处理控制平面故障,因此使用OSPF等传统分布式协议在 CPN 中路由。
- 有效性:
- 利用成熟协议简化实现,冗余设计避免单点故障(如Firepath依赖单一主控制器)。
- 机制:
-
集中式路由控制与管理(Centralized Routing Controllability/Manageability):
- 改进机制:
- 路径表和链路表的显式维护允许细粒度控制(如自定义路径权重)每个交换机的路由。
- 全局LSDB支持可视化故障定位和拓扑错误检测(如交换机位置与配置不符)。
- 有效性:
- 管理员可直接操作路径表实现策略(如负载均衡或流量隔离),无需复杂的分布式配置(如BGP的路由策略)。
- 改进机制:
Discussions and Limitations
-
主控制器状态丢失(Master State Loss):
- 问题:主控制器无状态化可能导致历史 LS 记录丢失,从而控制/管理功能临时失效。
- 缓解方案:
- 后台通过共识协议(如Raft)低频同步主备控制器状态,确保最终一致性。
- 路由正确性不依赖实时同步,仅依赖Reporter Switch机制保证LS传播;关键路由功能依赖于交换机的本地表,高级功能对时间的敏感性较低,允许短暂不一致。路由收敛与状态同步这两个功能解耦,避免同步延迟影响故障恢复。
-
路由正确性(Routing Correctness):
- 核心保证:
- 仅预安装最短路径,通过FL字段动态禁用/启用失效路径。因此只会使用最短路径,避免非最短路径导致的环路(如传统FRR的临时环路问题)。
- 当物理上仅存在非最短路径时(例如,回弹到上层交换机),路由可能不可达,Primus无法自动切换,需依赖DCN的高冗余设计,不过DCN拓扑通常提供充足等价最短路径,非最短路径场景极少。
- 由于某个LS只有一个生成器,即报告交换机(主交换机和其他交换机仅用于转发),因此整个网络中的路由最终是一致的。
- 核心保证:
-
合并路由的不可行性(Why Not Use Merged Routes?):
- 问题:仅合并路径(如相同下一跳的多路径)而不监控该路由上所有链路的状态,交换机无法判断可用性。
- Primus的解决方案:
- 维护完整路径表,通过FL字段直接判断路径是否可用。
- 有效性:
- 避免主控制器的集中计算(如Firepath的SPF算法),降低延迟和一致性风险。
-
集中式表查找的不可行性(Why not centralized table-lookup?):
- 内存与性能瓶颈:每个交换机本地的路径表和链路表会基于位置单独计算,若将所有交换机的路径表集中在主控,总内存需求爆炸(如10K交换机需30GB+)。
- 一致性问题:由主控制器负责全部计算,性能会很差且控制平面故障时会出现一致性问题。分布式计算还能支持并行更新。
-
控制平面流量突发(Traffic Incast/Outcast to/from the master):
- 流量突发的情况:
- Incast:1)多个交换机同时向主节点报告本地 LS 变化,然而并发 LS 变化的数量通常非常少,这只会产生非常低的 LS 报告流量;2)多个交换机在接收到 LS 时同时向主节点发送确认,然而以图 1 中的大型拓扑为例,即使所有交换机同时发送确认,整个流量也少于 700KB(每个确认 64B),这远低于现代 DCN 交换机的缓冲区容量,因此不太可能导致丢包。另外,交换机还可以在发送确认前添加一些随机延迟,这种设计的延迟仅适用于确认,不会增加路由反应时间。因此总的来说,Incast 导致的拥塞问题并不严重。
- Outcast:主节点确实需要向大量受影响的交换机发送大量 LS。然而,这不会花费太多时间,即使对于数万台交换机,也可以在几十毫秒内完成(实验可证明)。
- 流量突发的情况:
-
适用性限制(Primus for other topologies):
- 拓扑依赖:Primus 依赖规律性拓扑(如Fat-Tree),无法直接应用于随机拓扑(如Jellyfish)。
- 扩展性:表结构内存占用随规模线性增长(10K交换机需约10MB),但现代硬件可轻松支持。
核心设计思想与有效性总结
- 预配置与事件驱动:
- 预配置基础拓扑和位置信息,结合事件 ID 机制,确保初始化和重启的快速一致性。
