mmap ()
mmap 将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。
头文件 <sys/mman.h>
文件映射概述
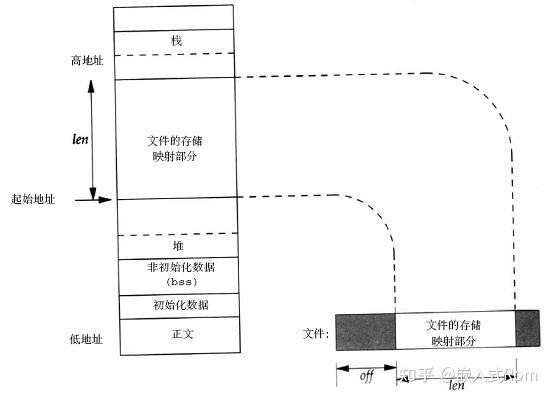
内存映射,简而言之就是将用户空间的一段内存区域映射到内核空间,映射成功后,用户对这段内存区域的修改可以直接反映到内核空间,同样,内核空间对这段区域的修改也直接反映用户空间。那么对于内核空间与用户空间两者之间需要大量数据传输等操作的话效率是非常高的。
以下是一个把普遍文件映射到用户空间的内存区域的示意图。
函数原型
void* mmap (void* start, size_t length, int prot, int flags, int fd, off_t offset);
- mmap ()必须以 PAGE_SIZE 为单位进行映射,而内存也只能以页为单位进行映射,
- 若要映射非 PAGE_SIZE 整数倍的地址范围,要先进行内存对齐,强行以 PAGE_SIZE 的倍数大小进行映射。
参数解释
函数:void *mmap (void *start, size_t length, int prot, int flags, int fd, off_t offsize);
-
参数 start:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址,映射成功后返回该地址。
-
参数 length:代表将文件中多大的部分映射到内存。
-
参数 prot:映射区域的保护方式。可以为以下几种方式的组合:
- PROT_EXEC 映射区域可被执行
- PROT_READ 映射区域可被读取
- PROT_WRITE 映射区域可被写入
- PROT_NONE 映射区域不能存取
-
参数 flags:影响映射区域的各种特性。在调用 mmap () 时必须要指定 MAP_SHARED 或 MAP_PRIVATE。
- MAP_FIXED 使用指定的映射起始地址,如果由 start 和 len 参数指定的内存区重叠于现存的映射空间,重叠部分将会被丢弃。如果指定的起始地址不可用,操作将会失败。并且起始地址必须落在页的边界上。如果参数 start 所指的地址无法成功建立映射时,则放弃映射,不对地址做修正。通常不鼓励用此 flag;
- MAP_SHARED 对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。
- MAP_PRIVATE 建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。这个标志和以上标志是互斥的,只能使用其中一个。对映射区域的写入操作会产生一个映射文件的复制,即私人的 “写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容。
- MAP_ANONYMOUS 建立匿名映射。此时会忽略参数 fd,不涉及文件,而且映射区域无法和其他进程共享。
- MAP_DENYWRITE 只允许对映射区域的写入操作,其他对文件直接写入的操作将会被拒绝。
- MAP_LOCKED 将映射区域锁定住,这表示该区域不会被置换(swap)。
- MAP_NORESERVE :不要为这个映射保留交换空间。当交换空间被保留,对映射区修改的可能会得到保证。当交换空间不被保留,同时内存不足,对映射区的修改会引起段违例信号。
- MAP_GROWSDOWN :用于堆栈,告诉内核 VM 系统,映射区可以向下扩展。
-
参数 fd:要映射到内存中的文件描述符。如果使用匿名内存映射时,即 flags 中设置了 MAP_ANONYMOUS,fd 设为 -1。有些系统不支持匿名内存映射,则可以使用 fopen 打开 / dev/zero 文件,然后对该文件进行映射,可以同样达到匿名内存映射的效果。
-
参数 offset:文件映射的偏移量,通常设置为 0,代表从文件最前方开始对应,offset 必须是分页大小的整数倍。
返回值与错误代码
- 若映射成功则返回映射区的内存起始地址;
- 否则返回 MAP_FAILED (-1),错误原因存于 errno 中。
- 错误代码:
- EBADF 参数 fd 不是有效的文件描述词
- EACCES 存取权限有误。如果是 MAP_PRIVATE 情况下文件必须可读,使用 MAP_SHARED 则要有 PROT_WRITE 以及该文件要能写入。
- EINVAL 参数 start、length 或 offset 有一个不合法。
- EAGAIN 文件被锁住,或是有太多内存被锁住。
- ENFILE:已达到系统对打开文件的限制
- ENODEV:指定文件所在的文件系统不支持内存映射
- ENOMEM:内存不足,或者进程已超出最大内存映射数量
- EPERM:权能不足,操作不允许
- ETXTBSY:已写的方式打开文件,同时指定 MAP_DENYWRITE 标志
- SIGSEGV:试着向只读区写入
- SIGBUS:试着访问不属于进程的内存区
内存映射的步骤
- 用 open 系统调用打开文件, 并返回描述符 fd.
