指令格式

- 指令格式将 32 位分为不同的“域”
- RISC-V 定义了六种指令的格式:
- R-格式:寄存器指令,指定指令中的 3 个寄存器
- I-格式:指令中包含立即数,用于带一个常数的算术指令以及加载指令
- S-格式:store 指令
- B-格式:分支指令
- U-格式:大立即数,两个指令 lui (load upper imm), auipc (add upper imm to PC)
- J-格式:唯一指令 jal
R 型指令

- opcode (7): 操作码,但未指明确切操作
- R 类型指令操作码都为 0110011
- funct3 (3), funct7 (7): 与操作码 opcode 一起指定了指令的具体功能
- 计算一下能够编码多少 R 类型指令功能? - opcode 是固定的, 依据 funct: 2^10 = 1024
- rs1 (5): 第一个操作数 ,(“source register”)
- rs2 (5): 第二个操作数 ,(“ second source register”)
- rd (5): 目标寄存器 ,(“ destination register”)
- 每一个寄存器5位进行编码,可以指定32个寄存器,编码的是寄存器编号
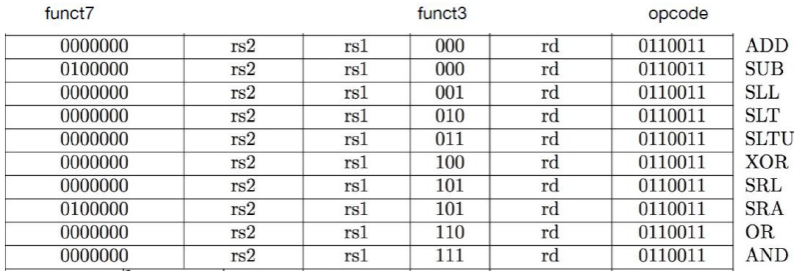
add x8,x9,x10则翻译成指令为:- binary: 0000000 01010 01001 000 01000 0110011
- hex: 0x00a48433
I 型指令
对于含有立即数的指令来说,5位的域能够表达的范围太小
- 理想来说,RISC-V 指令最好只有一种格式。
- 但是实际情况下需要折衷——在实际中可以依据类似于 R 指令格式的方式定义新的指令格式
- 如果一条指令使用了立即数,这条指令最多使用两个寄存器

- opcode (7): 指定操作类型
- rs1 (5): 指定一个寄存器操作数
- rd (5): 指定目标寄存器 (“destination register”)
- immediate (12): 12 位立即数
- 所有的计算是用字进行计算,即 32 位,必须要对立即数进行扩展
- 采用符号扩展方式
- 12 位表示范围
[-2048, +2047]- 如果立即数超过 12 位,怎么办?采用 U 型指令——大立即数,20 位
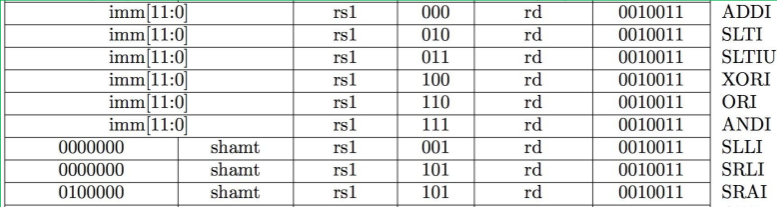
addi x15,x1,-50则翻译成指令为:- binary: 111111001110 00001 000 01111 0010011
- hex: 0xfce08793
load 指令
