读完论文你应该收获什么?
Problem
- What problem is the paper solving?
论文主要解决传统数据中心网络在 成本、扩展性和管理复杂度 上的局限性。具体包括:
- 高成本:依赖高端定制化交换机,硬件成本高昂。
- 扩展性差:传统树状拓扑(如“四柱式架构”)难以支持大规模集群(如超过 2 万台服务器)。
- 协议复杂度:分散式路由协议(如 OSPF/BGP)在大规模 Clos 拓扑中难以有效管理。
- Why is this problem important?
- 业务需求驱动:Google 的带宽需求每 12-15 个月翻倍(远超互联网增速),需支持存储、计算密集型应用(如搜索索引、机器学习)。
- 经济性:传统方案无法在成本可控下实现 PB 级带宽(如早期集群仅提供 2Tbps 带宽)。
- 可靠性:单点故障和运维复杂性威胁服务可用性(如链路故障导致应用级中断)。
Context
- What was the previous state of the art?
- 拓扑结构:传统树状架构(如“四柱式”),带宽受限于根节点,且无法水平扩展。
- 硬件:依赖 WAN 优化的高端交换机(如支持 IP 组播、深度缓冲),功能冗余且昂贵。
- 协议:分散式路由协议(如 OSPF/BGP),协议开销大,难以支持多路径负载均衡。
- How does the paper advance the state of the art?
通过 三方面创新 实现突破:
- Clos 拓扑:多级交换结构(如边缘-聚合-骨干),支持水平扩展和冗余路径。
- 商用交换芯片(Merchant Silicon):采用标准化、低成本芯片,快速迭代硬件(如从 10G 到 40G)。
- 集中式控制协议(Firepath):全局拓扑视图 + 本地 ECMP 计算,取代传统分布式路由协议。
Design
- How is the system designed?
- 硬件架构:
- 模块化设计:ToR(机架顶部交换机)、聚合块(Aggregation Block)、骨干块(Spine Block)分层构建。
- 商用芯片:如 Saturn 使用 24x10G 芯片,Jupiter 升级到 16x40G 芯片。
- 软件控制:
- Firepath 协议:集中式链路状态分发 + 本地 ECMP 计算,支持快速收敛(如链路故障恢复时间低至 125ms)。
- 统一管理:复用服务器运维工具(如镜像部署、监控告警)。
- 物理部署:
- 光纤捆绑(Cable Bundling):减少布线复杂度(成本降低 40%)。
- 部分部署(Depopulation):按需扩展带宽(如初始部署 50%容量)。
- What are the key insights from the design?
- 路径冗余为王:Clos 拓扑天然多路径,结合 ECMP 实现高可用和负载均衡。
- 硬件与软件协同:商用芯片 + 定制控制协议(如 Firepath)平衡性能与成本。
- 运维统一性:网络设备视为“特殊服务器”,复用服务器管理工具链(如监控、日志)。
- 渐进式升级:支持新旧硬件共存(如 Jupiter 兼容 10G/40G 混合链路)。
Results
- How is the design evaluated, what are the key results?
- 实际部署验证:
- 规模:Jupiter 支持 1.3Pbps 带宽,部署于全球数十个数据中心。
- 可靠性:链路故障恢复时间低至 125ms(局部收敛)至 4 秒(全局收敛)。
- 性能指标:
- 带宽密度:商用芯片每代升级带宽密度提升 2-4 倍。
- 成本节约:光纤捆绑降低 40%成本,商用芯片方案较传统交换机成本下降超 50%。
- 应用收益:
- 存储与计算:跨集群数据迁移带宽提升 10 倍,支撑 PB 级数据处理。
- What related problems are still open?
- 更高速度支持:如何适应 100G/400G 芯片的普及与混合速率组网。
- 动态流量工程:当前依赖静态 ECMP,未来需更智能的流量调度(如 AI 驱动的动态路径选择)。
- 安全与隔离:多租户场景下的流量隔离与安全策略(如云原生网络需求)。
- 绿色节能:超大规模网络能耗优化(如空闲链路休眠策略)。
Questions
- What questions do you have?
- 控制平面扩展性:Firepath 的集中式控制如何应对数万台交换机的规模?是否存在单点瓶颈?
- 协议兼容性:与外部网络(如第三方 ISP)的 BGP 互通是否存在限制(如路由策略冲突)?
- 故障场景覆盖:论文未提及控制平面分区(如 CPN 网络中断)的恢复机制,如何保证此时网络的可用性?
- 硬件依赖性:商用芯片的快速迭代是否导致硬件碎片化(如不同代芯片共存的管理挑战)?
Introduction
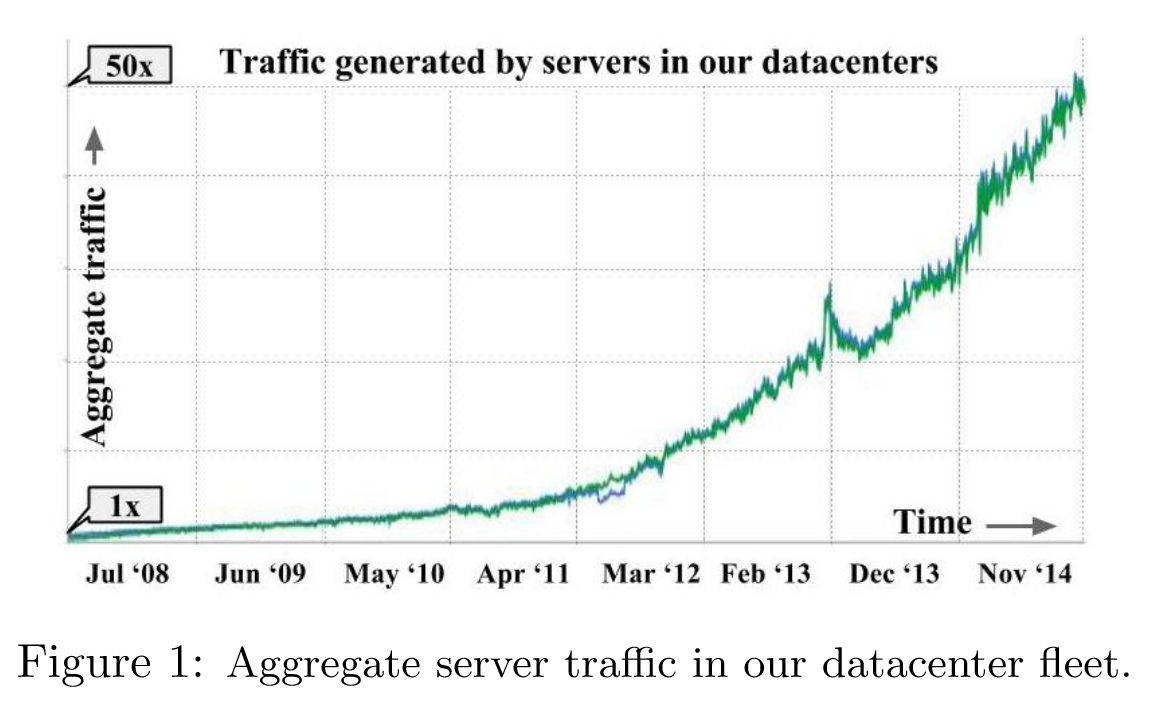
数据中心网络对于提供 web 服务、现代存储设施以及云计算服务至关重要。在数据中心中,带宽需求每 12-15 个月翻一番(如图 1)。这一增长来自以下网络内容的趋势变化:
- 随着照片/视频内容、日志和连接到互联网的传感器的激增,数据集规模持续地爆炸式增长。这导致的结果是,网络密集型数据处理流水线必须在更大的数据集上运行。
- Web 服务可以通过访问单个请求的关键路径上的更多数据来提供更高质量的结果1。
- 一系列共同驻留的应用程序通常在同一集群中彼此共享大量数据,例如索引生成、网络搜索和服务广告。
十年前(2005 年左右),Google 调研发现,与传统数据中心网络架构相关的成本和操作复杂性令人望而却步。
- 网络的最大规模受到当时可用的最高端交换机的成本和容量的限制。
- 这些交换机通常是从针对广域网部署的产品中回收利用的,广域网交换机通过硬件支持/卸载一系列协议(例如,IP 组播)或通过突破芯片内存的极限(例如,互联网规模的路由表、用于深层缓冲的片外 DRAM 等)来区分。
- 网络控制和管理协议针对的是自主的单个交换机,而不是预先配置且基本静态的数据中心结构。 这些特性中的大多数对数据中心并无用处,反而增加了成本、复杂性,延迟了上市时间,并使网络管理更加困难。
数据中心交换机作为复杂的基底来构建,以实现尽可能高的可用性。在 WAN Internet 部署中,丢失单个交换机/路由器可能会对应用程序产生重大影响。由于 WAN 链路非常昂贵,因此投资于高可用性是必要且有意义的。然而,数据中心带宽更丰富且更便宜,因此更明智的选择是以成本换取稍微减少的间歇性容量。最后,在具有终端主机种类复杂的多供应商 WAN 环境中运行的交换机需要支持许多协议,以确保互操作性;然而在单操作者的数据中心部署中,所需的协议数量可以大大减少。
受社区使用商品服务器的并行阵列扩展计算能力的启发,Google 探索了一种类似的组网方法。构建网络所要遵循的原则如下:
- Clos Topologies:
- 为了优雅地支持容错,增加 DCN 的规模/平分带宽2,并适应较低基数的交换机,Google 为数据中心采用了 Clos 拓扑。通过向拓扑中添加阶段,Clos 拓扑可以扩展到几乎任意的大小,这里的扩展主要受到故障域考虑和控制平面可扩展性的限制。
- Clos 拓扑还具有大量内置路径多样性和冗余,因此任何单个元件的故障导致容量减少的幅度相对较小。
- 然而,这种拓扑也带来了实质性的挑战,包括管理光纤扇出(fiber fanout)和跨多个等价路径的更复杂的路由。
- Merchant Silicon:
- 放弃使用针对小容量、大功能集和高可靠性的商用交换机,而是瞄准通用的商用交换机硅片、商品定价的、现成的交换机组件。
- 为了跟上服务器带宽需求(该需求随每台服务器的内核数和摩尔定律而扩展)的步伐,Google 强调了带宽密度和刷新周期——使用最新一代商用交换机定期升级网络结构,使得以经济高效的方式实现带宽容量的指数级增长。
- Centralized Control Protocols:
- 使用 Clos 拓扑时,控制和管理变得更加复杂,因为离散的开关元件的数量显著增加。现有的路由和管理协议不太适合这种环境。
- 为了控制这种复杂性,Google 观察到单个数据中心交换机根据集群计划发挥预定的转发作用。将这个观察利用到极致,即通过从网络中一个动态选择的中心点收集和分发动态变化的链路状态信息。然后,单个交换机可以根据相对于静态配置拓扑的当前链路状态计算转发表。
总的来说,与传统网络协议相比,Jupiter 的软件架构更类似于大规模存储和计算平台中的控制。网络协议通常使用基于成对消息交换的软状态,强调局部自治。然而 Jupiter 能够使用数据中心部署的独特特征和需求来简化控制和管理协议,从而实现现代 SDN 部署的许多原则。
Background and Related Work
从图 1 来看,自 2008 年以来,聚合服务器通信的流量在此期间增加了 50 倍,每年大约翻一番。远程存储访问、大规模数据处理和交互式 web 服务的结合推动了 Google 的带宽需求。
2004 年,Google 部署了类似于图 2 描述的传统集群网络。这种“四柱”集群体系结构采用了可用的最高密度以太网交换机,512 个 1GE 端口,以构建网络主干(CR 或集群路由器)。每个 ToR 连接到所有四个集群路由器,以保证规模和容错。
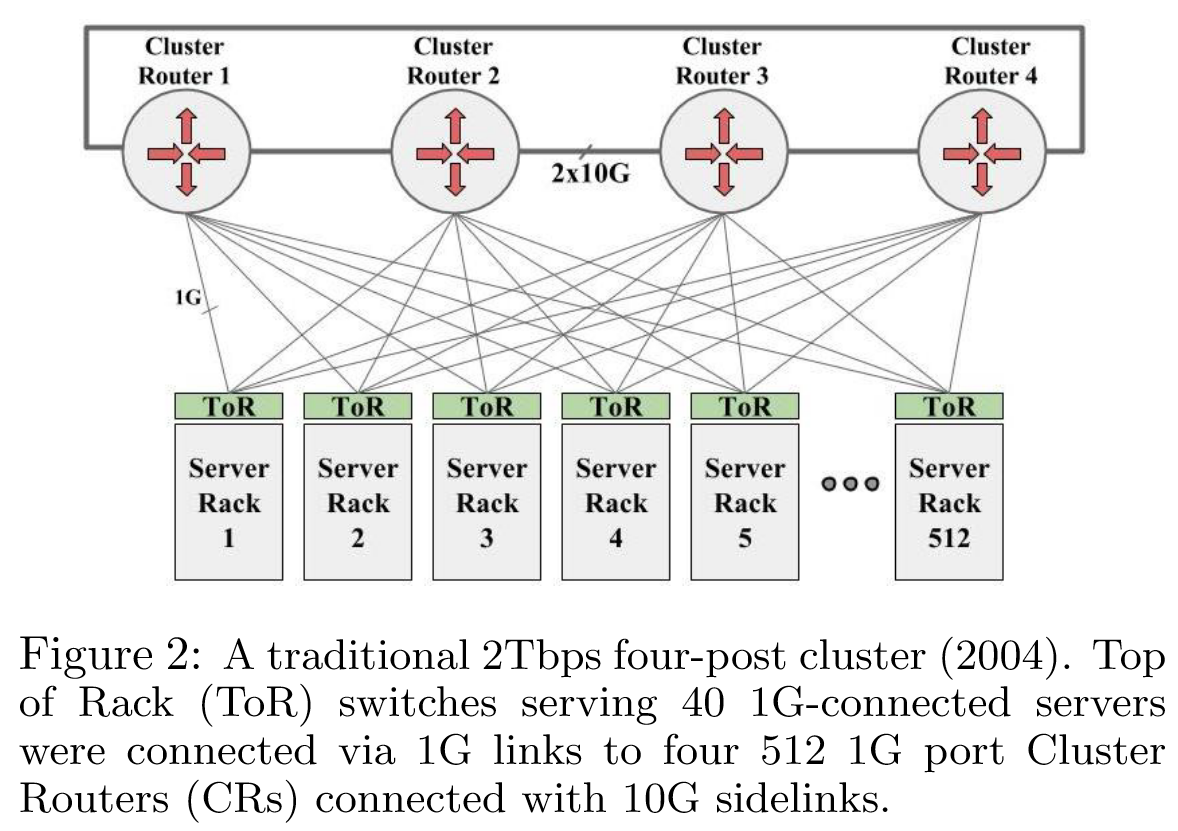 每个 ToR 最多支持 40 个服务器,这种方法支持每个集群 20k 个服务器。然而,高带宽应用不得不受限于单个 ToR,以避免 ToR 上行链路的过分 oversubscibed 。
每个 ToR 最多支持 40 个服务器,这种方法支持每个集群 20k 个服务器。然而,高带宽应用不得不受限于单个 ToR,以避免 ToR 上行链路的过分 oversubscibed 。
部署大型集群对 Google 的服务非常重要,因为有许多附属应用程序受益于高带宽通信,例如大规模数据处理,以生成并持续刷新搜索索引、web 搜索,并将广告作为附属应用程序而提供。较大的集群还能够减少作业无法在任何一个集群中调度的情况下搁浅的情况,显著提高了作业调度的装箱效率(bin-packing efficiency)3,尽管多个小集群聚合后有足够的资源可用。
最大集群规模之所以重要,是因为一个更微妙的原因——电源按建筑、兆瓦级发电机和物理数据中心行(physical datacenter rows)的粒度分层分布。层次结构的每个级别都表示一个故障和维护单元。为了可用性,集群调度故意将作业分布在多个行上。类似地,存储系统中所需的冗余在一定程度上取决于集群中可能由于电源事件而同时失败的部分。因此,较大的集群可以实现较低的存储开销和更有效的作业调度,同时满足多样性要求。
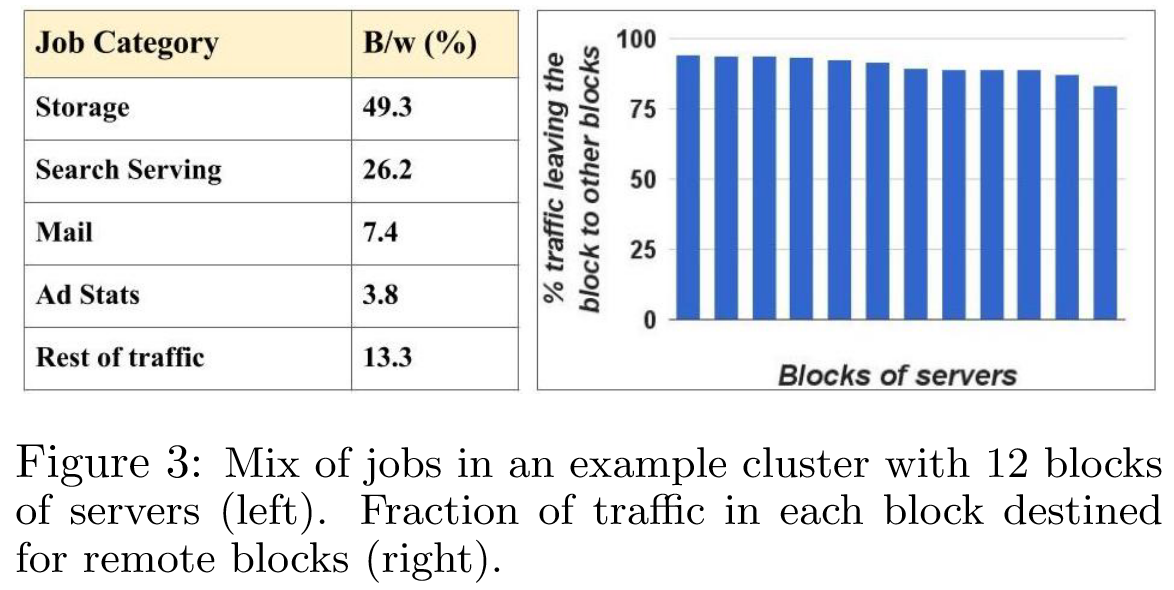
跨集群运行存储需要考虑机架和电源的多样性,以避免相关故障。因此,集群数据应该分布在集群的故障域中,以实现弹性(resilience,更多是指快速回复的能力)。然而,这种扩展式的分布自然地消除了局部性,并驱动对整个集群统一带宽的需求。因此,存储位置和作业调度在集群流量中几乎没有局部性,如图 3 所示。对于具有 12 个服务器块(机架组)的集群代表,图中显示了发往远程块的流量的比例。如果流量在集群中均匀分布,则预计 的流量将被发送到其他块。图 3 大致显示了中间块的这种分布, 方差并不大。