- 对比 Firepath 的全网 LSDB 同步,Primus 的事件驱动机制显著减少同步开销。
- 冗余与容错协同:
- Reporter Switch 机制和 UDP 冗余消息确保 LS 传播的可靠性,容忍控制平面故障。
- 主备控制器的低频同步避免影响实时路由处理,而 Firepath 的同步需阻塞 LS 处理。
- 显式路径管理:
- 路径表和链路表的显式维护支持细粒度控制,而 Firepath 依赖交换机的本地 SPF 计算,管理复杂度高。
- 拓扑规律性利用:
- 通过分类链路类型(4 种)和数学推导压缩索引结构,内存占用降低 3 个数量级(对比位图方案)。
最终效果:在路由震荡抑制、故障恢复、管理可控性等方面,Primus 通过集中式设计与拓扑规律性结合,解决了传统协议(如 BGP、Firepath)的收敛延迟和复杂性问题,同时保持了高可扩展性和容错性。
Implementation and Testbed Setup
Primus Implementation
实现细节:
- 代码与平台:Primus 实现为守护进程,运行在每个交换机和主机上,基于 Linux 和 Ruijie 白盒交换机(基于 SONiC 交换机操作系统)。
- 核心组件:
- 链路监控器:通过 Linux
epoll事件监控交换机的 NIC 端口状态。 - LS 更新器/接收器:主通道(TCP 长连接)与冗余通道(UDP 多路径)对 LS 及其他控制消息的报告/接收/转发,其中每个 LS 被格式化为一个 52 字节的数据结构。
- 路由计算器/更新器:基于预存路径表和链路表,通过
rtnetlink更新 Linux 内核路由表。
- 链路监控器:通过 Linux
- 主控设计:基于
epoll事件循环的多个 TCP 线程与多个交换机通信,支持高并发的 LS 分发。主机选举协议使用 Raft。
Testbed Setup and Methods Compared
测试环境搭建:
- 规模模拟:
- 物理拓扑:物理测试床仅含 14 台交换机(3 台 Ruijie 物理交换机+11 台 UbuntuVM),但通过逻辑配置模拟大规模拓扑(如 10K ToR 的 Fat-Tree)。通过 Dell R720XD 服务器 托管虚拟交换机,物理交换机通过 1Gbps 链路互联。
- 控制平面:4 个 Master 节点(1 主 + 3 备份),通过 1Gbps 带外网络 通信。使用 Raft 协议 实现主备切换,心跳间隔 5s,选举超时 30s。
- 对比方案:
- Firepath:基于 Yen 的 k-SPF 算法和 Raft 协议实现,模拟大规模拓扑时关闭计算以测试控制平面开销。
- BGP:使用 Quagga 实现,配置适用于生产 DCN 参数(如 1s 的通告计时器和 4s 的连接回复计时器)。
- 冗余设计:每个 LS 生成 3 份 UDP 冗余副本,通过随机路径传递。
- 故障注入:随机链路抖动(Log-Normal 分布)与控制平面链路故障。
实验设计的思路与一些疑惑
实验设计的独特性与优势
- 逻辑扩展代替物理部署:
- 背景:受限于硬件资源,无法真实部署 10K 交换机。
- 设计:通过单物理机运行多个虚拟交换机进程,安装完整大规模拓扑表结构(路径表+链路表),模拟 10K 规模的路由处理性能。
- 优势:验证算法扩展性,避免物理设备成本与复杂度。
- 混合物理与虚拟环境:
- 物理交换机验证:在 Ruijie 交换机上实测路由更新耗时(如内核路由表修改时间),确保方案在真实硬件中的可行性。
- 虚拟机灵活性:通过虚拟化快速注入故障(如控制平面链路瞬断)。
- 精细化指标测量:
- 路由处理时间分解:分别测量主控分发耗时(socket 发送/接收)、交换机查表耗时、内核路由更新耗时,明确性能瓶颈。
- 冗余有效性验证:统计 LS 副本通过冗余通道到达的比例,量化容错机制的效果。
发散性问题与解答
- 为何选择 Raft 协议作为主控选举机制?
- 答:Raft 以易实现性和高可读性著称,适合快速集成到 Primus 原型中。其强一致性保障适合主控选举,但后台运行(与实时路由解耦)避免影响性能。
- 小规模测试床如何保证大规模模拟结果的可信度?
