我们将 n 个互异节点所能组成二叉搜索树的总数,记作 T(n)。 由上题结论,尽管由同一组节点组成的二叉搜索树不尽相同,但它们的中序遍历序列却必然相同,不妨记作:
x0x1x2...xk−1xkxk+1xk+2...xn−1
根据所取树根节点的不同,所有搜索树可以分为 n 类。如上所示,对于其中以 xk 为根者而言,左、右子树必然分别由{ x0,x1,x2,...,xk−1 }和{ xk+1,xk+2,...,xn−1 }组成。
如此,可得边界条件和递推式如下:
T (0)=T (1)=1
T(n)=k=1∑nT(k−1)⋅T(n−k)=catalan(n)=(n+1)!⋅n!(2n)!
这是典型的 Catalan 数式递推关系,解之即得题中结论。
7-3 证明 n 个节点的二叉树最低 ⌊log2(n)⌋ ——即完全二叉树的树高
实际上不难证明,若高度为 h 的二叉树共含 n 个节点,则必有:
n ⇐ 2^(h+1) - 1
这里的等号成立,当且仅当是满树。于是有:
h >= log2(n + 1) - 1
h >= ⌈log2(n+1)⌉−1 = ⌊log2(n)⌋
7-5 证明 insert 在 BST 中插入节点 v 后的高度问题
除 v 的历代祖先外,其余节点的高度无需更新;
节点的高度仅取决于其后代——更确切地,等于该节点与其最深后代之间的距离。 因此在插入节点 v 之后,节点 a 的高度可能发生变化(增加),当且仅当 v 是 a 的后代,或反过来 等价地,a 是 v 的祖先。
祖先高度不会降低,但至多+1
插入节点 v 之后,所有节点的后代集不致缩小。而正如前述,高度取决于后代深度的最大值,故不致下降。 另一方面,假定节点 a 的高度由 h 增加至 h’。若将 v 的父节点记作 p,则 a 到 p 的距离不大于 a 在此之前的高度 h,于是必有:
h’ ⇐ |ap| + 1 ⇐ h + 1
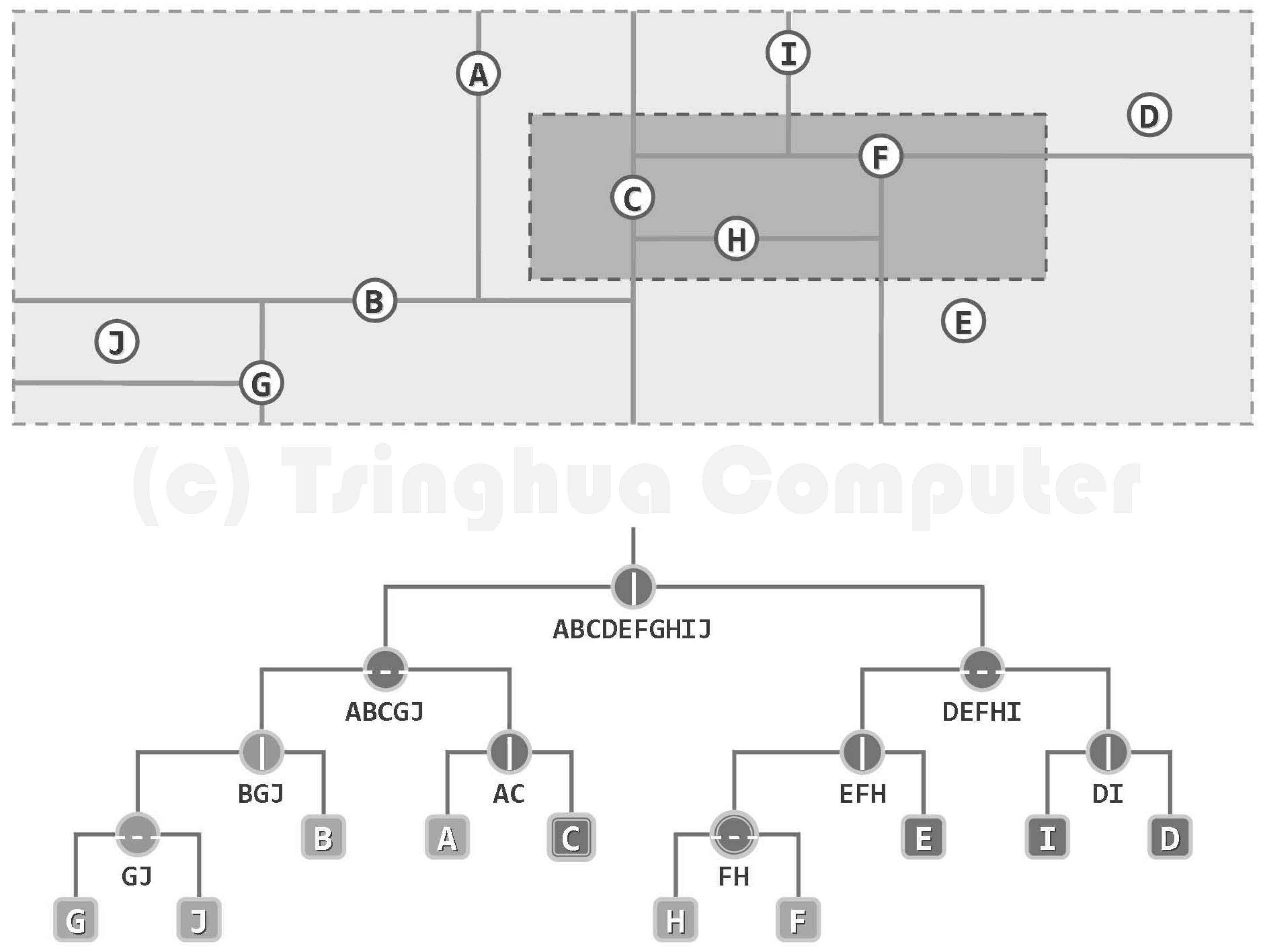
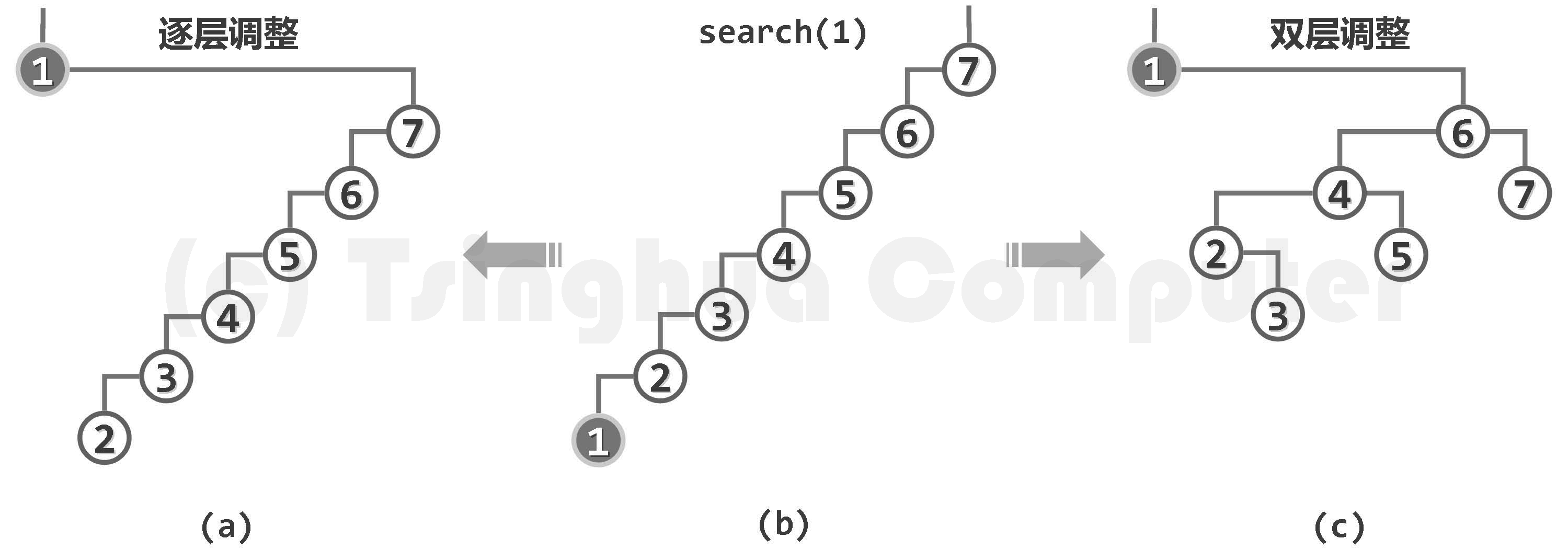
扩充 searchAll (e)接口以适应 BST 支持多个相等数据项并存的情况,要求时间复杂度不超过 O (h+k)(h is BST height, k is nums of e)
从后面第8.4.1节所介绍范围查询的角度来看,从二叉搜索树中找出所有数值等于 e 的节点,完全等效于针对区间(e - ε, e + ε)的范围查找,其中ε为某一足够小的正数。
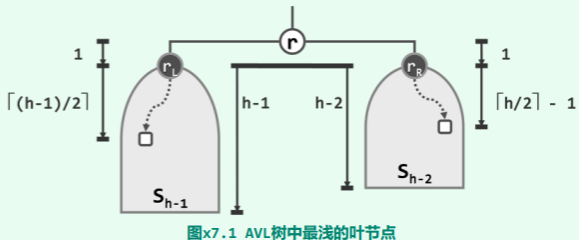