虽然传统集群网络架构在很大程度上满足了 Google 的规模需求,但在总体性能和成本方面还不够:
- 每个主机的带宽严重限制为平均 100Mbps。
- 与 incast 和 outcast 相关的数据包丢失是严重痛点。
- 增加每台服务器的带宽将大幅增加其成本,并减少集群规模。
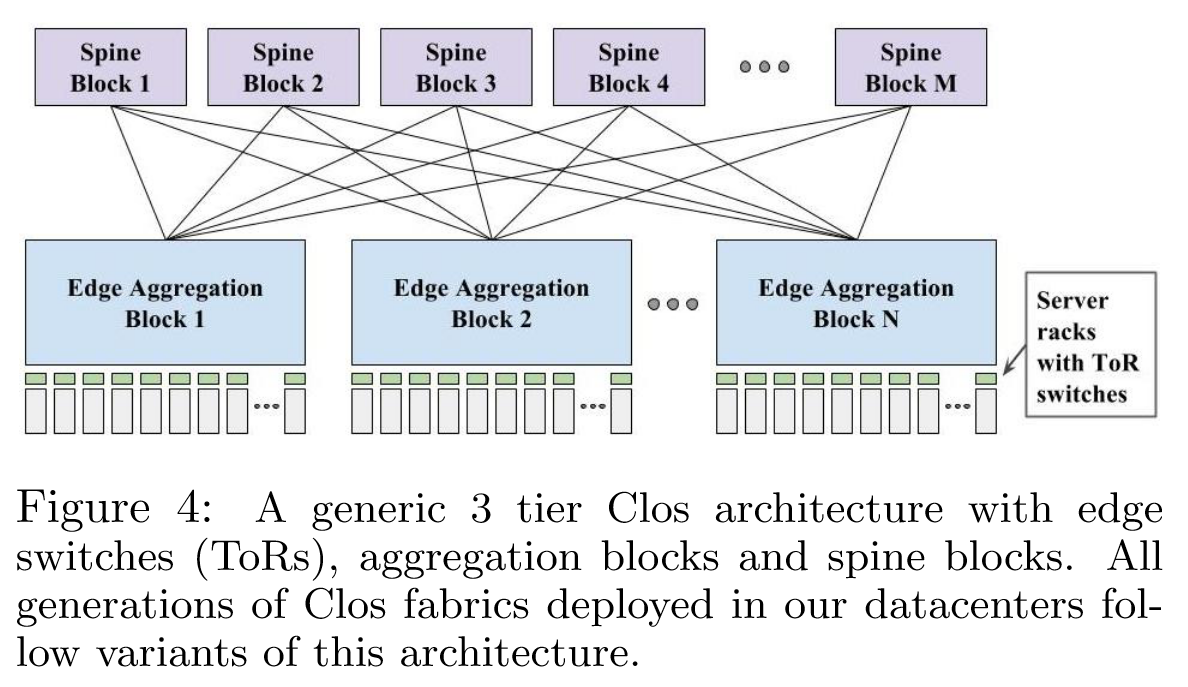
Google 决定定制 DCN 硬件和软件,从一个关键的见解开始——即可以通过利用 Clos 拓扑(图 4)4和当时新兴的(约 2003 年)商业交换机行业来将集群结构扩展到任意大小。表 1 总结了 Google 在构建和管理楼宇级网络结构时面临的一些挑战。
| Challenge | Our Approach (Section Discussed in) |
|---|---|
| Introducing the network to production | Initially deploy as bag-on-the-side with a fail-safe big-red button (3.2) |
| High availability from cheaper components | Redundancy in fabric, diversity in deployment, robust software, necessary protocols only, reliable out of band control plane (3.2, 3.3, 5.1) |
| High fiber count for deployment | Cable bundling to optimize and expedite deployment (3.3) |
| Individual racks can leverage full uplink capacity to external clusters | Introduce Cluster Border Routers to aggregate external bandwidth shared by all server racks (4.1) |
| Incremental deployment | Depopulate switches and optics (3.3) |
| Routing scalability | Scalable in-house IGP, centralized topology view and route control (5.2) |
| Interoperate with external vendor gear | Use standard BGP between Cluster Border Routers and vendor gear (5.2.5) |
| Small on-chip buffers | Congestion window bounding on servers, ECN, dynamic buffer sharing of chip buffers, QoS (6.1) |
| Routing with massive multipath | Granular control over ECMP tables with proprietary IGP (5.1) |
| Operating at scale | Leverage existing server installation, monitoring software; tools build and operate fabric as a whole; move beyond individual chassis-centric network view; single cluster-wide configuration (5.3) |
| Inter cluster networking | Portable software, modular hardware in other applications in the network hierarchy (4.2) |
Network Evolution
| Datacenter Generation | First Deployed | Merchant Silicon | ToR Config | Aggregation Block Config | Spine Block Config | Fabric Speed | Host Speed | Bisection BW |
|---|---|---|---|---|---|---|---|---|
| Four-Post CRs | 2004 | vendor | 48x1G | - | - | 10G | 1G | 2T |
| Firehose 1.0 | 2005 | 8x10G 4x10G (ToR) | 2x10G up 24x1G down | 2x32x10G (B) | 32x10G (NB) | 10G | 1G | 10T |
| Firehose 1.1 | 2006 | 8x10G | 4x10G up 48x1G down | 64x10G (B) | 32x10G (NB) | 10G | 1G | 10T |
| Watchtower | 2008 | 16x10G | 4x10G up 48x1G down | 4x128x10G (NB) | 128x10G (NB) | 10G | nx1G | 82T |
| Saturn | 2009 | 24x10G | 24x10G | 4x288x10G (NB) | 288x10G (NB) | 10G | nx10G | 207T |
| Jupiter | 2012 | 16x40G | 16x40G | 8x128x40G (B) | 128x40G (NB) | 10/40G | nx10G/nx40G | 1.3P |
表 2 总结了 Google 五代集群网络的数据。
Firehose 1.0
在最初的方法 Firehose 1.0(或 FH1.0)中,Google 的目标是向 10K 台服务器中的每个服务器提供 1Gbps 的无阻塞平分带宽。图 5 详细说明了 FH1.0 拓扑:
- 拓扑的起点是 8x10G 的结构交换机(fabric switch5)和 4x10G 的ToR 交换机。
- 在所有阶段中,结构交换机都部署了 4x10G 向上端口和 4x10G 向下端口,但最顶层的阶段除外,该阶段的所有 8x10G 端口都朝下。ToR 交换机向 fabric 提供 2x10GE6 端口,并配备 24x1GE 南向端口(south-facing7),其中 20x1GE 连接到服务器。
- 每个聚合块(aggregation block)承载 16 个 ToR(320 台机器),并向 32 个骨干块(spine block)暴露 32x10G 端口。每个骨干块具有 32x10G 端口连接到 32 个聚合块,从而形成一个可扩展至 10K 台机器的网络结构,每台机器在网络结构中的平均带宽为 1G 。
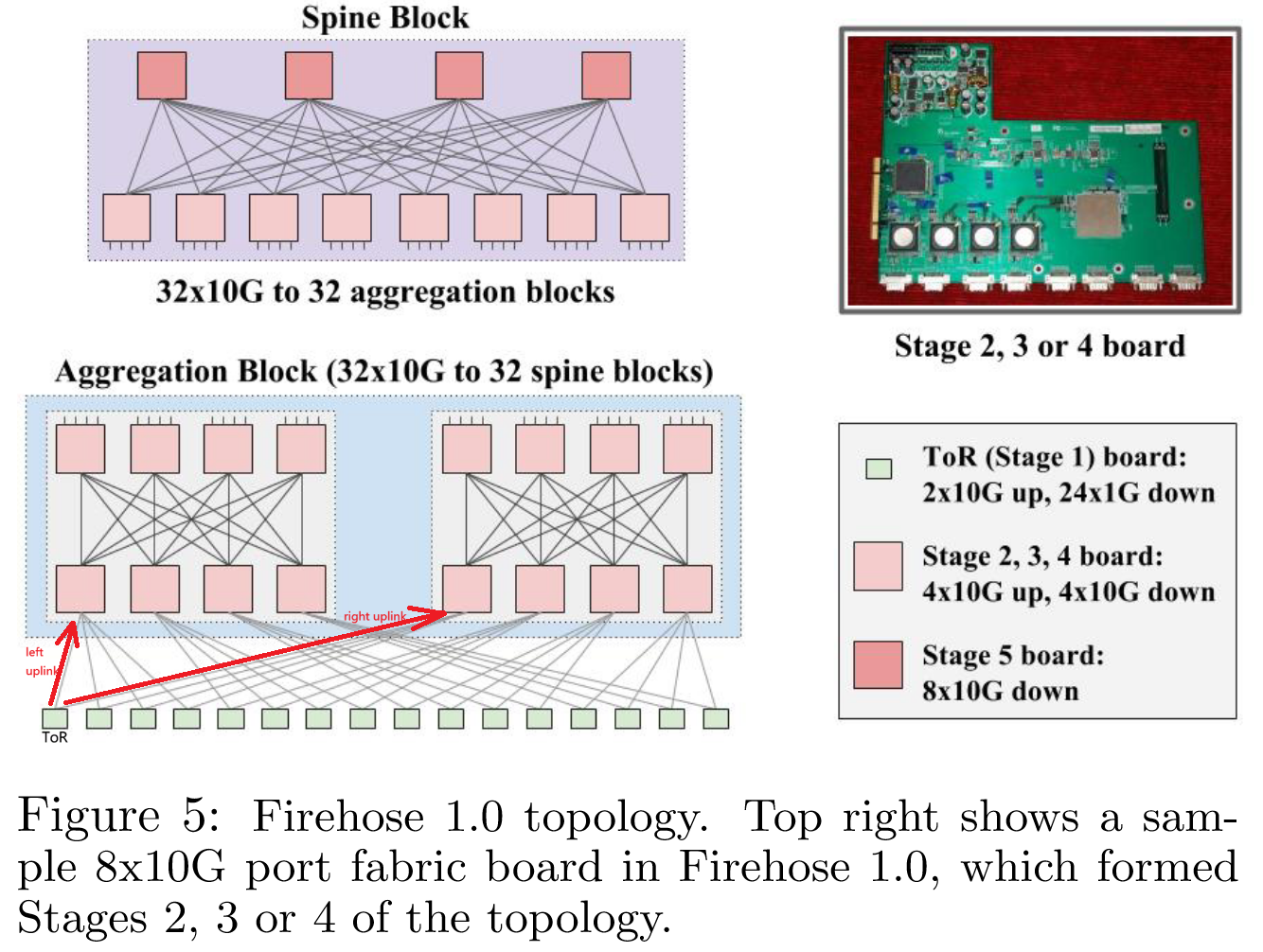
该拓扑结构的一个关键缺点是 ToR 交换机的低基数(radix8),这在链路故障发生时会有问题——如果源 ToR 的左上行链路9和目标 ToR 的右上行链路在 MTTR 窗口10内发生故障,这些 ToR 上的机器将无法相互通信,尽管它们与其他机器通信的能力还没有丧失——这种不可传递的断连(intransitive disconnect11)无法被应用程序有效处理。
由于 Google 没有构建交换机的经验,但不乏构建服务器的经验,因此他们选择通过 PCI 板将交换机结构集成在服务器中,如图 5 右上角插图所示。然而,服务器的运行时间并不理想。服务器崩溃和升级的频率比预期的要高,且重启时间较长。对于承载连接拓扑第一阶段中多个其他服务器的 ToR 的服务器而言,因服务器故障导致的网络中断问题尤为严重12。
服务器间连接所导致的布线复杂性、电气可靠性问题、可用性问题以及在首次尝试交换机时遇到的各种普遍问题,使得这一努力最终未能实际投入生产。不过,Google 认为 FH1.0 在内部仍然是一项具有里程碑意义的尝试,如果没有它及其带来的相关经验,后续的努力将无法实现。
Firehose 1.1: First Production Clos
Firehose 1.1 是第一个定制数据中心集群结构的生产部署,是 FH1.0 架构的变体。FH1.0 的教训是,不要使用常规服务器来容纳交换机芯片。因此,Google 构建了围绕 Compact PCI 机箱标准化的定制机柜,每个机柜具有 6 个独立的线路卡和一个专用的单板计算机(Single-Board Computer),以使用 PCI 控制线路卡。参见图 6 中的插图:
 该结构机箱未包含任何用于互连交换芯片的背板。所有端口均通过数据中心地板上的外部铜缆连接。线卡(linecard)采用了与 FH1.0 中用于第 2 至第 5 阶段的相同板卡的不同外形规格。Google 构建了一个独立的带外控制平面网络(Control Plane Network),用于配置和管理结构的单板计算机。
该结构机箱未包含任何用于互连交换芯片的背板。所有端口均通过数据中心地板上的外部铜缆连接。线卡(linecard)采用了与 FH1.0 中用于第 2 至第 5 阶段的相同板卡的不同外形规格。Google 构建了一个独立的带外控制平面网络(Control Plane Network),用于配置和管理结构的单板计算机。
FH1.1 拓扑是 FH1.0 中使用的拓扑的变体,虽然骨干块与 FH1.0 相同,但图 6 所示的边缘聚合块有一些差异:
- 这里使用两个 4x10G+24x1G 交换机芯片侧面连接在主板上,并为 ToR 提供 2x10G 链路。
- 最终的配置是一个 ToR 交换机,具有 4x10G 上行链路和 48x1G 到服务器的链路。
- ToR 被开发为单独的 1RU 交换机13,每个交换机都有自己的 CPU 控制器。
- 为了扩展到最多 20k 机器使得 oversubsciption 达到 2:1 ,需要将两个 ToR 交换机连接在一起。在每个 ToR 中的 4x10G 上行链路中,有两个连接到 fabric ,而两个横向连接到成对 ToR(buddied ToR)。
- 来自 ToR 之下机器的流量可以使用所有四个上行链路处理突发(burst)到 fabric,尽管竞争下的带宽会更低。
- 聚合块内的第 2 级和第 3 级交换机在单个块中布线(FH1.0 中则是 2 个不相交的块),配置类似于平面邻居网络。
- 每个 ToR 下最多有 40 台机器,FH1.1 聚合块可以以2:1超额订阅扩展到 640 台机器。
- 聚合块中的更改允许 Firehose 1.1 将支持的服务器数量扩展到 FH1.0 的 2 倍,同时与 FH1.0 相比,它对链路故障的鲁棒性更强。
Firehose 1.1 的聚合块如何扩展到 640 台服务器?
