单周期 CPU 设计
要实现的指令集
选取 RISC-V 指令中9条典型指令组成的子集:
- 访存指令:lw、sw
- 算术运算指令:add、sub、andi、auipc
- 转移指令:beq、jal、jalr
其他指令的实现原理可以从中体现——上面 9 条指令覆盖了所有的 RISC-V 指令集的不同类型指令
解决三个主要问题
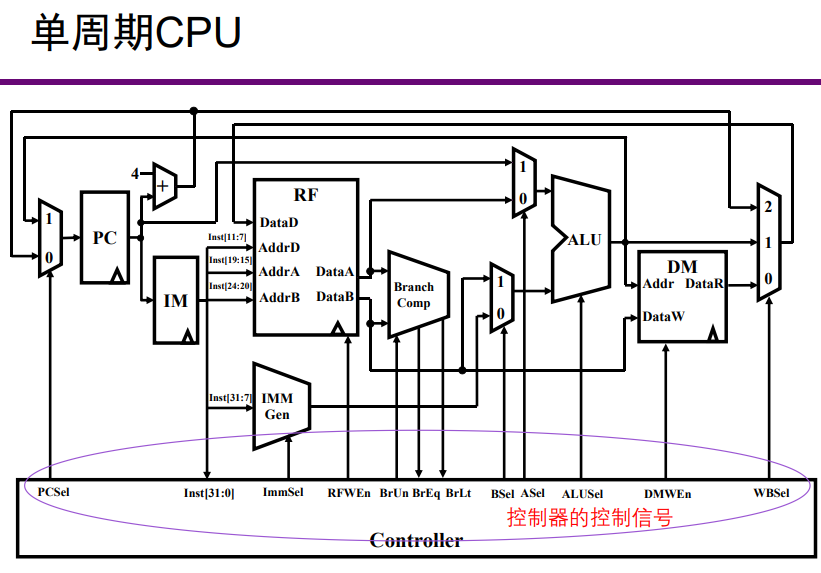
- 数据通路设计
- 控制信号设计
- 执行时序设计
元件细节
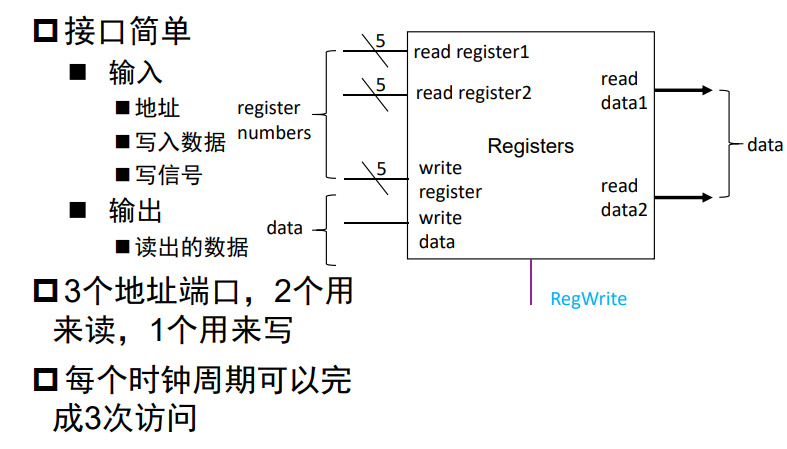
寄存器组 RF:
时序设计
- 每条指令占用一个(整)时钟周期
- 取指令后分析指令,并给出整个执行期间的全部信号
- 不需要状态信息,在时钟的结束的边沿写入结果
- 控制对象
- ALU 的运算
- 寄存器组和存储器的写入
- 多路选通器
- 时钟周期开始时读取指令
- 与具体指令无关,只要 PC+4 正确运行,找到下一条合法指令即可;
各指令具体的控制细节
时钟周期开始时

- 根据 PC 的值找到 IM 中对应的指令——取指阶段
- PC←PC+4,自动地找到下一条指令的地址;
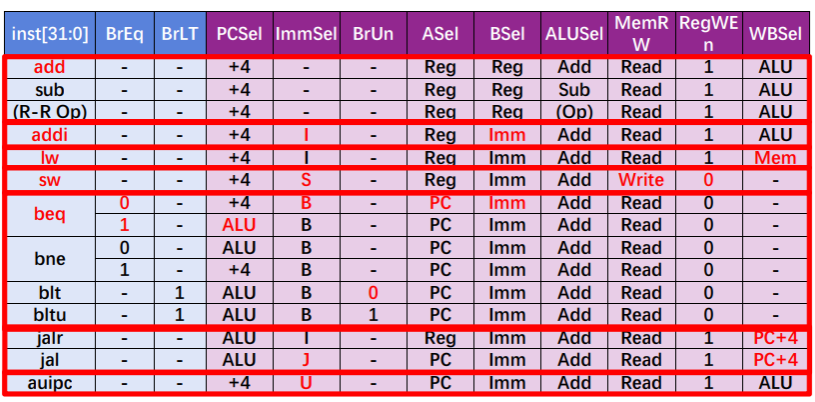
R 型指令
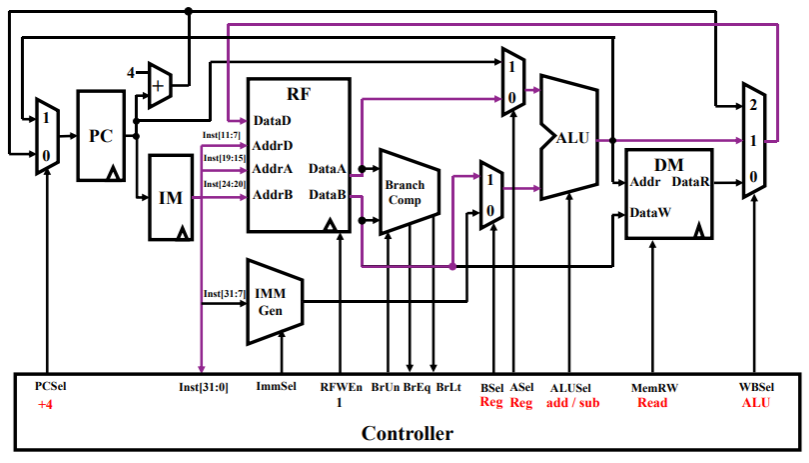
add rd,rs1,rs2- 指令从 IM 中读出,根据指令中各字段的含义和控制信号,选择合适的寄存器进行运算,此时控制信号 ASel=0、BSel=1,都表示寄存器选中;
- 注意到末尾的三路选通器有 1 个直连到 DataD 的,这是为了将 ALU 计算的结果写入指令中的目标寄存器 rd