- 用 mmap 建立内存映射, 并返回映射首地址指针 start.
- 对映射 (文件) 进行各种操作, 显示 (printf), 修改 (sprintf).
- 用
munmap (void *start, size_t lenght)关闭内存映射. - 用 close 系统调用关闭文件 fd.
主要用途
UNIX 网络编程第二卷进程间通信对 mmap 函数进行了说明。该函数主要用途有三个:
- 将一个普通文件映射到内存中,通常在需要对文件进行频繁读写时使用,这样用内存读写取代 I/O 读写,以获得较高的性能;
- 将特殊文件进行匿名内存映射,可以为关联进程提供共享内存空间;
- 为无关联的进程提供共享内存空间,一般也是将一个普通文件映射到内存中。
系统调用 mmap () 用于共享内存的两种方式
- 使用普通文件提供的内存映射:
- 适用于任何进程之间。此时,需要打开或创建一个文件,然后再调用 mmap ()
- 典型调用代码如下:
fd=open (name, flag, mode);
if (fd<0) /*Error Handler.*/
ptr=mmap (NULL, len , PROT_READ|PROT_WRITE, MAP_SHARED , fd , 0);
通过 mmap () 实现共享内存的通信方式有许多特点和要注意的地方,可以参看 UNIX 网络编程第二卷。
- 使用特殊文件提供匿名内存映射:
- 适用于具有亲缘关系的进程之间。
- 由于父子进程特殊的亲缘关系,在父进程中先调用 mmap (),然后调用 fork ()。那么在调用 fork () 之后,子进程继承父进程匿名映射后的地址空间,同样也继承 mmap () 返回的地址,这样,父子进程就可以通过映射区域进行通信了。
- 注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而 mmap () 返回的地址,却由父子进程共同维护。
- 对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可。
mmap、munmap、msync 组合实现内存映射与同步
- mmap 函数是 unix/linux 下的系统调用,详细内容可参考《Unix Netword programming》卷二 12.2 节。
- mmap 系统调用并不是完全为了用于共享内存而设计的。它本身提供了不同于一般对普通文件的访问方式,进程可以像读写内存一样对普通文件的操作。而 Posix 或系统的共享内存 IPC 则纯粹用于共享目的,当然 mmap () 实现共享内存也是其主要应用之一。
- mmap 系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用 read (),write()等操作。
- mmap 并不分配空间, 只是将文件映射到调用进程的地址空间里(但是会占掉你的 virutal memory), 然后你就可以用 memcpy 等操作写文件, 而不用 write () 了.
