Unix 并发机制
进程间传递数据
管道
管道是循环缓冲区,允许两个进程以生产者、消费者模型进行通信,是 FIFO 队列。
管道在创建时获得一个固定大小的字节数,当一个进程试图往管道中写时,若有足够的空间则立即执行写请求,否则被阻塞。读进程同理,只有在管道中数据足够大时,才会开始读。
管道分为两类,命名管道和匿名管道:
- 只有父子进程才可以共享匿名管道
- 不相关的进程只能共享命名管道。
消息
消息是有类型的一段文本。Unix 为参与消息传递的进程提供 msgsnd 和 msgrcv 两个 syscall。每个进程都有一个与之关联的消息队列,作用是信箱。
sender 指定每个发送的消息的类型,类型可被 receiver 用作选择的依据。receiver 按 FIFO 顺序接收消息或按类型区别地接收消息。
进程试图给满队列发送消息时会被阻塞,试图从空队列读取消息时也会被阻塞。但若试图读取某一特定类型消息,但此时还未产生这类消息,则进程不会被阻塞。
共享内存
Unix 的 IPC 手段中最快的一种。共享内存是虚存中的公共内存块,供多个进程使用。每个进程有只读或读写权限。
进程读写共享内存的指令与读取其它部分的指令相同(不是原子指令)。互斥约束由使用共享内存的进程提供,而不是共享内存机制的一部分。
触发其他进程行为
信号量
Unix SVR4 中信号量是非二元信号量,内核完成所有需要的操作,在操作完成前其他进程都不能访问该信号量。
组成部分:
- 信号量当前值
- 在信号量上操作的最后一个进程的 PID
- 等待该信号量的值大于当前值的进程数
- 等待该信号量的值为 0 的进程数
与信号量相关联的是阻塞在该信号量上的进程队列。
信号量实际上以集合形式创建。
与信号量有关的系统调用:
- semctl 系统调用允许同时设置集合中所有信号量的值;
- sem_op 把一系列信号量操作作为参数,每个操作定义在集合中的一个信号量上;
- sem_op 为正时,内核增加信号量的值,并唤醒所有等待该信号量的值增加的进程;
- 为 0 时,检查信号量的值,若信号量为 0 则继续其它信号量的操作;否则增加等待信号量为 0 的进程数量,并将该进程阻塞在信号量为 0 的事件上;
- sem_op 为负时,其绝对值小于信号量时,则给信号量的值加上 sem_op 的负数值,若结果为 0,则唤醒所有等待信号量值为 0 的进程;若绝对值大于信号量值,则把进程阻塞在使信号量值增加的事件上。
信号
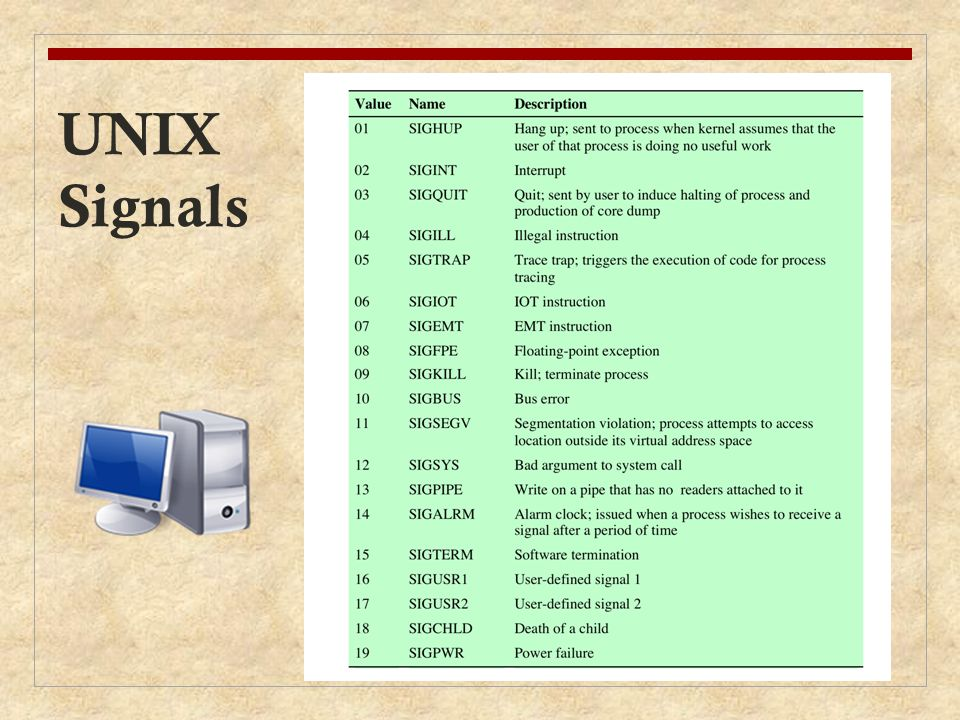