- PC 自增 4
I 型指令
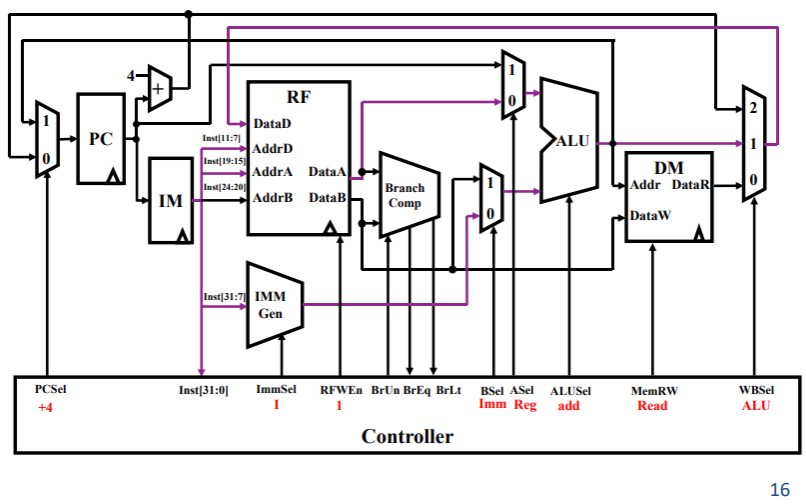
addi rd,rs,imm- 与 R 型指令大差不差,有些区别的地方在于 ImmSel=1,表示生成立即数;RFWEn=1,表示不使用寄存器 DataB,而是通过 BSel=0 获取立即数,用于 ALU 的计算;
- 同样 ALU 计算的结果在三路选通器后要回送到目标寄存器,PC 要自增;
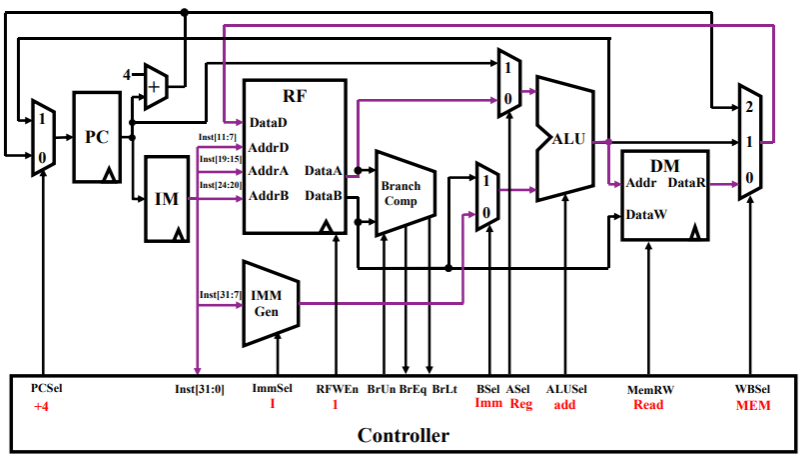
lw rd,rs,imm- load 指令也是 I 型指令的一种,故整体上没有什么大的差别,唯一区别是 ALU 中计算的结果,也就是 rs+imm 要作为 DM 的输入 Addr,从内存中读取数据到 DataR,最终通过三路选通器仍然写回到 rd 寄存器中
S 型指令
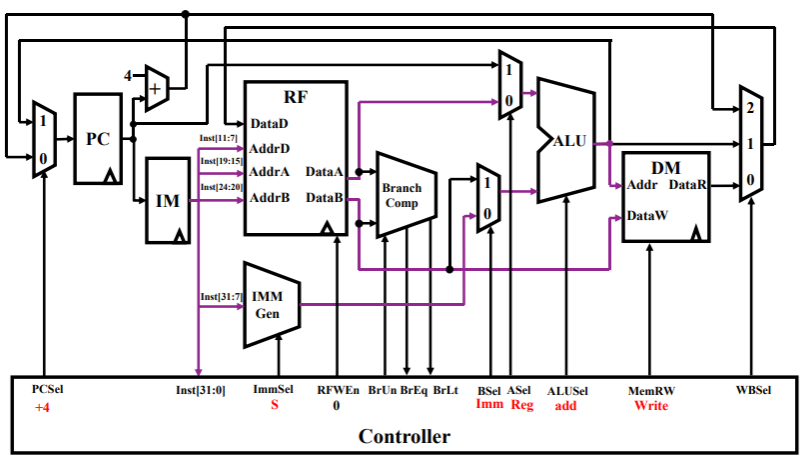
sw rs2,rs1,imm这里 rs2 是数据寄存器,rs1 是基地址寄存器,imm 是地址偏移量- 可以看到 DM 中控制信号 MemRW 变为写使能,根据 ALU 计算的结果作为写入地址、将数据寄存器 rs2 中的数据 DataB 写入的 DM 中,并且三路选通器都不开启
B 型指令
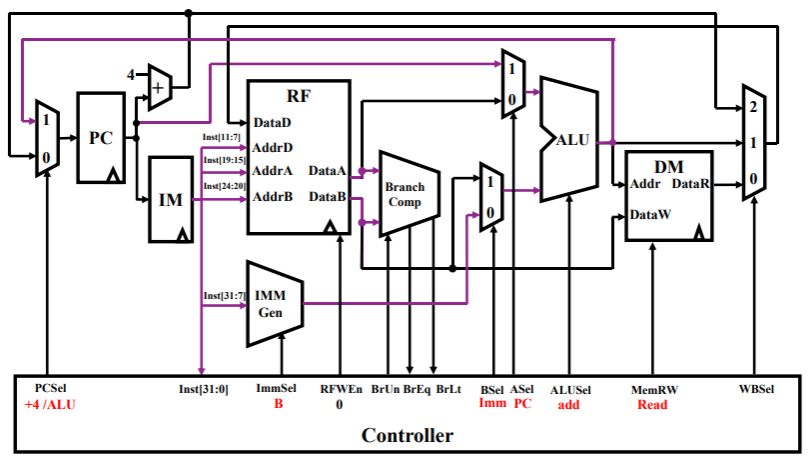
beq rs1,rs2,label- IMM Gen 生成的是 label 标签的地址,其寻址是基于基地址寄存器的偏移;
