Introduction
NVMe SSD 性能与可靠性现状
NVMe SSD 凭借其高速接口(如 NVMe 协议)和先进技术(如 3D NAND、RAIN 冗余架构、LDPC 纠错1)逐渐成为数据中心的主流存储介质。尽管其性能显著优于传统 SAS/SATA SSD 和 HDD,但其可靠性问题在实际大规模部署中仍存在显著挑战:包括突发性完全故障(Fail-Stop)和渐进性性能退化(Fail-Slow)。
现有研究多聚焦于 SAS/SATA SSD 的故障模式(如早期故障率、写入放大效应、时空相关性故障),但对 NVMe SSD 的现场故障特性缺乏深入分析,尤其在故障相关性、性能退化机制等方面存在研究空白。
现有工作的不足
- 研究对象的局限性:已有大规模可靠性研究主要针对 SAS/SATA SSD,缺乏对 NVMe SSD 的针对性分析。
- 故障模式认知不足:NVMe SSD 的 Fail-Slow 故障缺乏系统性研究,其定义、检测方法和影响因素尚未明确。
- 相关故障的时空特性:传统 SSD 的时空相关性故障(如短时间密集故障)是否适用于 NVMe SSD 仍不清晰。
- 例如,SATA SSD 的 fail-slow 故障会被本身相对较高的延迟(>100μs)所掩盖,但 NVMe SSD 由于超低延迟(<10μs)的特点更容易受到影响。
- 预测指标的局限性:SMART2 属性在传统 SSD 中的预警作用可能不适用于 NVMe SSD 的新型故障模式。
本文工作的研究与贡献
- 首个大规模 NVMe SSD 现场故障分析:基于阿里巴巴数据中心 180 万+ NVMe SSD 的多源数据(SMART、故障工单、性能日志),系统性研究 Fail-Stop 与 Fail-Slow 两类故障。
- Fail-Stop 故障的新发现:
- 早期事故率不显著:NVMe SSD 在部署后的早期阶段未表现出传统 SSD 的高故障率,可能得益于 FTL 错误处理的改进。
- 写入放大效应差异化:高写入放大(WAF3>2)对 NVMe SSD 的可靠性影响较小,但低写入放大(WAF≤1)仍具有高故障风险。
- 时空相关性转变:相关故障从传统 SSD 的短期密集分布(如 1 分钟内)转变为长期跨度(如 1 天至 1 个月)。并且同位置故障(指相同节点或机架内)的时间相关性显著增强,较 SATA SSD 在节点内和机架内场景下的关联故障率分别提升 14.69 倍和 1.78 倍。
- Fail-Slow 故障的开创性研究:
- 普遍性与严重性:NVMe SSD 的性能退化故障发生率显著高于 HDD4 和 SATA SSD,且可能使性能退化至 HDD 水平。
- 检测方法创新:提出基于同节点设备横向对比的统计方法(如 IQR 边界检测),有效识别可疑 Fail-Slow 设备。