信号是用于向进程通知发生异步事件的机制。类似于硬件中断,但没有优先级——内核公平地对待所有信号,对于同时发生的信号一次只传递一个给进程使用。
进程间可以相互发送信号,内核也可以在内部发送信号。
信号的传递通过修改信号要发送到的进程的进程表的域来完成,每个信号只保存一位,因此不能对给定类型的信号进行排队。
只有进程被唤醒继续运行时,或进程准备从 syscall 中返回时,才处理信号。进程通过执行进程行为(如 teminate)、执行信号处理函数或忽略该信号来做出回应。
Linux 并发机制
实时信号
RT signals 是 Linux 的 POSIX.b 实时扩展的一个特性,相比标准 POSIX.1 的 UNIX 信号有如下不同:
- 支持按优先级顺序排列的信号传递
- 多个信号能进行排队
- 标准信号中的数值和消息只是通知,不能发送给目标进程,但 RT signals 可以将数值随信号一起发送过去。
原子操作
atomic operation 在执行时不会被打断或干扰,单处理器中线程一旦启动原子操作,则从变量开始到结束的这段时间内不能中断线程;多处理器系统中,原子操作的变量被锁住,直到原子操作执行结束前不允许其它进程访问。
Linux 中的原子操作有两类:一种是针对整数变量的操作,一类是针对位图的某一 bit 的操作。具体物理实现,基于处理器体系结构是否有相应汇编指令,若没有则通过锁住内存总线的方式来保证操作原子性。
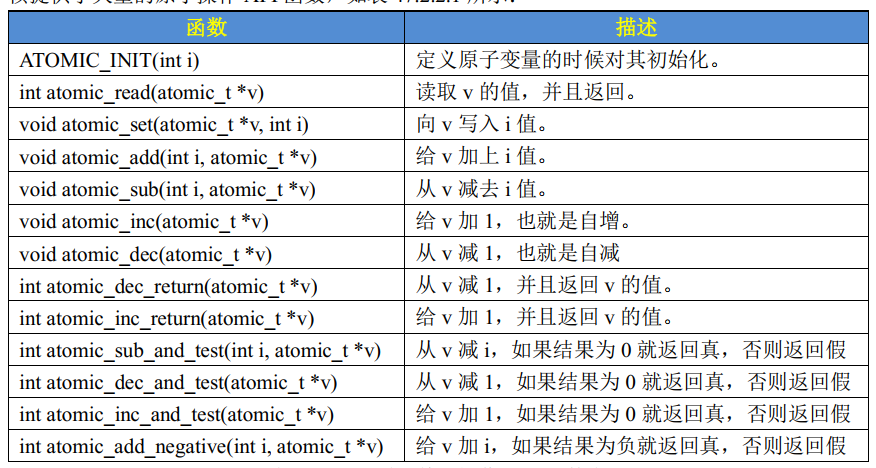 atomic integer operations 定义了特殊的数据类型 atomic_t,只有原子整数操作能应用于这个数据类型。好处是:
atomic integer operations 定义了特殊的数据类型 atomic_t,只有原子整数操作能应用于这个数据类型。好处是:
- 不受竞争条件保护的变量,不能使用原子操作;
- 能够避免被不恰当的非原子操作使用;
- 编译器不能错误地优化对该值的访问(只不能移到寄存器、起别名等)
- 隐藏了与计算机体系结构相关的差异
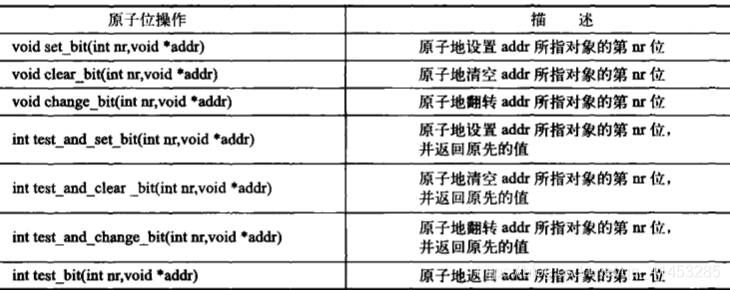 atomic bitmap operations 由指针变量指定的任意一块内存区域的位序列的某一位,不需要 atomic_t 数据类型。
atomic bitmap operations 由指针变量指定的任意一块内存区域的位序列的某一位,不需要 atomic_t 数据类型。
自旋锁