- Branch Comp 中对寄存器 rs1、rs2 中的数据进行比较,根据比较结果 ALU 决定下一个 PC 是自增(分支失败)、选择 label(分支成功)
J 型指令
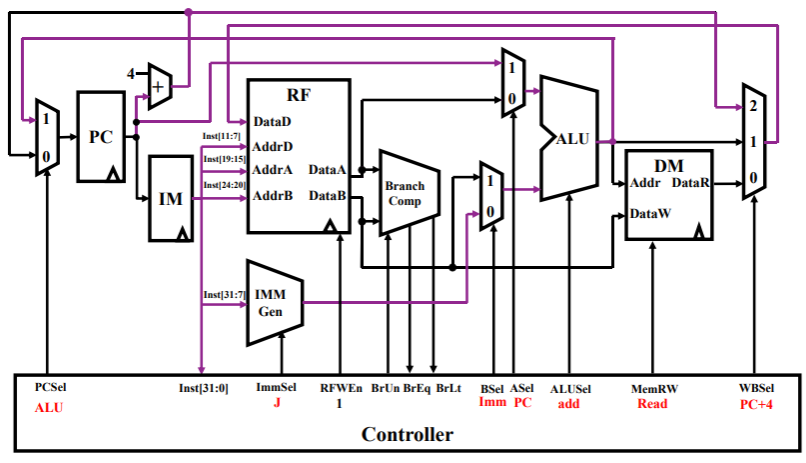
jal rd,imm- 强制跳转指令,根据 imm 的值设置跳转目标的地址,经过 ALU 计算出结果后写回到 PC 中,完成跳转;
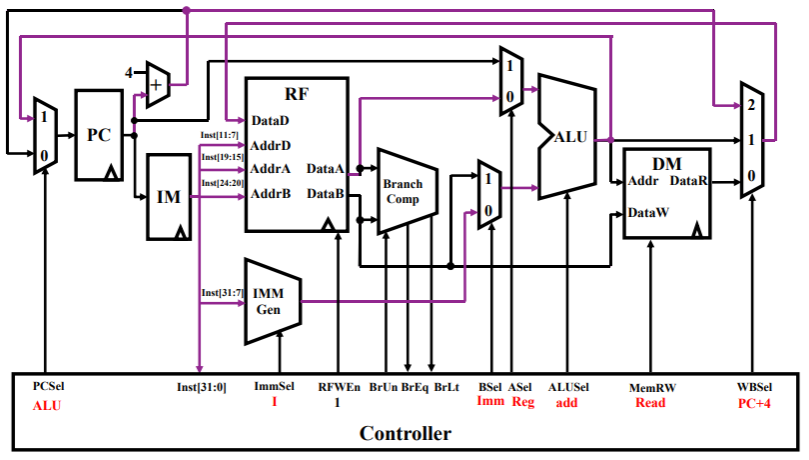
jalr rd,rs1,imm是 I 型指令,其中 rd 写入的是返回地址(PC+4),而 PC 则写入 rs1+imm 的目标地址;
U 型指令
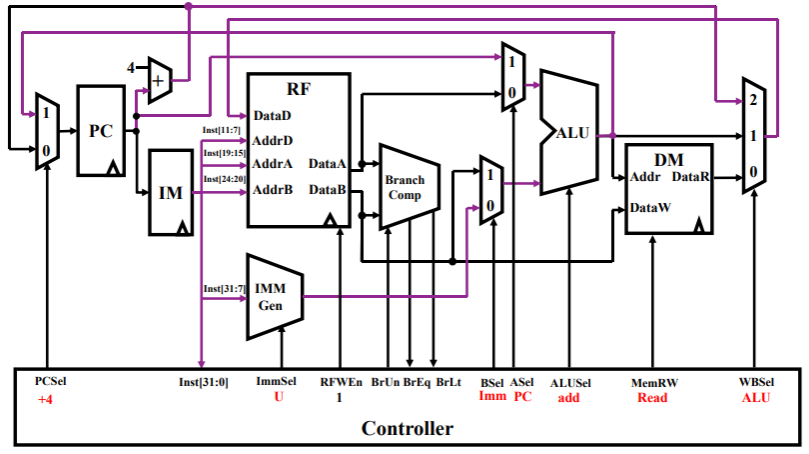
auipc rd,imm- auipc 指令将立即数左移 12 位加到 当前 PC 上,再写入到通用寄存器。
- 这样,可以将 auipc 中的 20 位立即数与 jalr 中的 12 位立即数组合,将执行流程转移到任何 32 位 pc 相对地址。 而 auipc 加上普通加载或存储指令中的 12 位立即数偏移量,可以使得程序访问任何 32 位 PC 相对地址的数据。
信号控制一览
单周期 CPU 特点
优点:
- 每条指令占用一个时钟周期
- 逻辑设计简单,时序设计也简单
缺点:
- 各组成部件的利用率不高
- 长时间地维持有效信号而不变化,可能导致后续无法复用
- 时钟周期应满足执行时间最长指令的要求
- Load 指令耗时极长
- CPI =1
多周期 CPU 设计
内容来自袁春风的计组,因为清华的 ppt 有所缺失,不过也可以参照往年的旧 ppt,毕竟 mips 和 riscv 大差不差。
基本思想