考查其中数值最大(中序遍历序列中最靠后)的节点 M。该节点共计 h 个祖先,而且它们的平衡因子均为-1。现在,假设需要将一个词条插入其中,而且该词条大于节点 M。按照二叉搜索树的插入算法,必然会相应地在节点 M 之下,新建一个右孩子 x。此时,节点 M 所有祖先的平衡因子都会更新为-2,从而出现失衡现象。
事实上,伸展树单次操作所需的时间量 T 起伏极大,并不能始终保证控制在 O(logn) 以内。故需从分摊的角度做一分析和评判。具体地,可将实际可能连续发生的一系列操作视作一个整体过程,将总体所需计算时间分摊至其间的每一操作,如此即可得到其单次操作的分摊复杂度 A,并依此评判伸展树的整体性能。
当然,就具体的某次操作而言,实际执行时间 T 与分摊执行时间 A 往往并不一致,如何弥合二者之间的差异呢? 实际上,分摊分析法在教材中已经而且将会多次出现,比如此前第2.4.4节的可扩充向量、第5.4节的各种迭代式遍历算法以及后面第11.3.7节的 KMP 串匹配算法等。相对而言,伸展树的性能分析更为复杂,以下将采用势能分析法(potential analysis)。
仿照物理学的思想和概念,这里可假想式地认为,每棵伸展树 S 都具有一定量(非负)的势能(potential),记作Φ(S)。于是,若经过某一操作并相应地通过旋转完成伸展之后 S 演化为另一伸展树 S’,则对应的势能变化为:
ΔΦ=Φ(S′)−Φ(S)
推而广之,考查对某伸展树 S0连续实施 m >> n 次操作的过程。将第 i 次操作后的伸展树记作 Si,则有:
ΔΦi=Φ(Si)−Φ(Si−1)
所述,这种情况在伸展树的每次操作中至多发生一次,而且只能是伸展调整过程的最后一步。作为单旋,这一步调整实际所需时间为 T = O(1)。并且由图示可知,这步调整过程中只有节点 v 和 p 的势能有所变化,且 v(p)后代增加(减少)势能必上升(下降), 故对应的分摊复杂度为:
A=T+ΔΦ=1+ΔΦ(p)+ΔΦ(v)≤1+[Φ′(v)−Φ(v)]
Bit 2 changes least often, Bit 0 changes most often. That’s the opposite of what we want, so what if we reverse the order of those bits, then sort our keys in order of this bit-reversed value…
It’s easiest to explain this in terms of an unbalanced binary search tree, growing by adding leaves. The first item is dead centre - it’s exactly the item we want for the root. Then we add the keys for the next layer down. Finally, we add the leaf layer. At every step, the tree is as balanced as it can be, so even if you happen to be building an AVL or red-black balanced tree, the rebalancing logic should never be invoked.
[EDIT I just realised you don’t need to sort the data based on those bit-reversed values in order to access the keys in that order. The trick to that is to notice that bit-reversing is its own inverse. As well as mapping keys to positions, it maps positions to keys. So if you loop through from 1..n, you can use this bit-reversed value to decide which item to insert next - for the first insert use the 4th item, for the second insert use the second item and so on. One complication - you have to round n upwards to one less than a power of two (7 is OK, but use 15 instead of 8) and you have to bounds-check the bit-reversed values. The reason is that bit-reversing can move some in-bounds positions out-of-bounds and visa versa.]
Actually, for a red-black tree some rebalancing logic will be invoked, but it should just be re-colouring nodes - not rearranging them. However, I haven’t double checked, so don’t rely on this claim.