spinlock 用于保护临界区。同一时刻只有一个线程能获得自旋锁,其它任何试图获得自旋锁的线程将一致自旋(忙等待)直到获得🔒。
本质上自旋锁建立在内存区中的一个整数上,任何线程进入临界区前都必须检查该整数,若整数为 0 则线程置为 1 并进入临界区;若值非 0 则自旋等待直到为 0。
自旋锁缺点在于忙等待会浪费 CPU 性能,只有临界区内耗时小于两次上下文切换时间时,才会显得高效。
自旋锁有四个版本:

plain:临界区代码不被中断处理程序或禁用中断的情况下,可以使用普通自旋锁。不会影响当前处理器的中断状态。_irq:中断一直启用时,使用这种自旋锁;_irqsave:不知道执行期间中断是否启用时,使用这个版本。获得锁后,本地处理器的中断状态会被保存,锁释放时恢复原状态;_bh:发生中断时,相应中断处理器只处理最少量的必要工作,bottom half 的代码执行中断工作的其他部分,因此会尽快地启用当前中断。这种自旋锁用以禁用和启用下半部,以避免和临界区冲突。
spinlock 在单处理器系统和多处理器系统的实现不同:
- 单处理器中必须考虑:
- 是否关闭内核抢占功能,若关闭则线程在内核模式下运行不会被打断,锁没必要使用,编译时就会删除;若不关闭,spinlock 仍会被删除,实现为简单的启用中断/禁用中断;
- 多处理器情况下,spinlock 会编译到内核代码中。 实际使用 spinlock 时,可不考虑单处理器还是多处理器上执行。
读写自旋锁允许内核中达到比基本自旋锁更高并发度。读写自旋锁允许多个线程同时只读访问,只有要写时才互斥地访问该自旋锁。每个读写者的自旋锁包含一个 24 位读者计数和一个解锁标记:
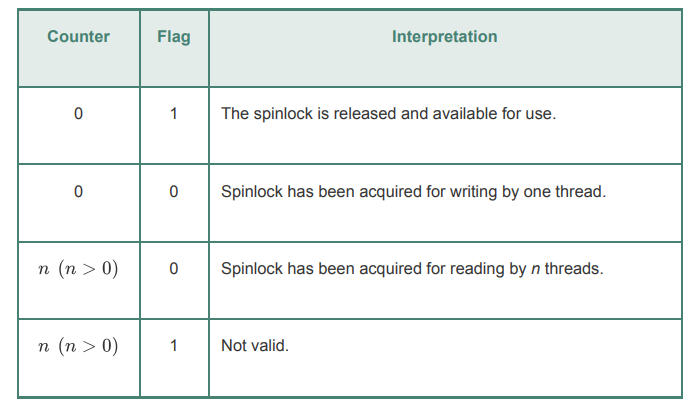
读写自旋锁采用的是读者优先策略的读写者问题。
信号量
内核代码能够调用内核信号量,是作为内核内部函数实现的,不能被 syscall 访问。
有三种信号量:binary semaphores, counting semaphores, reader-writer semaphores。
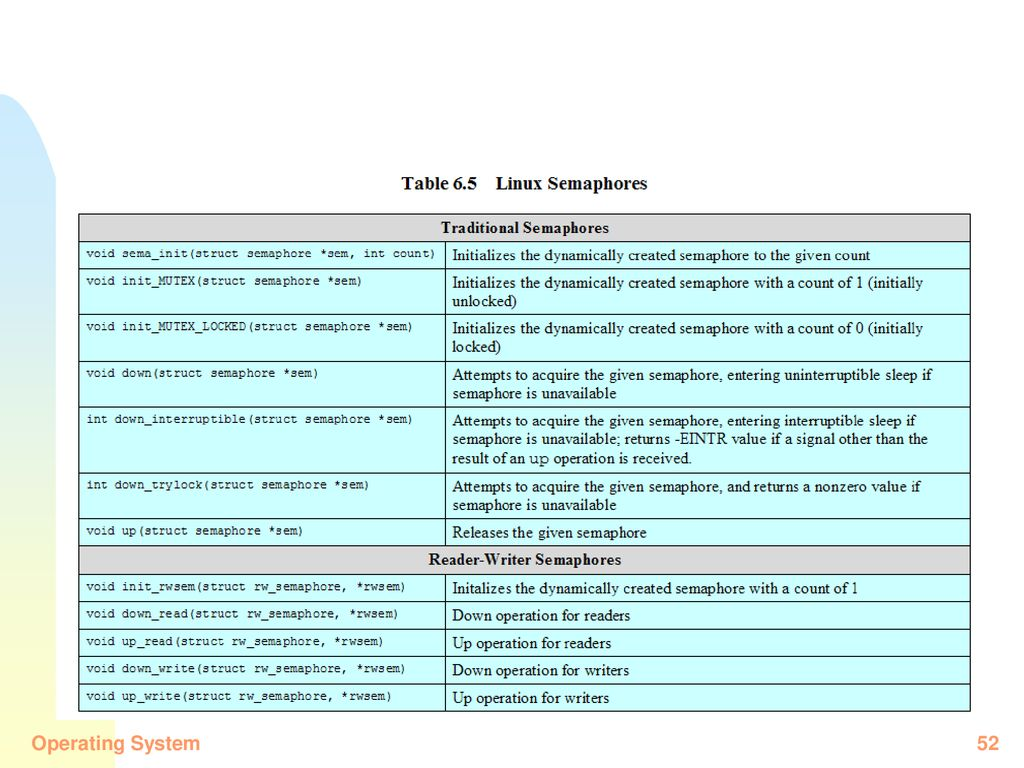 down (即 semWait)操作有三个版本:
down (即 semWait)操作有三个版本:
- down 本身对应于 semWait 操作,可用于二元或计数两种信号量;