- 把每条指令的执行分解为大致相等的数个阶段,通常是 IF、ID、EX、MEM、WB 五个步骤,每个步骤占用一个时钟周期;
- 每个阶段内使用有限的、单一的部件;
- 控制器仅需提供当前步骤所需要的控制信号;
- 各阶段的执行结果在下一个时钟到来时保存到相应存储单元或稳定保存的组合电路中——引入了内部寄存器(锁存器),这在一定程度上延长了指令执行时间,毕竟内部锁存器也有执行延迟
- 时钟周期宽度以最复杂的阶段的所用时间为准,通常是一次存储器读写的时间
- 转入到下一步骤执行,需要引入状态标记当前执行步骤,形成了一组有限状态自动机
多周期 CPU 的 Datapath
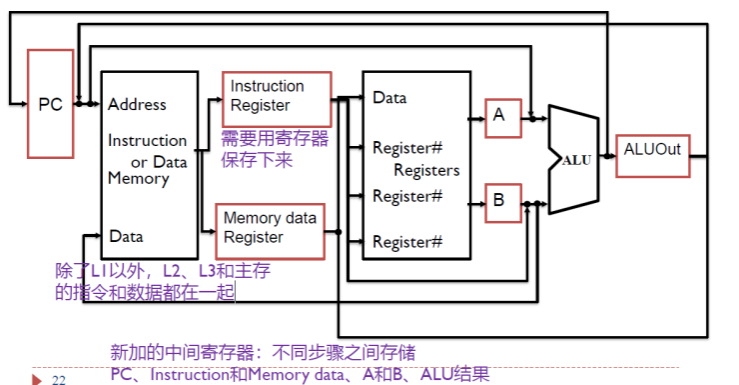
指令执行状态分析
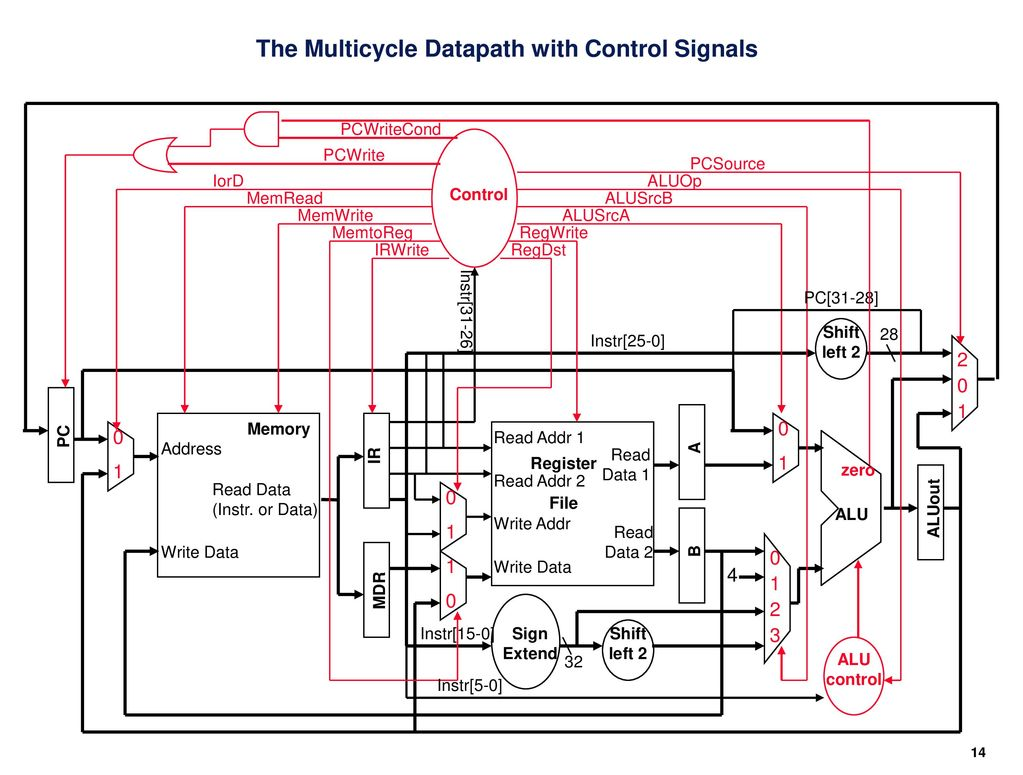
- PC 来源可以是 PC 自增、分支目标地址、无条件跳转目标地址,由 PCSource 信号控制;
- 分支目标地址保存在专门的分支目标地址寄存器 ALUout 中
- 无条件跳转目标地址由 PC 高 4 位和指令低 26 位拼接后在低位添加 00 后得到
- 对于需要判断溢出的算术运算类指令,当发生溢出时,禁止写结果到寄存器堆。
取指、译码/取数阶段
所有指令执行之前的公共操作。
-
取指令:
IR<-M[PC], PC<-PC+4- 将 PC 的数据读入存储器,并将读出的指令送入 IR(instruction register) 输入端,
- 下一个时钟到来时,读出的指令送至 IR,同时 PC 将送 ALU 的 A 口,并选择立即数 4 送 ALU 的 B 口,控制 ALU 做不判溢出的加法操作,得到 PC+4 送回 PC 输入端,完成 PC←PC+ 4
