课后练习
编程题
-
- 实现一个使用 nice, fork, exec, spawn 等与进程管理相关的系统调用的 linux 应用程序。
-
- 扩展操作系统内核,能够显示操作系统切换进程的过程。
-
- 请阅读下列代码,分析程序的输出
A的数量:( 已知&&的优先级比||高)
- 请阅读下列代码,分析程序的输出
int main () {
fork () && fork () && fork () || fork () && fork () || fork () && fork ();
printf ("A");
return 0;
}
如果给出一个 && || 的序列,如何设计一个程序来得到答案?
22个。&&优先级高于||,根据 fork 子进程返回值为0父进程返回 pid 和逻辑运算符的短路现象(&&左边为 F 即短路,||左边为 T 即短路), 可以按||分割来进行判断,共 1+1*3+3*2+3*2*2 = 22.
def count_fork(seq):
counts = [1] + [i.count("&&") + 1 for i in seq.split("||")]
total = sum([np.prod(counts[:i + 1]) for i in range(len(counts))])
return total
-
** 在本章操作系统中实现本章提出的某一种调度算法(RR 调度除外)。
-
*** 扩展操作系统内核,支持多核处理器。
-
*** 扩展操作系统内核,支持在内核态响应并处理中断。
问答题
-
- 如何查看 Linux 操作系统中的进程?
使用 ps 命令,常用方法:$ ps aux
-
- 简单描述一下进程的地址空间中有哪些数据和代码。
代码(text)段,数据(data)段: 已初始化的全局变量的内存映射,bss段:未初始化或默认初始化为0的全局变量,堆(heap),用户栈(stack),共享内存段
进程控制块内容
-
- 进程控制块保存哪些内容?
进程标识符、进程调度信息(进程状态,进程的优先级,进程调度所需的其它信息)、进程间通信信息、内存管理信息(基地址、页表或段表等存储空间结构)、进程所用资源( I/O 设备列表、打开文件列表等)、处理机信息(通用寄存器、指令计数器、用户的栈指针)
进程切换需要保存哪些内容
-
- 进程上下文切换需要保存哪些内容?
页全局目录、部分寄存器、内核栈、当前运行位置
- ** fork 为什么需要在父进程和子进程提供不同的返回值?
可以根据返回值区分父子进程,明确进程之间的关系,方便用户为不同进程执行不同的操作。
fork + exec 的问题与改进
- ** fork + exec 的一个比较大的问题是 fork 之后的内存页 / 文件等资源完全没有使用就废弃了,针对这一点,有什么改进策略?
采用COW(copy on write),或使用使⽤vfork等。
- ** 其实使用了 6 的策略之后,fork + exec 所带来的无效资源的问题已经基本被解决了,但是近年来 fork 还是在被不断的批判,那么到底是什么正在“杀死”fork?可以参考 论文 。
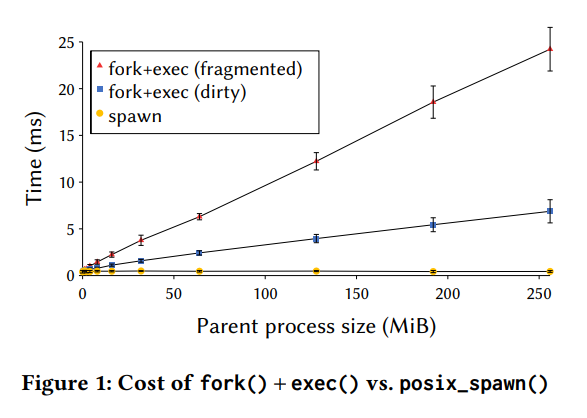 fork 和其他的操作不正交,也就是 os 每增加一个功能,都要改 fork, 这导致新功能开发困难,设计受限.有些和硬件相关的甚至根本无法支持 fork.
fork 和其他的操作不正交,也就是 os 每增加一个功能,都要改 fork, 这导致新功能开发困难,设计受限.有些和硬件相关的甚至根本无法支持 fork.
fork 得到的父子进程可能产生共享资源的冲突;
子进程继承父进程,如果父进程处理不当,子进程可以找到父进程的安全漏洞进而威胁父进程;
还有比如 fork 必须要虚存, SAS 无法支持等等.