Firehose 1.1 的聚合块通过以下方式实现 640 台服务器 的规模和 2:1 超额订阅:
关键配置与计算
- ToR 交换机配置
- 下行端口(服务器侧):每个 ToR 有 48x1G 端口,其中 40x1G 连接服务器(剩余 8 端口未使用)。
- 上行端口(网络侧):每个 ToR 有 4x10G 上行链路,其中:
- 2x10G 连接到 Fabric(核心网络)。
- 2x10G 侧向连接到配对的 ToR(用于冗余和带宽突发)。
- 聚合块设计
每个聚合块包含 16 个 ToR 交换机。
服务器总数:
上行带宽计算:
- 每个 ToR 的 4x10G 上行链路中,仅 2x10G 用于 Fabric,总上行带宽为:
- 服务器到 Fabric 的总下行带宽需求为:
- 超额订阅比:
即服务器的总带宽需求是上行带宽的 2 倍,通过侧向连接(2x10G 到配对 ToR)缓解突发流量。
- 容错性改进
- Firehose 1.1 的聚合块采用 Flat Neighborhood Network(FNN) 设计,通过侧向连接增加路径多样性。
- 单条链路故障时,流量可通过冗余路径绕行,避免 Firehose 1.0 的“非传递性断开”问题。
FH1.1 的铜线互连是一个重大挑战。图 7 显示了生产部署中的机箱,构建、测试和部署网络是劳动密集型的,并且容易出错。CX4 电缆的 14 米长度限制要求仔细放置多级拓扑的每个组件。最长的距离通常是 ToR 和 Firehose 下一阶段交换机的基础设施之间的距离。为了提高可部署性,Google 开发了一个解决方案——仅为网络拓扑的这一阶段运行光纤。通过与供应商合作,为该互连开发定制了 电气/光学/电气(EOE)电缆。图 7 右下角的橙色电缆是一种 EOE 电缆,与右侧笨重的 14m CX4 电缆相比,它能够跨越 100m。

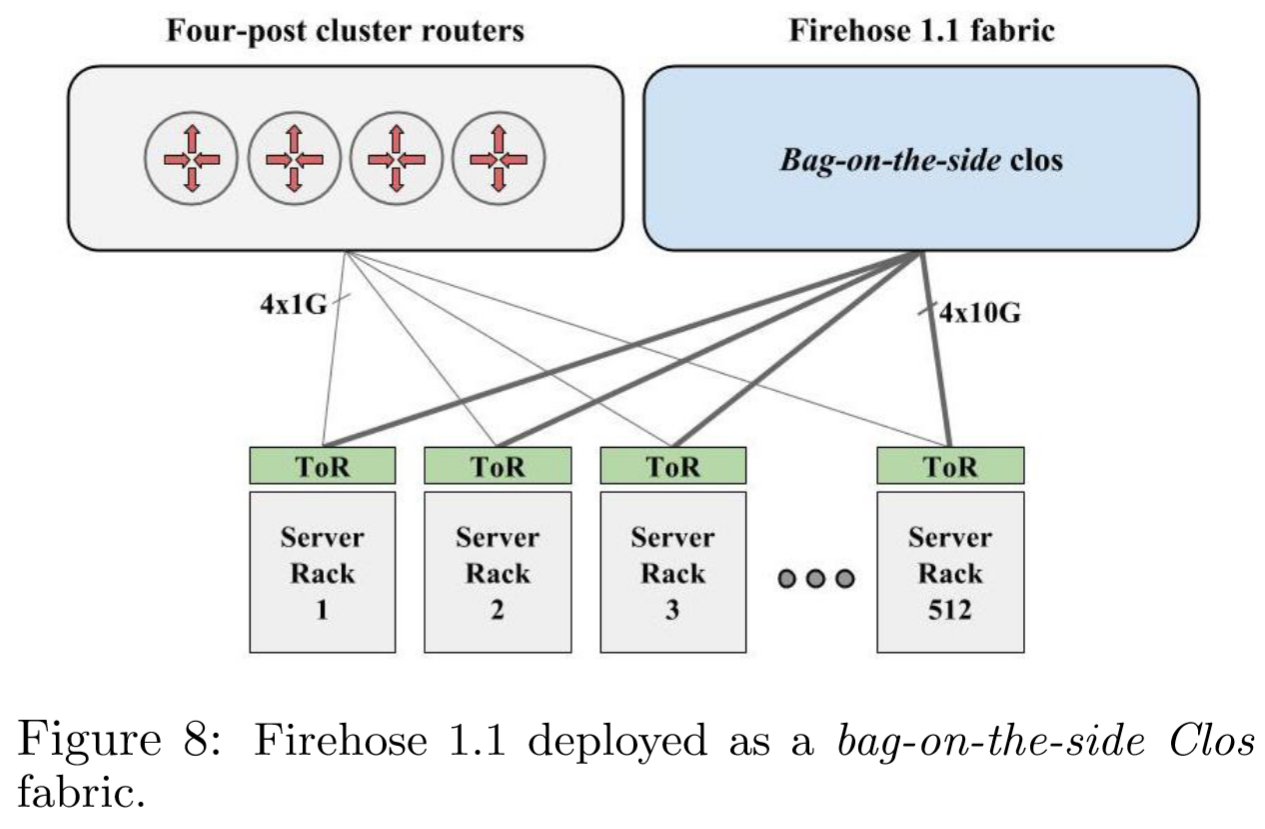
FH1.1 在生产中的一个主要问题是为任务关键型应用程序部署未经验证的新的网络技术。为了降低风险,Google 将 Firehose 1.1 与传统的四柱集群结构一起部署,如图 8 所示。ToR 将默认流量转发到四柱集群(例如,用于连接到外部集群/数据中心),而更具体的集群内流量将使用 Firehose 1.1 的上行链路。由于四柱集群采用了 1G 链路,因此只需要保留四个 1GE ToR 端口。Google 构建了一个“大红按钮”故障保护机制,用于配置 ToR(架顶交换机),以避免在发生灾难性故障时使用 Firehose 上行链路。
Watchtower: Global Deployment
FH1.1 的部署经验表明,与传统架构相比,服务可以获取更多的带宽,具有更低的单位带宽成本。Firehose 1.1 的主要缺点是外部铜缆布线的复杂性。
第三代集群结构 Watchtower 利用了这些经验,关键想法是利用下一代商用硅交换机芯片 16x10G,构建带有背板的传统交换机机箱。图 9 显示了半机架 Watchtower 机箱及其内部拓扑和布线。Watchtower 由八块线卡组成,每块线卡上有三个交换芯片。每块线卡上的两个芯片有一半端口对外,总共有 16x10GE SFP+端口。三个芯片都还连接到背板,以实现端口到端口的连接。
 Watchtower 的部署比早期的 Firehose 部署要简单得多。交换芯片的更大带宽密度也使得能够构建更大的架构,为单个服务器提供更多带宽,这是服务器采用越来越多核心的必要条件。
Watchtower 的部署比早期的 Firehose 部署要简单得多。交换芯片的更大带宽密度也使得能够构建更大的架构,为单个服务器提供更多带宽,这是服务器采用越来越多核心的必要条件。
光纤捆绑(fiber bundling)进一步降低了 Watchtower 集群的布线复杂性。图 10 显示了没有任何电缆捆绑的 Watchtower 结构部署。从每个机箱位置拉出不同长度的单独光纤会导致显著的部署开销。下半图展示了捆绑如何大幅降低复杂性——在每个机架中部署两个机箱,并将两个机架并置。然后可以将电缆束拉到并置机架的中点,在那里每个束被分配到每个机架,然后再分配到每个机箱。图 10 还描述了如何将集群结构连接到外部集群间网络。详细讨论推迟到 第 4 节。
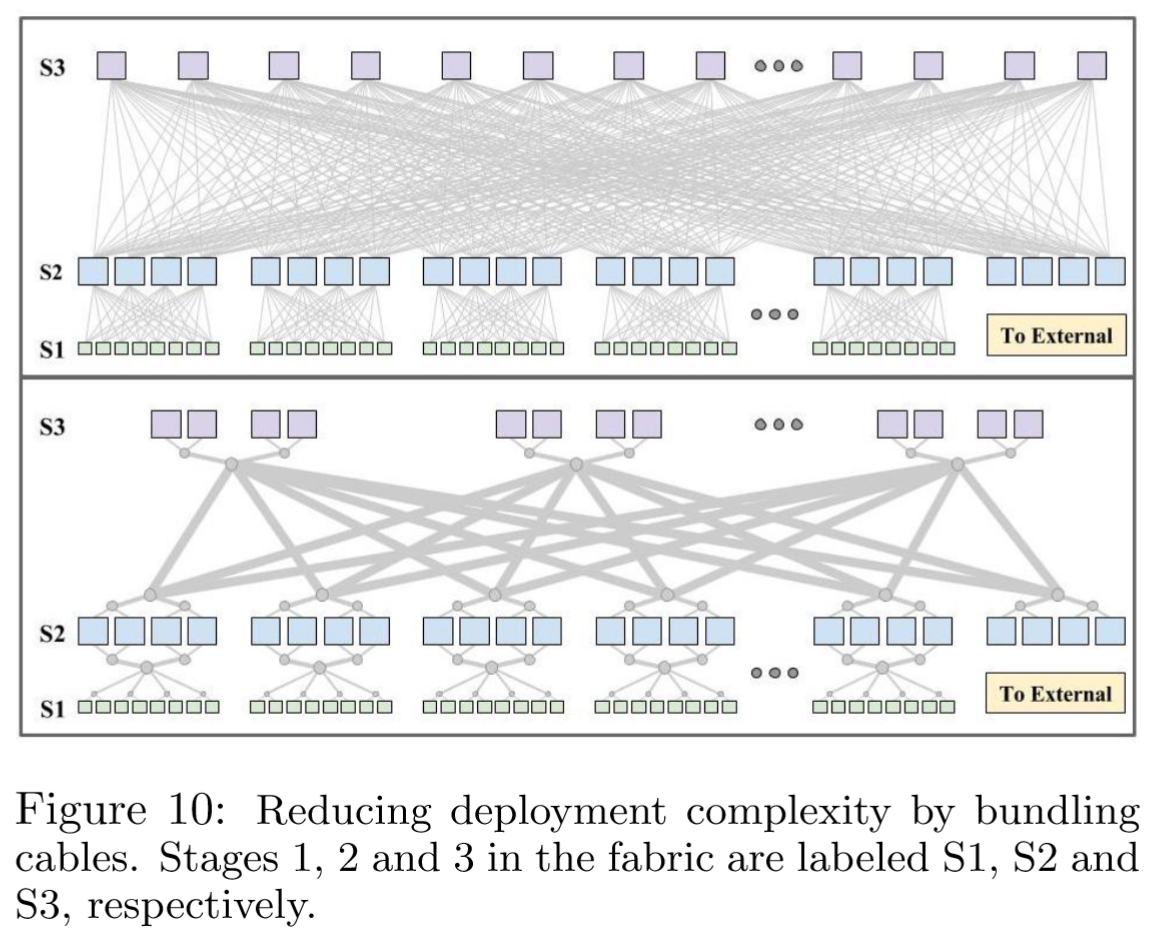 以束的形式制造光纤比单独的光纤更具成本优势。电缆捆绑帮助将光纤成本(资本支出+运营支出)降低了近 40%,并将 Watchtower 架构的启动时间缩短了数周。表 3 总结了捆绑和成本节约情况。
以束的形式制造光纤比单独的光纤更具成本优势。电缆捆绑帮助将光纤成本(资本支出+运营支出)降低了近 40%,并将 Watchtower 架构的启动时间缩短了数周。表 3 总结了捆绑和成本节约情况。

虽然 Watchtower 集群比任何可供购买的结构都便宜得多,规模更大,但绝对成本仍然很大。Google 使用了两个观察结果来推动额外的成本优化。首先,单个集群的带宽需求存在自然变化。其次,结构的主要成本是在光学和相关光纤方面。
虽然 Watchtower 集群架构的成本远低于市场上可购买的任何方案,并且规模更大,但其绝对成本仍然相当高。Google 通过两个观察来推动进一步的成本优化:
- 首先,各个集群的带宽需求存在自然变化。
- 其次,架构的主要成本在于光模块和相关光纤。
因此,Watchtower 架构设计为支持稀疏部署(depopulated deployment),即最初仅部署最大平分带宽的 50%。重要的是,随着稀疏集群的带宽需求增长,就可以在原地将其完全填充至 100% 平分带宽。图 11 展示了两种高层次的稀疏化选项(A)和(B),分别以红色标出稀疏化的交换机、光模块和光纤。
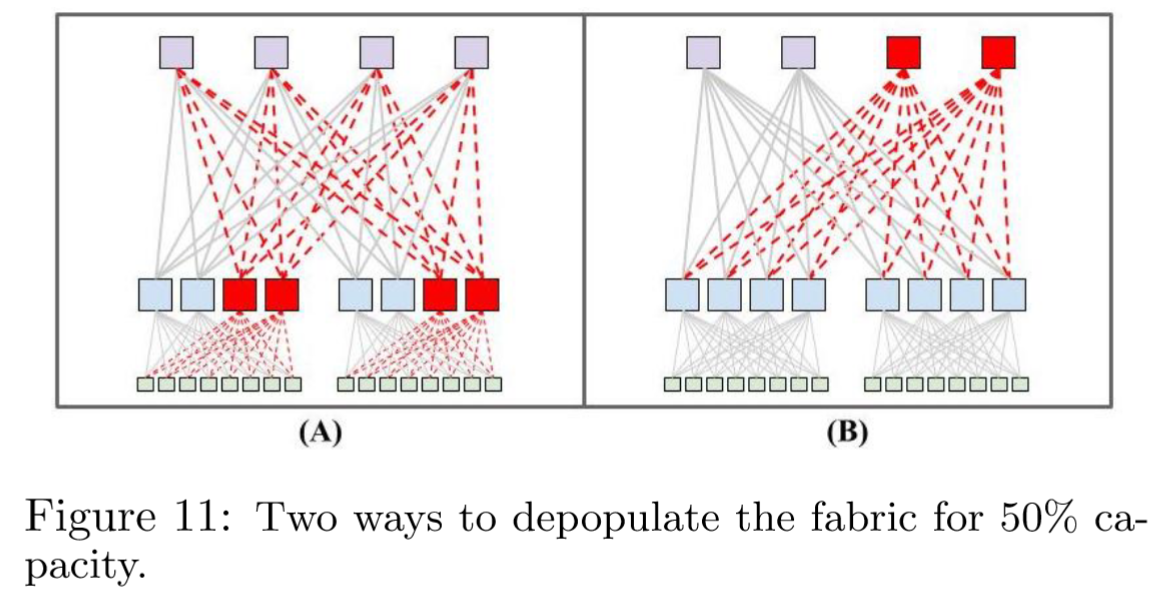 (A)通过稀疏化一半的 S2 交换机以及所有连接到稀疏化 S2 交换机的光纤和光模块,实现了 50%的容量。(B)则稀疏化一半的 S3 交换机及相关光纤和光模块。(A)在相同架构容量下,稀疏化的元素数量是(B)的两倍。