- 这一状态记作 IFetch,控制信号取值为
IorD=0,ALUSelA=0,ALUOp=addu,PCSource=01,PCWr=IRWr=1,MemWr=RegWr=BrWr=R-type=0
-
译码/取数:
CU<-IR<31:26>(CU 是译码,<31:26>是 opcode 字段)A<-R[IR<25:21>](<25:21>是 rs1 字段,放入 A 数据出口)B<-R[IR<20:16>](<20:16>是 rs2 字段,放入 B 数据出口)- 这个阶段 ALU 是空闲的,因此可以额外地计算分支目标地址——如果当前指令是分支指令,则可以节省一个时钟周期
- 分支目标地址计算方法是
PC+4+(SignExt(imm16)*4)
- 分支目标地址计算方法是
- 该阶段记作 RFetch/ID,控制信号取值为
ExtOp=1,ALUSelA=0,ALUSelB=11,ALUOp=addu,BrWr=1,PCWr=PCWrCond=IRWr=MemWr=RegWr=R-type=0
R-type 指令运行
R[IR<15:11>]<-A op B(<15:11>是 rd 字段)- 具体的操作控制信号 ALUctr 由局部 ALU 控制器根据 func 字段产生,主控制器生成的 ALUOp 不起作用
- 考虑到寄存器堆写入时“写使能”信号和写入数据、地址信号之间的竞争问题,该阶段要用两个状态来完成,第一个状态先送数据、地址,第二个状态再“写使能”信号有效
- 具体信号省略;
I-type 指令运算
R[IR<20:16>]<-A op Ext([IR<15:0>])(<20:16>是 rd,<15:0>是 imm)- 对运算指令是符号扩展,对逻辑运算指令是逻辑扩展