- 答:
- 计算与通信分离:路由处理时间主要依赖本地查表(与交换机数量无关),逻辑扩展可反映真实性能。
- 压力测试:通过单机多进程模拟 10K 交换机,验证主控分发与 socket 处理的并发能力。
- 硬件基准测试:在物理交换机上验证关键操作(如内核路由更新)的耗时,确保模型与实际一致。
- 如何应对更复杂的故障场景(如主控与数据平面同时故障)?
- 答:
- 实验局限:当前测试仅注入单一或组合故障(如控制平面链路失效+主控故障)。
- 扩展方向:可设计多节点持续故障(如主控集群部分宕机+数据平面分区),验证 Primus 的跨域冗余机制。
- 为何未使用 DPDK 等高性能网络框架?
- 答:
- 原型验证目标:优先验证算法有效性,而非极致性能优化。
- 未来方向:集成 DPDK 可进一步提升 LS 消息处理速度(如纳秒级响应)。
- 为什么选择 SONiC 作为交换机 OS?
- 答:
- SONiC 是开源的、模块化的交换机 OS,支持容器化部署,便于集成自定义路由逻辑。
- 兼容 Broadcom 等主流交换机芯片,适合在生产环境中快速部署。
- 如何模拟 10K 交换机的大规模网络?
- 答:
- 在单台服务器上运行多实例虚拟交换机,共享预配置的路径表和链路表。
- 通过 事件驱动模型 模拟 LS 消息传播,避免真实网络的带宽限制。
- 测试中如何保证实验的可重复性?
- 答:
- 使用 固定拓扑配置文件 和 确定性故障注入脚本。
- 通过 Raft 日志和 LS 事件 ID 确保控制平面操作可追溯。
- Primus 在测试中暴露的潜在问题?
- 可能问题:
- UDP 冗余消息的开销:在极端规模下,冗余消息可能占用较多带宽,需进一步优化传输策略。
- 拓扑依赖性:目前仅支持规则拓扑(如 Fat-Tree),对随机拓扑(如 Jellyfish)需重新设计索引结构。
Evaluation on Routing Processing
Switch Processing
实验设置:
- 硬件:在 Ruijie B6510-48VS8C 物理交换机上运行 Primus 进程,安装大规模拓扑(10K ToR、400 Agg、16 Core)的路径表(160K 条目)和链路表(40K 条目)。
- 测试方法:
1. 本地生成随机 LS 变化(链路故障/恢复)共 10K 次。
2. 测量路由处理时间(从接收 LS 到更新内核路由表)。
3. 对比 Firepath 的 SPF 算法耗时(同一拓扑下)。
结果:
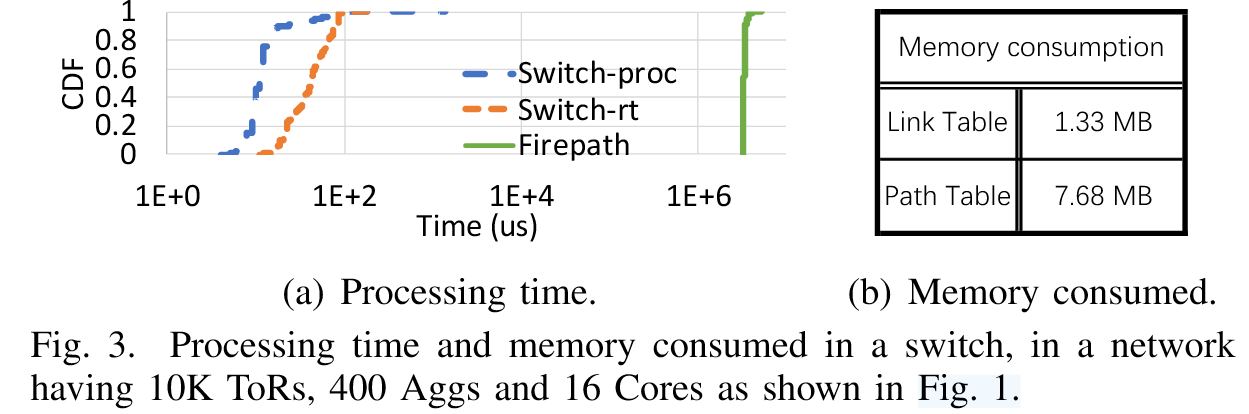
- 处理时间:
- Primus 交换机处理时间:50%分位:11μs,99%分位:110μs
- Firepath(k-SPF 计算):单次 LS 更新耗时>3 秒(比Primus慢 10⁴-10⁵倍 )。
- 内核路由更新耗时:
- 50%分位:41μs,99%分位:92μs
- 内存占用:
- 链路表:1.33MB
- 路径表:7.68MB
数据分析:
- 优化效果:
- 通过预存路径表+智能索引,Primus 将路由计算复杂度从 降至 ,实现微秒级更新。
- 路径合并减少内核路由表更新频率(仅在下一个路由 hop 的所有路径失败或下一个路由 hop 的所有路径失败后有一条路径返回时才触发),降低系统开销。
- 改进空间:
- 极端场景下的内存限制:当前内存占用<10MB/交换机,但若拓扑更复杂(如更多层级或随机拓扑),内存可能成为瓶颈。
- 硬件加速:通过 FPGA 或 ASIC 加速查表操作(如 TCAM),结合DPDK等高性能框架,进一步压缩处理时间至纳秒级。
Overall Routing Processing
实验设置:
- 硬件:两台物理服务器模拟大规模网络,其中
- 主控:Dell 服务器(25Gbps NIC 连接,9 发送线程+2 接收线程,线程绑定专用 CPU 核心)。
- 交换机模拟:单物理机运行多虚拟交换机进程,模拟 200 至 10K 规模,测试整体路由收敛时间。Primus主机和交换机都安装有图1所示的整个拓扑的完整数据结构(10K ToR、400 AGG和16 Core)
- 需要注意:
- 对于每个LS,主机将把它传送到所有交换机进程,从而评估套接字发送/接收的开销。
- 由于所有交换机进程都运行在同一台物理机器上,因此只有一个交换机进程实际执行表查找计算并更改Linux内核路由。
- 所有其他交换机进程仅在收到LS更新后直接向主机回复确认。
- 测试方法:
- 单交换机报告随机的 LS 变化,等待主控向所有交换机分发更新/接受确认/回复响应。
- 测量总处理时间(报告交换机生成 LS 消息→主控响应)、主控处理时间(主控接收到 LS 到通过 socket API 发送完所有 LS 更新)和交换机处理时间(交换机接收到 LS 更新,计算并更改路由,直到完成向主机发送确认)。
- 对比不同冗余级别(0/1/3 UDP 副本)的性能。
结果:
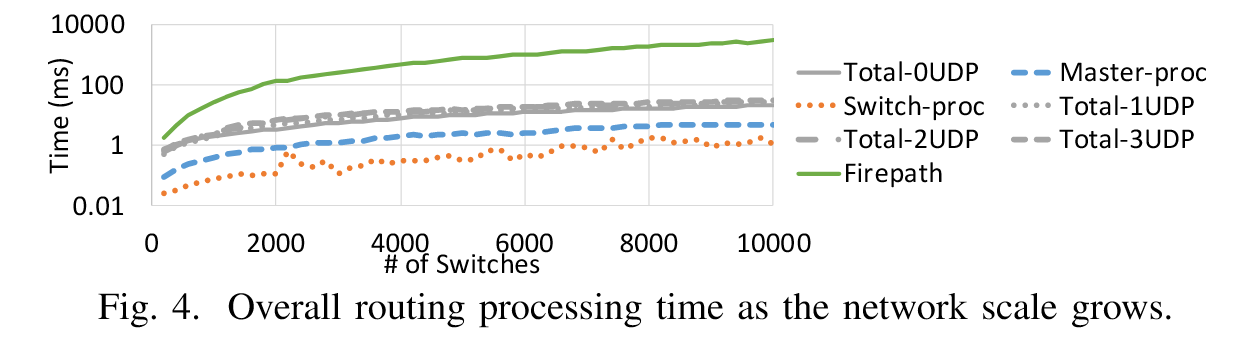
- 总处理时间(10K 交换机):
- 0 冗余:22ms
- 1/2/3 冗余:26/29/32ms
- Firepath:>3 秒(比Primus慢 98-148倍 )
- 主控处理时间:
- 10K 交换机下约 5ms(主要耗时在 socket API 调用)。
- 交换机处理时间:
- 平均 1ms(含查表与 ACK 回复)。
处理时间差异巨大的原因
总处理时间与主/交换机处理时间之间存在较大差距,这是由于在同一物理机器上运行的所有10K交换机进程的处理时间造成的。
由于这些进程是并行和独立运行的,因此无法准确地度量它们对总体路由处理时间的贡献。
数据分析:
- 优化效果:
- 无状态主控+多线程:主控分发效率高(5ms/10K 交换机),避免集中式计算瓶颈。