(A)通过稀疏化一半的 S2 交换机以及所有连接到稀疏化 S2 交换机的光纤和光模块,实现了 50%的容量。(B)则稀疏化一半的 S3 交换机及相关光纤和光模块。(A)在相同架构容量下,稀疏化的元素数量是(B)的两倍。
(A)要求所有骨干 S3 机箱在初期全部部署,即使边缘聚合模块可能缓慢地逐步部署,这导致更高的初始成本。(B)的初始成本更为渐进,因为所有骨干机箱并非在初期全部部署。(B)相较于(A)的另一个优势是每个 ToR 的突发带宽翻倍。
在 Watchtower 和 Saturn(第 3.4 节)架构中,Google 选择了选项(A),因为它最大限度地节省了成本。而在 Jupiter 架构(第 3.5 节)中,Google 转向了选项(B),因为随着向更大规模的建筑级架构发展,部署整个核心的初始成本增加,同时更高的 ToR 带宽优势变得更加明显。
Saturn: Fabric Scaling and 10G Servers
Saturn 是集群架构的下一个迭代。主要目标是响应服务器带宽需求的持续增长,并进一步提高最大集群规模。Saturn 由 24x10G 商用芯片构建模块组成。一个 Saturn 机箱支持 12 个线卡,提供 288 端口的无阻塞交换机。这些机箱与新的 Pluto 单芯片 ToR 交换机配合使用;参见图 12。
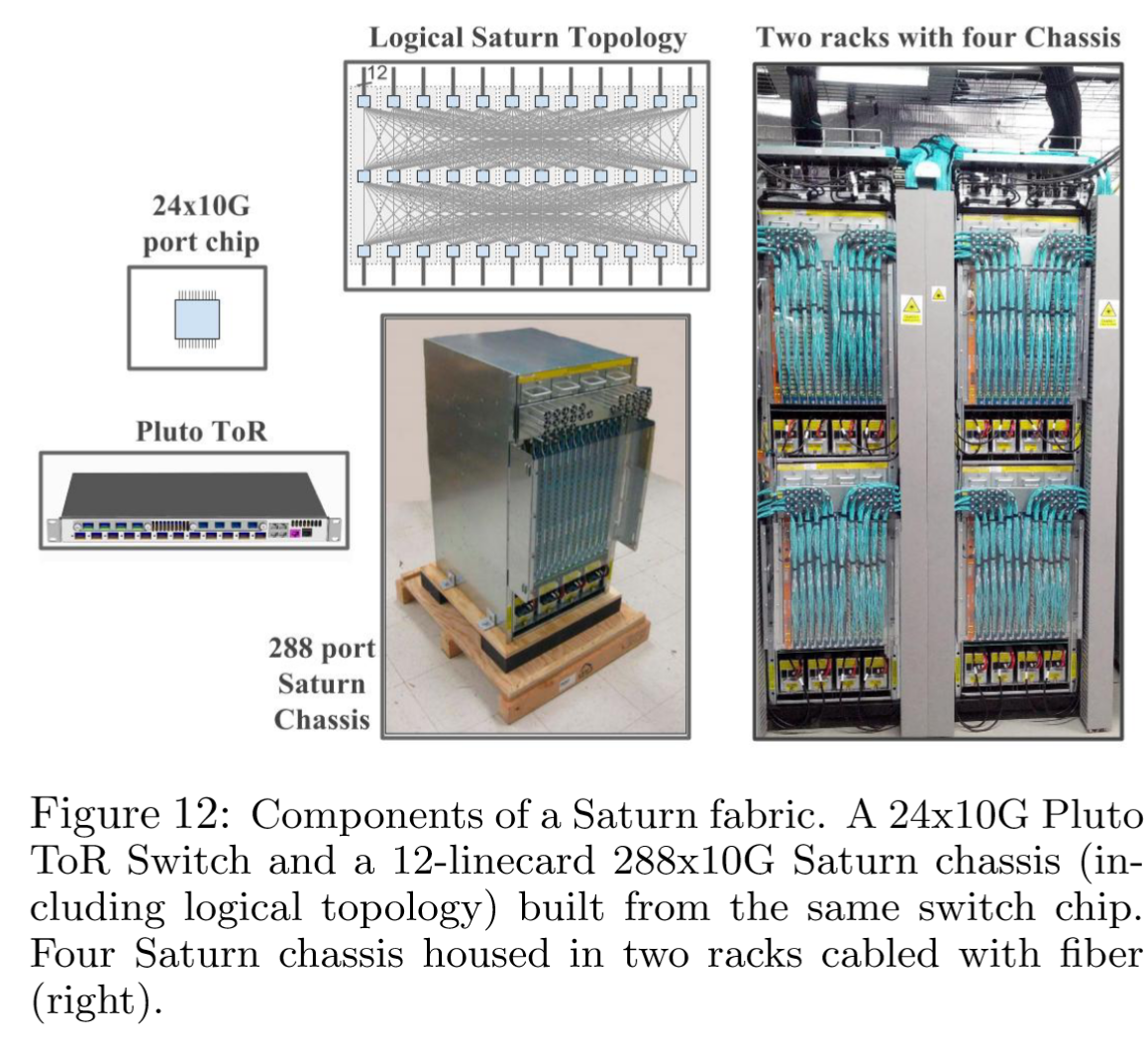 在默认配置中,Pluto 支持 20 台服务器,每台服务器通过 4x10G 连接到集群结构,平均带宽为 2 Gbps。对于带宽需求更高的服务器,可以将 Pluto ToR 配置为 8x10G 上行链路和 16x10G 连接到服务器,为每台服务器提供 5 Gbps 的带宽。重要的是,服务器首次可以在整个结构中突发达到 10Gbps 的带宽。
在默认配置中,Pluto 支持 20 台服务器,每台服务器通过 4x10G 连接到集群结构,平均带宽为 2 Gbps。对于带宽需求更高的服务器,可以将 Pluto ToR 配置为 8x10G 上行链路和 16x10G 连接到服务器,为每台服务器提供 5 Gbps 的带宽。重要的是,服务器首次可以在整个结构中突发达到 10Gbps 的带宽。
Jupiter: A 40G Datacenter-scale Fabric
随着每台服务器的带宽需求持续增长,数据中心内所有集群对统一带宽的需求也随之增加。随着支持密集 40G 的商用芯片的出现,Google 考虑将 Clos 架构扩展到整个数据中心,从而取代集群间的网络层。这将为应用程序调度提供一个前所未有的计算和存储资源池。关键的是,相对于架构的规模,维护单元可以保持足够小,使得大多数应用程序可以不受网络维护窗口的影响,这与前几代网络不同。
下一代数据中心架构 Jupiter 需要扩展到现有最大架构规模的 6 倍以上。与之前的迭代不同,Google 设定了逐步部署新网络技术的要求,因为资源闲置和停机成本过高。通过简单地替换现有集群来升级网络会导致已经投入生产的主机闲置。对于 Jupiter,新技术需要就地引入网络中。因此,该架构必须支持异构硬件和速度。由于规模庞大,网络中的事件(无论是计划内还是计划外的)预计会更加频繁,这就要求 Jupiter 能够稳健且优雅地应对这些事件。
在 Jupiter 的规模下,必须通过单独的构建模块来设计网络结构。然而,构建模块的规模是一个关键的讨论点。一个极端是 Firehose 方法,即每个交换芯片都通过线缆连接到数据中心内的其他芯片。另一个极端是采用 Watchtower 和 Saturn 结构的方式,即利用当前商用硅片构建最大的无阻塞两级机箱,并在网络结构中将这些机箱用于各种角色。
在第一代 Jupiter(图 13)中,构建块的大小进行了折中——部署单位是 Centauri 机箱,一个 4RU 的机箱,容纳两个线卡,每个线卡上有两个交换芯片,每个芯片有 16x40G 端口,由一个独立的 CPU 线卡控制。每个端口可以配置为 4x10G 或 40G 模式。这些芯片之间没有背板数据连接;所有端口都可以在机箱的前面板上访问。
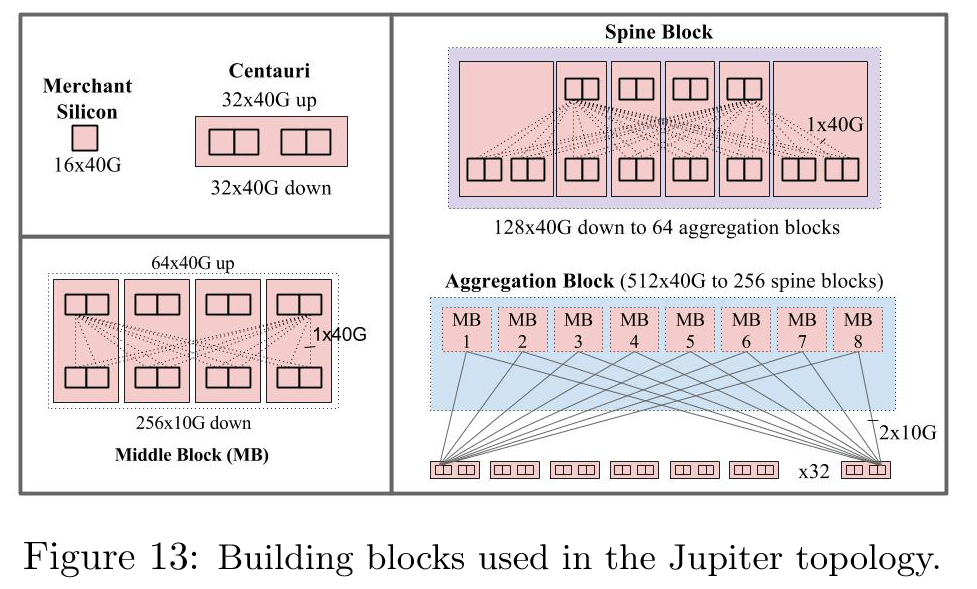
Centauri 交换机用作 ToR 交换机,每个芯片服务于一个子网的机器。在一个 ToR 配置中,每个芯片上 48x10G 连接到服务器,16x10G 连接到结构。服务器首次在生产环境中可以配置 40G 突发带宽(见表 2)。四个 Centauri 组成了一个中间块(MB),用于组成聚合块。MB 的逻辑拓扑是一个 2 级阻塞网络,具有 256x10G 链路用于 ToR 连接,64x40G 链路通过骨干连接到结构的其余部分。
每个 ToR 芯片通过双冗余的 10G 链路连接到八个这样的 MB。双冗余有助于在单链路故障或维护的常见情况下快速重新收敛。每个聚合块向骨干块暴露 512x40G(全填充)或 256x40G(部分填充)的链路。Jupiter 在每个骨干块中使用了六个 Centauri,向聚合块暴露 128x40G 端口。Google 将 Jupiter 的规模限制为 64 个聚合块,以确保在最大规模下每个脊柱块和聚合块对之间具有双冗余链路,再次确保在单链路故障时能够本地重新收敛。
Google 在单个网络机架中部署了四个 MB,如图 14 所示。同样,一个脊柱网络机架容纳了两个预接线的脊柱块。数据中心地板的布线涉及将这些网络机架之间的光纤电缆束连接起来,并连接到服务器机架顶部的 ToR 交换机。在其最大配置中,Jupiter 支持服务器之间的 1.3 Pbps 二分带宽。

External Connectivity
WCC: Decommissioning Cluster Routers
使用现有的集群网络块来提高集群间网络结构的性能和健壮性。
在最初的几次 Watchtower 部署中,所有集群结构都是作为与遗留网络共存的“袋装式”14网络部署的( 图 8 )。时间和经验缓解了安全性问题,使得天平倾向于减少部署两个并行网络的操作复杂性、成本和性能限制15。在迁移服务或跨集群复制大型搜索索引时,限制集群外的 ToR 突发带宽尤为受限。
{kind=link}
为什么说限制集群外的 ToR 突发带宽尤为受限?