- 信号 ALUOp 和 ExtOp 根据指令的不同而设置,其余信号相应设置即可
lw 指令
- `R[IR<20:16>]←M[A+SignExt([IR<15:0>])]
- 由以下三个阶段组成:
- 访存地址计算
- 存储器取数状态:访存地址信号要与之前保持稳定,地址和数据要尽早稳定在寄存器堆的输入端相应端口,对其他寄存器和存储器不做任何改动
- 结果写回寄存器:计算结果写回寄存器,其他信号不变
sw 指令
M[A+SignExt([IR<15:0>])]<-B- 有两个阶段:
- 访存地址计算
- 存储器存数
B-type 指令执行
- 以 beq 为例:
if A!=B then PC<-Branch_dst_addr - 只要一个阶段:
- 分支执行、完成
J-type 指令执行
PC<-jump_dst_addr- 只需要一个阶段:
- 跳转执行、完成
指令执行状态转换图
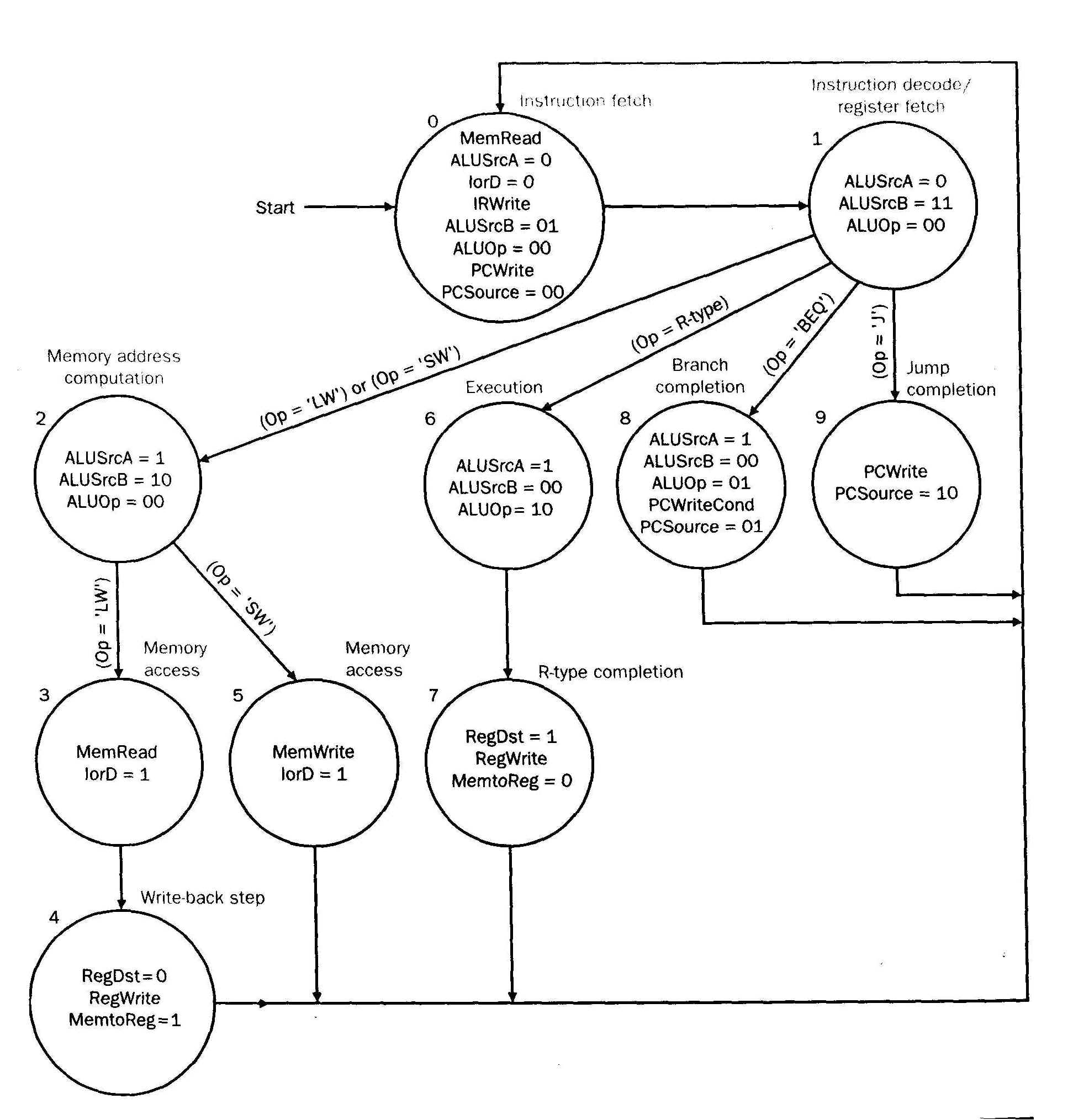
- 这个图里没有 I-type 指令,不过无关紧要,它和 R-type 几乎一模一样,唯一不同是第二个数据源 rs2 来自立即数生成器 IMM Gen
- 从上面可以看出各指令完成需要的 CPI:
- R-type, I-type, sw 需要的 CPI 都是 4
- lw 需要 CPI 为 5
- 跳转需要的 CPI 为 3
- 分支需要的 CPI 为 3,如果不在译码/取数阶段提前计算分支目标地址,则 CPI 为 4
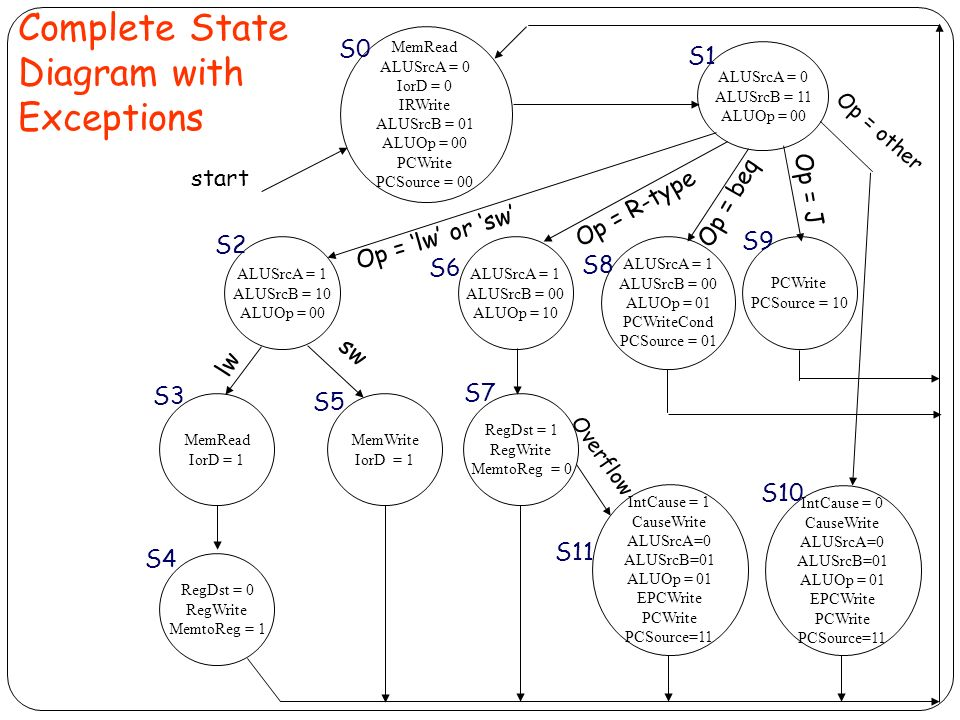
多周期 CPU 控制器设计