- 冗余设计代价可控:3 冗余仅增加 11ms 延迟,权衡了可靠性与性能。
- 改进空间:
- 主控网络栈优化:当前主控耗时集中在 socket 操作(非计算),可通过零拷贝或内核旁路(如 DPDK)进一步压缩至亚毫秒级。
- 动态冗余策略:根据网络状态(如故障率)动态调整冗余副本数量,平衡开销与可靠性。
总结与潜在改进方向
- 当前优势:
计算效率:本地查表替代动态 SPF,性能提升达 10^5 倍。
扩展性:10K 规模下处理时间线性增长,验证算法可扩展性。
轻量级容错 :冗余消息机制与无状态控制器设计,确保控制平面故障下仍保持毫秒级收敛。
- 潜在改进措施:
混合计算模式:对非常规拓扑(如部分随机化)引入轻量动态计算作为备用方案。
内存压缩算法:针对超大规模拓扑(如 100K+交换机),开发更紧凑的索引结构(如稀疏位图)。
硬件协同设计:与交换机芯片厂商合作,将路径表/链路表固化到硬件存储(如 SRAM),实现纳秒级响应。集成DPDK或智能网卡(SmartNIC)卸载路由计算,降低内核态延迟。
混合路由策略 :结合数据平面快速恢复(如FRR)与Primus的集中式控制,进一步缩短尾延迟。
- 实验局限性:
- 当前测试基于模拟环境,真实超大规模网络(100K+交换机)的性能需进一步验证。
Evaluation on Routing Convergence
Macro-benchmark
实验设置(Setup):
- 应用场景:模拟分区-聚合应用(Partition-Aggregate):
- 1 台服务器(ToR 1.1)向 3 台客户端(ToR 1.9801)发送周期性 TCP 请求(每秒 1 次),使用请求-响应模式(2KB 响应)。
- 故障注入:随机链路抖动(down/up 时间<30ms,包括 CPN 中的链路),链路抖动的时间间隔服从对数正态分布(平均 100 秒)。
- 对比方案:Primus vs. BGP(Quagga) vs. Firepath(含/不含 SPF 计算)。
- 指标:作业完成时间(JCT,从发送请求到接收所有响应)。
结果(Result):
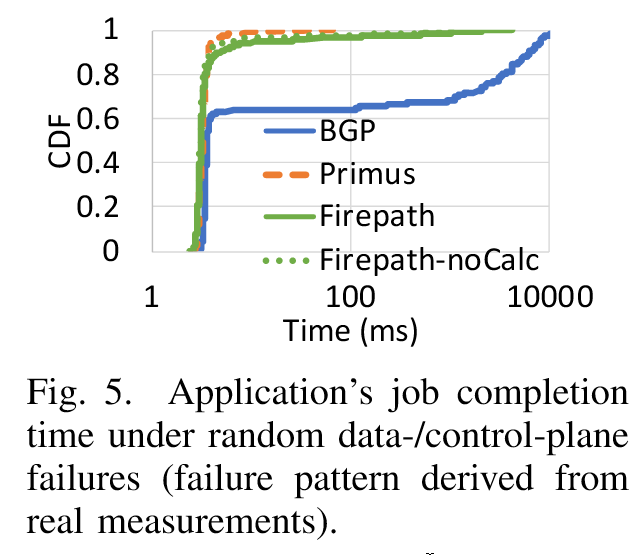
- JCT 分布:
- Primus:99%分位:9.4ms,99.5%分位:10.5ms,最大延迟:67ms(触发 1 次 TCP RTO)
- Firepath:99%分位:1.02s,99.5%分位:1.05s,最大延迟:4.1s(单链路故障恢复耗时——SPF计算和LSDB同步延迟)
- BGP:99%分位:11.9s,99.5%分位:12.9s比Primus慢 ~1226倍)
- Firepath-noCalc(关闭 SPF 计算):
- 99.5%分位 JCT 仍>1s(控制平面同步开销主导)。
数据分析:
- 优化效果:
- Primus 的快速收敛:得益于本地查表(μs 级更新)与冗余 LS 传递,链路抖动几乎不影响应用层(JCT<70ms)。
- Firepath 瓶颈:SPF 计算(>3s)与主控同步(Raft 协议)共同导致秒级延迟。
- 改进空间:
- 更细粒度的故障注入:测试未覆盖多链路并发失效与持久分区场景,需验证 Primus 在极端故障下的鲁棒性。
- 应用层协同优化:结合 Primus 的快速收敛特性,设计应用层重传策略(如缩短 TCP 超时),进一步降低尾延迟。
Micro-benchmark
实验设置(Setup):
- 流量模型:注入单向 UDP 流(400Mbps),路径为 1.9801→2.393→3.1→2.1→1.1。
- 故障场景:
- 数据平面故障:断开链路 2.1↔1.1。
- 控制平面故障的组合:如
-ctrl:Reporter Switch的控制链路故障;-2slave/-3slave:2或3个备份控制器链路故障;-lead:主控制器故障。
- 测量方法:以 30ms 时间粒度统计接收端吞吐量,观察路由恢复时间。
结果(Result):
-
路由响应时间:
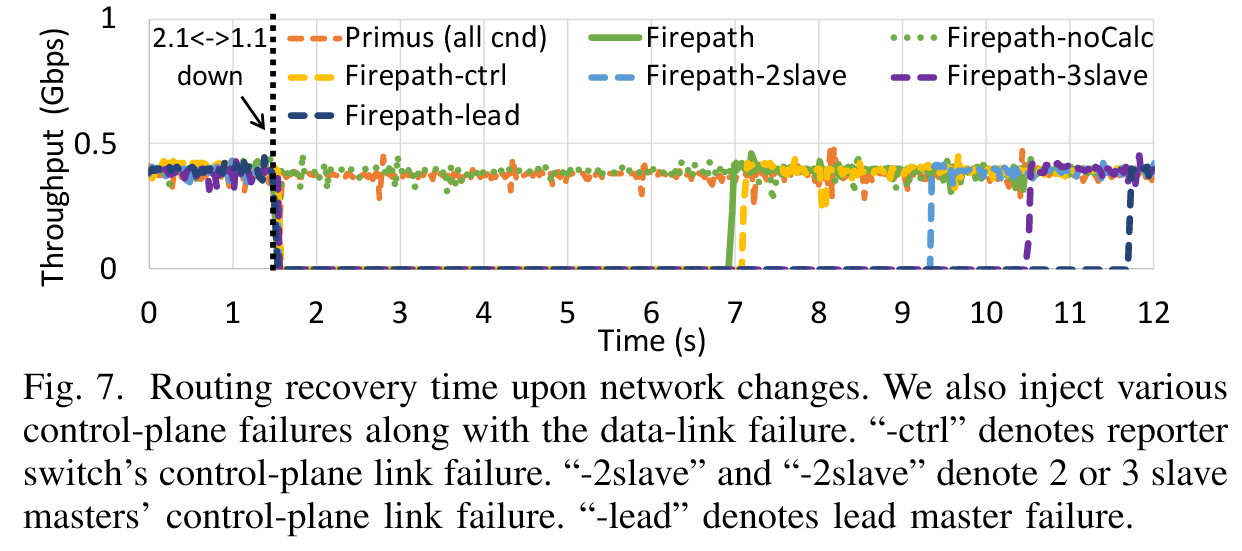
- 纯数据平面故障:
- Primus:吞吐量短暂下降至 10Mbps(时间粒度太小,这样的度量并不准确,但数量级不会差太多),30ms 内恢复。
- Firepath:吞吐量归零持续 5.4 秒(主要是 SPF 计算耗时),这段时间内路由无法正常运行。
- 混合故障(控制平面+数据平面):
- Firepath:
- 主控故障:恢复耗时额外增加 5 秒(Raft 选举)。
- 备控链路失效:恢复耗时增加 2-3.5 秒(LSDB 同步阻塞)。
- Primus:所有混合故障场景下恢复时间均<30ms。
- Firepath:
- 纯数据平面故障:
-
Primus 冗余效率:(增加了每个控制平面链路故障的持续时间,以评估 Primus LS 冗余方案的效率)
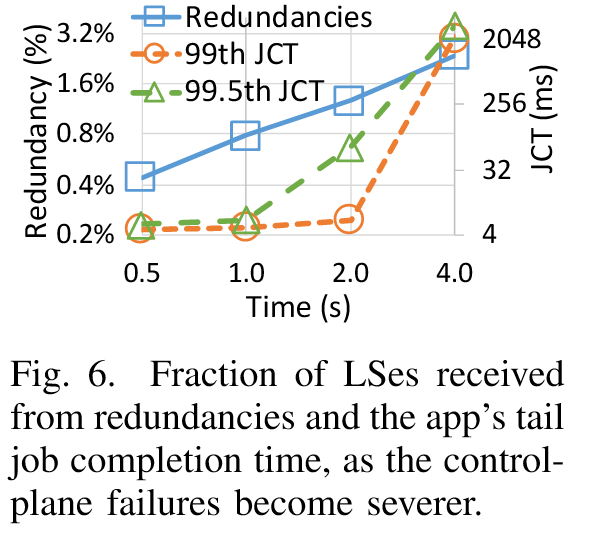
- LS冗余占比:控制平面故障越严重,冗余消息占比从 0.4% 升至 2.4%——有助于 Primus 在控制平面链路故障持续 2s 时,保持第 99 和 99.5 个百分位 JCT 在 10ms 和 70ms 以下,即使故障持续时间小于 30ms,也明显优于 Firepath 的结果。
- 尾延迟:即使控制平面故障持续4秒,Primus的第 99 和 99.5 个百分位 JCT 仍 <2.2秒和 <3.2秒(Firepath在30ms故障下已超时)。
数据分析:
- 优化效果:
- 冗余覆盖多故障域:即使控制平面链路或主控故障,冗余 LS 副本仍可通过其他路径传递,确保快速恢复。
- 无状态设计优势:主控切换无需等待状态同步,恢复时间与故障类型解耦。
- 改进空间:
- 更复杂的故障组合:测试未覆盖数据平面分区(如多 Pod 隔离)+控制平面全网故障,需验证 Primus 的最终一致性边界。
- 硬件级冗余:在交换机芯片中固化冗余通道(如硬件多播),避免依赖软件转发引入的随机性。
After Reading
Primus 设计思路优势总结
-
查表式路由计算:
- 利用数据中心拓扑的规律性(如 Fat-Tree),将路由更新简化为预定义规则驱动的表项启用/禁用,时间复杂度降至 O (1),显著优于传统 SPF 算法的 O (kn (m+n log n))。
- 内存优化:通过链路类型分类(4 种)设计紧凑索引结构,内存占用比位图方案降低 3 个数量级(10MB vs. 6.6GB)。
-
控制平面冗余机制:
- Reporter Switch 机制确保 LS 消息可靠传递,主控制器无状态化,备份控制器热备,无需实时同步 LSDB。
- 冗余消息通过不同故障域传输(如多备份控制器和物理链路),容忍控制平面故障,收敛时间保持 10ms 级。
-
混合容错与可扩展性:
- 分离路由计算与控制平面同步,避免传统协议(如 BGP、Firepath)的分布式不一致性和同步延迟。
- 支持超大规模网络(10K+交换机),实验显示收敛时间比 BGP 快 ~1200 倍,比 Firepath 快 ~100 倍。
形式化推导可行性分析
Primus 的设计可通过以下形式化方法验证:
-
模型检测(Model Checking):
- 验证查表机制在拓扑变化时的正确性(如路径表更新是否覆盖所有可能故障场景)。
- 使用工具如 Spin 或 NuSMV 模拟不同链路状态变化,确保无死锁或路由环路。
-
性能建模:
- 通过排队论或概率模型(如马尔可夫链)分析冗余消息机制的覆盖概率与收敛时间关系。
- 验证在 n 个冗余副本下,至少一个消息成功传递的概率是否满足 SLA(如 99.999%)。
-
拓扑泛化证明:
- 形式化证明查表规则对 Fat-Tree、BCube 等规则拓扑的普适性,并分析对部分随机拓扑(如 Jellyfish)的适应性边界。
实验设计扩展性分析
优势:
- 虚拟化模拟通过事件驱动模型和共享内存高效模拟大规模网络,验证了核心机制(如查表与冗余)的可行性。
- 物理交换机测试(Ruijie SONiC)确保方案在真实硬件上的兼容性。
局限性:
-
规模扩展假设:
- 虚拟机模拟的交换机进程共享同一物理资源(CPU/内存),可能低估真实网络中的资源竞争(如多交换机并行更新时的拥塞)。
- 需进一步测试 100K+交换机 规模下的控制消息开销(如 LS 冗余副本的带宽占用)。
-
故障场景覆盖:
- 当前实验主要模拟单链路故障和控制器故障,未充分测试 多故障级联 或 控制平面分区 场景。
改进建议:
- 使用大规模网络仿真器(如 Mininet 或 NS-3)模拟真实拓扑动态性。
- 在云平台(如 AWS)部署千节点级测试,验证分布式环境下的性能。