- 写完后,内存中的内容并不会立即更新到文件中,而是有一段时间的延迟,你可以调用 msync () 来显式同步一下, 这样你所写的内容就能立即保存到文件里了. 这点应该和驱动相关。 不过通过 mmap 来写文件这种方式没办法增加文件的长度, 因为要映射的长度在调用 mmap () 的时候就决定了. 如果想取消内存映射,可以调用 munmap () 来取消内存映射
munmap ()
函数原型:
int munmap (void* start, size_t length);
- start:要取消映射的内存区域的起始地址
- length:要取消映射的内存区域的大小。
返回说明
- 成功执行时 munmap ()返回 0。失败时 munmap 返回-1.
msync ()
函数原型:
int msync(const void *start, size_t length, int flags);
对映射内存的内容的更改并不会立即更新到文件中,而是有一段时间的延迟,可以调用 msync ()来显式同步一下, 这样内存的更新就能立即保存到文件里:
- start:要进行同步的映射的内存区域的起始地址。
- length:要同步的内存区域的大小
- flag: flags 可以为以下三个值之一:
- MS_ASYNC : 请 Kernel 快将资料写入。
- MS_SYNC : 在 msync 结束返回前,将资料写入。
- MS_INVALIDATE : 让核心自行决定是否写入,仅在特殊状况下使用
实例:用户空间和驱动程序的内存映射
基本过程
首先,驱动程序先分配好一段内存,接着用户进程通过库函数 mmap () 来告诉内核要将多大的内存映射到内核空间,内核经过一系列函数调用后调用对应的驱动程序的 file_operation 中指定的 mmap 函数,在该函数中调用 remap_pfn_range () 来建立映射关系。
映射的实现
首先在驱动程序分配一页大小的内存,然后用户进程通过 mmap () 将用户空间中大小也为一页的内存映射到内核空间这页内存上。映射完成后,驱动程序往这段内存写 10 个字节数据,用户进程将这些数据显示出来。
驱动程序:
#include <linux/miscdevice.h>
#include <linux/delay.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/init.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux/types.h>
#include <linux/delay.h>
#include <linux/moduleparam.h>
#include <linux/slab.h>
#include <linux/errno.h>
#include <linux/ioctl.h>
#include <linux/cdev.h>
#include <linux/string.h>
#include <linux/list.h>
#include <linux/pci.h>
#include <linux/gpio.h>
#define DEVICE_NAME "mymap"
static unsigned char array[10]={0,1,2,3,4,5,6,7,8,9};
static unsigned char *buffer;
static int my_open(struct inode *inode, struct file *file)
{
return 0;
}
static int my_map(struct file *filp, struct vm_area_struct *vma)
{
unsigned long page;
unsigned char i;
unsigned long start = (unsigned long)vma->vm_start;
//unsigned long end = (unsigned long)vma->vm_end;
unsigned long size = (unsigned long)(vma->vm_end - vma->vm_start);
//得到物理地址
page = virt_to_phys(buffer);
//将用户空间的一个vma虚拟内存区映射到以page开始的一段连续物理页面上
if(remap_pfn_range(vma,start,page>>PAGE_SHIFT,size,PAGE_SHARED))//第三个参数是页帧号,由物理地址右移PAGE_SHIFT得到
return -1;
//往该内存写10字节数据
for(i=0;i<10;i++)
buffer[i] = array[i];
return 0;
}
static struct file_operations dev_fops = {
.owner = THIS_MODULE,
.open = my_open,
.mmap = my_map,
};
static struct miscdevice misc = {
.minor = MISC_DYNAMIC_MINOR,
.name = DEVICE_NAME,
.fops = &dev_fops,
};
static int __init dev_init(void)
{
int ret;
//注册混杂设备
ret = misc_register(&misc);
//内存分配
buffer = (unsigned char *)kmalloc(PAGE_SIZE,GFP_KERNEL);
//将该段内存设置为保留
SetPageReserved(virt_to_page(buffer));
return ret;
}
static void __exit dev_exit(void)
{
//注销设备
misc_deregister(&misc);
//清除保留
ClearPageReserved(virt_to_page(buffer));
//释放内存
kfree(buffer);
}
module_init(dev_init);
module_exit(dev_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("LKN@SCUT");应用程序
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <linux/fb.h>
#include <sys/mman.h>
#include <sys/ioctl.h>
#define PAGE_SIZE 4096
int main(int argc , char *argv[])
{
int fd;
int i;
unsigned char *p_map;
//打开设备
fd = open("/dev/mymap",O_RDWR);
if(fd < 0)
{
printf("open fail\n");
exit(1);
}
//内存映射
p_map = (unsigned char *)mmap(0, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED,fd, 0);
if(p_map == MAP_FAILED)
{
printf("mmap fail\n");
goto here;
}
//打印映射后的内存中的前10个字节内容
for(i=0;i<10;i++)
printf("%d\n",p_map[i]);
here:
munmap(p_map, PAGE_SIZE);
return 0;
}先加载驱动后执行应用程序,用户空间打印如下:
sbrk ()
如何改变数据段大小?