- down_interruptible 允许因 down 而阻塞的线程同时能接收并响应内核信号。若线程被信号唤醒,则 down_interruptible 会在增加信号量值的同时返回错误代码-EINTR——告知线程对信号量操作的调用已取消。线程被强行放弃信号量,常用于设备驱动程序和其它服务
- down_trylock 可在不被阻塞的同时获得信号量,信号量可用时就获得它,否则返回一个非零值而不会阻塞该线程。
读写信号量:允许多读者、一写者。读者使用计数信号量,写者使用二元信号量。
屏障
编译器可能会优化源代码中的内存访问顺序,以提高处理器指令流水线的使用。要进行重新排序的指令需要检查数据依赖性:如 a=1; b=a;
Linux 提供内存屏障 memory barrier 设施保证指令执行的顺序。
 rmb ()保证代码中 rmb()之前的代码不会通过读操作穿过屏障(rmb 就是屏障)。类似地 wmb()保证写操作。
rmb ()保证代码中 rmb()之前的代码不会通过读操作穿过屏障(rmb 就是屏障)。类似地 wmb()保证写操作。
需要注意:
- barrier 与机器指令 load、store 相关。例如 a=b 会产生一个装载位置 b 和存储到 a 位置的指令;
- rmb、wmb、mb 指明编译器和处理器的行为,要求编译器不要重排指令,要求处理器中流水线上在屏障之前的任何指令必须在屏障后的指令开始执行之前提交。
Barrier ()只控制编译器行为,是轻量级版的 mb 指令。
读-复制-更新
RCU (read-copy-update)是另一种先进的轻量级同步机制。其中的读者不受锁影响,RCU 保护的共享资源必须通过指针访问。
RCU 的核心 API 只有 6 个:rcu_read_lock, rcu_read_unlock, call_rcu, synchronize_rcu, rcu_assign_pointer, rcu_dereference。
RCU 适合读频繁、写较少的场景:当一个写者想要更新资源时,会先创建该资源的一个副本,在副本上完成更新,然后更新指向资源的指针,使其指向新的副本。旧资源在不需要时释放。更新资源是个原子操作。
读者访问共享资源的操作必须封装在 rcu_read_lock 和 rcu_read_unlock 之间。在该代码块内访问共享资源指针的操作必须由 rcu_dereference 间接完成,并且不能在代码块之外的地方使用 rcu_dereference。
写者创建副本并更新后,在释放资源前必须确认不再被任何读者需要——使用 synchronize_rci 完成或非阻塞方法 call_rcu 完成。