- 与 SMART 属性和 Fail-Stop 的弱关联:fail-slow 故障与 SMART 属性不相关,且性能退化极少转化为完全故障(5 个月内转化率<0.01%),二者为独立故障模式。
- 实践启示:
- SMART 属性无法有效预警 Fail-Slow 故障,需依赖性能日志的实时监控。
- 厂商差异、盘龄、工作负载显著影响 Fail-Slow 的发生频率与严重性。
Background
System Architecture
NVMe SSD 在硬件与协议层面进行了显著革新:
- 接口协议:采用 NVMe 标准,支持高并发、低延迟的访问模式,区别于传统 SAS/SATA 接口的队列深度限制。
- 内部技术:
- 3D NAND:通过垂直堆叠提升存储密度与寿命。
- RAIN:引入冗余机制增强数据可靠性。
- LDPC纠错:优化纠错能力以应对高密度闪存的比特错误率。
集群架构:
- HDFS-like:NVMe SSD 来自多个 Internet DC,其中存储集群大多采用类 Hadoop 的分布式文件系统。单个集群包含数个至数十个机架,每台机架最多容纳48个节点。
- all-flash-configuration:所有参与研究的NVMe SSD 均来自全闪存配置节点——这些节点配备12块非RAID组态的NVMe SSD(不承载操作系统)专用于数据存储。
Drive Model & Workload
研究覆盖 180 万+ 企业级 NVMe SSD,涵盖以下多样性:
- 硬件配置:
- 存储单元类型:MLC、3D-TLC、QLC 闪存。
- 容量范围:12 种规格(370GB 至 4000GB)。
- 厂商与型号:3 家厂商的 11 种驱动型号。
- 工作负载场景:
- 多样化服务类型:块存储、对象存储、大数据处理、日志存储、流处理、查询服务等。每种服务都会涉及若干集群。
- 驱动年龄与使用强度:覆盖新盘至老盘的全生命周期,使用强度从轻度到重度不等。
Data Collection
数据来源覆盖多维度监控系统:

- SMART 日志:记录设备健康状态(如 CRC 错误、擦写错误、异常断电次数、介质错误计数、温度等)。
- 故障工单:通过监控守护进程自动上报 Fail-Stop 事件(如设备离线、不可恢复错误),由工程师人工核验,其中包含故障盘的基础信息(如型号和主机名)及时间戳,约 35%的节点还会记录错误代码,详细描述故障的直接表现。
- 性能日志(iostat):通过节点级守护程序监控并采集
iostat日志,其中包含实时 I/O 延迟、IOPS、吞吐量等指标,用于检测 Fail-Slow 事件。
Methodology Correctness