[! note]
man sbrksbrk(2): change data segment size - Linux man page
- Description:
- brk() and sbrk() change the location of the program break, which defines the end of the process’s data segment (i.e., the program break is the first location after the end of the uninitialized data segment). Increasing the program break has the effect of allocating memory to the process; decreasing the break deallocates memory.
- brk() sets the end of the data segment to the value specified by addr, when that value is reasonable, the system has enough memory, and the process does not exceed its maximum data size (see setrlimit(2)).
- sbrk() increments the program’s data space by increment bytes. Calling sbrk() with an increment of 0 can be used to find the current location of the program break.
- Return
- On success, brk() returns zero. On error, -1 is returned, and errno is set to ENOMEM. (But see Linux Notes below.)
- On success, sbrk() returns the previous program break. (If the break was increased, then this value is a pointer to the start of the newly allocated memory). On error, (void * ) -1 is returned, and errno is set to ENOMEM.
brk 和 sbrk 会改变 program break 的位置,program break 是程序 data segment 的结束位置。
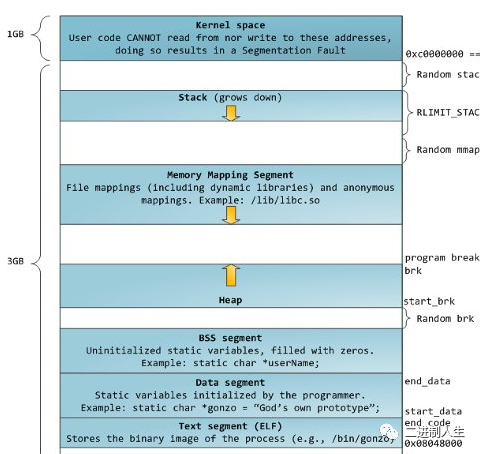
手册中的 data segment 包含了图中的 data segment、bss segment 和 heap,所以 program break 指的就是图中 heap 的结束地址。增加 program break 意味着给进程分配内存;减少 program break 意味着释放内存。
- brk ()设置 heap 的结束地址为 addr,当 addr 的值合理,且系统有足够内存,进程没有超出它的最大数据段大小时(参看 setrlimit (2))。成功则返回 0,否则返回-1。
- sbrk ()增加程序的 heap increment 字节,返回增加前的 heap 的 program break,调用 sbrk (0)可以用于获取进程 program break 的当前位置。
- 通俗讲就是可以改变下图 program break 的位置,而 brk ()是以绝对地址的形式,sbrk ()是以相对当前地址偏移的形式。