在“bag-on-the-side”模式下,ToR 交换机需要同时连接新旧网络,但其上行带宽被人为限制。
- 具体问题:
- ToR 的上行链路被配置为优先使用旧网络(四柱集群的 1G 链路),而新网络(Firehose 1.1 的 10G 链路)仅用于集群内部流量。
- 当需要跨集群迁移服务或复制大型搜索索引时,旧网络的带宽(1G)成为瓶颈,导致传输速度受限。
- 技术限制:
- 旧网络(四柱集群)的上行链路带宽仅为 1G,而 Firehose 1.1 的带宽为 10G,但旧网络仍被设为默认路径。
- 由于安全顾虑,团队未完全放开新网络的带宽分配,导致跨集群任务(如数据复制)无法充分利用 Firehose 1.1 的高带宽。
因此,Google 的下一个目标是通过将结构直接连接到集群间网络层,使用集群边界路由器(CBRs)来退役集群路由器(CRs)。这项工作在内部被称为 WCC(Wide Cluster Connectivity)。图 15 展示了外部连接的各种选择:i)从每个 ToR 保留一些链路,ii)在每个聚合块中保留端口,iii)在每个脊柱块中保留端口,iv)为外部连接构建一个单独的聚合块。
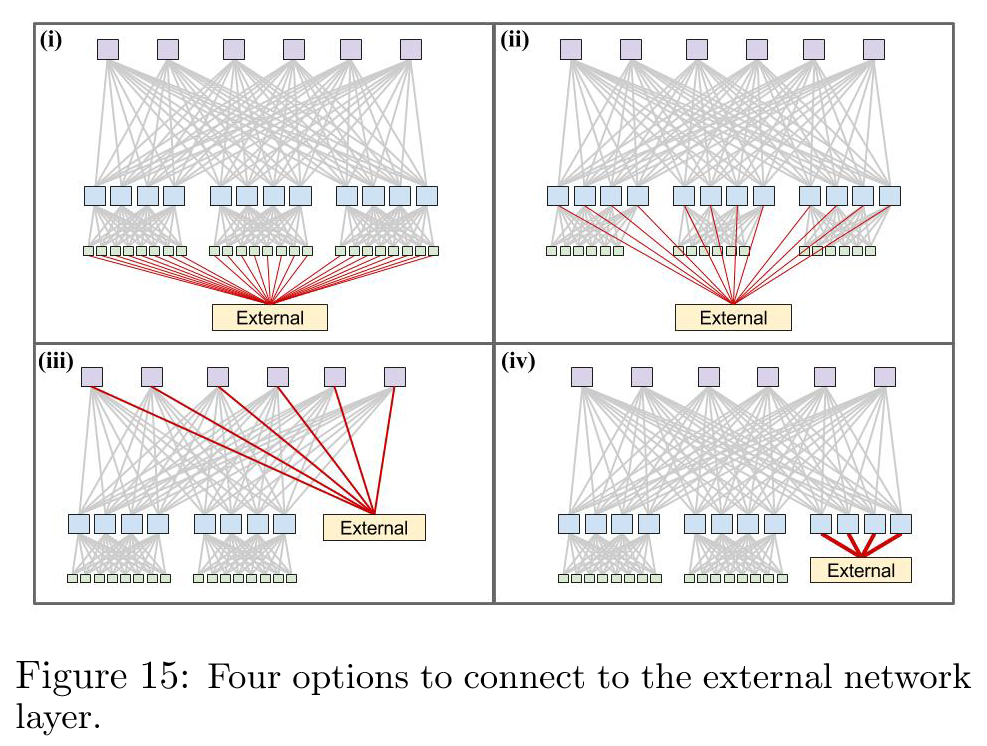 需要注意的是,i)与在 Firehose 1.1 中的方法类似。此外,假设采用最短路径路由,选项 i)和 ii)都无法提高外部突发带宽。然而,iii)和 iv)向每个聚合块提供整个外部带宽池。Google 最终选择选项 iv)是因为想要一个隔离的交换机层来与外部路由器对等,而不是将对等功能扩展到整个骨干交换机集。这种方法更安全,因为 Google 希望限制面向外部配置更改的爆炸半径,并且它限制了必须将内部 IGP 与外部路由协议集成的地方。
需要注意的是,i)与在 Firehose 1.1 中的方法类似。此外,假设采用最短路径路由,选项 i)和 ii)都无法提高外部突发带宽。然而,iii)和 iv)向每个聚合块提供整个外部带宽池。Google 最终选择选项 iv)是因为想要一个隔离的交换机层来与外部路由器对等,而不是将对等功能扩展到整个骨干交换机集。这种方法更安全,因为 Google 希望限制面向外部配置更改的爆炸半径,并且它限制了必须将内部 IGP 与外部路由协议集成的地方。
根据经验,使用一到三个聚合块分配了 10% 的集群内总带宽用于外部连接。这些聚合块在物理和拓扑上与用于 ToR 连接的聚合块相同。除此之外,还重新分配了通常用于 ToR 连接的端口,以连接到外部结构。
在这些区块中的每个 CBR 交换机与外部交换机之间配置了并行链路,作为链路聚合组(LAG)或中继链路。CBR 与集群间网络交换机之间使用了标准的外部 BGP(eBGP)路由。CBR 交换机通过 BGP 从 external peer 学习默认路由,并通过 Firepath 重新分发该路由。WCC 使集群结构真正独立,并解锁了集群间的高吞吐量批量数据传输。
Inter-Cluster Networking
在同一建筑内部署多个集群,在同一园区内部署多个建筑。考虑到物理距离和网络成本之间的关系,作业调度和资源分配基础设施利用园区级和建筑级的位置,将松散关联的服务尽可能紧密地放在一起。为 WCC 开发的 CBR 使集群能够连接到具有大量带宽的集群间网络——每个聚合块在 Watchtower 结构中支持 2.56Tbps 的外部连接,在 Saturn 结构中支持 5.76Tbps 的外部连接。
然而,外部网络层仍然基于昂贵且端口受限的供应商设备。网络结构演进的第三步涉及到替换基于供应商的集群间交换。Google 的新方法 Freedome 以比现有解决方案更低的成本在建筑物和校园内提供大量集群间带宽。
在集群路由器中开发的 BGP (第 5.2.5 节)被用于构建能够在集群间和园区内连接层之间使用 BGP 的两级结构。参见图 16。
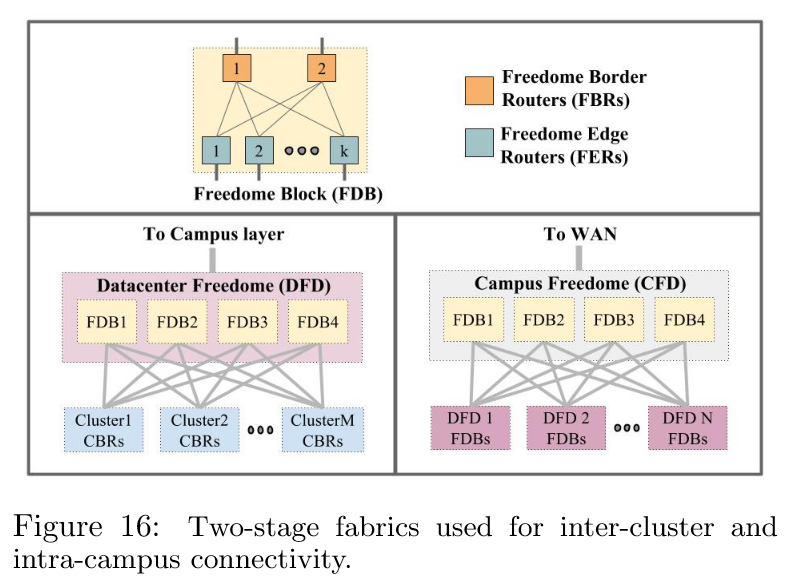 这个设计中通过聚合一组路由器作为 Freedome 块,如顶部图所示,每个块暴露的南向端口(面向集群)比北向端口(层次结构中的下一级,如园区或 WAN 等的更高一层)多 8 倍。每个块有两种交换机角色:Freedome 边缘路由器提供南向端口,而 Freedome 边界路由器提供北向端口。Freedome 块使用 eBGP 连接到南北向的对等体。每个块内部使用 iBGP,并将边界路由器配置为路由反射器。
这个设计中通过聚合一组路由器作为 Freedome 块,如顶部图所示,每个块暴露的南向端口(面向集群)比北向端口(层次结构中的下一级,如园区或 WAN 等的更高一层)多 8 倍。每个块有两种交换机角色:Freedome 边缘路由器提供南向端口,而 Freedome 边界路由器提供北向端口。Freedome 块使用 eBGP 连接到南北向的对等体。每个块内部使用 iBGP,并将边界路由器配置为路由反射器。
一个数据中心 Freedome 通常由 4 个独立的块组成,用于连接同一数据中心建筑内的多个集群。同一建筑内的集群间流量将从源集群的 CBR 层传输到数据中心 Freedome,通常保持在边缘路由器层,最后到达目标集群的 CBR 层。Google将 Freedome 边界路由器端口连接到北向的园区连接层。图 16 左下角描绘了一个数据中心 Freedome,建筑内流量的带宽是同一园区内建筑间流量的 8 倍。递归地,一个园区 Freedome 通常也由 4 个独立的 Freedome 块组成,用于连接园区内的多个数据中心 Freedome,南向连接多个数据中心 Freedome,北向连接 WAN 连接层。图 16 右下角描绘了一个园区 Freedome。
Freedome 块的递归式部署与路由反射器
1. Freedome 的 North-facing Ports 指向的层级
在 Freedome 架构中,north-facing ports 指向 更高层级的网络,具体取决于 Freedome 所处的层级:
- Datacenter Freedome(数据中心级)的 north-facing ports 连接到 Campus Freedome(园区级网络)。
- Campus Freedome 的 north-facing ports 进一步连接到 广域网(WAN)。
这种分层设计通过 Freedome 块的递归部署实现,每一层 Freedome 负责聚合下一层的流量(例如,Datacenter Freedome 聚合同一建筑内的多个集群流量,Campus Freedome 聚合同一园区内多个建筑的流量)。
2. 块内使用 iBGP 与路由反射器的原理(基于 RFC 4456)
背景:iBGP 的全连接问题
在传统 iBGP 中,所有路由器必须建立全互联(Full Mesh)会话以确保路由信息的一致性。但随着网络规模扩大,全互联的复杂度(
O(n²)连接数)变得不可行。路由反射器(Route Reflector, RR)的作用
根据 RFC 4456,路由反射器通过以下机制解决 iBGP 的扩展性问题:
- 反射客户端路由:
- 路由反射器从客户端(Client)收到路由后,将其反射给其他客户端和非客户端(Non-client)。
- 避免环路:
- 使用 Cluster ID 和 Originator ID 标记路由来源,防止反射导致的环路。
Freedome 中的应用
在 Freedome 块内:
- Freedome Border Routers 被配置为路由反射器,负责将外部路由(如 WAN 或园区级路由)反射给块内的 Freedome Edge Routers。
- 优势:
- 减少 iBGP 会话数量(无需全互联)。
- 简化路由传播,提高网络可扩展性。
部署独立块对于维持 Freedome 上的性能至关重要,因为每个块都可以独立地从服务中移除或排空,并在总容量下降 25% 的情况下完成升级。一旦在园区网络中推出 Freedome,BGP 路由器也将在 WAN 部署中得到应用。
对边缘路由器和边界路由器进行一个总结:
| 特性 | Cluster Border Router (CBR) | Freedome Edge Router |
|---|---|---|
| 位置 | 集群内部(连接集群网络与外部网络) | Freedome 块内部(同一层级网络,如数据中心内) |
| 主要任务 | 1. 通过 eBGP 与外部网络(如 WAN)交换路由。 2. 将外部路由通过 Firepath 协议分发到集群内部。 | 1. 通过 iBGP 处理同一层级内的流量(如数据中心内集群间通信)。 2. 依赖路由反射器优化路由传播。 |
| 路由协议 | eBGP(外部) + Firepath(内部) | iBGP(内部) |
| 部署场景 | 集群边缘(如连接到 Campus Freedome) | Freedome 块内部(如 Datacenter Freedome 的 Edge 层) |
Software Control
Discussion
构建网络硬件的控制平面时,必须考虑这些权衡:
- 部署传统的去中心化路由协议(如 OSPF/IS-IS/BGP)来管理网络结构,
- 或者构建一个自定义的控制平面以利用集群网络的一些独特特性和同质性。
传统路由协议的优势在于其经过验证的稳健性。但 Google 选择构建自己的控制平面,原因如下:
- 首先,也是最重要的,现有的路由协议在当时对 ECMP 转发的支持并不理想。
- 其次,过去没有高质量的开源路由栈。此外,修改硬件交换机栈以在硬件线卡之间隧道化运行的控制协议数据包到协议进程,需要大量的工作。
- 第三,担心在目标规模的网络结构(包含数百甚至数千个交换机)上运行基于广播的路由协议所带来的协议开销。像 OSPF Area 这样的扩展技术似乎难以配置和理解。
- 第四,网络可管理性是一个关键问题,维护数百个独立的交换机栈以及例如 BGP 配置令人望而生畏。
拥有大规模多路径的静态拓扑中进行路由的需求迫使研发新的方法。每个交换机根据其在网络结构中的位置具有预定义的角色,并可以相应地进行配置。从计算和通信的角度来看,集中式解决方案显得更为简单和高效——路由控制器收集动态链路状态信息,并通过可靠带外控制平面网络(Control Plane Network)将这些链路状态重新分发给所有交换机,然后,交换机可以根据当前链路状态计算转发表,作为相对于已知静态拓扑的增量,该静态拓扑已推送到所有交换机。