没错,访存用的 load 指令也是 I 型指令:

- rd (5): 结果放置的寄存器
- rs1 (5): 基地址寄存器
- immediate (12)
- 基地址寄存器的值 + 立即数 → load 内存地址

lw x14,8(x2)可翻译为:- binary:000000001000 00010 010 01110 0000011
- hex: 0x00812703
S 型指令
Store 指令:

- rs1 (5): 基地址寄存器
- rs2 (5): 数据寄存器
- immediate (11:5) + immediate (4:0) :地址偏移
[! question] 为什么不把 rs2 用作 imm 的低位? RISC-V 设计让 rs1 和 rs2 的位置保持固定。
对于所有的操作来说,关键路径包括获得寄存器的值
- 把读的寄存器都放到相同的位置,那么每次都可以立即去读寄存器文件,不需要做判断
- 如果读出来的数据其实是不必要的(例如 I 类型),后续丢弃即可
- 其它的 RISC 体系结构的设计有些许的不同
- 在译码阶段需要通过指令来判断需要读哪些寄存器
- 寄存器位置保持不变是 RISC-V 的体系结构上一系列微小的调整之一,可以让整个处理器工作流程更好

sw x14,8(x2)- binary: 0000000 01110 00010 010 01000 0100011
- hex: 0x00e12423
B 型指令
分支指令:

- beq and bne: 需要指定目标地址,也需要两个寄存器间比较
- opcode 指定是 beq (4) 还是 bne (5)
- rs1 , rs2 用来指定两个寄存器
- 与 S 类型指令非常相似——两个寄存器(rs1, rs2),一个立即数(12 位)
- Imm 表示了
[-4096, +4094]范围的 2 字节对齐的偏移 - Immediate 用 12 比特 表示了 13 比特的范围
- 因为 2 字节对齐,所以最低位总是为 0,因而省略了
- B 类型中
imm[12:1]与 S 类型中imm[11:0]不同
使用 immediate 指定地址?
PC 相对跳转,循环的跳转一般在一个比较小的范围。
- PC-Relative Addressing: 使用立即数作为补码,用作在 PC 上的偏移
- 类似于 lw/sw 的基址偏移寻址,源寄存器 rs1 为 PC
- 这样可以指定从 PC 开始的 ± 2^11 的地址范围
实际地址范围的计算:
- 实际上 RISC-V 使用的是固定长度的指令字长,内存是按字节地址寻址的
- 指令是按照字对齐的,指令的地址总是 2 的倍数(最后一位为 0)(与 Compact 的指令格式兼容,需要最后一位为 0 即可,但是在 RV32I 中实际是 4 字节对齐的)