随机的堆起始地址
heap 的起始地址并不是 bss segment 的结束地址,而是随机分配的:
#include <stdio.h>
#include <unistd.h>
int bss_end;
int main(void){
void *pret;
printf("bss end: %p\n", (char *)(&bss_end) + 4);
pret = sbrk(0);
if (pret != (void *)-1)
printf ("heap start: %p\n", pret);
return 0;
}
运行结果可以看到:
$ ./a.out
bss end: 0x804a028heap start: 0x9f7f000
$ ./a.out
bss end: 0x804a028heap start: 0x90ca000
$ ./a.out
bss end: 0x804a028heap start: 0x92c1000
bss 和 heap 是不相邻的,并且同一个程序 bss 的结束地址是固定的,而 heap 的起始地址在每次运行的时候都会改变。
malloc 和 brk 的关系
brk 和 sbrk 很少直接使用,大部分情况下使用的是 malloc 和 free 函数来分配和释放内存。这样能够提高程序的性能,不是每次分配内存都调用 brk 或 sbrk,而是重用前面空闲的内存空间。
brk 和 sbrk 分配的堆空间类似于缓冲池,每次 malloc 从缓冲池获得内存,如果缓冲池不够了,再调用 brk 或 sbrk 扩充缓冲池,直到达到缓冲池大小的上限,free 则将应用程序使用的内存空间归还给缓冲。
前面是网上的说法,但实际即使 malloc 一段很小的空间,brk 也会一次性调整到 brk 和 mmap 调用的分界值,也就是根本不存在缓冲池扩充的机会:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main(void) {
void *tret;
char *pmem1, *pmem2;
tret = sbrk(0);
if (tret != (void *) -1)
printf("heapstart:%p\n", tret);//-----A
pmem1 = (char *) malloc(128);//分配内存1
if (pmem1 == NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
printf("pmem1:%p\n", pmem1);//------B
pmem2 = (char *) malloc(0x20bc0);//分配内存2
if (pmem2 == NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
printf("pmem2:%p\n", pmem2);//------C
tret = sbrk(0);
if (tret != (void *) -1)
printf("heap size on each load:%p\n", (char *) tret - pmem1);//---D
printf("heap end before free1:%p\n", tret);//---F
free(pmem1);
tret = sbrk(0);
printf("heap end after free1:%p\n", tret);//---G
free(pmem2);
tret = sbrk(0);
printf("heap end after free2:%p\n", tret);//---H
return 0;
}
运行结果如下:
./a.out
heap start:0x804b000
pmem1:0x804b410