[! note] 论文的观点 这篇论文主要探讨了 Unix 系统调用 fork ()的问题。 论文的主要观点可以概括如下:
- fork ()是一个古老的系统调用设计, 在当今的系统和应用中已经不再适用。
- fork ()给应用程序和操作系统设计带来了许多问题, 比如不安全、低效率、不可扩展等。
- fork ()使得操作系统接口设计非常复杂, 和其他抽象捆绑在一起, 给创新带来阻碍。
- 我们应该逐步弃用 fork (), 使用像 spawn ()这样的新接口来取代它。
- 在教学中也不应该继续把 fork ()作为第一个进程创建机制介绍给学生。
作者认为 fork ()已经成为系统发展的负担, 不再适合现代操作系统, 需要被逐步替换。
论文中使用了以下例子来支持自己的观点:
- 性能数据对比: 比较了 fork+exec 和 posix_spawn 的性能, 显示随着进程大小增大, fork 的时间开销显著增加。
- 安全性问题: fork 会继承父进程所有资源, 违反最小权限原则; 也会破坏地址空间随机化。
- 编程复杂性: 一个简单的 fork 现在需要处理各种锁、内存映射等 25 种特殊情况。
- 不可扩展: fork 会增加内核锁争用, 影响扩展性。
- 内存错配: fork 促进了内存过度承诺 (overcommit)。
- 不合作用: fork 破坏了用户态实现的组件, 如缓冲 IO。
- 线程不安全: 多线程程序中 fork 会导致死锁等问题。
- 实现困难: 设计支持 fork 的新 OS 时需要面对种种限制。
- 单地址空间不兼容: fork 难以应用于 Picoprocess 等单地址空间环境。
- ** 请阅读下列代码,并分析程序的输出,假定不发生运行错误,不考虑行缓冲,不考虑中断:
[! note]
int main (){ int val = 2; printf ("%d", 0); int pid = fork (); if (pid == 0) { val++; printf ("%d", val); } else { val--; printf ("%d", val); wait (NULL); } val++; printf ("%d", val); return 0; }如果 fork () 之后主程序先运行,则结果如何?如果 fork () 之后 child 先运行,则结果如何?
01342 03412
waitpid 的必要性
- ** 为什么子进程退出后需要父进程对它进行 wait,它才能被完全回收?
当一个进程通过exit系统调用退出之后,它所占用的资源并不能够立即全部回收,需要由该进程的父进程通过wait收集该进程的返回状态并回收掉它所占据的全部资源,防止子进程变为僵尸进程造成内存泄漏。同时父进程通过wait可以获取子进程执行结果,判断运行是否达到预期,进行管理。
- ** 有哪些可能的时机导致进程切换?
进程主动放弃 cpu:运行结束、调用 yield/sleep 等、运行发生异常中断
进程被动失去cpu:时间片用完、新进程到达、发生I/O中断等
-
** 请描述在本章操作系统中实现本章提出的某一种调度算法(RR 调度除外)的简要实现步骤。
-
- 非抢占式的调度算法,以及抢占式的调度算法,他们的优点各是什么?
非抢占式:中断响应性能好、进程执行连续,便于分析管理
抢占式:任务级响应时间最优,更能满足紧迫作业要求
- ** 假设我们简单的将进程分为两种:前台交互(要求短时延)、后台计算(计算量大)。下列进程 / 或进程组分别是前台还是后台?a) make 编译 linux; b) vim 光标移动; c) firefox 下载影片; d) 某游戏处理玩家点击鼠标开枪; e) 播放交响乐歌曲; f) 转码一个电影视频。除此以外,想想你日常应用程序的运行,它们哪些是前台,哪些是后台的?
前台:b,d,e
后台:a,c,f
RR 算法时间片长短的性能影响
- ** RR 算法的时间片长短对系统性能指标有什么影响?
时间片太大,可以让每个任务都在时间片内完成,但进程平均周转时间会比较长,极限情况下甚至退化为 FCFS;
时间片过小,反应迅速,响应时间会比较短,可以提高批量短任务的完成速度。但产生大量上下文切换开销,使进程的实际执行时间受到挤占。
因此需要在响应时间和进程切换开销之间进行权衡,合理设定时间片大小。
欺骗 MLFQ 算法的方式
- ** MLFQ 算法并不公平,恶意的用户程序可以愚弄 MLFQ 算法,大幅挤占其他进程的时间。(MLFQ 的规则:“如果一个进程,时间片用完了它还在执行用户计算,那么 MLFQ 下调它的优先级”)你能举出一个例子,使得你的用户程序能够挤占其他进程的时间吗?