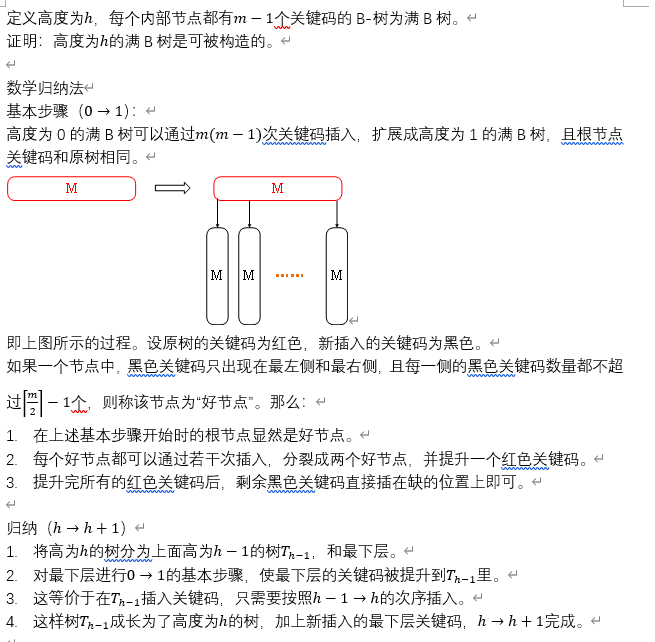
For a B tree, the height of the tree grows by adding a new root. Proving this works is, therefore, a little awkward (and it may require a more careful node-splitting than a B tree normally requires) but the basic idea is the same. Although rebalancing occurs, it occurs in a balanced way because of the order of inserts.
对于 B 树来说,树的高度是通过增加一个新根来增长的。因此,证明这种方法可行有点困难(而且可能需要比 B 树通常更仔细的节点分割),但基本思想是相同的。虽然重新平衡会发生,但由于插入的顺序不同,平衡的方式也不同。
This can be generalised for any set of known-in-advance keys because, once the keys are sorted, you can assign suitable indexes based on that sorted order.
这可以推广到任何一组已知的键,因为一旦键被排序,就可以根据排序顺序分配合适的索引。
WARNING - This isn’t an efficient way to construct a perfectly balanced tree from known already-sorted data.
If you have your data already sorted, and know it’s size, you can build a perfectly balanced tree in O(n) time. Here’s some pseudocode…
if size is zero, return null
from the size, decide which index should be the (subtree) root
recurse for the left subtree, giving that index as the size (assuming 0 is a valid index)
take the next item to build the (subtree) root
recurse for the right subtree, giving (size - (index + 1)) as the size
add the left and right subtree results as the child pointers
return the new (subtree) root
Basically, this decides the structure of the tree based on the size and traverses that structure, building the actual nodes along the way. It shouldn’t be too hard to adapt it for B Trees.
soulution 2 (correct)
This is how I would add elements to b-tree.
Thanks to Steve314, for giving me the start with binary representation,
Given are n elements to add, in order. We have to add it to m-order b-tree. Take their indexes (1…n) and convert it to radix m. The main idea of this insertion is to insert number with highest m-radix bit currently and keep it above the lesser m-radix numbers added in the tree despite splitting of nodes.
给定 n 个元素,按顺序添加。我们必须将其添加到 m 阶 b 树中。插入的主要目的是插入当前 m 阶最高位的数字,并使其高于树中添加的 m 阶较低的数字,尽管节点会分裂。
1,2,3.. are indexes so you actually insert the numbers they point to.
For example, order-4 tree
4 8 12 // highest radix bit nums
1,2,3 5,6,7 9,10,11 13,14,15
Now depending on order, the median can be:
order is even → number of keys are odd → median is middle (mid median)
order is odd → number of keys are even → left median or right median
The choice of median (left/right) to be promoted will decide the order in which I should insert elements. This has to be fixed for the b-tree.
中位数(左/右)的选择将决定我插入元素的顺序。这一点必须在 b 树中加以固定。
I add elements to trees in buckets. First I add bucket elements then on completion next bucket in order. Buckets can be easily created if median is known, bucket size is order m.
I take left median for promotion. Choosing bucket for insertion.
| 4 | 8 | 12 |
1,2,|3 5,6,|7 9,10,|11 13,14,|15
3 2 1 Order to insert buckets.
For left-median choice I insert buckets to the tree starting from right side, for right median choice I insert buckets from left side.
Choosing left-median we insert median first, then elements to left of it first then rest of the numbers in the bucket.
Bucket median first
12,
Add elements to left
11,12,
Then after all elements inserted it looks like,
| 12 |
|11 13,14,|
Then I choose the bucket left to it. And repeat the same process.