总体而言,数据中心网络抽象成一个具有数万个端口的单一结构,而不是数百个需要动态发现网络结构信息的自治交换机的集合。此时,受到具有集中管理的大规模分布式存储系统(Google Filesystem)成功的启发,为 Jupiter 数据中心网络和 Google 的 B4 广域网的控制架构提供了参考。
Routing
Firepath 是为 Firehose、Watchtower 和 Saturn 架构设计的路由架构。其中一些组件预见了现代软件定义网络(SDN)的一些原则,特别是在使用逻辑集中状态和控制方面。
- 首先,所有交换机都配置了基线或预期的拓扑结构。交换机通过成对邻居发现学习实际配置和链路状态。
- 接下来,路由过程由每个交换机与集中式的 Firepath 主节点交换其连接情况的本地视图,主节点将全局链路状态重新分发给所有交换机。交换机根据当前的网络拓扑视图本地计算转发表。
- 最后,仅在架构边缘使用标准 BGP 进行路由交换,并通过 Firepath 重新分发 BGP 学习到的路由。
Neighbor Discovery to Verify Connectivity
邻居间连接可能存在的问题:构建一个由数千条电缆组成的网络不可避免地会出现多种布线错误。此外,正确布线的链路在维护(如线卡更换)后可能会被错误地重新连接。流量使用错误布线的链路可能导致转发环路。单向故障或高错误率的链路也应避免使用,并安排更换。
为了解决这些问题,Google 开发邻居发现(Neighbor Discovery,ND)协议,这是一种在线活跃性(online liveness)和对端正确性(peer correctness)的检查协议。NDP 利用集群拓扑的配置视图以及交换机的本地 ID 来确定其本地端口的预期对端 ID。它定期交换本地端口 ID、预期对端端口 ID、发现的对端端口 ID 以及链路错误信号。这样做使得链路两端的 ND 能够验证布线的正确性。
每个交换机的嵌入式堆栈中的接口管理器(Interface Manager,IFM)模块持续监控每个端口的 ND 状态,只有在端口同时满足物理层和 ND 都处于 UP 状态时,才会向路由进程声明端口为 UP。线卡上的 LED 显示每个端口的 ND 状态,以协助现场物理调试。监控基础设施还收集并显示各种仪表板上的所有链路状态。ND 还用作保活(keepalive)协议,以确保对端设备处于活跃且功能正常的状态。如果远程软件崩溃或关闭,对端的 ND 实例最终会向接口管理器报告故障,接口管理器随后会向路由进程声明接口为 DOWN。
Firepath
通过定制的 IGP 协议 Firepath 来支持 Layer3 向 ToR 的任意路由。每个 ToR 支持一个 Layer2 的子网,例如某个 ToR 下的所有机器都作为一个广播域的部分。分配给 ToR 的 L3 子网旨在帮助在商用芯片的有限转发表中进行聚合。
Firepath 实现了集中式拓扑状态分发,但采用包含两个主要组件的分布式转发表计算。每个结构交换机上运行一个 Firepath 客户端,而一组冗余的 Firepath 主节点则在选定的骨干交换机子集上运行。客户端通过控制平面网络与选定的主节点通信。
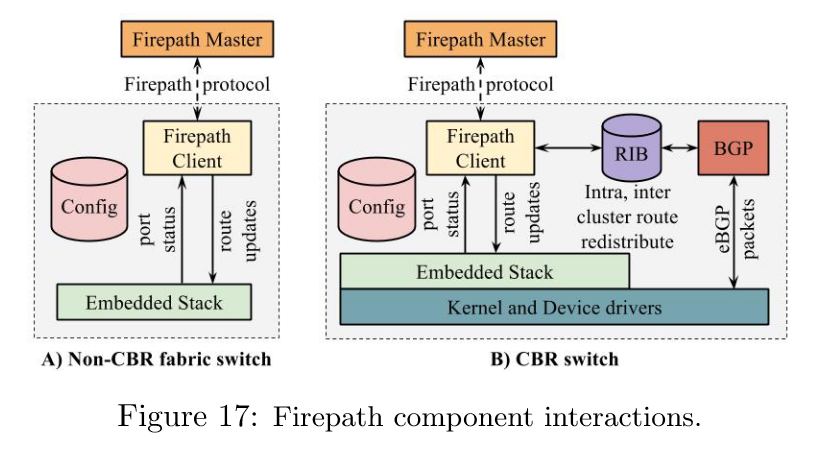 图 17 展示了 Firepath 客户端与交换机堆栈其余部分之间的交互。
图 17 展示了 Firepath 客户端与交换机堆栈其余部分之间的交互。
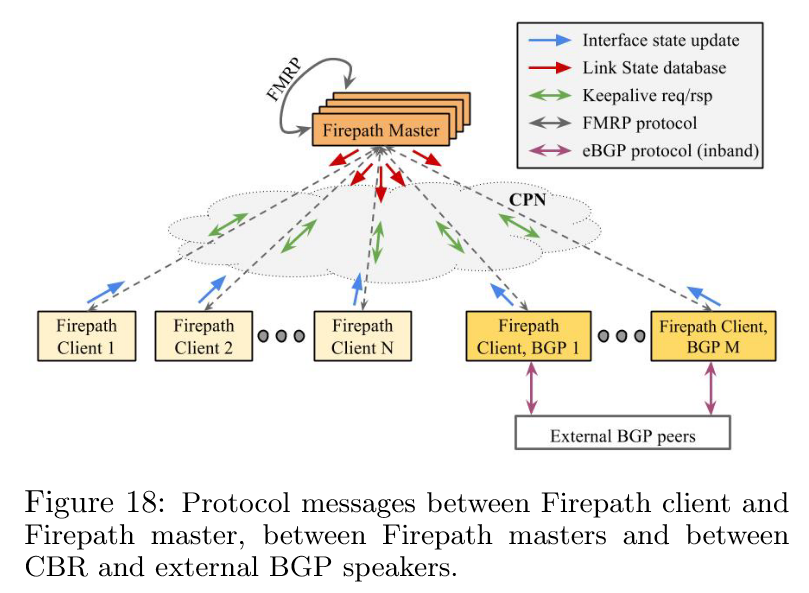 图 18 则说明了各种路由组件之间的协议消息交换。
图 18 则说明了各种路由组件之间的协议消息交换。
在启动时,每个客户端都会加载整个结构的静态拓扑(称为集群配置)。每个客户端从嵌入式堆栈的接口管理器中收集其本地接口的状态,并将此状态传输给主节点。主节点构建一个具有单调递增版本号的链路状态数据库(LSD),并通过 CPN 上的 UDP/IP 组播将其分发给所有客户端。在初始的完整更新之后,后续的 LSD 仅包含与先前状态的差异。整个网络的 LSD 可以容纳在 64KB 的有效载荷内。在接收到 LSD 更新后,每个客户端使用等价多路径(ECMP)计算最短路径转发,并编程其交换机本地的硬件转发表。为了避免客户端超负荷,主节点会限制它发给客户端的 LSD 更新的数量。
主节点还会与客户端维护一个 keepalive 协议,周期性地将主节点 ID 和当前 LSD 版本号作为“心跳”信息发送出去。如果客户端失去了与主节点的同步,例如失去了 LSD 信息,那么就要请求一个全量的 LSD 更新。
Path Diversity and Convergence on Failures
为了实现接口状态变化的快速收敛,每个客户端在接收到 LSD 更新后独立计算新的路由解决方案并更新转发表。由于客户端在收敛过程中不进行协调,网络在从旧状态过渡到新状态时可能会经历短暂的瞬态丢包。然而,假设扰动是暂时的,所有交换机最终都会基于网络状态的全局一致视图进行操作。表 4 展示了绕过组件故障的反应时间。

由于路径多样性高,大多数故障仅需要局部收敛,即故障相邻的元素通常具有多个其他可行的下一跳到达最终目的地。交换机的嵌入式堆栈可以快速从包含受影响链路的 ECMP 组中剪除故障链路/下一跳。ToR-S2 链路故障需要非局部收敛,因此耗时更长。在这种情况下,所有 S3 机箱必须避免使用受影响 ToR 交换机的 IP 前缀的特定 S2 机箱,即使此时如果 ToR 具有多个到 S2 交换机的链路可以进行优化。
这里局部收敛与否以及特殊的情况需要做进一步分析:
1. 为什么路径多样性高的情况下,大多数故障只需要局部收敛?
- 路径多样性:Clos 网络的多级拓扑(如 ToR → S2 → S3)天然支持多条等价路径(ECMP)。例如,一个 ToR 到另一个 ToR 的流量可以通过多个 S2 和 S3 节点转发。
- 局部收敛:当某条链路或节点故障时,直接相邻的节点(如 S2 或 S3 交换机)可以立即检测到故障,并通过预先配置的其他路径绕过故障点,而无需全局路由重新计算。例如:
- 若某个 S2 交换机的上行链路(到 S3)故障,相邻的 S3 交换机会通过其他 S2 节点转发流量。
- 这种局部修复仅涉及故障点附近的节点,收敛速度快(如表 4 中 S2-S3 链路故障的恢复时间为 125ms)。
关联:路径多样性为局部收敛提供了多条备用路径,使得故障修复无需扩散到整个网络。
2. ToR-S2 链路是什么?为什么需要非局部收敛?
- ToR-S2 链路:连接 ToR 交换机(服务器机架顶部交换机)到聚合层 S2 交换机的链路。
- 非局部收敛的原因:
- 若 ToR 到 S2 的链路故障,且该 ToR 仅有一条上行链路到该 S2,则所有经过该 S2 的流量必须通过其他 S2 节点绕行。
- 此时,S3 层交换机需要更新路由表,明确避开故障的 S2 节点,以确保到该 ToR 的流量不被错误转发。这需要 全局链路状态数据库(LSD)的更新,触发非局部收敛(恢复时间长达 4000ms,如表 4 所示)。
3. 为什么所有 S3 机箱必须避开特定的 S2 机箱?
- 问题场景:假设 ToR-A 通过 S2-X 连接到 S3 层。若 ToR-A 到 S2-X 的链路故障,而 ToR-A 没有其他到 S2-X 的链路:
- S3 层原本通过 S2-X 转发到 ToR-A 的流量将失败。
- 因此,所有 S3 交换机必须从路由表中移除通过 S2-X 到达 ToR-A 的路径,改用其他 S2 节点(如 S2-Y、S2-Z)。
- 结果:这一调整需要全局同步链路状态(通过 Firepath 协议),导致非局部收敛。
4. 如何通过多链路优化非局部收敛?
- 优化方法:如果 ToR 有 多条上行链路到同一个 S2 机箱(例如 2 条 10G 链路):
- 即使其中一条链路故障,ToR 仍可通过另一条链路与该 S2 通信。
- 此时,S3 层无需完全避开该 S2 机箱,只需调整 ECMP 组中的权重或哈希策略,继续利用剩余链路。
- 效果:故障修复仅需局部收敛(如 S2 机箱内部调整哈希),避免 S3 层的大规模路由更新。
总结
故障类型 收敛范围 原因 优化方法 S2-S3 链路故障 局部收敛 相邻 S2/S3 节点直接绕行,路径多样性提供备用路径。 无需优化,天然支持。 ToR-S2 链路故障 非局部收敛 ToR 缺乏冗余上行链路,需 S3 层全局更新路由。 为 ToR 增加多条到 S2 的链路。 核心逻辑:路径多样性通过多级 Clos 拓扑实现,而 Firepath 协议通过局部修复(利用备用路径)和全局状态同步(非局部收敛)的结合,在保证高可用性的同时最小化收敛时间。
Firepath LSD 更新包含由于计划内和计划外的网络事件引起的路由变化。在典型集群中(如 图 3 所示),此类事件的频率约为每月 2,000 次,每天 70 次,或每小时 3 次。
{kind=link}
Firepath Master Redundancy Protocol
集中式 Firepath 主节点是 Firepath 系统中的关键组件,它收集并分发接口状态,并通过保活协议同步 Firepath 客户端。为了提高可用性,Google 在预选的骨干交换机上运行冗余的主节点实例。交换机通过其静态配置了解候选主节点。
Firepath 主节点冗余协议(Firepath Master Redundancy Protocol)负责处理主节点与备份主节点之间的选举和簿记(bookkeeping)工作。主节点与备份主节点之间保持 keepalive 连接,并确保当前 LSD 与备份主节点在控制平面网络 FMRP 多播组上保持同步。启动时,主节点进入初始化状态,此时其 LSD 无效,并等待现有主节点的消息。如果收到现有主节点的 keepalive 信号,则进入备份状态。否则,进入选举状态,并向其他主节点候选者广播选举请求。通常情况下,选举的获胜者是拥有最新 LSD 版本的主节点,或者,抢占模式中会严格根据优先级(如最高 IP 地址)选举主节点。新当选的主节点进入主节点状态。
FMRP 在多年的生产环境和众多集群中表现出色。由于主节点选举具有粘性(sticky),行为异常的主节点候选者不会导致主节点变更或网络中的频繁变动。在控制平面网络分区的少数特殊情况下,可能会出现多主节点的情况,此时会立即提醒网络操作员进行手动干预。
什么是主节点选举的“粘性”?以及多主节点的场景是什么?