控制器组成
- 程序计数器 PC: 存放指令地址,有 自增 或 接收新值功能
- 指令寄存器 IR: 存放指令内容:操作码与操作数地址
- 指令执行步骤标记线路:指明每条指令的执行步骤和相对次序关系
- 控制信号产生线路:给出计算机各功能部件协同运行所需要的控制信号
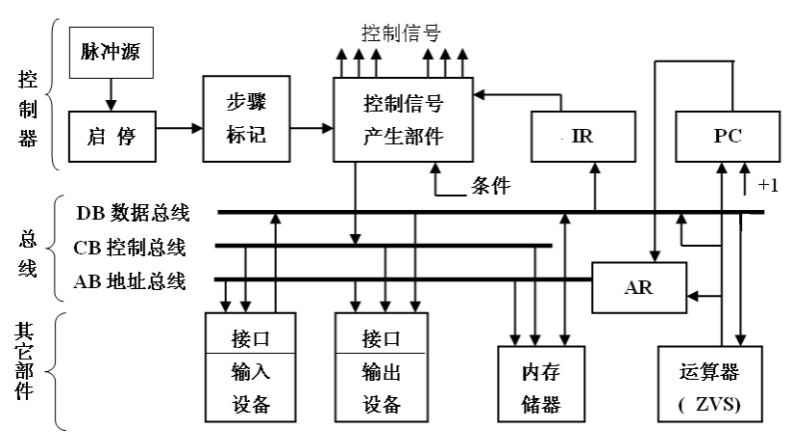
硬连线控制器
根据指令步骤标记线路和控制信号产生线路不同的组成和不同的运行原理,有两种不同类型的控制器:
- 硬连线控制器 (组合逻辑控制器): 采用组合逻辑线路、依据指令及其执行步骤直接产生控制信号。
- 微程序控制器:采用存储器电路把控制信号存储起来,依据指令执行的步骤读出要用到的信号组合
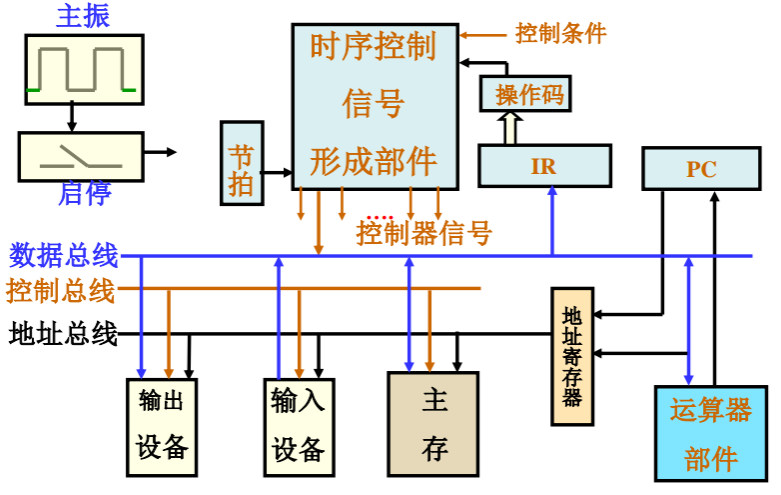
硬连线控制器的组成与实现:
- 硬连线控制器由程序计数器 PC、指令寄存器 IR、节拍发生器 Timer 和控制信号产生部件 4 部分组成。
- PC 用于提供待读出指令在主存储器中的地址,
- IR 用于保存从主存储器中读出的指令内容,
- Timer 用于给出并维护指令执行步骤的编码,
- 控制信号产生部件用于依据指令内容(在 IR 中)和指令执行所处的操作步骤(Timer 提供),用组合逻辑线路产生计算机本操作步骤中各个部件所需要的控制信号。
划分指令执行步骤,确定各步骤应执行的功能和步骤之间的衔接关系,以及确定各部件完成这些功能所需要的控制信号,是控制器设计的几个关键环节。
- 在多周期 CPU 系统中, 要按照指令总的功能要求, 把不同的功能序列划分到相应的步骤,再落实到不同的部件,控制器需要按照指令及其执行步骤,为计算机各个部件提供它们协同运行所需要的控制信号。