Median
12
8,11 13,14,
Add elements to left first
12
7,8,11 13,14,
Adding rest
8 | 12
7 9,10,|11 13,14,
Similarly keep adding all the numbers,
4 | 8 | 12
3 5,6,|7 9,10,|11 13,14,
At the end add numbers left out from buckets.
| 4 | 8 | 12 |
1,2,|3 5,6,|7 9,10,|11 13,14,|15
For mid-median (even order b-trees) you simply insert the median and then all the numbers in the bucket.
对于中位数(偶数阶 b 树),只需插入中位数,然后再插入桶中的所有数字。
For right-median I add buckets from the left. For elements within the bucket I first insert median then right elements and then left elements.
Here we are adding the highest m-radix numbers, and in the process I added numbers with immediate lesser m-radix bit, making sure the highest m-radix numbers stay at top. Here I have only two levels, for more levels I repeat the same process in descending order of radix bits.
Last case is when remaining elements are of same radix-bit and there is no numbers with lesser radix-bit, then simply insert them and finish the procedure.
最后一种情况是,当剩余元素的阶位相同,且没有半径位更小的数字时,只需插入这些元素并完成程序。
I would give an example for 3 levels, but it is too long to show. So please try with other parameters and tell if it works.
Test:
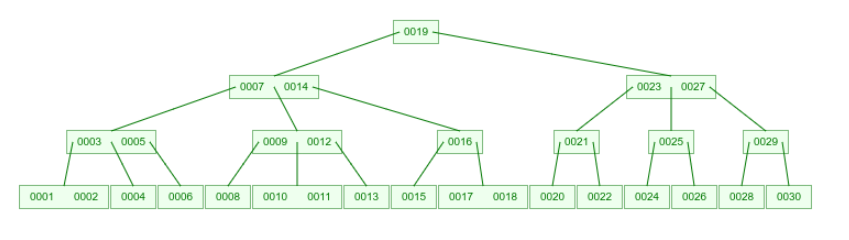
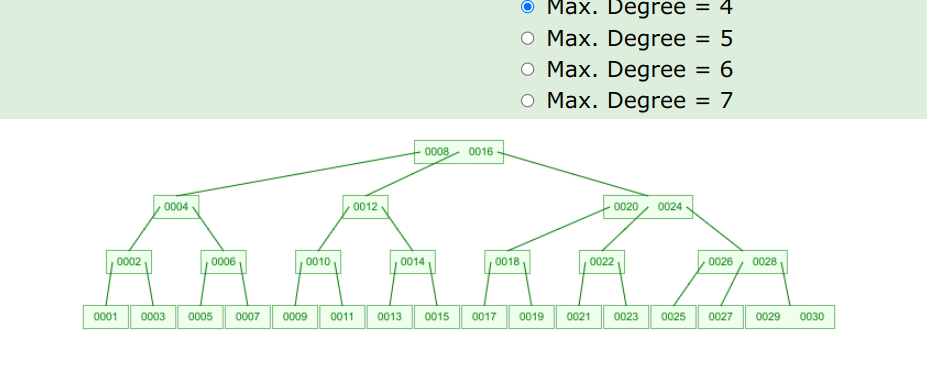
1~30, sequential insertion:
insertion by solu 2:
insertion by random:
好节点策略
证明存在一种插入方式使得 B 树的高度最小:
但是这个序列非常难以描述,只做拓展性的思考题。
8-6 考查 BTree 节点插入导致的分裂次数
对任意阶 BTree T,若 T 的初始高度为 1,在经历连续若干次插入操作后,高度增加至 h 且共有 n 个内部节点,则在此过程中 T 总共分裂多少次?
考查因新关键码的插入而引起的任何一次分裂操作。被分裂的节点,无非两种类型:
若它不是根节点,则树中的节点增加一个,同时树高保持不变,故有: n += 1 和 h += 0
否则若是根节点,则除了原节点一分为二,还会新生出一个(仅含单关键码的)树根,同时树的高度也将相应地增加一层,故有: n += 2 和 h += 1
可见,无论如何,n 与 h 的差值均会恰好地增加一个单位——因此,n - h 可以视作为分裂操作的一个计数器。该计数器的初始值为1 - 1 = 0,故最终的 n - h 即是从初始状态之最后,整个过程中所做分裂操作的总次数。
若 T 的初始高度为 h 且含有 n 个内部节点,而在经过连续若干次删除操作后高度下降至 1,则此过程中 T 总共合并过多少次?