Primus 潜在问题与改进方向
-
拓扑依赖性:
- 问题:仅适用于规则拓扑(如 Fat-Tree),无法直接支持随机拓扑(如 Jellyfish)。
- 改进:设计动态索引机制,结合图神经网络(GNN)学习非规则拓扑的路径变化模式。
-
冗余消息开销:
- 问题:大规模下 UDP 冗余副本可能占用显著带宽(如 10K 交换机需~2.4%冗余流量)。
- 改进:
- 动态冗余策略:根据网络状态(如故障率)自适应调整副本数。
- 增量更新:仅传输链路状态变化的差分信息,而非全量 LS 消息。
-
内存优化:
- 问题:路径表内存随规模线性增长(10K 交换机需~10MB)。
- 改进:利用压缩算法(如 Delta Encoding)或近似索引结构(如 Bloom Filter)进一步压缩存储。
结合近年研究热点的改进方向
-
AI 驱动的动态优化:
- 流量预测:利用 LSTM 或 Transformer 预测流量模式,动态调整路径权重(如为 LLM 训练的 All-Reduce 通信预留带宽)。
- 故障预测:通过历史 LS 数据训练模型,提前触发冗余路径切换。
-
可编程数据平面:
- P4 交换机集成:将查表逻辑卸载到交换机 ASIC,实现 纳秒级路由更新。
- In-Network 计算:在数据平面直接处理 LS 消息,减少控制器负载。
-
Serverless 与微服务适配:
- 细粒度 QoS 路由:结合应用层需求(如延迟敏感型微服务)动态调整路径优先级。
- 无服务器扩展:通过 Primus 的集中控制实现函数即服务(FaaS)的快速资源分配。
LLM 训练流量对 Primus 的挑战与改进
LLM 流量特性:
- 高带宽需求:分布式训练中 All-Reduce 通信占主导,需多路径负载均衡。
- 突发性与同步性:参数服务器与 GPU worker 的通信具有周期性峰值,易引发瞬时拥塞。
潜在失效点:
- 静态路径选择:Primus 当前基于最短路径,无法动态规避拥塞链路。
- 控制平面延迟:大规模参数同步可能触发 LS 风暴,影响收敛时间。
改进方向:
-
动态负载感知路由:
- 结合实时带宽监测(如 INT telemetry),动态选择低负载路径。
- 引入 WCMP(加权成本多路径)优化流量分布。
-
优先级队列与预路由:
- 为 LLM 训练流量分配高优先级队列,确保关键参数更新低延迟。
- 预路由(Proactive Routing):在训练任务启动前预分配专用路径。
-
混合控制平面:
- 结合数据平面快速恢复(如 FRR)与 Primus 的集中控制,缩短瞬时中断时间。
-
跨层优化:将 Primus 的路由状态(如 FL 值)暴露给传输层(如 QUIC),实现应用感知的快速重路由。
Footnotes
-
博主博主,位图存储路径还是太吃内存了,有没有更简单一点的办法?有的兄弟,有的。 ↩