- PC 总是指向一个指令地址,就可以做类型指针的操作
- 在指令地址范围计算的时候,可以指定 ± 2^12 范围的地址
分支的计算:
- 不需要分支:PC = PC + 4
- 需要进行分支:PC = PC + immediate
- immediate 是跳转字节数 (注意
imm[12:1]需要加上最末尾隐含的 0 位) - 为向前(+),或者向后(-)的偏移地址(范围为 )
- immediate 是跳转字节数 (注意
分支举例:


[! note] PC 相对寻址的特性
PC 相对寻址的情况下,如果整块代码进行移动,则代码中的相对寻址值无需更改,如果只移动其中的几行代码,则相对寻址值可能需要更改
如果需要移动的范围超过表达的指令范围 > 2
- 要么选用其它指令
- 要么分步:
beq x10, x0, far # next instr # 可转换为: bne x10, x0, next j far next: # next instr
U 型指令
处理大立即数——imm 长度有 20 位:

- lui: Load Upper Immediate
- lui reg, imm : 将 20 位的立即数装入到寄存器 reg 的高 20位
- 将低 12 位清零
- auipc: Add Upper Immediate to PC
使用 lui 指令的例子:
- lui 设置了高 20 位,通过 addi 设置低12位
- 例 1:设置 0x87654321
lui x10,0x87654 # x10=0x87654000addi x10,x10,0x321 # x10=0x87654321
- 例 2:设置 0xDEADBEEF
lui x10,0xDEADB # x10=0xDEADB000addi x10,x10,0xEEF # x10=0xDEADAEEF- 解决办法:lui 高 20 位 加 1
- 伪指令 li x10,0xDEADBEEF: 自动生成两条指令

J 型指令
跳转指令:
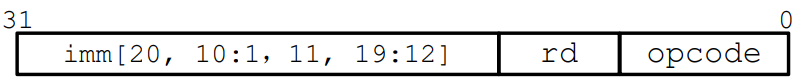
- Rd: 返回地址(PC+4)
- Imm: 偏移 offset, 设置跳转 PC = PC + offset
- 跳转范围:
[-2^19 ,+2^19]个位置,2 字节为单位 - 实际跳转范围
[-2^18 ,+2^18]个 32-bit 指令 - J 伪指令
j Label=jal x0, Label# Discard return address njal ra, FuncNam# Call function within 2^18 instructions of PC