- 向各部件提供哪些控制信号,决定于各部件的运行要求。为此必须规划汇总各部件在各个执行步骤中要求使用的控制信号。这些信号是用组合逻辑电路产生的,可以表示为:信号 i = f (指令内容,执行步骤等),通常表现为多个由与、或两级逻辑构成的表达式。
微程序控制器
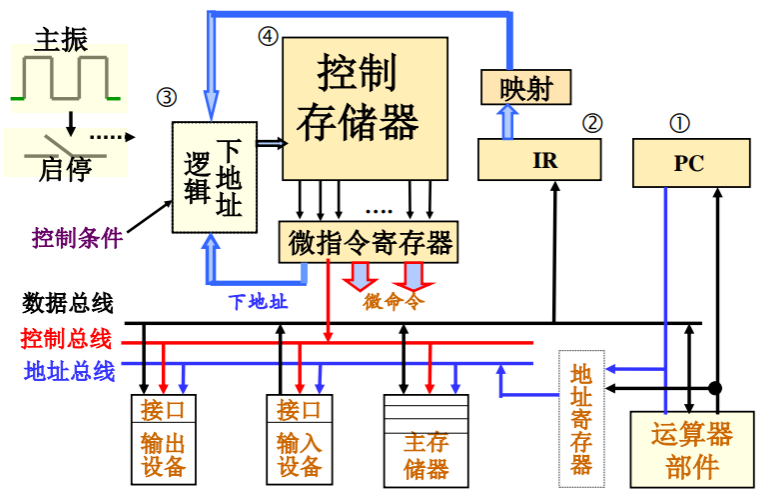
-
采用控制存储器存储每条指令的每个执行步骤所需要的全部控制信号
- 用微地址进行访问,读出控制信号并输出
-
采用下地址逻辑实现执行步骤之间的衔接
- 根据指令操作码映射出该指令的首条微指令的地址
- 每条微指令给出其下一步骤的微地址
微命令编码的方法
微指令通常是定长微指令字格式,与指令类似,也由位操作码和微地址码两部分组成。主要有四种编码风格:
- 直接控制法:类似位图,一个位对应一条微命令,一条微操作码的长度和所有微命令相当,无须译码。
优点:并行控制能力强,不必译码,控制电路简单、速度快
缺点:编码空间利用率极低
字段直接编码法:将微指令分成若干段,每个字段包含若干微命令。互斥的微操作组合在同一字段,相容微操作组合在不同字段。一条微指令中最多可同时发出的微操作数就是微命令字段的个数。
字段间接编码法:某一个字段可以表示为多个微命令组,到底代表哪组微命令,由另一个专门的字段决定,进一步压缩微指令的长度
最少编码法:采用类似指令编码的思想,整个微操作码部分作为一个字段,每次只产生一个微操作
[! note] 微指令地址的确定
- 计数器法
uPC+1->uPC或者
uPC+1+SignExt[imm16]->uPC
- 断定法:直接指定下一微指令的地址