pmem2:0xb7d5d008
heap size on each load:0x20bf0
heap end before free1:0x806c000
heap end after free1:0x806c000
heap end after free2:0x806c000
从结果可以看出调用 malloc (128)后缓冲池大小从 0 变成了 0x20bf0,将上面的 malloc (64)改成 malloc (1)结果也是一样,只要 malloc 分配的内存数量小于 0x20bf0,缓冲池都是默认扩充 0x20bf0 大小。值得注意的是如果 malloc 一次分配的内存超过了 0x20bf0(含等于),malloc 不再从堆中分配空间,而是使用 mmap ()这个系统调用从映射区寻找可用的内存空间。
第二次的内存分配了 0x20bc0,加上第一分配 128,显然超过了缓存池大小,所以会在 mmap 区分配,可以看到 pmem1 的地址和 pmem2 的地址相差很大。
另外我们可以发现 free 前后堆的结束地址并没有发生变化,印证了前面缓存的说法。
为啥是 0x20bf0 这个奇怪的值,暂时不清楚。我们前面的文章说是 128K,看来不准确了。我查了下资料,网上说如今的 glibc 使用了动态的阈值,初始值为 128_1024,下限为 0,上限由 DEFAULT_MMAP_THRESHOLD_MAX 决定,32 位系统为 512_1024,64 位系统为 4_1024_1024 * sizeof (long)。依据什么机制动态调整,暂时不清楚。
而且 pmem1 地址并不等于分配之前堆的起始地址,中间存在了 0x410 的空缺。
结论
-
当开辟的空间小于 128K 时,调用 brk()函数,malloc 的底层实现是系统调用函数 brk(),其主要移动指针
_enddata(此时的_enddata指的是 Linux 地址空间中堆段的末尾地址,不是数据段的末尾地址) -
当开辟的空间大于 128K 时,mmap()系统调用函数来在虚拟地址空间中(堆和栈中间,称为“文件映射区域”的地方)找一块空间来开辟。
malloc 机制的简单描述
具体内容
当一个进程发生缺页中断的时候,进程会陷入核心态,执行以下操作:
1)检查要访问的虚拟地址是否合法
2)查找/分配一个物理页
3)填充物理页内容(读取磁盘,或者直接置0,或者什么都不做)
4)建立映射关系(虚拟地址到物理地址的映射关系)
5)重复执行发生缺页中断的那条指令
如果第3步,需要读取磁盘,那么这次缺页就是 majfit(major fault:大错误),否则就是 minflt(minor fault:小错误)
内存分配的原理
从操作系统角度看,进程分配内存有两种方式,分别由两个系统调用完成:brk 和 mmap (不考虑共享内存)
1)brk 是将数据段(.data)的最高地址指针 _edata 往高地址推
2)mmap 是在进程的虚拟地址空间中(堆和栈中间,称为“文件映射区域”的地方)找一块空闲的虚拟内存。
这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系。
具体分配过程
情况一:malloc 小于 128K 的内存,使用 brk 分配。
将_edata 往高地址推(只分配虚拟空间,不对应物理内存(因此没有初始化),第一次读/写数据时,引起内核缺页中断,内核才分配对应的物理内存,然后虚拟地址空间建立映射关系),如下图:
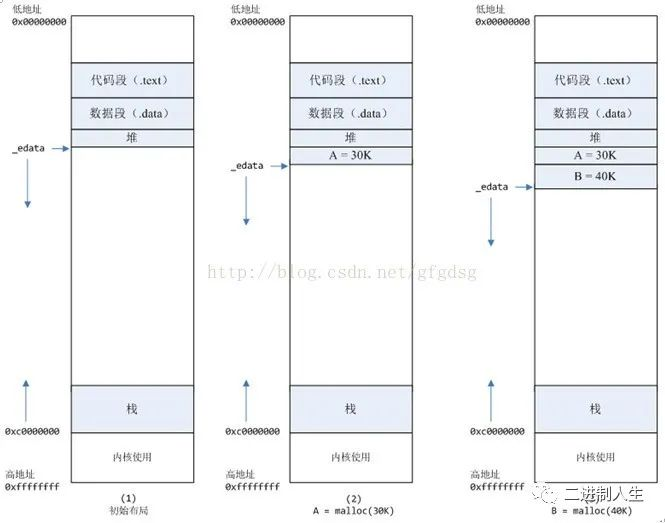
1,进程启动的时候,其(虚拟)内存空间的初始布局如图1所示
2,进程调用A=malloc(30K)以后,内存空间如图2:
malloc函数会调用brk系统调用,将_edata指针往高地址推30K,就完成虚拟内存分配
你可能会问:难道这样就完成内存分配了?