1. 主节点选举的“粘性”(Sticky Election)
粘性的含义是:一旦某个主节点(Master)被选举出来,即使后续出现其他符合条件的候选节点(如优先级更高或配置更新的节点),系统也会尽量维持当前主节点的权威性,避免频繁切换主节点。
- 目的:
- 减少因主节点频繁切换导致的网络状态不一致(如路由表震荡)。
- 保障网络稳定性,避免因短暂的网络波动或节点异常触发不必要的主从切换。
- 实现机制:
- 主节点通过周期性发送心跳(Keepalive)维持自身的权威状态。
- 备份节点(Backup Master)只有在持续无法检测到主节点的心跳(例如主节点故障或网络中断)时,才会触发新的选举。
- 即使新候选节点的优先级更高,若当前主节点仍在运行,系统不会主动切换,除非主节点明确失效。
2. CPN 分区导致多主节点的场景
CPN分区指控制平面网络因故障(如光纤中断、交换机故障)被分割为多个无法互通的子网络。此时可能出现多主节点的情况:
举例:
- 初始状态:
- 主节点(Master A)运行在分区 X,备份节点(Master B 和 Master C)运行在分区 Y。
- 主节点 A 通过 CPN 向所有备份节点发送心跳,维持自身权威性。
- 故障发生:
- CPN 网络发生分区,分区 X 和分区 Y 无法互通。
- 分区 Y 中的备份节点 B 和 C 长时间未收到主节点 A 的心跳,触发选举机制。
- 分区 Y 中根据优先级或配置版本,选举出新的主节点 B。
- 多主状态:
- 分区 X 中的主节点 A 仍认为自己是主节点,继续管理其所在分区的网络。
- 分区 Y 中的新主节点 B 开始独立管理其所在分区的网络。
- 结果:网络中同时存在两个主节点(A 和 B),各自维护不同的全局状态(如路由表),导致数据不一致和潜在冲突。
3. 为何需要人工干预?
- 自动恢复的局限性:
- 系统无法自动判断哪个主节点是“合法”的,因为分区可能导致双方都认为自己是权威的。
- 自动化的冲突解决可能引发更严重的路由混乱。
- 人工干预措施:
- 网络管理员需检查 CPN 分区的根本原因(如修复光纤或交换机故障)。
- 手动停用其中一个主节点,确保全网主节点唯一。
- 同步全局状态(如路由表)以消除不一致。
Cluster Border Router
集群与外部网络通过 BGP 进行对等连接。为此,CBR 上集成了 BGP 协议栈与 Firepath。这一集成有两个关键方面:i) 使 CBR 上的 BGP 协议栈能够通过带内通信与外部 BGP 发言者进行交互,ii) 支持 BGP 协议栈与 Firepath 之间的路由交换。 图 17B 展示了 BGP 协议栈、Firepath、交换机内核以及嵌入式协议栈之间的交互。
{kind=link}
- 对于 i),每个运行 eBGP 的外部中继接口都有一个 Linux 网络设备(netdev)。如 图 18 所示,BGP 协议数据包通过带内链路传输;利用嵌入式协议栈的数据包 I/O 引擎将这些控制数据包通过 netdevs 向量化到运行在嵌入式协议栈上的 BGP 协议栈。
- 对于 ii),CBR 上的一个代理进程在 BGP 和 Firepath 之间交换路由。该进程将集群内路由从 Firepath 导出到 BGP 的 RIB(路由信息库),并从 BGP 的 RIB 中提取集群间路由,重新分发到 Firepath 中。
{kind=link}
通过将路由汇总为集群前缀用于外部 BGP 通告,并将默认路由 /0 通告给 Firepath,做出了简化假设。通过这种方式,Firepath 仅管理所有出站流量的单一路由,假设所有 CBR 都可用于离开集群的流量。相反,假设所有 CBR 都可用于从外部网络到达集群的任何部分。Clos 结构固有的丰富路径多样性使得这些简化假设成为可能。
这里存在的两个疑惑
问题一:BGP协议栈如何通过“embedded stack’s packet I/O engine”向量化控制包?
解释:
在数据中心交换机中,“embedded stack”指的是交换机内部的嵌入式系统(如专用CPU或协处理器),负责运行控制平面软件(如路由协议、管理功能等)。“packet I/O engine”是嵌入式系统中用于处理数据包输入输出的模块。具体流程:
- 控制包分类:当外部BGP对等体(如其他路由器)发送BGP协议报文(如
OPEN、UPDATE)时,交换机的转发芯片(如ASIC)会识别这些控制包(通常基于目标端口号179或特定IP地址)。- 向量化(Vectoring):指通过硬件加速(如 DMA 或专用队列)高效地将数据包从交换机芯片的缓冲区“定向地”传递到 BGP 协议栈的虚拟网络接口(netdevs),减少 CPU 开销。
- BGP协议栈处理:控制包通过netdevs被传递给运行在嵌入式系统上的BGP协议栈,BGP协议栈解析并生成响应(如路由更新)。
类比理解:
这类似于在Linux系统中,特定类型的流量(如SSH)被iptables规则重定向到用户态进程处理,而不是直接通过内核转发。
问题二:关于路由汇总的简化假设及其意义
背景知识:
在Clos拓扑中,路径冗余极高(多级多路径),任何两个节点间存在大量等价路径。传统网络协议(如OSPF/BGP)需要维护复杂的路由表,但在大规模数据中心中,这种复杂性会带来性能和管理问题。简化假设的解释:
4. 对外的BGP路由汇总:
操作:将集群内所有子网(如
10.0.0.0/16)汇总为一个聚合前缀(如10.0.0.0/8)对外通告。目的:减少外部网络的路由表规模,避免明细路由泄露(如避免外部路由器需要处理成千上万的
/24路由)。
- 对内的默认路由(/0):
- 操作:在内部协议(Firepath)中,所有出集群流量只需匹配默认路由(
0.0.0.0/0),指向所有CBR作为下一跳。- 目的:简化内部路由表,Firepath无需维护外部网络的明细路由,仅依赖Clos拓扑的路径多样性来负载均衡流量到任意CBR。
为何可行?
- 路径冗余:Clos拓扑的任意CBR到外部网络的路径是等价的,且故障时可通过其他路径快速收敛。
- 负载均衡:ECMP(等价多路径)技术可将流量均匀分布到所有CBR,无需关心具体外部拓扑。
实际意义:
- 降低控制平面复杂度:Firepath只需关注集群内拓扑,无需集成外部路由协议(如BGP)的全部功能。
- 提高扩展性:路由表规模与集群规模解耦,即使外部网络变化(如新增ISP连接),内部无需重新配置。
- 高可用性保障 :Clos 网络的多路径特性确保即使部分 CBR 或链路故障,流量仍可通过其他路径传输。BGP 的路由汇总和 Firepath 的默认路由设计,避免了单点故障对全局路由的影响。
Configuration and Management
集群网络配置与管理的最核心目标是在整个项目中尽可能快地建造计算集群和网络结构。因此更倾向于简单性和可重复性,而不是灵活性——仅支持有限数量的结构参数,用于生成各个组部署网络所需的所有信息,并构建简单的工具和流程来操作网络。因此,该系统被广泛采用,负责构建数据中心的技术和非技术支持人员都能轻松上手。
Configuration Generation Approach
关键策略是将整个集群网络自上而下视为由预分配角色的交换机组成的单一静态结构,而不是自下而上地将单独配置的交换机集合成一个结构。另外还在集群级别限制了可供选择的数量,基本上提供了一个结构大小和选项的简单菜单——基于集群的预计最大大小以及可用的机箱类型。
配置系统是一个流水线,接受基本的集群级参数规范,如骨干的大小、集群的基本 IP 前缀以及 ToR 列表及其机架索引。然后,它为各个操作组生成一组输出文件:
- i)供应链操作的简化物料清单;
- ii)数据中心操作的机架布局细节、电缆捆绑和端口映射;
- iii)网络操作的 CPN 设计和交换机寻址细节(例如,DNS);iv)网络和监控数据库及系统的更新;
- v)交换机的通用结构配置文件;
- vi)用于审核逻辑拓扑和集群规格的图形视图的摘要数据。
将单一的整体集群配置分发给集群中的所有交换机(机箱和 ToR)。每个交换机只需提取其相关部分。这样做简化了配置生成,但每次集群配置更改时,每个交换机都必须更新为新配置。由于集群配置不经常更改,这种额外的开销并不显著,而且通常是必要的,因为 Firepath 需要全局拓扑状态。
Switch Management Approach
Google 为交换机设计了一个简单的管理系统——不再需要大多数标准的网络管理协议,相反,专注于将现有服务器管理基础设施与协议集成起来。不在服务器和网络基础设施之间划出明显界限的措施是有益的,例如包括镜像管理和安装、大规模监控、系统日志收集和全局告警。
这些例子怎样体现了不进行server和network infrastructure的划分所带来的收益?
1. Image Management and Installation(镜像管理与安装)
- 传统做法:
服务器通常通过自动化工具(如 PXE 引导、镜像仓库)安装操作系统和软件,而网络设备(如交换机)则需要通过专用工具(如 CLI 脚本、厂商特定的固件升级工具)单独管理。- Google 的做法:
交换机的固件和配置镜像被集成到与服务器相同的镜像管理系统中。例如:
- 使用与服务器相同的部署工具(如基于文件的镜像分发)为交换机安装固件。
- 交换机的配置文件(如启动配置)通过与服务器一致的版本控制系统进行管理。
- 收益:
- 统一工具链:管理员无需学习或维护两套独立的镜像管理工具。
- 自动化一致性:交换机与服务器的镜像更新可纳入同一自动化流程(如滚动升级),减少人为错误。
- 降低维护成本:无需为网络设备维护独立的镜像仓库和工具链。
2. Large Scale Monitoring(大规模监控)
- 传统做法:
服务器监控通常依赖代理(如 Prometheus、Zabbix)收集 CPU、内存等指标,而网络设备监控则依赖 SNMP 或专用协议(如 Cisco 的 NetFlow),两者数据分离。- Google 的做法:
交换机被配置为通过标准接口(如 REST API 或嵌入式代理)暴露监控数据,与服务器使用相同的监控框架。例如:
- 交换机的端口状态、流量统计、错误计数等指标通过与服务器相同的监控代理上报。
- 监控系统(如时间序列数据库)无需区分服务器或交换机的数据来源。
- 收益:
- 简化数据收集:无需为网络设备单独部署监控工具。
- 统一视图:在同一个仪表板中同时查看服务器和网络设备的健康状态,快速定位跨层问题(如网络拥塞导致服务器响应延迟)。
- 复用告警规则:复用服务器的阈值告警机制,例如对交换机CPU过载和服务器磁盘满的告警使用相同逻辑。
- 扩展性:利用已有的大规模监控基础设施处理海量网络指标,避免重复建设。
3. Syslog Collection(Syslog 日志收集)
- 传统做法:
服务器通过syslog协议将日志发送到集中式日志服务器,而网络设备的日志通常需要通过专用通道(如 SNMP Trap)或独立的 Syslog 配置进行收集。- Google 的做法:
交换机被配置为直接向与服务器相同的syslog服务器发送日志,格式和传输方式与服务器日志一致。例如:
- 交换机的链路状态变化、错误事件等日志与服务器的应用日志混合存储。
- 强制交换机使用与服务器相同的日志格式和传输协议(如结构化日志通过gRPC),统一接入日志管道(如Google的Dapper或内部日志系统)。
- 日志分析工具(如 ELK 栈)无需区分日志来源的设备类型。
- 收益:
- 日志标准化:通过统一的管道处理所有设备日志,降低日志管理复杂性。
- 关联分析:在故障排查时,可直接关联服务器和网络设备的日志(例如,服务器连接超时与交换机端口错误同时发生)。
4. Global Alerting(全局告警)
- 传统做法:
服务器的告警(如 CPU 过载)和网络设备的告警(如链路中断)通常由不同系统触发,需人工整合。- Google 的做法:
交换机的告警机制与服务器集成到同一告警框架中。例如:
- 交换机的接口状态变化(如
Link Down)通过与服务器相同的告警代理(如 Prometheus Alertmanager)生成告警。- 告警策略(如阈值、通知渠道)在服务器和网络设备间共享。
- 收益:
- 告警一致性:所有设备的告警通过同一管道处理,避免告警风暴或遗漏。
- 快速响应:运维团队只需关注单一告警系统,缩短故障响应时间。
总结:打破界限的核心价值
通过将交换机“伪装”成普通服务器,Google 实现了以下目标:
- 工具链统一:减少运维工具的数量和复杂性。
- 流程标准化:镜像部署、监控、日志、告警等流程无需区分设备类型。
- 故障定位效率:跨服务器和网络的故障可在一个系统中快速关联分析。
- 降低学习成本:管理员无需掌握专用网络管理技能,只需熟悉通用服务器管理工具。
这种设计体现了 “基础设施即代码”(Infrastructure as Code) 的理念,将网络设备纳入与服务器相同的自动化、可编程管理框架中,为超大规模数据中心的高效运维奠定了基础。
嵌入式堆栈对外部系统提供了一个单一的统一管理访问层(CMAL)接口来管理设备。Google 还将管理更新(administritive update)限制为排空或禁用特定端口。由于每个交换机上运行着多个软件组件,它们必须同时接受新的交换机配置。因此,采用由 CMAL 协调的标准两阶段 验证-提交 协议来部署新的交换机配置。