Jalr 指令
属于 I 类型而不是 J 类型

Jalr rd, rs, immediate- Rd: 返回地址(PC+4)
- Imm: 偏移 offset, 设置跳转 PC = rs1 + offset
- Immediate 与 I 类型指令中的算术和加载指令一样
- 注意,不需要 ✖2
# Jalr用法例子
# ret and jr psuedo-instructions
ret == jr ra == jalr x0, 0(ra)
# Call function at any 32-bit absolute address
lui x1,<hi20bits>
jalr ra, x1, <lo12bits>
# Jump PC-relative with 32-bit offset
auipc x1,<hi20bits> # Adds upper immediate value to
# and places result in x1
jalr x0, x1,<lo12bits> # Same sign extension trick needed
# as LUI
单周期数据通路
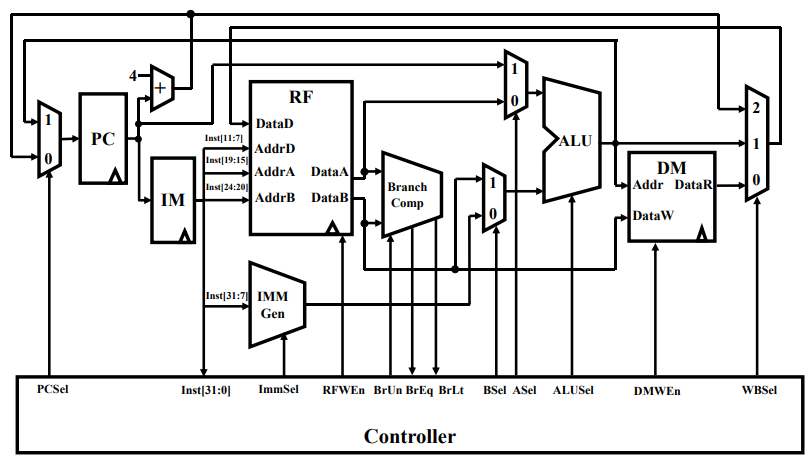
支持 R 型指令的数据通路设计
- R 型指令有:add, sub 等
- 执行过程:
- 取指令→
- 分析指令→
- 执行指令: 取操作数, 运算, 结果写回→
- 计算下一条指令的地址→回到取指
- 指令的内部域含义:
由此,设计能够实现 R 型指令的数据通路如下:
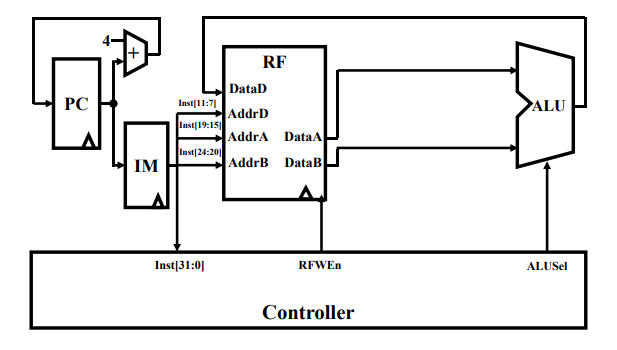
- PC:程序计数器,每个周期都+4,移向下一条指令
- IM (Instruction Memory):指令存储器
- RF (Register Files):寄存器文件,用以存储指令中的操作数,供给接下来 ALU 运算使用
支持 I 型指令的数据通路
以特殊的 I 型指令 Load 系列为例:
- Load: lw rd rs1 imm
- 指令功能
Addr = R[rs1] + SignExt(imm)R[rd] = MEM[Add]
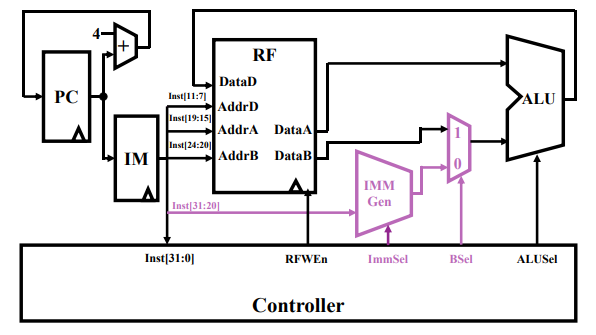
- IMM Gen:立即数生成器
- 另一个是二路选通器:BSel 位是 0 时选用 IMM Gen 生成的立即数,BSel 位是 1 时选用寄存器中的数据;
支持 S 型指令的数据通路
S 型指令会将 ALU 计算完成的数据回写到主存中:
- Store: sw rs2 rs1 imm
- 指令功能:
Addr = R[rs1] + SignExt(imm)MEM[Addr] = R[rs2]
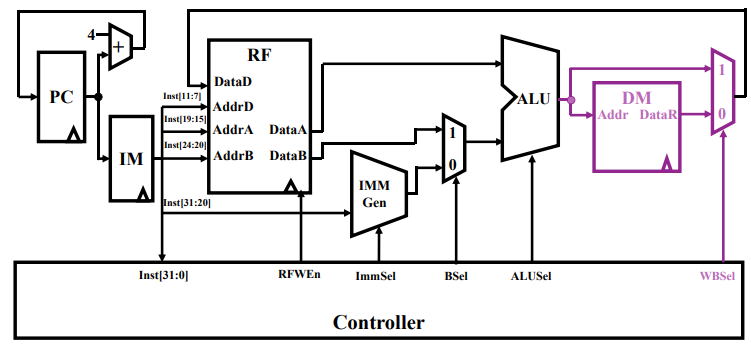
- DM (Data Memory):数据存储器,暂时存储 ALU 计算的结果;
- 另一个是二路选通器:WBSel 为 0 时回写到内存中;WBSel 为 1 时完成周期,回到译码阶段;
这个通路还可以进一步改进:
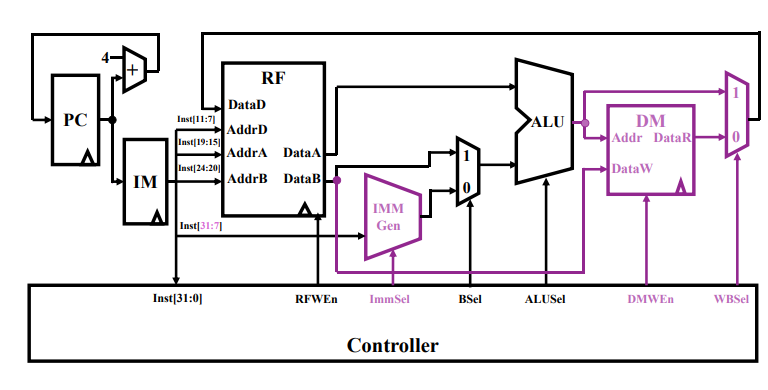
- 可以看到作出的改动就是从 IM 处取出的指令,可以预先流向 IMM Gen,从中提取出立即数;
- 其中 RF 的 AddrA 和 AddrB 分别接收 rs1 和 rs2 字段,从对应地址取出数据后各自通过 DataA 和 DataB 流出,这二者在 ALU 中进行大小比较;
- 注意到 DataB 有一部分已经流向了 DM,这是一种预取的机制,能够加快 ALU 比较后操作的处理速度,但对于逻辑方面没有影响;
支持 B 型指令的数据通路
B 型指令会根据比较的结果做出相应的操作:
- BEQ: beq rs1 rs2 label
- 指令功能
- if
R[rs1] = R[rs2] - then
PC <- PC+ SignExt(imm) - Else
PC <- PC+4
- if
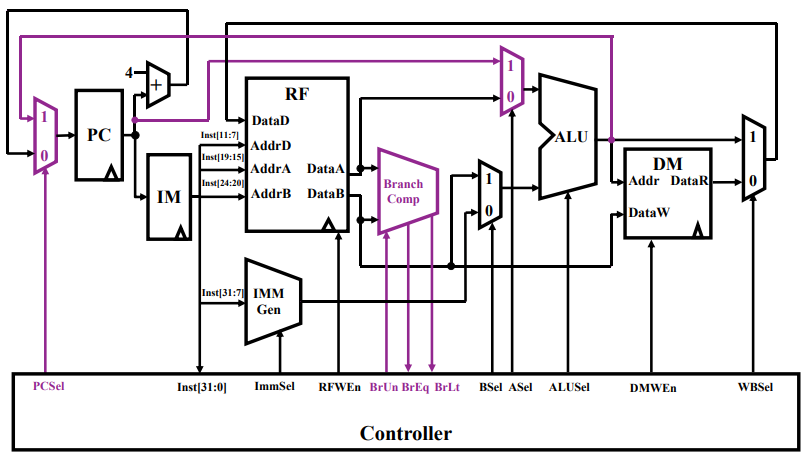
- Branch Comp 是用以数据比较的,DataA 和 DataB 是根据指令读出的操作数,二者比较后决定下一步操作;
- BrUn 控制信号是阻止 Branch 分支;其它 BrEq 和 BrLt 是等于或大于的结果信号;
- 注意到 ALU 前加了一个二路选通器,控制信号 ASel 为 0 时与之前一样,选择 RF 读出的数据输入到 ALU 中运算;ASel 为 1 时,选择 PC 的数据,这是用来实现分支的地址选取;
- 在 PC 前也加了一个二路选通器,控制信号 PCSel 为 0 时表示 PC 自增地选用下一条指令;PCSel 为 1 时选用分支的结果;
支持 U 型指令的数据通路
U 型指令是大立即数指令,其中立即数要占 20 位:
- lui reg, imm
- 指令功能
- 将 20 位的立即数装入到寄存器 reg 的高 20位
- 将低 12 位清零
- 对数据通路没有提出新的需求
支持 J 型指令的数据通路
J 型指令用以跳跃到对应立即数给出的地址处:
- Jump: jal rd, imm
- 指令功能:
- 置 rd 值为返回地址(PC+4)
- 设置跳转 PC = PC + offset
- 思考:是否缺少 PC+4 到 RF 的数据通路?
- 修改 ALU?
- 新增数据通路?