每次连续执行只进行大半个时间片长度即通过执行一个IO操作等让出cpu,这样优先级不会下降,仍能很快得到下一次调度。
多核处理器对线程调度的挑战
- *** 多核执行和调度引入了哪些新的问题和挑战?
多处理机之间的负载不均问题:在调度时,如何保证每一个处理机的就绪队列保证优先级、性能指标的同时负载均衡
数据在不同处理机之间的共享与同步问题:除了Cache一致性的问题,在不同处理机上同时运行的进程可能对共享的数据区域产生相同的数据要求,这时就需要避免数据冲突,采用同步互斥机制处理资源竞争;
线程化问题:如何将单个进程分为多线程放在多个处理机上
Cache一致性问题:由于各个处理机有自己的私有Cache,需要保证不同处理机下的Cache之中的数据一致性
处理器亲和性问题:在单一处理机上运行的进程可以利用Cache实现内存访问的优化与加速,这就需要我们规划调度策略,尽量使一个进程在它前一次运行过的同一个CPU上运行,也即满足处理器亲和性。
通信问题:类似同步问题,如何降低核间的通信代价
实验练习 1
实验练习包括实践作业和问答作业两部分。实验练习 1 和实验练习 2 可以选一个完成。
实践作业
进程创建
大家一定好奇过为啥进程创建要用 fork + execve 这么一个奇怪的系统调用,就不能直接搞一个新进程吗?思而不学则殆,我们就来试一试!这章的编程练习请大家实现一个完全 DIY 的系统调用 spawn,用以创建一个新进程。
spawn 系统调用定义 ( 标准 spawn 看这里 ):
fn sys_spawn(path: *const u8) -> isize
-
syscall ID: 400
-
功能:新建子进程,使其执行目标程序。
-
说明:成功返回子进程 id,否则返回 -1。
-
可能的错误:
-
无效的文件名。
-
进程池满 / 内存不足等资源错误。
-
TIPS:虽然测例很简单,但提醒读者 spawn 不必 像 fork 一样复制父进程的地址空间。
实验要求
-
实现分支:ch5-lab
-
实验目录要求不变
-
通过所有测例
在 os 目录下
make run TEST=1加载所有测例,test_usertest打包了所有你需要通过的测例,你也可以通过修改这个文件调整本地测试的内容。
challenge: 支持多核。
问答作业
-
fork + exec 的一个比较大的问题是 fork 之后的内存页 / 文件等资源完全没有使用就废弃了,针对这一点,有什么改进策略?
-
[选做,不占分]其实使用了题 (1) 的策略之后,fork + exec 所带来的无效资源的问题已经基本被解决了,但是近年来 fork 还是在被不断的批判,那么到底是什么正在”杀死”fork?可以参考 论文 。
-
请阅读下列代码,并分析程序的输出,假定不发生运行错误,不考虑行缓冲:
int main(){
int val = 2;
printf("%d", 0);
int pid = fork();
if (pid == 0) {
val++;
printf("%d", val);
} else {
val--;
printf("%d", val);
wait(NULL);
}
val++;
printf("%d", val);
return 0;
}
如果 fork () 之后主程序先运行,则结果如何?如果 fork () 之后 child 先运行,则结果如何?
- 请阅读下列代码,分析程序的输出
A的数量:( 已知&&的优先级比||高)
int main() {
fork() && fork() && fork() || fork() && fork() || fork() && fork();
printf("A");
return 0;
}
[选做,不占分] 更进一步,如果给出一个 && || 的序列,如何设计一个程序来得到答案?