与 1) 同理,若合并后的节点不是树根,则有 n -= 1 和 h -= 0 , 否则若是根节点,则有: n -= 2 和 h -= 1 可见,无论如何,n 与 h 的差值 n - h 均会恰好地减少一个单位。
既然最终有: n = h = 1 或等价地 n - h = 0 故其间所发生合并操作的次数,应恰好等于 n - h 的初值。
==设 T 的初始高度为 1,而且在随后经过若干次插入和删除操作——次序随意,且可能彼此相同。试证明:若在此期间总共做过 S 次分裂和 M 次合并,且最终共有 n 个内部节点、高度为 h,则必有 S-M=n-h==
综合 1) 和 3) 的结论可知:在 B-树的整个生命期内,n - h 始终忠实反映了分裂操作次数与合并操作次数之差。
与 B 树相比,B* 树的关键码删除算法有何不同?
与插入过程对称地,从节点 v 中删除关键码后若发生下溢,且其左、右兄弟均无法借出关键码,则先将 v 与左、右兄弟合并,再将合并节点等分为两个节点。同样地,实际上不必真地先合三为一,再一分为二。可通过更为快捷的方式,达到同样的效果:从来自原先三个节点及其父节点的共计:(⌈2m⌉−1)+1+(⌈2m⌉−2)+1+(⌈2m⌉−1)=3⋅⌈2m⌉−2 个关键码中,取一个上交给父节点,其余 3⋅⌈2m⌉−3 个则尽可能均衡地分摊给两个新节点。
针对数据局部性的另一改进策略,是使用所谓的页面缓冲池(buffer pool of pages)。这是在内存中设置的一个缓冲区,用以保存近期所使用过节点(页面)的副本。只要拟访问的节点仍在其中(同样地,在局部性较强的场合,这种情况也往往会反复出现),即可省略 I/O 操作并直接访问;否则,才照常规方法处理,通过 I/O 操作从外存取出对应的节点(页面)。缓冲池的规模确定后,一旦需要读入新的节点,只需将其中最不常用的节点删除即可腾出空间。实际上,不大的页面缓冲池即可极大地提高效率。
在树中某一节点发生递归,当且仅当与该节点对应的子区域,和查询区域的边界相交。
按照该算法的控制逻辑,只要当前子区域与查询区域 R 的边界相交时,即会发生递归;反之,无论当前子区域是完全处于 R 之外(当前递归实例直接返回),还是完全处于 R 之内(直接遍历当 前子树并枚举其中所有的点),都不会发生递归。
==若令 Q(n) = 规模为 n 的子树中与查询区域边界相交的子区域节点总数,则有 Q(n)=2+2Q(n/4)=O(√n)==
设 R 为任一查询区域。 根据其所对应子区域与 R 边界的相交情况,kd-树中的所有节点可以划分以下几类:
与 R 的边界不相交
只与 R 的一条边相交
同时与 R 的多条边相交
根据 8-16-1 ,其中第(0)类节点对 Q(n) 没有贡献。
如图 x8.6(a) 所示,第(1)类节点又可以细分为四种,分别对应于 R 的上、下、左、右四边。 既然是估计渐进复杂度,不妨只考虑其中一种——比如,如图(b)所示,只考查水平的上边。
根据定义,kd-树自顶而下地每经过 k 层,切分的维度方向即循环一轮。因此,不妨考查与 R 边界相交的任一节点,以及自该节点起向下的 k 代子孙节点。对于2d-树而言,也就是考查与 R 边 界相交的任一节点,以及它的2个子辈节点(各自大致包含 n/2个点)和4个孙辈节点(各自大致 包含 n/4个点)。
若矩形区域不保证与坐标轴平行,甚至不是矩形,上述结论是否依然成立?