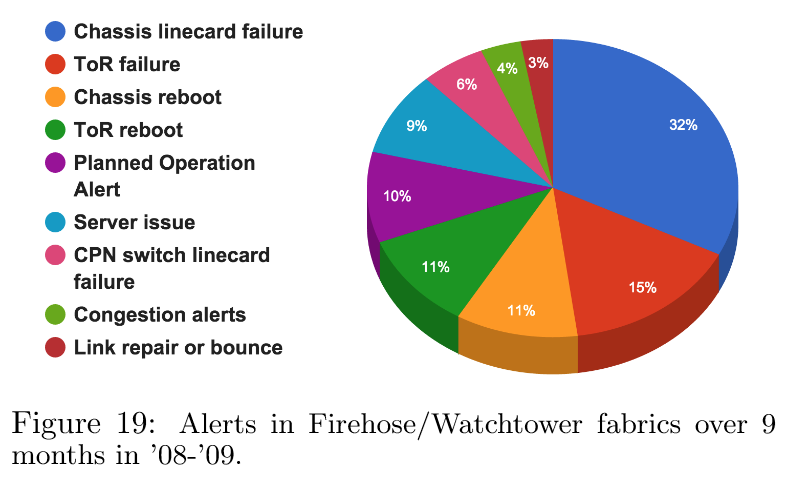
管理客户端通过简单的 API 检索交换机状态。重要的服务包括供操作员读取交换机状态以进行调试的本地 CLI、支持传统 SNMP 监视器的最小 SNMP 代理,以及将数据导出到网络和机器监控系统的特定监控代理。这个客户端使得再利用所有为管理服务器机群而构建的可扩展监控、警报、时间序列数据库(TSDB)系统,从而节省了大量工作。图 19 展示了 2008-2009 年 9 个月期间集群中观察到的监控/警报类型的样本分解。机箱线卡故障的高发生率是由于特定版本的商用硅片上的内存错误,并不反映线卡故障率的趋势。
Fabric Operation and Management
在结构操作和管理方面,继续沿用现有可扩展基础设施,该基础设施旨在管理和操作服务器群。Google 构建了更多能够感知整个网络结构的工具,从而在管理软件中隐藏了复杂性。因此,专注于开发仅真正适用于大规模网络部署的少数工具,包括链路/交换机认证、结构扩展/升级以及大规模网络故障排除。同样重要的是,在引入每个主要代次的网络结构之前,与网络运营团队密切合作,提供培训,以加快每项技术在整个服务器群中的推广速度。
图 20 总结了对结构软件升级的方法,原则或者说期望是,不在交换机上支持在线固件升级,而是利用结构冗余进行升级,结构容量的降低不应超过 25%。
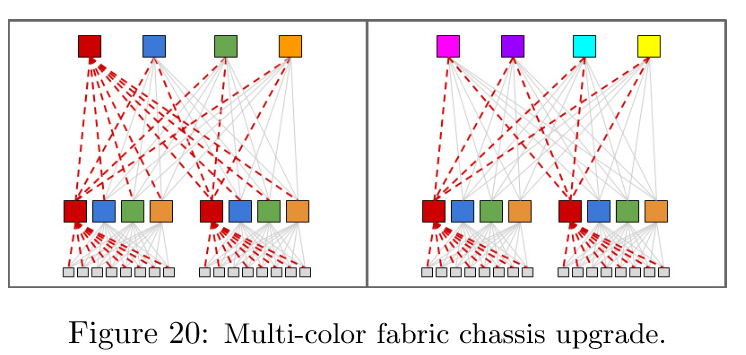 这幅图展示了在 Clos 拓扑中通过多个步骤升级结构机箱的两种方法:
这幅图展示了在 Clos 拓扑中通过多个步骤升级结构机箱的两种方法:
- 左图将所有机箱分为四组。当升级红色组时,虚线红色链路被禁用。然而,图中显示,网络结构容量降至56.25%(75%*75%)。
- 右图展示了一个更为优雅但更耗时的升级过程,涉及八组。逐个升级交换机会耗时过长。
在具有如此高路径多样性的网络中,排查异常流量对操作人员来说是一项艰巨的任务。因此,Google 扩展了调试工具(如 traceroute 和 ICMP),使其能够感知网络结构拓扑。这有助于在网络中三角定位可能造成流量黑洞的交换机。通过在集群中随机分布的服务器上运行探测来主动检测此类异常。当探测失败时,这些服务器会自动运行 traceroute 并识别网络中的可疑故障。
Experience
Fabric Congestion
尽管 Jupiter 具备足够的容量,但当利用率接近 25%时,网络仍然经历了较高的拥塞丢包。主要是以下几个因素导致了拥塞:
- i) 流量的固有突发性导致在短时间内出现不可接受的流量,通常表现为 incast 或 outcast;
- ii) 商用交换机缓冲能力有限,这对服务器 TCP 栈来说并不理想;
- iii) 网络的某些部分为了节省成本而有意保持过载,例如 ToR(架顶交换机)的上行链路;
- iv) 流量哈希不完美,尤其是在故障期间和流量波动时。
为了缓解拥塞,采用了以下技术:
- 首先,配置了交换机硬件调度器,使其基于 QoS 丢弃数据包。因此,在拥塞时会丢弃低优先级的流量。
- 其次,调整主机,限制其 TCP 拥塞窗口,以避免集群内流量超出交换机芯片的小缓冲区。
- 第三,对于早期的网络结构,在 ToR 上启用了链路级暂停,以防止服务器流量超出过载的上行链路。
- 第四,在交换机上启用了显式拥塞通知(ECN),并优化了主机栈对 ECN 信号的响应。
- 第五,监控应用的带宽需求,并根据过载比例进行带宽配置,通过部署具有四或八个上行链路的 Pluto ToR 来满足需求。同样,如果网络结构的去填充模式导致拥塞,则可以重新填充到骨干网的链路。
- 第六,商用芯片具有由所有端口共享的内存缓冲区,通过调整这些芯片上的缓冲区共享方案,以便动态分配更大比例的芯片缓冲区空间来吸收临时的流量突发。
- 最后,仔细配置了交换机的哈希功能,以支持跨多个网络路径的良好 ECMP 负载均衡。
这些拥塞缓解技术带来了显著的改进。在典型的 Clos 结构中,平均利用率为 25%时,将丢包率从 1%降低到<0.01%。
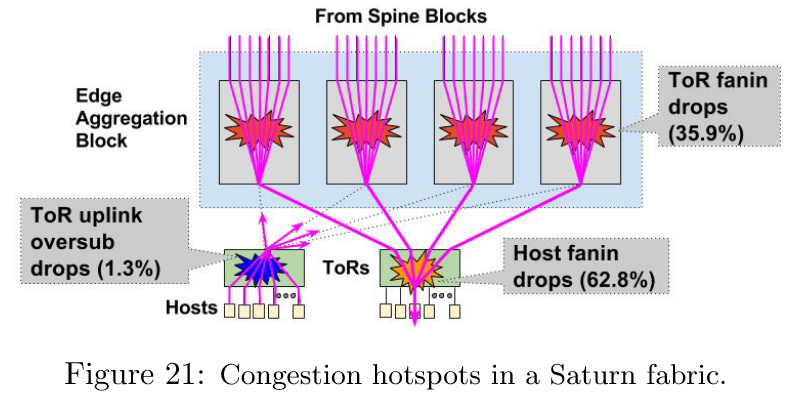 图 21 展示了一个具有 10G 主机的代表性 Saturn 集群中三个主要拥塞来源的分解。最大的丢包来源是 host fanin——从 ToR 流向某些主机的流量。其次是 ToR fanin,这可能是由于哈希不完美和特定 ToR 的 incast 通信引起的。最后,相对较小的一部分丢包是由于 ToR 上行链路向网络结构的过载造成的。
图 21 展示了一个具有 10G 主机的代表性 Saturn 集群中三个主要拥塞来源的分解。最大的丢包来源是 host fanin——从 ToR 流向某些主机的流量。其次是 ToR fanin,这可能是由于哈希不完美和特定 ToR 的 incast 通信引起的。最后,相对较小的一部分丢包是由于 ToR 上行链路向网络结构的过载造成的。
Outages
数据中心发生中断问题的原因可分为三类:i)大规模情形下控制软件问题;ii)老化的硬件暴露先前未处理的故障模式;iii)某些组件的错误配置。
Control software problems at large scale
在第一个例子中,数据中心的一次电源事件导致整个网络结构同时重启。然而,控制软件在没有人工干预的情况下无法收敛。不稳定性发生的原因是ND和路由计算在嵌入式交换机 CPU 上争夺有限的 CPU 资源。在整个网络结构重启时,路由经历了巨大的波动,这反过来导致 ND 无法及时响应 keepalive 消息。这进一步引发了路由的雪球效应,链路状态会错误地从“开启”变为“关闭”,然后又变回“开启”。于是不得不通过手动逐步启动几个区块来稳定网络。
展望未来,在测试计划中需要纳入最坏情况下的网络结构重启。由于最大规模的数据中心无法在硬件测试实验室中构建,需要启动在虚拟化环境中大规模压力测试控制软件的工作。还应严格审查 ND协议中的任何计时器值,针对最坏情况进行调整,同时在常见情况下平衡较慢的反应时间。最后,降低共享同一 CPU 的非关键进程的优先级。
Aging hardware exposes unhandled failure modes
在多年的部署过程中,内置的网络结构冗余由于硬件老化会逐渐退化。例如,
- 软件容易受到内部/背板链路故障的影响,导致罕见的流量黑洞问题。
- 另一个例子与控制平面网络的故障有关——每个网络结构机箱都有双冗余链路连接到 CPN,采用主备(active-standby)模式。最初并未主动监控主用和备用链路的状态。随着时间的推移,供应商设备出现了一些 CPN 链路的单向故障,暴露了路由协议中未处理的极端情况。 如果对网络结构背板和 CPN 链路进行了适当的监控和告警,这两个问题本可以更容易地得到缓解。
Component Misconfiguration
一次显著的配置错误中断发生在 Freedome 架构上。回顾一下,Freedome 机箱运行与 CBR 相同的代码库,并集成了 BGP 堆栈。CBR BGP 堆栈的 CLI 接口支持配置。没有实现锁定机制来防止对 BGP 配置的同时读写访问。
在对 Freedome 模块进行计划的 BGP 重新配置期间,一个独立的监控系统恰巧在同一接口上读取运行配置,而此时配置更改正在进行。不幸的是,由此产生的部分配置导致了 Freedome 与其 BGP 对等体之间的不良行为。Google 通过迅速恢复到之前的配置来缓解了这一错误。然而,这一事件的教训是要进一步强化操作工具。仅仅让工具能够配置整个架构是不够的;它们还需要以安全、可靠和一致的方式进行配置。
Footnotes
-
具体来说,这意味着当用户发起一个请求时(例如搜索查询或加载网页),服务器可以通过获取和处理更多的相关数据来生成更准确、更丰富或更个性化的响应。这种做法需要更高的带宽支持,因为更多的数据需要在网络中传输。 ↩
-
原词是 bisection bandwidth。这是数据中心网络设计中的一个重要概念。它指的是将数据中心网络分成两个相等部分时,这两部分之间总的可用通信带宽。简单来说,就是数据中心的一半服务器与另一半服务器之间的最大通信能力。在数据中心网络中,bisection bandwidth 是衡量网络性能和容量的一个关键指标,较高的 bisection bandwidth 意味着网络可以支持更多的服务器间通信,从而减少瓶颈并提高整体性能。这对于需要大量服务器间数据交换的应用(如大规模数据处理、分布式存储系统和高性能计算)尤为重要。论文中反复提到 bisection bandwidth,因为它直接影响了数据中心能够处理的工作负载规模和效率。例如,文中提到第一代 Firehose 1.0 的目标是为每个 10K 服务器集群提供 1Gbps 的非阻塞双分带宽,而后续的几代网络则逐步提高了这一指标,直到 Jupiter 达到 1.3Pbps 的双分带宽。这些改进反映了 Google 在提升数据中心网络规模和性能方面的持续努力。 ↩
-
就像操作系统中内存管理一样,如果应用无法将运行代码和数据一整个塞入内存,那么就要有取舍的选取驻留页,这里也是同理,装箱意味着将应用程序与相关数据打包在集群中处理。 ↩
-
在这里,“fabric” 指的是数据中心网络的核心部分或内部互联结构。具体来说,它是由多级交换机组成的 Clos 网络拓扑结构,用于连接所有的服务器和网络设备。Fabric 是整个网络的基础架构,负责实现服务器之间的高效通信。 ↩
-
这里的“4x10G”和“2x10GE”指的是端口的数量和速率:4x10G : 表示有 4 个端口,每个端口的速率为 10 Gbps;2x10GE : 同样表示有 2 个端口,每个端口的速率为 10 Gbps。“GE” 是 Gigabit Ethernet 的缩写,强调这些端口支持以太网协议。 ↩
-
“South-facing port” 是指交换机上朝向“南向”的端口,这是一种形象化的描述方式:South-facing : 通常指交换机端口连接到终端设备(如服务器或其他终端节点)的方向。在这种情况下,ToR(Top of Rack)交换机的 south-facing 端口是连接到机架内服务器的端口。相对地,“north-facing” 则指向上连接到更高层级交换机的端口。 ↩
-
这里的 radix 指的是交换机的端口数量或连接能力。具体来说,ToR(Top of Rack)交换机的 radix 是指它能够支持的上行链路和下行链路的端口总数。Firehose 1.0 中 ToR 交换机的 radix 较低,意味着它的端口数量有限,从而限制了网络的扩展性和容错能力。 ↩
-
left uplink 和 right uplink 是指 ToR 交换机的两个上行链路端口。在 Firehose 1.0 的拓扑中,每个 ToR 交换机有两条上行链路,分别连接到不同的聚合块。这些上行链路被形象地称为“左上行链路”和“右上行链路”。这些上行链路的作用是将 ToR 交换机连接到更高层级的网络,从而实现跨机架的通信。 ↩
-
MTTR window 指的是在故障发生后到系统完成修复之间的时间窗口:如果在 MTTR 时间窗口内,某个 ToR 的左上行链路和另一个 ToR 的右上行链路同时发生故障,那么这两个 ToR 之间的通信路径会被完全切断。 ↩
-
Intransitive disconnect (非传递性断开)是指一种特殊的网络故障情况:假设有两个 ToR 交换机 A 和 B,A 的左上行链路和 B 的右上行链路同时失效。此时,A 和 B 之间的直接通信路径被切断,但 A 和 B 仍然可以通过其他路径与其他 ToR 交换机通信。这种部分断开的情况被称为 intransitive disconnect ,因为通信的连通性不再是传递的(即如果 A 可以与 C 通信,C 可以与 B 通信,但 A 和 B 之间无法直接通信)。这种情况对应用程序来说很难处理,因为应用程序通常假设网络要么完全连通,要么完全断开,而不是部分连通。 ↩
-
Network disruptions from server failure were especially problematic for servers housing ToRs connecting multiple other servers to the first stage of the topology. ↩
-
1RU(1 Rack Unit)交换机 是指高度为 1.75英寸(约4.45厘米) 的标准机架式交换机。在 Firehose 1.1 中,ToR(Top of Rack)交换机被设计为独立的 1RU 设备,每个 ToR 有自己的 CPU 控制器。这种设计与 Firehose 1.0 不同(1.0 的交换机曾尝试集成在服务器机箱中),1RU 交换机更标准化,便于部署和维护。 ↩
-
bag-on-the-side,指新网络(如 Firehose 1.1)与传统旧网络(如四柱集群)并行部署 ,但两者在物理和逻辑上独立运行。 ↩
-
这里的意思是,通过 Firehose 1.1 等架构的实际运行经验,团队逐步建立了对新网络架构的信心,从而减少对旧网络的依赖。新网络在部署初期未经大规模验证,可能存在未知风险(如协议兼容性、硬件稳定性、故障恢复能力)。旧网络是经过长期验证的成熟方案,被视为“安全选项”。经过经验的积累,团队通过监控、故障排除和优化(如改进路由协议、冗余设计)逐步解决了初期问题,最终,团队认为新网络的风险可控,无需再依赖旧网络作为“安全备份”。 ↩