- 由浅入深:若高层观测无效或存疑,将进行细粒度控制变量实验(如基于工作负载、驱动器型号、使用时长及总写入字节数等条件),以揭示根本原因并为从业者提供可行的改进建议(若存在)。
- 数据预处理:其次,对原始数据集进行预筛选以消除异常值(如SMART值溢出、iostat记录为NULL)导致的偏差,最终从SMART日志和iostat中分别剔除了约5.8%和1.5%的不可信记录。此外,出于普适性考虑,本研究还排除了样本量不足(少于1千台)的驱动器型号。不同供应商可能对同一型号采用不同命名,但本文将其视为同一型号处理。
- 谨慎选用统计工具:谨慎选用统计工具来识别和验证NVMe SSD故障中的潜在模式。选用依据是这些技术或阈值已被前人研究采用,或有明确文献表明其适用于目标场景。
Baseline Statistics
Dataset Overview
本文数据集基于阿里巴巴大规模生产环境中的 180 万块企业级 NVMe SSD,覆盖 3 家厂商 的 11 种型号,容量范围为 370GB 至 4TB,包含 MLC、3D-TLC 和 QLC 闪存类型。驱动器的 使用场景多样,涵盖块存储、对象存储、大数据处理、日志、流媒体等服务,且驱动年龄与负载模式存在差异。数据来源包括:
- SMART 日志:记录设备自检报告的健康指标(如错误计数、不可纠正错误)。
- 基线统计数据中,数据集被分为三类——基本信息、使用特征和健康指标:
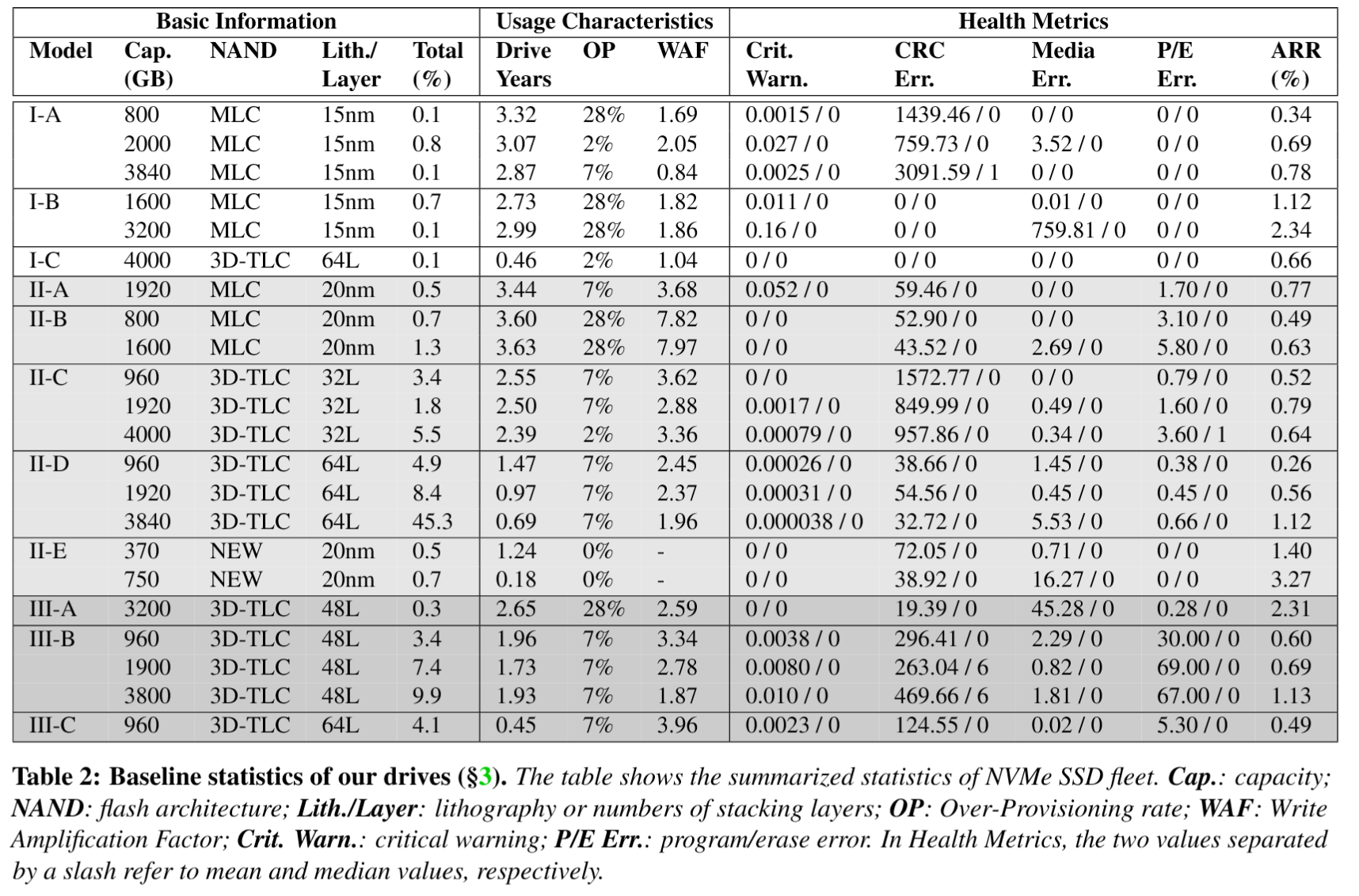
- 基础信息部分:驱动器型号命名为”制造商-型号”格式,采用字母顺序表示制造商的产品代际(例如I-A代表制造商I最早的型号);每个型号可通过容量(即Cap.列)和NAND架构(即NAND列)进一步细化说明;平面工艺芯片标注其制程节点(如I-A标注15nm),3D堆叠芯片则标注垂直堆叠层数(如I-C标注64层)。II-E属于特例,因其采用新型存储单元结构(既非平面也非3D堆叠),故标注为NEW(匿名化处理)。最后列出各型号的相对占比(即Total%列)。
- 特征部分:首列为平均通电时长(以年为单位),第二、三列分别呈现预留空间比例(即OP)与计算得出的平均写入放大系数(即WAF)。WAF通过NAND写入次数除以逻辑写入次数计算得出,两组数据均来自SSD的SMART属性报告。
- 可靠性相关的指标:严重警告表示驱动器可能存在严重介质错误(如处于只读或降级模式)、潜在硬件故障或超过温度报警阈值;CRC错误指传输错误次数(例如驱动器与主机间连接故障);介质错误指数据损坏错误次数(即无法访问闪存介质中存储的数据);编程/擦除错误指闪存单元编程错误次数(例如在复制回过程中无法对即将垃圾回收的块中的闪存单元进行编程);年更换率(ARR) 是设备故障数除以设备运行年数,反映驱动器的总体可靠性。