参考论文:J. L. Bentley. Multidimensional Binary Search Trees Used for Associative Searching. Communications of the ACM (1975), 18(9):509-517
8-17 kdTree 缺陷改进:即使范围相交输入点也未必在查询范围内
说明:kd-树中节点 v 所对应的矩形区域即便与查询范围 R 相交,其中所含的输入点也不见得会落在 R 之内。比如在极端情况下,v 中可能包含大量的输入点,但却没有一个落在 R 之内。当然,kdSearch() 在这类情况下所做的递归,都是不必进行的。


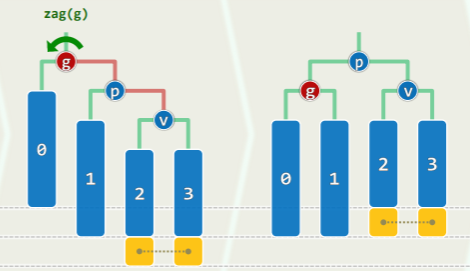

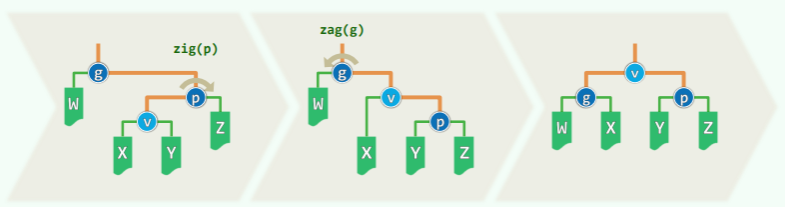
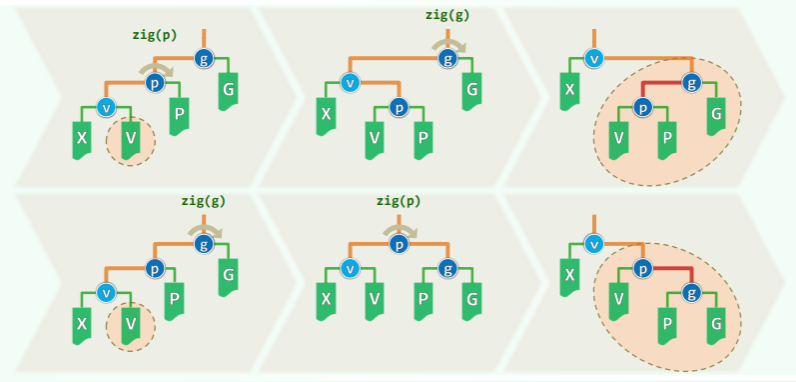
此时必有 v.parent () == T.root (),只需要单次旋转即可,并且每轮伸展最多发生一次。
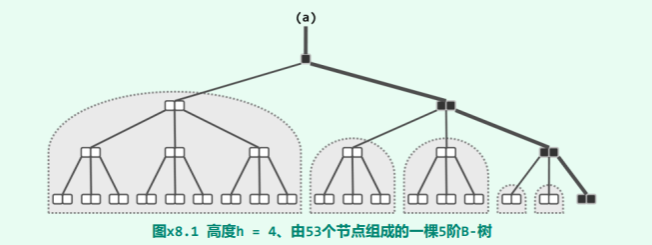
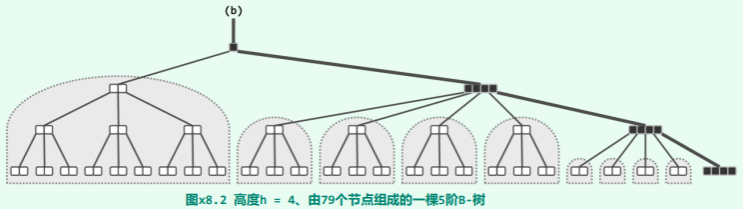
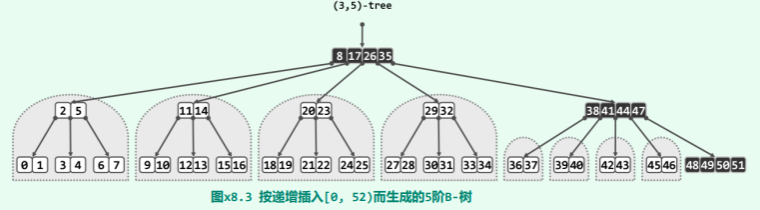


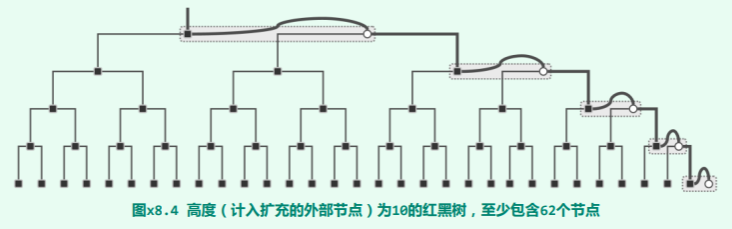 先考查 h 为偶数的情况。如图 x8.4所示,该 B-树的高度应为 h/2;其中几乎所有节点均只含单关键码;只有 h/2个节点包含两个关键码(分别对应于原红黑树中的一个红、黑节点),它们在每一高度上各有一个,且依次互为父子,整体构成一条路径(这里不妨以最右侧通路为例)。