事实是:_edata+30K只是完成虚拟地址的分配,A这块内存现在还是没有物理页与之对应的,等到进程第一次读写A这块内存的时候,发生缺页中断,这个时候,内核才分配A这块内存对应的物理页。也就是说,如果用malloc分配了A这块内容,然后从来不访问它,那么,A对应的物理页是不会被分配的。
3,进程调用B=malloc(40K)以后,内存空间如图3。
情况二:malloc 大于 128K 的内存,使用 mmap 分配(munmap 释放)
4,进程调用C=malloc(200K)以后,内存空间如图4。
默认情况下,malloc函数分配内存,如果请求内存大于128K(可由M_MMAP_THRESHOLD选项调节),那就不是去推_edata指针了,而是利用mmap系统调用,从堆和栈的中间分配一块虚拟内存
这样子做主要是因为:
brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,因为只有一个_edata 指针,这就是内存碎片产生的原因,什么时候紧缩看下面),而mmap分配的内存可以单独释放。
当然,还有其它的好处,也有坏处,再具体下去,有兴趣的同学可以去看glibc里面malloc的代码了。
5,进程调用D=malloc(100K)以后,内存空间如图5。
6,进程调用 free(C)以后,C 对应的虚拟内存和物理内存一起释放。
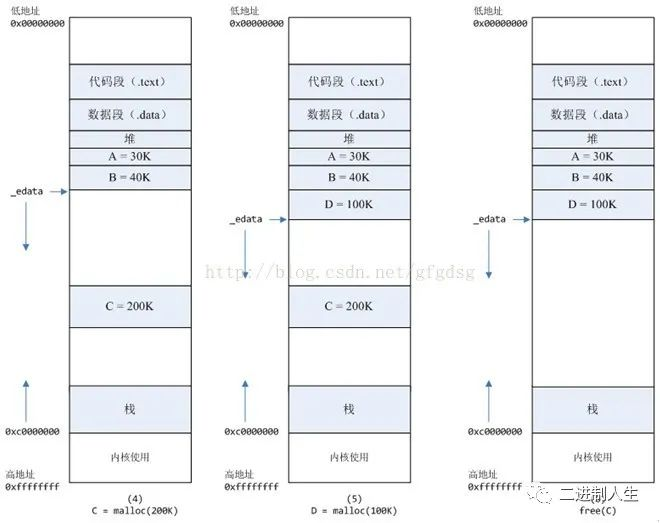
7,进程调用 free(B)以后,如图7所示。
B对应的虚拟内存和物理内存都没有释放,因为只有一个_edata指针,如果往回推,那么D这块内存怎么办呢?当然,B这块内存,是可以重用的,如果这个时候再来一个40K的请求,那么malloc很可能就把B这块内存返回回去了
8,进程调用free(D)以后,如图8所示。
B和D连接起来,变成一块140K的空闲内存。
9,默认情况下:
当最高地址空间的空闲内存超过128K(可由M_TRIM_THRESHOLD选项调节)时,执行内存紧缩操作(trim)。在上一个步骤free的时候,发现最高地址空闲内存超过128K,于是内存紧缩,变成图9所示。
思考
既然堆内内存 brk 和 sbrk 不能直接释放,为什么不全部使用 mmap 来分配,munmap 直接释放呢?
其实,进程向 OS 申请和释放地址空间的接口 sbrk/mmap/munmap 都是系统调用,频繁调用系统调用都比较消耗系统资源的。并且, mmap 申请的内存被 munmap 后,重新申请会产生更多的缺页中断。例如使用 mmap 分配 1M 空间,第一次调用产生了大量缺页中断 (1M/4K 次 ) ,当munmap 后再次分配 1M 空间,会再次产生大量缺页中断。缺页中断是内核行为,会导致内核态CPU消耗较大。另外,如果使用 mmap 分配小内存,会导致地址空间的分片更多,内核的管理负担更大。
同时堆是一个连续空间,并且堆内碎片由于没有归还 OS ,如果可重用碎片,再次访问该内存很可能不需产生任何系统调用和缺页中断,这将大大降低 CPU 的消耗。因此, glibc 的 malloc 实现中,充分考虑了 brk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128k) 才使用 mmap 获得地址空间,也可通过 mallopt(M_MMAP_THRESHOLD,) 来修改这个临界值。
shm ()
[! note] shm manual
- Description
- The POSIX shared memory API allows processes to communicate information by sharing a region of memory.
- The interfaces employed in the API are:
- shm_open
- ftruncate
- mmap
- munmap
- shm_unlink
- close
- fstat
- fchown
- fchmod
- Persistence
- POSIX shared memory objects have kernel persistence: a shared memory object will exist until the system is shut down, or until all processes have unmapped the object and it has been deleted with shm_unlink(3)
- Notes
- Typically, processes must synchronize their access to a shared memory object, using, for example, POSIX semaphores.
- System V shared memory (shmget(2), shmop(2), etc.) is an older shared memory API. POSIX shared memory provides a simpler, and better designed interface; on the other hand POSIX shared memory is somewhat less widely available (especially on older systems) than System V shared memory.