- 基线统计数据中,数据集被分为三类——基本信息、使用特征和健康指标:
- 故障工单:由监控守护程序记录的 fail-stop 故障事件(完全失效)。
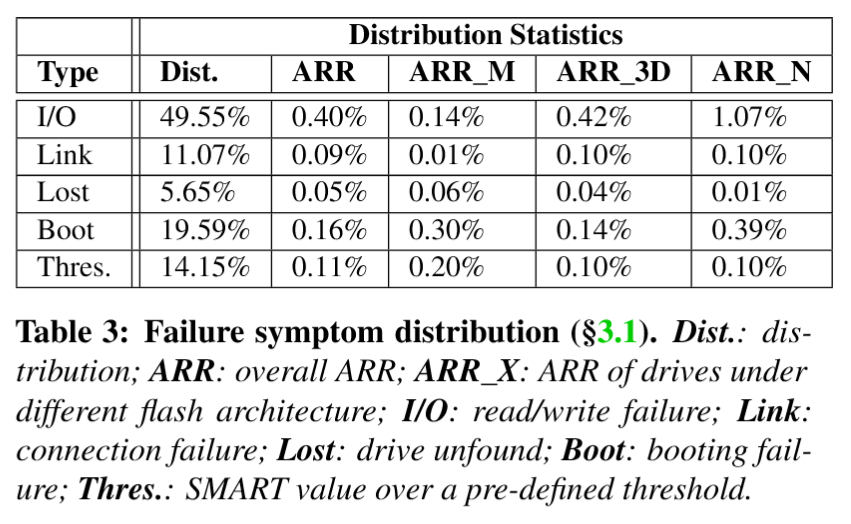
- 在报告的故障驱动器中,约35%明确标注了直接故障原因,表3展示了这些故障的症状分布情况,共识别出五类故障症状:I/O故障指驱动器无法执行读写请求;链路故障表现为PCI-e传输过程中的连接错误或带宽异常;丢失故障指正常运行中的驱动器突然无法被识别;启动故障描述驱动器初始化失败(如文件系统挂载失败);阈值故障则指一个或多个SMART属性达到预设阈值。
- 针对每类故障,统计了其在所有NVMe SSD中的分布比例(Dist.列),并分别给出整体平均修复率(ARR)、MLC型(ARR_M)、3D-TLC型(ARR_3D)及新型NAND驱动器(ARR_N)的对应数据。
- 性能日志(iostat):用于分析 fail-slow 故障(性能退化)的 I/O 延迟与吞吐量数据。
High-Level Observations
NVMe SSD vs. SATA/SAS SSD:
- 年化故障率更高:NVMe SSD 的年化故障率远高于 Netapp 企业存储系统中的 SATA/SAS SSD。对两组 ARR 进行 t 检验后,得到的 p 值为 3.554e-07。NVMe SSD 的平均 ARR 和中位 ARR 分别为 0.98%和 0.69%,较 SATA/SAS SSD 分别高出 2.77 倍和 2.83 倍。
- I/O 错误的比例更大:I/O 错误在 NVMe SSD 中占比显著上升(达 49.55%),驱动器丢失错误不再占主导地位(NVMe SSD 中为 5.65%,而 SATA SSD 中为 53.7%)。
Drive capacity:
- 平均P/E错误率与ARR均与容量呈正相关。以II-D驱动器系列为例,随着容量增加,平均P/E错误率从0.38升至0.66,ARR则从0.26%激增至1.12%。这种现象可解释为:大容量驱动器更频繁被访问,从而增加了发生编程错误的概率。
NAND type:
- 发现3D TLC驱动器的ARR略低于MLC驱动器,而在SATA SSD中这一趋势相反:MLC驱动器的ARR范围在0.34%至2.34%之间,3D TLC SSD则在0.26%至2.31%之间。
- 值得注意的是,采用新型NAND架构(即II-E系列)的驱动器,其平均ARR分别比MLC和3D-TLC驱动器高出约1.61倍和1.87倍(p值分别为2.065e-02和4.351e-03)。对于基于新型架构的SSD,其高ARR的主要诱因是I/O故障和启动故障。