先考查 h 为偶数的情况。如图 x8.4所示,该 B-树的高度应为 h/2;其中几乎所有节点均只含单关键码;只有 h/2个节点包含两个关键码(分别对应于原红黑树中的一个红、黑节点),它们在每一高度上各有一个,且依次互为父子,整体构成一条路径(这里不妨以最右侧通路为例)。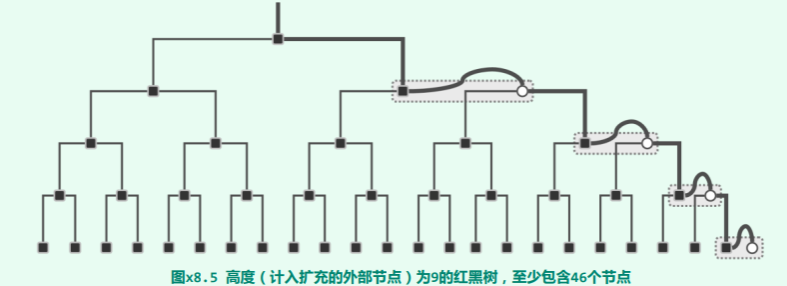 再考查 h 为奇数的情况。如图 x8.5所示,该 B-树的高度应为(h + 1)/2;其中几乎所有节点均只含单关键码;只有(h - 1)/2个节点包含两个关键码(分别对应于原红黑树中的一个红、黑节点),除了根节点,它们在每一高度上各有一个,且依次互为父子,整体构成一条路径(同样地,以最右侧通路为例)。
再考查 h 为奇数的情况。如图 x8.5所示,该 B-树的高度应为(h + 1)/2;其中几乎所有节点均只含单关键码;只有(h - 1)/2个节点包含两个关键码(分别对应于原红黑树中的一个红、黑节点),除了根节点,它们在每一高度上各有一个,且依次互为父子,整体构成一条路径(同样地,以最右侧通路为例)。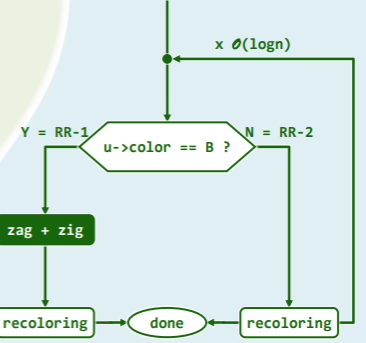
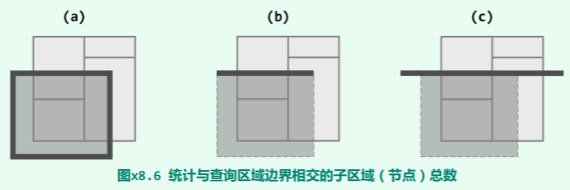 如图 x8.6(a) 所示,第(1)类节点又可以细分为四种,分别对应于 R 的上、下、左、右四边。 既然是估计渐进复杂度,不妨只考虑其中一种——比如,如图(b)所示,只考查水平的上边。
如图 x8.6(a) 所示,第(1)类节点又可以细分为四种,分别对应于 R 的上、下、左、右四边。 既然是估计渐进复杂度,不妨只考虑其中一种——比如,如图(b)所示,只考查水平的上边。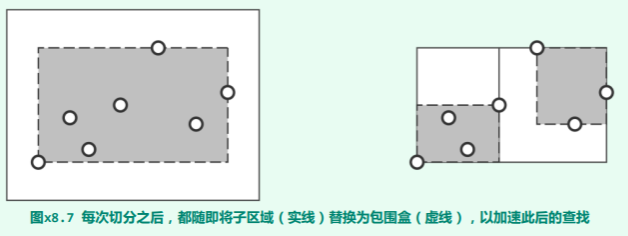 在依然保持各边平行于坐标轴,同时所包含输入点子集不变的前提下,尽可能地收缩各矩形区域。其效果等同于,将原矩形替换为依然覆盖其中所有输入点的最小矩形——即所谓包围盒(bounding-box)。其实,在如教材图
在依然保持各边平行于坐标轴,同时所包含输入点子集不变的前提下,尽可能地收缩各矩形区域。其效果等同于,将原矩形替换为依然覆盖其中所有输入点的最小矩形——即所谓包围盒(bounding-box)。其实,在如教材图