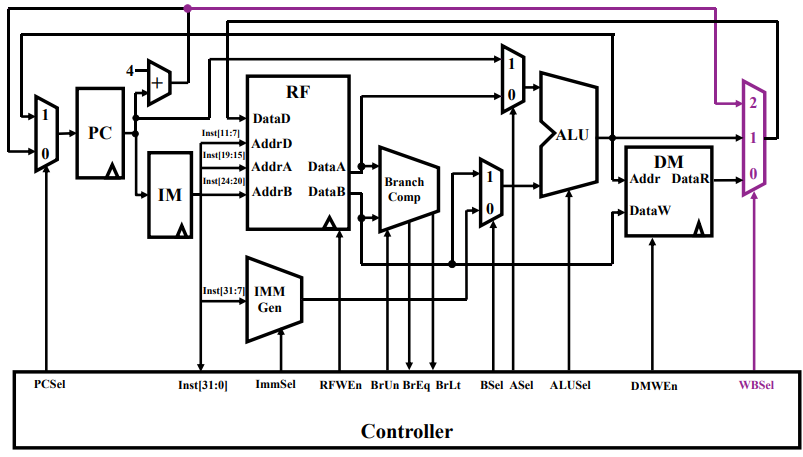
- 仅将最后的二路选通器改为三路选通器,其数据来源有:
- S 型指令的存回内存、
- ALU 计算的目标地址或寄存器、
- 由 PC 分支的直接用来跳跃的目标地址;
跳转 I 型指令 jalr
Jalr rd, rs, immediate
- Rd: 返回地址(PC+4)
- Imm: 偏移 offset, 设置跳转 PC = rs1 + offset
- Immediate 与 I 类型指令中的算术和加载指令一样
思考:现有数据通路是否可以满足该指令功能?当然可以,它本质还是 I 型指令
指令执行过程与控制
冯.诺依曼结构的计算机,即存储程序计算机,设置内存,存放程序和数据,在程序运行之前存入。
执行程序:
- 正确从程序首地址开始;
- 正确分步地执行每一条指令,
- 还要形成下条待执行指令的地址;
- 并保证自动地连续执行指令,
- 直到结束程序的最后一条指令。
从主存储器读来一条指令,分析指令,按指令的功能要求完成执行过程,本条指令完成后自动开始下一条指令的执行过程,由硬件本身完成(PC+4)
[! note] 哈佛结构的特点 哈佛结构与冯·诺依曼结构处理器相比,处理器有两个明显的特点:使用两个独立的存储器模块,分别存储指令和数据,每个存储模块都不允许指令和数据并存;使用独立的两条总线,分别作为 CPU 与每个存储器之间的专用通信路径,而这两条总线之间毫无关联。
指令执行的步骤:
- 读取指令 (IF), 从存储器读来指令并形成下条指令地址
- 指令译码 (ID), 指令译码,读寄存器堆为 ALU 准备数据
- 执行运算 (EXE), ALU 执行数据运算或计算存储器地址
- 存储器读写 (MEM), 完成存储器的读操作或者写操作
- 写回 (WB), 写 ALU 的结果或存储器读出数据到寄存器堆
从如何为不同指令安排这几个阶段,几个阶段如何 衔接考虑,大体有3 种可行方案,各自都对计算机的 内部结构、部件设置及其控制方式有着不同要求:
单周期 CPU
计算机一条指令的执行时间被称为指令周期,一个 CPU 时钟时间被称为CPU 周期(在某些计算机中,还可再把一个 CPU 周期区分为几个更小 的步骤,称其为节拍)。
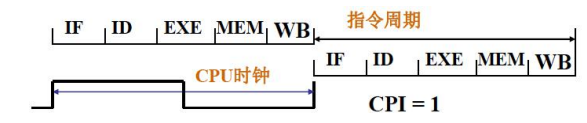
- 执行每条指令平均使用的 CPU 周期个数被称为 CPI
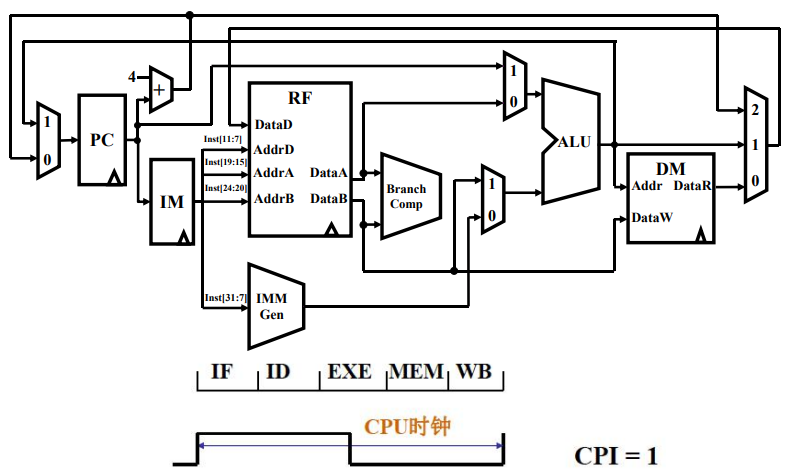
- 全部指令都选用一个 CPU 周期完成的系统被称为单周期 CPU,(意味着最长执行时间的指令决定了指令周期)
- 指令串行执行,前一条指令结束后才启动下条指令。
- 每条指令都用 5 个步骤的时间完成,控制各部件运行的信号在整个指令周期不变化。
- 单周期 CPU 用于早期计算机,系统性能和资源利用率很低,相对当前技术变得不再实用。
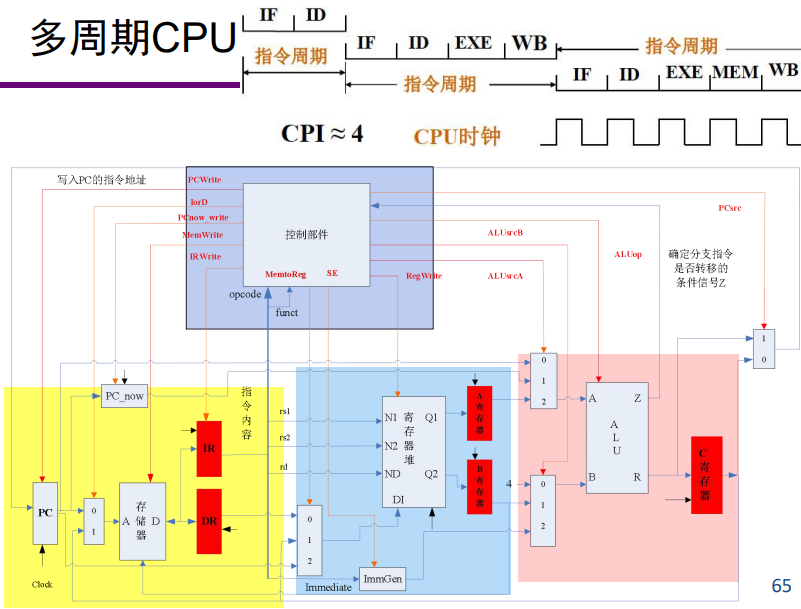
多周期 CPU
- 依据不同指令各自的功能需求为其选择不等的执行步骤的系统被称为多周期 CPU,
- 控制各部件运行的控制信号随着指令执行步骤改变,
- 系统性能和资源利用率更高。
- 相邻指令可以完全串行执行,也可能部分时间重叠,多周期 CPU(相比单周期 CPU)更实用。
流水线 CPU
全部指令都是选用5个步骤完成,执行时间相同,但相邻指令的执行并不是完全串行的,执行时间有所重叠,例如每结束指令的一个执行步骤就启动下条指令,这被称为指令流水线技术 pipeline。
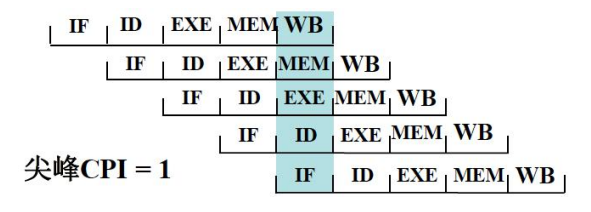
- 所有部件都高速运行,尖峰时刻 1 个 CPU 时钟执行一条指令,只不过是来自 5 条指令的各部分;
- 系统性能和资源利用率更高,显著地提高系统的性能价格比,但计算机结构和控制器的设计、实现略显复杂。当前计算机中普遍使用这种方案。