实验练习的提交报告要求
-
简单总结本次实验与上个实验相比你增加的东西。(控制在 5 行以内,不要贴代码)
-
完成问答问题
-
(optional) 你对本次实验设计及难度的看法。
实验练习 2
实践作业
stride 调度算法
ch3 中我们实现的调度算法十分简单。现在我们要为我们的 os 实现一种带优先级的调度算法:stride 调度算法。
算法描述如下:
-
为每个进程设置一个当前 stride,表示该进程当前已经运行的 “长度”。另外设置其对应的 pass 值(只与进程的优先权有关系),表示对应进程在调度后,stride 需要进行的累加值。
-
每次需要调度时,从当前 runnable 态的进程中选择 stride 最小的进程调度。对于获得调度的进程 P,将对应的 stride 加上其对应的步长 pass。
-
一个时间片后,回到上一步骤,重新调度当前 stride 最小的进程。
可以证明,如果令 P.pass = BigStride / P.priority 其中 P.priority 表示进程的优先权(大于 1),而 BigStride 表示一个预先定义的大常数,则该调度方案为每个进程分配的时间将与其优先级成正比。证明过程我们在这里略去,有兴趣的同学可以在网上查找相关资料。
其他实验细节:
- stride 调度要求进程优先级
>=2,所以设定进程优先级<=1会导致错误。
[! note] 为什么进程优先权要设置大于 1? pass 比较时是无符号数的有符号比较,因此 BIG_STRIDE/2 是有符号数正负的分界线,只有 stride>=2,才能在无符号溢出前一直保持同符号的比较,否则一个数 pass 一超过 BIG_STRIDE/2 就变成负数了,它虽然 stride=1,但是却一直让别的进程抢占。溢出之后就是正>负了没什么好说的。
比如设置 BIG_STRIDE=15,进程a.stride=1,进程b.stride=3,都从 0 开始,那么调度顺序是 a, a, a, b, a, a, a, b, a, a (此时a.pass=8,在比较时为-8 考虑),那么下一个调度的就是
b.pass=6>a.pass=8,然后一直调度 a,直到 a 溢出一轮后再到达a.pass=7,才会再调度 b
-
进程初始 stride 设置为 0 即可。
-
进程初始优先级设置为 16。
为了实现该调度算法,内核还要增加 set_prio 系统调用
// syscall ID:140
// 设置当前进程优先级为 prio
// 参数:prio 进程优先级,要求 prio >= 2
// 返回值:如果输入合法则返回 prio,否则返回 -1
fn sys_set_priority(prio: isize) -> isize;
tips: 可以使用优先级队列比较方便的实现 stride 算法,但是我们的实验不考察效率,所以手写一个简单粗暴的也完全没问题。
实验要求
-
完成分支: ch3-lab
-
实验目录要求不变
-
通过所有测例
lab3 有 3 类测例,在 os 目录下执行
make run TEST=1检查基本sys_write安全检查的实现,make run TEST=2检查set_priority语义的正确性,make run TEST=3检查 stride 调度算法是否满足公平性要求, 六个子程序运行的次数应该大致与其优先级呈正比,测试通过标准是 .
challenge: 实现多核,可以并行调度。
实验约定
在第三章的测试中,我们对于内核有如下仅仅为了测试方便的要求,请调整你的内核代码来符合这些要求:
- 用户栈大小必须为 4096,且按照 4096 字节对齐。这一规定可以在实验 4 开始删除,仅仅为通过 lab2 测例设置。
问答作业
stride 算法深入
stride 算法原理非常简单,但是有一个比较大的问题。例如两个 pass = 10 的进程,使用 8bit 无符号整形储存 stride, p1.stride = 255, p2.stride = 250,在 p2 执行一个时间片后,理论上下一次应该 p1 执行。
- 实际情况是轮到 p1 执行吗?为什么?
我们之前要求进程优先级 >= 2 其实就是为了解决这个问题。可以证明,在不考虑溢出的情况下, 在进程优先级全部 >= 2 的情况下,如果严格按照算法执行,那么 STRIDE_MAX – STRIDE_MIN ⇐ BigStride / 2。
为什么?尝试简单说明(传达思想即可,不要求严格证明)。
已知以上结论,考虑溢出的情况下,我们可以通过设计 Stride 的比较接口,结合 BinaryHeap 的 pop 接口可以很容易的找到真正最小的 Stride。
- 请补全如下
partial_cmp函数(假设永远不会相等)。
use core::cmp:: Ordering;
struct Stride (u64);
impl PartialOrd for Stride {
fn partial_cmp (&self, other: &Self) -> Option<Ordering> {
// ...
}
}
impl PartialEq for Person {
fn eq (&self, other: &Self) -> bool {
false
}
}
例如使用 8 bits 存储 stride, BigStride = 255, 则:
- (125 < 255) == false
- (129 < 255) == true
实验练习的提交报告要求
-
简单总结与上次实验相比本次实验你增加的东西(控制在 5 行以内,不要贴代码)。
-
完成问答问题。
-
(optional) 你对本次实验设计及难度 / 工作量的看法,以及有哪些需要改进的地方,欢迎畅所欲言。